原典:シン・ジユアン 画像ソース:無制限のAIによって生成すごい! GPTスキルツリーが再び成長し、ゲームを直接実行することもできます!?ご存知のように、現在の時代は、小さなゲームを作ることで市場をつかむことができる過去の時代ではなくなりました。 今日のゲーム開発プロセスは非常に複雑です。人的資源から始めましょう、各ゲームチームの人員は数十または数百に数えられます。 誰かがプログラミングを担当し、誰かがアートを担当し、誰かがメンテナンスを担当します。各ゲームには、巨大なコードベースとマテリアルライブラリもあります。その結果、優れたゲームを開発するには、多くの人と多くの時間が必要です。 そしてこの期間はしばしば数年です。 より直感的には、それはお金です。ゲームチームは、人々が覚えて愛する傑作を開発し、予算は1億ドルを超えます。そうでなければ、ゲーム制作は愛で生成された一種の電気です。今、物事は変わりました!研究者は、複数のAIエージェントを統合してゲーム開発のプロセスの一部を自動化できるGameGPTと呼ばれるモデルを開発しました。そして、さまざまなエージェントが自分の職務を遂行し、整然と働きます。ゲームのデザイン計画をレビューし、対応する変更と調整を行う責任を負うエージェントがいます。 タスクを具体的なコードに変換する責任がある人もいます。 前の手順で生成されたコードをチェックし、実行結果を確認する責任がある人もいます。 また、すべての作業が当初の期待を満たしていることを確認する担当者もいます。 このように、ワークフローを洗練および分解することで、GameGPTはAIエージェントの作業を簡素化できます。 この種のパフォーマンスは、すべてを実行する全能のエージェントよりも効率的で、達成がはるかに簡単です。研究者によると、GameGPTは、コードテストなど、従来のゲーム開発プロセスの反復的で厳格な側面の一部を簡素化できます。多くの開発者が複雑な検査作業から解放され、AIでは置き換えられないより困難な設計リンクに集中できます。もちろん、この論文はまだ比較的準備段階にあります。 パフォーマンスの向上を実証するための具体的な結果や実験はありません。つまり、実際にGameGPTでゲームを開発した人はおらず、モデルはまだ構想段階であり、具体的な応用実績や定量化可能なデータが出ないと評価が難しいのです。しかし、それは常に取り組むべき方向です。一部のネチズンは、LLMに関する人々の考えはやや偏っていると述べました。 現在、研究者はNLPの問題を100%解決するツールを持っていますが、人々は特定のワークフローの自動化にのみ関心があります。たとえば、ゲームの世界が、ルールベースのハードコーディングされたエンジンとして 5 分で判断できるよりも普通にあなたの決定に反応した場合を想像してみてください。ゲームがあなたが下した決定に基づいてあなたのためにサイドクエストを即興で作ることができると想像してみてください(途中で見た敵をランダムに虐殺するなど)。開発者がそのようなシステムを作成するとき、彼らはこれらのことをコーディングする代わりに、ヒントエンジニアリングを使用してLLMをガイドします。ただ、これの目的はコストを節約することではなく、今までこれ以上ゲームが作れなかった段階でゲームを作ることです(ちょっと一口ではありませんか)。**ゲームGPT**まず、GameGPTモデルの大きなフレームワーク、つまりプロセス全体を見てみましょう。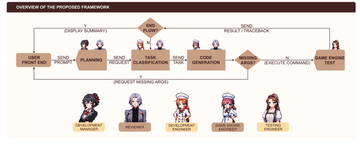 ご覧のとおり、著者は各エージェントを擬人化し、それぞれの職務をどのように遂行するかをより鮮やかに示します。プロセスの左端にはユーザー側があり、GameGPTに入力され、開発マネージャーとレビューが予備計画を立てます。次に、要件は開発エンジニアとゲームエンジンエンジニアに送信され、特定のタスクを実行してコードを生成します。最後に抜けがないか確認し、左側に送り返して再度走行します。 そうでない場合は、右側に進み、検査を担当するエンジニアがテストを実行します。**AI開発ゲーム?? ** 実際、AIが開発したゲームの歴史の基本はさらにさかのぼる可能性があります。ゲーム開発におけるAIの応用は、スタークラフトやディアブロなどの古典的なゲームにまでさかのぼることができます。 当時、開発者はインタラクティブな仮想世界とキャラクターを作成するためのAIシステムを必要としていました。これらのシステムは、このようなインタラクティブプラットフォームの開発の標準となっています。ゲーム開発におけるAIに関する初期の研究では、ノンプレイヤーキャラクター(NPC)の制御が重視され、自然言語処理(NLP)技術の開発に伴い、ディープラーニング技術を使用してレベルを生成する先駆的な研究がいくつかありました。傑作の1つはMarioGPTで、微調整されたGPT-2モデルを通じてスーパーマリオブラザーズのレベルの一部を生成することに成功しました。LLMは今年、NLPとコンピュータービジョン(CV)の両方で良い結果を残し、大きな進歩を遂げました。LLMトレーニングは多段階のプロセスであることを私たちは知っています。 初期段階では、これらのモデルを広範なコーパスでトレーニングし、基本的な言語スキルの習得を促進します。これに続いて、命令を通じてさまざまなNLPタスクからデータを生成することにより、モデルを微調整するというより重要な段階が続きます。 この命令調整により、幅広いアプリケーションでモデルの汎化能力が向上し、LLMは以前のトレーニングで実行されなかったタスクでエラーのないパフォーマンスを実現できます。最後に、ヒューマンフィードバック強化学習(RLHF)ステージは、モデルの構造的完全性と信頼性を保証します。 ここでのもう1つの注意点–RLHFステージを使用すると、モデルは人間のスタイルを模倣するコンテンツを生成できるため、エージェントとしての汎用性が向上します。さらに、LLMの進歩により、ソフトウェア開発プロセスにおけるエージェントの自動化が促進されました。 多くの研究は、さまざまなタスクを実行できるLLMベースのエージェントを開発する方法の問題に焦点を当てています。たとえば、AutoGPTはLLMエージェントを使用して現実世界の特定の意思決定タスクを処理しましたが、HuggingGPTはより複雑なAIタスクを調整するためのコントローラーとして単一のLLMを使用しました。これらの方法は単一のLLMエージェントに依存していますが、それらはすべて、決定を改善するためにレビュー担当者(上のフローチャートのレビュー担当者)を追加します。または、AutoGPTを例にとると、モデルは教師あり学習者からいくつかの補助的な意見を得て、自身のパフォーマンスを向上させ、HuggingGPTをGPT-4に接続して、意思決定の精度を評価するためのレビュー担当者を作成することもできます。さまざまなソフトウェアの開発を自動化するために使用できるマルチエージェントフレームワークを導入するMetaGPTなどの他の例があります。今日議論したゲーム開発に戻ると、一般的なソフトウェア開発とは異なり、ゲーム開発業界はトレンドに追いつく必要があるため、最高の効率を達成するために開発プロセス全体をより正確かつ簡潔にする必要があることを知っておく必要があります。さらに、単一のLLMを調整して使用して、錯覚や高精度のないゲーム開発の開発サイクル全体に対応することは、非現実的でコストがかかります。したがって、ゲーム開発AIのフレームワークには複数のレビュアーの参加が必要であり、言語モデルに固有の幻覚傾向を効果的に軽減できます。研究者たちはまた、言語モデルにはゲーム開発における別の制限、つまり冗長性があることを発見しました。 LLMは、ゲームのビルド時に、不要で情報のないタスクやコードスニペットを生成する場合があります。錯覚と冗長性の問題に効果的に対処するために、今日の主人公であるGameGPTは、デュアルコラボレーション、内部語彙による命令の調整、コードの分離など、問題に対してさまざまなアプローチを戦略的に採用しています。デュアルコラボレーションには、LLMと小規模なディープラーニングモデル間の相互作用、および実行を担当するエージェントとレビュー担当者エージェントの間のコラボレーション参加が含まれることに注意してください。研究者たちは、これらの相乗効果がGameGPTの錯覚と冗長性を軽減するのに効果的であることが証明されていると述べています。**メソッドの紹介**次に、研究者たちはプロセス全体からGameGPTの革新を分析しました。まず、ゲーム設計段階では、ユーザーリクエストを受け取った後、GameGPTのタスクには、ゲーム全体の開発計画の生成が含まれます。 この計画フェーズは、開発プロセス全体のシームレスな進行に大きく影響する重要なステップの1つです。このフェーズは、LLMベースのゲーム開発マネージャーが初期計画を考え出し、それをタスクリストに分解することによって計画されます。LLMの固有の制限により、この初期計画はしばしば幻覚を提示し、有益でないまたは不必要に冗長なタスクを含む予期しないタスクをもたらすことは注目に値します。これらの問題に対処するために、研究者は、互いに直交し、より良い結果を得るためにレイヤーで実行できるこれらの課題を軽減できる4つの戦略を提案しました。シナリオ 1: ゲームの種類を識別するために、受信要求を分類します。 現在、GameGPTフレームワークは、アクション、戦略、ロールプレイング、シミュレーション、アドベンチャーの5つの異なるゲームジャンルの開発をサポートしています。研究者は、タイプごとに、関連情報を含むテンプレートを使用してゲーム開発マネージャーエージェントをガイドする標準化された計画テンプレートを提供します。このアプローチを採用することにより、冗長なタスクの頻度が大幅に減少しますが、幻覚が発生する可能性は低くなります。戦略2:別のLLMベースのエージェントであるプログラム審査官エージェントの関与を含みます。 このエージェントは、ミッション計画の包括的なレビューを提供するために慎重な設計で動作します。その主な目標は、幻覚と冗長性の発生を最小限に抑えることです。 このエージェント評価プログラムは、その精度、効率、および単純さを改善および向上させるためのフィードバックを提供します。同時に、この部分で生成された指示は、ゲーム開発マネージャーのエージェントへの新しい入力として使用でき、タスク計画をより正確かつ完璧にします。戦略 3: ゲーム開発レベルでより良い計画を立てるために、特別な指示を通じてゲーム開発マネージャーのエージェントの LLM 自体を調整します。 この微調整プロセスの目的は、モデルが正確で簡潔な計画を作成できるようにすることです。便宜上、研究チームは、入力と出力の多くの組み合わせを含む内部データセットを収集して統合しました。 これらの組み合わせは、長さや構造が標準形式に準拠していませんが、すべてゲーム開発の要件を中心に展開しています。 固定ミックスのこの部分は、業界の開発者によって提供されます。このアプローチを採用することで、研究者はLLMの一般的な言語スキルとゲーム開発計画スキルの間のギャップを効果的に埋めました。戦略4:計画段階の「セーフティネット」。 計画プロセス全体を通して、ゲーム開発マネージャー エージェントは常にフロントエンド インターフェイスで中間結果をユーザーと共有し、残りのエージェントが進行中の開発を常に把握できるようにします。これを強化するために、研究者は、ユーザーが期待に基づいて計画を積極的にレビュー、修正、および強化できるようにするインタラクティブなアプローチを統合しました。 このアプローチにより、設計計画とユーザーのニーズの間の一貫性も保証されます。これらの戦略が邪魔にならないように、GameGPTの利点を見てみましょう。 まず、このモデルのタスク分類プロセスでは、タスクタイプとそれに対応するパラメータを識別する際に高い精度が必要です。そのため、この段階での精度を確保するために、研究者はゲーム開発エンジニアと呼ばれるエージェントを作成しました。 エージェントは、タスク分類のプロセスに参加するために連携する 2 つのモデルで構成されます。このコラボレーションアプローチにより、タスク識別の精度と有効性が向上します。 同時に、LLM錯覚の出現を回避し、タスク分類の精度を向上させるために、研究者はゲーム開発に現れる可能性のあるタスクタイプのリストを提供しました。これをよりよく分類するために、彼らはBERTモデルを採用しました。BERT モデルは、内部データセットで完全にトレーニングされています。 このデータセットには、ゲーム開発タスクに合わせたデータ項目が含まれています。 入力は所定のリストから抽出され、出力はタスクの指定されたカテゴリに対応します。この段階でタスクの種類とパラメーターのレビューが行われ、タスクレビュー担当者と呼ばれるエージェントが導入され、主に各カテゴリの識別とパラメーターが妥当かどうかを担当します。レビューのプロセスには、タスクタイプが所定の範囲内にあるかどうか、およびそれが最も適切なタスクであるかどうかをレビューすることが含まれる。 同時に、パラメーター リストをチェックして、タスクと一致しているかどうかを確認します。コンテキスト タスク情報に基づく状況や、ユーザー要求をパラメーターから推測できない状況など、一部のシナリオでは、GameGPT はそれらを解決するためのプロアクティブなアプローチを取ります。レビュー担当者は、フロントエンド インターフェイスでプロンプトを起動し、パラメーターに必要な追加情報を要求することで、ユーザーの注意を引き付けます。この対話型アプローチの利点は、自動推論が不十分な場合でも、引数の詳細の整合性が保証されることです。さらに、タスク間の依存関係を識別し、これらの関係をカプセル化する図を構築する別のエージェントがいます。 グラフが確立されると、アルゴリズムを使用してグラフを走査およびフィルター処理し、明確なタスク実行順序が得られます。このプロセスにより、タスクの依存関係に従ってモデルを整然と体系的に実行でき、一貫性のある構造化された開発プロセスが実現します。別の問題は、LLMを使用して長いコードを生成すると、幻覚が大きくなり、冗長性のリスクが生じることです。 この問題を解決するために、研究者はゲームデザインに表示されるコードを分離する新しい方法を導入し、LLMの推論プロセスを簡素化し、それによって幻覚と冗長性を大幅に軽減しました。このアプローチも理解するのは難しくありません - 研究者は期待されるスクリプトをLLMが処理するための多くの短いコードスニペットに分割します。 このデカップリング方式により、LLMの作業が大幅に簡素化されます。文脈学習と呼ばれる効果的な推論方法もあり、幻覚を効果的に軽減することもできます。さらに、GameGPTに適用される別の幻覚除去手法には、タスクごとに一連のKコードスニペットを生成することが含まれます。 これらのコード スニペットは、仮想環境でテストされ、同時にユーザーに提示されます。 