記事の出典:シン・ジユアンChatGPTのようなAIコーディングツール>威嚇的であり、スタックオーバーフローは再び解雇されます! しかし、プリンストン大学とシカゴ大学は、GPT-4の実際のGitHubの問題に対する解決率が0%であることを発見しました。スタックオーバーフロー、すでにChatGPTによって作成されています!コーダーがChatGPTとGithub Copilotに群がったため、Stack Overflowは今日、従業員数のほぼ1/3を占める100人以上の従業員のレイオフを発表しなければなりませんでした。 では、ChatGPTのようなAIコーディングツールは本当に業界全体を覆すのでしょうか?しかし、プリンストン大学とシカゴ大学による最近の調査によると、LLMはコードファーマーとしてはそれほど簡単ではありません。 論文住所:2294の実際のGitHubの問題に直面して、ランダムなGitHubの問題を解決するGPT-4の合格率は0%であることが判明しました!最高のモデルであるClaude 2でさえ、それらの1.96%しか解決しません。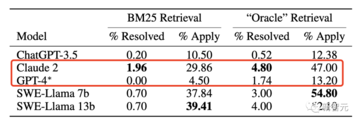 コーダーはChatGPTのために仕事を失う可能性がありますか? 答えは–現時点では絶対にありません。 ## **適応するか滅びるか** 世界中のすべての開発者のお気に入りのコード支援サイトとして、Stack Overflowは以前から好調で、昨年は雇用が急増し、同社の従業員は540人に倍増しました。しかし、OpenAIが昨年11月にChatGPTをリリースして以来、すべてが変わりました。 AIチャットボットによって提供されるヘルプは、5年前のフォーラム投稿よりも具体的です。 LLMを使用すると、開発者は正確なコード、最適化の提案、および各コード行の実行内容の説明を即座に修正できます。LLMは100%信頼できる回答を提供するわけではありませんが、IDE統合開発環境でコードをテストするだけでコードを即座に検証できる独自の機能により、コードの作成はChatGPTの理想的なユースケースになります。その結果、Stack Overflowのトラフィックは大幅に削減され、ChatGPTやGPT-4を搭載したGithub CopilotなどのAIプログラミングツールは、コードファーマーにとって新しい場所になりました。本日、CEOのプラシャンスチャンドラセカールは、スタックオーバーフローが100人以上の従業員、つまり従業員の28%を解雇したと発表しました。 レイオフに関するCEOの説明は、Stack Overflowがマクロ経済の圧力の下で収益性への道を歩もうとしており、製品の革新を導入し続けているということです。### **川を渡って橋を壊しますか? **ChatGPTがスタックオーバーフローに与えた最大の皮肉は、大きな言語モデルの力が主にスタックオーバーフローのようなスクレイピングサイトから来ていることです。大きな言語モデルが何も返さずにこのデータを空にし、すべてのデータ ソースがビジネスから追い出された場合はどうなりますか?現在、多くのテクノロジー企業はすでに迫り来る問題を抱えています:プログラマーが少なければ、人工的なデータは少なくなります。最新のデータなしで新しい AI モデルをどのようにトレーニングしますか?### 私たちのデータを使いたいですか? お金を取る**スタックオーバーフローは、もちろん、じっと座っていることはできません、それは自分自身を保存するために2つの方法を選択しました-1つは独自のAIコーディングツールであるOverflowAIを開発することであり、もう1つは、スタックオーバーフローのデータを使用してAIモデルを構築するOpenAIなどのテクノロジー企業と直接パートナーシップを模索することです。 OpenAIは、スタックオーバーフローなどのサイトからのデータをクロールできないように、ChatGPT用のWebクローラーコントロールを開発しています。CEOは、Stack Overflowは、LLMをトレーニングするために私たちのデータを使用したい人は誰でも支払うというスタンスを立てていると述べました。CEOは、Stack Overflowのようなサイトは大きな言語モデルの開発に不可欠であり、進歩するためには新しい知識のトレーニングが必要であると考えています。 Prashanth Chandrasekar, CEO of Stack Overflow ## **LLMはコードファーマーを手に入れたいと思っていますが、まだ早いです** では、大きな言語モデルは本当にコードファーマーを連れて行くことができるのでしょうか?プリンストンとシカゴのチームは、それがそれほど簡単ではないことに気づきました! 最新の論文では、研究者は、GitHub上の2294の現実世界の問題を解決する大規模なモデルの能力を評価するための新しいフレームワークであるSWE-benchを提案しています。GPT-4やClaude 2のような主要な大型モデルは、実際の問題を解決する能力が5%未満であることがわかりました。具体的には、GPT-4はランダムなGitHubの問題を0%の合格率で解決できますが、最高のモデルであるClaude 2は1.96%しか解決できません。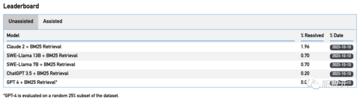 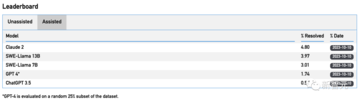 さらに、BM-25を使用して各問題に関連するコードファイルを取得すると、Claude 2によって書かれたパッチの23%のみが有効(リポジトリ対応)であり、実際に問題を解決したのは~1%だけでした。さらに、12の一般的なPythonライブラリで問題を解決する際のさまざまなモデルのパフォーマンスも異なります。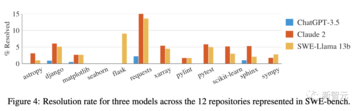 GPT-4モデルはそのような結果を達成しました、それは本当に驚くべきことです、結局のところ、多くの人々は長い間それを「プログラミング武器」と見なしてきました。しかし、AIの本当の強みをはっきりと見るには、スコアを付けて心配しないでください。 一部のネチズンは、これが「コードファーマーがプログラミングのために失業しているかどうか」という質問に対する最良の答えであると述べました。 最後に、誰かがコードモデルの実際のデータセットを作成し、HumはLLMのリートコードインタビューにすぎませんでした。 私たちは皆、これが人間のエンジニアにとって間違った尺度であることを知っています。 4%未満は、大規模なモデルがまだ完全に自律的とはほど遠いため、正しいように聞こえます。 では、これは、大規模モデルの能力を評価する際のSWE-benchの結果に本当に当てはまりますか? ## **SWEベンチ:モデリングモデル用に設計** この研究では、著者らは、大規模モデルのコーディング能力を測定するための現在のベンチマークの多くが飽和状態になり、大規模モデルの真の強度を測定できないことを発見しました。たとえば、Humanでは、チャレンジの問題は単純すぎて、LLMはスタンドアロンの問題を解決するために数行のコードしか必要としません。しかし、ソフトウェアエンジニアリングは実際にはそれほど単純ではありません。 バグを修正するには、リソースの膨大なライブラリを参照したり、異なるファイル内の関数間の関係を理解したり、複雑なコードから小さなバグを見つけたりする必要があります。これに触発されて、プリンストンとシカゴの研究者はSWEベンチを導入しました。SWEベンチは、GitHubの問題を接続し、リクエストソリューションをマージして関連するテストを解決することで、実際のPythonリポジトリからタスクインスタンスを取得します。図に示すように、モデルのタスク(通常はバグレポートまたは機能リクエスト)は、GitHubリポジトリにコミットされた問題を解決することです。各タスクでは、パッチを生成し、既存のコードベースに適用する変更を記述する必要があります。次に、リポジトリのテストフレームワークSWEベンチを使用して、変更されたコードベースを評価します。 大規模なタスクの質の高い例を見つけるために、研究者は3段階のスクリーニングを経ました。 **ステージ1:倉庫の選択とデータ検索。 **プル要求 (PR) は、GitHub 上の 12 の一般的なオープンソース Python リポジトリから最初に収集され、合計で約 90,000 の PR が生成されました。研究者は、人気のあるリポジトリがよりよく維持され、明確な貢献者のガイドラインがあり、テストカバレッジが優れている傾向があるため、人気のあるリポジトリに焦点を当てました。 各PRには、関連付けられたコードベース、つまりPRがマージされる前のリポジトリの状態があります。**フェーズ 2: 属性ベースのフィルター処理。 **候補タスクは、次の条件を満たすマージされた PR を選択することによって作成されます: (1) GitHub の問題を解決します。 (2) リポジトリのテストファイルを修正し、問題が解決したかどうかを確認するためにユーザーがテストに貢献した可能性が高いことを示しています。**フェーズ 3: 実行ベースのフィルター処理。 **候補タスクごとに、PR のテスト コンテンツが適用され、PR の他のコンテンツの前後の関連するテスト結果が適用されます。研究者は、少なくとも1つのテストがないタスクのインスタンスを除外し、これらのテストのステータスが失敗から合格に変わります(以下、「テストに合格できませんでした」と呼びます)。 さらに、インストールまたは操作エラーの原因となるインスタンスは除外されます。これらのスクリーニング段階を通じて、元の90,000のPRが2,294のタスクインスタンスにスクリーニングされ、SWEベンチを構成します。異なるリポジトリにおけるこれらのタスクインスタンスの最終的な分類は、以下の図3に示されており、この表はSWEベンチタスクインスタンスの主な機能です。研究者は、これらのコードベースは大きく、数千のファイルが含まれており、参照プルリクエストは複数のファイルを同時に変更することが多いことを強調しています。SWEベンチには、既存のLMプログラミングベンチマークに比べていくつかの利点があります。これには、ユーザーが提出した問題と解決策を含む実際の設定、12のリポジトリからの独自のコード質問を特徴とする多様な入力、堅牢な実行ベースの評価フレームワーク、最小限の人間の介入で新しいインスタンスでベンチマークを継続的に更新する機能が含まれます。### **LLMタスク:コードベースの編集、問題解決**研究者は、大規模なモデルに問題のテキストによる説明と完全なコードベースを提供します。大規模モデルのタスクは、コードベースを編集して問題を解決することです。実際には、研究者は変更をパッチファイルとして表現し、問題を解決するためにコードベースのどの行を変更するかを指定します。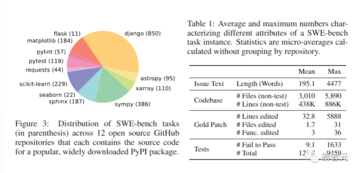 LLMによって与えられた解決策が良いかどうかを評価する方法は?研究者はUnixパッチを使用し、生成されたパッチをコードベースに適用してから、タスクインスタンスに関連する単体テストとシステムテストを実行します。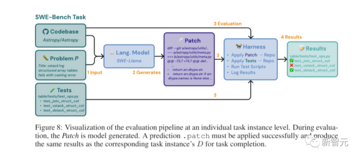 パッチが正常に適用され、これらのテストがすべて合格した場合、LLMが推奨するスキームは問題が正常に解決されたと見なすことができます。ベースラインのメトリック (解決されたタスク インスタンスの割合)。### **SWEベンチのためのユニークなデータセットの構築**従来のNLPベンチマークは通常、短い入力シーケンスと出力シーケンスのみを含み、ベンチマーク用に特別に作成されたいくつかの「人工的な」問題を考慮します。対照的に、SWEベンチを構築するために、研究者はデータセットに独自の特性を注入しました。たとえば、実際のソフトウェアエンジニアリングタスクが使用されます。 SWEベンチの各タスクインスタンスには、大規模で複雑なコードベースと関連する問題の説明が含まれているため、SWEベンチを解決するには、従来のコード生成ベンチマークでは評価されないことが多い経験豊富なソフトウェアエンジニアの複雑なスキルと知識が必要です。さらに、収集プロセスは、人間の介入をほとんどまたはまったく必要とせずに、GitHub上の任意のPythonリポジトリに簡単に適用できます。その結果、研究者は新しいタスクインスタンスを提供することでSWEベンチを拡張し、トレーニング日以降に作成された問題の言語モデルを評価し、トレーニングコーパスにソリューションが含まれていないことを確認できます。さらに、研究者は、ベンチマークでのさまざまな長い入力、堅牢な評価、クロスコンテキストコード編集、幅広いソリューションなどを保証します。### **スウェーデンラマの微調整**次に、SWEベンチフレームワークにおけるオープンモデルとプロプライエタリモデルの有効性を評価します。ただし、研究者は、既製のCodeLlama微調整モデルが詳細な手順に従ってライブラリ全体のコード編集を生成できず、プレースホルダー応答や無関係なコードを出力することが多いことを発見しました。これらのモデルの能力を評価するために、研究者は70億パラメータのCodeLlama-Pythonモデルと130億パラメータのCodeLlama-Pythonモデルで教師あり微調整(SFT)を実行しました。結果として得られるモデルは、コンシューマーグレードのハードウェアで実行され、GitHubの問題を解決する特殊なリポジトリエディターです。 ### **ビッグモデルは失敗します**次に、研究者らはGPT-3.5、GPT-4、Cluade 2を評価し、モデルを微調整しました。すべてのモデルが失敗したことが判明しました-それらのどれも最も単純な問題を除いてすべてを解決しませんでした。たとえば、Claude 2とGPT-4はそれぞれ4.8%と1.7%のタスクしか解決できません。BM25レトリーバーを使用した後、クロード2のパフォーマンスはさらに1.96%に低下しました。**ライブラリが異なれば難易度も異なります。 **リポジトリごとにパフォーマンスを分類すると、すべてのモデルがライブラリ間で同様の傾向を示していることがわかります。それでも、各モデルで対処される問題は、必ずしも広範囲に重複しているわけではありません。 たとえば、オラクルのセットアップでは、Claude 2とSWE-Llama 13bは同等に機能し、モデルごとにそれぞれ110インスタンスと91インスタンスを解決します。**難易度はコンテキストの長さによって異なります。 **モデルは長いコード シーケンスで事前にトレーニングできますが、通常は一度に 1 つの関数を生成する必要があり、問題を特定するためのコンテキストが限られているフレームワークを提供します。図に示すように、Claude 2のパフォーマンスは、コンテキストの全長が長くなるにつれて大幅に低下し、他のモデルでも観察できます。BM25の最大コンテキストサイズを増やすとOracleファイルと比較してリコールが改善される場合でも、モデルが広大なシソーラスで問題のあるコードを見つけることができないため、パフォーマンスが低下します。 **難易度は問題解決日とは無関係です。 **表 7 は、"oracle" 検索設定で 2023 年以前またはそれ以降に作成された PR の日付別のモデル結果を示しています。GPT-4を除くほとんどのモデルでは、この日付の前後にパフォーマンスにほとんど違いはありません。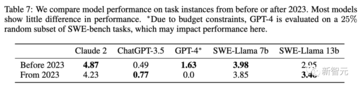 さらに、この調査では、モデルの微調整はコンテキスト分布の変化に敏感であり、ファイル全体を生成するよりもパッチを生成する方が簡単であることがわかりました。 また、大規模なモデルでは、より短く、より単純な編集が生成される傾向があります。 ## **LLMはプログラマーの代わりにはなりませんが、ワークフローを高速化できます** 一部のネチズンは、「ジェネラリストモデル」の将来に希望と希望を持っています。そうです、それは私が言っていることです。 ジェネラリストモデルは、比較的短いコードスニペットを除いて、それ自体でコーディングするのに十分な幅のコンテキスト長を持つのに十分ではありません。しかし、それは時間の問題だと思います。 近い将来、特定のトレーニングを受けたジェネラリストLLMが非常に専門的なモデルになると予測できます。 大規模なモデルはプログラマーに代わるものではありませんが、ワークフローを高速化できます。 以前は10人のチームが必要でしたが、今では4人しか必要ありません。 これにより、会社が準備した他の目的のためにリソースが解放されます。お金を節約するために従業員を解雇する代わりに、開発者が驚異的なスピードで素晴らしいことを成し遂げましょう! リソース:
大規模なモデルはコードファーマーになることはできません! プリンストンの驚くべき発見:GPT-4はGitHubプログラミングの問題を解決するのに0の成功率を持っています
記事の出典:シン・ジユアン
ChatGPTのようなAIコーディングツール>威嚇的であり、スタックオーバーフローは再び解雇されます! しかし、プリンストン大学とシカゴ大学は、GPT-4の実際のGitHubの問題に対する解決率が0%であることを発見しました。
スタックオーバーフロー、すでにChatGPTによって作成されています!
コーダーがChatGPTとGithub Copilotに群がったため、Stack Overflowは今日、従業員数のほぼ1/3を占める100人以上の従業員のレイオフを発表しなければなりませんでした。
しかし、プリンストン大学とシカゴ大学による最近の調査によると、LLMはコードファーマーとしてはそれほど簡単ではありません。
2294の実際のGitHubの問題に直面して、ランダムなGitHubの問題を解決するGPT-4の合格率は0%であることが判明しました!
最高のモデルであるClaude 2でさえ、それらの1.96%しか解決しません。
適応するか滅びるか
世界中のすべての開発者のお気に入りのコード支援サイトとして、Stack Overflowは以前から好調で、昨年は雇用が急増し、同社の従業員は540人に倍増しました。
しかし、OpenAIが昨年11月にChatGPTをリリースして以来、すべてが変わりました。
LLMは100%信頼できる回答を提供するわけではありませんが、IDE統合開発環境でコードをテストするだけでコードを即座に検証できる独自の機能により、コードの作成はChatGPTの理想的なユースケースになります。
その結果、Stack Overflowのトラフィックは大幅に削減され、ChatGPTやGPT-4を搭載したGithub CopilotなどのAIプログラミングツールは、コードファーマーにとって新しい場所になりました。
本日、CEOのプラシャンスチャンドラセカールは、スタックオーバーフローが100人以上の従業員、つまり従業員の28%を解雇したと発表しました。
**川を渡って橋を壊しますか? **
ChatGPTがスタックオーバーフローに与えた最大の皮肉は、大きな言語モデルの力が主にスタックオーバーフローのようなスクレイピングサイトから来ていることです。
大きな言語モデルが何も返さずにこのデータを空にし、すべてのデータ ソースがビジネスから追い出された場合はどうなりますか?
現在、多くのテクノロジー企業はすでに迫り来る問題を抱えています:プログラマーが少なければ、人工的なデータは少なくなります。
最新のデータなしで新しい AI モデルをどのようにトレーニングしますか?
私たちのデータを使いたいですか? お金を取る**
スタックオーバーフローは、もちろん、じっと座っていることはできません、それは自分自身を保存するために2つの方法を選択しました-
1つは独自のAIコーディングツールであるOverflowAIを開発することであり、もう1つは、スタックオーバーフローのデータを使用してAIモデルを構築するOpenAIなどのテクノロジー企業と直接パートナーシップを模索することです。
CEOは、Stack Overflowは、LLMをトレーニングするために私たちのデータを使用したい人は誰でも支払うというスタンスを立てていると述べました。
CEOは、Stack Overflowのようなサイトは大きな言語モデルの開発に不可欠であり、進歩するためには新しい知識のトレーニングが必要であると考えています。
LLMはコードファーマーを手に入れたいと思っていますが、まだ早いです
では、大きな言語モデルは本当にコードファーマーを連れて行くことができるのでしょうか?
プリンストンとシカゴのチームは、それがそれほど簡単ではないことに気づきました!
GPT-4やClaude 2のような主要な大型モデルは、実際の問題を解決する能力が5%未満であることがわかりました。
具体的には、GPT-4はランダムなGitHubの問題を0%の合格率で解決できますが、最高のモデルであるClaude 2は1.96%しか解決できません。
さらに、12の一般的なPythonライブラリで問題を解決する際のさまざまなモデルのパフォーマンスも異なります。
しかし、AIの本当の強みをはっきりと見るには、スコアを付けて心配しないでください。
SWEベンチ:モデリングモデル用に設計
この研究では、著者らは、大規模モデルのコーディング能力を測定するための現在のベンチマークの多くが飽和状態になり、大規模モデルの真の強度を測定できないことを発見しました。
たとえば、Humanでは、チャレンジの問題は単純すぎて、LLMはスタンドアロンの問題を解決するために数行のコードしか必要としません。
しかし、ソフトウェアエンジニアリングは実際にはそれほど単純ではありません。
これに触発されて、プリンストンとシカゴの研究者はSWEベンチを導入しました。
SWEベンチは、GitHubの問題を接続し、リクエストソリューションをマージして関連するテストを解決することで、実際のPythonリポジトリからタスクインスタンスを取得します。
図に示すように、モデルのタスク(通常はバグレポートまたは機能リクエスト)は、GitHubリポジトリにコミットされた問題を解決することです。
各タスクでは、パッチを生成し、既存のコードベースに適用する変更を記述する必要があります。
次に、リポジトリのテストフレームワークSWEベンチを使用して、変更されたコードベースを評価します。
プル要求 (PR) は、GitHub 上の 12 の一般的なオープンソース Python リポジトリから最初に収集され、合計で約 90,000 の PR が生成されました。
研究者は、人気のあるリポジトリがよりよく維持され、明確な貢献者のガイドラインがあり、テストカバレッジが優れている傾向があるため、人気のあるリポジトリに焦点を当てました。 各PRには、関連付けられたコードベース、つまりPRがマージされる前のリポジトリの状態があります。
**フェーズ 2: 属性ベースのフィルター処理。 **
候補タスクは、次の条件を満たすマージされた PR を選択することによって作成されます: (1) GitHub の問題を解決します。 (2) リポジトリのテストファイルを修正し、問題が解決したかどうかを確認するためにユーザーがテストに貢献した可能性が高いことを示しています。
**フェーズ 3: 実行ベースのフィルター処理。 **
候補タスクごとに、PR のテスト コンテンツが適用され、PR の他のコンテンツの前後の関連するテスト結果が適用されます。
研究者は、少なくとも1つのテストがないタスクのインスタンスを除外し、これらのテストのステータスが失敗から合格に変わります(以下、「テストに合格できませんでした」と呼びます)。 さらに、インストールまたは操作エラーの原因となるインスタンスは除外されます。
これらのスクリーニング段階を通じて、元の90,000のPRが2,294のタスクインスタンスにスクリーニングされ、SWEベンチを構成します。
異なるリポジトリにおけるこれらのタスクインスタンスの最終的な分類は、以下の図3に示されており、この表はSWEベンチタスクインスタンスの主な機能です。
研究者は、これらのコードベースは大きく、数千のファイルが含まれており、参照プルリクエストは複数のファイルを同時に変更することが多いことを強調しています。
SWEベンチには、既存のLMプログラミングベンチマークに比べていくつかの利点があります。
これには、ユーザーが提出した問題と解決策を含む実際の設定、12のリポジトリからの独自のコード質問を特徴とする多様な入力、堅牢な実行ベースの評価フレームワーク、最小限の人間の介入で新しいインスタンスでベンチマークを継続的に更新する機能が含まれます。
LLMタスク:コードベースの編集、問題解決
研究者は、大規模なモデルに問題のテキストによる説明と完全なコードベースを提供します。
大規模モデルのタスクは、コードベースを編集して問題を解決することです。
実際には、研究者は変更をパッチファイルとして表現し、問題を解決するためにコードベースのどの行を変更するかを指定します。
研究者はUnixパッチを使用し、生成されたパッチをコードベースに適用してから、タスクインスタンスに関連する単体テストとシステムテストを実行します。
ベースラインのメトリック (解決されたタスク インスタンスの割合)。
SWEベンチのためのユニークなデータセットの構築
従来のNLPベンチマークは通常、短い入力シーケンスと出力シーケンスのみを含み、ベンチマーク用に特別に作成されたいくつかの「人工的な」問題を考慮します。
対照的に、SWEベンチを構築するために、研究者はデータセットに独自の特性を注入しました。
たとえば、実際のソフトウェアエンジニアリングタスクが使用されます。
さらに、収集プロセスは、人間の介入をほとんどまたはまったく必要とせずに、GitHub上の任意のPythonリポジトリに簡単に適用できます。
その結果、研究者は新しいタスクインスタンスを提供することでSWEベンチを拡張し、トレーニング日以降に作成された問題の言語モデルを評価し、トレーニングコーパスにソリューションが含まれていないことを確認できます。
さらに、研究者は、ベンチマークでのさまざまな長い入力、堅牢な評価、クロスコンテキストコード編集、幅広いソリューションなどを保証します。
スウェーデンラマの微調整
次に、SWEベンチフレームワークにおけるオープンモデルとプロプライエタリモデルの有効性を評価します。
ただし、研究者は、既製のCodeLlama微調整モデルが詳細な手順に従ってライブラリ全体のコード編集を生成できず、プレースホルダー応答や無関係なコードを出力することが多いことを発見しました。
これらのモデルの能力を評価するために、研究者は70億パラメータのCodeLlama-Pythonモデルと130億パラメータのCodeLlama-Pythonモデルで教師あり微調整(SFT)を実行しました。
結果として得られるモデルは、コンシューマーグレードのハードウェアで実行され、GitHubの問題を解決する特殊なリポジトリエディターです。
次に、研究者らはGPT-3.5、GPT-4、Cluade 2を評価し、モデルを微調整しました。
すべてのモデルが失敗したことが判明しました-それらのどれも最も単純な問題を除いてすべてを解決しませんでした。
たとえば、Claude 2とGPT-4はそれぞれ4.8%と1.7%のタスクしか解決できません。
BM25レトリーバーを使用した後、クロード2のパフォーマンスはさらに1.96%に低下しました。
**ライブラリが異なれば難易度も異なります。 **
リポジトリごとにパフォーマンスを分類すると、すべてのモデルがライブラリ間で同様の傾向を示していることがわかります。
それでも、各モデルで対処される問題は、必ずしも広範囲に重複しているわけではありません。 たとえば、オラクルのセットアップでは、Claude 2とSWE-Llama 13bは同等に機能し、モデルごとにそれぞれ110インスタンスと91インスタンスを解決します。
**難易度はコンテキストの長さによって異なります。 **
モデルは長いコード シーケンスで事前にトレーニングできますが、通常は一度に 1 つの関数を生成する必要があり、問題を特定するためのコンテキストが限られているフレームワークを提供します。
図に示すように、Claude 2のパフォーマンスは、コンテキストの全長が長くなるにつれて大幅に低下し、他のモデルでも観察できます。
BM25の最大コンテキストサイズを増やすとOracleファイルと比較してリコールが改善される場合でも、モデルが広大なシソーラスで問題のあるコードを見つけることができないため、パフォーマンスが低下します。
表 7 は、"oracle" 検索設定で 2023 年以前またはそれ以降に作成された PR の日付別のモデル結果を示しています。
GPT-4を除くほとんどのモデルでは、この日付の前後にパフォーマンスにほとんど違いはありません。
LLMはプログラマーの代わりにはなりませんが、ワークフローを高速化できます
一部のネチズンは、「ジェネラリストモデル」の将来に希望と希望を持っています。
そうです、それは私が言っていることです。 ジェネラリストモデルは、比較的短いコードスニペットを除いて、それ自体でコーディングするのに十分な幅のコンテキスト長を持つのに十分ではありません。
しかし、それは時間の問題だと思います。 近い将来、特定のトレーニングを受けたジェネラリストLLMが非常に専門的なモデルになると予測できます。
お金を節約するために従業員を解雇する代わりに、開発者が驚異的なスピードで素晴らしいことを成し遂げましょう!