**これまでのストーリー**ゼロ知識証明(ZKP)は、分散型システムにとってますます重要になってきています。 ZKは当初、ZCashなどのプロジェクトでの成功で世間の注目を集めましたが、今日ではZKはイーサリアムのスケーリングソリューションとして知られています。ZKを活用して、ロールアップとも呼ばれるレイヤー2(スクロールやポリゴンなど)は、zkEVM(zk Ethereum Virtual Machine)を開発しています。 これらのzkEVMは、トランザクションのバッチを処理し、小さなプルーフ(キロバイト単位)を生成します。 この構成証明は、トランザクションのバッチが有効で正しいことをネットワーク全体に対して検証するために使用できます。しかし、その用途はそれだけにとどまりません。 ZKは、さまざまな興味深いアプリケーションを可能にします。例えば、プライベートレイヤー1 – Minaは、ブロックチェーン上の取引の詳細とデータを隠蔽し、ユーザーは取引自体の詳細を明らかにすることなく、取引の有効性を証明することしかできません。 neptune.cashとAleoも非常に興味深いプロジェクトです。**分散型クラウドプラットフォーム** - FedMLと together.xyz を使用すると、機械学習(ML)モデルを分散型でトレーニングし、計算をネットワークにアウトソーシングし、ZKPを使用して計算の正確性を検証できます。 Druglikeは、同様の技術を使用して、よりオープンな創薬プラットフォームを構築しています。**分散型ストレージ** - Filecoinはクラウドストレージに革命をもたらしており、ZKはその中核であり、ストレージプロバイダーが一定期間にわたって適切なデータを保存したことを証明することができます。**ゲーム** - Darkforestのより高度なバージョンが登場する可能性があり、リアルタイムの証拠が必要です。 ZKは、不正行為の可能性を減らすためにゲームを拡張することもできます。 分散型クラウドプラットフォームと連携して、ゲームが独自のホスティング料金を支払うことができるようにすることもできます。**ID** - ZKによる分散型認証も可能になりました。 このアイデアを中心に、多くの興味深いプロジェクトが構築されています。 たとえば、notebook や zkemail (学習することをお勧めします) などです。ZKと分散型システムの影響は甚大ですが、ストーリーの展開は完璧ではなく、今日でも多くの障害や課題があります。 証明の生成を含めるプロセスは非常にリソースを大量に消費し、多くの複雑な数学的操作を必要とします。 開発者は、証明生成プロセスと検証プロセスの両方において、ZK技術を使用してより野心的で複雑なプロトコルとシステムを構築しようとするため、開発者はより小さな証明サイズ、より高速なパフォーマンス、およびより優れた最適化を求めています。この記事では、ハードウェアアクセラレーションの現状と、ZKの採用を進める上でハードウェアアクセラレーションがどのように重要な役割を果たすかを探ります。**スナーク対スターク**現在、zk-STARKとzk-SNARKの2つの一般的なゼロ知識手法があります(この記事ではBulletproofsは無視しています)。| | | ||--- |--- |--- ||zk-スターク |ZK-スナーク | ||複雑性 - Prover |O(N \* poly-log(N)) |O(N \* log(N)) ||複雑性 - Verifier |O(poly-log(N)) |O(1) ||**プルーフサイズ** |45KB-200KBの|~ 288 バイト ||**抗量子** |はい (ハッシュ関数ベース) |いいえ ||**信頼できる設定** |いいえ |**はい** ||ゼロ知識 |はい |はい ||インタラクティビティ |インタラクティブまたは非インタラクティブ |非インタラクティブ || 開発者向けドキュメント | 限定的だが拡大中 良い |**表1:スナークVSスターク**前述したように、両者には違いとトレードオフがあります。 最も重要な点は、zk-SNARKベースのシステムの信頼できるセットアップは、信頼できるセットアッププロセスに関与し、プロセスの最後にキーが破棄される少なくとも1人の誠実な参加者に依存していることです。 オンチェーン検証の面では、zk-SNARKsはガス代の面ではるかに安価です。 さらに、zk-SNARKのプルーフも大幅に小さいため、オンチェーンでの保存コストが安くなります。現在、zk-STARKよりもzk-SNARKの方が人気があります。 最も可能性の高い理由は、zk-SNARKの歴史がはるかに長いことです。 もう一つの理由として考えられるのは、最初のZKブロックチェーンの1つであるZcashがzk-SNARKを使用していたため、現在の開発ツールやドキュメントのほとんどがzk-SNARKエコシステムを中心に展開していることです。**ZKアプリケーションの構築方法**開発者は、ZKアプリケーションの開発を完了するために2つのコンポーネントを必要とする場合がありますZKフレンドリーな式計算方法(DSLまたは低レベルライブラリ)。Prove と Verify の 2 つの機能を実装する構成証明システム。DSL (ドメイン固有言語) と低レベルライブラリDSLに関しては、Circom、Halo2、Noirなど、多くのオプションがあります。 Circomはおそらく現時点で最も人気があります。 低レベルのライブラリに関して言えば、一般的な例はArkworksです。 また、CUDAアクセラレーションライブラリであるICICLEなど、開発中のライブラリもあります。これらのDSLは、制限されたシステムを出力するように設計されています。 通常 x:= y \*z の形式で評価される通常のプログラムとは異なり、制約された形式の同じプログラムは x-y \* z = 0 のようになります。 プログラムを制約のシステムとして表現することで、加算や乗算などの演算を単一の制約で表現できることがわかります。 ただし、ビット演算などのより複雑な演算には、何百もの制約が必要になることがあります。その結果、一部のハッシュ関数をZKフレンドリーなプログラムとして実装することが複雑になります。 ゼロ知識証明では、データの完全性を確保したり、データの特定の特性を検証したりするためにハッシュ関数がよく使用されますが、ビット演算の制約が多いため、一部のハッシュ関数はゼロ知識証明の環境に適応することが困難です。 この複雑さは、証明の生成と検証の効率に影響を与える可能性があるため、開発者がZKベースのアプリケーションを構築する際に考慮して解決する必要がある問題になりますその結果、ZKに適したハッシュ関数を実装するのが複雑になります。はんめいプルーフシステムは、プルーフの生成とプルーフの検証という2つの主要なタスクを実行するソフトウェアに例えることができます。 プルーフ・システムは通常、回路、証拠、およびパブリック/プライベート・パラメータを入力として受け入れます。2つの最も普及した証拠システムはGroth16およびPLONKシリーズ(Plonk、HyperPlonk、UltraPlonk)である| | | | | | ||--- |--- |--- |--- |--- |--- || | トラステッドセットアップ | プルーフサイズ | 証明の複雑性 | 検証ツールの複雑性 | 柔軟性 ||Groth16 |回路固有 |小さい |該当なし |該当なし |該当なし ||プロンク |ユニバーサル |ラージ |高 |常数 |高 |**表2:Groth16 vs Plonk**表 2 に示すように、Groth16 には信頼できるセットアップ プロセスが必要ですが、Groth16 は、より高速な証明と検証時間、および一定の証明サイズを提供します。Plonk は、証明が生成されるたびに、実行している回路の前処理フェーズを実行する汎用セットアップを提供します。 多くの回路をサポートしているにもかかわらず、Plonkの検証時間は一定です。この 2 つには、制約の点でも違いがあります。 Groth16 は制約サイズの点で線形に成長し、柔軟性に欠けますが、Plonk はより柔軟です。全体として、パフォーマンスはZKアプリケーションの制約の数に直接関係することを理解してください。 制約条件が多ければ多いほど、証明者が計算しなければならない演算の数も多くなります。ボトルネック証明システムは、マルチスカラー乗算(MSM)と高速フーリエ変換(FFT)の2つの主要な数学演算で構成されています。 今日は、MSMが実行時間の約60%を占め、FFTが約30%を占めるシステムについて説明します。MSM は大量のメモリ アクセスを必要とし、ほとんどの場合、マシン上で大量のメモリを消費し、同時に多くのスカラー乗算演算も実行します。FFTアルゴリズムでは、多くの場合、変換を実行するために入力データを特定の順序に並べ替える必要があります。 これには大量のデータ移動が必要になり、特に入力サイズが大きい場合はボトルネックになる可能性があります。 キャッシュ使用率は、メモリ アクセス パターンがキャッシュ階層に適合しない場合にも問題になる可能性があります。**この場合、ハードウェアアクセラレーションは、ZKPのパフォーマンスを完全に最適化する唯一の方法です。 ****ハードウェアアクセラレーション**ハードウェアアクセラレーションに関しては、ASICとGPUがビットコインとイーサリアムのマイニングをどのように支配したかを思い出させます。ソフトウェアの最適化も同様に重要で価値がありますが、限界もあります。 一方、ハードウェア最適化では、スレッドの同期やベクトル化を減らすなど、複数の処理ユニットを持つFPGAを設計することで、並列性を向上させることができます。 メモリ階層とアクセスパターンを改善することで、メモリアクセスをより効率的に最適化することもできます。現在、ZKPの分野では、GPUとFPGAが主なトレンドにシフトしているようです。短期的には、特にETHがプルーフ・オブ・ステーク(POS)に移行した後、GPUは価格面で優位に立ち、多くのGPUマイナーがアイドル状態になり、スタンバイ状態になります。 さらに、GPU には開発サイクルが短いという利点があり、開発者に多くの "プラグ アンド プレイ" 並列処理を提供します。しかし、FPGAは、特にフォームファクタと消費電力を比較する場合、追いつく必要があります。 また、FPGAは高速データストリームのレイテンシを低く抑えます。 複数のFPGAをクラスタ化すると、GPUクラスタと比較してパフォーマンスが向上します。**GPUとFPGA****GPU:**開発時間: GPU は開発時間を短縮します。 CUDAやOpenCLなどのフレームワークの開発者向けドキュメントは、よく開発され、人気があります。消費電力:GPUは非常に「電力を大量に消費する」ものです。 開発者がデータレベルの並列処理とスレッドレベルの並列処理を利用した場合でも、GPU は依然として多くの電力を消費します。**可用性**: コンシューマー グレードの GPU は安価で、今すぐすぐに入手できます。**FPGA:**開発サイクル:FPGAの開発サイクルはより複雑で、より専門的なエンジニアが必要です。 FPGAを使用すると、エンジニアはGPUでは不可能な多くの「低レベル」の最適化を実現できます。レイテンシ:FPGAは、特に大規模なデータストリームを処理する場合にレイテンシを低くします。コストと可用性:FPGAはGPUよりも高価であり、GPUほど簡単に入手できません。**ZPRIZEの**今日、ハードウェア最適化とZKPのボトルネックに関しては、避けて通れない競争があります-**ZPRIZE**ZPrizeは、現在ZK分野で最も重要な取り組みの1つです。 ZPrizeは、複数のプラットフォーム(FPGA、GPU、モバイルデバイス、ブラウザなど)で、レイテンシー、スループット、効率に基づいて、ZKPの主要なボトルネック(MSM、NTT、Poseidonなど)のハードウェアアクセラレーションを開発することをチームに奨励するコンペティションです。その結果、非常に興味深い結果が得られました。 たとえば、GPU の改良は大きく異なります。2^26 の MSM は 5.86 秒から 2.52 秒に 131% 増加しました。 一方、FPGAソリューションは、比較する以前のベンチマークがあるGPUの結果と比較してベンチマークがない傾向があり、ほとんどのFPGAソリューションは、そのようなアルゴリズムが将来的に改善されることが期待されて、初めてオープンソース化されています。これらの結果は、ほとんどの開発者がハードウェア アクセラレーション ソリューションの開発に安心感を持っていることを示しています。 多くのチームがGPUカテゴリーを競い合っていますが、FPGAカテゴリーを争うのはごく一部です。 FPGA向けの開発経験が不足しているからなのか、それともほとんどのFPGA企業/チームがソリューションを商業的に販売するために秘密裏に開発することを選択しているのかはわかりません。ZPrizeは、コミュニティにいくつかの非常に興味深い研究を提供しています。 ZPrizeのラウンドが増えるにつれて、ますます興味深い解決策や問題が現れるでしょう。**ハードウェアアクセラレーションの実例**Groth16を例にとると、Groth16のrapidsnarkの実装を調べると、FFT(高速フーリエ変換)とMSM(マルチスカラー乗算)の2つの主要な演算が実行されていることがわかります。 これら 2 つの基本的な操作は、多くの証明システムで共通です。 それらの実行時間は、回路内の制約の数に直接関係します。 当然のことながら、回路が複雑になればなるほど、制約の数は増えます。FFTとMSMの演算がいかに計算量が多いかを知るために、IngonyamaのGroth16回路(FilecoinのバニラC2プロセスを32GBセクターで実行)のベンチマークを確認すると、結果は次のようになります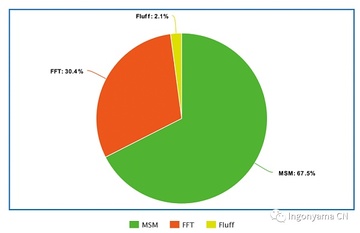 上の図に示すように、MSM(Multiscalar Multiplication)は時間がかかり、多くの証明者にとって深刻なパフォーマンスのボトルネックとなる可能性があるため、MSMは高速化が必要な最も重要な暗号演算子の1つとなっています。では、MSMは他のZK証明システムで証明者に対してどのくらいの計算量を占めるのでしょうか? これを下図に示します Plonkでは、MSMがオーバーヘッドの85%以上を占めていることが、Ingonyama氏の最新の論文「Pipe MSM」で示されています。 **では、ハードウェアアクセラレーションはどのようにしてMSMを高速化すべきなのでしょうか? ****MSMの**MSMを高速化する方法を説明する前に、MSMとは何かを理解する必要がありますMulti-Scalar Multiplication (MSM) は、複数のスカラー乗算の合計を次の形式で計算するためのアルゴリズムです ここで、G は楕円曲線群の点、a はスカラーであり、MSM の結果も楕円曲線の点になります**MSMは、2つの主要なサブコンポーネントに分解できます。モジュラー乗算楕円カーブ ポイントの追加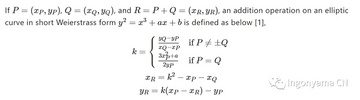 Affine(x,y)を例にとり、素朴なP+Q演算を実行してみましょう。P + Q = Rを計算する場合は、kとP、Qの横軸で値kを計算する必要がありますR の座標を取得します。 計算処理は上記の通りで、この処理では**2回の掛け算、1つの2乗演算、1つの逆演算**、および数回の加算と減算の演算を実行します。 上記の操作は有限体、つまりmod Pの下で実行されることは注目に値します。 実際には、Pは非常に大きくなります。 **上記の演算のコストは、逆>>乗算** **> ****の2乗を見つけることであり、加算と減算のコストはごくわずかです。したがって、1回の反転のコストは少なくとも100倍の乗算であるため、逆数はできるだけ避けたいと考えています。 これは座標系を拡張することで実現できますが、ヤコビアン座標:XYZ + = XYZなどのプロセスでの乗算の数を増やし、加算アルゴリズムに応じて10倍以上乗算します。 ****GPU と FPGA のアクセラレーテッド MSM**このセクションでは、PipeMSM が FPGA に実装され、Sppark が GPU に実装されている 2 つの主要な MSM 実装である PipeMSM と Sppark を比較します。Sppark と PipeMSM は、最先端の Pippenger アルゴリズムを使用して MSM (バケット アルゴリズムとも呼ばれます) を実装します。 **Sppark は CUDA を使用して実装されます。 それらのバージョンは高度に並列処理されており、最新のGPUで実行すると印象的な結果が得られています。ただし、PipeMSM はアルゴリズムを最適化するだけでなく、モジュラー乗算と EC 加算の数学的プリミティブの最適化も提供します。 PipeMSMは「MSMスタック」全体を扱い、MSMをよりハードウェアに適したものにするための一連の数学的トリックと最適化を実装し、並列化に重点を置いたレイテンシーを低減するハードウェア設計を設計します。PipeMSM の実装について簡単におさらいしましょう。**低遅延** PipeMSM は、多数の入力に対して複数の MSM を実行する場合に低レイテンシを提供するように設計されています。 GPU は、動的な周波数スケーリングにより確定的な低遅延を提供せず、GPU はワークロードに基づいてクロック速度を調整します。しかし、最適化されたハードウェア設計により、FPGAの実装は、特定のワークロードに対して確定的なパフォーマンスとレイテンシを提供することができます。**EC追加実装** 楕円曲線点加算 (EC 加算) は、低遅延、高度に並列化、および **完全** 式として実装されます (完全とは、楕円曲線グループ内の任意の 2 つの点の合計を正しく計算することを意味します)。 楕円曲線点加算は、待機時間を短縮するために、EC 加算モジュールでパイプライン方式で使用されます。座標を射影座標として表すことを選択し、加算アルゴリズムでは完全楕円曲線点加算式を使用します。 主な利点は、**エッジケースに対処する必要がない**ことです。 完全な数式。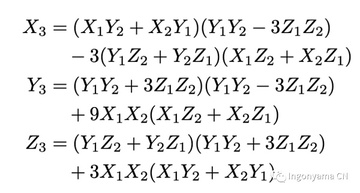 この加算式をパイプライン方式と並列方式で実装し、FPGA楕円曲線加算回路は12回の乗算と17回の加算のみで、この式を実行しました。 元の式では、15 の剰余乗と 13 の加算が必要です。 FPGAの設計は以下の通りです。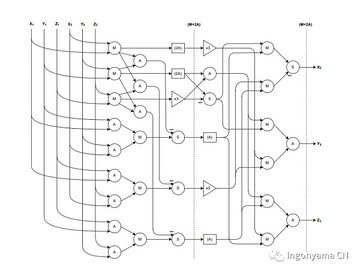 マルチモッドバレットリダクションアルゴリズムとカラツバアルゴリズムを利用しました。バレットリダクションは、r≡ab mod p (p は固定) を効率的に計算するアルゴリズムです。 バレットリダクションは、除算(コストのかかる操作)を近似除算に置き換えようとします。 許容誤差を選択して、正しい結果を求めている範囲を記述できます。 許容誤差が大きいため、より小さなリダクション定数を使用できることがわかります。 これにより、モジュロリダクション演算で使用される中間値のサイズが小さくなり、最終結果の計算に必要な乗算の数が減ります。下の青いボックスでは、エラー耐性が高いため、正確な結果を見つけるために複数のチェックを実行する必要があることがわかります。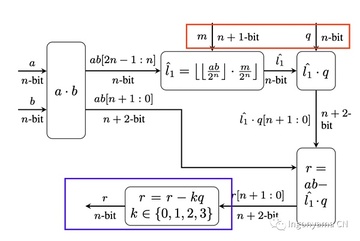 一言で言えば、Karatsubaアルゴリズムは、Barrett Reductionで実行する乗算を最適化するために使用されます。 Karatsubaのアルゴリズムは、2つのn桁の乗算を3つのn/2桁の乗算に単純化します。 これらの乗算により、ハードウェアで直接計算できるほど桁数を狭くすることができます。 **詳細はIngoの論文「Pipe MSM」で読むことができます。上記の演算子を使用して、低遅延で高度に並列化されたMSM実装を開発しました。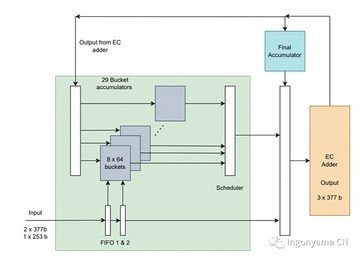 核となる考え方は、MSM全体を一度に計算する代わりに、各チャンクを並列にEC加算器に渡すことです。 EC 加算器の結果は、最終 MSM に累積されます。最終結果****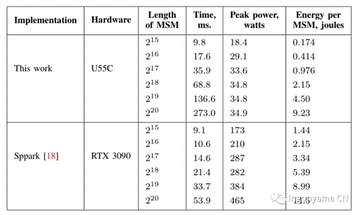 上の図は、Sppark と PipeMSM の比較を示しています。最も顕著なのは、FPGAがもたらす大幅な省エネであり、これは将来の大規模なプルーフ生成操作にとって非常に重要になる可能性があります。 私たちの実装は@125MHzの下でプロトタイプ化され、ベンチマークされており、クロック速度を@500MHzに上げると、計算時間が4倍以上増加する可能性があることは注目に値します。また、当社のFPGAは、消費電力や発熱が少ないため、小型の筐体サーバに搭載できるのもメリットです。ZKPのFPGAエンジニアリングは初期段階にあり、アルゴリズムのさらなる改善が期待されます。 また、CPUがアイドル状態のときにFPGAがMSMを計算しているため、FPGAをシステムリソース(CPU/GPU)と組み合わせて使用することで、より高速な時間を実現できる可能性があります。**概要**ZKPは、分散システムのキーテクノロジーとなっています。ZKPのアプリケーションは、イーサリアムレベルを拡張するだけでなく、信頼できない第三者への計算のアウトソーシングを可能にし、分散クラウドコンピューティングやIDシステムなど、以前は不可能だったシステムの開発を可能にします。従来、ZKPの最適化はソフトウェアレベルの改善に重点が置かれていましたが、より優れたパフォーマンスに対する需要が高まるにつれて、ハードウェアとソフトウェアの両方を含むより高度なアクセラレーションソリューションが登場するでしょう。現在、CUDAを使用した開発期間が短く、現在のコンシューマ向けGPUは非常に安価で豊富であるため、現在見られるアクセラレーションソリューションは主にGPUを使用しています。 GPUは驚異的なパフォーマンスも提供します。 したがって、GPUがすぐにこの分野から姿を消す可能性は低いでしょう。より複雑な開発チームがこの分野に参入するにつれて、FPGAが電力効率と性能の面で先導するようになるでしょう。 GPUと比較して、FPGAはより多くの低レベルのカスタマイズとより多くの構成オプションを提供します。 FPGAは、ASICよりも高速な開発速度と柔軟性を提供します。 ZKPの世界の急速な発展に伴い、FPGAはさまざまなプログラムで再フラッシュして、さまざまなシステムや更新ソリューションに対応することができます。ただし、ほぼリアルタイムの証明を生成するには、証明を生成するシステムによっては、GPU/FPGA/ASIC 構成を組み合わせる必要がある場合があります。また、ZPUは、大規模なプルーフジェネレーターや低電力デバイス向けに非常に効率的なソリューションを提供するために進化する可能性があります(詳細は以前の記事を参照)。
ハードウェアアクセラレーションが推進するZKの新時代
これまでのストーリー
ゼロ知識証明(ZKP)は、分散型システムにとってますます重要になってきています。 ZKは当初、ZCashなどのプロジェクトでの成功で世間の注目を集めましたが、今日ではZKはイーサリアムのスケーリングソリューションとして知られています。
ZKを活用して、ロールアップとも呼ばれるレイヤー2(スクロールやポリゴンなど)は、zkEVM(zk Ethereum Virtual Machine)を開発しています。 これらのzkEVMは、トランザクションのバッチを処理し、小さなプルーフ(キロバイト単位)を生成します。 この構成証明は、トランザクションのバッチが有効で正しいことをネットワーク全体に対して検証するために使用できます。
しかし、その用途はそれだけにとどまりません。 ZKは、さまざまな興味深いアプリケーションを可能にします。
例えば、プライベートレイヤー1 – Minaは、ブロックチェーン上の取引の詳細とデータを隠蔽し、ユーザーは取引自体の詳細を明らかにすることなく、取引の有効性を証明することしかできません。 neptune.cashとAleoも非常に興味深いプロジェクトです。
分散型クラウドプラットフォーム - FedMLと together.xyz を使用すると、機械学習(ML)モデルを分散型でトレーニングし、計算をネットワークにアウトソーシングし、ZKPを使用して計算の正確性を検証できます。 Druglikeは、同様の技術を使用して、よりオープンな創薬プラットフォームを構築しています。
分散型ストレージ - Filecoinはクラウドストレージに革命をもたらしており、ZKはその中核であり、ストレージプロバイダーが一定期間にわたって適切なデータを保存したことを証明することができます。
ゲーム - Darkforestのより高度なバージョンが登場する可能性があり、リアルタイムの証拠が必要です。 ZKは、不正行為の可能性を減らすためにゲームを拡張することもできます。 分散型クラウドプラットフォームと連携して、ゲームが独自のホスティング料金を支払うことができるようにすることもできます。
ID - ZKによる分散型認証も可能になりました。 このアイデアを中心に、多くの興味深いプロジェクトが構築されています。 たとえば、notebook や zkemail (学習することをお勧めします) などです。
ZKと分散型システムの影響は甚大ですが、ストーリーの展開は完璧ではなく、今日でも多くの障害や課題があります。 証明の生成を含めるプロセスは非常にリソースを大量に消費し、多くの複雑な数学的操作を必要とします。 開発者は、証明生成プロセスと検証プロセスの両方において、ZK技術を使用してより野心的で複雑なプロトコルとシステムを構築しようとするため、開発者はより小さな証明サイズ、より高速なパフォーマンス、およびより優れた最適化を求めています。
この記事では、ハードウェアアクセラレーションの現状と、ZKの採用を進める上でハードウェアアクセラレーションがどのように重要な役割を果たすかを探ります。
スナーク対スターク
現在、zk-STARKとzk-SNARKの2つの一般的なゼロ知識手法があります(この記事ではBulletproofsは無視しています)。
| | | | |--- |--- |--- | |zk-スターク |ZK-スナーク | | |複雑性 - Prover |O(N * poly-log(N)) |O(N * log(N)) | |複雑性 - Verifier |O(poly-log(N)) |O(1) | |プルーフサイズ |45KB-200KBの|~ 288 バイト | |抗量子 |はい (ハッシュ関数ベース) |いいえ | |信頼できる設定 |いいえ |はい | |ゼロ知識 |はい |はい | |インタラクティビティ |インタラクティブまたは非インタラクティブ |非インタラクティブ | | 開発者向けドキュメント | 限定的だが拡大中 良い |
表1:スナークVSスターク
前述したように、両者には違いとトレードオフがあります。 最も重要な点は、zk-SNARKベースのシステムの信頼できるセットアップは、信頼できるセットアッププロセスに関与し、プロセスの最後にキーが破棄される少なくとも1人の誠実な参加者に依存していることです。 オンチェーン検証の面では、zk-SNARKsはガス代の面ではるかに安価です。 さらに、zk-SNARKのプルーフも大幅に小さいため、オンチェーンでの保存コストが安くなります。
現在、zk-STARKよりもzk-SNARKの方が人気があります。 最も可能性の高い理由は、zk-SNARKの歴史がはるかに長いことです。 もう一つの理由として考えられるのは、最初のZKブロックチェーンの1つであるZcashがzk-SNARKを使用していたため、現在の開発ツールやドキュメントのほとんどがzk-SNARKエコシステムを中心に展開していることです。
ZKアプリケーションの構築方法
開発者は、ZKアプリケーションの開発を完了するために2つのコンポーネントを必要とする場合があります
ZKフレンドリーな式計算方法(DSLまたは低レベルライブラリ)。
Prove と Verify の 2 つの機能を実装する構成証明システム。
DSL (ドメイン固有言語) と低レベルライブラリ
DSLに関しては、Circom、Halo2、Noirなど、多くのオプションがあります。 Circomはおそらく現時点で最も人気があります。
低レベルのライブラリに関して言えば、一般的な例はArkworksです。 また、CUDAアクセラレーションライブラリであるICICLEなど、開発中のライブラリもあります。
これらのDSLは、制限されたシステムを出力するように設計されています。 通常 x:= y *z の形式で評価される通常のプログラムとは異なり、制約された形式の同じプログラムは x-y * z = 0 のようになります。 プログラムを制約のシステムとして表現することで、加算や乗算などの演算を単一の制約で表現できることがわかります。 ただし、ビット演算などのより複雑な演算には、何百もの制約が必要になることがあります。
その結果、一部のハッシュ関数をZKフレンドリーなプログラムとして実装することが複雑になります。 ゼロ知識証明では、データの完全性を確保したり、データの特定の特性を検証したりするためにハッシュ関数がよく使用されますが、ビット演算の制約が多いため、一部のハッシュ関数はゼロ知識証明の環境に適応することが困難です。 この複雑さは、証明の生成と検証の効率に影響を与える可能性があるため、開発者がZKベースのアプリケーションを構築する際に考慮して解決する必要がある問題になります
その結果、ZKに適したハッシュ関数を実装するのが複雑になります。
はんめい
プルーフシステムは、プルーフの生成とプルーフの検証という2つの主要なタスクを実行するソフトウェアに例えることができます。 プルーフ・システムは通常、回路、証拠、およびパブリック/プライベート・パラメータを入力として受け入れます。
2つの最も普及した証拠システムはGroth16およびPLONKシリーズ(Plonk、HyperPlonk、UltraPlonk)である
| | | | | | | |--- |--- |--- |--- |--- |--- | | | トラステッドセットアップ | プルーフサイズ | 証明の複雑性 | 検証ツールの複雑性 | 柔軟性 | |Groth16 |回路固有 |小さい |該当なし |該当なし |該当なし | |プロンク |ユニバーサル |ラージ |高 |常数 |高 |
表2:Groth16 vs Plonk
表 2 に示すように、Groth16 には信頼できるセットアップ プロセスが必要ですが、Groth16 は、より高速な証明と検証時間、および一定の証明サイズを提供します。
Plonk は、証明が生成されるたびに、実行している回路の前処理フェーズを実行する汎用セットアップを提供します。 多くの回路をサポートしているにもかかわらず、Plonkの検証時間は一定です。
この 2 つには、制約の点でも違いがあります。 Groth16 は制約サイズの点で線形に成長し、柔軟性に欠けますが、Plonk はより柔軟です。
全体として、パフォーマンスはZKアプリケーションの制約の数に直接関係することを理解してください。 制約条件が多ければ多いほど、証明者が計算しなければならない演算の数も多くなります。
ボトルネック
証明システムは、マルチスカラー乗算(MSM)と高速フーリエ変換(FFT)の2つの主要な数学演算で構成されています。 今日は、MSMが実行時間の約60%を占め、FFTが約30%を占めるシステムについて説明します。
MSM は大量のメモリ アクセスを必要とし、ほとんどの場合、マシン上で大量のメモリを消費し、同時に多くのスカラー乗算演算も実行します。
FFTアルゴリズムでは、多くの場合、変換を実行するために入力データを特定の順序に並べ替える必要があります。 これには大量のデータ移動が必要になり、特に入力サイズが大きい場合はボトルネックになる可能性があります。 キャッシュ使用率は、メモリ アクセス パターンがキャッシュ階層に適合しない場合にも問題になる可能性があります。
**この場合、ハードウェアアクセラレーションは、ZKPのパフォーマンスを完全に最適化する唯一の方法です。 **
ハードウェアアクセラレーション
ハードウェアアクセラレーションに関しては、ASICとGPUがビットコインとイーサリアムのマイニングをどのように支配したかを思い出させます。
ソフトウェアの最適化も同様に重要で価値がありますが、限界もあります。 一方、ハードウェア最適化では、スレッドの同期やベクトル化を減らすなど、複数の処理ユニットを持つFPGAを設計することで、並列性を向上させることができます。 メモリ階層とアクセスパターンを改善することで、メモリアクセスをより効率的に最適化することもできます。
現在、ZKPの分野では、GPUとFPGAが主なトレンドにシフトしているようです。
短期的には、特にETHがプルーフ・オブ・ステーク(POS)に移行した後、GPUは価格面で優位に立ち、多くのGPUマイナーがアイドル状態になり、スタンバイ状態になります。 さらに、GPU には開発サイクルが短いという利点があり、開発者に多くの "プラグ アンド プレイ" 並列処理を提供します。
しかし、FPGAは、特にフォームファクタと消費電力を比較する場合、追いつく必要があります。 また、FPGAは高速データストリームのレイテンシを低く抑えます。 複数のFPGAをクラスタ化すると、GPUクラスタと比較してパフォーマンスが向上します。
GPUとFPGA
GPU:
開発時間: GPU は開発時間を短縮します。 CUDAやOpenCLなどのフレームワークの開発者向けドキュメントは、よく開発され、人気があります。
消費電力:GPUは非常に「電力を大量に消費する」ものです。 開発者がデータレベルの並列処理とスレッドレベルの並列処理を利用した場合でも、GPU は依然として多くの電力を消費します。
可用性: コンシューマー グレードの GPU は安価で、今すぐすぐに入手できます。
FPGA:
開発サイクル:FPGAの開発サイクルはより複雑で、より専門的なエンジニアが必要です。 FPGAを使用すると、エンジニアはGPUでは不可能な多くの「低レベル」の最適化を実現できます。
レイテンシ:FPGAは、特に大規模なデータストリームを処理する場合にレイテンシを低くします。
コストと可用性:FPGAはGPUよりも高価であり、GPUほど簡単に入手できません。
ZPRIZEの
今日、ハードウェア最適化とZKPのボトルネックに関しては、避けて通れない競争があります-ZPRIZE
ZPrizeは、現在ZK分野で最も重要な取り組みの1つです。 ZPrizeは、複数のプラットフォーム(FPGA、GPU、モバイルデバイス、ブラウザなど)で、レイテンシー、スループット、効率に基づいて、ZKPの主要なボトルネック(MSM、NTT、Poseidonなど)のハードウェアアクセラレーションを開発することをチームに奨励するコンペティションです。
その結果、非常に興味深い結果が得られました。 たとえば、GPU の改良は大きく異なります。
2^26 の MSM は 5.86 秒から 2.52 秒に 131% 増加しました。 一方、FPGAソリューションは、比較する以前のベンチマークがあるGPUの結果と比較してベンチマークがない傾向があり、ほとんどのFPGAソリューションは、そのようなアルゴリズムが将来的に改善されることが期待されて、初めてオープンソース化されています。
これらの結果は、ほとんどの開発者がハードウェア アクセラレーション ソリューションの開発に安心感を持っていることを示しています。 多くのチームがGPUカテゴリーを競い合っていますが、FPGAカテゴリーを争うのはごく一部です。 FPGA向けの開発経験が不足しているからなのか、それともほとんどのFPGA企業/チームがソリューションを商業的に販売するために秘密裏に開発することを選択しているのかはわかりません。
ZPrizeは、コミュニティにいくつかの非常に興味深い研究を提供しています。 ZPrizeのラウンドが増えるにつれて、ますます興味深い解決策や問題が現れるでしょう。
ハードウェアアクセラレーションの実例
Groth16を例にとると、Groth16のrapidsnarkの実装を調べると、FFT(高速フーリエ変換)とMSM(マルチスカラー乗算)の2つの主要な演算が実行されていることがわかります。 これら 2 つの基本的な操作は、多くの証明システムで共通です。 それらの実行時間は、回路内の制約の数に直接関係します。 当然のことながら、回路が複雑になればなるほど、制約の数は増えます。
FFTとMSMの演算がいかに計算量が多いかを知るために、IngonyamaのGroth16回路(FilecoinのバニラC2プロセスを32GBセクターで実行)のベンチマークを確認すると、結果は次のようになります
上の図に示すように、MSM(Multiscalar Multiplication)は時間がかかり、多くの証明者にとって深刻なパフォーマンスのボトルネックとなる可能性があるため、MSMは高速化が必要な最も重要な暗号演算子の1つとなっています。
では、MSMは他のZK証明システムで証明者に対してどのくらいの計算量を占めるのでしょうか? これを下図に示します
Plonkでは、MSMがオーバーヘッドの85%以上を占めていることが、Ingonyama氏の最新の論文「Pipe MSM」で示されています。 **
では、ハードウェアアクセラレーションはどのようにしてMSMを高速化すべきなのでしょうか? **
MSMの
MSMを高速化する方法を説明する前に、MSMとは何かを理解する必要があります
Multi-Scalar Multiplication (MSM) は、複数のスカラー乗算の合計を次の形式で計算するためのアルゴリズムです
ここで、G は楕円曲線群の点、a はスカラーであり、MSM の結果も楕円曲線の点になります**
MSMは、2つの主要なサブコンポーネントに分解できます。
モジュラー乗算
楕円カーブ ポイントの追加
Affine(x,y)を例にとり、素朴なP+Q演算を実行してみましょう。
P + Q = Rを計算する場合は、kとP、Qの横軸で値kを計算する必要があります
R の座標を取得します。 計算処理は上記の通りで、この処理では2回の掛け算、1つの2乗演算、1つの逆演算、および数回の加算と減算の演算を実行します。 上記の操作は有限体、つまりmod Pの下で実行されることは注目に値します。 実際には、Pは非常に大きくなります。 **
上記の演算のコストは、逆>>乗算** **> ****の2乗を見つけることであり、加算と減算のコストはごくわずかです。
したがって、1回の反転のコストは少なくとも100倍の乗算であるため、逆数はできるだけ避けたいと考えています。 これは座標系を拡張することで実現できますが、ヤコビアン座標:XYZ + = XYZなどのプロセスでの乗算の数を増やし、加算アルゴリズムに応じて10倍以上乗算します。 **
GPU と FPGA のアクセラレーテッド MSM
このセクションでは、PipeMSM が FPGA に実装され、Sppark が GPU に実装されている 2 つの主要な MSM 実装である PipeMSM と Sppark を比較します。
Sppark と PipeMSM は、最先端の Pippenger アルゴリズムを使用して MSM (バケット アルゴリズムとも呼ばれます) を実装します。 **
Sppark は CUDA を使用して実装されます。 それらのバージョンは高度に並列処理されており、最新のGPUで実行すると印象的な結果が得られています。
ただし、PipeMSM はアルゴリズムを最適化するだけでなく、モジュラー乗算と EC 加算の数学的プリミティブの最適化も提供します。 PipeMSMは「MSMスタック」全体を扱い、MSMをよりハードウェアに適したものにするための一連の数学的トリックと最適化を実装し、並列化に重点を置いたレイテンシーを低減するハードウェア設計を設計します。
PipeMSM の実装について簡単におさらいしましょう。
低遅延
PipeMSM は、多数の入力に対して複数の MSM を実行する場合に低レイテンシを提供するように設計されています。 GPU は、動的な周波数スケーリングにより確定的な低遅延を提供せず、GPU はワークロードに基づいてクロック速度を調整します。
しかし、最適化されたハードウェア設計により、FPGAの実装は、特定のワークロードに対して確定的なパフォーマンスとレイテンシを提供することができます。
EC追加実装
楕円曲線点加算 (EC 加算) は、低遅延、高度に並列化、および 完全 式として実装されます (完全とは、楕円曲線グループ内の任意の 2 つの点の合計を正しく計算することを意味します)。 楕円曲線点加算は、待機時間を短縮するために、EC 加算モジュールでパイプライン方式で使用されます。
座標を射影座標として表すことを選択し、加算アルゴリズムでは完全楕円曲線点加算式を使用します。 主な利点は、エッジケースに対処する必要がないことです。 完全な数式。
この加算式をパイプライン方式と並列方式で実装し、FPGA楕円曲線加算回路は12回の乗算と17回の加算のみで、この式を実行しました。 元の式では、15 の剰余乗と 13 の加算が必要です。 FPGAの設計は以下の通りです。
マルチモッド
バレットリダクションアルゴリズムとカラツバアルゴリズムを利用しました。
バレットリダクションは、r≡ab mod p (p は固定) を効率的に計算するアルゴリズムです。 バレットリダクションは、除算(コストのかかる操作)を近似除算に置き換えようとします。 許容誤差を選択して、正しい結果を求めている範囲を記述できます。 許容誤差が大きいため、より小さなリダクション定数を使用できることがわかります。 これにより、モジュロリダクション演算で使用される中間値のサイズが小さくなり、最終結果の計算に必要な乗算の数が減ります。
下の青いボックスでは、エラー耐性が高いため、正確な結果を見つけるために複数のチェックを実行する必要があることがわかります。
一言で言えば、Karatsubaアルゴリズムは、Barrett Reductionで実行する乗算を最適化するために使用されます。 Karatsubaのアルゴリズムは、2つのn桁の乗算を3つのn/2桁の乗算に単純化します。 これらの乗算により、ハードウェアで直接計算できるほど桁数を狭くすることができます。 **詳細はIngoの論文「Pipe MSM」で読むことができます。
上記の演算子を使用して、低遅延で高度に並列化されたMSM実装を開発しました。
核となる考え方は、MSM全体を一度に計算する代わりに、各チャンクを並列にEC加算器に渡すことです。 EC 加算器の結果は、最終 MSM に累積されます。
最終結果****
上の図は、Sppark と PipeMSM の比較を示しています。
最も顕著なのは、FPGAがもたらす大幅な省エネであり、これは将来の大規模なプルーフ生成操作にとって非常に重要になる可能性があります。 私たちの実装は@125MHzの下でプロトタイプ化され、ベンチマークされており、クロック速度を@500MHzに上げると、計算時間が4倍以上増加する可能性があることは注目に値します。
また、当社のFPGAは、消費電力や発熱が少ないため、小型の筐体サーバに搭載できるのもメリットです。
ZKPのFPGAエンジニアリングは初期段階にあり、アルゴリズムのさらなる改善が期待されます。 また、CPUがアイドル状態のときにFPGAがMSMを計算しているため、FPGAをシステムリソース(CPU/GPU)と組み合わせて使用することで、より高速な時間を実現できる可能性があります。
概要
ZKPは、分散システムのキーテクノロジーとなっています。
ZKPのアプリケーションは、イーサリアムレベルを拡張するだけでなく、信頼できない第三者への計算のアウトソーシングを可能にし、分散クラウドコンピューティングやIDシステムなど、以前は不可能だったシステムの開発を可能にします。
従来、ZKPの最適化はソフトウェアレベルの改善に重点が置かれていましたが、より優れたパフォーマンスに対する需要が高まるにつれて、ハードウェアとソフトウェアの両方を含むより高度なアクセラレーションソリューションが登場するでしょう。
現在、CUDAを使用した開発期間が短く、現在のコンシューマ向けGPUは非常に安価で豊富であるため、現在見られるアクセラレーションソリューションは主にGPUを使用しています。 GPUは驚異的なパフォーマンスも提供します。 したがって、GPUがすぐにこの分野から姿を消す可能性は低いでしょう。
より複雑な開発チームがこの分野に参入するにつれて、FPGAが電力効率と性能の面で先導するようになるでしょう。 GPUと比較して、FPGAはより多くの低レベルのカスタマイズとより多くの構成オプションを提供します。 FPGAは、ASICよりも高速な開発速度と柔軟性を提供します。 ZKPの世界の急速な発展に伴い、FPGAはさまざまなプログラムで再フラッシュして、さまざまなシステムや更新ソリューションに対応することができます。
ただし、ほぼリアルタイムの証明を生成するには、証明を生成するシステムによっては、GPU/FPGA/ASIC 構成を組み合わせる必要がある場合があります。
また、ZPUは、大規模なプルーフジェネレーターや低電力デバイス向けに非常に効率的なソリューションを提供するために進化する可能性があります(詳細は以前の記事を参照)。