テストプロセスとユーザーフィードバックの両方を使用して、問題のあるコードスニペットを特定して排除し、実行する最も実行可能なオプションのみを残します。 このアプローチはまた、幻覚の発生をさらに減らすのに役立ちます。さらに、研究者は、ゲーム開発用に設計された多数のコードスニペットを備えた社内ライブラリを持っています。 各コードスニペットはラベラーによってコメントされ、その意図された目的の明確な説明を提供します。要約すると、コードを冗長にしたり幻覚させたりしないようにするために、開発者は事前とイベントの2つの準備を行いました。同時に、上記のライブラリは、モデルを微調整するための貴重なリソースでもあります。 コードのレビューと改善 ゲームエンジンエージェントがコードを生成した後、コードレビューエージェントはコードベースの徹底的なレビューとレビューを実行します。エージェントは、元の要求から逸脱する可能性のあるインスタンスや、コード内の予期しない幻覚を特定するために、徹底的な評価を実施します。徹底的なレビューの後、エージェントは潜在的な違いにフラグを立てるだけでなく、コードを改善するための提案を提供し、より合理的なバージョンになります。レビュープロセスの後、変更されたコードとエージェントからのフィードバックは、フロントエンドインターフェイスを介してゲームエンジンエンジニア、エージェント、およびユーザーと共有されます。 ユーザーが必要と判断した場合は、フロントエンドインターフェイスから直接コード変更の提案を提供できます。次に、これらの推奨事項はコードレビューエージェントに渡され、コードレビューエージェントはそれらを評価して選択的にマージし、コードを強化するための協調的で反復的なアプローチをさらに生成します。最後に、コードが生成され、すべてが完了すると、責任は、生成されたコードの実行を担当するゲームエンジンテストエージェントにあります。この段階で、エージェントは前のフェーズで確立された実行シーケンスにも従います。特定の実行プロセスでは、個々のタスクのコードをゲームエンジンに送信して実行し、実行中に継続的に追跡してログを生成します。実行シーケンスで指定されたすべてのタスクを完了すると、エージェントは実行中に生成されたすべてのログをマージします。その結果、フロントエンドインターフェイスを介してユーザーに表示される簡潔で包括的な要約が得られます。さらに、テストエンジニアエージェントは、実行中に観察されたバックトラッキングの発生を識別して報告します。 これらのバックトレースは、AIが実行プロセスまたはコードをさらに調整する重要な指標として機能し、プロセス全体を洗練し、完璧な最終製品の生産を支援します。最後に、同時に動作する複数のエージェントのフレームワーク式を見てみましょう。まず、GameGPTでは、各エージェントにプライベートメモリシステムがあり、共有パブリックコンテンツにアクセスして、意思決定プロセスの指針となるために必要な情報を取得できます。時間ステップ t を持つエージェント i の場合、このプロセスは次のように表すことができます。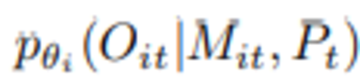 ここで、pθiはエージェントiに関連するLLMまたはエキスパートモデルに対応し、Oitは時間ステップtにおけるエージェントiの出力または成果物を表し、MitとPtはそれぞれ時間ステップt内のすべてのプライベートメモリと必要な公開記録を参照します。ゲーム開発業界の特殊性と大きな言語モデルの限界により、GameGPTには異なる役割を持つ複数のエージェントが存在することが重要です。ゲーム開発サイクルは数か月かかることが多いため、包括的なメモリとコンテキスト情報を備えた単一のエージェントに依存すると、LLMを含む言語モデルの効率が大幅に低下する可能性があります。プロジェクトが時間の経過とともに複雑になるにつれて、このアプローチにはスケーラビリティの課題があります。 また、LLMが扱うタグの数に制限があるため、大規模なゲーム開発プロジェクトでは、フルメモリの別のエージェントを使用することは実用的ではありません。また、LLMで観察される幻覚や冗長性などの固有の問題は、複数のエージェント、特に重要な役割を持つエージェント間のコラボレーションの重要性を浮き彫りにします。このコラボレーションは、LLMの幻想と冗長性によってもたらされる課題を軽減する上で重要です。その結果、GameGPTは、ゲーム開発サイクル全体の責任など、さまざまな役割を利用して運用を容易にします。これらの役割には、ゲームコンテンツデザイナー、ゲーム開発マネージャー、プログラム監査人、ゲーム開発エンジニア、タスク監査人、および前述のゲームエンジンエンジニア、コード監査人、およびゲームエンジンテストエンジニアが含まれます。ゲーム開発プロセス全体を通して、各キャラクターは異なるタスクを引き受けます。リソース:
ゲームGPTがゲーム制作に参入! 完全に自動生成されたゲーム、時間は100倍短縮できます
原典:シン・ジユアン
すごい! GPTスキルツリーが再び成長し、ゲームを直接実行することもできます!?
ご存知のように、現在の時代は、小さなゲームを作ることで市場をつかむことができる過去の時代ではなくなりました。 今日のゲーム開発プロセスは非常に複雑です。
人的資源から始めましょう、各ゲームチームの人員は数十または数百に数えられます。 誰かがプログラミングを担当し、誰かがアートを担当し、誰かがメンテナンスを担当します。
各ゲームには、巨大なコードベースとマテリアルライブラリもあります。
その結果、優れたゲームを開発するには、多くの人と多くの時間が必要です。 そしてこの期間はしばしば数年です。
ゲームチームは、人々が覚えて愛する傑作を開発し、予算は1億ドルを超えます。
そうでなければ、ゲーム制作は愛で生成された一種の電気です。
今、物事は変わりました!
研究者は、複数のAIエージェントを統合してゲーム開発のプロセスの一部を自動化できるGameGPTと呼ばれるモデルを開発しました。
そして、さまざまなエージェントが自分の職務を遂行し、整然と働きます。
ゲームのデザイン計画をレビューし、対応する変更と調整を行う責任を負うエージェントがいます。 タスクを具体的なコードに変換する責任がある人もいます。 前の手順で生成されたコードをチェックし、実行結果を確認する責任がある人もいます。 また、すべての作業が当初の期待を満たしていることを確認する担当者もいます。
研究者によると、GameGPTは、コードテストなど、従来のゲーム開発プロセスの反復的で厳格な側面の一部を簡素化できます。
多くの開発者が複雑な検査作業から解放され、AIでは置き換えられないより困難な設計リンクに集中できます。
もちろん、この論文はまだ比較的準備段階にあります。 パフォーマンスの向上を実証するための具体的な結果や実験はありません。
つまり、実際にGameGPTでゲームを開発した人はおらず、モデルはまだ構想段階であり、具体的な応用実績や定量化可能なデータが出ないと評価が難しいのです。
しかし、それは常に取り組むべき方向です。
一部のネチズンは、LLMに関する人々の考えはやや偏っていると述べました。 現在、研究者はNLPの問題を100%解決するツールを持っていますが、人々は特定のワークフローの自動化にのみ関心があります。
たとえば、ゲームの世界が、ルールベースのハードコーディングされたエンジンとして 5 分で判断できるよりも普通にあなたの決定に反応した場合を想像してみてください。
ゲームがあなたが下した決定に基づいてあなたのためにサイドクエストを即興で作ることができると想像してみてください(途中で見た敵をランダムに虐殺するなど)。
開発者がそのようなシステムを作成するとき、彼らはこれらのことをコーディングする代わりに、ヒントエンジニアリングを使用してLLMをガイドします。
ただ、これの目的はコストを節約することではなく、今までこれ以上ゲームが作れなかった段階でゲームを作ることです(ちょっと一口ではありませんか)。
ゲームGPT
まず、GameGPTモデルの大きなフレームワーク、つまりプロセス全体を見てみましょう。
プロセスの左端にはユーザー側があり、GameGPTに入力され、開発マネージャーとレビューが予備計画を立てます。
次に、要件は開発エンジニアとゲームエンジンエンジニアに送信され、特定のタスクを実行してコードを生成します。
最後に抜けがないか確認し、左側に送り返して再度走行します。 そうでない場合は、右側に進み、検査を担当するエンジニアがテストを実行します。
**AI開発ゲーム?? **
実際、AIが開発したゲームの歴史の基本はさらにさかのぼる可能性があります。
ゲーム開発におけるAIの応用は、スタークラフトやディアブロなどの古典的なゲームにまでさかのぼることができます。 当時、開発者はインタラクティブな仮想世界とキャラクターを作成するためのAIシステムを必要としていました。
これらのシステムは、このようなインタラクティブプラットフォームの開発の標準となっています。
ゲーム開発におけるAIに関する初期の研究では、ノンプレイヤーキャラクター(NPC)の制御が重視され、自然言語処理(NLP)技術の開発に伴い、ディープラーニング技術を使用してレベルを生成する先駆的な研究がいくつかありました。
傑作の1つはMarioGPTで、微調整されたGPT-2モデルを通じてスーパーマリオブラザーズのレベルの一部を生成することに成功しました。
LLMは今年、NLPとコンピュータービジョン(CV)の両方で良い結果を残し、大きな進歩を遂げました。
LLMトレーニングは多段階のプロセスであることを私たちは知っています。 初期段階では、これらのモデルを広範なコーパスでトレーニングし、基本的な言語スキルの習得を促進します。
これに続いて、命令を通じてさまざまなNLPタスクからデータを生成することにより、モデルを微調整するというより重要な段階が続きます。 この命令調整により、幅広いアプリケーションでモデルの汎化能力が向上し、LLMは以前のトレーニングで実行されなかったタスクでエラーのないパフォーマンスを実現できます。
最後に、ヒューマンフィードバック強化学習(RLHF)ステージは、モデルの構造的完全性と信頼性を保証します。
さらに、LLMの進歩により、ソフトウェア開発プロセスにおけるエージェントの自動化が促進されました。 多くの研究は、さまざまなタスクを実行できるLLMベースのエージェントを開発する方法の問題に焦点を当てています。
たとえば、AutoGPTはLLMエージェントを使用して現実世界の特定の意思決定タスクを処理しましたが、HuggingGPTはより複雑なAIタスクを調整するためのコントローラーとして単一のLLMを使用しました。
これらの方法は単一のLLMエージェントに依存していますが、それらはすべて、決定を改善するためにレビュー担当者(上のフローチャートのレビュー担当者)を追加します。
または、AutoGPTを例にとると、モデルは教師あり学習者からいくつかの補助的な意見を得て、自身のパフォーマンスを向上させ、HuggingGPTをGPT-4に接続して、意思決定の精度を評価するためのレビュー担当者を作成することもできます。
さまざまなソフトウェアの開発を自動化するために使用できるマルチエージェントフレームワークを導入するMetaGPTなどの他の例があります。
今日議論したゲーム開発に戻ると、一般的なソフトウェア開発とは異なり、ゲーム開発業界はトレンドに追いつく必要があるため、最高の効率を達成するために開発プロセス全体をより正確かつ簡潔にする必要があることを知っておく必要があります。
さらに、単一のLLMを調整して使用して、錯覚や高精度のないゲーム開発の開発サイクル全体に対応することは、非現実的でコストがかかります。
したがって、ゲーム開発AIのフレームワークには複数のレビュアーの参加が必要であり、言語モデルに固有の幻覚傾向を効果的に軽減できます。
研究者たちはまた、言語モデルにはゲーム開発における別の制限、つまり冗長性があることを発見しました。 LLMは、ゲームのビルド時に、不要で情報のないタスクやコードスニペットを生成する場合があります。
錯覚と冗長性の問題に効果的に対処するために、今日の主人公であるGameGPTは、デュアルコラボレーション、内部語彙による命令の調整、コードの分離など、問題に対してさまざまなアプローチを戦略的に採用しています。
デュアルコラボレーションには、LLMと小規模なディープラーニングモデル間の相互作用、および実行を担当するエージェントとレビュー担当者エージェントの間のコラボレーション参加が含まれることに注意してください。
研究者たちは、これらの相乗効果がGameGPTの錯覚と冗長性を軽減するのに効果的であることが証明されていると述べています。
メソッドの紹介
次に、研究者たちはプロセス全体からGameGPTの革新を分析しました。
まず、ゲーム設計段階では、ユーザーリクエストを受け取った後、GameGPTのタスクには、ゲーム全体の開発計画の生成が含まれます。 この計画フェーズは、開発プロセス全体のシームレスな進行に大きく影響する重要なステップの1つです。
このフェーズは、LLMベースのゲーム開発マネージャーが初期計画を考え出し、それをタスクリストに分解することによって計画されます。
LLMの固有の制限により、この初期計画はしばしば幻覚を提示し、有益でないまたは不必要に冗長なタスクを含む予期しないタスクをもたらすことは注目に値します。
これらの問題に対処するために、研究者は、互いに直交し、より良い結果を得るためにレイヤーで実行できるこれらの課題を軽減できる4つの戦略を提案しました。
シナリオ 1: ゲームの種類を識別するために、受信要求を分類します。 現在、GameGPTフレームワークは、アクション、戦略、ロールプレイング、シミュレーション、アドベンチャーの5つの異なるゲームジャンルの開発をサポートしています。
研究者は、タイプごとに、関連情報を含むテンプレートを使用してゲーム開発マネージャーエージェントをガイドする標準化された計画テンプレートを提供します。
このアプローチを採用することにより、冗長なタスクの頻度が大幅に減少しますが、幻覚が発生する可能性は低くなります。
戦略2:別のLLMベースのエージェントであるプログラム審査官エージェントの関与を含みます。 このエージェントは、ミッション計画の包括的なレビューを提供するために慎重な設計で動作します。
その主な目標は、幻覚と冗長性の発生を最小限に抑えることです。 このエージェント評価プログラムは、その精度、効率、および単純さを改善および向上させるためのフィードバックを提供します。
同時に、この部分で生成された指示は、ゲーム開発マネージャーのエージェントへの新しい入力として使用でき、タスク計画をより正確かつ完璧にします。
戦略 3: ゲーム開発レベルでより良い計画を立てるために、特別な指示を通じてゲーム開発マネージャーのエージェントの LLM 自体を調整します。 この微調整プロセスの目的は、モデルが正確で簡潔な計画を作成できるようにすることです。
便宜上、研究チームは、入力と出力の多くの組み合わせを含む内部データセットを収集して統合しました。 これらの組み合わせは、長さや構造が標準形式に準拠していませんが、すべてゲーム開発の要件を中心に展開しています。
このアプローチを採用することで、研究者はLLMの一般的な言語スキルとゲーム開発計画スキルの間のギャップを効果的に埋めました。
戦略4:計画段階の「セーフティネット」。 計画プロセス全体を通して、ゲーム開発マネージャー エージェントは常にフロントエンド インターフェイスで中間結果をユーザーと共有し、残りのエージェントが進行中の開発を常に把握できるようにします。
これを強化するために、研究者は、ユーザーが期待に基づいて計画を積極的にレビュー、修正、および強化できるようにするインタラクティブなアプローチを統合しました。 このアプローチにより、設計計画とユーザーのニーズの間の一貫性も保証されます。
これらの戦略が邪魔にならないように、GameGPTの利点を見てみましょう。
そのため、この段階での精度を確保するために、研究者はゲーム開発エンジニアと呼ばれるエージェントを作成しました。 エージェントは、タスク分類のプロセスに参加するために連携する 2 つのモデルで構成されます。
このコラボレーションアプローチにより、タスク識別の精度と有効性が向上します。 同時に、LLM錯覚の出現を回避し、タスク分類の精度を向上させるために、研究者はゲーム開発に現れる可能性のあるタスクタイプのリストを提供しました。
これをよりよく分類するために、彼らはBERTモデルを採用しました。
BERT モデルは、内部データセットで完全にトレーニングされています。 このデータセットには、ゲーム開発タスクに合わせたデータ項目が含まれています。 入力は所定のリストから抽出され、出力はタスクの指定されたカテゴリに対応します。
この段階でタスクの種類とパラメーターのレビューが行われ、タスクレビュー担当者と呼ばれるエージェントが導入され、主に各カテゴリの識別とパラメーターが妥当かどうかを担当します。
レビューのプロセスには、タスクタイプが所定の範囲内にあるかどうか、およびそれが最も適切なタスクであるかどうかをレビューすることが含まれる。 同時に、パラメーター リストをチェックして、タスクと一致しているかどうかを確認します。
コンテキスト タスク情報に基づく状況や、ユーザー要求をパラメーターから推測できない状況など、一部のシナリオでは、GameGPT はそれらを解決するためのプロアクティブなアプローチを取ります。
レビュー担当者は、フロントエンド インターフェイスでプロンプトを起動し、パラメーターに必要な追加情報を要求することで、ユーザーの注意を引き付けます。
この対話型アプローチの利点は、自動推論が不十分な場合でも、引数の詳細の整合性が保証されることです。
さらに、タスク間の依存関係を識別し、これらの関係をカプセル化する図を構築する別のエージェントがいます。 グラフが確立されると、アルゴリズムを使用してグラフを走査およびフィルター処理し、明確なタスク実行順序が得られます。
このプロセスにより、タスクの依存関係に従ってモデルを整然と体系的に実行でき、一貫性のある構造化された開発プロセスが実現します。
別の問題は、LLMを使用して長いコードを生成すると、幻覚が大きくなり、冗長性のリスクが生じることです。 この問題を解決するために、研究者はゲームデザインに表示されるコードを分離する新しい方法を導入し、LLMの推論プロセスを簡素化し、それによって幻覚と冗長性を大幅に軽減しました。
このアプローチも理解するのは難しくありません - 研究者は期待されるスクリプトをLLMが処理するための多くの短いコードスニペットに分割します。 このデカップリング方式により、LLMの作業が大幅に簡素化されます。
文脈学習と呼ばれる効果的な推論方法もあり、幻覚を効果的に軽減することもできます。
さらに、GameGPTに適用される別の幻覚除去手法には、タスクごとに一連のKコードスニペットを生成することが含まれます。
さらに、研究者は、ゲーム開発用に設計された多数のコードスニペットを備えた社内ライブラリを持っています。 各コードスニペットはラベラーによってコメントされ、その意図された目的の明確な説明を提供します。
要約すると、コードを冗長にしたり幻覚させたりしないようにするために、開発者は事前とイベントの2つの準備を行いました。
同時に、上記のライブラリは、モデルを微調整するための貴重なリソースでもあります。 コードのレビューと改善 ゲームエンジンエージェントがコードを生成した後、コードレビューエージェントはコードベースの徹底的なレビューとレビューを実行します。
エージェントは、元の要求から逸脱する可能性のあるインスタンスや、コード内の予期しない幻覚を特定するために、徹底的な評価を実施します。
徹底的なレビューの後、エージェントは潜在的な違いにフラグを立てるだけでなく、コードを改善するための提案を提供し、より合理的なバージョンになります。
レビュープロセスの後、変更されたコードとエージェントからのフィードバックは、フロントエンドインターフェイスを介してゲームエンジンエンジニア、エージェント、およびユーザーと共有されます。 ユーザーが必要と判断した場合は、フロントエンドインターフェイスから直接コード変更の提案を提供できます。
次に、これらの推奨事項はコードレビューエージェントに渡され、コードレビューエージェントはそれらを評価して選択的にマージし、コードを強化するための協調的で反復的なアプローチをさらに生成します。
最後に、コードが生成され、すべてが完了すると、責任は、生成されたコードの実行を担当するゲームエンジンテストエージェントにあります。
この段階で、エージェントは前のフェーズで確立された実行シーケンスにも従います。
特定の実行プロセスでは、個々のタスクのコードをゲームエンジンに送信して実行し、実行中に継続的に追跡してログを生成します。
実行シーケンスで指定されたすべてのタスクを完了すると、エージェントは実行中に生成されたすべてのログをマージします。
その結果、フロントエンドインターフェイスを介してユーザーに表示される簡潔で包括的な要約が得られます。
さらに、テストエンジニアエージェントは、実行中に観察されたバックトラッキングの発生を識別して報告します。 これらのバックトレースは、AIが実行プロセスまたはコードをさらに調整する重要な指標として機能し、プロセス全体を洗練し、完璧な最終製品の生産を支援します。
最後に、同時に動作する複数のエージェントのフレームワーク式を見てみましょう。
まず、GameGPTでは、各エージェントにプライベートメモリシステムがあり、共有パブリックコンテンツにアクセスして、意思決定プロセスの指針となるために必要な情報を取得できます。
時間ステップ t を持つエージェント i の場合、このプロセスは次のように表すことができます。
ゲーム開発業界の特殊性と大きな言語モデルの限界により、GameGPTには異なる役割を持つ複数のエージェントが存在することが重要です。
ゲーム開発サイクルは数か月かかることが多いため、包括的なメモリとコンテキスト情報を備えた単一のエージェントに依存すると、LLMを含む言語モデルの効率が大幅に低下する可能性があります。
プロジェクトが時間の経過とともに複雑になるにつれて、このアプローチにはスケーラビリティの課題があります。 また、LLMが扱うタグの数に制限があるため、大規模なゲーム開発プロジェクトでは、フルメモリの別のエージェントを使用することは実用的ではありません。
また、LLMで観察される幻覚や冗長性などの固有の問題は、複数のエージェント、特に重要な役割を持つエージェント間のコラボレーションの重要性を浮き彫りにします。
このコラボレーションは、LLMの幻想と冗長性によってもたらされる課題を軽減する上で重要です。
その結果、GameGPTは、ゲーム開発サイクル全体の責任など、さまざまな役割を利用して運用を容易にします。
これらの役割には、ゲームコンテンツデザイナー、ゲーム開発マネージャー、プログラム監査人、ゲーム開発エンジニア、タスク監査人、および前述のゲームエンジンエンジニア、コード監査人、およびゲームエンジンテストエンジニアが含まれます。
ゲーム開発プロセス全体を通して、各キャラクターは異なるタスクを引き受けます。
リソース: