著者: シン・ジユアン東京大学の疑惑エージェントは、GPT-4を使用して、不完全な情報ゲームで高次の心の理論(ToM)を実証します。完全な情報ゲームでは、各プレイヤーは情報のすべての要素を知っています。しかし、不完全な情報ゲームは、不確実または不完全な情報の下で現実の世界で意思決定を行うことの複雑さをシミュレートするという点で異なります。GPT-4は、現在最も強力なモデルとして、並外れた知識検索および推論機能を備えています。しかし、GPT-4は、不完全な情報ゲームをプレイするために学んだことを使用できますか?この目的のために、東京大学の研究者は、GPT-4の機能を使用して不完全な情報ゲームを実行する革新的なエージェントである疑惑エージェントを導入しました。 論文住所:本研究では、GPT-4ベースの疑惑エージェントは、適切なヒントエンジニアリングによって異なる機能を実現することができ、一連の不完全な情報ゲームで優れた適応性を示しました。最も重要なことは、GPT-4がゲーム中に強力な高次心理論(ToM)能力を示したことです。GPT-4は、人間の認知の理解を利用して、敵の思考プロセス、感受性、行動を予測することができます。これは、GPT-4が他者を理解し、人間のように意図的に彼らの行動に影響を与える能力を持っていることを意味します。同様に、GPT-4ベースのエージェントは、不完全な情報ゲームで従来のアルゴリズムよりも優れているため、不完全な情報ゲームでのLLMのより多くのアプリケーションを刺激する可能性があります。#01トレーニング方法LLMが専門的なトレーニングなしでさまざまな不完全な情報ゲームゲームをプレイできるようにするために、研究者はタスク全体を、観測通訳、ゲームモード分析、計画モジュールなど、下図に示すようにいくつかのモジュールに分割しました。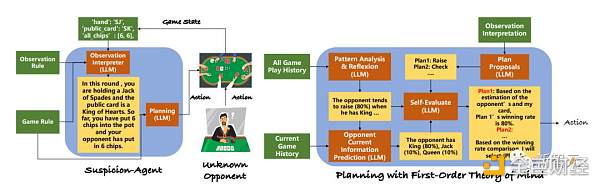 また、不完全な情報ゲームでLLMが誤解される可能性があるという問題を軽減するために、研究者は最初に、LLMがゲームのルールと現在の状態を理解するのに役立つ構造化されたヒントを開発しました。不完全な情報ゲームの種類ごとに、次の構造化されたルールの説明を書くことができます。一般的なルール:ゲームの紹介、ラウンド数、賭けのルール。アクションの説明: (アクション 1 の説明)、(アクション 2 の説明)......;勝敗ルール:勝敗または引き分けの条件。勝敗リターンルール:1つのゲームの勝ち負けに対する報酬またはペナルティ。ゲーム全体の勝ち負けルール:ゲーム数と全体的な勝敗条件。ほとんどの不完全な情報ゲーム環境では、ゲームの状態は通常、機械学習を容易にするために、クリックベクトルなどの低レベルの数値として表されます。しかし、LLMを使用すると、低レベルのゲーム状態を自然言語テキストに変換できるため、パターンを理解するのに役立ちます。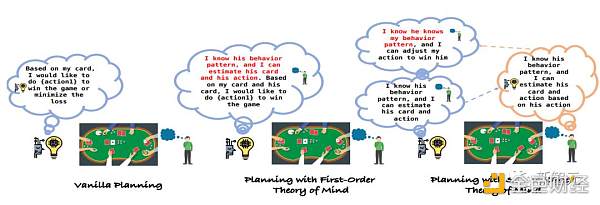 入力の説明: 受信した入力の種類 (辞書、リスト、その他の形式など) で、ゲーム状態の要素の数と各要素の名前が記述されます。要素の説明: (要素 11 の記述,(要素 2 の記述),....移行のヒント: 低レベルのゲーム状態をテキストに変換するための詳細なガイダンス。不完全な情報ゲームでは、この定式化により、モデルとの相互作用を理解しやすくなります。研究者は、試合の履歴を自動的にチェックするように設計されたReflexionモジュールを備えたニヒリスティックプログラミング手法を導入し、LLMが履歴経験から計画を学習および改善できるようにし、対応する決定を行うための専用の別の計画モジュールを導入しました。しかし、虚無的な計画方法は、特に他人の戦略を使用することに長けている対戦相手に直面した場合、不完全な情報ゲームに固有の不確実性に対処するのに苦労することがよくあります。この適応に触発されて、研究者はLLMのToM機能を利用して対戦相手の行動を理解し、それに応じて戦略を調整する新しい計画アプローチを考案しました。#02実験の定量的評価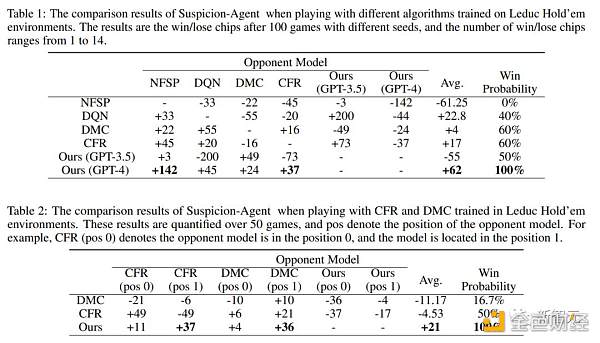 表1に示すように、疑惑エージェントはすべてのベースラインを上回り、GPT-4ベースの疑惑エージェントは比較で最高の平均チップ数を獲得しました。これらの知見は、不完全情報ゲームの分野で大規模な言語モデルを使用することの利点を強く示しており、提案されたフレームワークの有効性も示しています。次のグラフは、疑いエージェントとベースライン モデルによって実行されたアクションの割合を示しています。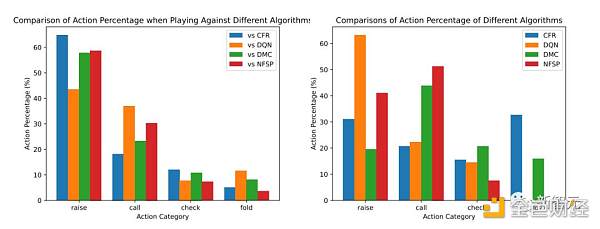 それは観察することができます:疑惑エージェントとCFR:CFRアルゴリズムは保守的な戦略であり、保守的である傾向があり、弱いカードを保持すると折りたたまれることがよくあります。疑惑エージェントはこのパターンを特定することに成功し、戦略的により頻繁な昇給を選択し、CFRにフォールドプレッシャーをかけました。これにより、疑惑エージェントは、カードが弱いか、CFRのカードに匹敵する場合でも、より多くのチップを蓄積できます。疑惑エージェント対DMC:DMCは検索アルゴリズムに基づいており、ブラフを含むより多様な戦略を採用しています。 手が最も弱くて強いときによく上がります。それに応じて、疑惑エージェントは自分の手に応じてレイズの頻度を減らし、DMCの動作を観察し、より多くのコールまたはフォールドを選択しました。疑惑エージェント対DON:DONアルゴリズムはより積極的なスタンスを取り、ほとんどの場合、強力なカードまたは中間カードで上昇し、決して折りたたむことはありません。疑惑エージェントはこれを発見し、今度は自分の昇給を最小限に抑え、一般市民とDONの行動に基づいて電話をかけるか折りたたむかを選択しました。疑惑エージェントとNFSP:NFSPはコール戦略を示し、常にコールし、決してフォールドしないことを選択します。疑惑エージェントは、約定の頻度を減らし、コミュニティと NFSP によって観察されたアクションに基づいてフォールドを選択することで対応します。以上の分析結果から、Suspicion Agentは適応性が高く、他の様々なアルゴリズムで採用されている戦略の弱点を悪用できることが分かります。これは、不完全な情報ゲームにおける大規模な言語モデルの推論と適応性を完全に示しています。#03定性評価定性的評価では、研究者は3つの不完全な情報ゲームゲーム(クーデター、テキサスホールデムリミット、ルダックホールデム)で疑惑エージェントを評価しました。クーデター、中国語の翻訳はクーデターであり、プレイヤーが他のプレイヤーの政権を打倒しようとする政治家としてプレイするカードゲームです。 ゲームの目的は、ゲームで生き残り、力を蓄積することです。テキサスホールデムリミット、またはテキサスホールデムリミットは、いくつかのバリエーションを持つ非常に人気のあるカードゲームです。 「リミット」とは、各ベットに固定の上限があることを意味し、プレイヤーは一定量のベットしか行えません。Leduc Hold'emは、ゲーム理論と人工知能の研究のためのテキサスホールデムの簡易版です。いずれの場合も、疑惑エージェントはジャックを手に持ち、対戦相手はジャックまたはクイーンを持っています。対戦相手は最初は上げるのではなく電話することを選択し、手が弱いことを意味します。 通常の計画戦略では、疑惑エージェントはコールを選択してパブリックカードを表示します。これにより、対戦相手のハンドが弱いことが明らかになると、対戦相手はすぐに賭け金を上げ、ジャックが最も弱いハンドであるため、疑惑エージェントは不安定な状況に置かれます。 一次理論的精神戦略の下では、疑惑エージェントは損失を最小限に抑えるために折りたたむことを選択します。 この決定は、対戦相手が通常、クイーンまたはジャックを手にしているときに電話をかけることを観察することに基づいています。 しかし、これらの戦略は、相手の手の投機的な弱点を十分に活用することができません。 この欠点は、疑惑エージェントの行動が相手の反応にどのように影響するかを考慮していないという事実に起因しています。 対照的に、図 9 に示すように、単純なヒントにより、疑惑エージェントは敵対者の行動に影響を与える方法を理解できます。 意図的に上げることを選択すると、対戦相手にフォールドして損失を最小限に抑えるように圧力がかかります。したがって、手の強さが似ていても、疑惑エージェントは多くのゲームに勝つことができ、ベースラインよりも多くのチップを獲得できます。 さらに、図 10 に示すように、疑惑エージェントからのレイズに対する対戦相手の呼び出しまたは応答 (相手の手が強いことを示す) が発生した場合、疑惑エージェントは戦略をすばやく調整し、それ以上の損失を防ぐためにフォールドを選択します。 これは、疑惑エージェントの優れた戦略的柔軟性を示しています。#04アブレーション研究と成分分析異なる順序ToM知覚計画法が大規模な言語モデルの動作にどのように影響するかを調べるために、研究者らはLeduc Hold'emとplaagainst CFRで実験と比較を行った。図5は、ToMレベルの計画が異なる疑いエージェントのアクションの割合を示し、チップ歩留まりの結果を表3に示します。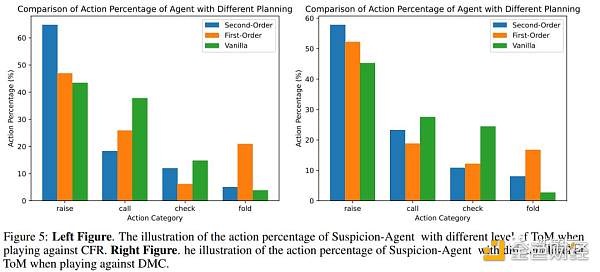 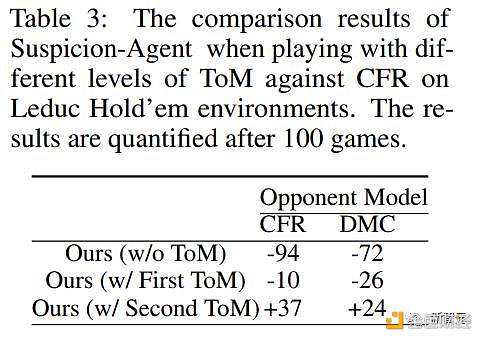 表3:異なるレベルのToMを使用したCFRonLeducホールデム環境に対する疑惑エージェントの比較結果と100ゲーム後の定量化結果それは観察することができます:リフレクションモジュールバニラプランに基づくと、ゲーム中により多くのコールとパスを行う傾向があり(CFRおよびDMCに対してコールアンドパスの割合が最も高い)、相手にフォールドするように圧力をかけることができず、多くの不必要な損失につながります。ただし、表3に示すように、バニラプログラムのチップゲインは最も低くなっています。一次ToMを使用して、疑惑エージェントは自分の力と対戦相手の力の見積もりに基づいて決定を下すことができます。その結果、通常の計画よりも多くの回数を調達しますが、不要な損失を最小限に抑えるために、他の戦略よりも多くの倍を折りたたむ傾向があります。 ただし、この慎重なアプローチは、精通したライバルモデルによって悪用される可能性があります。たとえば、DMCは最も弱い手を持っているときに上がることがよくありますが、CFRは疑わしいエージェントに圧力をかけるために中間の手を持っているときに上がることさえあります。 このような場合、疑惑エージェントが倍増する傾向は損失につながる可能性があります。対照的に、疑惑エージェントは、ライバルモデルの動作パターンを特定して悪用するのに優れています。具体的には、CFRがカードを選択したとき(通常は弱いハンドを示す)、またはDMCが通過したとき(そのハンドがコミュニティカードと一致していないことを示す)、疑惑エージェントはブラフして対戦相手をフォールドさせます。その結果、疑惑エージェントは3つの計画方法の中で最も高い充填率を示しました。この積極的な戦略により、疑惑エージェントは弱いカードでもより多くのチップを蓄積できるため、チップゲインを最大化できます。後方観察の効果を評価するために、研究者らは、後方観察が現在のゲームに組み込まれていないアブレーション研究を実施しました。表 4 および 5 に示すように、疑惑エージェントは、後方観察なしでベースライン法よりもパフォーマンス上の利点を維持します。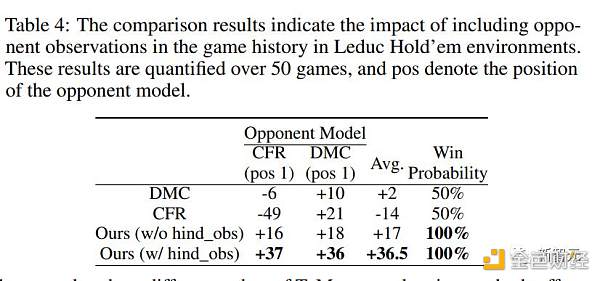 表4:比較結果は、Ledekハンドのコンテキストで、対戦相手の観察をハンドの履歴に組み込むことの影響を示しています 表 5: 比較結果から、疑惑エージェントが Leduc ホールデム環境で CFR と対戦すると、対戦相手の観測の影響がゲーム履歴に追加されることがわかります。 その結果、異なるシードを使用して100ラウンド後に勝ち負けチップが発生し、勝ち負けチップの数は1から14の範囲になります# **05 まとめ**疑惑エージェントは専門的なトレーニングを受けておらず、GPT-4の事前知識と推論能力のみを使用して、Leduc Hold'emなどのさまざまな不完全な情報ゲームで、CFRやNFSPなどのこれらのゲーム用に特別にトレーニングされたアルゴリズムを打ち負かします。これは、大規模なモデルが不完全な情報を持つゲームで強力なパフォーマンスを達成する可能性があることを示しています。一次および二次理論的メンタルモデルを統合することにより、疑惑エージェントは対戦相手の行動を予測し、それに応じて戦略を調整することができます。 これにより、さまざまなタイプの対戦相手に適応することができます。疑惑エージェントはまた、さまざまな不完全な情報ゲーム間で一般化する能力を示しており、クーデターやテキサスホールデムなどのゲームでゲームのルールと観察ルールのみに基づいて決定を下すことができます。ただし、疑惑エージェントには特定の制限もあります。 例えば、異なるアルゴリズムの評価のサンプルサイズは、計算コストの制約のために小さい。ゲームあたり1ドル近くの費用がかかる推論のコストが高く、疑惑エージェントの出力がプロンプトに非常に敏感であることに加えて、幻覚の問題があります。同時に、複雑な推論や計算に関しては、疑惑エージェントも不十分なパフォーマンスを発揮します。将来的には、Suspicion Agentは計算効率、推論の堅牢性を向上させ、マルチモーダルおよびマルチステップの推論をサポートして、複雑なゲーム環境へのより良い適応を実現します。同時に、不完全な情報ゲームゲームでの疑惑エージェントの適用は、将来的にマルチモーダル情報の統合に移行し、より現実的な相互作用をシミュレートし、マルチプレイヤーゲーム環境に拡張することもできます。リソース:
GPT-4は「心の理論」を使って人間を倒す方法をプレイします
著者: シン・ジユアン
東京大学の疑惑エージェントは、GPT-4を使用して、不完全な情報ゲームで高次の心の理論(ToM)を実証します。
完全な情報ゲームでは、各プレイヤーは情報のすべての要素を知っています。
しかし、不完全な情報ゲームは、不確実または不完全な情報の下で現実の世界で意思決定を行うことの複雑さをシミュレートするという点で異なります。
GPT-4は、現在最も強力なモデルとして、並外れた知識検索および推論機能を備えています。
しかし、GPT-4は、不完全な情報ゲームをプレイするために学んだことを使用できますか?
この目的のために、東京大学の研究者は、GPT-4の機能を使用して不完全な情報ゲームを実行する革新的なエージェントである疑惑エージェントを導入しました。
論文住所:
本研究では、GPT-4ベースの疑惑エージェントは、適切なヒントエンジニアリングによって異なる機能を実現することができ、一連の不完全な情報ゲームで優れた適応性を示しました。
最も重要なことは、GPT-4がゲーム中に強力な高次心理論(ToM)能力を示したことです。
GPT-4は、人間の認知の理解を利用して、敵の思考プロセス、感受性、行動を予測することができます。
これは、GPT-4が他者を理解し、人間のように意図的に彼らの行動に影響を与える能力を持っていることを意味します。
同様に、GPT-4ベースのエージェントは、不完全な情報ゲームで従来のアルゴリズムよりも優れているため、不完全な情報ゲームでのLLMのより多くのアプリケーションを刺激する可能性があります。
#01トレーニング方法
LLMが専門的なトレーニングなしでさまざまな不完全な情報ゲームゲームをプレイできるようにするために、研究者はタスク全体を、観測通訳、ゲームモード分析、計画モジュールなど、下図に示すようにいくつかのモジュールに分割しました。
また、不完全な情報ゲームでLLMが誤解される可能性があるという問題を軽減するために、研究者は最初に、LLMがゲームのルールと現在の状態を理解するのに役立つ構造化されたヒントを開発しました。
不完全な情報ゲームの種類ごとに、次の構造化されたルールの説明を書くことができます。
一般的なルール:ゲームの紹介、ラウンド数、賭けのルール。
アクションの説明: (アクション 1 の説明)、(アクション 2 の説明)......;
勝敗ルール:勝敗または引き分けの条件。
勝敗リターンルール:1つのゲームの勝ち負けに対する報酬またはペナルティ。
ゲーム全体の勝ち負けルール:ゲーム数と全体的な勝敗条件。
ほとんどの不完全な情報ゲーム環境では、ゲームの状態は通常、機械学習を容易にするために、クリックベクトルなどの低レベルの数値として表されます。
しかし、LLMを使用すると、低レベルのゲーム状態を自然言語テキストに変換できるため、パターンを理解するのに役立ちます。
入力の説明: 受信した入力の種類 (辞書、リスト、その他の形式など) で、ゲーム状態の要素の数と各要素の名前が記述されます。
要素の説明: (要素 11 の記述,(要素 2 の記述),....
移行のヒント: 低レベルのゲーム状態をテキストに変換するための詳細なガイダンス。
不完全な情報ゲームでは、この定式化により、モデルとの相互作用を理解しやすくなります。
研究者は、試合の履歴を自動的にチェックするように設計されたReflexionモジュールを備えたニヒリスティックプログラミング手法を導入し、LLMが履歴経験から計画を学習および改善できるようにし、対応する決定を行うための専用の別の計画モジュールを導入しました。
しかし、虚無的な計画方法は、特に他人の戦略を使用することに長けている対戦相手に直面した場合、不完全な情報ゲームに固有の不確実性に対処するのに苦労することがよくあります。
この適応に触発されて、研究者はLLMのToM機能を利用して対戦相手の行動を理解し、それに応じて戦略を調整する新しい計画アプローチを考案しました。
#02実験の定量的評価
表1に示すように、疑惑エージェントはすべてのベースラインを上回り、GPT-4ベースの疑惑エージェントは比較で最高の平均チップ数を獲得しました。
これらの知見は、不完全情報ゲームの分野で大規模な言語モデルを使用することの利点を強く示しており、提案されたフレームワークの有効性も示しています。
次のグラフは、疑いエージェントとベースライン モデルによって実行されたアクションの割合を示しています。
それは観察することができます:
疑惑エージェントとCFR:CFRアルゴリズムは保守的な戦略であり、保守的である傾向があり、弱いカードを保持すると折りたたまれることがよくあります。
疑惑エージェントはこのパターンを特定することに成功し、戦略的により頻繁な昇給を選択し、CFRにフォールドプレッシャーをかけました。
これにより、疑惑エージェントは、カードが弱いか、CFRのカードに匹敵する場合でも、より多くのチップを蓄積できます。
疑惑エージェント対DMC:DMCは検索アルゴリズムに基づいており、ブラフを含むより多様な戦略を採用しています。 手が最も弱くて強いときによく上がります。
それに応じて、疑惑エージェントは自分の手に応じてレイズの頻度を減らし、DMCの動作を観察し、より多くのコールまたはフォールドを選択しました。
疑惑エージェント対DON:DONアルゴリズムはより積極的なスタンスを取り、ほとんどの場合、強力なカードまたは中間カードで上昇し、決して折りたたむことはありません。
疑惑エージェントはこれを発見し、今度は自分の昇給を最小限に抑え、一般市民とDONの行動に基づいて電話をかけるか折りたたむかを選択しました。
疑惑エージェントとNFSP:NFSPはコール戦略を示し、常にコールし、決してフォールドしないことを選択します。
疑惑エージェントは、約定の頻度を減らし、コミュニティと NFSP によって観察されたアクションに基づいてフォールドを選択することで対応します。
以上の分析結果から、Suspicion Agentは適応性が高く、他の様々なアルゴリズムで採用されている戦略の弱点を悪用できることが分かります。
これは、不完全な情報ゲームにおける大規模な言語モデルの推論と適応性を完全に示しています。
#03定性評価
定性的評価では、研究者は3つの不完全な情報ゲームゲーム(クーデター、テキサスホールデムリミット、ルダックホールデム)で疑惑エージェントを評価しました。
クーデター、中国語の翻訳はクーデターであり、プレイヤーが他のプレイヤーの政権を打倒しようとする政治家としてプレイするカードゲームです。 ゲームの目的は、ゲームで生き残り、力を蓄積することです。
テキサスホールデムリミット、またはテキサスホールデムリミットは、いくつかのバリエーションを持つ非常に人気のあるカードゲームです。 「リミット」とは、各ベットに固定の上限があることを意味し、プレイヤーは一定量のベットしか行えません。
Leduc Hold'emは、ゲーム理論と人工知能の研究のためのテキサスホールデムの簡易版です。
いずれの場合も、疑惑エージェントはジャックを手に持ち、対戦相手はジャックまたはクイーンを持っています。
対戦相手は最初は上げるのではなく電話することを選択し、手が弱いことを意味します。 通常の計画戦略では、疑惑エージェントはコールを選択してパブリックカードを表示します。
これにより、対戦相手のハンドが弱いことが明らかになると、対戦相手はすぐに賭け金を上げ、ジャックが最も弱いハンドであるため、疑惑エージェントは不安定な状況に置かれます。
一次理論的精神戦略の下では、疑惑エージェントは損失を最小限に抑えるために折りたたむことを選択します。 この決定は、対戦相手が通常、クイーンまたはジャックを手にしているときに電話をかけることを観察することに基づいています。
しかし、これらの戦略は、相手の手の投機的な弱点を十分に活用することができません。 この欠点は、疑惑エージェントの行動が相手の反応にどのように影響するかを考慮していないという事実に起因しています。
対照的に、図 9 に示すように、単純なヒントにより、疑惑エージェントは敵対者の行動に影響を与える方法を理解できます。 意図的に上げることを選択すると、対戦相手にフォールドして損失を最小限に抑えるように圧力がかかります。
したがって、手の強さが似ていても、疑惑エージェントは多くのゲームに勝つことができ、ベースラインよりも多くのチップを獲得できます。
さらに、図 10 に示すように、疑惑エージェントからのレイズに対する対戦相手の呼び出しまたは応答 (相手の手が強いことを示す) が発生した場合、疑惑エージェントは戦略をすばやく調整し、それ以上の損失を防ぐためにフォールドを選択します。
これは、疑惑エージェントの優れた戦略的柔軟性を示しています。
#04アブレーション研究と成分分析
異なる順序ToM知覚計画法が大規模な言語モデルの動作にどのように影響するかを調べるために、研究者らはLeduc Hold'emとplaagainst CFRで実験と比較を行った。
図5は、ToMレベルの計画が異なる疑いエージェントのアクションの割合を示し、チップ歩留まりの結果を表3に示します。
表3:異なるレベルのToMを使用したCFRonLeducホールデム環境に対する疑惑エージェントの比較結果と100ゲーム後の定量化結果
それは観察することができます:
リフレクションモジュールバニラプランに基づくと、ゲーム中により多くのコールとパスを行う傾向があり(CFRおよびDMCに対してコールアンドパスの割合が最も高い)、相手にフォールドするように圧力をかけることができず、多くの不必要な損失につながります。
ただし、表3に示すように、バニラプログラムのチップゲインは最も低くなっています。
一次ToMを使用して、疑惑エージェントは自分の力と対戦相手の力の見積もりに基づいて決定を下すことができます。
その結果、通常の計画よりも多くの回数を調達しますが、不要な損失を最小限に抑えるために、他の戦略よりも多くの倍を折りたたむ傾向があります。 ただし、この慎重なアプローチは、精通したライバルモデルによって悪用される可能性があります。
たとえば、DMCは最も弱い手を持っているときに上がることがよくありますが、CFRは疑わしいエージェントに圧力をかけるために中間の手を持っているときに上がることさえあります。 このような場合、疑惑エージェントが倍増する傾向は損失につながる可能性があります。
対照的に、疑惑エージェントは、ライバルモデルの動作パターンを特定して悪用するのに優れています。
具体的には、CFRがカードを選択したとき(通常は弱いハンドを示す)、またはDMCが通過したとき(そのハンドがコミュニティカードと一致していないことを示す)、疑惑エージェントはブラフして対戦相手をフォールドさせます。
その結果、疑惑エージェントは3つの計画方法の中で最も高い充填率を示しました。
この積極的な戦略により、疑惑エージェントは弱いカードでもより多くのチップを蓄積できるため、チップゲインを最大化できます。
後方観察の効果を評価するために、研究者らは、後方観察が現在のゲームに組み込まれていないアブレーション研究を実施しました。
表 4 および 5 に示すように、疑惑エージェントは、後方観察なしでベースライン法よりもパフォーマンス上の利点を維持します。
表4:比較結果は、Ledekハンドのコンテキストで、対戦相手の観察をハンドの履歴に組み込むことの影響を示しています
表 5: 比較結果から、疑惑エージェントが Leduc ホールデム環境で CFR と対戦すると、対戦相手の観測の影響がゲーム履歴に追加されることがわかります。 その結果、異なるシードを使用して100ラウンド後に勝ち負けチップが発生し、勝ち負けチップの数は1から14の範囲になります
05 まとめ
疑惑エージェントは専門的なトレーニングを受けておらず、GPT-4の事前知識と推論能力のみを使用して、Leduc Hold'emなどのさまざまな不完全な情報ゲームで、CFRやNFSPなどのこれらのゲーム用に特別にトレーニングされたアルゴリズムを打ち負かします。
これは、大規模なモデルが不完全な情報を持つゲームで強力なパフォーマンスを達成する可能性があることを示しています。
一次および二次理論的メンタルモデルを統合することにより、疑惑エージェントは対戦相手の行動を予測し、それに応じて戦略を調整することができます。 これにより、さまざまなタイプの対戦相手に適応することができます。
疑惑エージェントはまた、さまざまな不完全な情報ゲーム間で一般化する能力を示しており、クーデターやテキサスホールデムなどのゲームでゲームのルールと観察ルールのみに基づいて決定を下すことができます。
ただし、疑惑エージェントには特定の制限もあります。 例えば、異なるアルゴリズムの評価のサンプルサイズは、計算コストの制約のために小さい。
ゲームあたり1ドル近くの費用がかかる推論のコストが高く、疑惑エージェントの出力がプロンプトに非常に敏感であることに加えて、幻覚の問題があります。
同時に、複雑な推論や計算に関しては、疑惑エージェントも不十分なパフォーマンスを発揮します。
将来的には、Suspicion Agentは計算効率、推論の堅牢性を向上させ、マルチモーダルおよびマルチステップの推論をサポートして、複雑なゲーム環境へのより良い適応を実現します。
同時に、不完全な情報ゲームゲームでの疑惑エージェントの適用は、将来的にマルチモーダル情報の統合に移行し、より現実的な相互作用をシミュレートし、マルチプレイヤーゲーム環境に拡張することもできます。
リソース: