元のソース: 量子ビット 画像ソース:無制限のAIによって生成ビッグモデルの嵐が一年のほとんどの間吹き荒れ、AIGC市場は再び変化し始めました。クールな技術デモは、完全な製品体験に置き換えられています。 **たとえば、OpenAIの最新AIペイントモデルDALL· E 3がデビューするとすぐに、ChatGPTと力を合わせて、ChatGPT Plusで最も期待されている新しい生産性ツールになりました。######** **###### **△**ダル· E3はテキスト入力の細部を正確に再現しますたとえば、GPT-4に基づくマイクロソフトのコパイロットはWindows 11で完全に解決され、オペレーティングシステムの新世代のAIアシスタントとしてCortanaに正式に取って代わりました。######** **###### **△** Copilotを使用して、ワンクリックでブログ投稿を要約します別の例として、Jiyue 01などの国産車はコックピットに大型モデルを正式に装備しており、完全にオフラインになっています...2023年3月の「ビッグモデルがすべてを再形成する」ことがテクノロジーパイオニアの楽観的な予測にすぎなかった場合、今日、依然として激しい100モデルの戦争と実用化の進歩により、この見解は業界の内外でますます共鳴しています。言い換えれば、インターネット生産方法全体からすべての車のインテリジェントコックピットまで、大型モデルを技術基盤とし、何千もの産業を牽引する自己革新の時代が来ています。蒸気時代と電気時代の命名方法によれば、「モジュラーフォース時代」と名付けられる場合がある。「モリ時代」において、最も懸念されるシナリオの1つは**スマート端末**です。理由は簡単で、スマートフォン、PC、スマートカー、さらにはXRデバイスに代表されるスマート端末産業は、現代人の生活に最も密接に関連するテクノロジー産業の1つであり、当然、最先端技術の成熟度をテストするためのゴールドスタンダードになっています。したがって、スマート端末のシナリオをアンカーとして、テクノロジーブームによってもたらされた誇大宣伝の最初の波が徐々に落ち着くとき、「モジュラーパワー時代」の新しい機会と課題をどのように見て解釈する必要がありますか?さて、それを砕いてこねて梳く時が来ました。 ## **スマートターミナル、ビッグモデル新戦場** 課題と機会を詳細に分析する前に、本質的な質問に戻りましょう:なぜ大規模なモデルで表される生成型AIはそれほど人気があり、「第4次産業革命」と見なされているのでしょうか。この現象に対応して、多くの機関が、Sequoia Capitalの「ジェネレーティブAI:創造的な新世界」など、さまざまなシナリオで生成AIの開発を予測または要約しようとする研究を行っています。その中で、業界の多くの大手企業は、独自の経験に基づいて、特定の業界におけるジェネレーティブAIの着陸シナリオと潜在的な変化の方向性を分析しています。たとえば、端末側のAIはクアルコムのプレーヤーを表しており、少し前に生成型AIの開発状況と傾向に関するホワイトペーパー「ハイブリッドAIはAIの未来」をリリースしました。このことから、ジェネレーティブAIが業界で人気がある3つの主な理由を解釈できるかもしれません。まず第一に、技術自体は十分に難しいです。インテリジェントに出現する大きなモデルであろうと、偽の品質で偽の品質を生成するAIペイントであろうと、効果を使用して話すことがすべてであり、テキスト、画像、ビデオ、自動化に関連する実際の作業領域であり、従来のワークフローを混乱させる驚くべき能力を示しています。第二に、豊富な潜在的な着陸シナリオがあります。 ビッグモデルによってもたらされたAIの世代間のブレークスルーは、最初から人々に無限の想像力をもたらしました:経験豊富な初期のバッチは、ジェネレーティブAIが機能する利点をすぐに認識しました。ユーザー側の大きな需要は、ChatGPTなどの代表的なアプリケーションのユーザー成長率から見ることができます。######**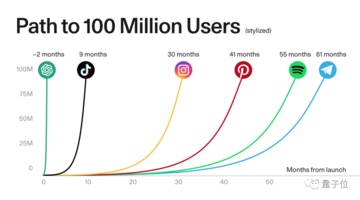 **#### **△**ChatGPTは、人気のあるアプリケーションの1億人以上の登録ユーザーの記録を破りました、ソースSequoia Capitalは最初のインターネット検索、プログラミング、オフィスから、文化観光、法律、医学、産業、輸送、その他のシーンアプリケーションの出現まで、生成AIの風に乗って、基本的な大規模モデルを提供できる企業をはるかに超えていますが、多数の新興企業が繁栄し、成長しています。多くの業界専門家は、起業家にとって、大規模なモデルによってもたらされるアプリケーション層にはより大きな機会があると信じています。下部には世代の技術革新があり、上部にはアプリケーション需要の活発な爆発があり、**生態学的効果**が刺激されます。ブルームバーグインテリジェンスの予測によると、ジェネレーティブAI市場は2032年までに400億ドルから1.3兆ドル**に爆発し、インフラストラクチャ、基本モデル、開発者ツール、アプリケーション製品、端末製品など、エコロジカルチェーンの幅広い参加者をカバーします。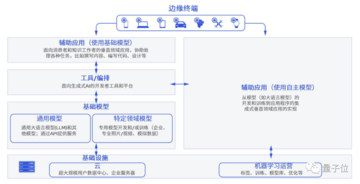 このエコロジカルチェーンの形成は、業界の新たな変化を促進し、AIをさらに基礎となるコア生産性にすることが期待されています。このような背景を踏まえて、今日のスマート業界で何が起こっているのかを見てみましょう。一方では、大規模なモデルに代表されるAIGCアプリケーションの嵐は、日々の反復リズムでクラウドからターミナルまで急速に**発生します。ChatGPTは、モバイル端末の「視聴覚トーク」のマルチモーダル機能を最初に更新し、ユーザーは写真を撮ってアップロードしたり、写真の内容についてChatGPTと話したりできます。たとえば、「自転車のシートの高さを調整する方法」:######** **#### **△**とGPT-4グラフィックダイアログ、数秒で5つの提案を与えるクアルコムはまた、端末側で10億を超えるパラメータを実行する安定した拡散とControlNetの大規模なモデルを迅速に実現し、携帯電話で高品質のAI画像を生成するのに12秒以上しかかかりません。多くの携帯電話メーカーも、音声アシスタント用の大型モデルの「頭脳」をインストールすることを発表しました。そして、それは電話だけではありません。上海モーターショー、成都モーターショー、ミュンヘンモーターショーなどの国内外の大規模な展示会では、基本モデルメーカーと自動車メーカーの協力がますます一般的になり、大型モデルの「車に乗る」はインテリジェントコックピットの分野で新しい競争ポイントになっています。######** **###### **△**一文で車のモデルにAPPで材料を購入させることができ、家に帰ったときに料理することができます一方、**アプリケーションの発生は、計算能力が不足している状況を悪化させています。 **毎日のアクティブユーザー数とその使用頻度の増加に伴い、モデルの推論コストが増加することが予想され、クラウドコンピューティングパワーのみに依存するだけでは、生成AIの規模を迅速に推進することはできません。これは、すべての人生の歩みが端末側のAIコンピューティング能力への注目を高めているという事実からもわかります。たとえば、端末側のAIプレーヤーであるクアルコムは、クアルコムの自社開発のOryon CPUを使用して、PCチップのパフォーマンスを向上させるための新世代のPCコンピューティングプラットフォームをリリースし、特にそれを搭載したNPUは、Snapdragon Xシリーズプラットフォームと呼ばれる生成AIにより強力なパフォーマンスを提供します。この新しいコンピューティングプラットフォームは、2023年のSnapdragonサミットでリリースされる予定です。明らかに、アプリケーションまたは計算能力の観点から、スマート端末はAIGCの最大の着陸の可能性を秘めたシナリオの1つになっています。 ## **AIGCリーフアンダータイド** 多くの場合、物事には2つの側面があり、急速な開発から着陸までの大きなモデルも同様です。ジェネレーティブAIが今日まで急上昇したとき、インテリジェント端末業界の大きな可能性の下での本当のボトルネックが表面化しました。**最大の制約の1つは、最低レベルのハードウェアです。 **Sequoiaの投資家であるSonya Huang氏とPat Grady氏が最新のジェネレーティブAI分析記事「Generative AI's Act Two」で言及したように、AIGCは急速に成長していますが、予想されるボトルネックは顧客の需要ではなく、供給側のコンピューティングパワーです。ここでの計算能力は、主にAIおよび機械学習ハードウェアアクセラレータを指し、展開シナリオの観点から5つのカテゴリに分類できます。データセンタークラスのシステム、サーバーレベルのアクセラレータ、運転支援および自動運転シナリオ用のアクセラレータ、エッジコンピューティング、および超低消費電力アクセラレータ。######**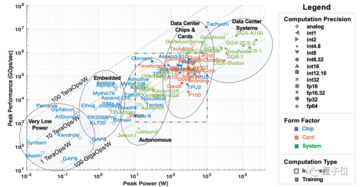 **###### **△**5種類のAIアクセラレータ、出典:MIT論文「AIとMLアクセラレータの調査と動向」ChatGPTの爆発的な増加により、大型モデルはAIGCを驚異的に追い出し、データセンターやサーバーレベルのプロセッサなどの「**クラウドコンピューティングパワー**」が短期的には大きな注目を集め、供給不足の状況でさえあります。しかし、ジェネレーティブAIが第2段階に入るにつれて、計算能力に関するいくつかの質問がますます顕著になっています。**最初の最大の問題はコストです。 **クアルコムの「ハイブリッドAIはAIの未来」ホワイトペーパーに記載されているように、半年以上が経過し、大規模モデルがテクノロジーの追跡からアプリケーションランディングに移行するにつれて、各社の基本モデル**トレーニング**は徐々に落ち着き、計算能力のほとんどは大規模モデルの**推論**に落ちています。短期的には、推論コストは許容範囲ですが、大規模なモデル用のアプリやアプリケーションシナリオが増えるにつれて、サーバーなどのアクセラレータでの推論のコストが急激に増加し、最終的には大規模なモデル自体をトレーニングするよりも大規模なモデルを呼び出すコストが高くなります。つまり、大規模モデルが第2段階に入った後、推論のための計算能力に対する長期的な需要は、単一のトレーニングよりもはるかに高く、データセンターとサーバーレベルのプロセッサで構成される「クラウドコンピューティング能力」のみに依存することは、ユーザーが許容できるコストに推論を打つには完全に不十分です。ホワイトペーパーのクアルコムの統計によると、大規模なモデルを使用した検索エンジンを例にとると、各検索クエリのコストは従来の方法の10倍に達する可能性があり、この領域だけでも年間コストは数十億ドル増加する可能性があります。これは、大型モデルの着陸に対する重要な制約になる運命にあります。**それに加えて、遅延、プライバシー、およびパーソナライズの問題があります。 **クアルコムはまた、「ハイブリッドAIはAIの未来」で、大規模なモデルがクラウドに直接展開されていること、ユーザーの急増によるサーバーコンピューティングの不足、「使用のためにキューに入れる」必要性などのバグに加えて、ユーザーのプライバシーとパーソナライズの問題を解決することもバインドされています。ユーザーがクラウドにデータをアップロードしたくない場合、オフィスやインテリジェントアシスタントなどの大規模なモデルの使用シナリオには多くの制限があり、これらのシナリオのほとんどは端末側に分散されます。 大規模モデルを自分用にカスタマイズするなど、さらに成果を追求する必要がある場合は、大規模モデルの学習に個人情報を直接活用する必要があります。さまざまな要因の下で、推論に役割を果たすことができる「端末計算能力」、つまり自動運転と支援運転、エッジコンピューティング(組み込み)、超低消費電力アクセラレータを含むいくつかのタイプのプロセッサが人々の視野に入り始めています。端末には巨大な計算能力があります。 IDCの予測によると、世界のIoTデバイスの数は2025年までに400億を超え、80ゼタバイト近くのデータを生成し、データの半分以上が処理を端末またはエッジの計算能力に依存する必要があります。ただし、端末には消費電力や熱放散が制限されるなどの問題もあり、計算能力が制限されます。この場合、端末に隠された巨大な計算能力を使用して、クラウド計算能力の開発が直面するボトルネックをどのように突破するかが、「モジュラー電力時代」で最も一般的な技術的問題の1つになりつつあります。**言うまでもなく、大規模なモデルの実装は、計算能力に加えて、アルゴリズム、データ、市場競争などの課題にも直面しています。 **アルゴリズムの場合、基になるモデルのアーキテクチャはまだ不明です。 ChatGPTは良い結果を達成しましたが、その技術的なルートは次世代モデルのアーキテクチャの方向性ではありません。データについては、他社がChatGPTの大きなモデル成果を出すためには高品質なデータが不可欠ですが、ジェネレーティブAIのAct Twoでは、アプリケーション企業が生成したデータは実際には障壁を作らないことも指摘しています。データによって構築された利点は脆弱で持続不可能であり、次世代の基本モデルはこの「壁」を直接破壊する可能性があり、対照的に、継続的で安定したユーザーは真にデータソースを構築できます。市場では、現在、大型モデル製品のキラーアプリケーションはなく、どのようなシナリオに適しているかはまだ不明です。どのような製品に使用され、どのアプリケーションが最大の価値を発揮できるのかという時代において、市場はまだ従うことができる一連の方法論や標準的な答えを与えていません。 **この一連の問題に対して、現在、業界の問題を解決するには、主に2つの方法があります。 **1つは、モデルの「本質」を変更することなく、大規模なモデル自体のアルゴリズムを改善し、そのサイズを改善し、より多くのデバイスでの展開能力を強化することです。Transformerアルゴリズムを例にとると、このようなパラメータ数の多いモデルをエンドサイドで実行する場合は構造内で調整する必要があるため、この間にMobileViTなどの軽量アルゴリズムが多数誕生しました。これらのアルゴリズムは、出力効果に影響を与えることなくパラメーターの構造と量を改善し、より小さなモデルでより多くのデバイスで実行できるようにします。もう一つは、ハードウェア自体のAI計算能力を向上させ、大型モデルがエンドサイドにうまく着地できるようにすることです。このような方法には、ハードウェアコンピューティングのパフォーマンスとさまざまなデバイス上のモデルの汎用性を向上させ、大きなモデルがエンドサイドに着陸する可能性を高めるために使用されるハードウェアおよび開発ソフトウェアスタック上のマルチコア設計が含まれます。前者はソフトのハードウェアへの適応、後者はハードウェアメーカーが時代の潮流の変化に適応することといえます。 しかし、どちらの方向でも、賭けだけで追い抜かれるリスクがあります。 **「モジュラーパワーの時代」の下では、技術は日を追うごとに変化しており、ソフトウェアとハ ードウェアのどちらの側からも新しいブレークスルーが現れ、必要な技術的予備力が不足すると、それらは遅れをとる可能性があります。では、私たちは盲目的にフォローアップする必要がありますか、それとも単にこのテクノロジーの波の開発を見逃すべきですか? いやそうではありません。**インターネットやAI時代に自らの価値を見出した企業にとっては、独自のシナリオや技術の蓄積から、AIGC時代の第3のソリューションアイデアを模索できるかもしれません。 **例として、ソフトウェアとハ ードウェアの両方のテクノロジーを備えたAI企業であるクアルコムを取り上げます。さまざまなシナリオでの大規模モデル技術の課題に直面したクアルコムは、チップ会社のアイデンティティから飛び出し、AIGCの波を早期に受け入れました。クアルコムは、端末側チップのAIコンピューティング能力を継続的に改善することに加えて、基本的なAIテクノロジーも開発しており、インテリジェント端末業界全体の速度を加速して、AIGCをイネーブリングエンタープライズとして受け入れるよう努めています。ただし、このアプローチにはさまざまな予測可能な困難もあります。より大規模で複雑なAIモデルの場合、端末でスムーズに実行しながらパフォーマンスを確保するにはどうすればよいでしょうか。端末とクラウドの間でコンピューティングパワーを最適に割り当てるために、異なるモデルを使用する場合端末側に大型モデルをデプロイする問題が解決したとしても、どの部分をクラウドにデプロイし、どのパーツをターミナルにデプロイすべきか、そしてラージモデルの異なる部分間の接続や機能に影響を与えないようにするにはどうすればよいでしょうか。端末側の性能優位性が不十分な場合、どのように解決しますか?......これらの問題は単一のケースに現れるのではなく、AIGCの影響を受けるすべての業界またはシナリオにすでに存在します。それがゲームを壊す方法であろうと実際の着陸体験であろうと、答えは特定のシナリオと業界の事例からのみ探求することができます。 ## **「モジュラーパワー時代」の霧を断ち切る方法は? ** AIGCは第2段階に入り、大型モデルの人気が高まり、業界は着陸する方法を模索し始めています。**クアルコムの「ハイブリッドAIはAIの未来」ホワイトペーパーでは、スマートフォンやPCを例にとると、新しい戦場のインテリジェント端末業界でAIGCの着陸シナリオが数多くあると述べられています。 **企業はすでに、メッセージの検索、返信メッセージの生成、カレンダーイベントの変更、ワンクリックナビゲーションなど、よりパーソナライズされた問題のために、より小さく、より大きなモデルを端末側に展開しています。例えば、大規模モデルに基づいて、「お気に入りのレストランの座席を予約する」は、お気に入りのレストランと空きスケジュールのユーザーデータ分析に従って、スケジュールの推奨事項を提供し、結果をカレンダーに追加します。クアルコムは、端末によって展開される大規模なモデルパラメータの量が限られており、ネットワークが不足しているため、応答時に「AI錯覚」が発生する可能性があり、大規模なモデルに上記の問題を防ぐための情報が不足している場合にガードレールを設定するオーケストレーターテクノロジーに基づくことができると考えています。大規模なモデルによって生成されたコンテンツに満足できない場合は、ワンクリックで実行するためにクラウドに質問を送信し、大規模なモデルの生成結果を端末側により良い回答でフィードバックすることもできます。このようにして、クラウドで実行されている大規模なモデルの計算能力のプレッシャーを軽減するだけでなく、ユーザーのプライバシーを最大限に保護しながら、大規模なモデルをパーソナライズできるようにすることもできます。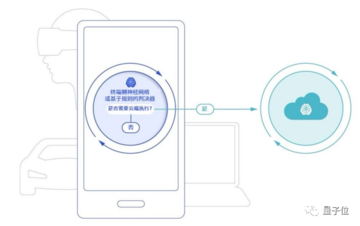 **端末の計算能力やアルゴリズムなど、突破する必要のある技術的なボトルネックについては、一部のプレーヤーはいくつかの「ゲームを破る方法」も開発しています。 **ホワイトペーパーでは、クアルコムは、少し前に火事になった投機的デコードなど、ホワイトペーパーで広く使用されている新しいテクノロジーのクラスを紹介しました。これは、GoogleとDeepMindが同時に発見した手法で、大規模モデルの推論を高速化し、小型の大規模モデルを適用して大規模モデルの生成を高速化することができます。簡単に言えば、大きなモデルに自分で「考えて」生成させ、直接「選択」するのではなく、小さなモデルを訓練し、大きなモデルの「候補単語」のバッチを事前に生成することです。小さなモデルの生成速度は大きなモデルの数倍速いため、大きなモデルがすでに持っている単語が利用可能であると感じたら、自分でゆっくりと生成することなく直接取ることができます。この方法は、主に、大規模モデルの推論速度が計算量の増加よりもメモリ帯域幅の影響を受けることを利用している。パラメーターの数が膨大で、キャッシュ容量をはるかに超えているため、大規模なモデルは、推論中のコンピューティング ハードウェア パフォーマンスよりもメモリ帯域幅によって制限される可能性が高くなります。 たとえば、GPT-3はワードを生成するたびに1,750億個のパラメータをすべて読み取る必要があり、DRAMからのメモリデータを待っている間、コンピューティングハードウェアはアイドル状態になることがよくあります。つまり、モデルがバッチ推論を行う場合、一度に 100 個のトークンと 1 つのトークンを処理する時間差はほとんどありません。したがって、投機的サンプリングを使用すると、数百億のパラメータを持つ大規模なモデルを簡単に実行できるだけでなく、計算能力の一部を端末側に置き、大規模なモデルの生成効果を維持しながら推論速度を確保できます。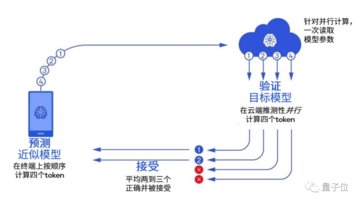 ......しかし、それがシナリオであろうとテクノロジーであろうと、ソフトウェアとハードウェアの関係が不可分であるように、最終的には、実質的なアプリケーション価値を生み出すために、お互いの適応ポイントを見つける必要があります**。スマートターミナルの着陸シナリオを探すとき、生成AIなどのソフトウェアアルゴリズムのブレークスルーは、必然的にクアルコムなどのモバイルAIハードウェアと組み合わせた技術的要件に直面するでしょう。スマートフォン、PC、XR、自動車、モノのインターネットなど、スマート端末業界のさまざまなセグメントがAIGCホットスポットに基づいて独自の遊びと価値をどのように見つけることができるでしょうか。企業はどのようにしてこの時代の波を捉えて、このタイプのテクノロジーのアプリケーション価値を刺激し、業界全体の生産性変革の機会を逃さないことができるでしょうか。
10年の市場規模は1.3兆米ドルで、モジュラーパワーの時代が到来しました
元のソース: 量子ビット
ビッグモデルの嵐が一年のほとんどの間吹き荒れ、AIGC市場は再び変化し始めました。
クールな技術デモは、完全な製品体験に置き換えられています。 **
たとえば、OpenAIの最新AIペイントモデルDALL· E 3がデビューするとすぐに、ChatGPTと力を合わせて、ChatGPT Plusで最も期待されている新しい生産性ツールになりました。
** **###### △ダル· E3はテキスト入力の細部を正確に再現します
**###### △ダル· E3はテキスト入力の細部を正確に再現します
たとえば、GPT-4に基づくマイクロソフトのコパイロットはWindows 11で完全に解決され、オペレーティングシステムの新世代のAIアシスタントとしてCortanaに正式に取って代わりました。
** **###### △ Copilotを使用して、ワンクリックでブログ投稿を要約します
**###### △ Copilotを使用して、ワンクリックでブログ投稿を要約します
別の例として、Jiyue 01などの国産車はコックピットに大型モデルを正式に装備しており、完全にオフラインになっています...
2023年3月の「ビッグモデルがすべてを再形成する」ことがテクノロジーパイオニアの楽観的な予測にすぎなかった場合、今日、依然として激しい100モデルの戦争と実用化の進歩により、この見解は業界の内外でますます共鳴しています。
言い換えれば、インターネット生産方法全体からすべての車のインテリジェントコックピットまで、大型モデルを技術基盤とし、何千もの産業を牽引する自己革新の時代が来ています。
蒸気時代と電気時代の命名方法によれば、「モジュラーフォース時代」と名付けられる場合がある。
「モリ時代」において、最も懸念されるシナリオの1つはスマート端末です。
理由は簡単で、スマートフォン、PC、スマートカー、さらにはXRデバイスに代表されるスマート端末産業は、現代人の生活に最も密接に関連するテクノロジー産業の1つであり、当然、最先端技術の成熟度をテストするためのゴールドスタンダードになっています。
したがって、スマート端末のシナリオをアンカーとして、テクノロジーブームによってもたらされた誇大宣伝の最初の波が徐々に落ち着くとき、「モジュラーパワー時代」の新しい機会と課題をどのように見て解釈する必要がありますか?
さて、それを砕いてこねて梳く時が来ました。
スマートターミナル、ビッグモデル新戦場
課題と機会を詳細に分析する前に、本質的な質問に戻りましょう:なぜ大規模なモデルで表される生成型AIはそれほど人気があり、「第4次産業革命」と見なされているのでしょうか。
この現象に対応して、多くの機関が、Sequoia Capitalの「ジェネレーティブAI:創造的な新世界」など、さまざまなシナリオで生成AIの開発を予測または要約しようとする研究を行っています。
その中で、業界の多くの大手企業は、独自の経験に基づいて、特定の業界におけるジェネレーティブAIの着陸シナリオと潜在的な変化の方向性を分析しています。
たとえば、端末側のAIはクアルコムのプレーヤーを表しており、少し前に生成型AIの開発状況と傾向に関するホワイトペーパー「ハイブリッドAIはAIの未来」をリリースしました。
このことから、ジェネレーティブAIが業界で人気がある3つの主な理由を解釈できるかもしれません。
まず第一に、技術自体は十分に難しいです。
インテリジェントに出現する大きなモデルであろうと、偽の品質で偽の品質を生成するAIペイントであろうと、効果を使用して話すことがすべてであり、テキスト、画像、ビデオ、自動化に関連する実際の作業領域であり、従来のワークフローを混乱させる驚くべき能力を示しています。
第二に、豊富な潜在的な着陸シナリオがあります。 ビッグモデルによってもたらされたAIの世代間のブレークスルーは、最初から人々に無限の想像力をもたらしました:経験豊富な初期のバッチは、ジェネレーティブAIが機能する利点をすぐに認識しました。
ユーザー側の大きな需要は、ChatGPTなどの代表的なアプリケーションのユーザー成長率から見ることができます。
**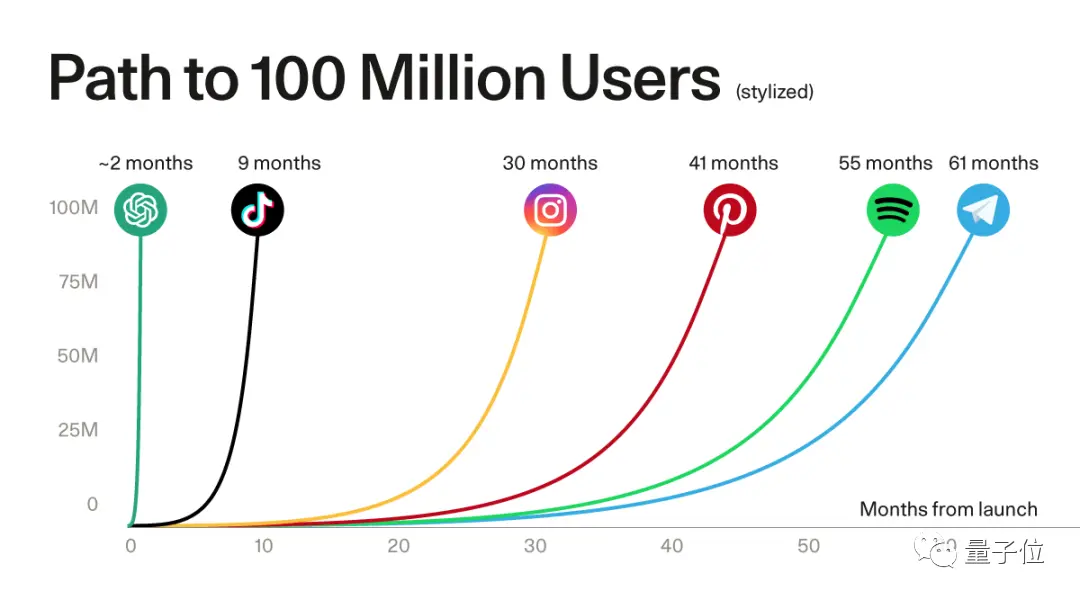 **#### △ChatGPTは、人気のあるアプリケーションの1億人以上の登録ユーザーの記録を破りました、ソースSequoia Capitalは
**#### △ChatGPTは、人気のあるアプリケーションの1億人以上の登録ユーザーの記録を破りました、ソースSequoia Capitalは
最初のインターネット検索、プログラミング、オフィスから、文化観光、法律、医学、産業、輸送、その他のシーンアプリケーションの出現まで、生成AIの風に乗って、基本的な大規模モデルを提供できる企業をはるかに超えていますが、多数の新興企業が繁栄し、成長しています。
多くの業界専門家は、起業家にとって、大規模なモデルによってもたらされるアプリケーション層にはより大きな機会があると信じています。
下部には世代の技術革新があり、上部にはアプリケーション需要の活発な爆発があり、生態学的効果が刺激されます。
ブルームバーグインテリジェンスの予測によると、ジェネレーティブAI市場は2032年までに400億ドルから1.3兆ドル**に爆発し、インフラストラクチャ、基本モデル、開発者ツール、アプリケーション製品、端末製品など、エコロジカルチェーンの幅広い参加者をカバーします。
このような背景を踏まえて、今日のスマート業界で何が起こっているのかを見てみましょう。
一方では、大規模なモデルに代表されるAIGCアプリケーションの嵐は、日々の反復リズムでクラウドからターミナルまで急速に**発生します。
ChatGPTは、モバイル端末の「視聴覚トーク」のマルチモーダル機能を最初に更新し、ユーザーは写真を撮ってアップロードしたり、写真の内容についてChatGPTと話したりできます。
たとえば、「自転車のシートの高さを調整する方法」:
**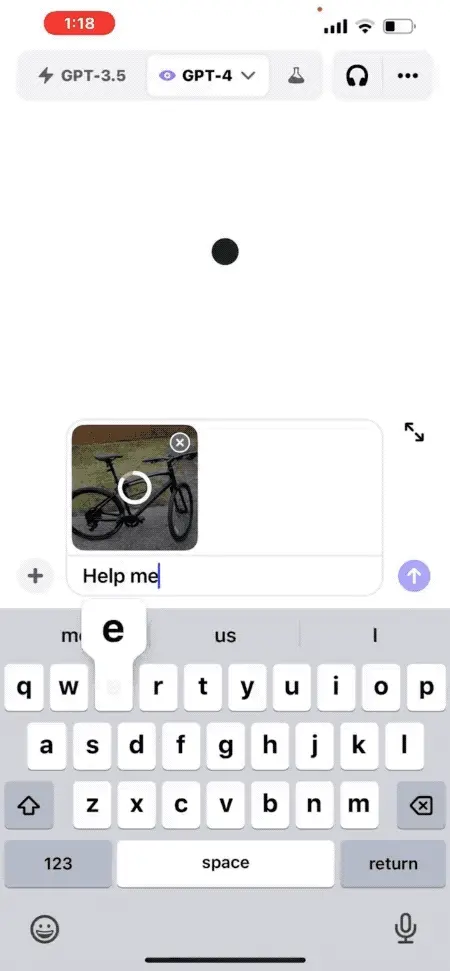 **#### △とGPT-4グラフィックダイアログ、数秒で5つの提案を与える
**#### △とGPT-4グラフィックダイアログ、数秒で5つの提案を与える
クアルコムはまた、端末側で10億を超えるパラメータを実行する安定した拡散とControlNetの大規模なモデルを迅速に実現し、携帯電話で高品質のAI画像を生成するのに12秒以上しかかかりません。
多くの携帯電話メーカーも、音声アシスタント用の大型モデルの「頭脳」をインストールすることを発表しました。
そして、それは電話だけではありません。
上海モーターショー、成都モーターショー、ミュンヘンモーターショーなどの国内外の大規模な展示会では、基本モデルメーカーと自動車メーカーの協力がますます一般的になり、大型モデルの「車に乗る」はインテリジェントコックピットの分野で新しい競争ポイントになっています。
**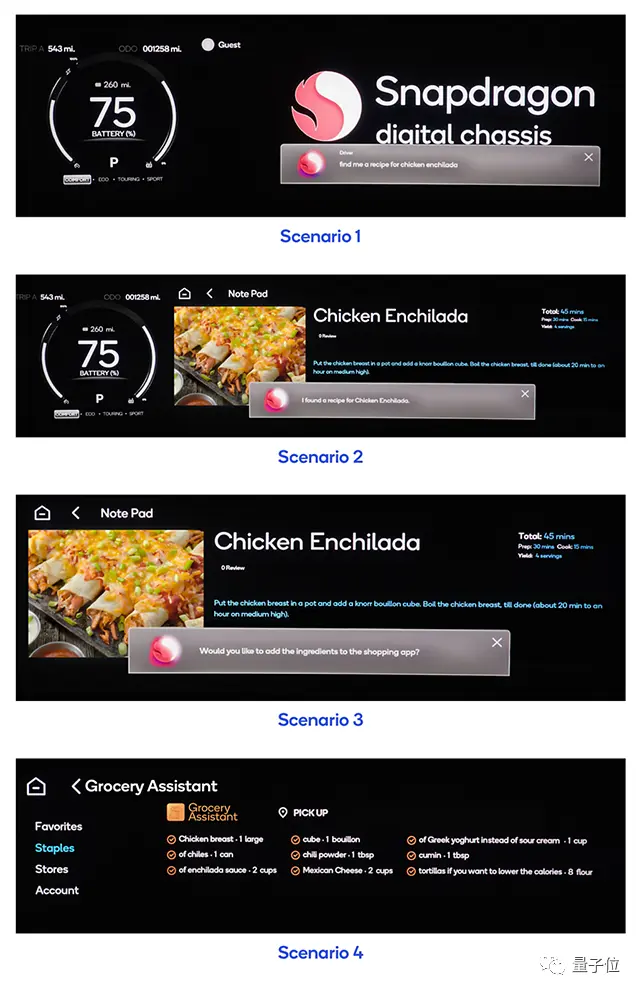 **###### △一文で車のモデルにAPPで材料を購入させることができ、家に帰ったときに料理することができます
**###### △一文で車のモデルにAPPで材料を購入させることができ、家に帰ったときに料理することができます
一方、**アプリケーションの発生は、計算能力が不足している状況を悪化させています。 **
毎日のアクティブユーザー数とその使用頻度の増加に伴い、モデルの推論コストが増加することが予想され、クラウドコンピューティングパワーのみに依存するだけでは、生成AIの規模を迅速に推進することはできません。
これは、すべての人生の歩みが端末側のAIコンピューティング能力への注目を高めているという事実からもわかります。
たとえば、端末側のAIプレーヤーであるクアルコムは、クアルコムの自社開発のOryon CPUを使用して、PCチップのパフォーマンスを向上させるための新世代のPCコンピューティングプラットフォームをリリースし、特にそれを搭載したNPUは、Snapdragon Xシリーズプラットフォームと呼ばれる生成AIにより強力なパフォーマンスを提供します。
この新しいコンピューティングプラットフォームは、2023年のSnapdragonサミットでリリースされる予定です。
明らかに、アプリケーションまたは計算能力の観点から、スマート端末はAIGCの最大の着陸の可能性を秘めたシナリオの1つになっています。
AIGCリーフアンダータイド
多くの場合、物事には2つの側面があり、急速な開発から着陸までの大きなモデルも同様です。
ジェネレーティブAIが今日まで急上昇したとき、インテリジェント端末業界の大きな可能性の下での本当のボトルネックが表面化しました。
**最大の制約の1つは、最低レベルのハードウェアです。 **
Sequoiaの投資家であるSonya Huang氏とPat Grady氏が最新のジェネレーティブAI分析記事「Generative AI's Act Two」で言及したように、AIGCは急速に成長していますが、予想されるボトルネックは顧客の需要ではなく、供給側のコンピューティングパワーです。
ここでの計算能力は、主にAIおよび機械学習ハードウェアアクセラレータを指し、展開シナリオの観点から5つのカテゴリに分類できます。
データセンタークラスのシステム、サーバーレベルのアクセラレータ、運転支援および自動運転シナリオ用のアクセラレータ、エッジコンピューティング、および超低消費電力アクセラレータ。
**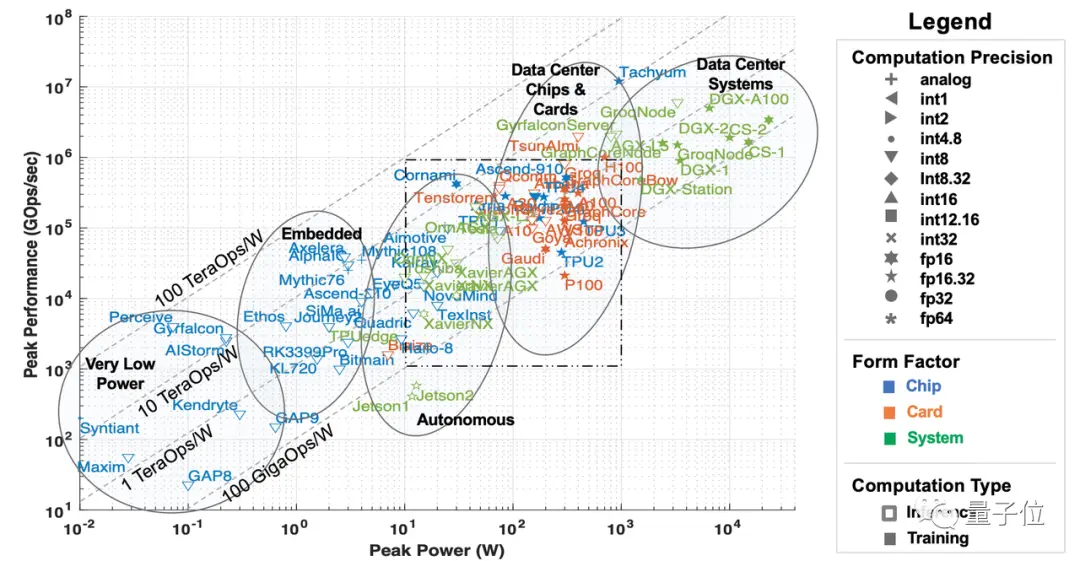 **###### △5種類のAIアクセラレータ、出典:MIT論文「AIとMLアクセラレータの調査と動向」
**###### △5種類のAIアクセラレータ、出典:MIT論文「AIとMLアクセラレータの調査と動向」
ChatGPTの爆発的な増加により、大型モデルはAIGCを驚異的に追い出し、データセンターやサーバーレベルのプロセッサなどの「クラウドコンピューティングパワー」が短期的には大きな注目を集め、供給不足の状況でさえあります。
しかし、ジェネレーティブAIが第2段階に入るにつれて、計算能力に関するいくつかの質問がますます顕著になっています。
最初の最大の問題はコストです。 クアルコムの「ハイブリッドAIはAIの未来」ホワイトペーパーに記載されているように、半年以上が経過し、大規模モデルがテクノロジーの追跡からアプリケーションランディングに移行するにつれて、各社の基本モデルトレーニングは徐々に落ち着き、計算能力のほとんどは大規模モデルの推論に落ちています。
短期的には、推論コストは許容範囲ですが、大規模なモデル用のアプリやアプリケーションシナリオが増えるにつれて、サーバーなどのアクセラレータでの推論のコストが急激に増加し、最終的には大規模なモデル自体をトレーニングするよりも大規模なモデルを呼び出すコストが高くなります。
つまり、大規模モデルが第2段階に入った後、推論のための計算能力に対する長期的な需要は、単一のトレーニングよりもはるかに高く、データセンターとサーバーレベルのプロセッサで構成される「クラウドコンピューティング能力」のみに依存することは、ユーザーが許容できるコストに推論を打つには完全に不十分です。
ホワイトペーパーのクアルコムの統計によると、大規模なモデルを使用した検索エンジンを例にとると、各検索クエリのコストは従来の方法の10倍に達する可能性があり、この領域だけでも年間コストは数十億ドル増加する可能性があります。
これは、大型モデルの着陸に対する重要な制約になる運命にあります。
**それに加えて、遅延、プライバシー、およびパーソナライズの問題があります。 **クアルコムはまた、「ハイブリッドAIはAIの未来」で、大規模なモデルがクラウドに直接展開されていること、ユーザーの急増によるサーバーコンピューティングの不足、「使用のためにキューに入れる」必要性などのバグに加えて、ユーザーのプライバシーとパーソナライズの問題を解決することもバインドされています。
ユーザーがクラウドにデータをアップロードしたくない場合、オフィスやインテリジェントアシスタントなどの大規模なモデルの使用シナリオには多くの制限があり、これらのシナリオのほとんどは端末側に分散されます。 大規模モデルを自分用にカスタマイズするなど、さらに成果を追求する必要がある場合は、大規模モデルの学習に個人情報を直接活用する必要があります。
さまざまな要因の下で、推論に役割を果たすことができる「端末計算能力」、つまり自動運転と支援運転、エッジコンピューティング(組み込み)、超低消費電力アクセラレータを含むいくつかのタイプのプロセッサが人々の視野に入り始めています。
端末には巨大な計算能力があります。 IDCの予測によると、世界のIoTデバイスの数は2025年までに400億を超え、80ゼタバイト近くのデータを生成し、データの半分以上が処理を端末またはエッジの計算能力に依存する必要があります。
ただし、端末には消費電力や熱放散が制限されるなどの問題もあり、計算能力が制限されます。
この場合、端末に隠された巨大な計算能力を使用して、クラウド計算能力の開発が直面するボトルネックをどのように突破するかが、「モジュラー電力時代」で最も一般的な技術的問題の1つになりつつあります。
**言うまでもなく、大規模なモデルの実装は、計算能力に加えて、アルゴリズム、データ、市場競争などの課題にも直面しています。 **
アルゴリズムの場合、基になるモデルのアーキテクチャはまだ不明です。 ChatGPTは良い結果を達成しましたが、その技術的なルートは次世代モデルのアーキテクチャの方向性ではありません。
データについては、他社がChatGPTの大きなモデル成果を出すためには高品質なデータが不可欠ですが、ジェネレーティブAIのAct Twoでは、アプリケーション企業が生成したデータは実際には障壁を作らないことも指摘しています。
データによって構築された利点は脆弱で持続不可能であり、次世代の基本モデルはこの「壁」を直接破壊する可能性があり、対照的に、継続的で安定したユーザーは真にデータソースを構築できます。
市場では、現在、大型モデル製品のキラーアプリケーションはなく、どのようなシナリオに適しているかはまだ不明です。
どのような製品に使用され、どのアプリケーションが最大の価値を発揮できるのかという時代において、市場はまだ従うことができる一連の方法論や標準的な答えを与えていません。
1つは、モデルの「本質」を変更することなく、大規模なモデル自体のアルゴリズムを改善し、そのサイズを改善し、より多くのデバイスでの展開能力を強化することです。
Transformerアルゴリズムを例にとると、このようなパラメータ数の多いモデルをエンドサイドで実行する場合は構造内で調整する必要があるため、この間にMobileViTなどの軽量アルゴリズムが多数誕生しました。
これらのアルゴリズムは、出力効果に影響を与えることなくパラメーターの構造と量を改善し、より小さなモデルでより多くのデバイスで実行できるようにします。
もう一つは、ハードウェア自体のAI計算能力を向上させ、大型モデルがエンドサイドにうまく着地できるようにすることです。
このような方法には、ハードウェアコンピューティングのパフォーマンスとさまざまなデバイス上のモデルの汎用性を向上させ、大きなモデルがエンドサイドに着陸する可能性を高めるために使用されるハードウェアおよび開発ソフトウェアスタック上のマルチコア設計が含まれます。
前者はソフトのハードウェアへの適応、後者はハードウェアメーカーが時代の潮流の変化に適応することといえます。 しかし、どちらの方向でも、賭けだけで追い抜かれるリスクがあります。 **
「モジュラーパワーの時代」の下では、技術は日を追うごとに変化しており、ソフトウェアとハ ードウェアのどちらの側からも新しいブレークスルーが現れ、必要な技術的予備力が不足すると、それらは遅れをとる可能性があります。
では、私たちは盲目的にフォローアップする必要がありますか、それとも単にこのテクノロジーの波の開発を見逃すべきですか? いやそうではありません。
**インターネットやAI時代に自らの価値を見出した企業にとっては、独自のシナリオや技術の蓄積から、AIGC時代の第3のソリューションアイデアを模索できるかもしれません。 **
例として、ソフトウェアとハ ードウェアの両方のテクノロジーを備えたAI企業であるクアルコムを取り上げます。
さまざまなシナリオでの大規模モデル技術の課題に直面したクアルコムは、チップ会社のアイデンティティから飛び出し、AIGCの波を早期に受け入れました。
クアルコムは、端末側チップのAIコンピューティング能力を継続的に改善することに加えて、基本的なAIテクノロジーも開発しており、インテリジェント端末業界全体の速度を加速して、AIGCをイネーブリングエンタープライズとして受け入れるよう努めています。
ただし、このアプローチにはさまざまな予測可能な困難もあります。
より大規模で複雑なAIモデルの場合、端末でスムーズに実行しながらパフォーマンスを確保するにはどうすればよいでしょうか。
端末とクラウドの間でコンピューティングパワーを最適に割り当てるために、異なるモデルを使用する場合
端末側に大型モデルをデプロイする問題が解決したとしても、どの部分をクラウドにデプロイし、どのパーツをターミナルにデプロイすべきか、そしてラージモデルの異なる部分間の接続や機能に影響を与えないようにするにはどうすればよいでしょうか。
端末側の性能優位性が不十分な場合、どのように解決しますか?
......
これらの問題は単一のケースに現れるのではなく、AIGCの影響を受けるすべての業界またはシナリオにすでに存在します。
それがゲームを壊す方法であろうと実際の着陸体験であろうと、答えは特定のシナリオと業界の事例からのみ探求することができます。
**「モジュラーパワー時代」の霧を断ち切る方法は? **
AIGCは第2段階に入り、大型モデルの人気が高まり、業界は着陸する方法を模索し始めています。
**クアルコムの「ハイブリッドAIはAIの未来」ホワイトペーパーでは、スマートフォンやPCを例にとると、新しい戦場のインテリジェント端末業界でAIGCの着陸シナリオが数多くあると述べられています。 **
企業はすでに、メッセージの検索、返信メッセージの生成、カレンダーイベントの変更、ワンクリックナビゲーションなど、よりパーソナライズされた問題のために、より小さく、より大きなモデルを端末側に展開しています。
例えば、大規模モデルに基づいて、「お気に入りのレストランの座席を予約する」は、お気に入りのレストランと空きスケジュールのユーザーデータ分析に従って、スケジュールの推奨事項を提供し、結果をカレンダーに追加します。
クアルコムは、端末によって展開される大規模なモデルパラメータの量が限られており、ネットワークが不足しているため、応答時に「AI錯覚」が発生する可能性があり、大規模なモデルに上記の問題を防ぐための情報が不足している場合にガードレールを設定するオーケストレーターテクノロジーに基づくことができると考えています。
大規模なモデルによって生成されたコンテンツに満足できない場合は、ワンクリックで実行するためにクラウドに質問を送信し、大規模なモデルの生成結果を端末側により良い回答でフィードバックすることもできます。
このようにして、クラウドで実行されている大規模なモデルの計算能力のプレッシャーを軽減するだけでなく、ユーザーのプライバシーを最大限に保護しながら、大規模なモデルをパーソナライズできるようにすることもできます。
ホワイトペーパーでは、クアルコムは、少し前に火事になった投機的デコードなど、ホワイトペーパーで広く使用されている新しいテクノロジーのクラスを紹介しました。
これは、GoogleとDeepMindが同時に発見した手法で、大規模モデルの推論を高速化し、小型の大規模モデルを適用して大規模モデルの生成を高速化することができます。
簡単に言えば、大きなモデルに自分で「考えて」生成させ、直接「選択」するのではなく、小さなモデルを訓練し、大きなモデルの「候補単語」のバッチを事前に生成することです。
小さなモデルの生成速度は大きなモデルの数倍速いため、大きなモデルがすでに持っている単語が利用可能であると感じたら、自分でゆっくりと生成することなく直接取ることができます。
この方法は、主に、大規模モデルの推論速度が計算量の増加よりもメモリ帯域幅の影響を受けることを利用している。
パラメーターの数が膨大で、キャッシュ容量をはるかに超えているため、大規模なモデルは、推論中のコンピューティング ハードウェア パフォーマンスよりもメモリ帯域幅によって制限される可能性が高くなります。 たとえば、GPT-3はワードを生成するたびに1,750億個のパラメータをすべて読み取る必要があり、DRAMからのメモリデータを待っている間、コンピューティングハードウェアはアイドル状態になることがよくあります。
つまり、モデルがバッチ推論を行う場合、一度に 100 個のトークンと 1 つのトークンを処理する時間差はほとんどありません。
したがって、投機的サンプリングを使用すると、数百億のパラメータを持つ大規模なモデルを簡単に実行できるだけでなく、計算能力の一部を端末側に置き、大規模なモデルの生成効果を維持しながら推論速度を確保できます。
しかし、それがシナリオであろうとテクノロジーであろうと、ソフトウェアとハードウェアの関係が不可分であるように、最終的には、実質的なアプリケーション価値を生み出すために、お互いの適応ポイントを見つける必要があります**。
スマートターミナルの着陸シナリオを探すとき、生成AIなどのソフトウェアアルゴリズムのブレークスルーは、必然的にクアルコムなどのモバイルAIハードウェアと組み合わせた技術的要件に直面するでしょう。
スマートフォン、PC、XR、自動車、モノのインターネットなど、スマート端末業界のさまざまなセグメントがAIGCホットスポットに基づいて独自の遊びと価値をどのように見つけることができるでしょうか。
企業はどのようにしてこの時代の波を捉えて、このタイプのテクノロジーのアプリケーション価値を刺激し、業界全体の生産性変革の機会を逃さないことができるでしょうか。