元のソース: 量子ビット 画像ソース:無制限のAIによって生成大きなモデルの「写真を読む」能力はとても強いのに、なぜ間違ったものを探し続けるのですか?たとえば、見た目の悪いコウモリをラケットと混同したり、一部のデータセットで珍しい魚を認識しなかったり... これは、大きなモデルに「何かを見つけさせる」ときに、**テキスト**を入力することが多いためです。説明が曖昧または部分的すぎる場合、「バット」(バットまたはビート? または「キプリノドンディアボリス」とAIは混乱します。これにより、**オブジェクト検出**、特にオープンワールド(未知のシーン)オブジェクト検出タスクを実行するために大規模なモデルが使用されるようになり、効果が期待したほど良くないことがよくあります。さて、NeurIPS 2023に含まれる論文がついにこの問題を解決しました。 本稿では,入力に画像例を追加するだけでよいマルチモーダルクエリに基づく物体検出手法**MQ-Det**を提案する.ベンチマーク検出データセットLVISでは、MQ-Detは主流検出大規模モデルのGLIP精度を平均約7.8%向上させ、13のベンチマーク小規模サンプルダウンストリームタスクの精度を平均6.3%向上させます。これはどの程度正確に行われますか? 見てみましょう。以下は、論文の著者であるZhihuブロガー@Qinyuanxiaからの複製です。 ## **目次** * MQ-Det: マルチモーダルクエリのためのオープンワールドオブジェクト検出大規模モデル* 1.1 テキストクエリからマルチモーダルクエリへ* 1.2 MQ-Det プラグアンドプレイマルチモーダルクエリモデルアーキテクチャ* 1.3 MQ-Det 効率的なトレーニング戦略※1.4 実験結果:ファインチューニングフリー評価*1.5 実験結果:少ショット評価* 1.6 物体検出の見通しのマルチモーダルクエリ ## MQ-Det: マルチモーダルクエリのためのオープンワールドオブジェクト検出の大規模モデル** 野生でのマルチモーダルクエリオブジェクト検出**論文リンク:**コードアドレス:** ### **1.1 テキスト クエリからマルチモーダル クエリへ****1枚の写真は千の言葉の価値があります**:グラフィックの事前トレーニングの台頭により、テキストのオープンセマンティクスの助けを借りて、オブジェクト検出は徐々にオープンワールド知覚の段階に入りました。 このため、多くの大規模な検出モデルは、テキスト クエリのパターン、つまり、カテゴリ テキストの説明を使用してターゲット イメージ内の潜在的なターゲットをクエリします。 しかし、このアプローチはしばしば「広範だが洗練されていない」という問題に直面します。たとえば、(1)図1の細粒物体(フィンガリング)検出は、限られたテキストでさまざまな細粒の種を説明するのが難しい場合が多く、(2)カテゴリのあいまいさ(「バット」はバットとラケットの両方を指す場合があります)。しかし、上記の問題は、テキストよりもターゲットオブジェクトに豊富な特徴の手がかりを提供する画像例によって解決できますが、同時にテキストは**強い一般化**を持っています。したがって、2つのクエリメソッドを有機的に組み合わせる方法は自然なアイデアになりました。マルチモーダルクエリ機能の取得の難しさ:マルチモーダルクエリでこのようなモデルを取得する方法には、次の3つの課題があります。 (1)限られた画像例で直接微調整すると、壊滅的な忘却につながりやすくなります。 (2)大規模な検出モデルをゼロからトレーニングすると、一般化は適切ですが、たとえば、シングルカードトレーニングGLIPでは、3,000万データ量で480日間のトレーニングが必要です。マルチモーダルクエリオブジェクトの検出:上記の考慮事項に基づいて、著者はシンプルで効果的なモデル設計とトレーニング戦略を提案します-MQ-Det。MQ-Devは、既存のフリーズされたテキストクエリ検出大規模モデルに基づいて視覚的な例の入力を受け取るために少数のゲート認識モジュール(GCP)を挿入し、高性能マルチモーダルクエリの検出器を効率的に取得するための視覚条件マスク言語予測トレーニング戦略を設計します。### **1.2 MQ-Det プラグアンドプレイマルチモーダルクエリモデルアーキテクチャ**######**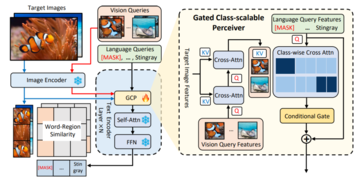 **####### **△**図1 MQ-Detメソッドアーキテクチャ図**ゲート知覚モジュール**図1に示すように、著者は、既存のフリーズされたテキストクエリ検出大規模モデルのテキストエンコーダー側にゲーティング認識モジュール(GCP)をレイヤーごとに挿入し、GCPの動作モードは次の式で簡潔に表すことができます。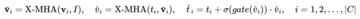 i番目のカテゴリには、最初にターゲット画像Iとのクロスアテンション(X-MHA)を行う視覚的な例Viを入力します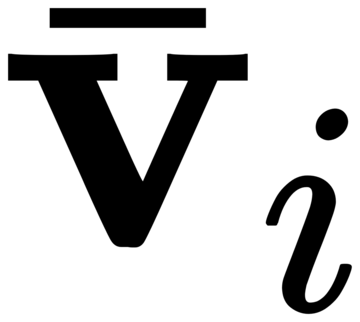 その表現能力を広げ、次に各カテゴリテキストTIと対応するカテゴリの視覚的な例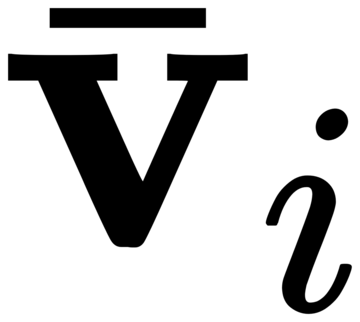 クロスアテンションを実行する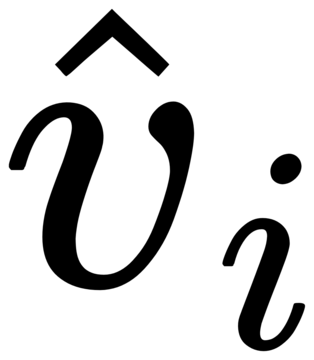 その後、元のテキストtiとテキストの視覚的な拡張がゲーティングモジュールゲートによって強化されます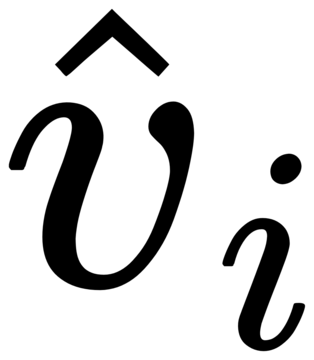 現在のレイヤーの出力を取得するための融合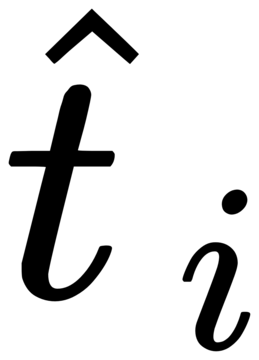 。 このシンプルな設計は、次の 3 つの原則に従います。 (2)意味的完全性。 (3)反健忘症、具体的な議論は原文にあります。### **1.3 MQ-Det 効率的なトレーニング戦略****凍結言語クエリ検出器に基づく変調トレーニング**テキストクエリ自体の現在のトレーニング前の検出大規模モデルは優れた一般化を持っているため、著者は、元のテキストの特徴に基づいて視覚的な詳細をわずかに調整するだけでよいと考えています。この記事では、元の事前トレーニング済みモデルのパラメータを開いて微調整した後、壊滅的な忘却を引き起こすのは簡単であるという特定の実験的デモンストレーションもありますが、オープンワールド検出の能力は失われます。したがって、MQ-Detは、フリーズしたテキストクエリの事前トレーニング済み検出器に基づいて、既存のテキストクエリの検出器に視覚情報を効率的に挿入し、トレーニングによって挿入されたGCPモジュールのみを変調できます。本論文では、MQ-Detの構造設計と学習技術を現在のSOTAモデルであるGLIPとGroundingDINOにそれぞれ適用し、この方法の汎用性を検証しています。**視覚条件によるマスク言語予測トレーニング戦略**また、著者たちは、事前学習済みモデルのフリーズによって引き起こされる学習怠惰の問題を解決するために、視覚的に条件付けされたマスキング言語予測学習戦略を提案している。いわゆる学習怠惰とは、検出器がトレーニングプロセス中に元のテキストクエリの特性を維持する傾向があるため、新しく追加されたビジュアルクエリ機能を無視することを意味します。この目的のために、MQ-Det はトレーニング中にランダムに使用されます[MASK] token はテキスト トークンを置き換え、モデルにビジュアル クエリ機能側からの学習を強制します。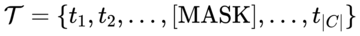 この戦略は単純ですが、非常に効果的であり、実験結果から、この戦略は大幅なパフォーマンスの向上をもたらしました。### **1.4 実験結果:ファインチューニングフリー評価**ファインチューニングフリー:MQ-Detは、カテゴリテキストのみを使用する従来のゼロショット評価と比較して、より実用的な評価戦略を提案します:*ファインチューニングフリー*。 これは、カテゴリテキスト、画像例、または両方の組み合わせを使用したオブジェクト検出として定義され、ダウンストリームの微調整はありません。ファインチューニングフリー設定では、MQ-Detはカテゴリごとに5つの視覚的な例を選択し、オブジェクト検出用のカテゴリテキストを結合しますが、他の既存のモデルはビジュアルクエリをサポートしておらず、オブジェクト検出にはプレーンテキストの説明のみを使用できます。 次の表は、LVIS MiniVal と LVIS v1.0 での結果を示しています。 マルチモーダルクエリの導入により、オープンワールドのオブジェクト検出機能が大幅に向上したことがわかります。######**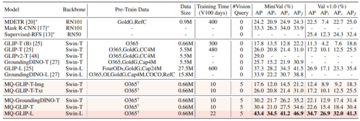 **###### **△**表1 LVISベンチマークデータセットにおける各検出モデルのファインチューニングフリー性能表1からわかるように、MQ-GLIP-LはGLIP-Lに基づいてAPを7%以上改善しており、その効果は非常に大きいです。### **1.5 実験結果:少数ショット評価**######**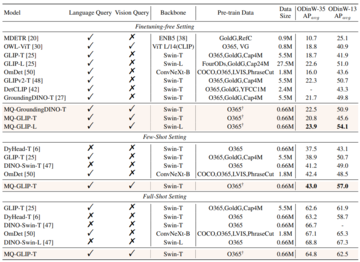 **#### **△**表2 ODinW-35 における各モデルと ODinW-13 の 13 サブセットの 35 の検出タスクにおけるパフォーマンス著者らはさらに、下流の35検出タスクであるODinW-35で包括的な実験を行った。 表2からわかるように、MQ-Detは強力なファインチューニングフリーパフォーマンスを備えているだけでなく、優れた少量サンプル検出機能も備えており、マルチモーダルクエリの可能性をさらに確認しています。 図2は、MQ-DetからGLIPへの大幅な改善も示しています。######**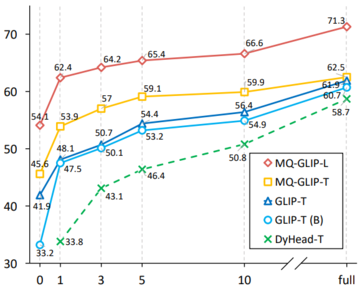 **###### **△**図2 データ利用効率の比較 横軸:トレーニングサンプルの数、縦軸:OdinW-13の平均AP### **1.6 マルチモーダルクエリオブジェクト検出の展望**実用的なアプリケーションに基づく研究分野として、物体検出はアルゴリズムの着陸に大きな注意を払っています。以前のプレーンテキストクエリオブジェクト検出モデルは優れた一般化を示していますが、実際のオープンワールド検出中国語ではきめ細かい情報をカバーすることは困難であり、画像の豊富な情報粒度がこのリンクを完全に完成させます。これまでのところ、テキストは一般的であるが正確ではなく、画像は正確であるが一般的ではないことがわかり、2つ、つまりマルチモーダルクエリを効果的に組み合わせることができれば、オープンワールドのオブジェクト検出がさらに進むようになります。MQ-Detはマルチモーダルクエリの第一歩を踏み出し、その大幅なパフォーマンスの向上は、マルチモーダルクエリターゲット検出の大きな可能性も示しています。同時に、テキストの説明と視覚的な例の導入により、ユーザーはより多くの選択肢を利用でき、オブジェクト検出がより柔軟でユーザーフレンドリーになります。元のリンク:
タイピング作業よりも大きなモデルに図を見てもらいましょう! NeurIPS 2023の新しい調査では、マルチモーダルクエリ手法が提案され、精度が7.8%向上
元のソース: 量子ビット
大きなモデルの「写真を読む」能力はとても強いのに、なぜ間違ったものを探し続けるのですか?
