オリジナルソース: AIGCオープンコミュニティ 画像ソース:無制限のAIによって生成MidjourneyとStable Difusionは、商業的な収益化とシナリオベースのランディングで大きな成功を収めており、OpenAIは新しいビジネスチャンスを見出し、DALL· E 3の重要な理由の1つ。先週、OpenAIは、ChatGPT PlusとEnterprise Editionのユーザーの間でVenshengグラフモデルDALL· の完全な可用性を発表しました。 E3、そして同時に研究論文のまれなリリース。ダル· E 3 および前の 2 世代の DALL· E、ダル· E 2と比較して、特にChatGPTとの組み合わせで、意味理解、画質、画像修正、画像解釈、長いテキスト入力などの質的な飛躍を達成し、OpenAIの新しい切り札アプリケーションになりました。論文住所: 以下の「AIGCオープンコミュニティ」は、DALL· E3ペーパーでは、各モジュールの主な技術原理と機能について説明しています。研究者らは、テキストで生成された画像モデルでは、トレーニングデータセットの画像記述の品質が低いため、詳細な画像の説明をたどったり、プロンプト内の単語を無視したり、その意味を混乱させたりするのにさまざまな困難が生じることが多いことを発見しました。この仮説を検証するために、研究者は最初に説明画像のキャプションを生成するモデルを訓練しました。 モデルは、画像の詳細で正確な説明を生成するように注意深くトレーニングされています。 このモデルを使用してトレーニングデータセットの説明を再生成した後、研究者は元の説明と新しく生成された説明でトレーニングされた複数のテキスト生成画像モデルを比較しました。結果は、プロンプトに従うという点で、新しい説明でトレーニングされたモデルが元の記述モデルよりも大幅に優れていることを示しています。 この方法はその後、大規模なデータセットであるDALL-E 3でトレーニングされました。 DALL-E 3の技術アーキテクチャの観点から、主に画像記述生成と画像生成の2つのモジュールに分かれています。**画像記述生成モジュール**このモジュールでは、CLIP (コントラスティブ言語-画像事前トレーニング) 画像エンコーダーと GPT 言語モデル (GPT-4) を使用して、各画像の詳細なテキスト記述を生成します。小規模の主題記述データセット、大規模詳細記述データセットを構築し、生成ルールを設定することで、モジュールが出力する画像記述情報の量を大幅に増加させ、その後の画像生成を強力にサポートします。 各モジュールの主な機能は次のとおりです。**1) クリップイメージエンコーダ**CLIP は、画像のセマンティック情報を含む固定長ベクトルに画像をエンコードするトレーニング済みの画像テキスト一致モデルです。 DALL-E 3は、CLIPの画像エンコーダを利用して、条件付きテキスト生成入力の一部としてトレーニング画像を画像特徴ベクトルにエンコードします。**2) GPT 言語モデル**DALL-E 3は、GPTアーキテクチャに基づいて言語モデルを構築し、テキストシーケンスをランダムにサンプリングする結合確率を最大化することにより、一貫したテキスト記述を生成することを学習します。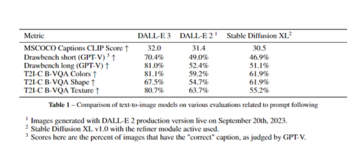 **3) 条件付きテキスト生成**上記2つを組み合わせることで、画像特徴ベクトルが前の単語列とともにGPT言語モデルに入力され、画像の条件付きテキスト生成が実現できる。 トレーニングを通じて、モジュールは各画像の詳細なDeiveの説明を生成することを学習します。**4)トレーニングの最適化**DALL-E 3のインフラストラクチャは完成しましたが、直接トレーニングの結果は、詳細な説明を生成するのに十分理想的ではありません。 したがって、研究者は以下の技術的最適化を行いました。 *小規模なデータセットを構築し、特に主題の詳細な説明を収集し、言語モデルを微調整し、画像の主題を記述する傾向があります。*大規模な詳細説明データセットを構築し、主題、背景、色、テキストなどのさまざまな側面を記述し、微調整により説明の品質をさらに向上させます。*生成された記述の長さやスタイルなどのルールを設定して、言語モデルが人間のスタイルから逸脱しないようにします。**画像生成モジュール**このモジュールは、最初にVAEを使用して高解像度の画像を低次元ベクトルに圧縮し、学習の難しさを軽減します。 次に、テキストはT5トランスフォーマーを使用してベクトルにエンコードされ、GroupNormレイヤーを介して拡散モデルに挿入され、画像生成方向をガイドします。研究者らは、拡散モデルを追加することで、画像の詳細生成の効果が大幅に向上すると考えています。 具体的なプロセスは次のとおりです。**1) 画像圧縮**高解像度の画像は、まずVAEモデルによって低次元ベクトルに圧縮され、画像生成の難しさが軽減されます。 DALL-E 3は8倍のダウンサンプリングを採用し、256pxの画像は32x32サイズの潜在ベクトルに圧縮されます。**2) テキストエンコーダ**T5 Transformer などのネットワークを使用して、テキスト プロンプトをベクトルにエンコードし、画像生成モデルに挿入します。 **3)潜在拡散**これは画像生成のコア技術であり、画像生成問題をノイズベクトルの複数の小さなスケール摂動に分解し、徐々にターゲット画像に近づきます。 重要なのは、適切な順方向と逆方向のプロセスを設計することです。4) テキストインジェクション**エンコードされたテキストベクトルは、GroupNormレイヤーを介して潜在拡散モデルに注入され、反復の各ラウンドの画像生成方向をガイドします。**5)トレーニングの最適化**研究者らは、圧縮された画像の潜在空間で追加の拡散モデルをトレーニングすると、詳細生成の品質がさらに向上することを発見しました。 これが、DALL-E 3が前の2世代よりも高品質の画像を生成する理由の1つです。**CLIP評価データ**研究者は最初にCLIPモデルを使用して、DALL-E 3によって生成された画像と元の説明テキスト、つまりCLIPスコアとの類似性を計算しました。 彼らは、MSCOCOデータセットから4096の画像記述をプロンプトテキストとしてランダムに選択し、DALL-E 2、DALL-E 3、および安定拡散XLに対応する画像を生成するように依頼し、3つの平均CLIPスコアを計算しました。 その結果、DALL-E 3のCLIPスコアは32.0に達し、DALL-E 2の31.4と安定拡散XLの30.5を上回りました。これは、DALL-E 3によって生成された画像が元の説明テキストによりよく適合し、テキストが画像生成をよりよく導くことを示しています。**ドローベンチ評価データ**モデルのパフォーマンスは、ドローベンチデータセットで比較されました。 データセットには、プロンプトに対するモデルの理解をテストする、多くの脆弱なテキスト プロンプトが含まれています。研究者らは、視覚言語モデルであるGPT-Vを使用して、生成された画像の正確性を自動的に判断しました。 短いテキストプロンプトのサブテストでは、DALL-E 3によって正しく生成された画像の割合は70.4%に達し、DALL-E 2の49%と安定拡散XLの46.9%を大幅に超えました。長いテキストプロンプトでは、DALL-E 3も81%正解し、他のモデルを上回り続けました。**T2I-コンプベンチ評価**T2I-CompBenchの相関サブテストを通じて、組み合わせクラスのプロンプトを処理するモデルの能力が調査されます。 DALL-E 3は、カラーバインディング、シェイプバインディング、テクスチャバインディングの3つのテストで、正しいバインディング比でモデルの中で1位にランクされ、組み合わせの手がかりを理解する能力を十分に示しています。**手動評価**研究者たちはまた、生成されたサンプルを、次の手がかり、文体の一貫性などの観点から判断するように人間に勧めました。 170のヒントの評価では、DALL-E 3はミッドジャーニーと安定した拡散XLを大幅に上回りました。
OpenAIの最強の文学グラフモデルの解釈—DALL· E 3
オリジナルソース: AIGCオープンコミュニティ
MidjourneyとStable Difusionは、商業的な収益化とシナリオベースのランディングで大きな成功を収めており、OpenAIは新しいビジネスチャンスを見出し、DALL· E 3の重要な理由の1つ。
先週、OpenAIは、ChatGPT PlusとEnterprise Editionのユーザーの間でVenshengグラフモデルDALL· の完全な可用性を発表しました。 E3、そして同時に研究論文のまれなリリース。
ダル· E 3 および前の 2 世代の DALL· E、ダル· E 2と比較して、特にChatGPTとの組み合わせで、意味理解、画質、画像修正、画像解釈、長いテキスト入力などの質的な飛躍を達成し、OpenAIの新しい切り札アプリケーションになりました。
論文住所:
研究者らは、テキストで生成された画像モデルでは、トレーニングデータセットの画像記述の品質が低いため、詳細な画像の説明をたどったり、プロンプト内の単語を無視したり、その意味を混乱させたりするのにさまざまな困難が生じることが多いことを発見しました。
この仮説を検証するために、研究者は最初に説明画像のキャプションを生成するモデルを訓練しました。 モデルは、画像の詳細で正確な説明を生成するように注意深くトレーニングされています。
結果は、プロンプトに従うという点で、新しい説明でトレーニングされたモデルが元の記述モデルよりも大幅に優れていることを示しています。 この方法はその後、大規模なデータセットであるDALL-E 3でトレーニングされました。
画像記述生成モジュール
このモジュールでは、CLIP (コントラスティブ言語-画像事前トレーニング) 画像エンコーダーと GPT 言語モデル (GPT-4) を使用して、各画像の詳細なテキスト記述を生成します。
小規模の主題記述データセット、大規模詳細記述データセットを構築し、生成ルールを設定することで、モジュールが出力する画像記述情報の量を大幅に増加させ、その後の画像生成を強力にサポートします。 各モジュールの主な機能は次のとおりです。
1) クリップイメージエンコーダ
CLIP は、画像のセマンティック情報を含む固定長ベクトルに画像をエンコードするトレーニング済みの画像テキスト一致モデルです。 DALL-E 3は、CLIPの画像エンコーダを利用して、条件付きテキスト生成入力の一部としてトレーニング画像を画像特徴ベクトルにエンコードします。
2) GPT 言語モデル
DALL-E 3は、GPTアーキテクチャに基づいて言語モデルを構築し、テキストシーケンスをランダムにサンプリングする結合確率を最大化することにより、一貫したテキスト記述を生成することを学習します。
上記2つを組み合わせることで、画像特徴ベクトルが前の単語列とともにGPT言語モデルに入力され、画像の条件付きテキスト生成が実現できる。 トレーニングを通じて、モジュールは各画像の詳細なDeiveの説明を生成することを学習します。
4)トレーニングの最適化
DALL-E 3のインフラストラクチャは完成しましたが、直接トレーニングの結果は、詳細な説明を生成するのに十分理想的ではありません。 したがって、研究者は以下の技術的最適化を行いました。
画像生成モジュール
このモジュールは、最初にVAEを使用して高解像度の画像を低次元ベクトルに圧縮し、学習の難しさを軽減します。 次に、テキストはT5トランスフォーマーを使用してベクトルにエンコードされ、GroupNormレイヤーを介して拡散モデルに挿入され、画像生成方向をガイドします。
研究者らは、拡散モデルを追加することで、画像の詳細生成の効果が大幅に向上すると考えています。 具体的なプロセスは次のとおりです。
1) 画像圧縮
高解像度の画像は、まずVAEモデルによって低次元ベクトルに圧縮され、画像生成の難しさが軽減されます。 DALL-E 3は8倍のダウンサンプリングを採用し、256pxの画像は32x32サイズの潜在ベクトルに圧縮されます。
2) テキストエンコーダ
T5 Transformer などのネットワークを使用して、テキスト プロンプトをベクトルにエンコードし、画像生成モデルに挿入します。
これは画像生成のコア技術であり、画像生成問題をノイズベクトルの複数の小さなスケール摂動に分解し、徐々にターゲット画像に近づきます。 重要なのは、適切な順方向と逆方向のプロセスを設計することです。
エンコードされたテキストベクトルは、GroupNormレイヤーを介して潜在拡散モデルに注入され、反復の各ラウンドの画像生成方向をガイドします。
5)トレーニングの最適化
研究者らは、圧縮された画像の潜在空間で追加の拡散モデルをトレーニングすると、詳細生成の品質がさらに向上することを発見しました。 これが、DALL-E 3が前の2世代よりも高品質の画像を生成する理由の1つです。
CLIP評価データ
研究者は最初にCLIPモデルを使用して、DALL-E 3によって生成された画像と元の説明テキスト、つまりCLIPスコアとの類似性を計算しました。 彼らは、MSCOCOデータセットから4096の画像記述をプロンプトテキストとしてランダムに選択し、DALL-E 2、DALL-E 3、および安定拡散XLに対応する画像を生成するように依頼し、3つの平均CLIPスコアを計算しました。
これは、DALL-E 3によって生成された画像が元の説明テキストによりよく適合し、テキストが画像生成をよりよく導くことを示しています。
ドローベンチ評価データ
モデルのパフォーマンスは、ドローベンチデータセットで比較されました。 データセットには、プロンプトに対するモデルの理解をテストする、多くの脆弱なテキスト プロンプトが含まれています。
研究者らは、視覚言語モデルであるGPT-Vを使用して、生成された画像の正確性を自動的に判断しました。
長いテキストプロンプトでは、DALL-E 3も81%正解し、他のモデルを上回り続けました。
T2I-コンプベンチ評価
T2I-CompBenchの相関サブテストを通じて、組み合わせクラスのプロンプトを処理するモデルの能力が調査されます。 DALL-E 3は、カラーバインディング、シェイプバインディング、テクスチャバインディングの3つのテストで、正しいバインディング比でモデルの中で1位にランクされ、組み合わせの手がかりを理解する能力を十分に示しています。
手動評価
研究者たちはまた、生成されたサンプルを、次の手がかり、文体の一貫性などの観点から判断するように人間に勧めました。 170のヒントの評価では、DALL-E 3はミッドジャーニーと安定した拡散XLを大幅に上回りました。