>GPT-4は単にそれが間違いを犯していることを知らないのですか? 最新の研究では、推論タスクのLLMは、自己修正後、パフォーマンスの低下を救うことができず、AIのボスであるLeCunMarcusが監視していることがわかっています。原典:シン・ジユアン 画像ソース:無制限のAIによって生成大きなモデルは大きな欠陥にさらされ、同時にLeCunとMarcusの注目を集めました!  推論実験では、精度の向上を主張するモデルが自己修正し、正解率を16%から1%に「改善」しました!  簡単に言えば、LLMは、自己修正の過程で正しい答えをすでに知らない限り、推論タスクの形で自己修正の形で出力を改善することはできません。 ASUの研究者によって発表された2つの論文は、多くの先行研究によって提案された「自己修正」方法に反論しています-大規模なモデルが出力結果を自己修正できるようにすることで、モデルの出力の品質を向上させることができます。 論文住所: 論文住所:論文の共著者であるスバラオ・カンバンパティ教授は、AI推論能力の研究に取り組んでおり、9月に論文を発表し、GPT-4の推論能力と計画能力を完全に否定しています。 論文住所:この教授に加えて、DeepMindとUIUC大学の最近の研究者も、推論タスクで「自己修正」するLLMの能力に疑問を呈しています。この論文は、関連する研究を行うすべての学者に、あなたの研究を真剣に受け止め、大きなモデルに正しい答えを伝えてから、いわゆる「自己修正」を実行させないように求めています。モデルが正解を知らない場合、モデルが「自己修正」した後に出力品質が低下するためです。 次に、これら2つの最新の論文を見てみましょう。## **GPT-4 "自己修正"、出力が悪い**最初の論文はGPT-4に焦点を当て、GPT-4にグラフィックスシェーディングの問題に対する解決策を提供するように依頼し、GPT-4に独自の解決策を「自己修正」させました。同時に、GPT-4の直接出力と「自己補正」サイクル後の出力を評価するための外部評価システムを導入しました。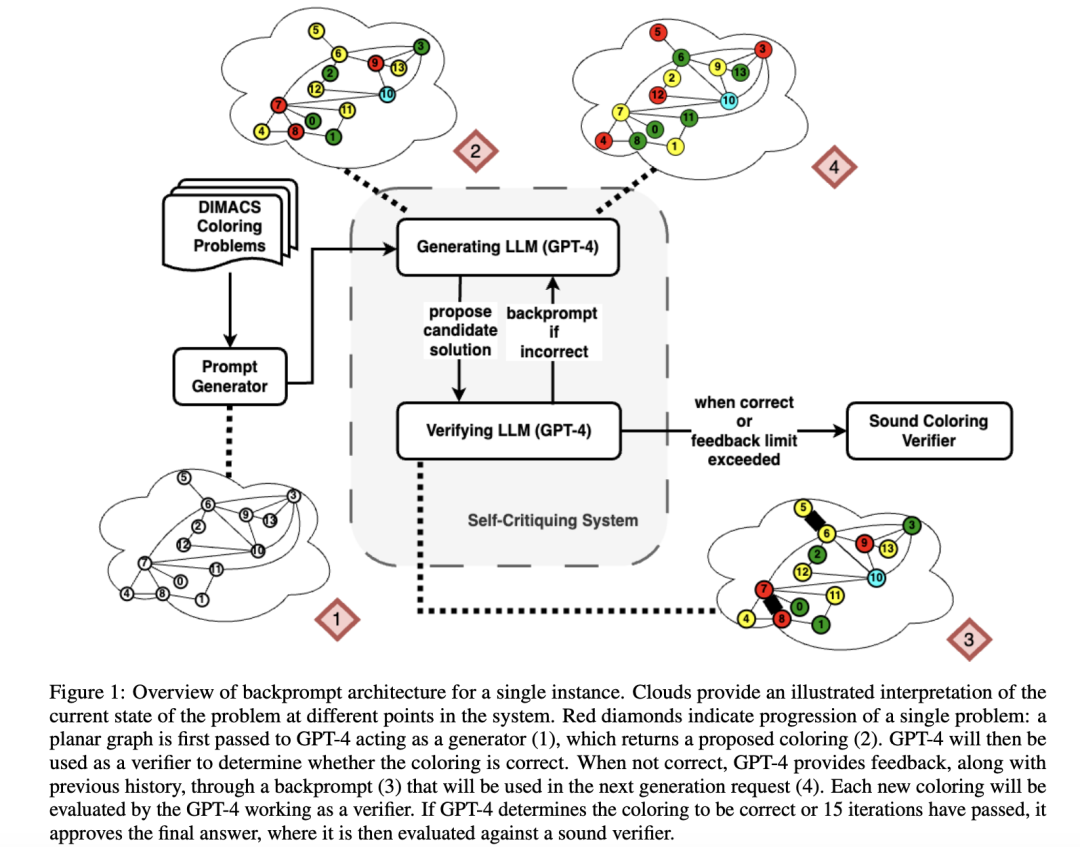 実験結果は、GPT-4が色の推測において20%未満であることを示していますが、これは驚くべきことではないようです。しかし、驚くべきことに、「自己修正」モードの精度は大幅に低下し(下の2番目のバー)、すべての自己修正の意図に完全に反しています。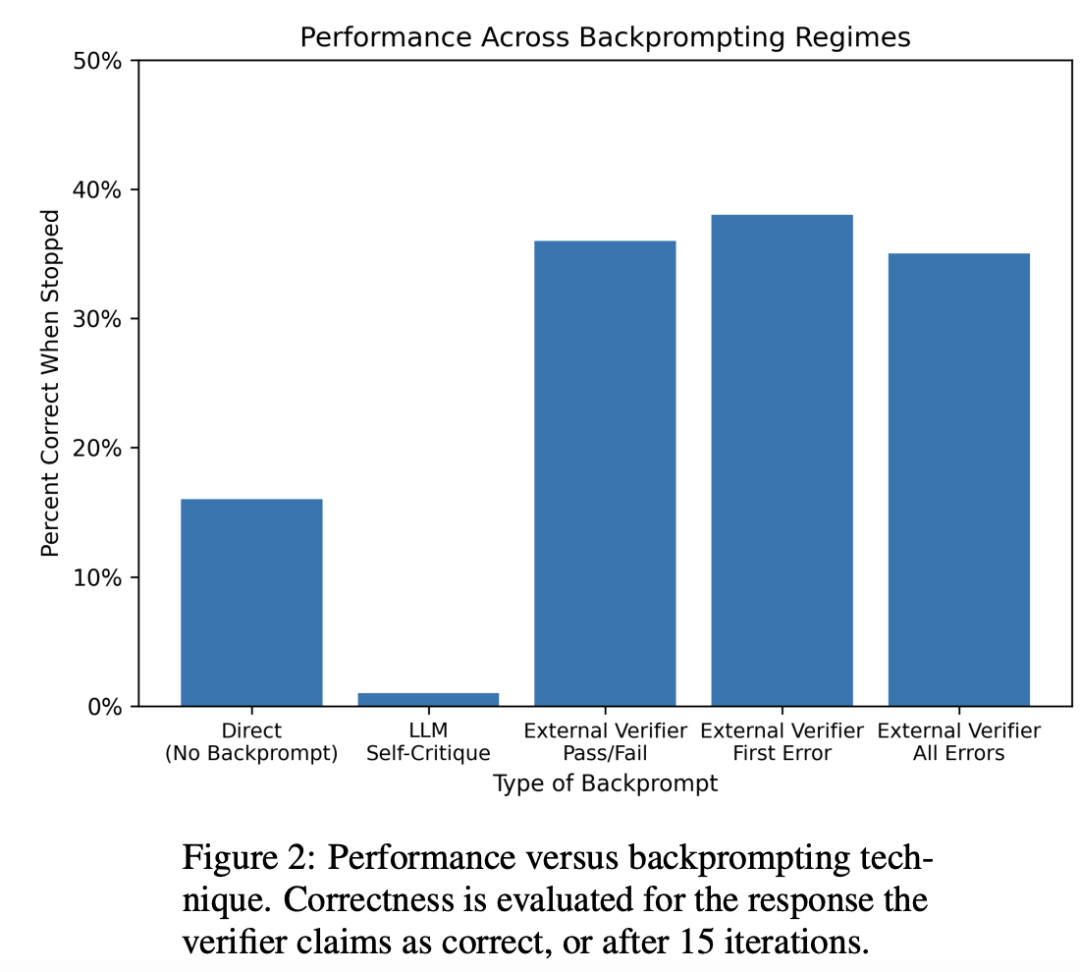 著者によると、この一見直感に反する状況はこれで説明することができます:GPT-4はまた正しい答えを検証するというひどい仕事をします!GPT-4が誤って正しい色を推測した場合でも、その「自己修正」により、正解に問題があると思わせ、正解を置き換えるからです。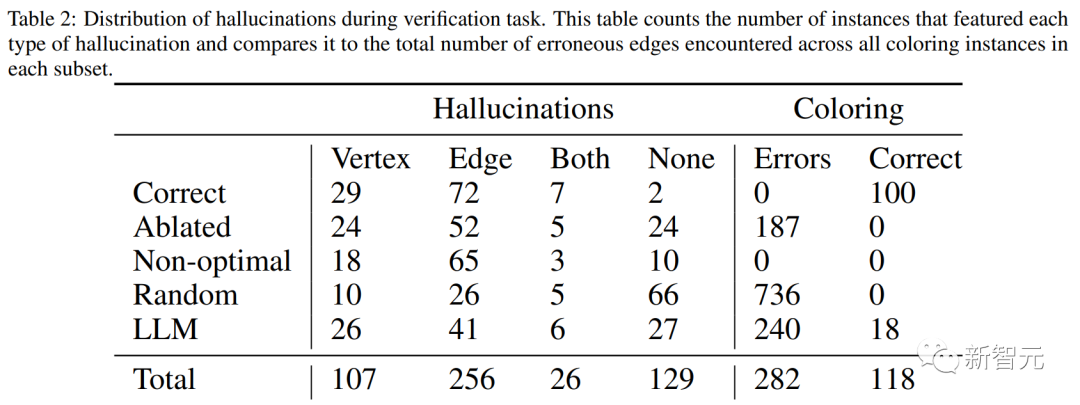 さらなる研究により、GPT-4は、外部のバリデーターが推測した色に対して検証可能な正しい答えを提供した場合、実際にソリューションを改善することもわかりました。この場合、「自己修正」によって生成されたプロンプトは、実際に出力の品質を向上させることができます(上の図のバー3〜5)要約すると、「着色問題」タスクの場合、GPT-4は答えが正しいことを検証できないため、GPT-4の独立した「自己修正」は出力のパフォーマンスを損ないます。しかし、正しい外部検証プロセスが提供されれば、GPT-4によって生成される「自己修正」は実際にパフォーマンスを向上させることができます。別の論文では、大規模な言語モデルの「自己修正」能力について、タスク計画の観点から検討し、結果は前の論文と同様でした。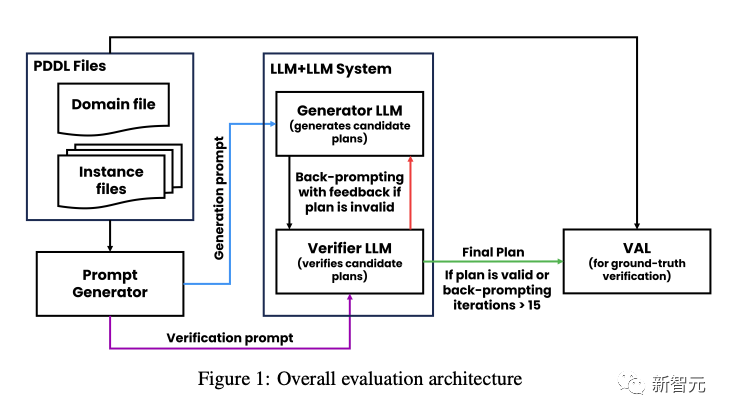 さらに、研究者たちは、出力の精度を本当に改善したのは、LLMの「自己修正」ではなく、外部の独立したバリデーターからのフィードバックであることを発見しました。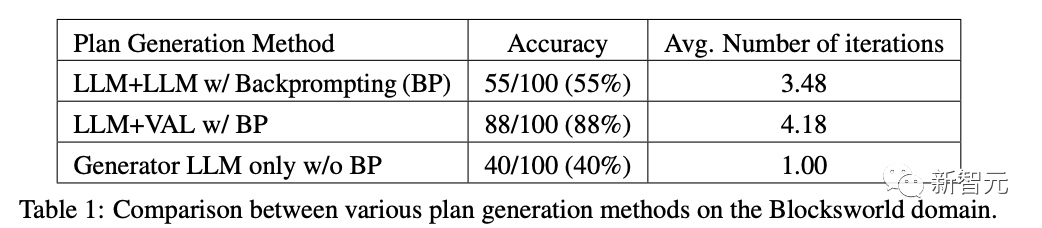 最終的な分析では、LLMは独立した検証を行う方法がなく、効果的に「自己修正」するために外部のバリデーターによって与えられた「正解」に頼らなければなりません。## **「色付け問題」のパフォーマンスが低く、LLMが独立して正解を確認できませんでした**### **研究デザインフレームワーク**「着色問題」は非常に古典的な推論問題であり、難しくなくても、答えは十分に多様であり、答えの正しさは簡単に検証できます。多様性の結果、LLMの学習データ全体を網羅することは困難であり、LLM学習データの汚染の可能性は極力回避されます。これらの理由により、「着色問題」はLLMの推論能力を研究するのに非常に適しており、推論において「自己修正」するLLMの能力を研究することも便利です。研究者は、GrinPy2を使用して一般的なグラフ操作を処理する独自のデータセットを構築しました。 各グラフは、エルドス・レニ法(̋p = 0.4)を使用して構築されます。正解が見つかると、事前に計算された色数を含むコメントとともに標準のDIMACS形式にコンパイルされます。次の実験では、研究者は、それぞれ平均24のエッジを持ち、10から17までのノードの範囲に分布する100個のインスタンスを生成しました。研究者が使用した図を下の図1に示しており、LLMの最初の応答、応答のバックプロンプト、および最終的な正しい配色が含まれています。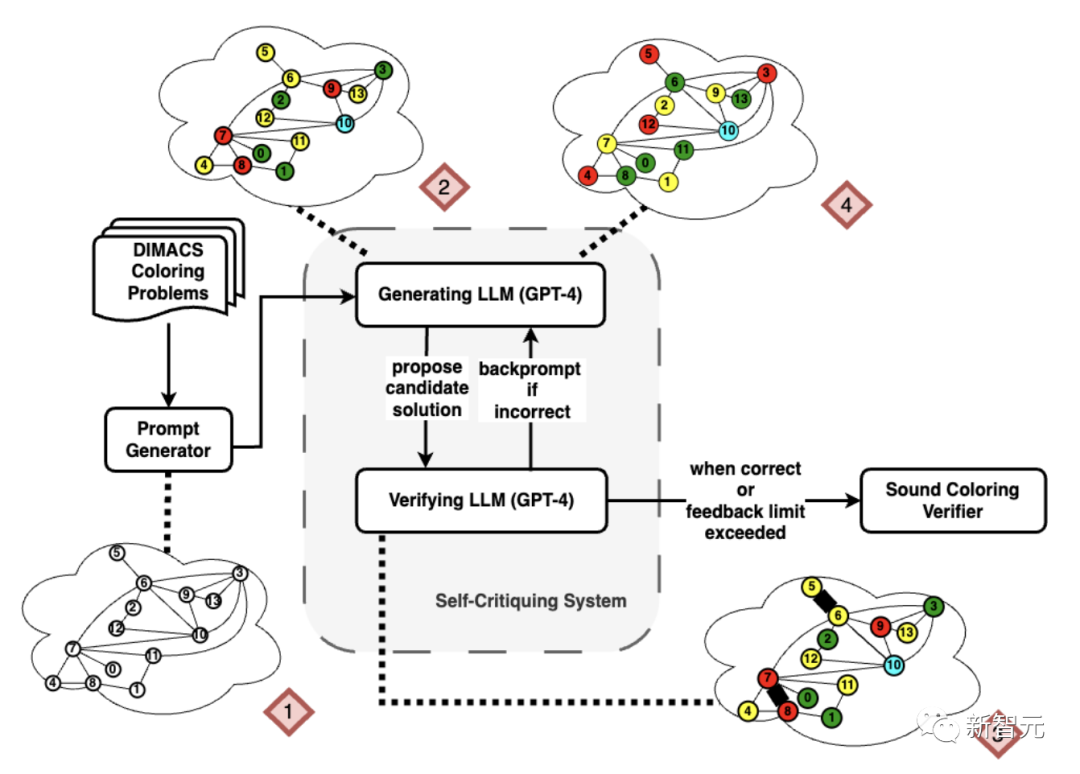 ### **反復バッキングのアーキテクチャ**プロンプトジェネレータ:このプロンプトジェネレータは、DIMACSインスタンスを受け取り、各エッジを文に変換し、全体を一連の一般的な命令でラップして自然言語プロンプトを構築します。研究者は、研究者がLLMに漏らした問題固有の情報を減らすために、異なるインスタンスプロンプトの違いを意図的に絞り込みました。 さまざまなタイプのプロンプトの例については、付録を参照してください。大規模な言語モデル:GPT-4は、現在最も先進的なモデルであるOpenAI APIを介して呼び出されます。研究者は、「あなたはさまざまなCSP(制約充足問題)を解く制約充足ソルバーです」というシステムの役割を提供します。### **バックジェネレーション**認証モードでは、LLM は異なるタイプのプロンプトを受信します。標準的な指示に加えて、それは図の説明と推奨される配色パターンだけを含みます。 そのタスクは、正確性、最適性、および各頂点が色で塗られていることを確認することです。結果の応答に矛盾するエッジのセットがある場合、色付けスキームは間違っています。各ポイントを比較するために、研究者は各矛盾するエッジをリストしたバリデーターも構築しました。LLMの回答も自然言語形式であるため、研究者は最初にそれらを分析しやすい形式に変換しました。 このプロセスの一貫性を高めるために、研究者は、モデルが従う必要のある正確な出力形式を記述するための初期ヒントを設計しました。 次に、応答の正確性が評価されます。LLM検証結果を判断するために、研究者は、提案されたシェーディングスキームのエラーを特定するのにどれだけうまく機能するかを調べます。直感的には、これらは簡単に識別できるはずです:エッジを構成する2つの頂点が色を共有している場合、すぐにそのエッジに戻ります。 アルゴリズムの観点からは、すべてのエッジを検出し、各頂点の色をそれが接続されている点の色と比較するだけで十分です。### **検証**LLMの検証能力をより深く理解するために、研究者は提案された着色スキームのエラーを特定する際のパフォーマンスを研究しました。直感的には、これらのエラーは簡単に識別できるはずです:エッジを構成する2つの頂点が色を共有している場合、エッジはすぐに返されます。 アルゴリズムの観点からは、すべてのエッジを反復処理し、各頂点の色を対応する頂点の色と比較するだけです。研究者は同じ分析プロセスを使用しましたが、研究者が色\_verificationと呼ぶ新しいドメインを構築しました。 LLMは、シェーディングの正確さ、最適性、および各頂点に色が割り当てられているかどうかをチェックするようにガイドされます。シェーディングが正しくない場合は、シェーディングのエラーを一覧表示するように指示されます。つまり、接続された 2 つのノードが色を共有している場合、エラーを表すためにそのエッジが返されます。 バックは与えられていません。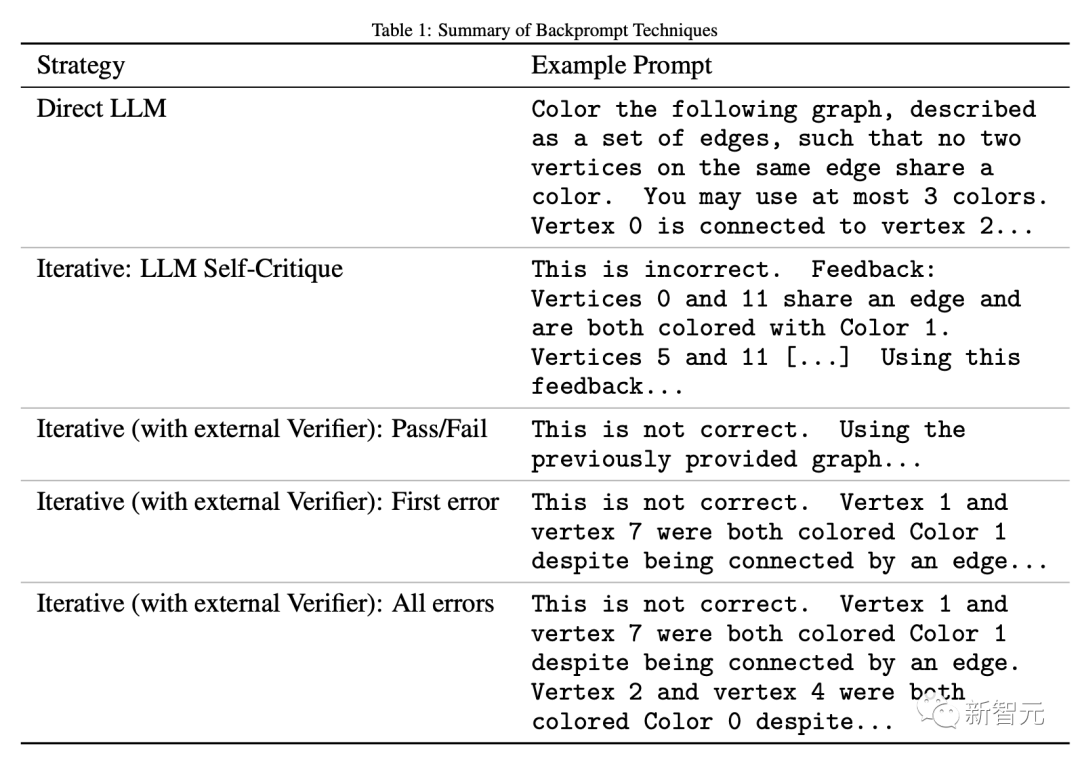 研究者は以前と同じグラフの例を使用しましたが、モデルをテストするために4つのシェーディングスキームを生成しました。正解:反復的でランダムな貪欲アルゴリズムによって生成されたエラーのない最適なシェーディングスキーム(最適性を確保するために事前に計算された色数を使用)。Ablated: ランダムなノードの色を以前のシェーディングスキームのセットからその隣接ノードに変更します。最適でない: 正しいセットでは、カラー部分がランダムに選択され、新しい色相に色が変更されます。ランダム:完全にランダムに割り当てられた色で、異なる色の数は図の色の数と同じです。LLM: 以前の実験から LLM によって生成された出力からランダムに選択された配色スキーム。## **結論**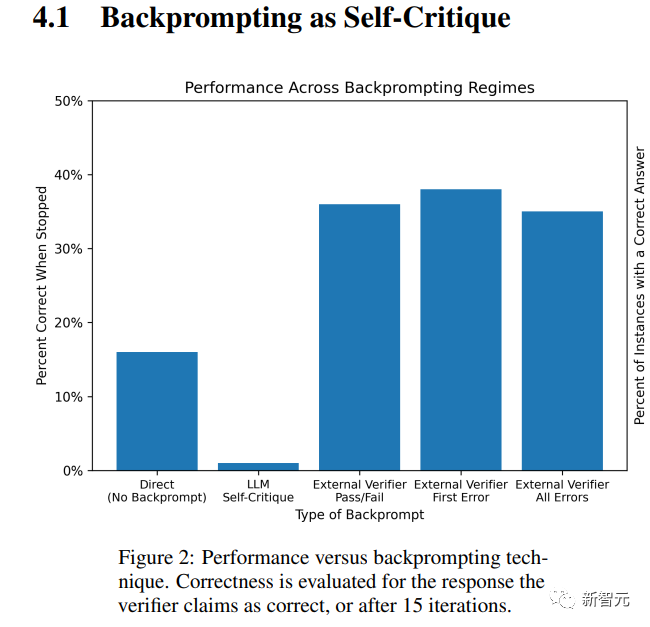 LLMがプロンプトが表示され、回答が評価され、次のインスタンスがバックなしで移動され、ベースラインスコアは16%になります。研究者が同じインスタンスを実行したが、今回はバリデーターとして機能する同じ言語モデルによって生成されたフィードバックを使用してプロンプトを返した場合、パフォーマンスは劇的に低下し、100インスタンスのうち1つだけが正解を得ました。外部資格のあるバリデーターによる戻りプロンプトの結果は、最初はより効果的であるように思われるかもしれません。正解の事例数は40%近くですが、それがGPT-4がフィードバックに基づいて耳を傾け、改善し、推論していることを意味する場合、研究者はより正確なリターンプロンプトからより良い結果を期待しています。ただし、このドメインでは、生の分数(上の図2を参照)はこれを証明しません。### **LLM 検証機能**研究者らは、同じインスタンスでグラフシェーディングスキームを検証するGPT-4の能力をテストし、インスタンスごとに5つの異なるタイプのシェーディングスキームを生成しました。明らかな結果は、上記のLLM自己修正結果とまったく同じです:モデルは、答えを正しいものとしてマークすることにほとんど消極的です。 100の最適なシェーディングスキームのうち、そのうちの2つだけが正しいことに同意します。500の配色スキームのコレクション全体のうち、118は正しいですが、そのうち30が正しいと主張しているだけです。 これらの30のうち、実際に正しいのは5つだけでした。全体として、このパターンは同じままです。 LLMは10%未満のケースで、「正しい」、「最適ではない」、または「割り当てが欠落している」と回答しました。 このような場合、動作はややランダムに見えます。約4分の1のインスタンスでは、解釈が現実に対応している間、「これは正しくない」検証で応答し、片側のみを示すことによってこれを行い、何かを誤って述べる可能性を最小限に抑えます。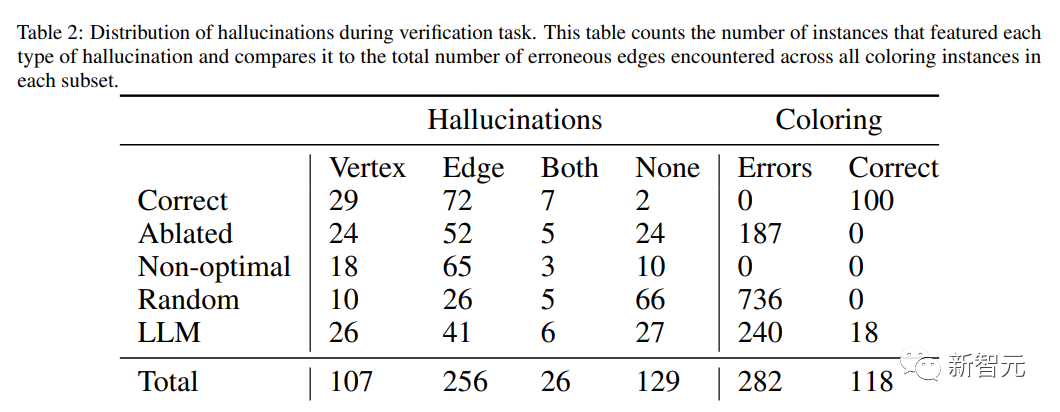 結果を上記の表2に示す。 ドメインのエラー率が増加すると、幻覚率は減少することに注意してください。 つまり、正しくないエッジが多いほど、モデルは何かがうまくいかなかった場所を指摘する可能性が高くなります。## **LLM自己批判、パフォーマンスは向上せず低下**12日に提出された論文でも、著者は上記と同じ結論に達しました。計画、単純な算術、論理のいずれであっても、現在の最先端の大規模モデルであるGPT-4は完全には機能していません。多くの研究者が、LLMが自己反復、自己検証、およびパフォーマンスを向上させるためのその他の戦略を学習できるようにするなど、それを調査および改善してきました。その結果、業界の人々は、大きなモデルがまだ救われることができると楽観的です!ただし、古典的な意味での推論タスクの複雑さは、LLMが正確な推論ではなく近似検索を使用するモデルであるため、大規模なモデルとは関係ありません。12日にarXivが発表した論文では、ASUの研究者は、タスクの計画と反復的な最適化において自己批判するLLMの能力を体系的に評価および分析しました。この研究では、著者らは、ジェネレータLLMとバリデーターLLMを含む計画システムを提案しています。 その中で、GPT-4ジェネレーターは候補プランの生成を担当し、GPT-4バリデーターはプランの正確性の検証とフィードバックの提供を担当します。その後、研究者たちはブロックスワールド計画の分野で実験を行い、以下の実証的評価を実施しました。- 自己批判がLLM+LLMシステム全体の計画発電性能に与える影響- グラウンドトゥルース検証と比較したバリデーターLLMのパフォーマンス。- LLM生成を批判する場合、同じフィードバックレベルがシステム全体のパフォーマンスに影響します。結果は、自己批判が外部の信頼できるバリデーターを使用する場合と比較して、LLM計画の生成パフォーマンスを低下させることを示しています。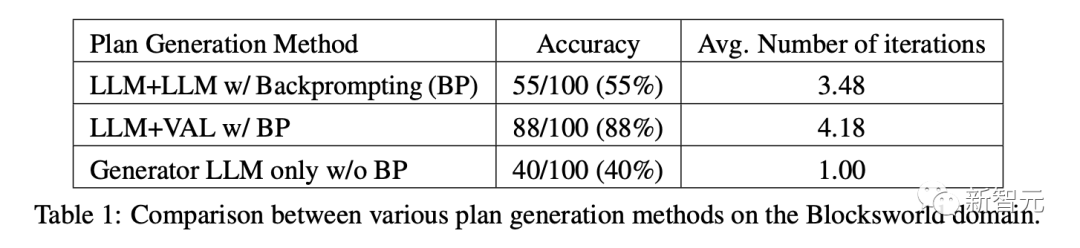 パフォーマンスの低下は、バリデーターLLMの結果が悪いことに直接起因する可能性があり、これにより多数の誤検知が生成され、システムの信頼性が著しく損なわれる可能性があります。バリデーターLLMの二項分類精度はわずか61%であり、多数の誤検知(間違ったスキームを正しいと判断する)があります。 また、フィードバックの詳細度の比較から、計画生成のパフォーマンスにはほとんど影響しないことがわかります。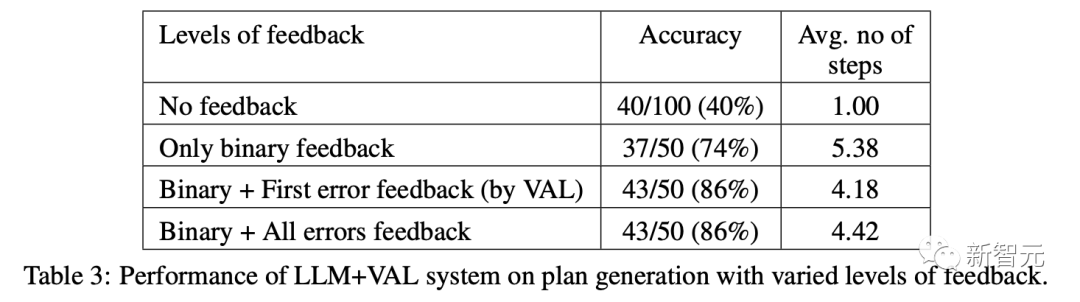 全体として、この研究の体系的な調査は、反復的で自己批判的なフレームワーク内の計画タスクの検証者としてのLLMの有効性に疑問を呈する予備的な証拠を提供します。## **著者について**スバラオ カンバンパティSubbarao Kambhampatiは、アリゾナ州立大学のコンピューターサイエンスの教授です。 Kambhampatiは、特に人間の知覚のための人工知能システムの課題によって推進される、計画と意思決定における基本的な問題を研究しています。 リソース:
GPT-4はそれが間違っていることを知りません! LLMの新しい欠陥が露呈し、自己修正の成功率はわずか1%であり、LeCun Marcusは、修正すればするほど間違っていると叫びました
原典:シン・ジユアン
大きなモデルは大きな欠陥にさらされ、同時にLeCunとMarcusの注目を集めました!
論文の共著者であるスバラオ・カンバンパティ教授は、AI推論能力の研究に取り組んでおり、9月に論文を発表し、GPT-4の推論能力と計画能力を完全に否定しています。
この教授に加えて、DeepMindとUIUC大学の最近の研究者も、推論タスクで「自己修正」するLLMの能力に疑問を呈しています。
この論文は、関連する研究を行うすべての学者に、あなたの研究を真剣に受け止め、大きなモデルに正しい答えを伝えてから、いわゆる「自己修正」を実行させないように求めています。
モデルが正解を知らない場合、モデルが「自己修正」した後に出力品質が低下するためです。
GPT-4 "自己修正"、出力が悪い
最初の論文はGPT-4に焦点を当て、GPT-4にグラフィックスシェーディングの問題に対する解決策を提供するように依頼し、GPT-4に独自の解決策を「自己修正」させました。
同時に、GPT-4の直接出力と「自己補正」サイクル後の出力を評価するための外部評価システムを導入しました。
しかし、驚くべきことに、「自己修正」モードの精度は大幅に低下し(下の2番目のバー)、すべての自己修正の意図に完全に反しています。
GPT-4が誤って正しい色を推測した場合でも、その「自己修正」により、正解に問題があると思わせ、正解を置き換えるからです。
この場合、「自己修正」によって生成されたプロンプトは、実際に出力の品質を向上させることができます(上の図のバー3〜5)
要約すると、「着色問題」タスクの場合、GPT-4は答えが正しいことを検証できないため、GPT-4の独立した「自己修正」は出力のパフォーマンスを損ないます。
しかし、正しい外部検証プロセスが提供されれば、GPT-4によって生成される「自己修正」は実際にパフォーマンスを向上させることができます。
別の論文では、大規模な言語モデルの「自己修正」能力について、タスク計画の観点から検討し、結果は前の論文と同様でした。
「色付け問題」のパフォーマンスが低く、LLMが独立して正解を確認できませんでした
研究デザインフレームワーク
「着色問題」は非常に古典的な推論問題であり、難しくなくても、答えは十分に多様であり、答えの正しさは簡単に検証できます。
多様性の結果、LLMの学習データ全体を網羅することは困難であり、LLM学習データの汚染の可能性は極力回避されます。
これらの理由により、「着色問題」はLLMの推論能力を研究するのに非常に適しており、推論において「自己修正」するLLMの能力を研究することも便利です。
研究者は、GrinPy2を使用して一般的なグラフ操作を処理する独自のデータセットを構築しました。 各グラフは、エルドス・レニ法(̋p = 0.4)を使用して構築されます。
正解が見つかると、事前に計算された色数を含むコメントとともに標準のDIMACS形式にコンパイルされます。
次の実験では、研究者は、それぞれ平均24のエッジを持ち、10から17までのノードの範囲に分布する100個のインスタンスを生成しました。
研究者が使用した図を下の図1に示しており、LLMの最初の応答、応答のバックプロンプト、および最終的な正しい配色が含まれています。
プロンプトジェネレータ:
このプロンプトジェネレータは、DIMACSインスタンスを受け取り、各エッジを文に変換し、全体を一連の一般的な命令でラップして自然言語プロンプトを構築します。
研究者は、研究者がLLMに漏らした問題固有の情報を減らすために、異なるインスタンスプロンプトの違いを意図的に絞り込みました。 さまざまなタイプのプロンプトの例については、付録を参照してください。
大規模な言語モデル:
GPT-4は、現在最も先進的なモデルであるOpenAI APIを介して呼び出されます。
研究者は、「あなたはさまざまなCSP(制約充足問題)を解く制約充足ソルバーです」というシステムの役割を提供します。
バックジェネレーション
認証モードでは、LLM は異なるタイプのプロンプトを受信します。
標準的な指示に加えて、それは図の説明と推奨される配色パターンだけを含みます。 そのタスクは、正確性、最適性、および各頂点が色で塗られていることを確認することです。
結果の応答に矛盾するエッジのセットがある場合、色付けスキームは間違っています。
各ポイントを比較するために、研究者は各矛盾するエッジをリストしたバリデーターも構築しました。
LLMの回答も自然言語形式であるため、研究者は最初にそれらを分析しやすい形式に変換しました。 このプロセスの一貫性を高めるために、研究者は、モデルが従う必要のある正確な出力形式を記述するための初期ヒントを設計しました。 次に、応答の正確性が評価されます。
LLM検証結果を判断するために、研究者は、提案されたシェーディングスキームのエラーを特定するのにどれだけうまく機能するかを調べます。
直感的には、これらは簡単に識別できるはずです:エッジを構成する2つの頂点が色を共有している場合、すぐにそのエッジに戻ります。 アルゴリズムの観点からは、すべてのエッジを検出し、各頂点の色をそれが接続されている点の色と比較するだけで十分です。
検証
LLMの検証能力をより深く理解するために、研究者は提案された着色スキームのエラーを特定する際のパフォーマンスを研究しました。
直感的には、これらのエラーは簡単に識別できるはずです:エッジを構成する2つの頂点が色を共有している場合、エッジはすぐに返されます。 アルゴリズムの観点からは、すべてのエッジを反復処理し、各頂点の色を対応する頂点の色と比較するだけです。
研究者は同じ分析プロセスを使用しましたが、研究者が色_verificationと呼ぶ新しいドメインを構築しました。 LLMは、シェーディングの正確さ、最適性、および各頂点に色が割り当てられているかどうかをチェックするようにガイドされます。
シェーディングが正しくない場合は、シェーディングのエラーを一覧表示するように指示されます。つまり、接続された 2 つのノードが色を共有している場合、エラーを表すためにそのエッジが返されます。 バックは与えられていません。
正解:反復的でランダムな貪欲アルゴリズムによって生成されたエラーのない最適なシェーディングスキーム(最適性を確保するために事前に計算された色数を使用)。
Ablated: ランダムなノードの色を以前のシェーディングスキームのセットからその隣接ノードに変更します。
最適でない: 正しいセットでは、カラー部分がランダムに選択され、新しい色相に色が変更されます。
ランダム:完全にランダムに割り当てられた色で、異なる色の数は図の色の数と同じです。
LLM: 以前の実験から LLM によって生成された出力からランダムに選択された配色スキーム。
結論
研究者が同じインスタンスを実行したが、今回はバリデーターとして機能する同じ言語モデルによって生成されたフィードバックを使用してプロンプトを返した場合、パフォーマンスは劇的に低下し、100インスタンスのうち1つだけが正解を得ました。
外部資格のあるバリデーターによる戻りプロンプトの結果は、最初はより効果的であるように思われるかもしれません。
正解の事例数は40%近くですが、それがGPT-4がフィードバックに基づいて耳を傾け、改善し、推論していることを意味する場合、研究者はより正確なリターンプロンプトからより良い結果を期待しています。
ただし、このドメインでは、生の分数(上の図2を参照)はこれを証明しません。
LLM 検証機能
研究者らは、同じインスタンスでグラフシェーディングスキームを検証するGPT-4の能力をテストし、インスタンスごとに5つの異なるタイプのシェーディングスキームを生成しました。
明らかな結果は、上記のLLM自己修正結果とまったく同じです:モデルは、答えを正しいものとしてマークすることにほとんど消極的です。 100の最適なシェーディングスキームのうち、そのうちの2つだけが正しいことに同意します。
500の配色スキームのコレクション全体のうち、118は正しいですが、そのうち30が正しいと主張しているだけです。 これらの30のうち、実際に正しいのは5つだけでした。
全体として、このパターンは同じままです。 LLMは10%未満のケースで、「正しい」、「最適ではない」、または「割り当てが欠落している」と回答しました。 このような場合、動作はややランダムに見えます。
約4分の1のインスタンスでは、解釈が現実に対応している間、「これは正しくない」検証で応答し、片側のみを示すことによってこれを行い、何かを誤って述べる可能性を最小限に抑えます。
LLM自己批判、パフォーマンスは向上せず低下
12日に提出された論文でも、著者は上記と同じ結論に達しました。
計画、単純な算術、論理のいずれであっても、現在の最先端の大規模モデルであるGPT-4は完全には機能していません。
多くの研究者が、LLMが自己反復、自己検証、およびパフォーマンスを向上させるためのその他の戦略を学習できるようにするなど、それを調査および改善してきました。
その結果、業界の人々は、大きなモデルがまだ救われることができると楽観的です!
ただし、古典的な意味での推論タスクの複雑さは、LLMが正確な推論ではなく近似検索を使用するモデルであるため、大規模なモデルとは関係ありません。
12日にarXivが発表した論文では、ASUの研究者は、タスクの計画と反復的な最適化において自己批判するLLMの能力を体系的に評価および分析しました。
この研究では、著者らは、ジェネレータLLMとバリデーターLLMを含む計画システムを提案しています。
その後、研究者たちはブロックスワールド計画の分野で実験を行い、以下の実証的評価を実施しました。
自己批判がLLM+LLMシステム全体の計画発電性能に与える影響
グラウンドトゥルース検証と比較したバリデーターLLMのパフォーマンス。
LLM生成を批判する場合、同じフィードバックレベルがシステム全体のパフォーマンスに影響します。
結果は、自己批判が外部の信頼できるバリデーターを使用する場合と比較して、LLM計画の生成パフォーマンスを低下させることを示しています。
バリデーターLLMの二項分類精度はわずか61%であり、多数の誤検知(間違ったスキームを正しいと判断する)があります。
著者について
スバラオ カンバンパティ
Subbarao Kambhampatiは、アリゾナ州立大学のコンピューターサイエンスの教授です。 Kambhampatiは、特に人間の知覚のための人工知能システムの課題によって推進される、計画と意思決定における基本的な問題を研究しています。