原典:シン・ジユアン 画像ソース:無制限のAIによって生成近年、Transformerは自然言語処理とコンピュータービジョンタスクで継続的なブレークスルーを達成し、ディープラーニングの分野における基本モデルになりました。これに触発されて、トランスフォーマーモデルの多数のバリエーションが時系列の分野で提案されています。しかし、最近の研究では、単純な線形レイヤーベースの予測モデルを使用すると、あらゆる種類の魔法の変圧器よりも優れた結果が得られることがわかっています。 最近、時系列予測の分野におけるTransformerの有効性に関する質問に答えて、清華大学ソフトウェア学部の機械学習研究所とAnt Groupの学者が共同で時系列予測作業を発表し、Redditやその他のフォーラムで白熱した議論が巻き起こりました。その中で、著者が提案したiTransformerは、多次元時系列のデータ特性を考慮し、Transformerモジュールを変更せず、従来のモデル構造を破り、複雑な時系列予測タスクで包括的なリードを達成し、Transformerモデリング時系列データの問題点を解決しようとしています。 論文住所:コードの実装:iTransformerの祝福により、トランスフォーマーは時系列予測タスクの包括的な逆転を完了しました。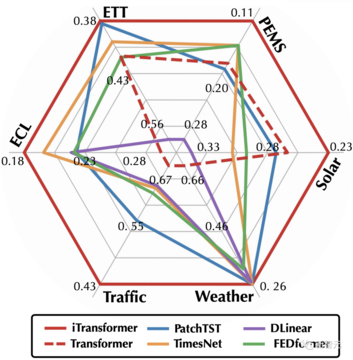 ## **問題の背景** 実世界の時系列データは、時間ディメンションに加えて可変ディメンションを含む多次元になる傾向があります。各変数は、天気予報で使用される複数の気象指標(風速、温度、湿度、気圧など)などの異なる観測物理量を表すことも、発電所内の異なる機器の時間単位の発電など、異なる観測対象を表すこともできます。一般に、異なる変数は完全に異なる物理的意味を持ち、セマンティクスが同じであっても、それらの測定単位は完全に異なる場合があります。 これまで、トランスフォーマーベースの予測モデルは通常、同時に複数の変数をテンポラルトークンに埋め込み、フィードフォワードネットワークを使用して各瞬間の特徴をエンコードし、アテンションモジュールを使用して異なる瞬間間の相関関係を学習していました。ただし、この方法には次の問題が発生する可能性があります。 ## **デザインのアイデア** 既存のTransformerの視点で見られる各「Temporal Token」は、強力な独立意味情報を持つ自然言語の各単語(Token)とは異なり、時系列データの同じシーケンスに対するセンマンティ性に欠けることが多く、タイムスタンプの不整合や受容フィールドが小さすぎるなどの問題に直面しています。言い換えれば、時系列に関する従来のトランスフォーマーのモデリング機能が大幅に弱体化しています。この目的のために、著者らは反転のまったく新しい視点を提案します。下図に示すように、iTransformerはTransformerの元のモジュールを反転させることで、まず同じ変数のシーケンス全体を高次元の特徴表現(iateトークン)にマッピングし、得られた特徴ベクトルは変数を記述された本体として取り、それが反映する歴史的プロセスを独立して描写します。その後、アテンションモジュールは自然に多重相関をモデル化することができ、フィードフォワードネットワークは時間次元で過去の観測の特徴を層ごとにエンコードし、学習した特徴を将来の予測にマッピングします。対照的に、過去に時系列データについて深く調査されたことのないLayerNormも、変数間の分布の違いを排除する上で重要な役割を果たします。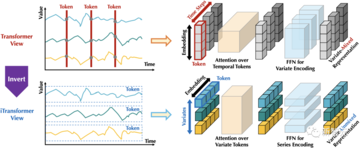 ## **iトランスフォーマー** ### **全体構造**以前のトランスフォーマー予測モデルで使用されていたより複雑なエンコーダー/デコーダー構造とは異なり、iTransformerには、埋め込みレイヤー、投影レイヤー(プロジェクター)、スタッカブルトランスモジュール(TrmBlock)を含むエンコーダーのみが含まれています。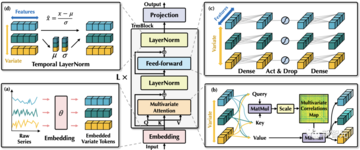 モデリング変数の特徴表現時間の長さと多数の変数を持つ多次元時系列の場合、この記事では、同じ瞬間を表すすべての変数と、同じ変数を表す履歴観測シーケンス全体を使用します。この方法は、以前の特徴の埋め込み方法とは異なり、より強力なセマンティクスと比較的一貫した測定単位を持っていることを考慮して、埋め込みレイヤーを使用して各特徴を個別にマッピングし、過去の変数の時系列変化を含む各変数の特徴表現を取得します。この特徴表現は、まずTransformerモジュールの各層のセルフアテンションメカニズムを介して変数間の情報を相互作用し、層の正規化を使用して異なる変数の特徴分布を統合し、フィードフォワードネットワークで完全に接続された特徴コーディングを実行します。 最後に、予測結果が投影レイヤーによってマッピングされます。上記のプロセスに基づいて、モデル全体の実装は非常に単純であり、計算プロセスは次のように表すことができます。 このうち、各変数に対応する予測結果、埋め込み層及び投影層は、多層パーセプトロン(MLP)に基づいて実施される。時間ポイント間の順序は、ニューロンが配置される順序ですでに暗黙的であるため、モデルはTransformerに位置埋め込みを導入する必要がないことに注意してください。**モジュール分析**Transformer モジュールの時系列データの処理の次元を逆にした後、この作業では、iTransformer の各モジュールの役割を再検討します。**1. レイヤー正規化: ** レイヤー正規化は、もともとディープネットワークトレーニングの安定性と収束を改善するために提案されました。以前の Transformer では、モジュールは複数の変数を同時に正規化し、各変数を区別できないようにしました。 収集されたデータが時間的に整合しないと、操作によって、因果プロセスまたは遅延プロセス間の相互作用ノイズも発生します。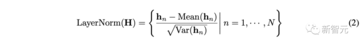 反転バージョン(式は上記の通り)では、各変数の特徴表現(iateトークン)にレイヤー正規化が適用されるため、すべての変数の特徴チャネルが比較的均一な分布になります。この正規化の概念は、時系列の非定常問題に対処するのに効果的であることが広く証明されていますが、レイヤー正規化によってiTransformerに自然に実装できます。さらに、すべての変数の特徴表現は正規分布に正規化されるため、変数の値の範囲が異なることによる差を減らすことができます。代わりに、前の構造では、すべてのタイムスタンプの Temporal Token が一様に正規化され、その結果、モデルは実際には過度に滑らかな時系列になります。**2. フィードフォワードネットワーク:Transformerは、フィードフォワードネットワークを使用して単語ベクトルをエンコードします。以前のモデルで形成された「単語」ベクトルは、同時に収集された複数の変数であり、それらの生成時間に一貫性がない場合があり、時間ステップを反映する「単語」が十分な意味を提供することが困難でした。反転バージョンでは、「単語」ベクトルは、過去の観測と将来の予測で共有される時間的特徴を抽出するのに十分な大きなモデル容量を持ち、予測結果として特徴外挿を使用する多層パーセプトロンの普遍表現定理に基づいて、同じ変数のシーケンス全体によって形成されます。フィードフォワードネットワークを使用して時間次元をモデル化するもう1つの基礎は、線形層が任意の時系列が持つ時間特性を学習するのに優れていることを発見した最近の研究から来ています。著者らは、線形層のニューロンは、振幅、周期性、さらには周波数スペクトルなど、任意の時系列の固有の特性を抽出する方法を学習できるというもっともらしい説明を提案しています(フーリエ変換は本質的に元のシーケンス上の完全に接続されたマップです)。したがって、時系列の依存関係をモデル化するためにアテンションメカニズムを使用するTransformerの以前のプラクティスと比較して、フィードフォワードネットワークの使用は、目に見えないシーケンスの一般化を完了する可能性が高くなります。**3. セルフアテンション:セルフアテンションモジュールは、このモデルでさまざまな変数の相関関係をモデル化するために使用され、天気予報などの物理的知識によって駆動される複雑な予測シナリオで非常に重要です。その結果、アテンションマップの各位置が次の式を満たすことが分かった。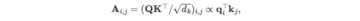 著者は、任意の2つの変数のクエリベクトルとキーベクトルに対応して、アテンションマップ全体が変数の相関をある程度明らかにすることができ、アテンションマップに基づくその後の重み付け操作では、相関性の高い変数がそれらの値ベクトルとの相互作用においてより大きな重みを獲得するため、この設計はより自然であり、多次元時系列データモデリングにとって解釈可能であると考えています。要約すると、iTransformerでは、レイヤー正規化、フィードフォワードネットワーク、およびセルフアテンションモジュールは、多次元時系列データ自体の特性を考慮し、3つは体系的に互いに協力して、異なる次元のモデリングニーズに適応し、1 + 1 + 1>3の効果を発揮します。**実験解析**著者らは、6つの多次元時系列予測ベンチマークで広範な実験を行い、Alipay取引プラットフォームのオンラインサービス負荷予測タスクシナリオのデータ(市場)で予測を行いました。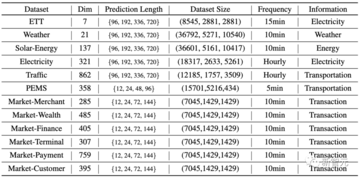 実験部分では、ドメイン代表トランスモデルを含む10の異なる予測モデルを比較します:PatchTST(2023)、クロスフォーマー(2023)、FEDフォーマー(2022)、ステーショナリー(2022)、オートフォーマー(2021)、インフォーマー(2021)。 線形予測モデル:TiDE(2023)、DLinear(2023); TCNモデル:タイムズネット(2023)、SCINet(2022)。さらに、この記事では、一般的な効果の改善、未知の変数への一般化、過去の観測値のより完全な使用など、多くのTransformerバリアントへのモジュール反転によってもたらされる利益を分析します。**時系列予測**冒頭のレーダーチャートに示されているように、iTransformerは6つのテストベンチマークすべてでSOTAを達成し、市場データの28/30シナリオで最適な結果を達成しました(詳細については、論文の付録を参照してください)。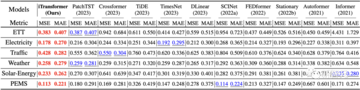 長期予測と多次元時間予測の困難なシナリオでは、iTransformerは近年の予測モデルを包括的に上回っています。 ## **iTransformer フレームワークの共通性** 最良の結果を達成しながら、著者は、リフォーマー、インフォーマー、フローフォーマー、フラッシュフォーマーなどのトランスフォーマーバリアントモデルで反転前後の比較実験を行い、反転が時系列データの特性に沿った構造フレームワークであることを証明しました。**1. 予測を改善する**提案フレームワークの導入により、これらのモデルは予測効果の大幅な改善を達成し、iTransformerのコアアイデアの多様性と効率的な注意研究の進歩から利益を得る可能性を証明しました。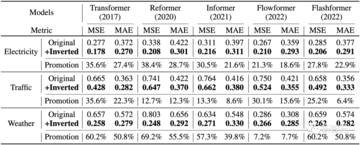 **2. 未知の変数に一般化する**反転することで、モデルは推論時にトレーニングとは異なる数の変数を入力でき、論文はそれを汎化戦略であるチャネル独立性と比較し、結果は、フレームワークが変数の20%のみを使用する場合でも汎化エラーを最小限に抑えることができることを示しています。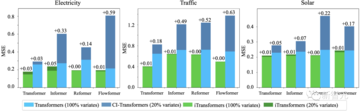 **3. より長い履歴観測値を使用する**従来、Transformerモデルの予測効果は、履歴観測の長さによって必ずしも向上するわけではありませんでしたが、著者らは、このフレームワークを使用した後、履歴観測が増加した場合に予測誤差が減少するという驚くべき傾向を示し、モジュール反転の合理性をある程度検証しました。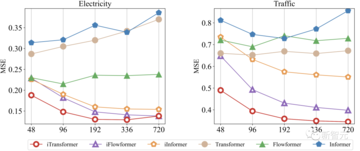 **モデル分析****1. モデルアブレーション実験**著者らは、iTransformerモジュール配置の合理性を検証するためにアブレーション実験を実施しました。結果は、可変次元でセルフアテンションを使用し、時間次元で線形層を使用するモデリング手法が、ほとんどのデータセットで最良の効果を達成することを示しています。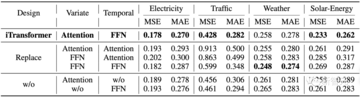 **2. 特徴表現分析**フィードフォワードネットワークが配列特徴をよりよく抽出できるという考えを検証するために、著者らはCKA(中心化カーネルアライメント)類似性に基づいて特徴表現分析を行います。 CKAの類似性が低いほど、モデルの最下層と最上層の特徴の違いが大きくなります。以前の研究では、時系列予測は、きめ細かな特徴学習タスクとして、より高いCKA類似性を好む傾向があることが示されていることは注目に値します。著者らは、反転前後のモデルの低レベルおよびトップレベルのCKAを計算し、次の結果を得て、iTransformerがより良いシーケンス特徴を学習し、それによってより良い予測効果を達成することを確認しました。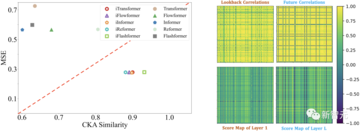 **3. 変数相関分析**上の図に示すように、可変次元に作用するアテンションメカニズムは、学習されたアテンションマップにおいてより大きな解釈可能性を示す。 太陽エネルギーデータセットのサンプルを視覚化することにより、次の観察が行われます。*浅い注意モジュールでは、学習された注意グラフは、履歴シーケンスの変数相関に似ています。*深い注意モジュールを支払う場合、学習された注意マップは、予測されるシーケンスの変数相関により類似しています。これは、アテンションモジュールがより解釈可能な変数相関を学習し、フィードフォワードネットワーク内の履歴観測の時間的特徴を符号化し、それらを予測されるシーケンスに徐々にデコードできることを示している。 ## **概要** 多次元時系列のデータ特性に触発されて、著者は時系列データのモデリングにおける既存のトランスフォーマーの問題を振り返り、一般的な時系列予測フレームワークiTransformerを提案します。iTransformerフレームワークは、時系列を観察するための逆視点を革新的に導入しているため、Transformerモジュールは独自の役割を果たし、時系列データの2次元のモデリング問題を完了し、優れたパフォーマンスと汎用性を示します。Transformerが時系列予測の分野で有効かどうかという疑問に直面して、著者のこの発見は、その後の関連研究を刺激し、Transformerを時系列予測の主流の位置に戻らせ、時系列データの分野での基礎モデル研究に新しいアイデアを提供する可能性があります。リソース:
トランスフォーマーキングが帰ってきた! モジュールを変更することなく、タイミング予測が全面的にリードします
原典:シン・ジユアン
近年、Transformerは自然言語処理とコンピュータービジョンタスクで継続的なブレークスルーを達成し、ディープラーニングの分野における基本モデルになりました。
これに触発されて、トランスフォーマーモデルの多数のバリエーションが時系列の分野で提案されています。
しかし、最近の研究では、単純な線形レイヤーベースの予測モデルを使用すると、あらゆる種類の魔法の変圧器よりも優れた結果が得られることがわかっています。
その中で、著者が提案したiTransformerは、多次元時系列のデータ特性を考慮し、Transformerモジュールを変更せず、従来のモデル構造を破り、複雑な時系列予測タスクで包括的なリードを達成し、Transformerモデリング時系列データの問題点を解決しようとしています。
コードの実装:
iTransformerの祝福により、トランスフォーマーは時系列予測タスクの包括的な逆転を完了しました。
問題の背景
実世界の時系列データは、時間ディメンションに加えて可変ディメンションを含む多次元になる傾向があります。
各変数は、天気予報で使用される複数の気象指標(風速、温度、湿度、気圧など)などの異なる観測物理量を表すことも、発電所内の異なる機器の時間単位の発電など、異なる観測対象を表すこともできます。
一般に、異なる変数は完全に異なる物理的意味を持ち、セマンティクスが同じであっても、それらの測定単位は完全に異なる場合があります。
これまで、トランスフォーマーベースの予測モデルは通常、同時に複数の変数をテンポラルトークンに埋め込み、フィードフォワードネットワークを使用して各瞬間の特徴をエンコードし、アテンションモジュールを使用して異なる瞬間間の相関関係を学習していました。
ただし、この方法には次の問題が発生する可能性があります。
デザインのアイデア
既存のTransformerの視点で見られる各「Temporal Token」は、強力な独立意味情報を持つ自然言語の各単語(Token)とは異なり、時系列データの同じシーケンスに対するセンマンティ性に欠けることが多く、タイムスタンプの不整合や受容フィールドが小さすぎるなどの問題に直面しています。
言い換えれば、時系列に関する従来のトランスフォーマーのモデリング機能が大幅に弱体化しています。
この目的のために、著者らは反転のまったく新しい視点を提案します。
下図に示すように、iTransformerはTransformerの元のモジュールを反転させることで、まず同じ変数のシーケンス全体を高次元の特徴表現(iateトークン)にマッピングし、得られた特徴ベクトルは変数を記述された本体として取り、それが反映する歴史的プロセスを独立して描写します。
その後、アテンションモジュールは自然に多重相関をモデル化することができ、フィードフォワードネットワークは時間次元で過去の観測の特徴を層ごとにエンコードし、学習した特徴を将来の予測にマッピングします。
対照的に、過去に時系列データについて深く調査されたことのないLayerNormも、変数間の分布の違いを排除する上で重要な役割を果たします。
iトランスフォーマー
全体構造
以前のトランスフォーマー予測モデルで使用されていたより複雑なエンコーダー/デコーダー構造とは異なり、iTransformerには、埋め込みレイヤー、投影レイヤー(プロジェクター)、スタッカブルトランスモジュール(TrmBlock)を含むエンコーダーのみが含まれています。
時間の長さと多数の変数を持つ多次元時系列の場合、この記事では、同じ瞬間を表すすべての変数と、同じ変数を表す履歴観測シーケンス全体を使用します。
この方法は、以前の特徴の埋め込み方法とは異なり、より強力なセマンティクスと比較的一貫した測定単位を持っていることを考慮して、埋め込みレイヤーを使用して各特徴を個別にマッピングし、過去の変数の時系列変化を含む各変数の特徴表現を取得します。
この特徴表現は、まずTransformerモジュールの各層のセルフアテンションメカニズムを介して変数間の情報を相互作用し、層の正規化を使用して異なる変数の特徴分布を統合し、フィードフォワードネットワークで完全に接続された特徴コーディングを実行します。 最後に、予測結果が投影レイヤーによってマッピングされます。
上記のプロセスに基づいて、モデル全体の実装は非常に単純であり、計算プロセスは次のように表すことができます。
時間ポイント間の順序は、ニューロンが配置される順序ですでに暗黙的であるため、モデルはTransformerに位置埋め込みを導入する必要がないことに注意してください。
モジュール分析
Transformer モジュールの時系列データの処理の次元を逆にした後、この作業では、iTransformer の各モジュールの役割を再検討します。
**1. レイヤー正規化: ** レイヤー正規化は、もともとディープネットワークトレーニングの安定性と収束を改善するために提案されました。
以前の Transformer では、モジュールは複数の変数を同時に正規化し、各変数を区別できないようにしました。 収集されたデータが時間的に整合しないと、操作によって、因果プロセスまたは遅延プロセス間の相互作用ノイズも発生します。
この正規化の概念は、時系列の非定常問題に対処するのに効果的であることが広く証明されていますが、レイヤー正規化によってiTransformerに自然に実装できます。
さらに、すべての変数の特徴表現は正規分布に正規化されるため、変数の値の範囲が異なることによる差を減らすことができます。
代わりに、前の構造では、すべてのタイムスタンプの Temporal Token が一様に正規化され、その結果、モデルは実際には過度に滑らかな時系列になります。
**2. フィードフォワードネットワーク:Transformerは、フィードフォワードネットワークを使用して単語ベクトルをエンコードします。
以前のモデルで形成された「単語」ベクトルは、同時に収集された複数の変数であり、それらの生成時間に一貫性がない場合があり、時間ステップを反映する「単語」が十分な意味を提供することが困難でした。
反転バージョンでは、「単語」ベクトルは、過去の観測と将来の予測で共有される時間的特徴を抽出するのに十分な大きなモデル容量を持ち、予測結果として特徴外挿を使用する多層パーセプトロンの普遍表現定理に基づいて、同じ変数のシーケンス全体によって形成されます。
フィードフォワードネットワークを使用して時間次元をモデル化するもう1つの基礎は、線形層が任意の時系列が持つ時間特性を学習するのに優れていることを発見した最近の研究から来ています。
著者らは、線形層のニューロンは、振幅、周期性、さらには周波数スペクトルなど、任意の時系列の固有の特性を抽出する方法を学習できるというもっともらしい説明を提案しています(フーリエ変換は本質的に元のシーケンス上の完全に接続されたマップです)。
したがって、時系列の依存関係をモデル化するためにアテンションメカニズムを使用するTransformerの以前のプラクティスと比較して、フィードフォワードネットワークの使用は、目に見えないシーケンスの一般化を完了する可能性が高くなります。
**3. セルフアテンション:セルフアテンションモジュールは、このモデルでさまざまな変数の相関関係をモデル化するために使用され、天気予報などの物理的知識によって駆動される複雑な予測シナリオで非常に重要です。
その結果、アテンションマップの各位置が次の式を満たすことが分かった。
要約すると、iTransformerでは、レイヤー正規化、フィードフォワードネットワーク、およびセルフアテンションモジュールは、多次元時系列データ自体の特性を考慮し、3つは体系的に互いに協力して、異なる次元のモデリングニーズに適応し、1 + 1 + 1>3の効果を発揮します。
実験解析
著者らは、6つの多次元時系列予測ベンチマークで広範な実験を行い、Alipay取引プラットフォームのオンラインサービス負荷予測タスクシナリオのデータ(市場)で予測を行いました。
さらに、この記事では、一般的な効果の改善、未知の変数への一般化、過去の観測値のより完全な使用など、多くのTransformerバリアントへのモジュール反転によってもたらされる利益を分析します。
時系列予測
冒頭のレーダーチャートに示されているように、iTransformerは6つのテストベンチマークすべてでSOTAを達成し、市場データの28/30シナリオで最適な結果を達成しました(詳細については、論文の付録を参照してください)。
iTransformer フレームワークの共通性
最良の結果を達成しながら、著者は、リフォーマー、インフォーマー、フローフォーマー、フラッシュフォーマーなどのトランスフォーマーバリアントモデルで反転前後の比較実験を行い、反転が時系列データの特性に沿った構造フレームワークであることを証明しました。
1. 予測を改善する
提案フレームワークの導入により、これらのモデルは予測効果の大幅な改善を達成し、iTransformerのコアアイデアの多様性と効率的な注意研究の進歩から利益を得る可能性を証明しました。
反転することで、モデルは推論時にトレーニングとは異なる数の変数を入力でき、論文はそれを汎化戦略であるチャネル独立性と比較し、結果は、フレームワークが変数の20%のみを使用する場合でも汎化エラーを最小限に抑えることができることを示しています。
従来、Transformerモデルの予測効果は、履歴観測の長さによって必ずしも向上するわけではありませんでしたが、著者らは、このフレームワークを使用した後、履歴観測が増加した場合に予測誤差が減少するという驚くべき傾向を示し、モジュール反転の合理性をある程度検証しました。
1. モデルアブレーション実験
著者らは、iTransformerモジュール配置の合理性を検証するためにアブレーション実験を実施しました。
結果は、可変次元でセルフアテンションを使用し、時間次元で線形層を使用するモデリング手法が、ほとんどのデータセットで最良の効果を達成することを示しています。
フィードフォワードネットワークが配列特徴をよりよく抽出できるという考えを検証するために、著者らはCKA(中心化カーネルアライメント)類似性に基づいて特徴表現分析を行います。 CKAの類似性が低いほど、モデルの最下層と最上層の特徴の違いが大きくなります。
以前の研究では、時系列予測は、きめ細かな特徴学習タスクとして、より高いCKA類似性を好む傾向があることが示されていることは注目に値します。
著者らは、反転前後のモデルの低レベルおよびトップレベルのCKAを計算し、次の結果を得て、iTransformerがより良いシーケンス特徴を学習し、それによってより良い予測効果を達成することを確認しました。
上の図に示すように、可変次元に作用するアテンションメカニズムは、学習されたアテンションマップにおいてより大きな解釈可能性を示す。 太陽エネルギーデータセットのサンプルを視覚化することにより、次の観察が行われます。
*浅い注意モジュールでは、学習された注意グラフは、履歴シーケンスの変数相関に似ています。 *深い注意モジュールを支払う場合、学習された注意マップは、予測されるシーケンスの変数相関により類似しています。
これは、アテンションモジュールがより解釈可能な変数相関を学習し、フィードフォワードネットワーク内の履歴観測の時間的特徴を符号化し、それらを予測されるシーケンスに徐々にデコードできることを示している。
概要
多次元時系列のデータ特性に触発されて、著者は時系列データのモデリングにおける既存のトランスフォーマーの問題を振り返り、一般的な時系列予測フレームワークiTransformerを提案します。
iTransformerフレームワークは、時系列を観察するための逆視点を革新的に導入しているため、Transformerモジュールは独自の役割を果たし、時系列データの2次元のモデリング問題を完了し、優れたパフォーマンスと汎用性を示します。
Transformerが時系列予測の分野で有効かどうかという疑問に直面して、著者のこの発見は、その後の関連研究を刺激し、Transformerを時系列予測の主流の位置に戻らせ、時系列データの分野での基礎モデル研究に新しいアイデアを提供する可能性があります。
リソース: