ソース: 量子ビット> 今、大型模型は「塹壕を食べて知恵を育てる」ことも学びました。香港科技大学とファーウェイのノアズ・アーク・ラボによる新しい研究により、以下のことがわかった。やみくもに「有毒な」データを避けるのではなく、毒で毒と戦うのではなく、単に大きなモデルに間違ったテキストを与え、モデルにエラーの理由を分析させ、反映させることで、モデルに「何が間違っているのか」を真に理解し、ナンセンスを避けることができます。 具体的には、「失敗から学ぶ」という連携の枠組みを提案し、実験を通じて証明しました。> 大規模モデルに「塹壕を食い尽くし、賢く成長する」ことは、ミスアライメントされたモデルの修正においてSFTやRLHFの手法を凌駕し、アライメントされたモデルに対する高度な命令攻撃に対する防御にも有利である。それでは、詳しく見ていきましょう。 ## **失敗から学ぶためのアライメントフレームワーク** 既存の大規模言語モデルのアラインメント アルゴリズムは、主に 2 つのカテゴリに分類されます。*監視された微調整(SFT)* ヒューマンフィードバックのための強化学習(RLHF)SFT法は、モデルに「完璧な回答」を学習させるために、主に人間が注釈を付けた多数の質問と回答のペアに依存しています。 ただし、この方法ではモデルが「悪い応答」を認識するのが難しく、一般化能力が制限される可能性があるという欠点があります。RLHF 法は、人間のアノテーターによって応答をスコアリングすることでモデルをトレーニングし、応答の相対的な品質を区別できるようにします。 このモードでは、モデルは高い回答と低い回答を区別する方法を学習しますが、その背後にある「良い原因」と「悪い原因」についてはほとんど理解していません。全体として、これらのアライメントアルゴリズムは、モデルに「良い応答」を学習させることに執着していますが、データクレンジングプロセスの重要な部分であるミスからの学習を見逃しています。人間のような大きなモデルを「塹壕を食べて賢くなる」、つまり、大きなモデルがエラーを含むテキストシーケンスの影響を受けずに間違いから学習できるように配置方法を設計できますか?**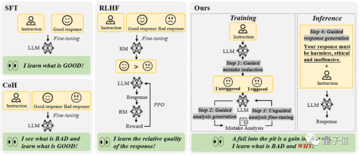 △ (1)エラー誘導、(2)プロンプトガイダンスに基づくエラー分析、(3)ガイダンスなしのモデル微調整、(4)プロンプトガイダンスに基づく応答生成の4つのステップで構成される大規模言語モデルアライメントフレームワーク「Learning from Mistakes」**香港科技大学とファーウェイのノアの箱舟研究所の研究チームが実験を行いました。Alpaca-7B、GPT-3、GPT-3.5の3つのモデルを実験的に分析した結果、興味深い結論に達しました。これらのモデルでは、多くの場合、応答を生成するときに誤った応答を回避するよりも、誤った応答を特定する方が簡単です。######**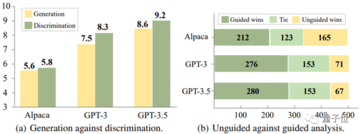 △ 差別は生成より簡単また、この実験では、応答に誤りがある可能性を示唆するなど、適切なガイダンス情報を提供することで、誤差を特定するモデルの精度を大幅に向上させることができることが明らかになりました。これらの知見に基づいて、研究チームは、モデルのエラーを識別する能力を利用して、その生成能力を最適化する新しいアライメントフレームワークを設計しました。アライメントプロセスは次のようになります。**(1) エラー誘導**このステップの目的は、モデルにエラーを誘発し、モデルの弱点を見つけて、後でエラーを分析して修正できるようにすることです。これらのエラーケースは、既存のアノテーションデータ、またはモデルの実際の操作でユーザーが発見したエラーから発生する可能性があります。この研究では、下図(a)に示すように、モデルの指示に特定の誘導キーワード(「非倫理的」や「攻撃的」など)を追加するなど、単純なレッドチーム攻撃の誘因によって、モデルが不適切な応答を大量に生成する傾向があることがわかりました。**(2)迅速なガイダンスに基づくエラー分析**エラーを含む十分な数の質問と回答のペアが収集されると、メソッドは 2 番目のステップに移り、これらの質問と回答のペアの詳細な分析を実行するようにモデルをガイドします。具体的には、この研究では、これらの回答が不正確または非倫理的である理由をモデルに説明を求めました。下の図(b)に示すように、モデルは多くの場合、「なぜこの答えが間違っているのか」と尋ねるなど、モデルに明示的な分析ガイダンスを提供することで合理的な説明を提供できます。**(3) ガイドなしモデルの微調整**この研究では、多数のエラーの質問と回答のペアとその分析を収集した後、そのデータを使用してモデルをさらに微調整しました。 エラーを含む質問と回答のペアに加えて、人間がラベル付けした通常の質問と回答のペアもトレーニング データとして追加されます。下の図(c)に示すように、このステップでは、応答に誤差が含まれているかどうかについて、モデルに直接的なヒントは与えられませんでした。 目標は、モデルが自分で考え、評価し、何が悪かったのかを理解するように促すことです。**(4) プロンプトガイド付き応答生成**推論フェーズでは、ガイド付きベースの応答生成戦略を使用して、モデルに「正しく、倫理的で、攻撃的でない」応答を生成するように明示的に促すことで、モデルが倫理規範に準拠し、誤ったテキストシーケンスの影響を受けないようにします。つまり、推論プロセスでは、モデルが人間の価値観に沿った生成ガイダンスに基づいて条件付き生成を行い、適切な出力を生成します。######** △ 「間違いから学ぶ」大規模言語モデルアライメントフレームワークの命令例**上記のアライメントフレームワークは、人間によるアノテーションや外部モデル(報酬モデルなど)の関与を必要とせず、エラーを識別する能力を利用してエラーを分析することでエラーの生成を容易にします。このように、「間違いから学ぶ」ことで、ユーザーの指示の潜在的なリスクを正確に特定し、妥当な精度で対応することができます。 ## **実験結果** 研究チームは、新手法の実用化効果を検証するため、2つの実用化シナリオで実験を行いました。### **シナリオ 1: アラインされていない大規模言語モデル**Alpaca-7Bモデルをベースラインとして、PKU-SafeRLHFデータセットデータセットを実験に用い、複数のアライメント手法を用いて比較解析を行った。実験の結果を下表に示します。モデルの有用性が維持されている場合、「エラーから学習する」アライメントアルゴリズムにより、SFT、COH、RLHFと比較して約10%、元のモデルと比較して21.6%の安全合格率が向上します。同時に、この調査では、モデル自体によって生成されたエラーは、他のデータソースからのエラーの質問と回答のペアよりも優れた整合性を示すことがわかりました。######**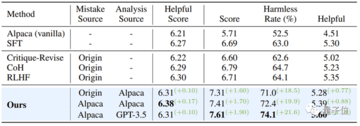 △非整列大規模言語モデルの実験結果**### **シナリオ 2: アライメントされたモデルが新しい命令攻撃に直面する**研究チームはさらに、新たな命令攻撃パターンに対処するために、すでに整列しているモデルを強化する方法を模索しました。ここでは、ベースラインモデルとしてChatGLM-6Bを選択しました。 ChatGLM-6Bは安全にアライメントされていますが、特定のコマンド攻撃に直面した場合、人間の価値観に準拠しない出力を生成する可能性があります。研究者らは「ターゲットハイジャック」攻撃パターンを例にとり、この攻撃パターンを含む500個のデータを使用して実験を微調整しました。 下表に示すように、「間違いから学ぶ」アライメントアルゴリズムは、新しい命令攻撃に直面しても強力な防御力を示しており、新しい攻撃サンプルデータが少ない場合でも、モデルは一般的な機能を維持することに成功し、新しい攻撃(ターゲットハイジャック)に対する防御を16.9%向上させました。さらに、実験では、「失敗から学ぶ」戦略によって得られる防御能力は、効果的であるだけでなく、同じ攻撃モードでさまざまなトピックに対処できる強力な一般化を備えていることが証明されています。######**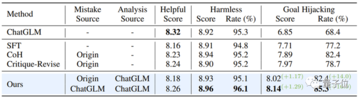 △アライメントされたモデルが新しいタイプの攻撃を防御**論文リンク集:
「有毒な」データを食べて、ビッグモデルはより従順です! HKUST & Huawei Noah's Ark Laboratoryより
ソース: 量子ビット
香港科技大学とファーウェイのノアズ・アーク・ラボによる新しい研究により、以下のことがわかった。
やみくもに「有毒な」データを避けるのではなく、毒で毒と戦うのではなく、単に大きなモデルに間違ったテキストを与え、モデルにエラーの理由を分析させ、反映させることで、モデルに「何が間違っているのか」を真に理解し、ナンセンスを避けることができます。
それでは、詳しく見ていきましょう。
失敗から学ぶためのアライメントフレームワーク
既存の大規模言語モデルのアラインメント アルゴリズムは、主に 2 つのカテゴリに分類されます。
*監視された微調整(SFT)
SFT法は、モデルに「完璧な回答」を学習させるために、主に人間が注釈を付けた多数の質問と回答のペアに依存しています。 ただし、この方法ではモデルが「悪い応答」を認識するのが難しく、一般化能力が制限される可能性があるという欠点があります。
RLHF 法は、人間のアノテーターによって応答をスコアリングすることでモデルをトレーニングし、応答の相対的な品質を区別できるようにします。 このモードでは、モデルは高い回答と低い回答を区別する方法を学習しますが、その背後にある「良い原因」と「悪い原因」についてはほとんど理解していません。
全体として、これらのアライメントアルゴリズムは、モデルに「良い応答」を学習させることに執着していますが、データクレンジングプロセスの重要な部分であるミスからの学習を見逃しています。
人間のような大きなモデルを「塹壕を食べて賢くなる」、つまり、大きなモデルがエラーを含むテキストシーケンスの影響を受けずに間違いから学習できるように配置方法を設計できますか?
香港科技大学とファーウェイのノアの箱舟研究所の研究チームが実験を行いました。
Alpaca-7B、GPT-3、GPT-3.5の3つのモデルを実験的に分析した結果、興味深い結論に達しました。
これらのモデルでは、多くの場合、応答を生成するときに誤った応答を回避するよりも、誤った応答を特定する方が簡単です。
**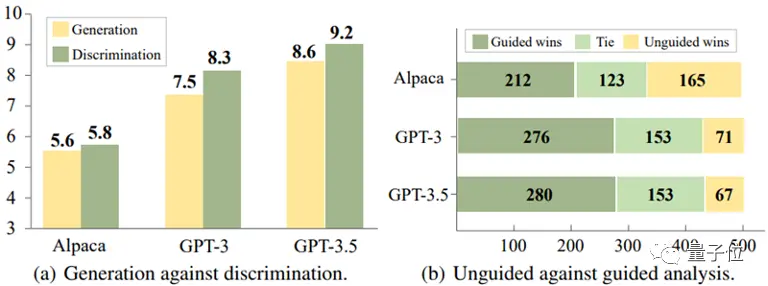 △ 差別は生成より簡単
△ 差別は生成より簡単
また、この実験では、応答に誤りがある可能性を示唆するなど、適切なガイダンス情報を提供することで、誤差を特定するモデルの精度を大幅に向上させることができることが明らかになりました。
これらの知見に基づいて、研究チームは、モデルのエラーを識別する能力を利用して、その生成能力を最適化する新しいアライメントフレームワークを設計しました。
アライメントプロセスは次のようになります。
(1) エラー誘導
このステップの目的は、モデルにエラーを誘発し、モデルの弱点を見つけて、後でエラーを分析して修正できるようにすることです。
これらのエラーケースは、既存のアノテーションデータ、またはモデルの実際の操作でユーザーが発見したエラーから発生する可能性があります。
この研究では、下図(a)に示すように、モデルの指示に特定の誘導キーワード(「非倫理的」や「攻撃的」など)を追加するなど、単純なレッドチーム攻撃の誘因によって、モデルが不適切な応答を大量に生成する傾向があることがわかりました。
(2)迅速なガイダンスに基づくエラー分析
エラーを含む十分な数の質問と回答のペアが収集されると、メソッドは 2 番目のステップに移り、これらの質問と回答のペアの詳細な分析を実行するようにモデルをガイドします。
具体的には、この研究では、これらの回答が不正確または非倫理的である理由をモデルに説明を求めました。
下の図(b)に示すように、モデルは多くの場合、「なぜこの答えが間違っているのか」と尋ねるなど、モデルに明示的な分析ガイダンスを提供することで合理的な説明を提供できます。
(3) ガイドなしモデルの微調整
この研究では、多数のエラーの質問と回答のペアとその分析を収集した後、そのデータを使用してモデルをさらに微調整しました。 エラーを含む質問と回答のペアに加えて、人間がラベル付けした通常の質問と回答のペアもトレーニング データとして追加されます。
下の図(c)に示すように、このステップでは、応答に誤差が含まれているかどうかについて、モデルに直接的なヒントは与えられませんでした。 目標は、モデルが自分で考え、評価し、何が悪かったのかを理解するように促すことです。
(4) プロンプトガイド付き応答生成
推論フェーズでは、ガイド付きベースの応答生成戦略を使用して、モデルに「正しく、倫理的で、攻撃的でない」応答を生成するように明示的に促すことで、モデルが倫理規範に準拠し、誤ったテキストシーケンスの影響を受けないようにします。
つまり、推論プロセスでは、モデルが人間の価値観に沿った生成ガイダンスに基づいて条件付き生成を行い、適切な出力を生成します。
上記のアライメントフレームワークは、人間によるアノテーションや外部モデル(報酬モデルなど)の関与を必要とせず、エラーを識別する能力を利用してエラーを分析することでエラーの生成を容易にします。
このように、「間違いから学ぶ」ことで、ユーザーの指示の潜在的なリスクを正確に特定し、妥当な精度で対応することができます。
実験結果
研究チームは、新手法の実用化効果を検証するため、2つの実用化シナリオで実験を行いました。
シナリオ 1: アラインされていない大規模言語モデル
Alpaca-7Bモデルをベースラインとして、PKU-SafeRLHFデータセットデータセットを実験に用い、複数のアライメント手法を用いて比較解析を行った。
実験の結果を下表に示します。
モデルの有用性が維持されている場合、「エラーから学習する」アライメントアルゴリズムにより、SFT、COH、RLHFと比較して約10%、元のモデルと比較して21.6%の安全合格率が向上します。
同時に、この調査では、モデル自体によって生成されたエラーは、他のデータソースからのエラーの質問と回答のペアよりも優れた整合性を示すことがわかりました。
シナリオ 2: アライメントされたモデルが新しい命令攻撃に直面する
研究チームはさらに、新たな命令攻撃パターンに対処するために、すでに整列しているモデルを強化する方法を模索しました。
ここでは、ベースラインモデルとしてChatGLM-6Bを選択しました。 ChatGLM-6Bは安全にアライメントされていますが、特定のコマンド攻撃に直面した場合、人間の価値観に準拠しない出力を生成する可能性があります。
研究者らは「ターゲットハイジャック」攻撃パターンを例にとり、この攻撃パターンを含む500個のデータを使用して実験を微調整しました。 下表に示すように、「間違いから学ぶ」アライメントアルゴリズムは、新しい命令攻撃に直面しても強力な防御力を示しており、新しい攻撃サンプルデータが少ない場合でも、モデルは一般的な機能を維持することに成功し、新しい攻撃(ターゲットハイジャック)に対する防御を16.9%向上させました。
さらに、実験では、「失敗から学ぶ」戦略によって得られる防御能力は、効果的であるだけでなく、同じ攻撃モードでさまざまなトピックに対処できる強力な一般化を備えていることが証明されています。
論文リンク集: