出典:アカデミックヘッドライン *画像ソース:無制限のAIによって生成*先月、ChatGPTは画像および音声認識機能を正式にリリースしました。今月初め、マイクロソフトはGPT-4V関連のドキュメントの166ページのマルチモーダルバージョンをリリースし、業界で広く注目を集めたGPT-4Vの機能と使用法を詳しく説明しました。 しかし、Googleは視覚言語モデルの競争に負けるべきではありません。 **最近、Google Research、Google DeepMind、Google Cloudは共同で、より小さく、より速く、より強力な視覚言語モデル(VLM)であるPaLI-3を発売しましたが、これは10倍大きい同様のモデルと大幅に競争力があります。研究者らは、カテゴリターゲットを使用して事前トレーニングされたビジュアルトランスフォーマー(ViT)モデルとコントラスティブ事前トレーニングモデル(SigLIP)を比較し、PaLI-3は標準的な画像分類ベンチマークでわずかにパフォーマンスが低い一方で、SigLIPベースのPaLIは、さまざまなマルチモーダルベンチマーク、特にローカリゼーションとテキスト理解において優れたパフォーマンスを示したことを発見しました。「*PaLI-3 Vision Language Models: Small, Faster, Stronger*」と題された研究論文が、プレプリントウェブサイトarXivに掲載されました。 研究チームは、わずか50億個のパラメータを持つPaLI-3が、複雑なVLMのコアコンポーネントに関する研究を再燃させ、新世代の大型モデルの開発を促進する可能性があると考えています。 ## **高解像度マルチモーダル学習** 最近では、大規模な視覚言語モデルでは、大規模なモデルで事前トレーニング済みの画像エンコーダーが使用されており、教師付き分類を使用して事前トレーニングされているもの(PaLI、PaLI-X、Flamingo、PaLM-Eなど)、事前トレーニング済みのCLIPエンコーダーを使用しているもの(BLIPv2、CrossTVR、ChatBridgeなど)、カスタムマルチモーダル事前トレーニングを使用しているもの(BEiT3、CoCa、SimVLMなど)があります。**本研究の学習方法は、ネットワーク規模の画像テキストデータに対する画像エンコーダの対照的事前学習、PaLIマルチモーダル訓練データブレンディングの改善、高解像度での学習の3つの主要コンポーネントで構成されています。 **シングルモーダル事前学習段階では、画像エンコーダはSigLIP学習プロトコルを使用して、Web上の画像テキストペアリングの比較事前学習を行います。 研究者らは、ペアリングの約40%を保存するモデルベースのフィルタリング方法を採用しました。 イメージ エンコーダーは、224×224 の解像度でトレーニングされます。 テキストエンコーダー/デコーダーは、ハイブリッドノイズ除去プログラムでトレーニングされた3B UL2モデルです。マルチモーダルトレーニングフェーズでは、研究者は画像エンコーダーとテキストエンコーダーデコーダーを組み合わせてPaLIモデルを形成しました。 このモデルは、ネイティブ解像度(224×224)を使用して、画像エンコーダーをフリーズしたままにするマルチモーダルタスク用にトレーニングされています。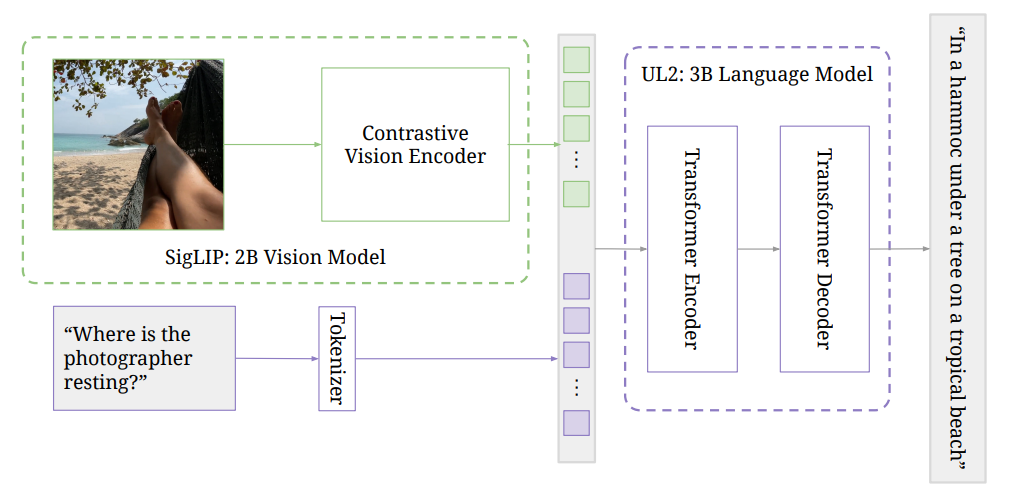 主なデータミックスはWebLIデータセットから取得され、フィルタリングされて特定のトレーニングターゲットで使用されます。 その他の要素には、多言語キャプション、OCR処理、言語間VQAおよびVQG、オブジェクト認識VQA、およびオブジェクト検出が含まれます。 ビデオからのタスクやデータは含まれていませんが、PaLI-3は強力な画像エンコーダーのおかげで、これらのベンチマークで競争力があります。 さらに、ポスターやドキュメントなどの密度の高いテキストやWeb画像を含むPDFドキュメント、および100を超える言語のテキストをWebLIに追加することで、ドキュメントと画像の理解がさらに向上しました。解像度を上げるフェーズでは、モデル全体を微調整し(画像エンコーダーを解凍)、チェックポイントを812×812および1064×1064の解像度に維持しながら、解像度を徐々に上げる短いレッスンを使用して、PaLI-3の解像度を調べます。 データブレンディングは、主にテキストの視覚的な配置とオブジェクトの検出を含む部分に焦点を当てています。 ## **画像の理解とテキストの配置タスクを改善する** まず、研究者らはPaLIの枠組みの中で異なるViTモデルの制御された比較を行った。 SigLIPモデルは、小サンプル線形分類ではパフォーマンスが低いが、PaLI-3で使用した場合、SigLIPモデルは、キャプションや質問応答などの「単純な」タスクでわずかなパフォーマンスの向上をもたらし、TextVQAやRefCOCOバリアントなどのより「複雑な」シーンテキストおよび空間理解タスクで大幅な改善をもたらすことがわかった。 **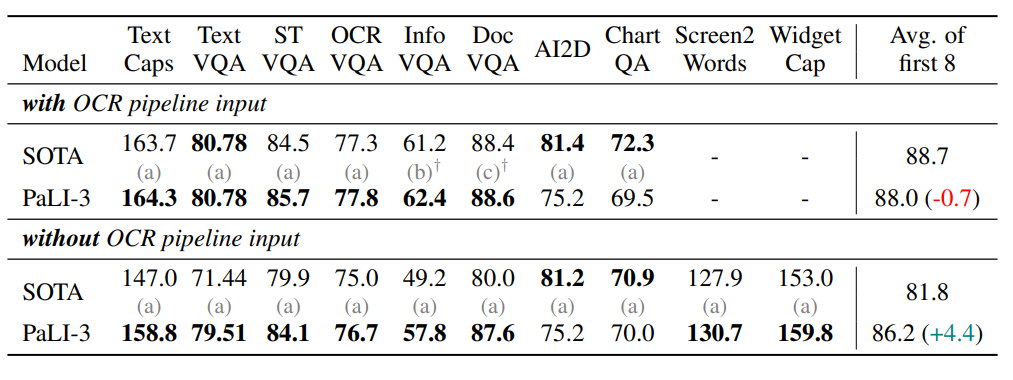 次に、PaLI-3は、自然な画像、イラスト、ドキュメント、ユーザーインターフェイスなどのデータセット内の画像を使用して、視覚的に配置されたテキスト理解タスクで評価されました。 **PaLI-3は、外部OCR入力の有無にかかわらず、ほとんどの字幕およびVQAベンチマークで最先端のパフォーマンスを実現します。 唯一の例外はAI2DとChartQAで、チャートを理解するだけでなく、強力な推論も必要です。 どちらのベンチマークでも、PaLI-3はPaLI-Xよりわずかに遅れています。さらに、研究者らはPaLI-3の機能を拡張して、言語のような出力でセグメンテーションマスクを予測しました。 実験結果は、このタイプのローカリゼーションタスクでは、比較事前学習が分類事前学習よりも効果的であることを示しています。 **完全なPaLI-3モデルは、指の表現の点で最先端の方法よりもわずかに優れています。 **自然画像理解のセクションでは、PaLI-3は、COCOキャプションやVQAv2**を含む一般的な視覚言語理解タスクで評価されましたが、最近のSOTAモデルと比較してスケールははるかに小さいものの、PaLI-3はこれらのベンチマークで非常に優れたパフォーマンスを示しました。 **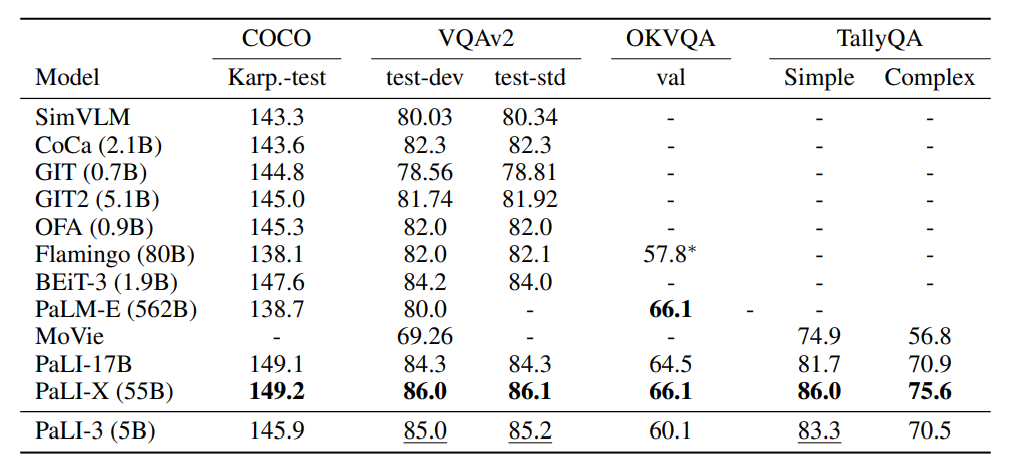 ビデオキャプションとQ&Aのセクションでは、研究者は4つのビデオキャプションベンチマーク(MSR-VTT、VATEX、ActivityNetキャプション、Spoken Moments in Time)でPaLI-3モデルを微調整および評価しました。 次に、同じテストを3つのビデオ質問応答ベンチマーク(NExT-QA、MSR-VTT-QA、およびActivityNet-QA)で実行しました。 **PaLI-3は、ビデオデータによる事前学習を行っていないにもかかわらず、より小さなモデルサイズで優れたビデオ品質保証結果を達成しました。 **全体として、この研究では、研究者はVLMの画像エンコーダー、特にPaLIタイプのモデルの事前トレーニングを掘り下げました。 初めて、分類事前学習と画像テキスト(コントラスト)事前学習の2つの方法が明確に比較され、後者が、特にローカリゼーションとテキスト理解タスクにおいて、より優れた効率的なVLMにつながることがわかりました。さらに、研究者たちは論文の中で、「これはVLMの小さな側面の1つに過ぎず、この研究とその結果がVLMトレーニングの他の多くの側面のより深い探求を刺激することを願っています」と述べています。 "*論文リンク:*
GPT-4Vと向き合おう! GoogleのPaLI-3ビジュアル言語モデルが登場し、より小さく、より速く、より強力になりました
出典:アカデミックヘッドライン
先月、ChatGPTは画像および音声認識機能を正式にリリースしました。
今月初め、マイクロソフトはGPT-4V関連のドキュメントの166ページのマルチモーダルバージョンをリリースし、業界で広く注目を集めたGPT-4Vの機能と使用法を詳しく説明しました。
最近、Google Research、Google DeepMind、Google Cloudは共同で、より小さく、より速く、より強力な視覚言語モデル(VLM)であるPaLI-3を発売しましたが、これは10倍大きい同様のモデルと大幅に競争力があります。
研究者らは、カテゴリターゲットを使用して事前トレーニングされたビジュアルトランスフォーマー(ViT)モデルとコントラスティブ事前トレーニングモデル(SigLIP)を比較し、PaLI-3は標準的な画像分類ベンチマークでわずかにパフォーマンスが低い一方で、SigLIPベースのPaLIは、さまざまなマルチモーダルベンチマーク、特にローカリゼーションとテキスト理解において優れたパフォーマンスを示したことを発見しました。
「PaLI-3 Vision Language Models: Small, Faster, Stronger」と題された研究論文が、プレプリントウェブサイトarXivに掲載されました。
高解像度マルチモーダル学習
最近では、大規模な視覚言語モデルでは、大規模なモデルで事前トレーニング済みの画像エンコーダーが使用されており、教師付き分類を使用して事前トレーニングされているもの(PaLI、PaLI-X、Flamingo、PaLM-Eなど)、事前トレーニング済みのCLIPエンコーダーを使用しているもの(BLIPv2、CrossTVR、ChatBridgeなど)、カスタムマルチモーダル事前トレーニングを使用しているもの(BEiT3、CoCa、SimVLMなど)があります。
**本研究の学習方法は、ネットワーク規模の画像テキストデータに対する画像エンコーダの対照的事前学習、PaLIマルチモーダル訓練データブレンディングの改善、高解像度での学習の3つの主要コンポーネントで構成されています。 **
シングルモーダル事前学習段階では、画像エンコーダはSigLIP学習プロトコルを使用して、Web上の画像テキストペアリングの比較事前学習を行います。 研究者らは、ペアリングの約40%を保存するモデルベースのフィルタリング方法を採用しました。 イメージ エンコーダーは、224×224 の解像度でトレーニングされます。 テキストエンコーダー/デコーダーは、ハイブリッドノイズ除去プログラムでトレーニングされた3B UL2モデルです。
マルチモーダルトレーニングフェーズでは、研究者は画像エンコーダーとテキストエンコーダーデコーダーを組み合わせてPaLIモデルを形成しました。 このモデルは、ネイティブ解像度(224×224)を使用して、画像エンコーダーをフリーズしたままにするマルチモーダルタスク用にトレーニングされています。
解像度を上げるフェーズでは、モデル全体を微調整し(画像エンコーダーを解凍)、チェックポイントを812×812および1064×1064の解像度に維持しながら、解像度を徐々に上げる短いレッスンを使用して、PaLI-3の解像度を調べます。 データブレンディングは、主にテキストの視覚的な配置とオブジェクトの検出を含む部分に焦点を当てています。
画像の理解とテキストの配置タスクを改善する
まず、研究者らはPaLIの枠組みの中で異なるViTモデルの制御された比較を行った。 SigLIPモデルは、小サンプル線形分類ではパフォーマンスが低いが、PaLI-3で使用した場合、SigLIPモデルは、キャプションや質問応答などの「単純な」タスクでわずかなパフォーマンスの向上をもたらし、TextVQAやRefCOCOバリアントなどのより「複雑な」シーンテキストおよび空間理解タスクで大幅な改善をもたらすことがわかった。 **
さらに、研究者らはPaLI-3の機能を拡張して、言語のような出力でセグメンテーションマスクを予測しました。 実験結果は、このタイプのローカリゼーションタスクでは、比較事前学習が分類事前学習よりも効果的であることを示しています。 **完全なPaLI-3モデルは、指の表現の点で最先端の方法よりもわずかに優れています。 **
自然画像理解のセクションでは、PaLI-3は、COCOキャプションやVQAv2**を含む一般的な視覚言語理解タスクで評価されましたが、最近のSOTAモデルと比較してスケールははるかに小さいものの、PaLI-3はこれらのベンチマークで非常に優れたパフォーマンスを示しました。 **
全体として、この研究では、研究者はVLMの画像エンコーダー、特にPaLIタイプのモデルの事前トレーニングを掘り下げました。 初めて、分類事前学習と画像テキスト(コントラスト)事前学習の2つの方法が明確に比較され、後者が、特にローカリゼーションとテキスト理解タスクにおいて、より優れた効率的なVLMにつながることがわかりました。
さらに、研究者たちは論文の中で、「これはVLMの小さな側面の1つに過ぎず、この研究とその結果がVLMトレーニングの他の多くの側面のより深い探求を刺激することを願っています」と述べています。 "
論文リンク: