記事の出典:シン・ジユアンAIがAIに勝てないのは当然のことです。 最近、数千万人が乳児の死亡の写真を見ており、AI検出ツールは一貫した答えを出すことができませんでした。AI画像検出器が再び洗浄されます!最近、中東での紛争の多数の写真がインターネット上に公開されており、そのような極端な状況下での生活がいかに脆弱で無力であるかを世界に示しています。その中で、「焼けた赤ちゃん」の写真は残酷すぎて真実ではありません。 そこで、誰かが写真をAI画像検出器に入れて、これらの写真がAI生成であるかどうかを検出します。案の定、写真はAI検出器Opticによって「AI生成」として識別されました。 4chanには「原画」すらあり、体の元の場所は実際には犬です。 そのため、ネチズンは怒って出版社のツイートの一番下に行き、AIで生成された写真を使用して誤った終末パニックを広めたとして彼を攻撃しました。 写真がAIによって生成されたと信じるツイートは、2日以内に2100万人に読まれました。 しかし、すぐにネチズンは写真を同じAI検出器に載せたことに気づき、結果はAIと人間の両方でほぼランダムでした。 誰かが、同じ画像がトリミングされているか、背景色が白黒に変更されている限り、検出器は画像が人間によって撮影されたと考えることを発見しました。 検出器が「コインを投げる」ときでさえ、コインは立ち上がることがあります... では、このグラフはAIによって生成されたのでしょうか?最後に、AI検出器の関係者もこの事件についてツイートし、画像がAIによって生成されたかどうかを判断する方法はないと信じており、誰もが合理的に議論することを望んでいます。  ## **AI画像検出器、それはどれほど信頼できませんか? ** カリフォルニア大学バークレー校の教授であり、デジタル画像処理の世界有数の専門家の1人であるHany Faridは、画像はAIによって生成されたことを示すものではないと述べました。「AI画像ジェネレーターの最大の問題の1つは、高度に構造化された形状と直線です」とFarid氏は述べています。 「脚とネジを見て、すべてが完璧に見える場合、AIによって画像を生成することはほとんど不可能です。」たとえば、この有名な「スポンジボブスクエアパンツ製9/1」の写真では、窓の外のツインタワーの線がまっすぐではなく、飛行機のダッシュボードがねじれていて、「AinA」のように見えます。 「その写真では、オブジェクトの構造が正確で、影が正確で、アーティファクトがないことがわかりました。そのため、写真は完全に本物であるべきだと信じるようになりました」とファリド氏は述べています。ファリドはまた、彼自身の他のAI画像検出器を介して画像を識別し、他の4つのAI画像検出ツールも、画像がAI生成ではないと想定しました。「AI検出器はツールですが、ツールキットの一部にすぎません」とFarid氏は述べています。 ユーザーは画像全体に対して一連のテストを実行する必要があり、ボタンを押すだけで答えを得ることは不可能です。」また、AI検出ツールのOpticは、独自の検出技術の具体的な詳細を提供していませんでした。Opticalのウェブサイトには、「AI検出器は不正確な結果を生成する可能性がある」とも記載されています。 ## **AI画像検出技術** ファリド教授は昨年、AIバイオグラフツールで画像の一貫性を判断する方法について論文を書いた。画像の一貫性を判断することで、画像がAIによって生成されたかどうかを判断するのに役立ちます。 論文リンク:教授は、画像形成プロセスに固有の同じ基本的な遠近法ジオメトリを利用した、関連する3つの物理学ベースの分析方法を概説することから始めます。### **消失点**1.平行なセットバックラインは消失点で収束します。瓷砖之间的线图1(a) は並列です。 イメージング時には、これらの線はすべて消失点で収束します。 シーン内の平行線がレンズから奥行きが遠い場合、消失点がありますが、画像の外側にある可能性があります。シーン内の平行線が深さが後退しない場合、つまり、レンズセンサーと完全に平行である場合(任意の距離で)、平行線は平行線として画像化され、実用的な目的で消失点は無限大にあると見なすことができます。 このジオメトリは、透視投影の基本に由来します。透視投影では、シーン内の点(X、Y、Z)が点(f X / Z、f Y/Z)に画像化され、fはレンズの焦点距離です。画像内の点の位置は距離Zに反比例するため、投影された点は距離の関数として圧縮され、画像内の線が収束します。2.平行な平面上の平行線は同じ消失点に収束します遠くのボックスは、図1(b)の床のタイルと位置合わせされ、ボックスの端がタイル間の線と平行になります。 平行な平面上の平行線は消失点を共有するため、消失点はボックスの側面とタイルの床で同じです。3.平面上のすべての線の消失点は、消失線上にあります。図1(c)に示すように、それぞれが異なる消失点に収束する平行線の多くのグループ。 平行線のグループがシーン内の同じ平面にまたがっている場合、それらの消失点は消失線上にあります。 消失線の方向は、平行線が交差する平面に対するレンズの回転によって決まります### **影**やや意外なことに、消失点の背後にある同じジオメトリは、影を落とすためにも機能します。 上の画像は、ボックス上の点と影を落とす上の対応する点を結ぶ3つの光線を示しています。 画像境界を拡張すると、3つの光線が、シーンを照らす光源の投影に対応する点で交差することがわかる。影、オブジェクト、およびライトに関連付けられたこの幾何学的拘束は、光源が近く(電気スタンド)にあるか遠く(太陽)にあるかにかかわらず、影が投影されるサーフェスの位置と方向に関係なく保持されます。もちろん、この解析では、シーンが 1 つのマスター光源によって照らされていることを前提としていますが、これはオブジェクトごとに 1 つのキャスト シャドウのみが存在することからも明らかです。上記の例では、シーンを照らす光源がレンズの前にあるため、光源の投影は像面の上半分にあります。ただし、光がレンズの後ろにある場合、光源の投影は像面の下半分になります。 この反転のため、オブジェクト拘束の影も反転する必要があります。したがって、画像のキャスティングシャドウ分析では、次の 3 つの可能性を考慮する必要があります。(1)光はレンズの前にあり、光源の投影は像面の上部にあり、拘束はキャストシャドウに固定され、オブジェクトを囲みます。(2)光はレンズの後ろにあり、光源は像面の下半分に投影され、オブジェクトに固定され、キャストシャドウを包み込みます。(3)光はレンズの中心の真上または真下にあり、光源の投影は無限大にあり、拘束は無限大で交差します。 これらのケースのいずれかによってすべての制約が共通に交差する場合は、影を落とすことが物理的に合理的です。### **リフレクション**下の図2に示すシーンは、平面鏡に映った3つのボックスを示しています。 この図の下半分は、実際のボックスと仮想ボックスの間の幾何学的関係を示しています。オレンジ色の線は、2つのボックスセットの中間点にあるミラーを表します。 黄色の線は、実際のボックスと仮想ボックス上の対応するポイントを接続します。 これらの線は互いに平行で、鏡に垂直です。次に、これらの平行線がシーンに重ねられたときにどのように表示されるかを考えます。 ミラー平面から見ると、平行線は平行ではなくなります。 代わりに、透視投影により、ワールド内の平行線が消失点に収束するのと同じように、これらの平行線は点に収束します。シーン内の対応するポイントとその反射を結ぶ線は常に平行であるため、物理的にもっともらしいものにするには、画像内で共通の交点が必要です。### **インスタンス分析** 上の図3は、AI合成画像の代表的な3つの例を示し、床とカウンタートップの幾何学的遠近法の一貫性を分析しています。各画像(数ピクセル以内)は、一貫した消失点(青色でレンダリング)の証拠として、タイルの床の遠近法ジオメトリを正確にキャプチャします。 ただし、平行なカウンタートップの消失点(シアンでレンダリング)は、カウンタートップの消失点と幾何学的に矛盾しています。それに応じてタイルを揃えます。 カウンタートップがタイルと平行でない場合でも、シアンの消失点は、タイルの床の消失点によって定義される消失線(赤でレンダリング)上にある必要があります。 図 3 の右上隅の画像では、タイルの床の水平線がほぼ平行であるため、対応する消失点は無限大にあり、交差しないことに注意してください。これらの画像の消失点は局所的には一貫していますが、グローバルに一貫していません。 25の複合キッチン画像のそれぞれで、同じパターンが見つかりました。 上の画像はプロンプトで生成された正方形の画像であり、影に明らかな矛盾があります。 上の図8は、かなり正確な反射を含むAI生成画像に幾何学的分析を適用した結果を示しています。これらの反射は視覚的に正当化されますが、幾何学的に一貫性がありません。前のセクションのキャストシャドウとジオメトリとは異なり、DALL· E-2は、おそらくそのような反射がトレーニング画像データセットであまり一般的ではないため、合理的な反射を合成することは困難です。AIで生成された画像の限界に関するこれらの理解に基づいて、画像の一貫性の検出を通じて画像がAIによって合成されているかどうかを判断することは非常に役立ちます。 ## **画像認識は難しい、AIはAIに勝る** AI画像ジェネレーターは常に進化しています。今年の前半に、Midjourneyは爆発し、十分にリアルな画像を生成することができましたが、多くの人々をだましました。86歳の教皇は、白いメロンの帽子、フレアの白いダウンジャケット、露出した金属製の十字架のネックレスを身に着け、真剣な表情をしています。当時、写真が公開されるとすぐに、ソーシャルメディアでみんなをだまし、多くのネチズンによって必死に転送され、教皇をトレンディすぎるとさえ呼ぶ人もいました。 誰もがそれを信じたとき、誰かが突然それがAIによって生成されたことを指摘し、多くの人々は即座に唖然としました。 これは栗の1つに過ぎず、マスクの新しいガールフレンドGMのCEOであるBarraなどのさまざまな偽の写真が偽の現実のレベルに達しています。この事件は、マスク、アップルの共同創設者であるスティーブンウォズニアック、その他のテクノロジーリーダーがAIの研究開発の停止を要求するきっかけとなりました。AIの生成は楽しく便利ですが、業界全体にリスクをもたらします。小さくなければ、下心のある人が虚偽の情報を流布したり、知的財産権を侵害したり、「フルーツ写真」の生成などに利用したりします。今後数か月以内に、Midjourneyは画像生成の点で完成した最新のV6バージョンをリリースします。他のAI画像ジェネレーターも急速に反復されています。 少し前に、OpenAIはDALL· E 3、同時にマイクロソフトBingイメージ生成もDALL· E 3。 もちろん、研究者は画像を区別できるツールを構築しようとしていますが、重要なのはAI画像ジェネレーターのペースに追いつく方法です。 ## **AI検査ツールコンペティション** 現在、画像がAIによって生成されたかどうかを識別するためのツールを提供している企業は12社以上あり、その名前にはSensity AI(ディープファジティ検出)、Fictitious.AI(盗用検出)、Originality.AI などがあります。人工知能の信頼と安全の会社であるOpticsは、「AIかどうか」のウェブサイトを立ち上げました。このウェブサイトでは、写真をアップロードしたり、画像のURLを貼り付けたりすることができ、ウェブサイトは写真がAIによって生成されたかどうかを自動的に判断します。 アップロードできる画像の数に制限はありません。 または、OpticのTwitterアカウント@optic\_xyzに画像を投稿またはリツイートしたり、#aiornot を追加したりすると、画像の信頼度が記載された返信が届きます。同社の最高経営責任者(CEO)であるAndrey Doronichev氏は、OpticのAIツールは、画像の明るさや色の変化など、人間の目には見えないアーティファクトがないか各画像をチェックできると述べました。驚いたことに、このツールの精度は95%です。しかし、MidjourneyなどのAI画像生成ツールのアップグレードと反復により、「AIかどうか」の正解率は88.9%に低下しました。たとえば、教皇の写真では、AIは人間がそれを行う確率は87%であると信じています。 白いダウンジャケットを着た教皇の画像は、光学系の更新前にだまされました実際、一部のネチズンは、この写真をよく見ると、明らかにぼやけた詳細領域など、人工知能によって生成された明らかな兆候が見つかると述べました。-一見不完全な手は、隣に汚れがあるコーヒーカップにあまり似ていないものをつかもうとしています-教皇が身に着けている十字架は直角の形ではなく、粘土から彫られたように見える座っているイエスの彫刻もあります-メガネは顔の影と一致しませんこれらの点はすべて、これが人工知能によって生成されることを示しています。 それは現実の表面を理解するだけで、物理的なオブジェクトがどのように相互作用するかを支配する基本的なルールは理解しません。 Opticのツールに加えて、コンテンツにタグを付けるAI企業であるHiveは、最近、独自の無料のAI生成コンテンツ検出器を更新しました。AIツールは、DALL-E、Stable Diffusion、Midjourneyの数百万枚の画像でトレーニングされました。 Hiveは、AIで生成された画像の約95%、特にオンラインでバイラルになる共有画像の約95%を正確に検出することを期待しており、多くの場合、他の画像認識よりも優れています。CEOのKevin Guo氏は、人々がAI画像を共有するとき、最も現実的な偽の画像を選択するため、人々は何が本物であるかを区別できると述べました。 左の画像はAIが生成した2本の指と奇数のハイタッチで識別できる画像で、右は通常のiStock写真の実物です。Opticと同様に、HiveはImage Creatorからの画像を検出できませんでしたBing。ただし、これらの検出ツールは停滞しておらず、AI イメージ モデルが反復されるにつれて更新およびアップグレードされます。実際、AI画像認識は、業界の検出ツールに依存して完了するだけでなく、モデルをトレーニングするときにガードレールを設定することもできます。多くの人工知能画像ジェネレータには、一部のコンテンツを生成できるかどうかを制限する「ブラックリスト」もあります。たとえば、Bing Image Creatorは、有名な公人の画像を作成するように依頼するユーザーからのプロンプトにフラグを付けてブロックします。Midjourneyには「人間のモデレーター」がいて、アルゴリズムを使用してユーザーのリクエストをモデレートする方法を展開しています。そしてダル· E 3テクニカルレポートによると、ChatGPTに「フルーツマップ」または白黒を含む画像を生成するように依頼すると、入力が直接書き換えられます。 ## **AIに透かしを追加する、大手メーカーが行っている** また、電子透かしも生成AIのセキュリティを強化する重要な手段の1つであり、MicrosoftやGoogleなどのテクノロジーの巨人が製品に使用されています。Microsoftは9月のSurface ConferenceでDALL· を紹介した。 E 3は、画像を生成するBingの能力に恵まれています。同時に、画像が悪用されないようにするために、Microsoftチームは暗号化方式を使用して、作成日時など、画像ごとに目に見えない透かしを生成します。誰でも各画像をクリックして、AIによって生成されたかどうかを簡単に識別できます。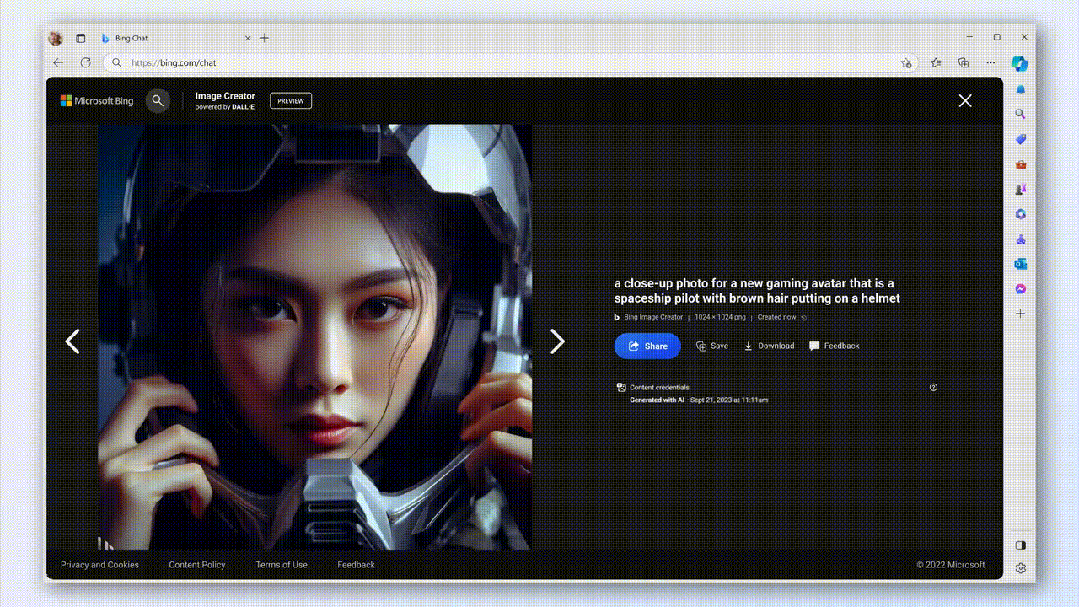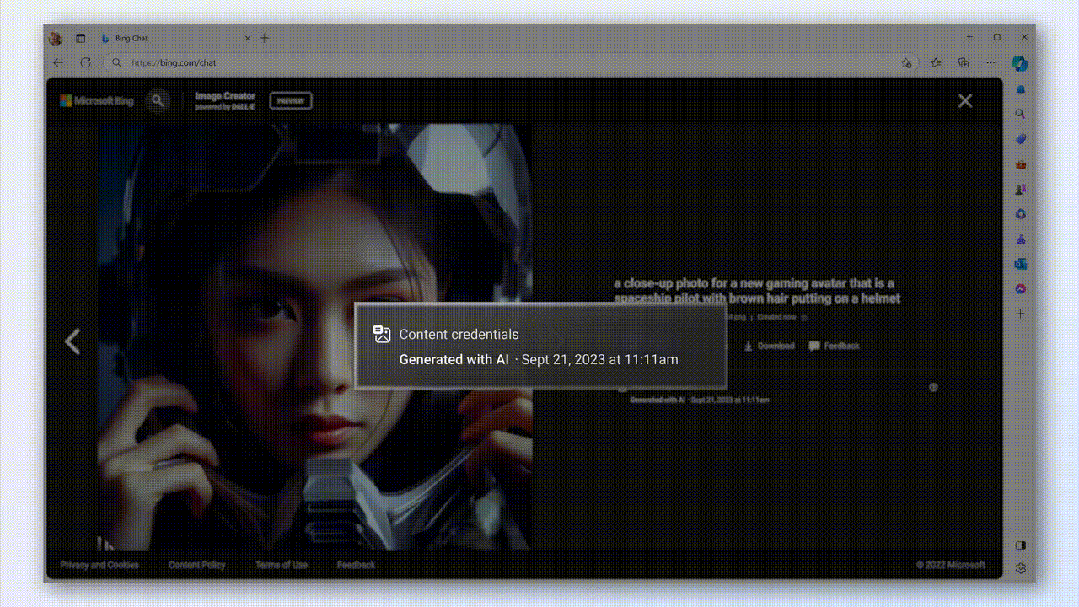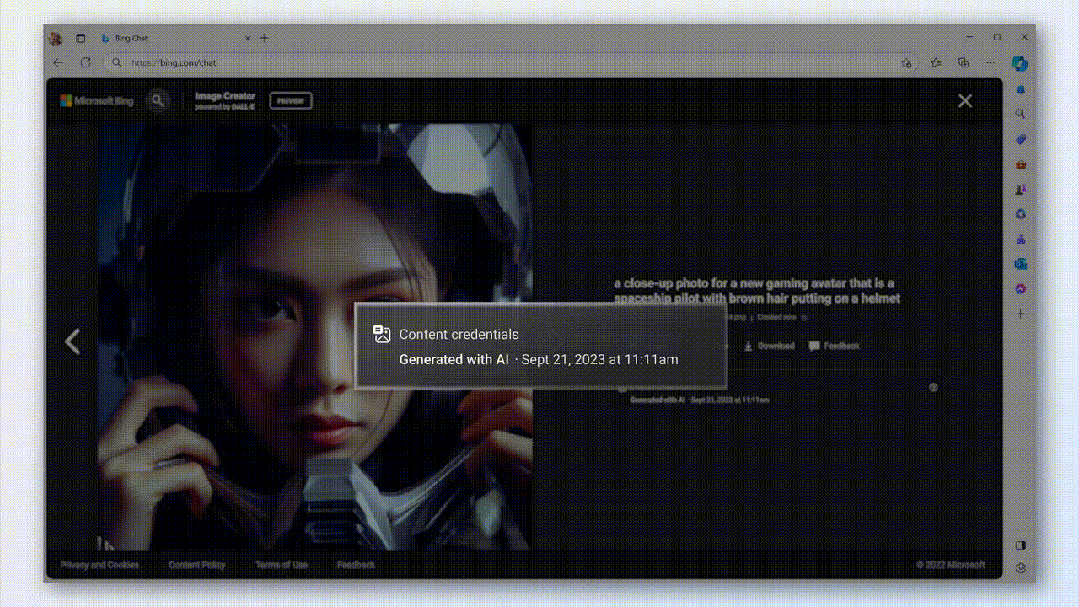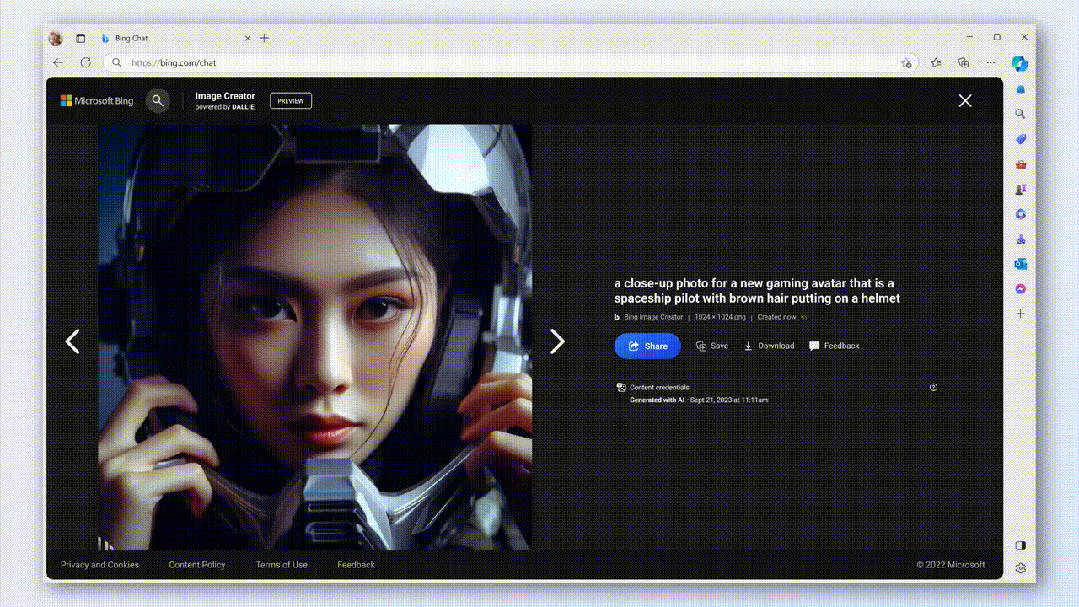 Metaはまた、AIによって自動的に生成された画像にデジタル透かしを直接埋め込む安定した署名をオープンソース化しました。 論文住所:Stable Signatureによって生成された電子透かしは、トリミング、圧縮、色の変更などの破壊的な操作の影響を受けず、画像の元のソースにまでさかのぼることができることに注意してください。安定拡散などの拡散やGANなどのモデルに適用できます。 また、GoogleはGoogle Cloud Nextで、AIが生成した画像に透かしを入れ、それらを検出して識別するSynthIDもリリースしました。SynthID は、透かし用と認識用の 2 つのディープ ラーニング モデルを使用します。 それらは、異なる画像のセットで一緒にトレーニングできます。結合されたモデルは、透かし入りのコンテンツを正しく識別し、透かしを元のコンテンツと視覚的に整列させることによる透かしの隠蔽性の向上など、さまざまな目標に合わせて最適化されています。 SynthIDによって生成されたデジタル透かしは、画像のピクセルに直接埋め込まれ、人間の目には知覚できません。 しかし、SynthIDはそれらを検出して識別することができます。 SynthID は、画像が Imagen によって作成された可能性を評価するのに役立ちますカリフォルニア大学リバーサイド校の電気およびコンピューター工学の教授であるAmit Roy-Chowdhuryは、画像の背景を注意深く見ることで、自分の目で偽の画像をより適切に検出できると述べました。 しかし、AIモデルがイテレーションを加速している現時点では、「黄金の目」を持つことは難しすぎます。リソース:
何千万人もの人々が「焦げた赤ちゃん」の写真を見ています! バークレー教授は、AI画像検出器は役に立たないという噂を暴きます
記事の出典:シン・ジユアン
AIがAIに勝てないのは当然のことです。 最近、数千万人が乳児の死亡の写真を見ており、AI検出ツールは一貫した答えを出すことができませんでした。
AI画像検出器が再び洗浄されます!
最近、中東での紛争の多数の写真がインターネット上に公開されており、そのような極端な状況下での生活がいかに脆弱で無力であるかを世界に示しています。
その中で、「焼けた赤ちゃん」の写真は残酷すぎて真実ではありません。
案の定、写真はAI検出器Opticによって「AI生成」として識別されました。
最後に、AI検出器の関係者もこの事件についてツイートし、画像がAIによって生成されたかどうかを判断する方法はないと信じており、誰もが合理的に議論することを望んでいます。
**AI画像検出器、それはどれほど信頼できませんか? **
カリフォルニア大学バークレー校の教授であり、デジタル画像処理の世界有数の専門家の1人であるHany Faridは、画像はAIによって生成されたことを示すものではないと述べました。
「AI画像ジェネレーターの最大の問題の1つは、高度に構造化された形状と直線です」とFarid氏は述べています。 「脚とネジを見て、すべてが完璧に見える場合、AIによって画像を生成することはほとんど不可能です。」
たとえば、この有名な「スポンジボブスクエアパンツ製9/1」の写真では、窓の外のツインタワーの線がまっすぐではなく、飛行機のダッシュボードがねじれていて、「AinA」のように見えます。
ファリドはまた、彼自身の他のAI画像検出器を介して画像を識別し、他の4つのAI画像検出ツールも、画像がAI生成ではないと想定しました。
「AI検出器はツールですが、ツールキットの一部にすぎません」とFarid氏は述べています。 ユーザーは画像全体に対して一連のテストを実行する必要があり、ボタンを押すだけで答えを得ることは不可能です。」
また、AI検出ツールのOpticは、独自の検出技術の具体的な詳細を提供していませんでした。
Opticalのウェブサイトには、「AI検出器は不正確な結果を生成する可能性がある」とも記載されています。
AI画像検出技術
ファリド教授は昨年、AIバイオグラフツールで画像の一貫性を判断する方法について論文を書いた。
画像の一貫性を判断することで、画像がAIによって生成されたかどうかを判断するのに役立ちます。
教授は、画像形成プロセスに固有の同じ基本的な遠近法ジオメトリを利用した、関連する3つの物理学ベースの分析方法を概説することから始めます。
消失点
1.平行なセットバックラインは消失点で収束します。
シーン内の平行線が深さが後退しない場合、つまり、レンズセンサーと完全に平行である場合(任意の距離で)、平行線は平行線として画像化され、実用的な目的で消失点は無限大にあると見なすことができます。 このジオメトリは、透視投影の基本に由来します。
透視投影では、シーン内の点(X、Y、Z)が点(f X / Z、f Y/Z)に画像化され、fはレンズの焦点距離です。
画像内の点の位置は距離Zに反比例するため、投影された点は距離の関数として圧縮され、画像内の線が収束します。
2.平行な平面上の平行線は同じ消失点に収束します
遠くのボックスは、図1(b)の床のタイルと位置合わせされ、ボックスの端がタイル間の線と平行になります。 平行な平面上の平行線は消失点を共有するため、消失点はボックスの側面とタイルの床で同じです。
3.平面上のすべての線の消失点は、消失線上にあります。
図1(c)に示すように、それぞれが異なる消失点に収束する平行線の多くのグループ。 平行線のグループがシーン内の同じ平面にまたがっている場合、それらの消失点は消失線上にあります。 消失線の方向は、平行線が交差する平面に対するレンズの回転によって決まります
影
やや意外なことに、消失点の背後にある同じジオメトリは、影を落とすためにも機能します。
影、オブジェクト、およびライトに関連付けられたこの幾何学的拘束は、光源が近く(電気スタンド)にあるか遠く(太陽)にあるかにかかわらず、影が投影されるサーフェスの位置と方向に関係なく保持されます。
もちろん、この解析では、シーンが 1 つのマスター光源によって照らされていることを前提としていますが、これはオブジェクトごとに 1 つのキャスト シャドウのみが存在することからも明らかです。
上記の例では、シーンを照らす光源がレンズの前にあるため、光源の投影は像面の上半分にあります。
ただし、光がレンズの後ろにある場合、光源の投影は像面の下半分になります。 この反転のため、オブジェクト拘束の影も反転する必要があります。
したがって、画像のキャスティングシャドウ分析では、次の 3 つの可能性を考慮する必要があります。
(1)光はレンズの前にあり、光源の投影は像面の上部にあり、拘束はキャストシャドウに固定され、オブジェクトを囲みます。
(2)光はレンズの後ろにあり、光源は像面の下半分に投影され、オブジェクトに固定され、キャストシャドウを包み込みます。
(3)光はレンズの中心の真上または真下にあり、光源の投影は無限大にあり、拘束は無限大で交差します。 これらのケースのいずれかによってすべての制約が共通に交差する場合は、影を落とすことが物理的に合理的です。
リフレクション
下の図2に示すシーンは、平面鏡に映った3つのボックスを示しています。
オレンジ色の線は、2つのボックスセットの中間点にあるミラーを表します。 黄色の線は、実際のボックスと仮想ボックス上の対応するポイントを接続します。 これらの線は互いに平行で、鏡に垂直です。
次に、これらの平行線がシーンに重ねられたときにどのように表示されるかを考えます。 ミラー平面から見ると、平行線は平行ではなくなります。 代わりに、透視投影により、ワールド内の平行線が消失点に収束するのと同じように、これらの平行線は点に収束します。
シーン内の対応するポイントとその反射を結ぶ線は常に平行であるため、物理的にもっともらしいものにするには、画像内で共通の交点が必要です。
インスタンス分析
各画像(数ピクセル以内)は、一貫した消失点(青色でレンダリング)の証拠として、タイルの床の遠近法ジオメトリを正確にキャプチャします。 ただし、平行なカウンタートップの消失点(シアンでレンダリング)は、カウンタートップの消失点と幾何学的に矛盾しています。
それに応じてタイルを揃えます。 カウンタートップがタイルと平行でない場合でも、シアンの消失点は、タイルの床の消失点によって定義される消失線(赤でレンダリング)上にある必要があります。 図 3 の右上隅の画像では、タイルの床の水平線がほぼ平行であるため、対応する消失点は無限大にあり、交差しないことに注意してください。
これらの画像の消失点は局所的には一貫していますが、グローバルに一貫していません。 25の複合キッチン画像のそれぞれで、同じパターンが見つかりました。
これらの反射は視覚的に正当化されますが、幾何学的に一貫性がありません。
前のセクションのキャストシャドウとジオメトリとは異なり、DALL· E-2は、おそらくそのような反射がトレーニング画像データセットであまり一般的ではないため、合理的な反射を合成することは困難です。
AIで生成された画像の限界に関するこれらの理解に基づいて、画像の一貫性の検出を通じて画像がAIによって合成されているかどうかを判断することは非常に役立ちます。
画像認識は難しい、AIはAIに勝る
AI画像ジェネレーターは常に進化しています。
今年の前半に、Midjourneyは爆発し、十分にリアルな画像を生成することができましたが、多くの人々をだましました。
86歳の教皇は、白いメロンの帽子、フレアの白いダウンジャケット、露出した金属製の十字架のネックレスを身に着け、真剣な表情をしています。
当時、写真が公開されるとすぐに、ソーシャルメディアでみんなをだまし、多くのネチズンによって必死に転送され、教皇をトレンディすぎるとさえ呼ぶ人もいました。
この事件は、マスク、アップルの共同創設者であるスティーブンウォズニアック、その他のテクノロジーリーダーがAIの研究開発の停止を要求するきっかけとなりました。
AIの生成は楽しく便利ですが、業界全体にリスクをもたらします。
小さくなければ、下心のある人が虚偽の情報を流布したり、知的財産権を侵害したり、「フルーツ写真」の生成などに利用したりします。
今後数か月以内に、Midjourneyは画像生成の点で完成した最新のV6バージョンをリリースします。
他のAI画像ジェネレーターも急速に反復されています。 少し前に、OpenAIはDALL· E 3、同時にマイクロソフトBingイメージ生成もDALL· E 3。
AI検査ツールコンペティション
現在、画像がAIによって生成されたかどうかを識別するためのツールを提供している企業は12社以上あり、その名前にはSensity AI(ディープファジティ検出)、Fictitious.AI(盗用検出)、Originality.AI などがあります。
人工知能の信頼と安全の会社であるOpticsは、「AIかどうか」のウェブサイトを立ち上げました。
このウェブサイトでは、写真をアップロードしたり、画像のURLを貼り付けたりすることができ、ウェブサイトは写真がAIによって生成されたかどうかを自動的に判断します。 アップロードできる画像の数に制限はありません。
同社の最高経営責任者(CEO)であるAndrey Doronichev氏は、OpticのAIツールは、画像の明るさや色の変化など、人間の目には見えないアーティファクトがないか各画像をチェックできると述べました。
驚いたことに、このツールの精度は95%です。
しかし、MidjourneyなどのAI画像生成ツールのアップグレードと反復により、「AIかどうか」の正解率は88.9%に低下しました。
たとえば、教皇の写真では、AIは人間がそれを行う確率は87%であると信じています。
実際、一部のネチズンは、この写真をよく見ると、明らかにぼやけた詳細領域など、人工知能によって生成された明らかな兆候が見つかると述べました。
-一見不完全な手は、隣に汚れがあるコーヒーカップにあまり似ていないものをつかもうとしています
-教皇が身に着けている十字架は直角の形ではなく、粘土から彫られたように見える座っているイエスの彫刻もあります
-メガネは顔の影と一致しません
これらの点はすべて、これが人工知能によって生成されることを示しています。 それは現実の表面を理解するだけで、物理的なオブジェクトがどのように相互作用するかを支配する基本的なルールは理解しません。
AIツールは、DALL-E、Stable Diffusion、Midjourneyの数百万枚の画像でトレーニングされました。
CEOのKevin Guo氏は、人々がAI画像を共有するとき、最も現実的な偽の画像を選択するため、人々は何が本物であるかを区別できると述べました。
Opticと同様に、HiveはImage Creatorからの画像を検出できませんでしたBing。
ただし、これらの検出ツールは停滞しておらず、AI イメージ モデルが反復されるにつれて更新およびアップグレードされます。
実際、AI画像認識は、業界の検出ツールに依存して完了するだけでなく、モデルをトレーニングするときにガードレールを設定することもできます。
多くの人工知能画像ジェネレータには、一部のコンテンツを生成できるかどうかを制限する「ブラックリスト」もあります。
たとえば、Bing Image Creatorは、有名な公人の画像を作成するように依頼するユーザーからのプロンプトにフラグを付けてブロックします。
Midjourneyには「人間のモデレーター」がいて、アルゴリズムを使用してユーザーのリクエストをモデレートする方法を展開しています。
そしてダル· E 3テクニカルレポートによると、ChatGPTに「フルーツマップ」または白黒を含む画像を生成するように依頼すると、入力が直接書き換えられます。
AIに透かしを追加する、大手メーカーが行っている
また、電子透かしも生成AIのセキュリティを強化する重要な手段の1つであり、MicrosoftやGoogleなどのテクノロジーの巨人が製品に使用されています。
Microsoftは9月のSurface ConferenceでDALL· を紹介した。 E 3は、画像を生成するBingの能力に恵まれています。
同時に、画像が悪用されないようにするために、Microsoftチームは暗号化方式を使用して、作成日時など、画像ごとに目に見えない透かしを生成します。
誰でも各画像をクリックして、AIによって生成されたかどうかを簡単に識別できます。
Stable Signatureによって生成された電子透かしは、トリミング、圧縮、色の変更などの破壊的な操作の影響を受けず、画像の元のソースにまでさかのぼることができることに注意してください。
安定拡散などの拡散やGANなどのモデルに適用できます。
SynthID は、透かし用と認識用の 2 つのディープ ラーニング モデルを使用します。 それらは、異なる画像のセットで一緒にトレーニングできます。
結合されたモデルは、透かし入りのコンテンツを正しく識別し、透かしを元のコンテンツと視覚的に整列させることによる透かしの隠蔽性の向上など、さまざまな目標に合わせて最適化されています。
カリフォルニア大学リバーサイド校の電気およびコンピューター工学の教授であるAmit Roy-Chowdhuryは、画像の背景を注意深く見ることで、自分の目で偽の画像をより適切に検出できると述べました。
リソース: