原典:シン・ジユアンDeepMind>研究者は、LLMには固有の欠陥があることを発見しました—データセットに真実のラベルが事前設定されていない限り、推論中に自己修正することによってより良い応答を得ることはできません。 マーカスは喜んで再び紙を転送しました。 画像ソース:無制限のAIによって生成大きな言語モデルのもう一つの大きな欠陥は、DeepMindによって明らかにされました!LLMは、独自の推論の誤りを修正することはできません。自己修正は、モデルが独自の回答を修正できるようにする手法であり、多くの種類のタスクでモデルの出力品質を大幅に向上させることができます。しかし最近、Google DeepMindとUIUCの研究者は、LLMの「自己修正メカニズム」が突然推論タスクに役に立たなくなったことを発見しました。 さらに、LLMは推論タスクに対する回答を自己修正できないだけでなく、しばしば自己修正するため、回答の質も大幅に低下します。 マーカスはまた、大きな言語モデルのこの欠陥により多くの研究者の注意を引くことを望んで、論文をリツイートしました。 「自己修正」技術は、LLMが特定の基準に従って生成されたコンテンツを修正および改善できるようにするという単純なアイデアに基づいています。 この方法では、数学の問題などのタスクにおけるモデルの出力品質を大幅に向上させることができます。しかし、研究者たちは、推論タスクでは、自己修正後のフィードバックが非常に良い場合もあれば、効果が非常に悪い場合もあり、パフォーマンスさえ低下することを発見しました。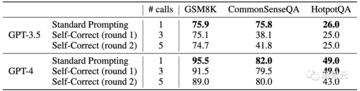 研究者たちはまた、「自己修正」が推論出力を改善できると信じていた文献を研究し、綿密な調査の結果、「自己修正」の改善は、モデルを自己修正に導くための外部情報の導入からもたらされることを発見しました。 そして、外部情報が導入されない場合、これらの改善は消えます。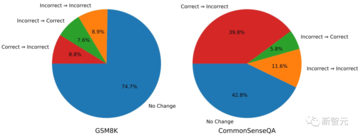 具体的には、自己修正は、モデルがベンチマークデータセットに含まれるグラウンドトゥルースラベルにアクセスできる場合に効果的に機能します。これは、アルゴリズムが推論プロセスを停止するタイミングを正確に決定し、すでに正しい場合に回答を変更できないためです。研究者たちは、モデルが正解を不正解に変更するのを防ぐために、以前の研究では実際のラベルが使用される傾向があると考えています。 しかし、この「正しい修正」の状況をどのように防ぐかは、実際には自己修正の成功を確実にするための鍵です。研究者が自己修正プロセスから真のラベルを削除すると、モデルのパフォーマンスが大幅に低下するためです。推論タスクに対するLLMの自己修正アプローチを改善する試みとして、研究者たちはまた、推論を改善する手段としての「マルチエージェント討論」の可能性を探りました。 しかし、彼らの結果は、同じ数の応答を考慮すると、この方法が自己一貫性よりもうまく機能しないことを示しています。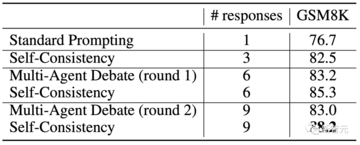 研究者たちはさらに、「プレプロンプト」と「ポストプロンプト」の概念を提案しました。彼らは、自己修正を事後プロンプトの一形態と見なしており、LLMの応答の後に修正プロンプトが入力されます。研究者の分析は、いくつかのタスクにおける自己修正の強化は、粗雑な初期プロンプトを隠す適切に設計されたフィードバックプロンプトに起因する可能性があることを示唆しています。この場合、より良いフィードバックを最初の命令に統合するか、より良い初期プロンプトを設計すると、より良い結果が得られ、推論コストが削減される可能性があります。研究者の調査結果に基づいて、研究者はLLMの自己修正能力のニュアンスを掘り下げ、研究コミュニティに自己修正研究により厳密に取り組むように促しました。大きな言語モデルは推論を自己修正できますか? **研究者らは、既存の自己修正方法を採用し、そのセットアップ(ラベルを使用して自己修正プロセスをガイドする)を使用して、LLM推論タスクのパフォーマンスを改善する効果を調べようとしました。 ## **実験のセットアップ** **プロンプトワード**研究者は、自己修正するために3段階のキュー戦略を使用しました。1)モデルの初期生成を促します(これは標準プロンプトの結果でもあります)。2)モデルに前世代をレビューし、フィードバックを生成するように促します。3)フィードバックプロンプトモデルを使用して元の質問に再度回答します。**モデル**研究者の主なテストはGPT-3.5-ターボで行われました。研究者たちはまた、OpenAIモデルの最新かつ最も強力な反復の自己修正機能をテストすることを目的として、2023年8月29日にアクセスされたGPT-4をテストしました。GPT-3.5の場合、研究者は前述の評価の完全なセットを使用しました。 GPT-4の場合、コストを削減するために、研究者はテストのためにデータセットごとに200の質問(HotpotQAの場合は100の質問)をランダムにサンプリングしました。**結果と反省**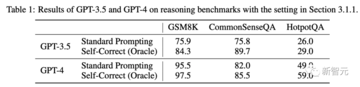 研究者は実験に外部のリソースやツールを利用しませんでしたが、研究者は以前の研究に従い、真実ラベルを使用して自己修正サイクルをいつ停止するかを決定しました。しかし、現実の世界では、特に研究者がLLMで数学的問題を解決しようとする場合、ほとんどの場合、正しい答えはわかりません。したがって、パフォーマンスの向上をより慎重に検討する必要があります。この考えを確認するために、研究者はランダムな推測に基づいてベースラインを設計しました。 このベースラインでは、研究者はいつ停止するかを決定するために真実のラベルを使用し続けます。 ただし、是正措置はLLMによって実行されず、残りのオプションのランダムな推測に基づいています。CommonSenseQAは、各質問に5つの候補オプションを提供する多肢選択式の質問データセットです。k番目のラウンド(最初の生成はラウンド0)の生成精度をxとして表すと、後続のビルドの期待される精度はx +(1 − x)/(5 − k)になります。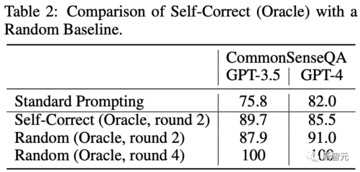 このランダムベースラインの結果を上記の表2に示す。2ラウンド後、その性能は自己校正と同等またはそれ以上になり、4ラウンド後、その精度は100%に達します。ただし、このようなランダムなベースラインが効果的な補正方法とは見なされないことは明らかです。 それでも、ラベルを使用して得られた結果はオラクルとして機能する可能性があり、答えの正しさを判断できる完璧な検証者がいることを示しています。コード生成などのタスクでは、研究者はエグゼキュータと単体テストを利用して、生成されたコードが正常に実行されるかどうかを判断できるため、これは実現可能です(Chen et al.、2023b)。ただし、数学の問題を解くなどの推論タスクの場合、この設定は直感に反しているようです。 研究者がすでに真実を持っている場合、問題を解決するためにLLMを使用する理由はないようです。**本質的な自己修正**GSM8Kの場合、同様のランダムなベースラインは存在しない可能性がありますが、理論的根拠は同じままです。さらに、研究者は、乱数を一度に1つずつ生成するなどのベースラインを設計できます。 かなりのラウンドの後、それは正しい答えを得るかもしれませんが、そのような改善は明らかに意味がありません。 より直接的な理由:研究者がすでに答えを知っているのに、なぜこれを行うのでしょうか?実験のセットアップは以前に定義されています。 これを達成するために、研究者は単に使用ラベルを削除していつ停止するかを決定し、2回の自己修正を通じてパフォーマンスを評価しました。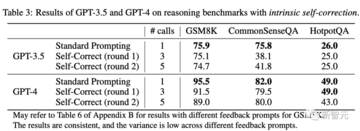 上記の表 3 は、モデル呼び出しの精度と数を示しています。 研究者らは、自己修正後、モデルのパフォーマンスがすべてのベンチマークで低下することを観察しました。 ## **パフォーマンスが低下したのはなぜですか? ** 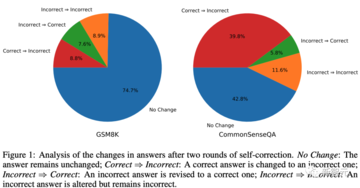 上の図1は、GPT-3.5による2回の自己修正後の回答変更の結果をまとめたもので、下の図2に2つの例を示します。 GSM8Kの場合、モデルは74.7%の確率で最初の答えを保持します。 残りの例では、モデルは、間違った答えを正しい答えに変更するよりも、正しい答えを間違った答えに変更する可能性が高かった。CommonSenseQAの場合、GPT-3.5はその答えを変える可能性が高いです。 この主な理由は、CommonSenseQAの間違った回答オプションが質問に多少関連しているように見えることが多く、自己修正ヒントを使用すると、モデルが別のオプションを選択するように偏り、「正解⇒エラー」の比率が高くなる可能性があるためです。研究者に上記の表1に示す結果をもう一度見てみましょう。 これらの結果では、真理値ラベルを使用して、モデルが正しい答えを間違った答えに変更しないようにします。しかし、この「修正ミス」をいかに防ぐかが、実は自己修正を成功させるための鍵となります。直感的な説明は、モデルが適切に設計された初期プロンプトと一致する場合、プロンプトと特定のデコードアルゴリズムが与えられた場合、初期応答はすでに最適であるはずであるということです。フィードバックの導入は、その入力の組み合わせに適合する応答を生成するようにモデルを偏らせる可能性のある追加のヒントを追加すると見なすことができます。本質的な自己修正設定では、推論タスクでは、この補足プロンプトは質問に答えるための追加の利点を提供しない場合があります。実際、モデルが最初のプロンプトに対して最適な応答を生成できないように逸脱し、パフォーマンスが低下する可能性もあります。研究者によってテストされた自己修正の手がかりは理想的ではないのか疑問に思うかもしれません。他のヒントはパフォーマンスを向上させることができますか? 答えは、研究者が特定のベンチマークでモデルのパフォーマンスを向上させるヒントを見つけることは完全に可能であるということです。 ただし、これは、この記事で説明した固有の自己修正設定とは一致しなくなり、真のサンプル数が少ない設定の説明と同様です。この検索では、基本的に人間からのフィードバックまたはトレーニングの例を活用します。 さらに、同じ戦略を効果的に適用して初期ヒントを最適化することができ、自己修正のための追加のモデル呼び出しを必要とせずに、パフォーマンスが向上する可能性があります。付録Bでは、研究者はさまざまなヒントをテストしましたが、パフォーマンスはまだ改善されていないことがわかりました。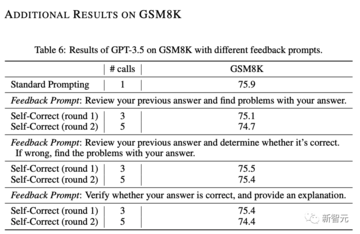 さらに、研究者は、自己修正が必ずしもLLM推論能力を向上させるとは限らないことを最初に観察したわけではありません。 要約すると、研究者の焦点は、「特定のベンチマークのパフォーマンスを向上させることができる自己修正の手がかりはありますか?」などの質問に対処することではありません。 などなど。 このようなクエリは、特に意味がない場合があります。代わりに、研究者たちは、「大規模な言語モデルは、固有の能力だけに基づいて、本当に自分で推論を修正できるのか」という、より根本的な問題を解決することを目指しています。後付けとしての自己修正**以前のコンテンツでは、研究者たちは、LLMがその推論を自己修正する際に課題に直面していることを観察しました。しかし、以前の研究が示しているように、場合によっては自己修正が印象的な結果をもたらしました。 したがって、不一致を特定し、根本原因を特定することが重要です。この問題を解決するためには、自己修正の基本的な性質を把握することが重要です。 その形では、自己修正は後付けと見なすことができます。これは、プロンプトがLLMの回答の上に作成されるという点で、標準のプロンプト(ここでは事前プロンプトと呼ばれます)とは異なります。研究者は、そのような手がかりを改善するプロセスをイベント後のプロンプトエンジニアリングと呼んでいます。したがって、自己修正は、自己修正が以前のプロンプトでは提供できない貴重なガイダンスまたはフィードバックを提供できる場合に、モデルの応答を強化します。たとえば、応答をより安全にすることが目標である場合、事前のヒントのみを使用して、最初の試行で完全にリスクのない応答を生成するようにモデルをガイドするのは難しい場合があります。 この場合、自己修正は、きめ細かな事後分析チェックを通じて応答のセキュリティを強化する手段として使用できます。ただし、これは推論タスクには当てはまらない場合があります。フィードバック プロンプト ("以前の回答を確認し、回答に関する問題を見つける" など)。 それは必ずしも推論のための具体的な利益を提供するわけではありません。また、自己補正後に大幅な性能向上が見られたとしても、迅速な設計については慎重な検討が必要である。たとえば、応答が最初の命令で簡単に指定できる基準を満たす必要がある場合(たとえば、出力に特定の単語が含まれている必要があり、生成されたコードが効率的である必要があり、感情が非常に否定的である必要があります)、これらの要件を事後分析プロンプトのフィードバックとして提供するのではなく、より費用効果の高い代替戦略は、これらの要件を事前プロンプトに直接(明示的に)埋め込むことです。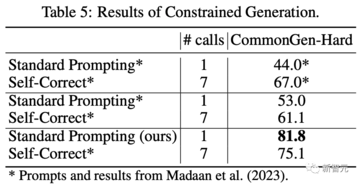 上記の表5の結果は、研究者が慎重に設計した「(研究者の)標準キュー」が先行研究の自己修正結果よりも優れていることを示しています。さらに、研究者がヒントを使用して研究者のアウトプットを改善すると、パフォーマンスも低下します。繰り返しになりますが、ここでの研究者の目標は、研究者が自由に書いたプロンプトに勝る可能性のあるポストホックプロンプトがあるかどうかを議論することではありません。 研究者の主な目標は、自己校正実験のより厳密な精査を促進することです。適切に設計された事後分析プロンプトを使用して、不適切な事前プロンプトによって生成された応答を「自己修正」するようにモデルを導くことは意味がありません。公正な比較を行うためには、イベントの前後のプロンプトに同等の努力を払う必要があります。リソース:
DeepMind:大規模なモデルも大きな欠陥にさらされており、正解が事前にわかっていない限り、自分で推論を修正することはできません
原典:シン・ジユアン
DeepMind>研究者は、LLMには固有の欠陥があることを発見しました—データセットに真実のラベルが事前設定されていない限り、推論中に自己修正することによってより良い応答を得ることはできません。 マーカスは喜んで再び紙を転送しました。
大きな言語モデルのもう一つの大きな欠陥は、DeepMindによって明らかにされました!
LLMは、独自の推論の誤りを修正することはできません。
自己修正は、モデルが独自の回答を修正できるようにする手法であり、多くの種類のタスクでモデルの出力品質を大幅に向上させることができます。
しかし最近、Google DeepMindとUIUCの研究者は、LLMの「自己修正メカニズム」が突然推論タスクに役に立たなくなったことを発見しました。
しかし、研究者たちは、推論タスクでは、自己修正後のフィードバックが非常に良い場合もあれば、効果が非常に悪い場合もあり、パフォーマンスさえ低下することを発見しました。
これは、アルゴリズムが推論プロセスを停止するタイミングを正確に決定し、すでに正しい場合に回答を変更できないためです。
研究者たちは、モデルが正解を不正解に変更するのを防ぐために、以前の研究では実際のラベルが使用される傾向があると考えています。 しかし、この「正しい修正」の状況をどのように防ぐかは、実際には自己修正の成功を確実にするための鍵です。
研究者が自己修正プロセスから真のラベルを削除すると、モデルのパフォーマンスが大幅に低下するためです。
推論タスクに対するLLMの自己修正アプローチを改善する試みとして、研究者たちはまた、推論を改善する手段としての「マルチエージェント討論」の可能性を探りました。 しかし、彼らの結果は、同じ数の応答を考慮すると、この方法が自己一貫性よりもうまく機能しないことを示しています。
彼らは、自己修正を事後プロンプトの一形態と見なしており、LLMの応答の後に修正プロンプトが入力されます。
研究者の分析は、いくつかのタスクにおける自己修正の強化は、粗雑な初期プロンプトを隠す適切に設計されたフィードバックプロンプトに起因する可能性があることを示唆しています。
この場合、より良いフィードバックを最初の命令に統合するか、より良い初期プロンプトを設計すると、より良い結果が得られ、推論コストが削減される可能性があります。
研究者の調査結果に基づいて、研究者はLLMの自己修正能力のニュアンスを掘り下げ、研究コミュニティに自己修正研究により厳密に取り組むように促しました。
大きな言語モデルは推論を自己修正できますか? **
研究者らは、既存の自己修正方法を採用し、そのセットアップ(ラベルを使用して自己修正プロセスをガイドする)を使用して、LLM推論タスクのパフォーマンスを改善する効果を調べようとしました。
実験のセットアップ
プロンプトワード
研究者は、自己修正するために3段階のキュー戦略を使用しました。
1)モデルの初期生成を促します(これは標準プロンプトの結果でもあります)。
2)モデルに前世代をレビューし、フィードバックを生成するように促します。
3)フィードバックプロンプトモデルを使用して元の質問に再度回答します。
モデル
研究者の主なテストはGPT-3.5-ターボで行われました。
研究者たちはまた、OpenAIモデルの最新かつ最も強力な反復の自己修正機能をテストすることを目的として、2023年8月29日にアクセスされたGPT-4をテストしました。
GPT-3.5の場合、研究者は前述の評価の完全なセットを使用しました。 GPT-4の場合、コストを削減するために、研究者はテストのためにデータセットごとに200の質問(HotpotQAの場合は100の質問)をランダムにサンプリングしました。
結果と反省
しかし、現実の世界では、特に研究者がLLMで数学的問題を解決しようとする場合、ほとんどの場合、正しい答えはわかりません。
したがって、パフォーマンスの向上をより慎重に検討する必要があります。
この考えを確認するために、研究者はランダムな推測に基づいてベースラインを設計しました。 このベースラインでは、研究者はいつ停止するかを決定するために真実のラベルを使用し続けます。 ただし、是正措置はLLMによって実行されず、残りのオプションのランダムな推測に基づいています。
CommonSenseQAは、各質問に5つの候補オプションを提供する多肢選択式の質問データセットです。
k番目のラウンド(最初の生成はラウンド0)の生成精度をxとして表すと、後続のビルドの期待される精度はx +(1 − x)/(5 − k)になります。
2ラウンド後、その性能は自己校正と同等またはそれ以上になり、4ラウンド後、その精度は100%に達します。
ただし、このようなランダムなベースラインが効果的な補正方法とは見なされないことは明らかです。 それでも、ラベルを使用して得られた結果はオラクルとして機能する可能性があり、答えの正しさを判断できる完璧な検証者がいることを示しています。
コード生成などのタスクでは、研究者はエグゼキュータと単体テストを利用して、生成されたコードが正常に実行されるかどうかを判断できるため、これは実現可能です(Chen et al.、2023b)。
ただし、数学の問題を解くなどの推論タスクの場合、この設定は直感に反しているようです。 研究者がすでに真実を持っている場合、問題を解決するためにLLMを使用する理由はないようです。
本質的な自己修正
GSM8Kの場合、同様のランダムなベースラインは存在しない可能性がありますが、理論的根拠は同じままです。
さらに、研究者は、乱数を一度に1つずつ生成するなどのベースラインを設計できます。 かなりのラウンドの後、それは正しい答えを得るかもしれませんが、そのような改善は明らかに意味がありません。 より直接的な理由:研究者がすでに答えを知っているのに、なぜこれを行うのでしょうか?
実験のセットアップは以前に定義されています。 これを達成するために、研究者は単に使用ラベルを削除していつ停止するかを決定し、2回の自己修正を通じてパフォーマンスを評価しました。
**パフォーマンスが低下したのはなぜですか? **
CommonSenseQAの場合、GPT-3.5はその答えを変える可能性が高いです。 この主な理由は、CommonSenseQAの間違った回答オプションが質問に多少関連しているように見えることが多く、自己修正ヒントを使用すると、モデルが別のオプションを選択するように偏り、「正解⇒エラー」の比率が高くなる可能性があるためです。
研究者に上記の表1に示す結果をもう一度見てみましょう。 これらの結果では、真理値ラベルを使用して、モデルが正しい答えを間違った答えに変更しないようにします。
しかし、この「修正ミス」をいかに防ぐかが、実は自己修正を成功させるための鍵となります。
直感的な説明は、モデルが適切に設計された初期プロンプトと一致する場合、プロンプトと特定のデコードアルゴリズムが与えられた場合、初期応答はすでに最適であるはずであるということです。
フィードバックの導入は、その入力の組み合わせに適合する応答を生成するようにモデルを偏らせる可能性のある追加のヒントを追加すると見なすことができます。
本質的な自己修正設定では、推論タスクでは、この補足プロンプトは質問に答えるための追加の利点を提供しない場合があります。
実際、モデルが最初のプロンプトに対して最適な応答を生成できないように逸脱し、パフォーマンスが低下する可能性もあります。
研究者によってテストされた自己修正の手がかりは理想的ではないのか疑問に思うかもしれません。
他のヒントはパフォーマンスを向上させることができますか? 答えは、研究者が特定のベンチマークでモデルのパフォーマンスを向上させるヒントを見つけることは完全に可能であるということです。 ただし、これは、この記事で説明した固有の自己修正設定とは一致しなくなり、真のサンプル数が少ない設定の説明と同様です。
この検索では、基本的に人間からのフィードバックまたはトレーニングの例を活用します。 さらに、同じ戦略を効果的に適用して初期ヒントを最適化することができ、自己修正のための追加のモデル呼び出しを必要とせずに、パフォーマンスが向上する可能性があります。
付録Bでは、研究者はさまざまなヒントをテストしましたが、パフォーマンスはまだ改善されていないことがわかりました。
代わりに、研究者たちは、「大規模な言語モデルは、固有の能力だけに基づいて、本当に自分で推論を修正できるのか」という、より根本的な問題を解決することを目指しています。
後付けとしての自己修正**
以前のコンテンツでは、研究者たちは、LLMがその推論を自己修正する際に課題に直面していることを観察しました。
しかし、以前の研究が示しているように、場合によっては自己修正が印象的な結果をもたらしました。
したがって、不一致を特定し、根本原因を特定することが重要です。
この問題を解決するためには、自己修正の基本的な性質を把握することが重要です。 その形では、自己修正は後付けと見なすことができます。
これは、プロンプトがLLMの回答の上に作成されるという点で、標準のプロンプト(ここでは事前プロンプトと呼ばれます)とは異なります。
研究者は、そのような手がかりを改善するプロセスをイベント後のプロンプトエンジニアリングと呼んでいます。
したがって、自己修正は、自己修正が以前のプロンプトでは提供できない貴重なガイダンスまたはフィードバックを提供できる場合に、モデルの応答を強化します。
たとえば、応答をより安全にすることが目標である場合、事前のヒントのみを使用して、最初の試行で完全にリスクのない応答を生成するようにモデルをガイドするのは難しい場合があります。 この場合、自己修正は、きめ細かな事後分析チェックを通じて応答のセキュリティを強化する手段として使用できます。
ただし、これは推論タスクには当てはまらない場合があります。
フィードバック プロンプト ("以前の回答を確認し、回答に関する問題を見つける" など)。 それは必ずしも推論のための具体的な利益を提供するわけではありません。
また、自己補正後に大幅な性能向上が見られたとしても、迅速な設計については慎重な検討が必要である。
たとえば、応答が最初の命令で簡単に指定できる基準を満たす必要がある場合(たとえば、出力に特定の単語が含まれている必要があり、生成されたコードが効率的である必要があり、感情が非常に否定的である必要があります)、これらの要件を事後分析プロンプトのフィードバックとして提供するのではなく、より費用効果の高い代替戦略は、これらの要件を事前プロンプトに直接(明示的に)埋め込むことです。
さらに、研究者がヒントを使用して研究者のアウトプットを改善すると、パフォーマンスも低下します。
繰り返しになりますが、ここでの研究者の目標は、研究者が自由に書いたプロンプトに勝る可能性のあるポストホックプロンプトがあるかどうかを議論することではありません。 研究者の主な目標は、自己校正実験のより厳密な精査を促進することです。
適切に設計された事後分析プロンプトを使用して、不適切な事前プロンプトによって生成された応答を「自己修正」するようにモデルを導くことは意味がありません。
公正な比較を行うためには、イベントの前後のプロンプトに同等の努力を払う必要があります。
リソース: