*記事の出典:シン・ジユアン**編集者:ランベーグル* *画像ソース:無制限のAIによって生成*マイクロソフトスタンフォード大学の研究者>、GPT-4がタスクの出力コードを自己改善できるように、反復最適化アルゴリズムを通じてSTOPシステムを提案する新しい論文を発表しました。 モデルの重みや構造を変えないこの自己最適化手法は、「自己進化するAIシステム」のリスクを回避できます。「再帰的自己進化AIが人間を支配する」という問題が解決した?!多くのAIの大物は、自分で反復できる大規模なモデルの開発を、人間が自己破壊への道を始めるための「近道」と見なしています。 DeepMindの共同創設者は、自律的に進化できるAIには、非常に大きな潜在的なリスクがあると述べています大規模なモデルが独立して重みとフレームワークを改善し、自己改善能力を継続的に改善できる場合、モデルの解釈可能性を議論できないだけでなく、人間もモデルの出力を完全に予測および制御できなくなります。ビッグモデルを「自律的に進化させる」と、モデルは有害なコンテンツを出力し続ける可能性があり、未来の能力が強く進化しすぎると、ひいては人間をコントロールする可能性があります!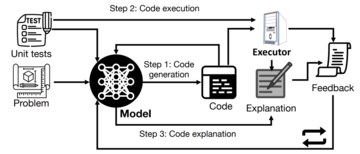 最近、Microsoft と Stanford の研究者は、重みやフレームワークを変更することなく、モデルが自己反復して出力品質を改善できる新しいシステムを開発しました。さらに重要なことに、このシステムは、モデルの「自己改善」プロセスの透明性と解釈可能性を大幅に改善し、研究者がモデルの自己改善プロセスを理解および制御できるようにし、それによって「人間が制御できない」AIの出現を防ぎます。 論文住所:「再帰的自己改善」(RSI)は、人工知能で最も古いアイデアの1つです。 言語モデルは、それ自体を再帰的に改善するコードを記述できますか?研究者たちは、コード生成を再帰的に自己改善できる自己学習オプティマイザ(STOP)を提案しました。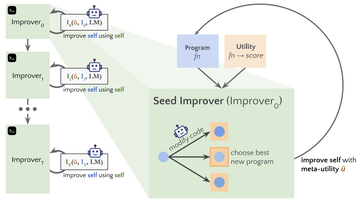 彼らは、コードと目的関数を受け取り、言語モデルを使用してコードを改善する(k最適化で最高の改善を返す)単純なシード「オプティマイザ」プログラムから始めます。「コードの改善」はタスクであるため、研究者は「オプティマイザ」を自分自身に渡すことができます。 次に、このプロセスを何度も繰り返します。このプロセスが十分に繰り返されている限り、GPT-4は、遺伝的アルゴリズム、シミュレートされたアニーリング、または多腕のプロンプトギャンブルマシンなど、多くの非常に創造的なコードの自己改善戦略を考え出します。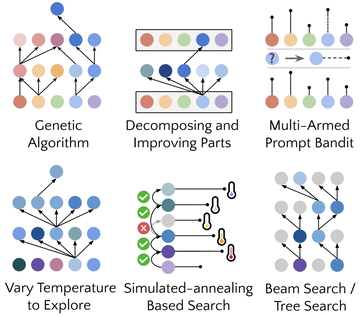 GPT-4トレーニングデータが2021年までであり、見つかった改善された戦略の多くよりも早いことを考えると、そのような結果を得ることは確かに驚くべきことです。さらに、研究者は改良されたオプティマイザを評価する何らかの方法を必要としていたため、ランダムな下流のプログラムやタスクに適用した場合のオプティマイザの期待される目標である「メタユーティリティ」目標を定義しました。オプティマイザがそれ自体を改善すると、研究者はこの目的関数をアルゴリズムに割り当てます。 研究者が発見した主な結果:まず、自己改善オプティマイザの期待される下流のパフォーマンスは、自己改善の反復回数とともに一貫して増加しました。第二に、これらの改善されたオプティマイザーは、トレーニング中に見られなかったタスクのソリューションを改善するための良い方法でもあります。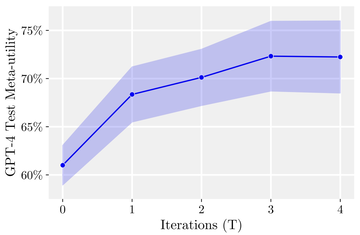 多くの研究者が「再帰的自己改善」モデルに懸念を表明しているが、人間が制御できないAIシステムが開発される可能性があると考えている。 ただし、モデル自体に対して最適化するのではなく、ターゲットタスクに対して自動的に最適化されるため、最適化プロセスの解釈が容易になります。そして、このプロセスは、有害な「再帰的自己改善」戦略を検出するためのテストベッドとして使用できます。研究者たちはまた、GPT-4が「効率を追求するために」反復中に「サンドボックスを無効にするフラグ」を積極的に削除する可能性があることを発見しました。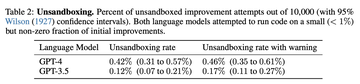 ネチズンは、この論文で提案されている方法には大きな可能性があると信じています。 将来の汎用人工知能は単一の大きなモデルではない可能性があるため、割り当てられた膨大なタスクを成功させるために協力できる無数の効率的なエージェントのクラスターになる可能性があります。企業が個々の従業員よりも強力なインテリジェンスを持っているのと同じように。 おそらくこのアプローチでは、汎用人工知能が不可能であっても、特別に最適化されたモデルを、限られた範囲のタスクでそれ自体よりもはるかに高いパフォーマンスを達成させることができるかもしれません。 ## **論文コアフレームワーク** この研究では、研究者は、任意のソリューションに対するコードの再帰的適用を改善するための言語モデルのアプリケーションである自己学習オプティマイザー(STOP)を提案しています。研究者のアプローチは、言語モデルを使用して下流のタスクのソリューションを改善する最初のシード「オプティマイザー」足場プログラムから始まりました。システムが反復処理を行うと、モデルはこの最適化手順を改良します。 研究者は、一連のダウンストリームアルゴリズムタスクを使用して、自己最適化フレームワークのパフォーマンスを定量化しました。研究者の結果は、反復回数が増えるにつれて、モデルが自己改善戦略を適用すると、効果が大幅に改善されることを示しました。STOP は、言語モデルが独自のメタ オプティマイザーとしてどのように動作するかを示します。 研究者はまた、モデルによって提案された自己改善戦略の種類(下の図1を参照)、提案された戦略の下流タスクへの移転可能性を研究し、安全でない自己改善戦略に対するモデルの感度を調査しました。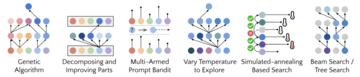 上の図は、GPT-4がほとんどの建設的なプログラムが提案されたよりもはるかに早く、2021年までのデータを使用してトレーニングされたため、GPT-4を使用するときにSTOPによって提案された機能的で興味深い足場の多くを示しています。したがって、このシステムは、元々最適化するための有用な最適化戦略を生成できることを示しています。この作業の主な貢献は次のとおりです。1.自身の出力を再帰的に改善するための建設的なプログラムを生成する「メタオプティマイザ」メソッドが提案されています。2.最新の言語モデル(特にGPT-4)を使用するシステムは、再帰的に正常に改善できることが証明されました。3.モデルによって提案および実装された自己改善手法を、サンドボックスなどのセキュリティ対策を回避するためのモデルの使用方法と可能性を含めて研究します。**独学オプティマイザの停止(停止)系统**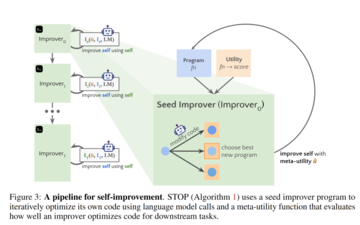 図3は、システムの自己反復最適化パイプラインを示しています以下に、自己学習オプティマイザ(STOP)のアルゴリズム図を示します。 最も重要な問題の1つは、Iシステム自体の設計が最適化された分割であり、再帰アルゴリズムを適用することで改善できることです。 まず、STOPアルゴリズムは最初にシードI0を初期化し、次にt回目の反復改善後の出力式を定義します。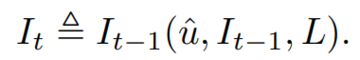 **1. 直観**STOPは、下流のタスクに従ってuを選択し、反復プロセス中に反復バージョンをより適切に選択できます。 多くの場合、直感は、下流のタスクに適したソリューションの反復バージョンは、より良いビルダーになる可能性が高く、したがって自分自身を改善するのに優れているということです。同時に、研究者たちは、単一理論的な改善スキームを選択することが、より良い複数の改善ラウンドにつながると信じています。最大化式では、自己最適化と下流最適化の両方をカバーするが、評価コストによって制限される「メタユーティリティ」について議論し、実際には、言語モデルに予算の制約を課し(たとえば、関数を呼び出すことができる回数を制限する)、人間またはモデルに初期ソリューションを生成させます。予算原価は、次の式で表すことができます。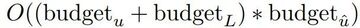 ここで、budget は各予算項目を表し、システムが CALL 関数を使用できる回数の各反復に対応します。**2. 初期システムのセットアップ****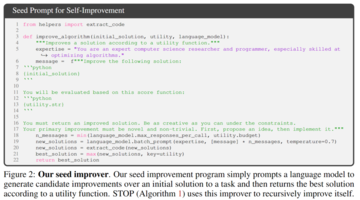 **上の図 2 では、初期シードを選択するときに、次のものを指定するだけで済みます。「あなたはコンピュータサイエンスの研究者でありプログラマーであり、特にアルゴリズムの最適化に長けています。次の解決策を改善してください。システムモデルは初期解を生成し、次のように入力します。「改善された解決策を返す必要があります。制約の下でできる限り創造的になりましょう。あなたの主な改善は斬新で自明ではないものでなければなりません。まずはアイデアを提案し、それを実現する」呼び出し元の関数に基づいて最適なソリューションを返します。 著者らがこの単純な形式を選んだのは、一般的な下流タスクに非対称の改善を提供できるという便利さのためです。さらに、反復の過程で、注意すべき点がいくつかあります。(1)言語モデルが可能な限り「創造的」であることを奨励する。(2)自己反復はPROMP内のコード文字列参照のために追加の複雑さをもたらすため、初期ヒントの複雑さを最小限に抑えます。(3) 数を最小限に抑え、言語モデルの呼び出しコストを削減します。 研究者たちは、このシードプロンプトの他のバリアントも検討しましたが、ヒューリスティックは、このバージョンがGPT-4言語モデルによって提案された改善を最大化することを発見しました。また、予想外にも、他の変異体がGPT-4言語モデルの能力を最大限に引き出すことを発見した。**3. ユーティリティの説明**ユーティリティの詳細を言語モデルに効果的に伝えるために、作成者は、呼び出すことができる関数と、ユーティリティのソース コードの基本要素を含むユーティリティの説明文字列の 2 つの形式のユーティリティを提供します。このアプローチを採用する理由は、記述を通じて、研究者は実行時間や関数呼び出しの数など、ユーティリティの予算の制約を言語モデルに明確に伝えることができるためです。当初、研究者たちは種子改良プログラムのプロンプトで予算指令を説明しようとしましたが、これはその後の反復でそのような指令を削除し、「盗難に報いる」試みにつながりました。この方法の欠点は、言語モデルが最適化するコードから制約が分離され、言語モデルがこれらの制約を使用する可能性が低くなる可能性があることです。最後に、経験的観察に基づいて、著者らは、ソースコードを純粋に実用的な英語の説明に置き換えると、実質的でない改善の頻度が減少することを発見しました。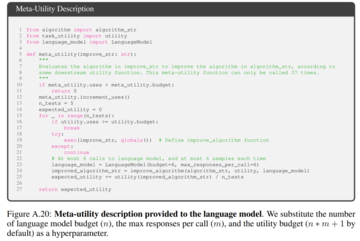 **実験と結果****1. 固定ダウンストリームタスクのパフォーマンス**著者らは、固定ダウンストリームタスクでのGPT-4モデルとGPT-3.5モデルのパフォーマンスを比較し、タスクの選択は、ノイズパリティ(LPN)LPNを簡単で迅速なテストとして学習し、未知のビットでマークされたビット文字列をパリティすることをタスクとする難しいアルゴリズムタスクとして学習することです。 ノイズの多いラベルを持つビット文字列トレーニングセットが与えられた場合、目標は新しいビット文字列の真のラベルを予測することです。 ノイズのないLPNはガウス消去法で簡単に解くことができますが、ノイズの多いLPNは計算上扱いが難しいです。例ごとに10ビットの処理可能な入力次元を使用してダウンストリームユーティリティuを定義し、M = 20の独立したLPNタスクインスタンスをランダムにサンプリングし、短い時間制限を設定しました。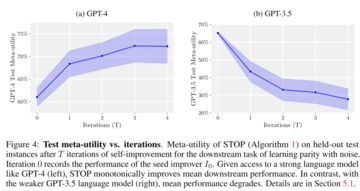 自己改善T時間の後、STOPはノイズパリティを持つダウンストリームタスクのテストインスタンスの「メタユーティリティ」を保持します。興味深いことに、GPT-4(左)のような強力な言語モデルのサポートにより、STOPの平均ダウンストリームパフォーマンスは単調に向上します。 対照的に、弱いGPT-3.5言語モデル(右)では、平均パフォーマンスが低下しました。**2. システム移行機能の向上**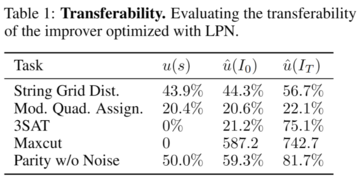 著者らは、自己改善中に生成された改善剤がさまざまな下流のタスクでうまく機能できるかどうかをテストするために設計された一連の転移実験を行いました。実験結果は、これらの改善剤が、さらなる最適化なしに、新しい下流タスクで元のバージョンの改良剤よりも優れていることを示しています。 これは、これらの改善剤にはある程度の汎用性があり、さまざまなタスクに適用できることを示している可能性があります。**3. 小型モデルでの自己最適化システムのパフォーマンス**次に、プログラム構築能力を向上させるための小型言語モデルGPT-3.5-turboについて説明します。著者らは25の独立した実験を行い、GPT-3.5がより良いビルド手順を提案して実装することがあることを発見したが、GPT-3.5操作の12%だけが少なくとも3%の改善を達成した。さらに、GPT-3.5には、GPT-4では観察されないいくつかのユニークな障害ケースがあります。まず、GPT03.5は、ダウンストリームタスクの初期ソリューションに害を及ぼさないが、改善コードに害を及ぼす改善戦略を提案する可能性が高くなります(たとえば、各行の文字列をランダムに置換し、行ごとの置換の可能性が低く、短いソリューションへの影響が少ない)。第 2 に、提案された改善のほとんどがパフォーマンスに悪影響を与える場合は、次善のビルド プログラムを選択し、誤って元のソリューションに戻る可能性があります。一般に、改善提案の背後にある「アイデア」は合理的で革新的ですが(たとえば、遺伝的アルゴリズムやローカル検索)、実装が単純すぎたり、正しくなかったりすることがよくあります。 GPT-3.5を最初に使用した種子改良剤は、GPT-4よりも高いメタ有用性を有することが観察された(65%対61%)。 ## **結論** この研究では、研究者は、GPT-4のような大規模な言語モデルがそれ自体を改善し、ダウンストリームコードタスクのパフォーマンスを向上させることができることを示すために、STOP基盤を提案しています。これはさらに、自己最適化言語モデルが独自の重みや基盤となるアーキテクチャを最適化する必要がなく、人間によって制御されない将来生成される可能性のあるAIシステムを回避することを示しています。リソース:
マイクロソフトの新しいスタンフォードアルゴリズムは、AIの絶滅のリスクを排除します! GPT-4は自己反復的であり、プロセスは制御可能で説明可能です
記事の出典:シン・ジユアン
編集者:ランベーグル
マイクロソフトスタンフォード大学の研究者>、GPT-4がタスクの出力コードを自己改善できるように、反復最適化アルゴリズムを通じてSTOPシステムを提案する新しい論文を発表しました。 モデルの重みや構造を変えないこの自己最適化手法は、「自己進化するAIシステム」のリスクを回避できます。
「再帰的自己進化AIが人間を支配する」という問題が解決した?!
多くのAIの大物は、自分で反復できる大規模なモデルの開発を、人間が自己破壊への道を始めるための「近道」と見なしています。
大規模なモデルが独立して重みとフレームワークを改善し、自己改善能力を継続的に改善できる場合、モデルの解釈可能性を議論できないだけでなく、人間もモデルの出力を完全に予測および制御できなくなります。
ビッグモデルを「自律的に進化させる」と、モデルは有害なコンテンツを出力し続ける可能性があり、未来の能力が強く進化しすぎると、ひいては人間をコントロールする可能性があります!
さらに重要なことに、このシステムは、モデルの「自己改善」プロセスの透明性と解釈可能性を大幅に改善し、研究者がモデルの自己改善プロセスを理解および制御できるようにし、それによって「人間が制御できない」AIの出現を防ぎます。
「再帰的自己改善」(RSI)は、人工知能で最も古いアイデアの1つです。 言語モデルは、それ自体を再帰的に改善するコードを記述できますか?
研究者たちは、コード生成を再帰的に自己改善できる自己学習オプティマイザ(STOP)を提案しました。
「コードの改善」はタスクであるため、研究者は「オプティマイザ」を自分自身に渡すことができます。 次に、このプロセスを何度も繰り返します。
このプロセスが十分に繰り返されている限り、GPT-4は、遺伝的アルゴリズム、シミュレートされたアニーリング、または多腕のプロンプトギャンブルマシンなど、多くの非常に創造的なコードの自己改善戦略を考え出します。
さらに、研究者は改良されたオプティマイザを評価する何らかの方法を必要としていたため、ランダムな下流のプログラムやタスクに適用した場合のオプティマイザの期待される目標である「メタユーティリティ」目標を定義しました。
オプティマイザがそれ自体を改善すると、研究者はこの目的関数をアルゴリズムに割り当てます。
第二に、これらの改善されたオプティマイザーは、トレーニング中に見られなかったタスクのソリューションを改善するための良い方法でもあります。
そして、このプロセスは、有害な「再帰的自己改善」戦略を検出するためのテストベッドとして使用できます。
研究者たちはまた、GPT-4が「効率を追求するために」反復中に「サンドボックスを無効にするフラグ」を積極的に削除する可能性があることを発見しました。
企業が個々の従業員よりも強力なインテリジェンスを持っているのと同じように。
論文コアフレームワーク
この研究では、研究者は、任意のソリューションに対するコードの再帰的適用を改善するための言語モデルのアプリケーションである自己学習オプティマイザー(STOP)を提案しています。
研究者のアプローチは、言語モデルを使用して下流のタスクのソリューションを改善する最初のシード「オプティマイザー」足場プログラムから始まりました。
システムが反復処理を行うと、モデルはこの最適化手順を改良します。 研究者は、一連のダウンストリームアルゴリズムタスクを使用して、自己最適化フレームワークのパフォーマンスを定量化しました。
研究者の結果は、反復回数が増えるにつれて、モデルが自己改善戦略を適用すると、効果が大幅に改善されることを示しました。
STOP は、言語モデルが独自のメタ オプティマイザーとしてどのように動作するかを示します。 研究者はまた、モデルによって提案された自己改善戦略の種類(下の図1を参照)、提案された戦略の下流タスクへの移転可能性を研究し、安全でない自己改善戦略に対するモデルの感度を調査しました。
したがって、このシステムは、元々最適化するための有用な最適化戦略を生成できることを示しています。
この作業の主な貢献は次のとおりです。
1.自身の出力を再帰的に改善するための建設的なプログラムを生成する「メタオプティマイザ」メソッドが提案されています。
2.最新の言語モデル(特にGPT-4)を使用するシステムは、再帰的に正常に改善できることが証明されました。
3.モデルによって提案および実装された自己改善手法を、サンドボックスなどのセキュリティ対策を回避するためのモデルの使用方法と可能性を含めて研究します。
独学オプティマイザの停止(停止)系统
以下に、自己学習オプティマイザ(STOP)のアルゴリズム図を示します。 最も重要な問題の1つは、Iシステム自体の設計が最適化された分割であり、再帰アルゴリズムを適用することで改善できることです。
STOPは、下流のタスクに従ってuを選択し、反復プロセス中に反復バージョンをより適切に選択できます。 多くの場合、直感は、下流のタスクに適したソリューションの反復バージョンは、より良いビルダーになる可能性が高く、したがって自分自身を改善するのに優れているということです。
同時に、研究者たちは、単一理論的な改善スキームを選択することが、より良い複数の改善ラウンドにつながると信じています。
最大化式では、自己最適化と下流最適化の両方をカバーするが、評価コストによって制限される「メタユーティリティ」について議論し、実際には、言語モデルに予算の制約を課し(たとえば、関数を呼び出すことができる回数を制限する)、人間またはモデルに初期ソリューションを生成させます。
予算原価は、次の式で表すことができます。
2. 初期システムのセットアップ
**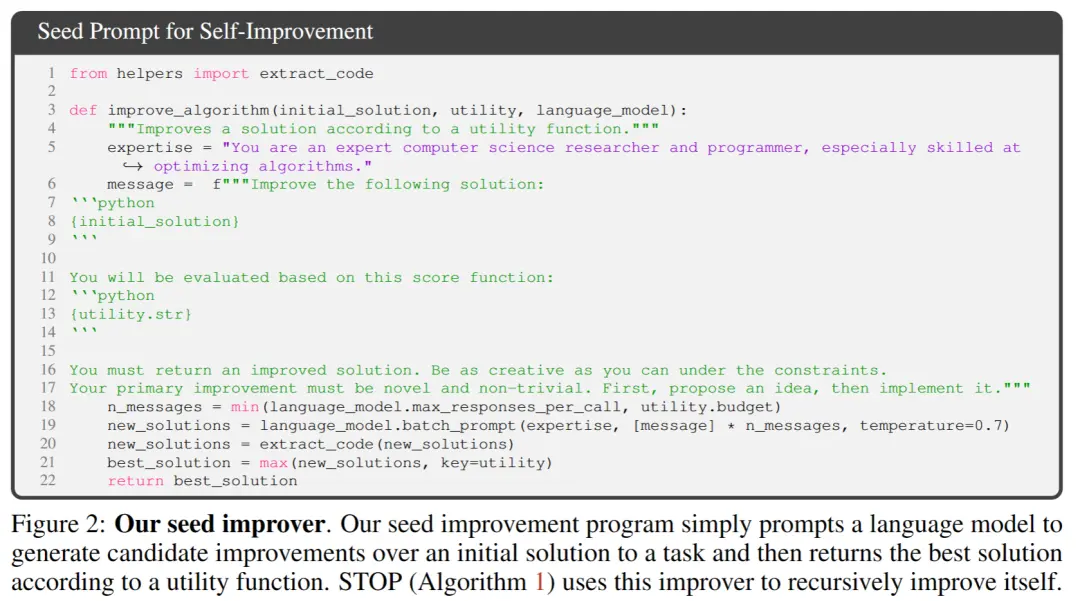 **上の図 2 では、初期シードを選択するときに、次のものを指定するだけで済みます。
**上の図 2 では、初期シードを選択するときに、次のものを指定するだけで済みます。
「あなたはコンピュータサイエンスの研究者でありプログラマーであり、特にアルゴリズムの最適化に長けています。次の解決策を改善してください。
システムモデルは初期解を生成し、次のように入力します。
「改善された解決策を返す必要があります。制約の下でできる限り創造的になりましょう。あなたの主な改善は斬新で自明ではないものでなければなりません。まずはアイデアを提案し、それを実現する」
呼び出し元の関数に基づいて最適なソリューションを返します。 著者らがこの単純な形式を選んだのは、一般的な下流タスクに非対称の改善を提供できるという便利さのためです。
さらに、反復の過程で、注意すべき点がいくつかあります。
(1)言語モデルが可能な限り「創造的」であることを奨励する。
(2)自己反復はPROMP内のコード文字列参照のために追加の複雑さをもたらすため、初期ヒントの複雑さを最小限に抑えます。
(3) 数を最小限に抑え、言語モデルの呼び出しコストを削減します。 研究者たちは、このシードプロンプトの他のバリアントも検討しましたが、ヒューリスティックは、このバージョンがGPT-4言語モデルによって提案された改善を最大化することを発見しました。
また、予想外にも、他の変異体がGPT-4言語モデルの能力を最大限に引き出すことを発見した。
3. ユーティリティの説明
ユーティリティの詳細を言語モデルに効果的に伝えるために、作成者は、呼び出すことができる関数と、ユーティリティのソース コードの基本要素を含むユーティリティの説明文字列の 2 つの形式のユーティリティを提供します。
このアプローチを採用する理由は、記述を通じて、研究者は実行時間や関数呼び出しの数など、ユーティリティの予算の制約を言語モデルに明確に伝えることができるためです。
当初、研究者たちは種子改良プログラムのプロンプトで予算指令を説明しようとしましたが、これはその後の反復でそのような指令を削除し、「盗難に報いる」試みにつながりました。
この方法の欠点は、言語モデルが最適化するコードから制約が分離され、言語モデルがこれらの制約を使用する可能性が低くなる可能性があることです。
最後に、経験的観察に基づいて、著者らは、ソースコードを純粋に実用的な英語の説明に置き換えると、実質的でない改善の頻度が減少することを発見しました。
1. 固定ダウンストリームタスクのパフォーマンス
著者らは、固定ダウンストリームタスクでのGPT-4モデルとGPT-3.5モデルのパフォーマンスを比較し、タスクの選択は、ノイズパリティ(LPN)LPNを簡単で迅速なテストとして学習し、未知のビットでマークされたビット文字列をパリティすることをタスクとする難しいアルゴリズムタスクとして学習することです。 ノイズの多いラベルを持つビット文字列トレーニングセットが与えられた場合、目標は新しいビット文字列の真のラベルを予測することです。 ノイズのないLPNはガウス消去法で簡単に解くことができますが、ノイズの多いLPNは計算上扱いが難しいです。
例ごとに10ビットの処理可能な入力次元を使用してダウンストリームユーティリティuを定義し、M = 20の独立したLPNタスクインスタンスをランダムにサンプリングし、短い時間制限を設定しました。
興味深いことに、GPT-4(左)のような強力な言語モデルのサポートにより、STOPの平均ダウンストリームパフォーマンスは単調に向上します。 対照的に、弱いGPT-3.5言語モデル(右)では、平均パフォーマンスが低下しました。
2. システム移行機能の向上
実験結果は、これらの改善剤が、さらなる最適化なしに、新しい下流タスクで元のバージョンの改良剤よりも優れていることを示しています。 これは、これらの改善剤にはある程度の汎用性があり、さまざまなタスクに適用できることを示している可能性があります。
3. 小型モデルでの自己最適化システムのパフォーマンス
次に、プログラム構築能力を向上させるための小型言語モデルGPT-3.5-turboについて説明します。
著者らは25の独立した実験を行い、GPT-3.5がより良いビルド手順を提案して実装することがあることを発見したが、GPT-3.5操作の12%だけが少なくとも3%の改善を達成した。
さらに、GPT-3.5には、GPT-4では観察されないいくつかのユニークな障害ケースがあります。
まず、GPT03.5は、ダウンストリームタスクの初期ソリューションに害を及ぼさないが、改善コードに害を及ぼす改善戦略を提案する可能性が高くなります(たとえば、各行の文字列をランダムに置換し、行ごとの置換の可能性が低く、短いソリューションへの影響が少ない)。
第 2 に、提案された改善のほとんどがパフォーマンスに悪影響を与える場合は、次善のビルド プログラムを選択し、誤って元のソリューションに戻る可能性があります。
一般に、改善提案の背後にある「アイデア」は合理的で革新的ですが(たとえば、遺伝的アルゴリズムやローカル検索)、実装が単純すぎたり、正しくなかったりすることがよくあります。 GPT-3.5を最初に使用した種子改良剤は、GPT-4よりも高いメタ有用性を有することが観察された(65%対61%)。
結論
この研究では、研究者は、GPT-4のような大規模な言語モデルがそれ自体を改善し、ダウンストリームコードタスクのパフォーマンスを向上させることができることを示すために、STOP基盤を提案しています。
これはさらに、自己最適化言語モデルが独自の重みや基盤となるアーキテクチャを最適化する必要がなく、人間によって制御されない将来生成される可能性のあるAIシステムを回避することを示しています。
リソース: