オリジナルソース: AIGCオープンコミュニティ 画像ソース:無制限のAIによって生成Transformer の登場により、ChatGPT などの大規模な言語モデルが自然言語タスクを処理する機能が大幅に向上しました。 ただし、生成されたコンテンツには不正確または古い情報が多数含まれており、コンテンツの信憑性を検証するための事実評価システムはありません。Google AI研究チームは、世の中の変化に対する大規模な言語モデルの適応性やコンテンツの信憑性を総合的に評価するために、「検索エンジンの知識を通じて大規模な言語モデルの精度を高める」という論文を発表しました。 検索エンジンからリアルタイム情報を取得することにより、ChatGPTやBardなどの大規模な言語モデルの精度を向上させるために、FRESH手法が提案されています。研究者は、さまざまな種類の600の実際の質問を含む新しい質問と回答のベンチマークセットFRESHQAを構築し、回答の頻度を「決して変わらない」、「遅い変化」、「頻繁な変化」、「誤った前提」**の4つのカテゴリに分類しました。同時に、回答のすべての情報が正確で最新でなければならないことを要求する厳密モードと、主な回答の正しさのみを評価するリラックスモードの2つの評価方法も設計されています。実験結果は、FRESHがFRESHQA上の大規模な言語モデルの精度を大幅に向上させることを示しています。 **たとえば、GPT-4は、FRESHの厳密モードの助けを借りて、元のGPT-4よりも47%正確です**。さらに、検索エンジンを融合するこの方法は、モデルのパラメータを直接拡張するよりも柔軟性があり、既存のモデルに動的な外部知識ソースを提供できます。 実験結果は、FRESHがリアルタイムの知識を必要とする問題に対する大規模な言語モデルの精度を大幅に向上させることができることも示しています。論文住所:オープンソースアドレス:ビッグランゲージモデルS / FreshQA(パイプラインでは、まもなくオープンソースになります)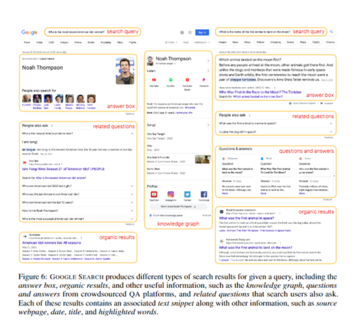 Googleの論文の内容から、FRESHのメソッドは主に5つのモジュールで構成されています。 ## **FRESHQAベンチマークセットを構築する** 変化する世界への大規模な言語モデルの適応性を包括的に評価するために、研究者は最初に、回答の変更の頻度に応じて4つのカテゴリに分類できる600の実際のオープンドメイン質問を含むFRESHQAベンチマークセットを構築しました:「決して変わらない」、「遅い変化」、「頻繁な変化」、「誤った前提」。1)決して変わらない:基本的に変わらない質問への答え。2)ゆっくりとした変化:質問に対する答えは数年ごとに変わります。3)頻繁な変更:毎年またはそれ以下で変更される可能性のある質問への回答。4)誤った前提:誤った前提を含む問題。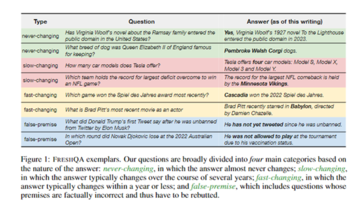 質問はさまざまなトピックをカバーし、難易度が異なります。 FRESHQAの大きな特徴は、答えが時間とともに変化する可能性があるため、モデルは世界の変化に敏感である必要があります。 ## **厳密モードと緩和モードの評価** 研究者は、回答のすべての情報が正確で最新でなければならないことを要求する厳密モードと、主要な回答の正しさのみを評価する緩和モードの2つの評価モードを提案しました。これにより、言語モデルの事実の性質を測定するためのより包括的で微妙な方法が提供されます。FRESHQAに基づいてさまざまな大規模言語モデルを評価するFRESHQAでは、GPT-3、GPT-4、ChatGPTなど、さまざまなパラメータをカバーする大規模な言語モデルを比較しました。 評価は、厳密モード(エラーなしが必要)と寛容モード(主要な回答のみが評価される)の両方で実施されます。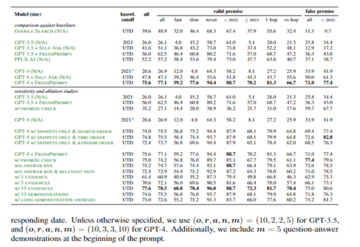 すべてのモデルは、リアルタイムの知識を必要とする問題、特に頻繁な変更や誤った前提の問題ではパフォーマンスが低いことがわかります。 これは、現在の大規模な言語モデルには、変化する世界への適応性に限界があることを示しています。 ## **検索エンジンからの関連情報の取得** 大きな言語モデルの事実の性質を改善するために、FRESHの中心的なアイデアは、検索エンジンから問題に関するリアルタイムの情報を取得することです。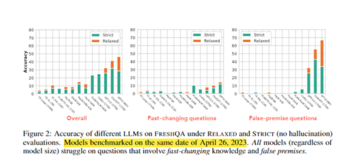 具体的には、質問が与えられた場合、FRESHはGoogleの検索エンジンをキーワードとしてクエリし、回答ボックス、Webページの結果、「他のユーザーも質問した」など、複数の種類の検索結果を取得します。 ## **スパーストレーニング統合による情報の取得** FRESHは、少数ショット学習を使用して、取得した証拠を統一された形式で大規模言語モデルの入力プロンプトに統合し、正しい答えに到達するために証拠を統合する方法のいくつかのデモンストレーションを提供します。これにより、大きな言語モデルにタスクを理解し、さまざまなソースからの情報を統合して、最新で正確な回答を考え出すように教えることができます。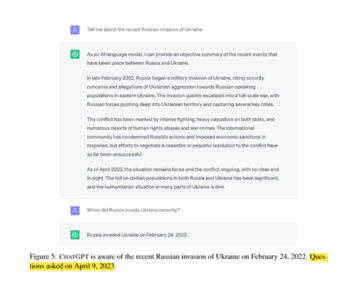 Googleは、FRESHは大規模な言語モデルの動的適応性を向上させるために非常に重要であり、これは大規模な言語モデルの将来の技術研究にとっても重要な方向性であると述べました。
Googleの最新テクノロジー:検索エンジンを通じて、ChatGPTなどのモデルの精度を大幅に向上させます
オリジナルソース: AIGCオープンコミュニティ
Transformer の登場により、ChatGPT などの大規模な言語モデルが自然言語タスクを処理する機能が大幅に向上しました。 ただし、生成されたコンテンツには不正確または古い情報が多数含まれており、コンテンツの信憑性を検証するための事実評価システムはありません。
Google AI研究チームは、世の中の変化に対する大規模な言語モデルの適応性やコンテンツの信憑性を総合的に評価するために、「検索エンジンの知識を通じて大規模な言語モデルの精度を高める」という論文を発表しました。 検索エンジンからリアルタイム情報を取得することにより、ChatGPTやBardなどの大規模な言語モデルの精度を向上させるために、FRESH手法が提案されています。
研究者は、さまざまな種類の600の実際の質問を含む新しい質問と回答のベンチマークセットFRESHQAを構築し、回答の頻度を「決して変わらない」、「遅い変化」、「頻繁な変化」、「誤った前提」**の4つのカテゴリに分類しました。
同時に、回答のすべての情報が正確で最新でなければならないことを要求する厳密モードと、主な回答の正しさのみを評価するリラックスモードの2つの評価方法も設計されています。
実験結果は、FRESHがFRESHQA上の大規模な言語モデルの精度を大幅に向上させることを示しています。 たとえば、GPT-4は、FRESHの厳密モードの助けを借りて、元のGPT-4よりも47%正確です。
さらに、検索エンジンを融合するこの方法は、モデルのパラメータを直接拡張するよりも柔軟性があり、既存のモデルに動的な外部知識ソースを提供できます。 実験結果は、FRESHがリアルタイムの知識を必要とする問題に対する大規模な言語モデルの精度を大幅に向上させることができることも示しています。
論文住所:
オープンソースアドレス:ビッグランゲージモデルS / FreshQA(パイプラインでは、まもなくオープンソースになります)
FRESHQAベンチマークセットを構築する
変化する世界への大規模な言語モデルの適応性を包括的に評価するために、研究者は最初に、回答の変更の頻度に応じて4つのカテゴリに分類できる600の実際のオープンドメイン質問を含むFRESHQAベンチマークセットを構築しました:「決して変わらない」、「遅い変化」、「頻繁な変化」、「誤った前提」。
1)決して変わらない:基本的に変わらない質問への答え。
2)ゆっくりとした変化:質問に対する答えは数年ごとに変わります。
3)頻繁な変更:毎年またはそれ以下で変更される可能性のある質問への回答。
4)誤った前提:誤った前提を含む問題。
厳密モードと緩和モードの評価
研究者は、回答のすべての情報が正確で最新でなければならないことを要求する厳密モードと、主要な回答の正しさのみを評価する緩和モードの2つの評価モードを提案しました。
これにより、言語モデルの事実の性質を測定するためのより包括的で微妙な方法が提供されます。
FRESHQAに基づいてさまざまな大規模言語モデルを評価する
FRESHQAでは、GPT-3、GPT-4、ChatGPTなど、さまざまなパラメータをカバーする大規模な言語モデルを比較しました。 評価は、厳密モード(エラーなしが必要)と寛容モード(主要な回答のみが評価される)の両方で実施されます。
検索エンジンからの関連情報の取得
大きな言語モデルの事実の性質を改善するために、FRESHの中心的なアイデアは、検索エンジンから問題に関するリアルタイムの情報を取得することです。
スパーストレーニング統合による情報の取得
FRESHは、少数ショット学習を使用して、取得した証拠を統一された形式で大規模言語モデルの入力プロンプトに統合し、正しい答えに到達するために証拠を統合する方法のいくつかのデモンストレーションを提供します。
これにより、大きな言語モデルにタスクを理解し、さまざまなソースからの情報を統合して、最新で正確な回答を考え出すように教えることができます。