たとえば、見た目の悪いコウモリをラケットと混同したり、一部のデータセットで珍しい魚を認識しなかったり...
説明が曖昧または部分的すぎる場合、「バット」(バットまたはビート? または「キプリノドンディアボリス」とAIは混乱します。
これにより、オブジェクト検出、特にオープンワールド(未知のシーン)オブジェクト検出タスクを実行するために大規模なモデルが使用されるようになり、効果が期待したほど良くないことがよくあります。
さて、NeurIPS 2023に含まれる論文がついにこの問題を解決しました。
ベンチマーク検出データセットLVISでは、MQ-Detは主流検出大規模モデルのGLIP精度を平均約7.8%向上させ、13のベンチマーク小規模サンプルダウンストリームタスクの精度を平均6.3%向上させます。
これはどの程度正確に行われますか? 見てみましょう。
以下は、論文の著者であるZhihuブロガー@Qinyuanxiaからの複製です。
目次
MQ-Det: マルチモーダルクエリのためのオープンワールドオブジェクト検出の大規模モデル**
野生でのマルチモーダルクエリオブジェクト検出
論文リンク:
コードアドレス:**
1枚の写真は千の言葉の価値があります:グラフィックの事前トレーニングの台頭により、テキストのオープンセマンティクスの助けを借りて、オブジェクト検出は徐々にオープンワールド知覚の段階に入りました。 このため、多くの大規模な検出モデルは、テキスト クエリのパターン、つまり、カテゴリ テキストの説明を使用してターゲット イメージ内の潜在的なターゲットをクエリします。 しかし、このアプローチはしばしば「広範だが洗練されていない」という問題に直面します。
たとえば、(1)図1の細粒物体(フィンガリング)検出は、限られたテキストでさまざまな細粒の種を説明するのが難しい場合が多く、(2)カテゴリのあいまいさ(「バット」はバットとラケットの両方を指す場合があります)。
しかし、上記の問題は、テキストよりもターゲットオブジェクトに豊富な特徴の手がかりを提供する画像例によって解決できますが、同時にテキストは強い一般化を持っています。
したがって、2つのクエリメソッドを有機的に組み合わせる方法は自然なアイデアになりました。
マルチモーダルクエリ機能の取得の難しさ:マルチモーダルクエリでこのようなモデルを取得する方法には、次の3つの課題があります。 (1)限られた画像例で直接微調整すると、壊滅的な忘却につながりやすくなります。 (2)大規模な検出モデルをゼロからトレーニングすると、一般化は適切ですが、たとえば、シングルカードトレーニングGLIPでは、3,000万データ量で480日間のトレーニングが必要です。
マルチモーダルクエリオブジェクトの検出:上記の考慮事項に基づいて、著者はシンプルで効果的なモデル設計とトレーニング戦略を提案します-MQ-Det。
MQ-Devは、既存のフリーズされたテキストクエリ検出大規模モデルに基づいて視覚的な例の入力を受け取るために少数のゲート認識モジュール(GCP)を挿入し、高性能マルチモーダルクエリの検出器を効率的に取得するための視覚条件マスク言語予測トレーニング戦略を設計します。
1.2 MQ-Det プラグアンドプレイマルチモーダルクエリモデルアーキテクチャ
** **####### △図1 MQ-Detメソッドアーキテクチャ図
**####### △図1 MQ-Detメソッドアーキテクチャ図
ゲート知覚モジュール
図1に示すように、著者は、既存のフリーズされたテキストクエリ検出大規模モデルのテキストエンコーダー側にゲーティング認識モジュール(GCP)をレイヤーごとに挿入し、GCPの動作モードは次の式で簡潔に表すことができます。
1.3 MQ-Det 効率的なトレーニング戦略
凍結言語クエリ検出器に基づく変調トレーニング
テキストクエリ自体の現在のトレーニング前の検出大規模モデルは優れた一般化を持っているため、著者は、元のテキストの特徴に基づいて視覚的な詳細をわずかに調整するだけでよいと考えています。
この記事では、元の事前トレーニング済みモデルのパラメータを開いて微調整した後、壊滅的な忘却を引き起こすのは簡単であるという特定の実験的デモンストレーションもありますが、オープンワールド検出の能力は失われます。
したがって、MQ-Detは、フリーズしたテキストクエリの事前トレーニング済み検出器に基づいて、既存のテキストクエリの検出器に視覚情報を効率的に挿入し、トレーニングによって挿入されたGCPモジュールのみを変調できます。
本論文では、MQ-Detの構造設計と学習技術を現在のSOTAモデルであるGLIPとGroundingDINOにそれぞれ適用し、この方法の汎用性を検証しています。
視覚条件によるマスク言語予測トレーニング戦略
また、著者たちは、事前学習済みモデルのフリーズによって引き起こされる学習怠惰の問題を解決するために、視覚的に条件付けされたマスキング言語予測学習戦略を提案している。
いわゆる学習怠惰とは、検出器がトレーニングプロセス中に元のテキストクエリの特性を維持する傾向があるため、新しく追加されたビジュアルクエリ機能を無視することを意味します。
この目的のために、MQ-Det はトレーニング中にランダムに使用されます[MASK] token はテキスト トークンを置き換え、モデルにビジュアル クエリ機能側からの学習を強制します。
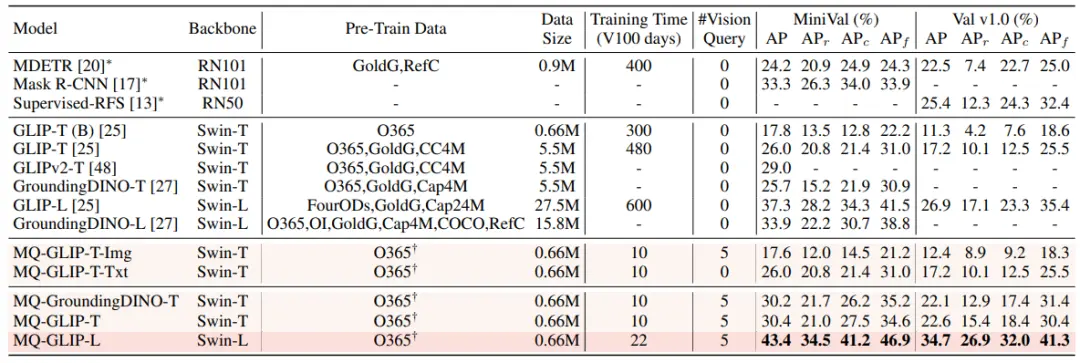
1.4 実験結果:ファインチューニングフリー評価
ファインチューニングフリー:MQ-Detは、カテゴリテキストのみを使用する従来のゼロショット評価と比較して、より実用的な評価戦略を提案します:ファインチューニングフリー。 これは、カテゴリテキスト、画像例、または両方の組み合わせを使用したオブジェクト検出として定義され、ダウンストリームの微調整はありません。
ファインチューニングフリー設定では、MQ-Detはカテゴリごとに5つの視覚的な例を選択し、オブジェクト検出用のカテゴリテキストを結合しますが、他の既存のモデルはビジュアルクエリをサポートしておらず、オブジェクト検出にはプレーンテキストの説明のみを使用できます。 次の表は、LVIS MiniVal と LVIS v1.0 での結果を示しています。 マルチモーダルクエリの導入により、オープンワールドのオブジェクト検出機能が大幅に向上したことがわかります。
** **###### △表1 LVISベンチマークデータセットにおける各検出モデルのファインチューニングフリー性能
**###### △表1 LVISベンチマークデータセットにおける各検出モデルのファインチューニングフリー性能
表1からわかるように、MQ-GLIP-LはGLIP-Lに基づいてAPを7%以上改善しており、その効果は非常に大きいです。
1.5 実験結果:少数ショット評価
**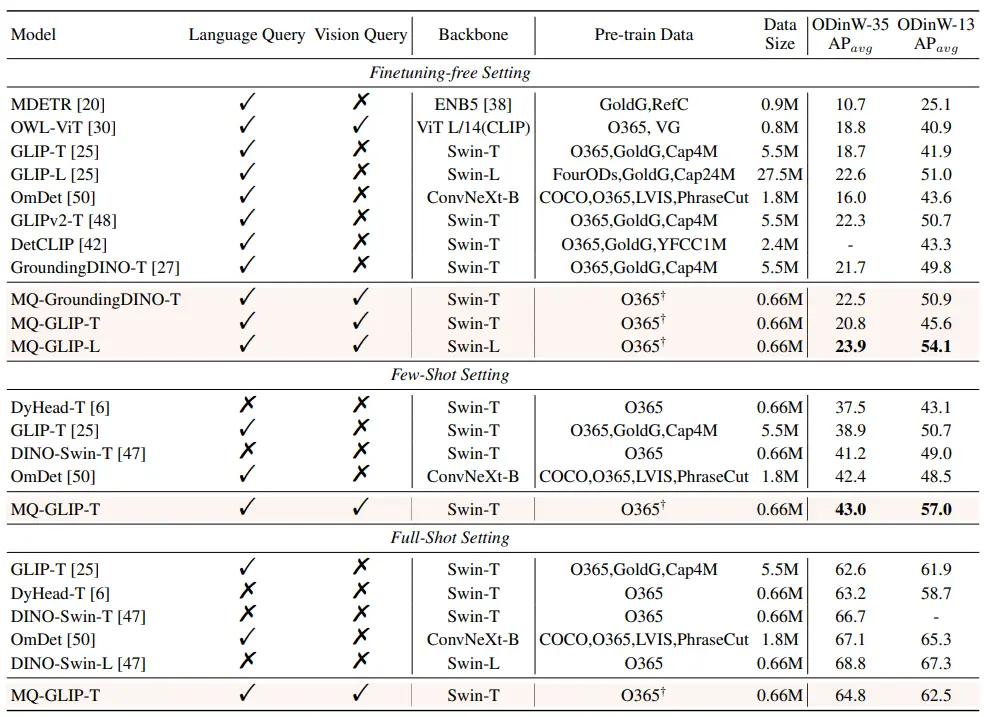 **#### △表2 ODinW-35 における各モデルと ODinW-13 の 13 サブセットの 35 の検出タスクにおけるパフォーマンス
**#### △表2 ODinW-35 における各モデルと ODinW-13 の 13 サブセットの 35 の検出タスクにおけるパフォーマンス
著者らはさらに、下流の35検出タスクであるODinW-35で包括的な実験を行った。 表2からわかるように、MQ-Detは強力なファインチューニングフリーパフォーマンスを備えているだけでなく、優れた少量サンプル検出機能も備えており、マルチモーダルクエリの可能性をさらに確認しています。 図2は、MQ-DetからGLIPへの大幅な改善も示しています。
**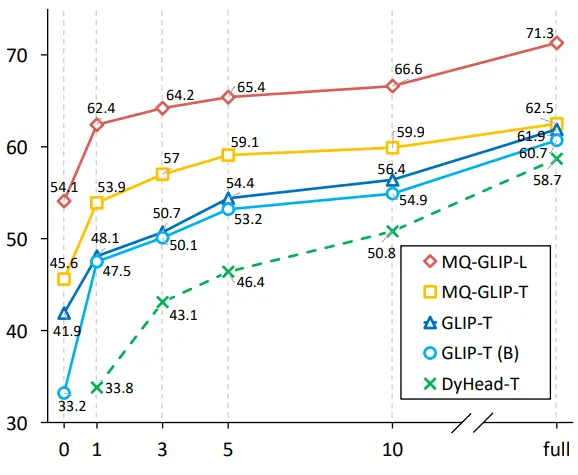 **###### △図2 データ利用効率の比較 横軸:トレーニングサンプルの数、縦軸:OdinW-13の平均AP
**###### △図2 データ利用効率の比較 横軸:トレーニングサンプルの数、縦軸:OdinW-13の平均AP
1.6 マルチモーダルクエリオブジェクト検出の展望
実用的なアプリケーションに基づく研究分野として、物体検出はアルゴリズムの着陸に大きな注意を払っています。
以前のプレーンテキストクエリオブジェクト検出モデルは優れた一般化を示していますが、実際のオープンワールド検出中国語ではきめ細かい情報をカバーすることは困難であり、画像の豊富な情報粒度がこのリンクを完全に完成させます。
これまでのところ、テキストは一般的であるが正確ではなく、画像は正確であるが一般的ではないことがわかり、2つ、つまりマルチモーダルクエリを効果的に組み合わせることができれば、オープンワールドのオブジェクト検出がさらに進むようになります。
MQ-Detはマルチモーダルクエリの第一歩を踏み出し、その大幅なパフォーマンスの向上は、マルチモーダルクエリターゲット検出の大きな可能性も示しています。
同時に、テキストの説明と視覚的な例の導入により、ユーザーはより多くの選択肢を利用でき、オブジェクト検出がより柔軟でユーザーフレンドリーになります。
元のリンク: