原典:シン・ジユアン 画像ソース:無制限のAIによって生成AIマインドリーディングが終わった!?本日、LeCunはMeta AIの最新のブレークスルーを転送しました:AIは脳活動における画像知覚をリアルタイムでデコードすることができました!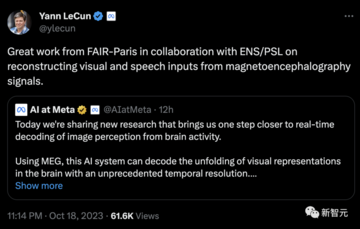 FAIR-Parisがエコール・デ・アーツ・エ・デ・アーツ・アンド・サイエンス(PSL)(ENS)と共同で行ったこの研究は、視覚および音声入力を再構築するための脳磁図(MEG)信号の使用における新しいマイルストーンです。 論文住所:Metaは、非侵襲的な神経イメージング技術である脳磁図(MEG)を使用して、毎秒数千回の脳活動スキャンをスキャンし、脳内の視覚表現をほぼリアルタイムでデコードできるAIシステムを開発しました。 このシステムはリアルタイムで展開でき、脳の活動に基づいて脳が各瞬間に知覚および処理する画像を再構築します。 間違いなく、この研究は、科学界が画像が脳内でどのように表現されているかを理解するのに役立つ前例のない新しい道を開き、人間の知性の他の側面にさらに光を当てます。長期的には、臨床現場での非侵襲的なブレインコンピュータインターフェースの基礎としても機能し、脳損傷を負った後に話す能力を失った人々が外界と通信するのに役立ちます。具体的には、画像エンコーダー、脳エンコーダー、画像デコーダーで構成されるシステムを開発しました。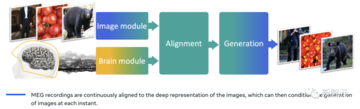 画像エンコーダーは、脳の外側で豊富な画像表現のセットを独立して構築します。 次に、脳エンコーダは、MEG信号を埋め込み、これらの構築された画像に合わせることを学習します。 最後に、画像デコーダは、これらの脳表現に基づいて信頼できる画像を生成する。Metaはまず、事前にトレーニングされたさまざまな画像モジュールのデコードパフォーマンスを比較し、脳信号がDINOv2などのコンピュータービジョンAIシステムと非常に一致していることを発見しました。この新知見は、自己教師あり学習によってAIシステムが脳のような表現を学習できることを確認している——アルゴリズムの人工ニューロンは、脳内の物理的なニューロンと同じように活性化され、同じ画像に反応する傾向がある。このAIシステムと脳機能の協調により、AIはスキャナーで人間が見る画像と非常によく似た画像を生成することができます。 この原則に基づいて、Metaは公開されているMEGデータセットでシステムをトレーニングしました。Metaは、機能的磁気共鳴画像法(fMRI)が画像をより適切にデコードできる一方で、MEGデコーダーはリアルタイムで結果を生成し、脳活動を継続的にデコードし、連続的かつほぼリアルタイムの画像ストリームを生成できると考えています。これは、脳の損傷のために外界と通信できず、リアルタイムで外界と通信できない患者を支援するための鍵です。 **前提、脳磁図(MEG)とは何ですか? ** ## 脳磁図(MEG)は、非常に感度の高い磁力計を使用して脳内で自然に発生する電流によって生成される磁場を記録することにより、脳の活動をマッピングする機能的なニューロイメージング技術です。SQUID(超伝導量子干渉計)アレイは現在最も一般的な磁力計ですが、将来のMEGマシン用にSERF(スピンフリー交換緩和)磁力計が研究されています。 MEGの応用には、知覚的および認知的脳プロセスに関する基礎研究、外科的切除前の病理学的に冒された領域の位置特定、脳のさまざまな部分の機能の決定、およびニューロフィードバックが含まれます。 これは、異常な場所を見つけるための臨床現場で、または単に脳活動を測定するための実験設定に適用できます。 コーエン博士は、MITのシールドルームでSQUIDを使用して最初のMEGをテストしました コーエン博士は、MITのシールドルームでSQUIDを使用して最初のMEGをテストしました**AIブレインリーディングの技術アーキテクチャ** ## ## 著者は、マルチモーダルトレーニングパイプラインを提案しています。 (1)MEG活動は、最初に事前にトレーニングされた画像の特徴と一致します。(2) MEG信号ストリームから画像を生成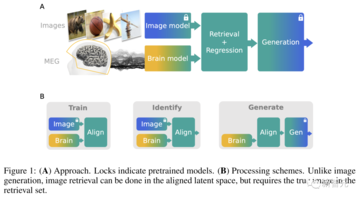 図1:(A)方法、事前学習済みモデルのフリーズ(B)処理スキームは、画像生成とは異なり、画像検索は整列された部分空間で実行できますが、検索セットに正のサンプル画像が必要です。著者らは、このシステムには2つの主要な貢献があると述べています。MEGデコーダは、(1)高性能な画像検索と画像生成を可能にし、(2)脳内の視覚処理を解釈するための新しい方法を提供する。 これは、提案された方法が新しい視覚的アイデアに本当に一般化し、「自由形式」の視覚的デコードへの道を開く能力を持っていることを示しています。要するに、研究の結果は、実験室や診療所での視覚的表現のリアルタイムデコードの有望な方向性を切り開きました。**方式**###**1. 問題の説明**著者らの研究の目的は、健康な参加者のグループに一連の自然画像を見てもらい、MEGを使用して脳活動を記録し、デコーダーが生成モデルに依存する時系列信号から画像をデコードすることでした。**2. トレーニングの目的**著者らが提案したパイプラインは複数の部分があるため、多目的最適化戦略が使用され、画像を取得するときにCLIP損失が使用されます。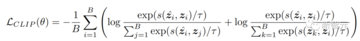 生成された画像の品質を評価するには、MSE損失、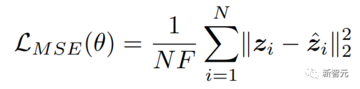 最後に、重み付き凸の組み合わせを使用してCLIP損失とMSE損失を組み合わせ、学習目標を達成します。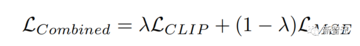 **3. 脳モデル**著者は畳み込みニューラルネットワークアーキテクチャを使用して特徴を抽出し、これに基づいて時系列集約レイヤーを追加して次元を減らし、計算オーバーヘッドを節約します。**4. 画像モデル**画像のフィーチャーエンコーディングについては、VGG-19、CLIPとその変種、およびトランスフォーマーの構造について調べました。**5. モデルの生成**fMRIの結果を公正に比較できるようにするために、著者らは他の論文と同様に事前にトレーニングされたモデルを使用し、このタスクについてトレーニングしました。**6. トレーニングのためのコンピューティング リソースの消費**喧嘩モダリティ検索タスクは約63,000枚の画像でトレーニングされ、検証セットは約15,800枚の画像でした。 32GBのRAMを搭載したボルタGPUが使用されます。**7. 評価方法**この方法の有効性を評価するために、著者らは検索インデックスの相対中央値ランク、トップ5の精度を使用し、指標PixCorr、SSIM、SwAVを生成しました。 同時に、MEGデコード性能を公正に評価するために、著者らは、指標を評価する前に、データセットで繰り返し画像デモンストレーションを利用して予測値を平均化します。**8. データセット:** モノのデータセット著者らは、THINGS-MEG データセットでメソッドをテストします。 4人の参加者(平均年齢23.25歳)が12回のMEGトレーニングを受け、トレーニングプロセス中に、THINGデータセットから選択された22,448枚の画像を見ました。 これに基づいて、THINGSデータベースから選択された画像のセットが表示され、これらの画像を使用して検索の規模を拡大し、検索能力を向上させることで、メソッドの堅牢性が向上します。**結果**###機械学習は、脳の反応を理解するための効果的なモデルと考えられています**自然な画像表現に最も強力なデコード性能を提供するモデルはどれですか?この質問に答えるために、Metaは線形リッジ回帰モデルを使用して、各画像の平坦化されたMEG応答が与えられた16の異なる潜在的な視覚表現を予測し、検索パフォーマンスを比較しました。 これを次の表に示します。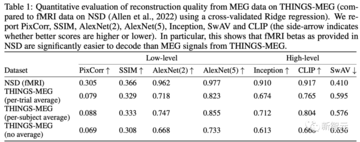 すべての画像埋め込みはランダム検索よりも高い検索パフォーマンスを示しましたが、教師ありモデルとテキスト/画像アライメントモデル(VGG、CLIPなど)が最高の検索スコアを達成しました。機械学習は脳の反応を学習するための効果的なツールと見なされています**次に、メタはこれらの線形ベースラインを、同じタスクでトレーニングされた深い畳み込みネットワーク構造と比較し、MEGウィンドウで一致する画像を取得します。深度モデルを使用すると、線形ベースラインよりも7倍のパフォーマンスが向上しました(下の図2)。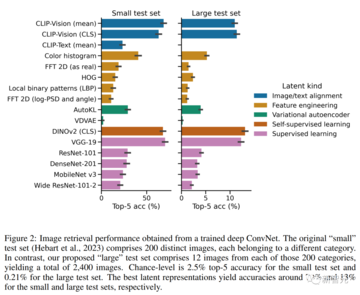 VGG-19(教師あり学習)、CLIP-Vision(テキスト/画像アライメント)、DINOv2(自己教師あり学習)の上位5つの正解率は、70.33 ± 2.80%、68.66 ± 2.84%、68.00 ± 2.86%(平均画像メトリックの標準誤差を計算)でした。同様の結論は、「大規模な」テストセット設定から引き出すことができますが、パフォーマンスは低くなりますが、デコードは画像クラスに依存するだけでなく、同じカテゴリの複数の画像を区別する必要があります。 代表的な検索例を下図に示します。 時間分解能レベルでの画像検索脳内で視覚表現が展開する可能性をさらに調査するために、著者らは250ミリ秒のスライディングウィンドウで分析しました。すべてのモデルは、画像がレンダリングされる前にベンチマークレベルの表現を達成しました。 最初の明らかなピークは、画像の0~250msのウィンドウで観察され、その後、画像シフト後の2番目のピークが続き、その後、0〜250msのウィンドウにすばやくフォールバックし、すべてのモデルがこの法則に準拠しています。興味深いことに、最近の自己教師ありモデルDINOv2は、画像バイアス後に特に優れたパフォーマンスを発揮します。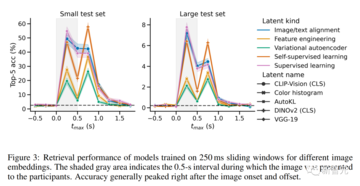 デコード メトリックの意味をよりよく理解するために、次の図は、参加者が見たことのない 3,659 枚の画像で構成される追加のセットを使用して、検索結果が元のテスト セットでテストされたことを示しています。 デコーダーは画像のバイアスに関連する脳の反応を利用しており、早くも250msでカテゴリ情報がこれらの視覚表現を支配していたことがわかります。#### **MEG信号から画像を生成する**検索タスクとしてデコードすると良い結果が得られますが、ポジティブサンプル画像が検索セットに含まれている必要があり、実際の適用は限られています。 この問題を解決するために、著者らは3つの異なる脳モジュールを訓練して予測した。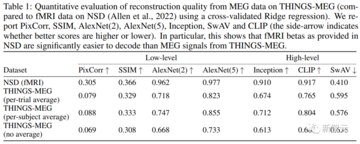 表1の評価指標によると、生成された画像は視覚的に比較的高品質を示し、複数の生成された画像は意味カテゴリを正しく提示しました。 しかし、これらの生成された画像には、実際の画像からの低レベルの視覚情報が含まれているように見えます。**話し合う**###**インパクト**この研究は根本的かつ実際的な意味を持っています。第一に、複雑な知覚表現を経時的に解読する能力は、脳の視覚処理に関与するさまざまなプロセスの人間の理解を大幅に前進させることが期待されています。ビジョンシステムによって構築される表現の性質とタイミングを調べるために、多くの作業が行われています。 ただし、これらの結果は、特に高度な機能の場合、解釈が難しい場合があります。この研究における生成デコードは、具体的で解釈可能な予測を提供します。第二に、脳デコード技術の最も明白なユースケースは、脳損傷がコミュニケーションに影響を与える患者を支援することです。ただし、このユースケースではリアルタイムのデコードが必要なため、fMRIなどの時間分解能の低いニューロイメージングモダリティの使用が制限されます。その結果、現在の取り組みは、将来のリアルタイムデコードへの道を開きます。制限メタの分析では、MEG信号から画像をデコードする際の3つの主な制限が浮き彫りになりました。第一に、高レベルのセマンティック特徴のデコードは、低レベルの特徴のデコードよりも優先されます:特に、結果として得られる画像は、低レベルの特徴(例えば、輪郭、影)よりもセマンティクス(例えば、オブジェクトカテゴリ)をよりよく保持します。この現象を研究の流れに帰することは困難です:実際、7T fMRI記録に同様の手順を適用することは、低レベルの特徴を再構築することを合理的にします。 代わりに、この結果は、MEGの空間分解能(≈ cm)が7T fMRI(≈ mm)よりもはるかに低いという事実を反映しています。第二に、現在のアプローチは、いくつかのモデルの事前トレーニングに直接依存しており、MEG信号をこれらの事前トレーニング済み埋め込みに合わせるためにエンドツーエンドで学習するだけです。この研究の結果は、この方法がカラーヒストグラム、高速フーリエ変換、方向勾配ヒストグラム(HOG)などの従来のコンピュータービジョン機能よりも優れていることを示しています。これは、音声デコードのコンテキストにおいて、事前トレーニングされた埋め込みが完全なエンドツーエンドアプローチよりも優れていることを示した最近のMEG研究と一致しています。ただし、今後、2つの側面をテストする必要があります。(1)画像を微調整してモジュールを生成する(2)異なるタイプの視覚的特徴を組み合わせることで、デコード性能が向上するかどうか。リソース:
AIの脳は、わずか0.25秒の遅延で実現します! メタマイルストーン新しい研究:MEGは脳画像をリアルタイムでデコードします、LeCunは好きです
原典:シン・ジユアン
AIマインドリーディングが終わった!?
本日、LeCunはMeta AIの最新のブレークスルーを転送しました:AIは脳活動における画像知覚をリアルタイムでデコードすることができました!
Metaは、非侵襲的な神経イメージング技術である脳磁図(MEG)を使用して、毎秒数千回の脳活動スキャンをスキャンし、脳内の視覚表現をほぼリアルタイムでデコードできるAIシステムを開発しました。
長期的には、臨床現場での非侵襲的なブレインコンピュータインターフェースの基礎としても機能し、脳損傷を負った後に話す能力を失った人々が外界と通信するのに役立ちます。
具体的には、画像エンコーダー、脳エンコーダー、画像デコーダーで構成されるシステムを開発しました。
Metaはまず、事前にトレーニングされたさまざまな画像モジュールのデコードパフォーマンスを比較し、脳信号がDINOv2などのコンピュータービジョンAIシステムと非常に一致していることを発見しました。
この新知見は、自己教師あり学習によってAIシステムが脳のような表現を学習できることを確認している——アルゴリズムの人工ニューロンは、脳内の物理的なニューロンと同じように活性化され、同じ画像に反応する傾向がある。
このAIシステムと脳機能の協調により、AIはスキャナーで人間が見る画像と非常によく似た画像を生成することができます。
Metaは、機能的磁気共鳴画像法(fMRI)が画像をより適切にデコードできる一方で、MEGデコーダーはリアルタイムで結果を生成し、脳活動を継続的にデコードし、連続的かつほぼリアルタイムの画像ストリームを生成できると考えています。
これは、脳の損傷のために外界と通信できず、リアルタイムで外界と通信できない患者を支援するための鍵です。
脳磁図(MEG)は、非常に感度の高い磁力計を使用して脳内で自然に発生する電流によって生成される磁場を記録することにより、脳の活動をマッピングする機能的なニューロイメージング技術です。
SQUID(超伝導量子干渉計)アレイは現在最も一般的な磁力計ですが、将来のMEGマシン用にSERF(スピンフリー交換緩和)磁力計が研究されています。
AIブレインリーディングの技術アーキテクチャ
著者は、マルチモーダルトレーニングパイプラインを提案しています。
(1)MEG活動は、最初に事前にトレーニングされた画像の特徴と一致します。
(2) MEG信号ストリームから画像を生成
著者らは、このシステムには2つの主要な貢献があると述べています。
MEGデコーダは、(1)高性能な画像検索と画像生成を可能にし、
(2)脳内の視覚処理を解釈するための新しい方法を提供する。 これは、提案された方法が新しい視覚的アイデアに本当に一般化し、「自由形式」の視覚的デコードへの道を開く能力を持っていることを示しています。
要するに、研究の結果は、実験室や診療所での視覚的表現のリアルタイムデコードの有望な方向性を切り開きました。
方式
1. 問題の説明
著者らの研究の目的は、健康な参加者のグループに一連の自然画像を見てもらい、MEGを使用して脳活動を記録し、デコーダーが生成モデルに依存する時系列信号から画像をデコードすることでした。
2. トレーニングの目的
著者らが提案したパイプラインは複数の部分があるため、多目的最適化戦略が使用され、画像を取得するときにCLIP損失が使用されます。
著者は畳み込みニューラルネットワークアーキテクチャを使用して特徴を抽出し、これに基づいて時系列集約レイヤーを追加して次元を減らし、計算オーバーヘッドを節約します。
4. 画像モデル
画像のフィーチャーエンコーディングについては、VGG-19、CLIPとその変種、およびトランスフォーマーの構造について調べました。
5. モデルの生成
fMRIの結果を公正に比較できるようにするために、著者らは他の論文と同様に事前にトレーニングされたモデルを使用し、このタスクについてトレーニングしました。
6. トレーニングのためのコンピューティング リソースの消費
喧嘩モダリティ検索タスクは約63,000枚の画像でトレーニングされ、検証セットは約15,800枚の画像でした。 32GBのRAMを搭載したボルタGPUが使用されます。
7. 評価方法
この方法の有効性を評価するために、著者らは検索インデックスの相対中央値ランク、トップ5の精度を使用し、指標PixCorr、SSIM、SwAVを生成しました。 同時に、MEGデコード性能を公正に評価するために、著者らは、指標を評価する前に、データセットで繰り返し画像デモンストレーションを利用して予測値を平均化します。
8. データセット:
著者らは、THINGS-MEG データセットでメソッドをテストします。 4人の参加者(平均年齢23.25歳)が12回のMEGトレーニングを受け、トレーニングプロセス中に、THINGデータセットから選択された22,448枚の画像を見ました。 これに基づいて、THINGSデータベースから選択された画像のセットが表示され、これらの画像を使用して検索の規模を拡大し、検索能力を向上させることで、メソッドの堅牢性が向上します。
結果
機械学習は、脳の反応を理解するための効果的なモデルと考えられています**
自然な画像表現に最も強力なデコード性能を提供するモデルはどれですか?
この質問に答えるために、Metaは線形リッジ回帰モデルを使用して、各画像の平坦化されたMEG応答が与えられた16の異なる潜在的な視覚表現を予測し、検索パフォーマンスを比較しました。 これを次の表に示します。
機械学習は脳の反応を学習するための効果的なツールと見なされています**
次に、メタはこれらの線形ベースラインを、同じタスクでトレーニングされた深い畳み込みネットワーク構造と比較し、MEGウィンドウで一致する画像を取得します。
深度モデルを使用すると、線形ベースラインよりも7倍のパフォーマンスが向上しました(下の図2)。
同様の結論は、「大規模な」テストセット設定から引き出すことができますが、パフォーマンスは低くなりますが、デコードは画像クラスに依存するだけでなく、同じカテゴリの複数の画像を区別する必要があります。 代表的な検索例を下図に示します。
脳内で視覚表現が展開する可能性をさらに調査するために、著者らは250ミリ秒のスライディングウィンドウで分析しました。
すべてのモデルは、画像がレンダリングされる前にベンチマークレベルの表現を達成しました。 最初の明らかなピークは、画像の0~250msのウィンドウで観察され、その後、画像シフト後の2番目のピークが続き、その後、0〜250msのウィンドウにすばやくフォールバックし、すべてのモデルがこの法則に準拠しています。
興味深いことに、最近の自己教師ありモデルDINOv2は、画像バイアス後に特に優れたパフォーマンスを発揮します。
MEG信号から画像を生成する
検索タスクとしてデコードすると良い結果が得られますが、ポジティブサンプル画像が検索セットに含まれている必要があり、実際の適用は限られています。 この問題を解決するために、著者らは3つの異なる脳モジュールを訓練して予測した。
話し合う
インパクト
この研究は根本的かつ実際的な意味を持っています。
第一に、複雑な知覚表現を経時的に解読する能力は、脳の視覚処理に関与するさまざまなプロセスの人間の理解を大幅に前進させることが期待されています。
ビジョンシステムによって構築される表現の性質とタイミングを調べるために、多くの作業が行われています。 ただし、これらの結果は、特に高度な機能の場合、解釈が難しい場合があります。
この研究における生成デコードは、具体的で解釈可能な予測を提供します。
第二に、脳デコード技術の最も明白なユースケースは、脳損傷がコミュニケーションに影響を与える患者を支援することです。
ただし、このユースケースではリアルタイムのデコードが必要なため、fMRIなどの時間分解能の低いニューロイメージングモダリティの使用が制限されます。
その結果、現在の取り組みは、将来のリアルタイムデコードへの道を開きます。
制限
メタの分析では、MEG信号から画像をデコードする際の3つの主な制限が浮き彫りになりました。
第一に、高レベルのセマンティック特徴のデコードは、低レベルの特徴のデコードよりも優先されます:特に、結果として得られる画像は、低レベルの特徴(例えば、輪郭、影)よりもセマンティクス(例えば、オブジェクトカテゴリ)をよりよく保持します。
この現象を研究の流れに帰することは困難です:実際、7T fMRI記録に同様の手順を適用することは、低レベルの特徴を再構築することを合理的にします。
第二に、現在のアプローチは、いくつかのモデルの事前トレーニングに直接依存しており、MEG信号をこれらの事前トレーニング済み埋め込みに合わせるためにエンドツーエンドで学習するだけです。
この研究の結果は、この方法がカラーヒストグラム、高速フーリエ変換、方向勾配ヒストグラム(HOG)などの従来のコンピュータービジョン機能よりも優れていることを示しています。
これは、音声デコードのコンテキストにおいて、事前トレーニングされた埋め込みが完全なエンドツーエンドアプローチよりも優れていることを示した最近のMEG研究と一致しています。
ただし、今後、2つの側面をテストする必要があります。
(1)画像を微調整してモジュールを生成する
(2)異なるタイプの視覚的特徴を組み合わせることで、デコード性能が向上するかどうか。
リソース: