元のソース: qubits 画像ソース: Unbounded AIによって生成「調整」に500ドルかかった70億パラメータのモデルは、700億パラメータのラマ2を打ち負かしました!また、ノートブックは簡単に実行でき、効果はChatGPTに匹敵します。重要: **無料、お金なし**。HuggingFace H4チームによって作成されたオープンソースモデル**Zephyr-7B**、shark crazy。 その基盤となるモデルは、しばらく前に爆発的に普及し、「ヨーロッパのOpenAI」として知られるMistral AIによって構築されたオープンソースの大規模モデル**Mistral-7B**です。 ご存知のように、Mistral-7Bの発売から2週間も経たないうちに、様々な微調整されたバージョンが次々と登場し、ラマが最初にリリースされたときにすぐに登場した「アルパカ」スタイルがたくさんあります。Zephyrがバリアントの中で際立っている鍵は、チームがMistral上でDirect Preference Optimization(DPO)を使用して公開データセットでモデルを微調整したことでした。また、データセットに組み込まれているアライメントを削除することで、MT Benchのパフォーマンスをさらに向上させることができることもわかりました。 初代Zephyr-7B-alphaのMT-Benchの平均スコアは7.09で、Llama2-70B-Chatを上回った。######**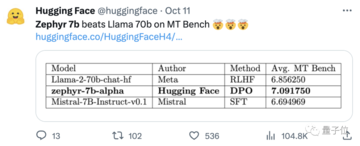 **###### **△**MT-Benchは、モデルの複数ラウンドの対話を処理する能力を評価するためのベンチマークテストであり、問題セットは、ライティング、ロールプレイング、抽出など8つのカテゴリをカバーしています。要するに、その後、アップグレードが進んだのです!H4チームは、第2世代のZephyr-7B-betaを発売しました。 また、GPT-4、Claude 2からアライメントを抽出し、それを小型モデルに注入するというアイデアを模索し、小型モデルに蒸留直接選好最適化(dDPO)を使用する方法を開発したと付け加えました。第2世代のZephyrでは、MT-Benchの平均スコアが7.34に上昇しました。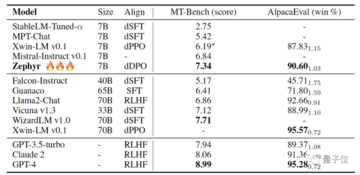 Alpacaでは、Zephyrの勝率は90.6%で、ChatGPT(3.5)よりも優れています。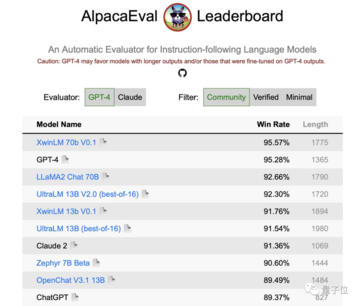 Zephyrに駆けつけたネチズンは満場一致で賞賛し、lmsysチームもZephyr-7b-beta 🔥のEloスコアを示しました。> アリーナの内部リーダーボードが13Bモデルを突破しました。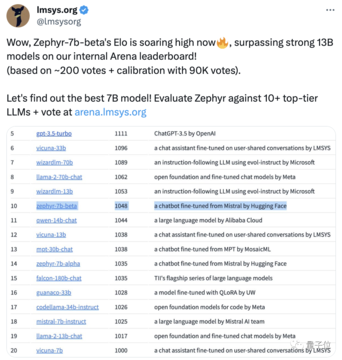 何人かの人々はさえ言いました:> DPOのアプローチが現場でうまく機能しているのを見るのは、おそらく今年の大規模言語モデルの開発で最もエキサイティングなことです。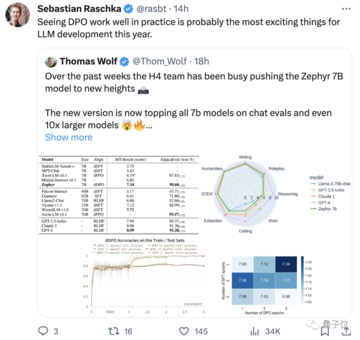 より多くのネチズンがゼファーの効果をテストし始めており、結果は驚くほど良好です。ミストラルという言葉はフランス語で乾燥した冷たく強い風を意味し、ゼファーは穏やかで心地よい西風を意味します。ラマの反対側に動物園があるのは間違いないし、こちら側には気象局があるのは間違いない。 ## **最高の7Bモデルが再び手を変えます** Zephyrを実行するためのコンピューター要件から始めましょう。 ネチズンはテスト後に「タイのパンツは辛い」と言いました! 、ノートブック(Apple M1 Pro)で十分、「結果は非常に良いです」。 効果の面では、Llama Index(旧GPT Index)チームもテストしました。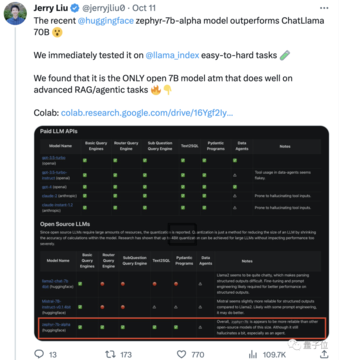 Zephyrは現在、高レベルのRAG/エージェントタスクで優れたパフォーマンスを発揮する唯一のオープンソース7Bモデルであることが判明しました。また、Zephyrの高度なRAGタスクの効果は、GPT-3.5やClaude 2に匹敵することもデータから示されています。さらに、ZephyrはRAGだけでなく、ルーティング、クエリ計画、複雑なSQLステートメントの取得、構造化データ抽出にも適していると付け加えました。 当局はテスト結果も発表し、MT-Benchでは、Zephyr-7B-betaはLlama2-Chat-70Bなどの大型モデルと比較して強力なパフォーマンスを発揮しています。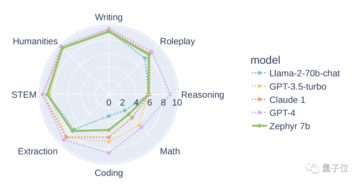 しかし、コーディングや数学などのより複雑なタスクでは、Zephyr-7B-betaは独自のモデルに遅れをとっており、ギャップを埋めるにはより多くの研究が必要です。 ## **強化学習の放棄** 誰もがZephyrの効果をテストしていますが、開発者は、最も興味深いのは指標ではなく、モデルのトレーニング方法だと言います。主な内容を以下にまとめます。*最高の小さなオープンソースの事前学習済みモデルを微調整する:Mistral 7B・大規模嗜好データセットの利用:UltraFeedback* 強化学習の代わりに直接選好最適化 (DPO) を使用する* 意外なことに、嗜好データセットのオーバーフィットはより良い結果をもたらします大まかに言うと、冒頭で述べたように、ゼファーが70Bラマ2を凌駕できる主な理由は、特殊な微調整方法を使用しているためです。従来のPPO強化学習アプローチとは異なり、研究チームはスタンフォード大学とCZ Biohubの最近のコラボレーションを使用して、DPOアプローチを提案しました。 研究者によると、> DPOはPPOよりもはるかに安定しています。簡単に言うと、DPOは次のように説明できます。モデルの出力を人間の好みに合わせるために、従来のアプローチは、報酬モデルを使用してターゲットモデルを微調整することでした。 アウトプットが良ければ報われ、アウトプットが悪ければ報われません。一方、DPOアプローチは、モデリング報酬関数をバイパスし、嗜好データに基づいてモデルを直接最適化することと同等です。一般的に、DPOは、人間のフィードバックによる強化学習トレーニングの困難でコストのかかる問題を解決します。特にZephyrのトレーニングに関しては、研究チームはまず、ChatGPTによって生成された160万件の会話(残り約20万件)を含むUltraChatデータセットの合理化されたバリアントでZephyr-7B-alphaを微調整しました。(合理化の理由は、Zephyr が "Hi. お元気ですか?」 応答が「私は個人的なXを持っていません」で始まることがあります。 )その後、TRLのDPO Trainerメソッドを使用して、公開されているopenbmb/UltraFeedbackデータセットとモデルをさらに整合させました。データセットには、さまざまなモデルからの 64,000 のプロンプトと応答のペアが含まれています。 各回答は、有用性などの基準に基づいてGPT-4によってランク付けされ、AIの好みが導き出されるスコアが与えられます。興味深い発見は、DPO法を使用する場合、トレーニング時間が長くなるにつれて、オーバーフィッティング後の効果が実際に向上することです。 研究者らは、これはSFTの過学習に似ていると考えています。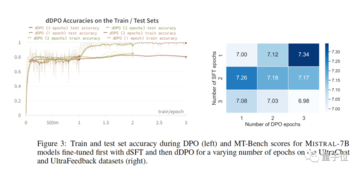 研究チームは、この方法でモデルを微調整するのにわずか500ドルしかかからず、16台のA100で8時間稼働できることも紹介しています。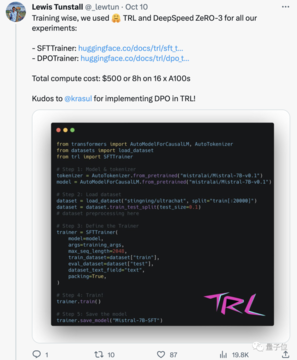 Zephyrをベータ版にアップグレードする際、チームは彼らのアプローチを説明しました。大規模なモデルで使用される蒸留教師あり微調整(dSFT)を検討しましたが、このアプローチではモデルがずれてしまい、ユーザーの意図に合った出力が得られませんでした。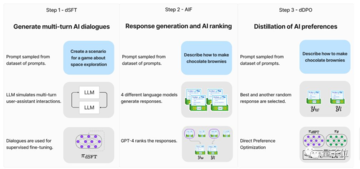 そこでチームは、AI Feedback(AIF)の嗜好データを使用して出力を「教師モデル」でランク付けしてデータセットを形成し、蒸留直接嗜好最適化(dDPO)を適用して、微調整中に追加のサンプリングを行うことなく、ユーザーの意図に沿ったモデルをトレーニングしようとしました。研究者らは、SFTを使用しない場合の効果もテストし、その結果、パフォーマンスが大幅に低下し、dSFTステップが重要であることが示されました。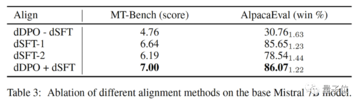 現在、モデルはオープンソースで商用化されているだけでなく、試してみるデモもあるので、簡単に始めて体験することができます。 ## **デモ体験** まず、テストを受けるために「知的障害者」の質問から移動しなければなりませんでした。「ママとパパは結婚しても私を連れて行かない」という質問では、ゼファーの全体的な答えの方が正確です。 ChatGPT はこの質問に勝るものはありません。 このテストでは、ZephyrがOpenAIによるGPT-4のリリースなどの最近のイベントについても知っていることもわかりました。 これは実際にはその基礎となるモデルに関連していますが、ミストラルの関係者はトレーニングデータの期限を指定していません。しかし、一部のネチズンは以前にそれをテストしており、今年の3月にもそれについて知っています。 これに対し、ラマ2の事前学習データは2022年9月時点のもので、2023年6月までは一部の微調整データのみとなっています。さらに、Zephyrは非常に応答性が高いため、コードを記述してストーリーを作成できます。 : Zephyrは英語での質問に答えるのが得意で、「幻覚」モデルに共通の問題を抱えていることは言及する価値があります。研究者は幻覚についても言及し、入力ボックスの下に小さなテキスト行がマークされ、モデルによって生成されたコンテンツが不正確または不正確である可能性があることが示されました。 重要なのは、Zephyrは人間の好みに合わせて人間のフィードバックによる強化学習などの方法を使用しておらず、ChatGPTの応答フィルタリングも使用していないことです。常にエムムフィッシュとクマの足のいずれかを選択してください。Zephyrはわずか70Bのパラメータでこれを実現できたため、「The 100-Page Machine Learning Book」の著者であるAndriy Burkov氏は次のように述べています。Zephyr-7B>、理論的には最大128Kトークンのアテンション範囲を持つ8kトークンのコンテキストウィンドウを持つMistral-7Bの基本モデルでLlama 2-70Bを打ち負かします。 > ゼファーが70Bモデルだったら? GPT-4を凌駕するのでしょうか? その可能性は高そうです。 Zephyr-7Bに興味がある方は、huggingfaceで試してみてください。論文リンク集:参考リンク: [1] [2] [3] [4] [5]
最高の7Bモデルが再び手を変え品を変えます! 700億のLLaMA2を打ち負かし、Appleコンピュータは稼働可能になる|オープンソースで無料
元のソース: qubits
「調整」に500ドルかかった70億パラメータのモデルは、700億パラメータのラマ2を打ち負かしました!
また、ノートブックは簡単に実行でき、効果はChatGPTに匹敵します。
重要: 無料、お金なし。
HuggingFace H4チームによって作成されたオープンソースモデルZephyr-7B、shark crazy。
Zephyrがバリアントの中で際立っている鍵は、チームがMistral上でDirect Preference Optimization(DPO)を使用して公開データセットでモデルを微調整したことでした。
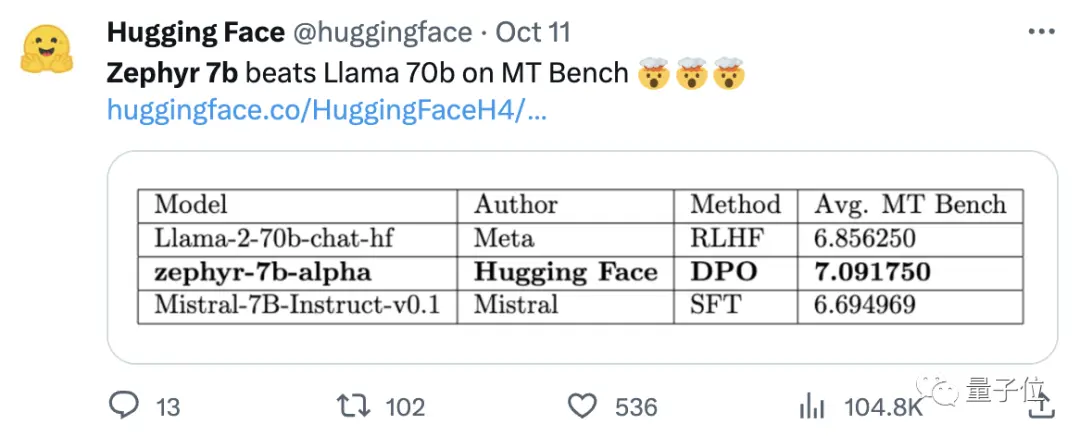
また、データセットに組み込まれているアライメントを削除することで、MT Benchのパフォーマンスをさらに向上させることができることもわかりました。 初代Zephyr-7B-alphaのMT-Benchの平均スコアは7.09で、Llama2-70B-Chatを上回った。
** **###### △MT-Benchは、モデルの複数ラウンドの対話を処理する能力を評価するためのベンチマークテストであり、問題セットは、ライティング、ロールプレイング、抽出など8つのカテゴリをカバーしています。
**###### △MT-Benchは、モデルの複数ラウンドの対話を処理する能力を評価するためのベンチマークテストであり、問題セットは、ライティング、ロールプレイング、抽出など8つのカテゴリをカバーしています。
要するに、その後、アップグレードが進んだのです!
H4チームは、第2世代のZephyr-7B-betaを発売しました。 また、GPT-4、Claude 2からアライメントを抽出し、それを小型モデルに注入するというアイデアを模索し、小型モデルに蒸留直接選好最適化(dDPO)を使用する方法を開発したと付け加えました。
第2世代のZephyrでは、MT-Benchの平均スコアが7.34に上昇しました。
ミストラルという言葉はフランス語で乾燥した冷たく強い風を意味し、ゼファーは穏やかで心地よい西風を意味します。
ラマの反対側に動物園があるのは間違いないし、こちら側には気象局があるのは間違いない。
最高の7Bモデルが再び手を変えます
Zephyrを実行するためのコンピューター要件から始めましょう。 ネチズンはテスト後に「タイのパンツは辛い」と言いました! 、ノートブック(Apple M1 Pro)で十分、「結果は非常に良いです」。
また、Zephyrの高度なRAGタスクの効果は、GPT-3.5やClaude 2に匹敵することもデータから示されています。
さらに、ZephyrはRAGだけでなく、ルーティング、クエリ計画、複雑なSQLステートメントの取得、構造化データ抽出にも適していると付け加えました。
強化学習の放棄
誰もがZephyrの効果をテストしていますが、開発者は、最も興味深いのは指標ではなく、モデルのトレーニング方法だと言います。
主な内容を以下にまとめます。
*最高の小さなオープンソースの事前学習済みモデルを微調整する:Mistral 7B ・大規模嗜好データセットの利用:UltraFeedback
大まかに言うと、冒頭で述べたように、ゼファーが70Bラマ2を凌駕できる主な理由は、特殊な微調整方法を使用しているためです。
従来のPPO強化学習アプローチとは異なり、研究チームはスタンフォード大学とCZ Biohubの最近のコラボレーションを使用して、DPOアプローチを提案しました。
簡単に言うと、DPOは次のように説明できます。
モデルの出力を人間の好みに合わせるために、従来のアプローチは、報酬モデルを使用してターゲットモデルを微調整することでした。 アウトプットが良ければ報われ、アウトプットが悪ければ報われません。
一方、DPOアプローチは、モデリング報酬関数をバイパスし、嗜好データに基づいてモデルを直接最適化することと同等です。
一般的に、DPOは、人間のフィードバックによる強化学習トレーニングの困難でコストのかかる問題を解決します。
特にZephyrのトレーニングに関しては、研究チームはまず、ChatGPTによって生成された160万件の会話(残り約20万件)を含むUltraChatデータセットの合理化されたバリアントでZephyr-7B-alphaを微調整しました。
(合理化の理由は、Zephyr が "Hi. お元気ですか?」 応答が「私は個人的なXを持っていません」で始まることがあります。 )
その後、TRLのDPO Trainerメソッドを使用して、公開されているopenbmb/UltraFeedbackデータセットとモデルをさらに整合させました。
データセットには、さまざまなモデルからの 64,000 のプロンプトと応答のペアが含まれています。 各回答は、有用性などの基準に基づいてGPT-4によってランク付けされ、AIの好みが導き出されるスコアが与えられます。
興味深い発見は、DPO法を使用する場合、トレーニング時間が長くなるにつれて、オーバーフィッティング後の効果が実際に向上することです。 研究者らは、これはSFTの過学習に似ていると考えています。
大規模なモデルで使用される蒸留教師あり微調整(dSFT)を検討しましたが、このアプローチではモデルがずれてしまい、ユーザーの意図に合った出力が得られませんでした。
研究者らは、SFTを使用しない場合の効果もテストし、その結果、パフォーマンスが大幅に低下し、dSFTステップが重要であることが示されました。
デモ体験
まず、テストを受けるために「知的障害者」の質問から移動しなければなりませんでした。
「ママとパパは結婚しても私を連れて行かない」という質問では、ゼファーの全体的な答えの方が正確です。
しかし、一部のネチズンは以前にそれをテストしており、今年の3月にもそれについて知っています。
さらに、Zephyrは非常に応答性が高いため、コードを記述してストーリーを作成できます。 :
研究者は幻覚についても言及し、入力ボックスの下に小さなテキスト行がマークされ、モデルによって生成されたコンテンツが不正確または不正確である可能性があることが示されました。
常にエムムフィッシュとクマの足のいずれかを選択してください。
Zephyrはわずか70Bのパラメータでこれを実現できたため、「The 100-Page Machine Learning Book」の著者であるAndriy Burkov氏は次のように述べています。
Zephyr-7B>、理論的には最大128Kトークンのアテンション範囲を持つ8kトークンのコンテキストウィンドウを持つMistral-7Bの基本モデルでLlama 2-70Bを打ち負かします。
論文リンク集:
参考リンク:
[1]
[2]
[3]
[4]
[5]