出典: Heart of the Machine 画像ソース: Unbounded AIによって生成大規模言語モデル(LLM)は、さまざまな自然言語タスクで優れたパフォーマンスを発揮していますが、大規模なパラメータモデルのトレーニングと推論に高いコストがかかるため、専門的な分野での大規模言語モデルの適用には、まだ多くの実用的な問題があります。 そのため、チームは軽量モデルから始めて、特定のドメインをより適切に提供し、下流タスクのトレーニングと推論のコストを削減することに基づいて、データとモデルの利点を最大化しました。10月24日、北京理工大学の自然言語処理チームは、データ構築、モデルアーキテクチャ、評価、適用プロセスのすべての詳細なステップを網羅し、大規模モデル開発の過程で蓄積された経験を包括的に紹介する、バイリンガル軽量大規模言語モデル(Min**g D**e LLM)シリーズ-MindLLMをリリースしました。 MindLLMはゼロからトレーニングされており、バージョン1.3Bと3Bがあり、一部の公開ベンチマークでは、他のオープンソースの大規模モデルのパフォーマンスに一貫して匹敵するか、それを上回るパフォーマンスを発揮しています。 また、MindLLMは、小型モデル向けに特別に調整された革新的な命令チューニングフレームワークを導入することで、その機能を強化しています。 さらに、法律や金融などの特定の業種のアプリケーションの場合、MindLLMは優れたドメイン適応性も備えています。  *住所: # **MindLLMのハイライト** 1. 高品質で高割合のWebテキストの維持、書籍や会話などの長期データの保存、数学データのダウンサンプリング、コードデータのアップサンプリングなど、データ処理の経験を共有しました。 コンピテンシー学習ではデータを均等にスクランブルし、小規模学習シナリオではいくつかのサンプルをチャンク化することをお勧めします。2. 評価結果は一部の大規模モデルを凌駕し、MindLLMモデルはMPT-7BやGPT-J-6Bなどの大規模モデルをMMLUやAGIの評価で上回り、指示の微調整やアライメントを行わなかった。 中国語では、MindLLMはCおよびCMMLUのより大きなパラメトリックモデルに匹敵する性能を示します。 具体的には、MindLLM-3Bは、数学的能力においてMOSS-Base-16BやMPT-7Bなどの大型モデルよりも優れており、バイリンガリズムではBaichuan2-7BやMOSS-Base-16Bを凌駕しています。 さらに、MindLLM-1.3Bは、同じサイズのGPT-Neo-1.3Bよりも数学的に優れています。3.バイリンガル学習における2つの異なるトレーニング戦略を比較し、プレトレーニング期間中にデータが均等に分散されているかどうかの効果を調べました。 容量スケールが限られている軽量モデル(≤7B)の場合、新しい知識と既存の知識を統合することが難しいため、事前にトレーニングされた戦略と転移トレーニングされた戦略によって、数学、推論、バイリンガルアライメントなどの複雑な機能を実現することは最適ではないと結論付けました。 対照的に、より効果的な戦略は、ゼロから開始し、複数のデータ型をダウンストリームタスクのニーズと組み合わせて統合し、必要な機能を一貫して効率的に取得することです。4.命令チューニング中に特定の機能のためにカスタマイズされたデータを利用すると、包括的な推論や主題知識など、軽量モデルの特定の機能を大幅に向上させることができることがわかりました。5.エントロピーベースの質量フィルタリング戦略を使用して命令セットを構築するアプローチを紹介し、軽量モデルの高品質な命令チューニングデータのフィルタリングにおけるその有効性を実証します。 軽量モデルのコンテキストでは、単にデータ量を増やすのではなく、命令チューニングのデータ品質を向上させることで、モデルのパフォーマンスをより効果的に最適化できることを実証します。6.私たちのモデルは、特定の分野、特に法律や金融などの分野で優れたパフォーマンスを示しています。 モデルパラメータのサイズの違いは、特定のドメイン内で有意差を生じさせず、小さなモデルが大きなモデルよりも優れていることがわかりました。 私たちのモデルは、6Bから13Bの範囲のパラメータサイズを持つモデルとの競争力を維持しながら、特定のドメインで1.3Bから3Bまでのパラメータサイズを持つすべてのモデルよりも優れた性能を発揮し、COTアプローチの下で特定のドメイン内で分類するモデルの能力が大幅に向上します。 # **データ関連** ## **データ処理** 英語と中国語の両方のトレーニングデータを使用します。 英語のデータは Pile データセットから派生し、さらに処理されました。 中国のデータには、Wudao や CBooks などのオープン ソースからのトレーニング データと、インターネットからクロールするデータが含まれます。 データの品質を確保するために、特にWebからクロールされたデータについては、厳格なデータ処理方法を採用しています。データ処理に対する当社のアプローチには、次のものが含まれます。1.フォーマットクリーニング:Webページパーサーを使用して、ソースWebページからテキストコンテンツを抽出してクリーンアップします。 このフェーズには、テキストの流れを確保するために、不要なHTML、CSS、JSロゴ、絵文字を削除することが含まれます。 さらに、一貫性のないフォーマットの問題にも対処しました。 また、モデルが古代の文学や詩を学べるように、繁体字中国語の文字を保存しています。2.低品質のデータフィルタリング:Webページのコンテンツに対するテキストの比率に基づいてデータ品質を評価します。 具体的には、文字密度が 75% 未満または中国語が 100 文字未満のページは除外されます。 このしきい値は、Web ページのサンプルの初期テストによって決定されました。3.データの重複排除:WuDaoのデータもWebページから派生しているため、一部のWebサイトでは同じ情報が繰り返し公開される場合があります。 そのため、ローカルに敏感なハッシュアルゴリズムを使用して、トレーニングデータの多様性を維持しながら重複するコンテンツを削除します。4. センシティブな情報のフィルタリング: Web ページにはセンシティブなコンテンツが含まれていることが多いため、ポジティブな言語モデルを構築するために、ヒューリスティックとセンシティブなレキシコンを使用してこのコンテンツを検出してフィルタリングしました。 プライバシー保護のため、正規表現を使用してID番号、電話番号、メールアドレスなどの個人情報を識別し、特別なタグに置き換えています。5. 情報量の少ないデータのフィルタリング: 広告などの情報量の少ないデータは、重複コンテンツとして表示されることがよくあります。 したがって、Webページのテキストコンテンツ内のフレーズの頻度を分析することにより、このタイプのコンテンツを特定します。 同じウェブサイトのフレーズを頻繁に繰り返すことは、モデル学習に悪影響を与える可能性があると考えています。 その結果、私たちのフィルターは、主に広告や認証されていないWebサイト内の連続した繰り返しフレーズに焦点を当てています。最終的に、以下のデータが得られました。 ## **スケーリングの法則** 深層学習や大規模言語モデルの学習コストが増大する中で最適なパフォーマンスを確保するために、データ量とモデル容量の関係について、スケーリングの法則として知られる研究を実施しました。 何十億ものパラメーターを持つ大規模な言語モデルのトレーニングに着手する前に、まず小さなモデルをトレーニングして、大規模なモデルをトレーニングするためのスケーリング パターンを確立します。 当社のモデルサイズは1,000万から5億のパラメータで、各モデルは最大100億個のトークンを含むデータセットでトレーニングされています。 これらのトレーニングでは、一貫したハイパーパラメーター設定と、前述のものと同じデータセットが使用されます。 様々なモデルの最終的な損失を解析することで、FLOP(浮動小数点演算)の学習から損失までのマッピングを確立することができました。 下図のように、異なるサイズのモデルによって飽和する学習データの量は異なり、モデルのサイズが大きくなると、必要な学習データも増加します。 対象モデルの正確なデータ要件を満たすために、モデルの膨張則にあてはめるべき乗則式を使用し、3Bパラメータモデルの学習データ量と損失値を予測し、実際の結果(図の星印)と比較しました。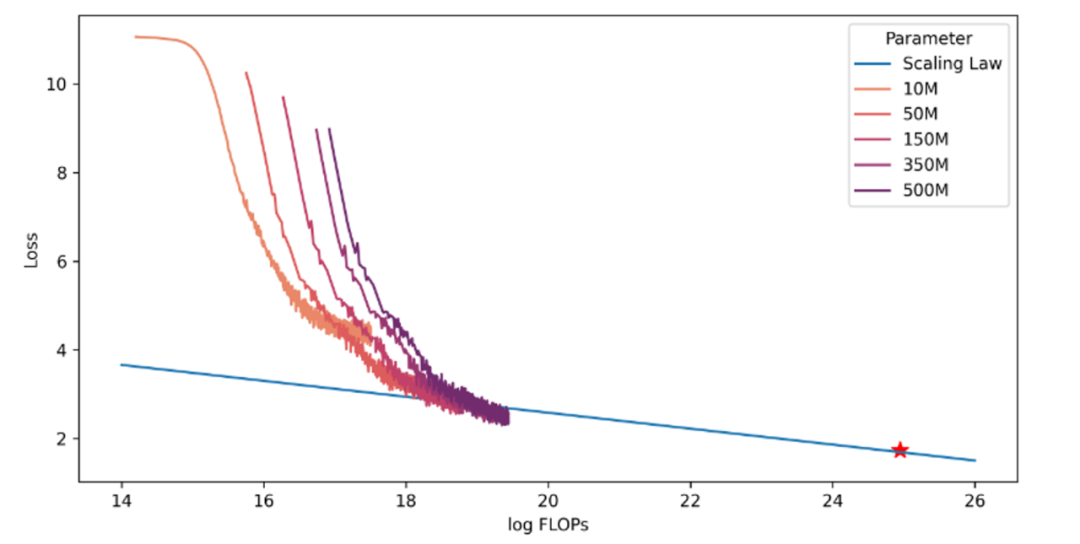 ## **データの乱交とデータコース** モデルに対するデータの影響は、主に2つの側面をカバーしています:(1)混合比は、異なるソースからのデータを組み合わせて、限られたトレーニング予算で特定のサイズのデータセットを構築する方法を含む。 (2)モデル固有のスキルをトレーニングするために、さまざまなソースからのデータの配置を扱うデータコース。各データソースをスケールダウンして、15Mのパラメータでモデルをトレーニングしました。 下の図に示すように、データの種類が異なれば、学習効率とモデルの最終結果への影響も異なります。 たとえば、数学の問題は、最終的なデータ損失が少なく、学習が速いため、パターンがはっきりしていて学習しやすいことを示します。 対照的に、有益な書籍や多様なウェブテキストからのデータは、適応に時間がかかります。 テクノロジー関連のデータや百科事典など、同様のデータの一部の領域は損失の点で近い場合があります。 1 つのデータから他のデータに一般化するモデルのパフォーマンスをさらに詳しく調べるために、1 つのデータでトレーニングされたこれらのモデルを使用して他のデータでテストを行い、その結果を次の図に示します。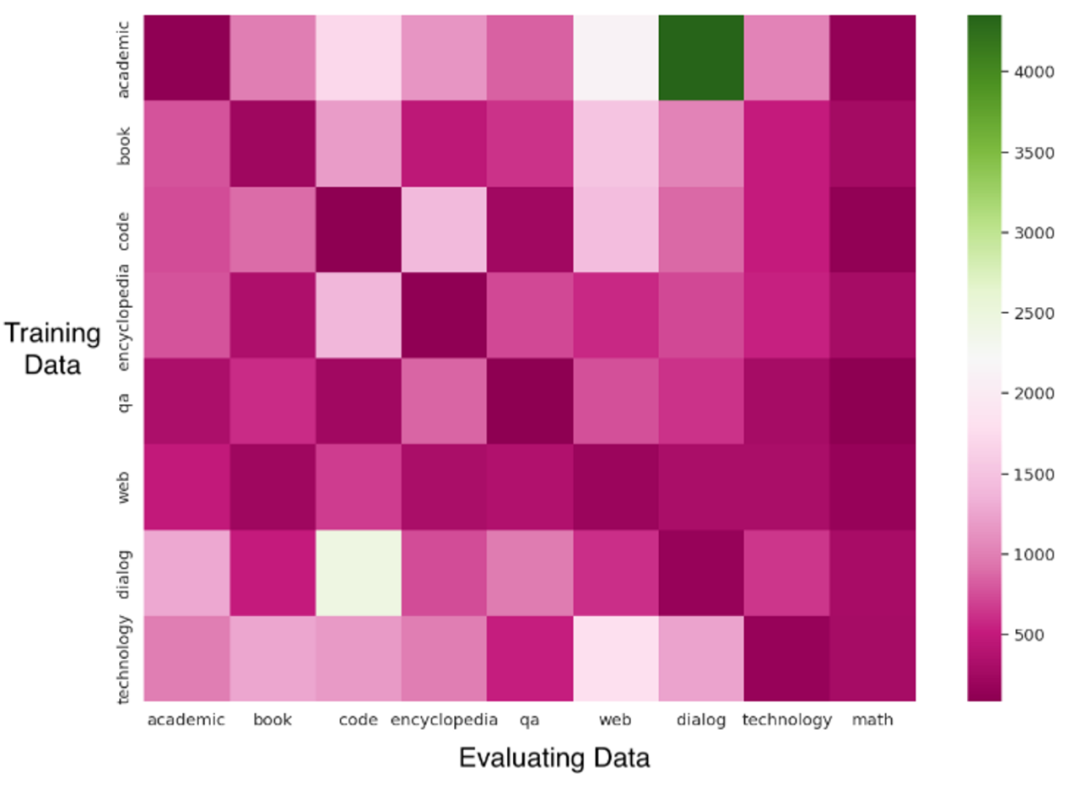 例えば、ウェブテキスト、百科事典、Q&Aデータでトレーニングされたモデルは、複数のデータソースで強い汎化能力を示し、そのコンテンツにはさまざまな分野の多様な情報が含まれていることを示しています。 対照的に、学術論文データやコードデータでトレーニングされたモデルは、数学的能力には優れていますが、ドメイン特異性と固有のフォーマット情報のために、一般化が弱いです。さらに、さまざまなスキルやデータタイプでモデルのパフォーマンスのバランスを取るために、複数のデータスケーリングを調整しました。 実験に基づいて、データ混合比に関するいくつかの原則を確定しました。*高品質のWebテキストと百科事典のデータは、その多様性のために、その割合を維持します。*過学習を避けるために、数学データの割合を減らします。*コードと学術データで数学を強化しながら、さまざまなサンプリングと関連する処理によってフォーマットを軽減します。*長期的な依存関係を学ぶのに役立つ会話と本のデータを保持します。混合比に加えて、データコース(データがトレーニングされる順序)もモデルの学習能力に影響を与えます。 実験では、さまざまなソースからのデータによってモデルがさまざまなスキルを学習し、特定の学習順序を採用すると、スキル間の相関関係によりモデルが新しいスキルを学習するのに役立つ可能性があることが示されています。 私たちの実験は、不均一な混合データと言語転移学習がモデルの能力に与える影響に焦点を当てています。 私たちの実験は、不均質な混合データは、同じタイプのデータでモデルの継続的なトレーニングにつながり、コンテキスト内学習のコンテキストに近く、したがって、少数ショット学習でより優れたパフォーマンスを発揮することを示しています。 しかし、学習のムラにより、後期に忘れてしまう現象が顕著になることがあります。 また、言語転移学習はモデルがバイリンガル能力を獲得するのに役立ち、言語アライメントによって全体的なパフォーマンスが向上する可能性がありますが、混合言語データを用いた学習は、モデル能力の割り当てと獲得に資すると考えています。 # **MindLLMsモデルアーキテクチャ** MindLLM-1.3B は GPTNeo-1.3B と同じモデル アーキテクチャを使用していますが、MindLLM-3B はその上にいくつかの改良を加えています。 学習の安定性とモデル機能に基づいて、回転位置符号化 (RoPE) DeepNorm、RMS Norm、FlashAttention-2、GeGLU、およびその他の最適化演算子を使用します。GPTNeo-1.3Bに基づいて中国語の語彙を追加し、転移学習戦略を使用してMindLLM-1.3Bのバイリンガル能力を訓練しました。 MindLLM-3Bでは、SentencePieceのBPEを使用してデータをトークン化し、トークナイザーの最終的な語彙サイズは125,700です。 バイリンガルトレーニングの2つの異なる方法を通じて、いくつかの一般的で実践的な事前トレーニング方法をまとめました。 # **事前トレーニング** ### 事前トレーニングの詳細バイリンガルモデルMindLLM de novoのトレーニングには、2つの異なる戦略を使用しました。 MindLLM-3Bでは、中国語と英語の習熟度を学習しながら、中国語と英語の混合バイリンガルデータで800,000歩を直接事前トレーニングしました。 MindLLM-1.3Bでは、まず英語のデータセットで101,100歩を事前学習し、次に中国語と英語の混合データを使用して105,900歩を学習しました。 事前トレーニングの詳細は次のとおりです。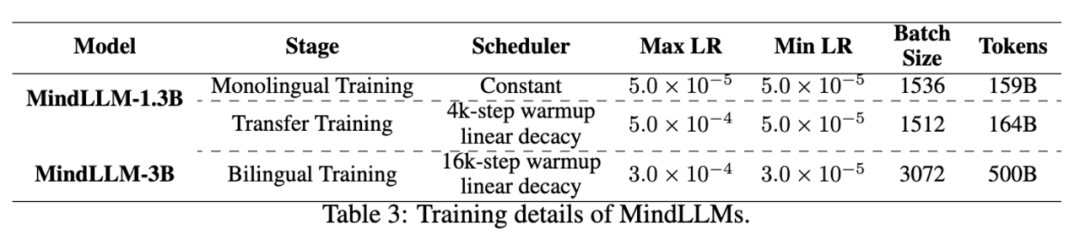 ### **トレーニング前段階の評価**小さなモデルは大きなモデルを打ち負かすことができますモデルの中国語と英語の能力を評価するために、MMLU(5ショット)とAGI(4ショット)を使用してモデルの英語能力を評価し、C-(5ショット)とCMMLU(4ショット)を使用してモデルの中国語能力を評価しました。 汎用人工知能は、英語部分の多肢選択式部分を使用します。 評価の結果は、以下のとおりです。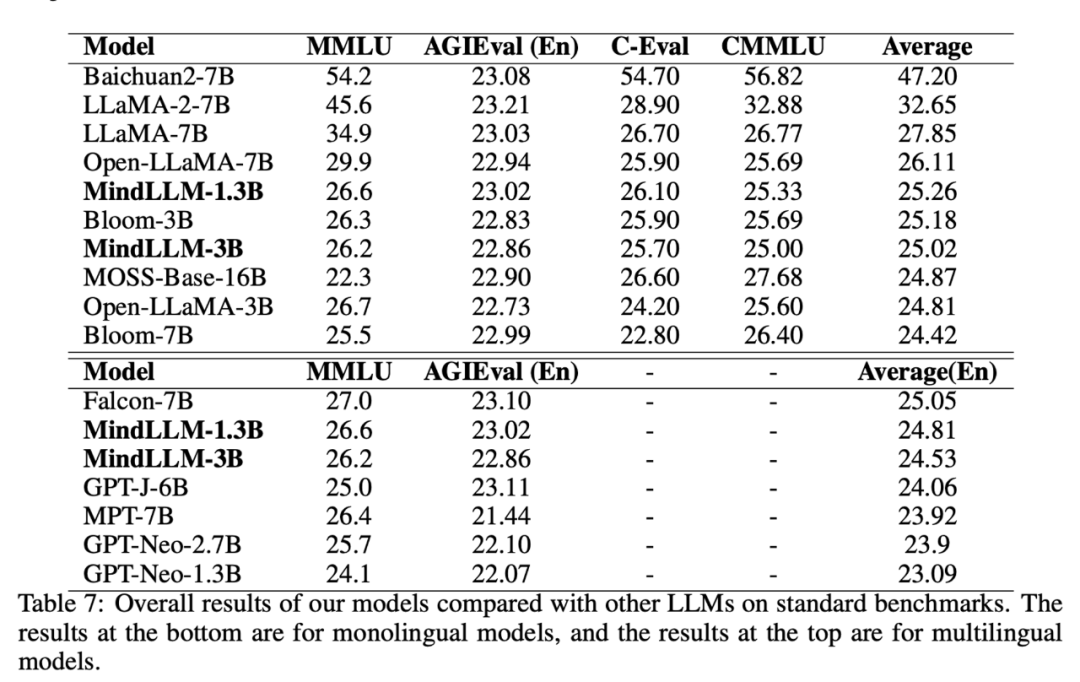 英語のパフォーマンスに関しては、MindLLMはGPT-J-6B、MPT-7B、MOSS-Base-16Bなどの大型モデルを平均して上回り、モデルサイズが大きく、事前学習済みデータが多いFalcon-7Bに近づいています。 中国語の能力という点では、MindLLMはオープンソースのLLMと同等のパフォーマンスを発揮します。 注目すべきは、MindLLMがいまだに強化のためのトレーニングを受けていることです。また、中国語と英語の両方のデータで学習したMindLLM-1.3Bは、MMLUでGPT-Neo-1.3Bを上回っていることがわかり、異なる言語間に能力の類似性があることから、これはバイリンガル学習による利益である可能性が示唆されました。 詳細な実験と分析は、論文のセクション4.4にあります。小型モデルは、特定の機能の点で大きな可能性を秘めています軽量モデルの場合、下流のタスクに適用する場合は、関連する機能が存在するだけで十分です。 したがって、このセクションでは、(≤7B)固有の機能におけるMindLLMおよびその他の軽量LLMのパフォーマンスと影響要因を探りたいと思います。数学的能力、推論能力、バイリンガルアライメント能力の3つの能力は複雑で、バイリンガルモデルの適用にとって相対的に重要であるため、主に3つの視点から異なるモデルの性能を評価します。(1)数学**算術(5ショット)データセットを使用してモデルの算術能力を評価し、GSM8K(4ショット)とMATH(4ショット)を使用してモデルの一般的な数学的能力を評価しました。 評価の結果は、以下のとおりです。我们发现,MindLLM-3B在数学能力上的平均分数达到了16.01,超过了MOSS-Base-16B(15.71)和MPT-7B(13.42),GPT-J-6B(13.15)。此外MindLLM-1.3B的数学平均水平也超过了相同大小的GPT-Neo-1.3B。以上结果表明,轻量级模型在数学上有着巨大的潜力,较小的模型也可以在具体领域表现出超越或者与更大模型相当的水平。进一步,我们可以看到数学能力较为出色的(均分≥15) MindLLM-3B以外は全モデル約7Bです。 このことは、数学的能力などの複雑な能力の完全な習得は、モデルの規模によって制限される可能性があることを示唆しており、この推測は、モデルのバイリンガリズムと推論能力の評価にさらに反映される可能性があります。**(2) 根拠**HellaSwag と WinoGrande を使用してモデルの言語推論能力 (5 ショット)、LogiQA を使用してモデルの論理的推論能力 (5 ショット)、PubMedQA、PIQA、MathQA を使用してモデルの知識推論能力 (5 ショット)、BBH を使用してモデルの包括的な推論能力を評価しました (3 ショット)。 具体的な評価結果は以下の通りです。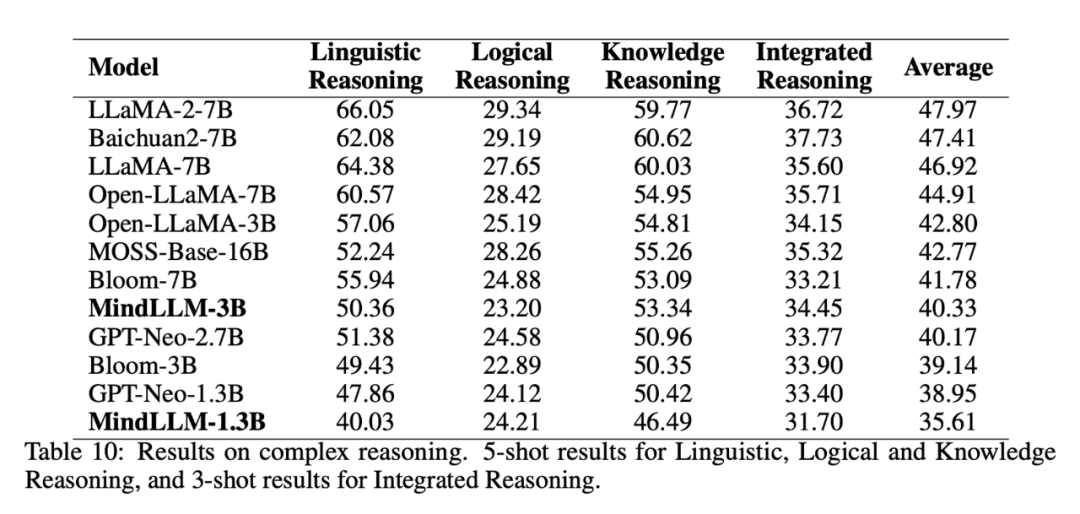 第1に、モデル能力が限られている状況下では、バイリンガリズムがもたらす能力向上と、言語学習によるモデル能力の消費とのバランスをとる必要があるかもしれない。 言語学習はモデルの能力の一部を占めることがあり、推論能力などの複雑な能力を獲得することを可能にします。 例えば、MindLLM-1.3Bは、英語のMMLU評価指標ではGPT-Neo-1.3Bよりも優れていますが、平均的な推論能力では後者よりも弱いです(35.61対38.95)。 ブルームズの推理力は特に良くなかったが、追跡評価のバイリンガリズムは素晴らしく、上記の点もある程度確認できた。 例えば、Open-LLaMA-3Bの推論性能は、より大きなモデルに匹敵し、事前学習済みデータは1TBBであり、同じサイズの他のモデルが使用する事前学習済みデータを上回っています。 その結果、小規模なモデルでも、大規模なモデルと同等の推論能力を達成できる可能性があります。 さらに、MOSSの推論レベルは、以前のコードデータの学習による利益よりも優れたパフォーマンスを発揮しているようには見えませんが(MOSSはCodeGenでトレーニングを継続しました)、関連する研究は、コードが実際にモデルの推論能力の向上に有益であることを示しているため、モデルの推論能力を強化するためにコードデータをトレーニングにいつ、どのように追加するかは、さらに議論する価値があります。**(3)バイリンガリズム**Flores-101(8ショット)のzh-enセクションを使用して、中国語と英語のバイリンガルまたはマルチリンガルモデルのアライメントを評価しました。 LLaMA-2-7Bに基づく中国語ドメイン適応モデルであるChinese-LLaMA-2-7Bを含めました。 結果は次のとおりです。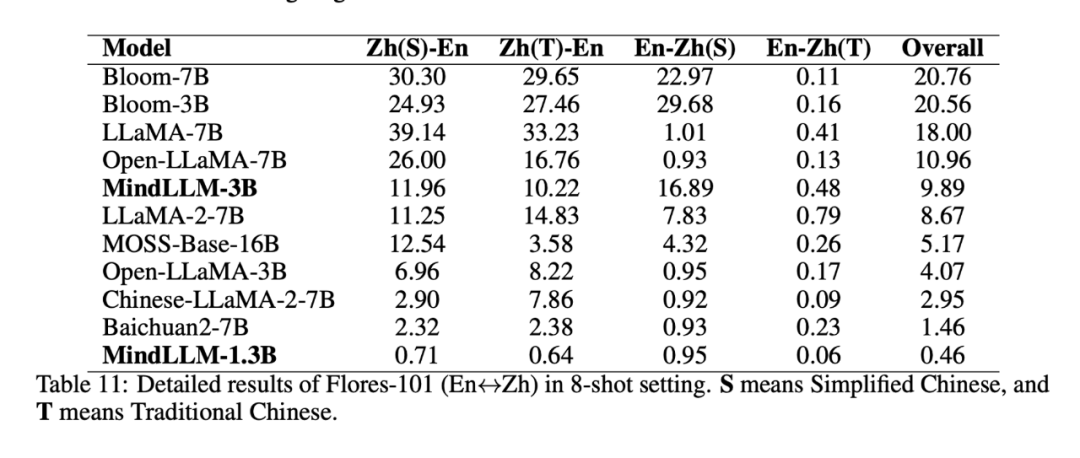 英語から繁体字中国語への翻訳の両方でモデルのパフォーマンスが悪いことがわかりましたが、これは主に、事前トレーニング済みのデータが繁体字中国語のごく一部を占めているためです。 さらに、中国語から英語、英語から中国語への双方向言語アライメントに優れていたのはBloomsとMindLLM-3Bのみで、LLaMA-2-7BとMOSS-Base-16Bがそれに続きました。 LLaMA-7BとOpen-LLaMA-7Bは、中国語から英語へのアライメントのみ可能です。 モデルの事前学習データと組み合わせると、BloomsとMindLLM-3Bの事前学習データは中国語と英語の比率がバランスよくなっているのに対し、LLaMA-2-7Bの中国語データの割合は英語のそれよりもはるかに低く、LLaMA-7BとOpen-LLaMA-7Bの事前学習データにおける中国語の割合はさらに少ないことがわかります。したがって、2つの結論があり、1つは、モデルが1つの言語で大量のトレーニングを行うことで言語表現を学習できると同時に、LLaMA-7BとOpen-LLaMA-7Bのパフォーマンスのように、少数の他の言語を混在させることで理解し、一方向アライメントできるということです。 2つ目は、より良いバイリンガルまたはマルチリンガルのアライメントが必要な場合は、事前トレーニングの最初に、BloomsやMindLLM-3Bなどのバイリンガルまたはマルチリンガルのデータをバランスよく組み合わせる必要があることです。 さらに、MOSS-Base-16BとChinese-LLaMA-2-7Bは中国語と英語のデータの割合が妥当であり、シングルは依然として双方向のアライメントを示さず、このときのモデルにはすでに多くの知識があり、容量が小さい場合は矛盾が生じるため、移行トレーニング中にバイリンガルアライメント能力を追加することは難しいという仮説を立てています。 これは、モノリンガルトレーニングの初期段階では容量が小さく、データ量も少ないMindLLM-1.3Bが、バイリンガルアライメント能力を獲得していないことも説明しています。 一方、白川2-7Bは他の面で非常に優れており、大容量を占める可能性があり、良好な双方向アライメントを学習できません。**(4) 概要**事前トレーニングフェーズの結果を評価すると、次の2つの結論が得られます。*軽量モデルは、特定のドメインまたは機能でより大きなモデルを凌駕またはレベルに達する大きな可能性を秘めています。*容量が限られているモデル(≤7B)の場合、下流タスクの特定の能力要件に応じて事前学習データのデータ比率を合理的に割り当てることができ、モデルが目標とする能力をゼロから学習して取得し、さまざまな知識と能力を統合して促進するのに役立ちます。また、本論文では、均一なデータ分布を維持することがモデルの事前学習性能に及ぼす影響も比較しており、実験結果は、類似のコース学習のデータ構築手法は、初期段階で学習したモデルや均等に混合したデータ構築法と同等の性能を発揮する可能性があるが、最終的には壊滅的な忘却と性能の急激な低下につながる可能性があるのに対し、後者のパフォーマンスはより一貫性と安定しており、得られた事前学習データの知識はより包括的であり、上記の2番目の結論も支持しています。 さらに、同様のコースでデータを構築する方法により、モデルのコンテキスト学習能力の向上に役立つデータ分布がさらに生成される可能性があることがわかりました。 詳細については、論文のセクション4.5を参照してください。 # **命令の微調整** 私たちは、さまざまなタイプのデータセットを持つ軽量モデルで命令の微調整がどのように実行できるかを探りたいと考えています。 次の表は、再構築された中国語データセット MingLi、公開データセット Tulu (英語)、中英バイリンガル データセット MOSS など、使用する命令微調整データセットです。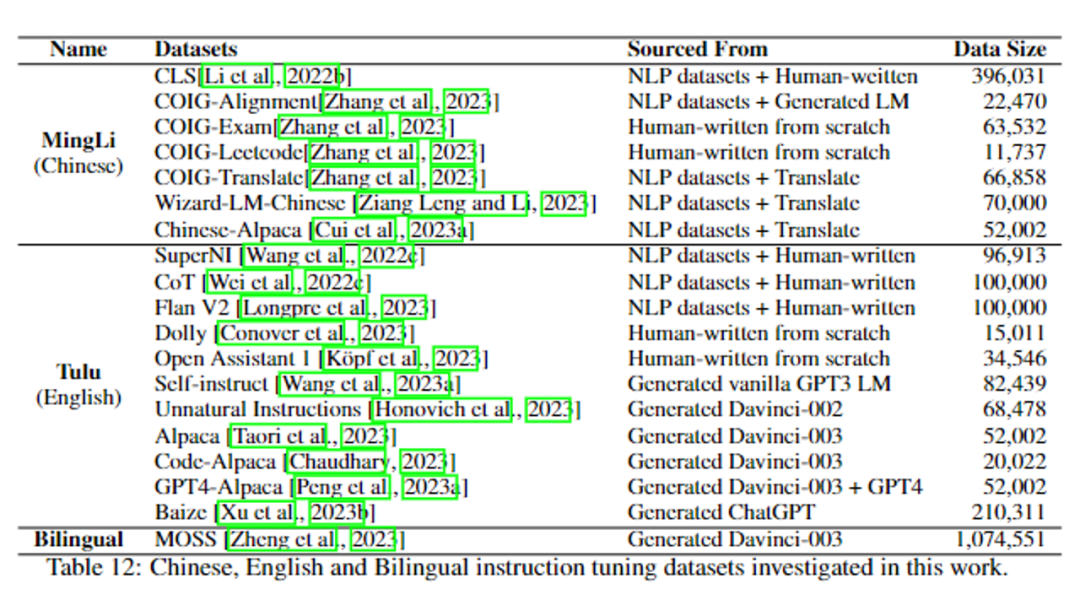 **MindLLMでは、データ量よりも命令の微調整のためのデータの質が重要です。 **MindLLM-1.3BモデルとMindLLM-3Bモデルについて、異なるデータで微調整を行った後のC-での性能は以下の通りです。 実験結果によると、厳選した50,000命令のfine-tuningデータセットで学習したモデルの性能は、多様性が高くデータ量の多い命令fine-tuningデータセットよりも高いことが分かりました。 同様に、このモデルは英語の指標MMLUでも同じパフォーマンスを示しました(詳細は表14を参照)。 したがって、軽量モデルの場合、高品質の命令微調整データセットを定義して除外することが非常に重要です。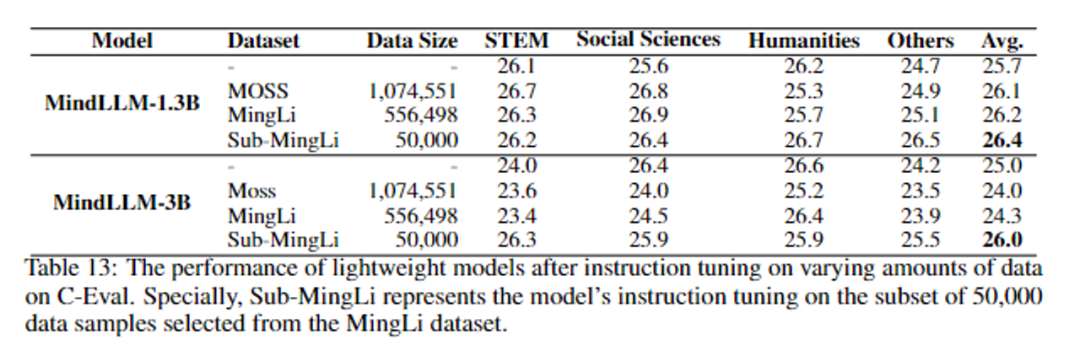 **データエントロピーに基づくデータフィルタリング戦略の微調整**高品質の指導微調整データをどのように定義しますか? 一部の学者は、指導微調整データの多様性が、指導微調整データセットのデータ品質を表すことができると提案しています。 しかし、我々の実験によると、命令の微調整のデータエントロピーとデータ長は、軽量モデルの性能に大きく影響します。 事前学習済みモデル上の各データのクロスエントロピー損失をデータのデータエントロピーとして定義し、K-Meansアルゴリズムによりデータエントロピーに従ってデータをクラスタリングし、異なるデータクラスタを取得します。 各データクラスタの命令を微調整した後、C-を微調整した後のMindLLMの結果を次の表に示します(MMLUの結果の詳細については、表19を参照してください)。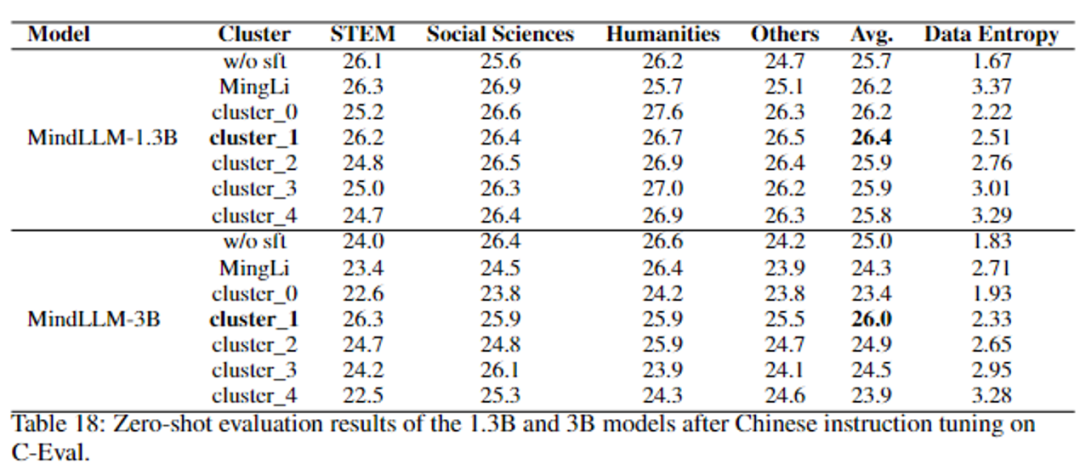 表の結果によると、異なるデータクラスタでのMindLLM-1.3BとMindLLM-3Bのパフォーマンスは大きく異なります。 さらに、図に示すように、C-およびMMLUおよび関数フィッティングにおけるデータエントロピーとモデルの精度との関係を分析します。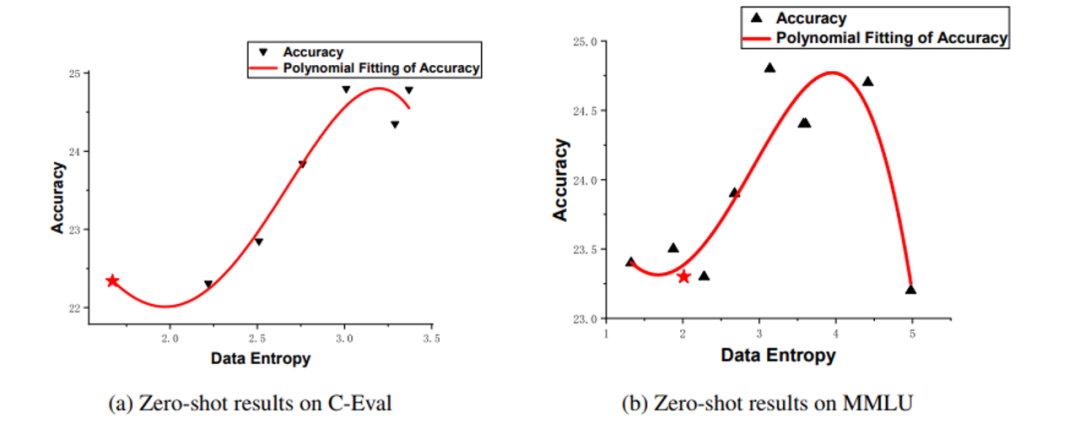 画像内の赤い五芒星の点は、事前学習済みモデルのエントロピーです。 分析によると、データのエントロピーが事前学習済みモデルのエントロピーよりも1〜1.5高い場合、この間隔でデータ命令を微調整した後、モデルは最高のパフォーマンスを発揮します。 そこで、データエントロピーによって高品質なデータを定義し、高品質なデータをスクリーニングする手法を提案する。**MindLLMは、特定の機能を取得するために、指定された命令によってデータセットを微調整できます**MindLLMが指導の微調整によって特定の能力を効果的に向上させることができるかどうかを調べるために、10,000ボリュームのデータセットの試験データ部分を使用してモデルを微調整し、モデルの主題知識能力を強化します。 C-について評価を行い、その結果は以下の通りである。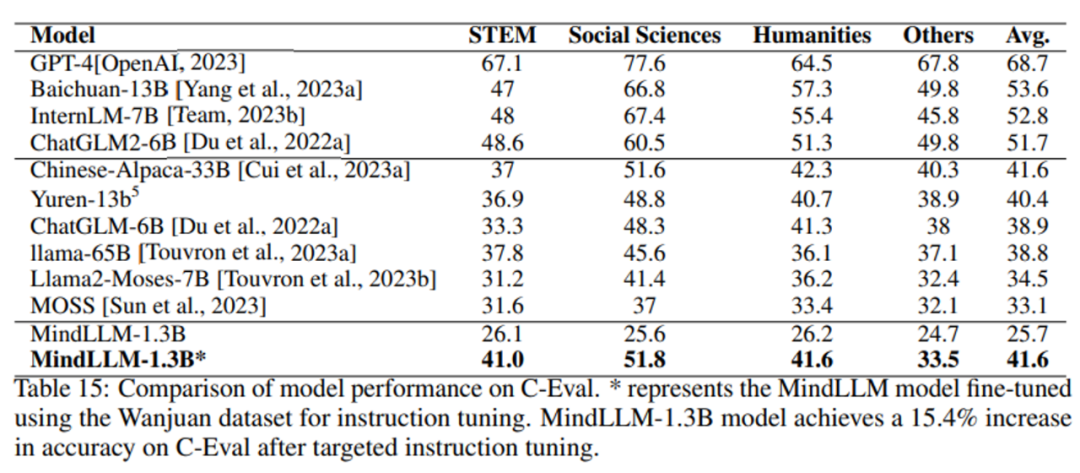 指示の微調整後、モデルは主題知識能力を大幅に向上させ、1.3B MindLLMのパフォーマンスは、ChatGLM-6BやChinese-Alpaca-33Bなどのより大きなモデルのパフォーマンスをも上回っていることがわかります。 したがって、MindLLMは、指示を微調整した後、その特定の機能を向上させることができ、その軽量な特性により、下流の垂直タスクへの展開に適していると考えています。 # **フィールドアプリケーション** 特定の分野における小規模モデルの適用の効果を実証するために、金融と法律の2つの公開データセットを使用して検証します。 この結果から、モデルのパラメータサイズがドメインのパフォーマンスに一定の影響を与えることがわかりますが、パフォーマンスは明らかではありません。 MindLLMの性能は、フィールドアプリケーションにおいて同規模の他のモデルよりも優れており、より大きなモデルに匹敵します。 さらに、小型モデルが応用分野で大きな可能性を秘めていることを証明しています。 ## **金融セクター** この分野では、感情知覚分類タスクが財務データに対して実行されます。 まず、2011年5月13日から2023年8月31日までのオリエンタルフォーチュン誌のデータをクロールし、以下の株価変動をもとにタグ付けしました。 その後、データは日付ごとにトレーニングセットとテストセットに分割されます。 カテゴリの不均衡を考慮して、データをサンプリングし、最終的に320,000個のデータをトレーニングセットとして使用し、20,000個のデータをテストセットとして使用しました。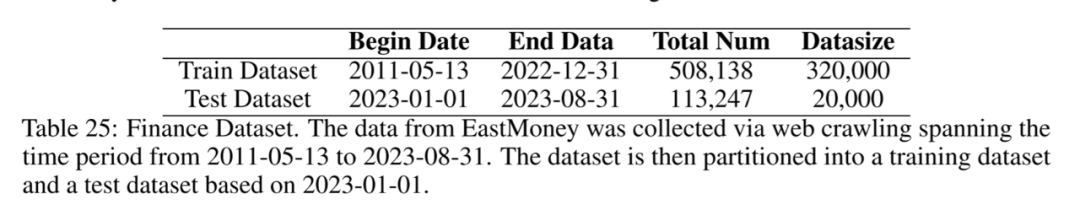 異なるモデルのパフォーマンスを比較するために、2つの異なるトレーニング方法を使用しました。 まず、単純な教師あり微調整 (SFT) のみを使用してテキストを分類します。 次に、ChatGPTから推論プロセスデータを抽出し、COT(Chain-Of-Thought)トレーニング手法を使用して補助データとしてトレーニングに追加しました。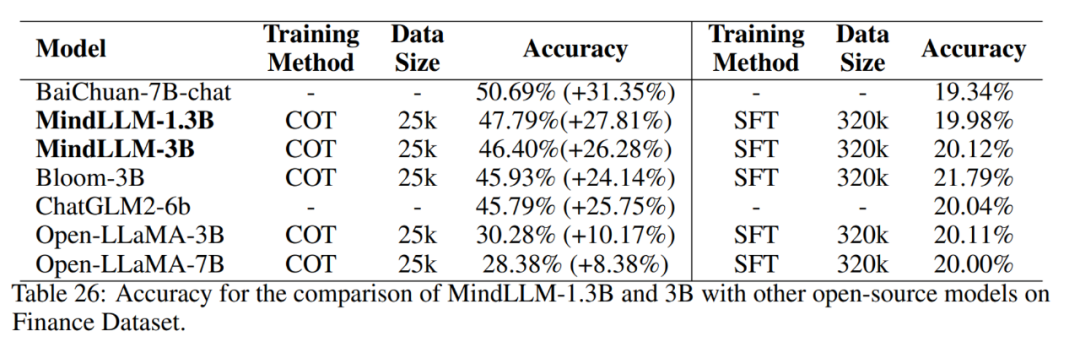 実験結果は、すべてのベースラインモデルとMindLLMモデルの効果が、補助情報を補完することによってさまざまな程度で改善できることを示しています。 さらに、MindLLM-1.3Bと3Bのパフォーマンスは、COTトレーニングによるSFTトレーニングパフォーマンスと比較して、それぞれ27.81%と26.28%向上しており、MindLLMはBaichuan-7Bを除く他のモデルよりも大幅に改善されていることがわかります。 さらに、MindLLM-1.3Bと3Bは、同じ規模で最高のパフォーマンスを達成し、ChatGLM2-6BとOpen-LLaMA-7Bを凌駕します。 ## ## **法律分野** 公開されている法的データを収集し、MindLLMのDirective Fine-Tuning(SFT)用の一般的な指令データと組み合わせました。 データのトークン長が特定のドメインでのモデルのパフォーマンスにどのように影響するかを調べるために、データ長の異なるデータを使用してMindLLMを個別にトレーニングします。 まず、長さが450未満のすべてのデータをスクリーニングし、次にMindLLM-1.3BとMindLLM-3Bトークナイザーを使用して、それぞれ200〜300と300〜450の間のデータをフィルタリングしました。 次の表に、統計と対応するトレーニング モデルを示します。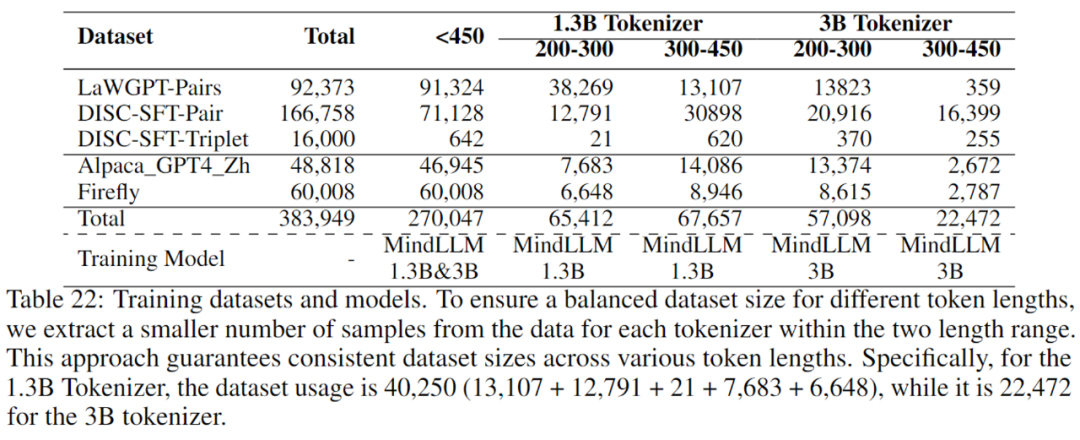 人間による評価におけるバイアスや専門知識の不足によるエラーを回避するため、ChatGPTを以下のように評価者として活用しています。 ChatGPTが生成した複数の法律相談会話のデータセットで、そのうち100件を評価データとして抽出しました。 ChatGPT を使用して、法的アドバイスに対するモデルの応答を評価し、ChatGPT にモデルの応答をランク付けさせ、ランキング結果に基づいて Elo スコアを計算します。 最後に、MindLLM-Lawを他のオープンソースモデルと比較するために、最適なモデルの1つを選択しました。Bloomでは、MindLLM-Lawと同じデータセットを用いてGPT-NeoモデルとOpen-LLaMAモデルを微調整し、比較結果は以下の通りです。 結果は、MindLLM-Lawが13BパラメータとChatGLM2-6Bのモデルを上回っていないことを示していますが、これは主に、より大きな利益をもたらすための法律の事前トレーニング段階でのデータが不足しているためです。 ただし、MindLLMは、Baichuan2-7B-Chat、微調整されたOpen-LLaMA-7B、および同じサイズの他のモデルよりも明らかに全体的な利点があります。 # **概要** この記事では、現在2つの軽量で大規模な言語モデルを含むMindLLMファミリーのモデルを紹介します。 データ処理、事前トレーニング、微調整、ドメインアプリケーションなど、トレーニングプロセスについて詳細に議論し、これらの分野で蓄積された貴重な経験と技術的アプリケーションを共有しました。 MindLLMは、パラメータサイズが比較的小さいにもかかわらず、複数のパフォーマンステストで優れた性能を発揮しており、いくつかの点で大規模なモデルのいくつかを凌駕しています。 MindLLMは、ドメイン適応の点で他の軽量モデルよりも優れた性能を発揮します。 同時に、大規模なモデルよりも速いトレーニング速度と少ないトレーニングリソースで、同等の結果を達成することができます。 以上の分析から、小型モデルにはまだ大きな可能性が秘められていると考えています。 データ品質をさらに向上させ、モデルのトレーニングプロセスを最適化し、モデルを拡張して、MindLLMのパフォーマンスを多次元的に向上させます。 将来的には、軽量で大規模なモデルのより詳細な特定のアプリケーションを実現するために、より多くの下流タスクと特定のドメインで実験を行う予定です。
小型モデルと大規模モデルをどのように比較できるか、北京理工大学はMingde大型モデルMindLLMをリリースし、小型モデルは大きな可能性を秘めています
出典: Heart of the Machine
大規模言語モデル(LLM)は、さまざまな自然言語タスクで優れたパフォーマンスを発揮していますが、大規模なパラメータモデルのトレーニングと推論に高いコストがかかるため、専門的な分野での大規模言語モデルの適用には、まだ多くの実用的な問題があります。 そのため、チームは軽量モデルから始めて、特定のドメインをより適切に提供し、下流タスクのトレーニングと推論のコストを削減することに基づいて、データとモデルの利点を最大化しました。
10月24日、北京理工大学の自然言語処理チームは、データ構築、モデルアーキテクチャ、評価、適用プロセスのすべての詳細なステップを網羅し、大規模モデル開発の過程で蓄積された経験を包括的に紹介する、バイリンガル軽量大規模言語モデル(Ming De LLM)シリーズ-MindLLMをリリースしました。 MindLLMはゼロからトレーニングされており、バージョン1.3Bと3Bがあり、一部の公開ベンチマークでは、他のオープンソースの大規模モデルのパフォーマンスに一貫して匹敵するか、それを上回るパフォーマンスを発揮しています。 また、MindLLMは、小型モデル向けに特別に調整された革新的な命令チューニングフレームワークを導入することで、その機能を強化しています。 さらに、法律や金融などの特定の業種のアプリケーションの場合、MindLLMは優れたドメイン適応性も備えています。
MindLLMのハイライト
データ関連
データ処理
英語と中国語の両方のトレーニングデータを使用します。 英語のデータは Pile データセットから派生し、さらに処理されました。 中国のデータには、Wudao や CBooks などのオープン ソースからのトレーニング データと、インターネットからクロールするデータが含まれます。 データの品質を確保するために、特にWebからクロールされたデータについては、厳格なデータ処理方法を採用しています。
データ処理に対する当社のアプローチには、次のものが含まれます。
1.フォーマットクリーニング:Webページパーサーを使用して、ソースWebページからテキストコンテンツを抽出してクリーンアップします。 このフェーズには、テキストの流れを確保するために、不要なHTML、CSS、JSロゴ、絵文字を削除することが含まれます。 さらに、一貫性のないフォーマットの問題にも対処しました。 また、モデルが古代の文学や詩を学べるように、繁体字中国語の文字を保存しています。 2.低品質のデータフィルタリング:Webページのコンテンツに対するテキストの比率に基づいてデータ品質を評価します。 具体的には、文字密度が 75% 未満または中国語が 100 文字未満のページは除外されます。 このしきい値は、Web ページのサンプルの初期テストによって決定されました。 3.データの重複排除:WuDaoのデータもWebページから派生しているため、一部のWebサイトでは同じ情報が繰り返し公開される場合があります。 そのため、ローカルに敏感なハッシュアルゴリズムを使用して、トレーニングデータの多様性を維持しながら重複するコンテンツを削除します。 4. センシティブな情報のフィルタリング: Web ページにはセンシティブなコンテンツが含まれていることが多いため、ポジティブな言語モデルを構築するために、ヒューリスティックとセンシティブなレキシコンを使用してこのコンテンツを検出してフィルタリングしました。 プライバシー保護のため、正規表現を使用してID番号、電話番号、メールアドレスなどの個人情報を識別し、特別なタグに置き換えています。 5. 情報量の少ないデータのフィルタリング: 広告などの情報量の少ないデータは、重複コンテンツとして表示されることがよくあります。 したがって、Webページのテキストコンテンツ内のフレーズの頻度を分析することにより、このタイプのコンテンツを特定します。 同じウェブサイトのフレーズを頻繁に繰り返すことは、モデル学習に悪影響を与える可能性があると考えています。 その結果、私たちのフィルターは、主に広告や認証されていないWebサイト内の連続した繰り返しフレーズに焦点を当てています。
最終的に、以下のデータが得られました。
スケーリングの法則
深層学習や大規模言語モデルの学習コストが増大する中で最適なパフォーマンスを確保するために、データ量とモデル容量の関係について、スケーリングの法則として知られる研究を実施しました。 何十億ものパラメーターを持つ大規模な言語モデルのトレーニングに着手する前に、まず小さなモデルをトレーニングして、大規模なモデルをトレーニングするためのスケーリング パターンを確立します。 当社のモデルサイズは1,000万から5億のパラメータで、各モデルは最大100億個のトークンを含むデータセットでトレーニングされています。 これらのトレーニングでは、一貫したハイパーパラメーター設定と、前述のものと同じデータセットが使用されます。 様々なモデルの最終的な損失を解析することで、FLOP(浮動小数点演算)の学習から損失までのマッピングを確立することができました。 下図のように、異なるサイズのモデルによって飽和する学習データの量は異なり、モデルのサイズが大きくなると、必要な学習データも増加します。 対象モデルの正確なデータ要件を満たすために、モデルの膨張則にあてはめるべき乗則式を使用し、3Bパラメータモデルの学習データ量と損失値を予測し、実際の結果(図の星印)と比較しました。
データの乱交とデータコース
モデルに対するデータの影響は、主に2つの側面をカバーしています:(1)混合比は、異なるソースからのデータを組み合わせて、限られたトレーニング予算で特定のサイズのデータセットを構築する方法を含む。 (2)モデル固有のスキルをトレーニングするために、さまざまなソースからのデータの配置を扱うデータコース。
各データソースをスケールダウンして、15Mのパラメータでモデルをトレーニングしました。 下の図に示すように、データの種類が異なれば、学習効率とモデルの最終結果への影響も異なります。 たとえば、数学の問題は、最終的なデータ損失が少なく、学習が速いため、パターンがはっきりしていて学習しやすいことを示します。 対照的に、有益な書籍や多様なウェブテキストからのデータは、適応に時間がかかります。 テクノロジー関連のデータや百科事典など、同様のデータの一部の領域は損失の点で近い場合があります。
さらに、さまざまなスキルやデータタイプでモデルのパフォーマンスのバランスを取るために、複数のデータスケーリングを調整しました。 実験に基づいて、データ混合比に関するいくつかの原則を確定しました。
*高品質のWebテキストと百科事典のデータは、その多様性のために、その割合を維持します。 *過学習を避けるために、数学データの割合を減らします。 *コードと学術データで数学を強化しながら、さまざまなサンプリングと関連する処理によってフォーマットを軽減します。 *長期的な依存関係を学ぶのに役立つ会話と本のデータを保持します。
混合比に加えて、データコース(データがトレーニングされる順序)もモデルの学習能力に影響を与えます。 実験では、さまざまなソースからのデータによってモデルがさまざまなスキルを学習し、特定の学習順序を採用すると、スキル間の相関関係によりモデルが新しいスキルを学習するのに役立つ可能性があることが示されています。 私たちの実験は、不均一な混合データと言語転移学習がモデルの能力に与える影響に焦点を当てています。 私たちの実験は、不均質な混合データは、同じタイプのデータでモデルの継続的なトレーニングにつながり、コンテキスト内学習のコンテキストに近く、したがって、少数ショット学習でより優れたパフォーマンスを発揮することを示しています。 しかし、学習のムラにより、後期に忘れてしまう現象が顕著になることがあります。 また、言語転移学習はモデルがバイリンガル能力を獲得するのに役立ち、言語アライメントによって全体的なパフォーマンスが向上する可能性がありますが、混合言語データを用いた学習は、モデル能力の割り当てと獲得に資すると考えています。
MindLLMsモデルアーキテクチャ
MindLLM-1.3B は GPTNeo-1.3B と同じモデル アーキテクチャを使用していますが、MindLLM-3B はその上にいくつかの改良を加えています。 学習の安定性とモデル機能に基づいて、回転位置符号化 (RoPE) DeepNorm、RMS Norm、FlashAttention-2、GeGLU、およびその他の最適化演算子を使用します。
GPTNeo-1.3Bに基づいて中国語の語彙を追加し、転移学習戦略を使用してMindLLM-1.3Bのバイリンガル能力を訓練しました。 MindLLM-3Bでは、SentencePieceのBPEを使用してデータをトークン化し、トークナイザーの最終的な語彙サイズは125,700です。 バイリンガルトレーニングの2つの異なる方法を通じて、いくつかの一般的で実践的な事前トレーニング方法をまとめました。
事前トレーニング
事前トレーニングの詳細
バイリンガルモデルMindLLM de novoのトレーニングには、2つの異なる戦略を使用しました。 MindLLM-3Bでは、中国語と英語の習熟度を学習しながら、中国語と英語の混合バイリンガルデータで800,000歩を直接事前トレーニングしました。 MindLLM-1.3Bでは、まず英語のデータセットで101,100歩を事前学習し、次に中国語と英語の混合データを使用して105,900歩を学習しました。 事前トレーニングの詳細は次のとおりです。
小さなモデルは大きなモデルを打ち負かすことができます
モデルの中国語と英語の能力を評価するために、MMLU(5ショット)とAGI(4ショット)を使用してモデルの英語能力を評価し、C-(5ショット)とCMMLU(4ショット)を使用してモデルの中国語能力を評価しました。 汎用人工知能は、英語部分の多肢選択式部分を使用します。 評価の結果は、以下のとおりです。
また、中国語と英語の両方のデータで学習したMindLLM-1.3Bは、MMLUでGPT-Neo-1.3Bを上回っていることがわかり、異なる言語間に能力の類似性があることから、これはバイリンガル学習による利益である可能性が示唆されました。 詳細な実験と分析は、論文のセクション4.4にあります。
小型モデルは、特定の機能の点で大きな可能性を秘めています
軽量モデルの場合、下流のタスクに適用する場合は、関連する機能が存在するだけで十分です。 したがって、このセクションでは、(≤7B)固有の機能におけるMindLLMおよびその他の軽量LLMのパフォーマンスと影響要因を探りたいと思います。
数学的能力、推論能力、バイリンガルアライメント能力の3つの能力は複雑で、バイリンガルモデルの適用にとって相対的に重要であるため、主に3つの視点から異なるモデルの性能を評価します。
(1)数学**
算術(5ショット)データセットを使用してモデルの算術能力を評価し、GSM8K(4ショット)とMATH(4ショット)を使用してモデルの一般的な数学的能力を評価しました。 評価の結果は、以下のとおりです。
(2) 根拠
HellaSwag と WinoGrande を使用してモデルの言語推論能力 (5 ショット)、LogiQA を使用してモデルの論理的推論能力 (5 ショット)、PubMedQA、PIQA、MathQA を使用してモデルの知識推論能力 (5 ショット)、BBH を使用してモデルの包括的な推論能力を評価しました (3 ショット)。 具体的な評価結果は以下の通りです。
(3)バイリンガリズム
Flores-101(8ショット)のzh-enセクションを使用して、中国語と英語のバイリンガルまたはマルチリンガルモデルのアライメントを評価しました。 LLaMA-2-7Bに基づく中国語ドメイン適応モデルであるChinese-LLaMA-2-7Bを含めました。 結果は次のとおりです。
したがって、2つの結論があり、1つは、モデルが1つの言語で大量のトレーニングを行うことで言語表現を学習できると同時に、LLaMA-7BとOpen-LLaMA-7Bのパフォーマンスのように、少数の他の言語を混在させることで理解し、一方向アライメントできるということです。 2つ目は、より良いバイリンガルまたはマルチリンガルのアライメントが必要な場合は、事前トレーニングの最初に、BloomsやMindLLM-3Bなどのバイリンガルまたはマルチリンガルのデータをバランスよく組み合わせる必要があることです。 さらに、MOSS-Base-16BとChinese-LLaMA-2-7Bは中国語と英語のデータの割合が妥当であり、シングルは依然として双方向のアライメントを示さず、このときのモデルにはすでに多くの知識があり、容量が小さい場合は矛盾が生じるため、移行トレーニング中にバイリンガルアライメント能力を追加することは難しいという仮説を立てています。 これは、モノリンガルトレーニングの初期段階では容量が小さく、データ量も少ないMindLLM-1.3Bが、バイリンガルアライメント能力を獲得していないことも説明しています。 一方、白川2-7Bは他の面で非常に優れており、大容量を占める可能性があり、良好な双方向アライメントを学習できません。
(4) 概要
事前トレーニングフェーズの結果を評価すると、次の2つの結論が得られます。
*軽量モデルは、特定のドメインまたは機能でより大きなモデルを凌駕またはレベルに達する大きな可能性を秘めています。 *容量が限られているモデル(≤7B)の場合、下流タスクの特定の能力要件に応じて事前学習データのデータ比率を合理的に割り当てることができ、モデルが目標とする能力をゼロから学習して取得し、さまざまな知識と能力を統合して促進するのに役立ちます。
また、本論文では、均一なデータ分布を維持することがモデルの事前学習性能に及ぼす影響も比較しており、実験結果は、類似のコース学習のデータ構築手法は、初期段階で学習したモデルや均等に混合したデータ構築法と同等の性能を発揮する可能性があるが、最終的には壊滅的な忘却と性能の急激な低下につながる可能性があるのに対し、後者のパフォーマンスはより一貫性と安定しており、得られた事前学習データの知識はより包括的であり、上記の2番目の結論も支持しています。 さらに、同様のコースでデータを構築する方法により、モデルのコンテキスト学習能力の向上に役立つデータ分布がさらに生成される可能性があることがわかりました。 詳細については、論文のセクション4.5を参照してください。
命令の微調整
私たちは、さまざまなタイプのデータセットを持つ軽量モデルで命令の微調整がどのように実行できるかを探りたいと考えています。 次の表は、再構築された中国語データセット MingLi、公開データセット Tulu (英語)、中英バイリンガル データセット MOSS など、使用する命令微調整データセットです。
MindLLM-1.3BモデルとMindLLM-3Bモデルについて、異なるデータで微調整を行った後のC-での性能は以下の通りです。 実験結果によると、厳選した50,000命令のfine-tuningデータセットで学習したモデルの性能は、多様性が高くデータ量の多い命令fine-tuningデータセットよりも高いことが分かりました。 同様に、このモデルは英語の指標MMLUでも同じパフォーマンスを示しました(詳細は表14を参照)。 したがって、軽量モデルの場合、高品質の命令微調整データセットを定義して除外することが非常に重要です。
高品質の指導微調整データをどのように定義しますか? 一部の学者は、指導微調整データの多様性が、指導微調整データセットのデータ品質を表すことができると提案しています。 しかし、我々の実験によると、命令の微調整のデータエントロピーとデータ長は、軽量モデルの性能に大きく影響します。 事前学習済みモデル上の各データのクロスエントロピー損失をデータのデータエントロピーとして定義し、K-Meansアルゴリズムによりデータエントロピーに従ってデータをクラスタリングし、異なるデータクラスタを取得します。 各データクラスタの命令を微調整した後、C-を微調整した後のMindLLMの結果を次の表に示します(MMLUの結果の詳細については、表19を参照してください)。
MindLLMは、特定の機能を取得するために、指定された命令によってデータセットを微調整できます
MindLLMが指導の微調整によって特定の能力を効果的に向上させることができるかどうかを調べるために、10,000ボリュームのデータセットの試験データ部分を使用してモデルを微調整し、モデルの主題知識能力を強化します。 C-について評価を行い、その結果は以下の通りである。
フィールドアプリケーション
特定の分野における小規模モデルの適用の効果を実証するために、金融と法律の2つの公開データセットを使用して検証します。 この結果から、モデルのパラメータサイズがドメインのパフォーマンスに一定の影響を与えることがわかりますが、パフォーマンスは明らかではありません。 MindLLMの性能は、フィールドアプリケーションにおいて同規模の他のモデルよりも優れており、より大きなモデルに匹敵します。 さらに、小型モデルが応用分野で大きな可能性を秘めていることを証明しています。
金融セクター
この分野では、感情知覚分類タスクが財務データに対して実行されます。 まず、2011年5月13日から2023年8月31日までのオリエンタルフォーチュン誌のデータをクロールし、以下の株価変動をもとにタグ付けしました。 その後、データは日付ごとにトレーニングセットとテストセットに分割されます。 カテゴリの不均衡を考慮して、データをサンプリングし、最終的に320,000個のデータをトレーニングセットとして使用し、20,000個のデータをテストセットとして使用しました。
法律分野
公開されている法的データを収集し、MindLLMのDirective Fine-Tuning(SFT)用の一般的な指令データと組み合わせました。 データのトークン長が特定のドメインでのモデルのパフォーマンスにどのように影響するかを調べるために、データ長の異なるデータを使用してMindLLMを個別にトレーニングします。 まず、長さが450未満のすべてのデータをスクリーニングし、次にMindLLM-1.3BとMindLLM-3Bトークナイザーを使用して、それぞれ200〜300と300〜450の間のデータをフィルタリングしました。 次の表に、統計と対応するトレーニング モデルを示します。
Bloomでは、MindLLM-Lawと同じデータセットを用いてGPT-NeoモデルとOpen-LLaMAモデルを微調整し、比較結果は以下の通りです。
概要
この記事では、現在2つの軽量で大規模な言語モデルを含むMindLLMファミリーのモデルを紹介します。 データ処理、事前トレーニング、微調整、ドメインアプリケーションなど、トレーニングプロセスについて詳細に議論し、これらの分野で蓄積された貴重な経験と技術的アプリケーションを共有しました。 MindLLMは、パラメータサイズが比較的小さいにもかかわらず、複数のパフォーマンステストで優れた性能を発揮しており、いくつかの点で大規模なモデルのいくつかを凌駕しています。 MindLLMは、ドメイン適応の点で他の軽量モデルよりも優れた性能を発揮します。 同時に、大規模なモデルよりも速いトレーニング速度と少ないトレーニングリソースで、同等の結果を達成することができます。 以上の分析から、小型モデルにはまだ大きな可能性が秘められていると考えています。 データ品質をさらに向上させ、モデルのトレーニングプロセスを最適化し、モデルを拡張して、MindLLMのパフォーマンスを多次元的に向上させます。 将来的には、軽量で大規模なモデルのより詳細な特定のアプリケーションを実現するために、より多くの下流タスクと特定のドメインで実験を行う予定です。