**記事のソース: New Zhiyuan** 画像ソース: Unbounded AIによって生成> 世界最長のコンテキストウィンドウが登場! 本日、Baichuan Intelligent は、コンテキストウィンドウの長さが最大 192K (漢字 350,000 文字) で、Claude 2 の 4.4 倍、GPT-4 の 14 倍である Baichuan2-192K ラージ モデルをリリースしました。長いコンテキストウィンドウの分野における新しいベンチマークがここにあります!本日、Baichuan Intelligent は、世界最長のコンテキスト ウィンドウを備えた大型モデルである Baichuan2-192K を正式にリリースしました。以前のモデルとは異なり、このモデルのコンテキスト ウィンドウの長さは 192K と高く、これは約 350,000 文字の漢字に相当します。具体的には、Baichuan2-192KはGPT-4(32Kコンテキスト、約25,000語)やClaude 2(100Kコンテキスト、約80,000語)の14倍の漢字を処理でき、「三体問題」のコピーを一度に読むことができます。 クロードが長い間保持していたコンテキストウィンドウレコードが今日更新されました三体問題「ワンス・アポン・ア・タイム・オン・アース」の最初の部分を投げると、Baichuan2-192Kは少し噛み砕いて、すぐに全体の話をよく理解しました。> ワン・ミャオが見たカウントダウンの36枚目の写真の数字は? 答え:1194:16:37。 彼はどのモデルのカメラを使用していますか? A:ライカM2です。 彼とダシは合計で何回飲んだのだろう? 回答:2回です。 2番目の「暗い森」を見て、白川2-192Kは、地球三体組織が2つの紅岸基地を設立し、「水滴」は相互作用の強い物質でできているとすぐに答えただけではありません。また、「三体問題と十段階学者」では答えられないかもしれないという不評な質問でも、白川2-192Kは流暢に答えられ、簡単に答えられます。> 自分の名前が最も多く登場するのは誰ですか? 答え:羅智。 コンテキストウィンドウを35万語に拡張すると、大型モデルを使った体験が一気に新しい世界が開けたような気がします! ## **世界最長のコンテキスト、クロード2を全面的にリード** 大型モデル、首に何が刺さるのか?ChatGPTを例にとると、その機能は素晴らしいものですが、この「全能」モデルには避けられない制約があります-コンテキストでは最大32Kトークン(25,000字)しかサポートしていません。 弁護士やアナリストなどの職業は、ほとんどの場合、それよりもはるかに長い時間がかかるテキストを処理する必要があります。 コンテキスト ウィンドウが大きくなると、モデルは入力からより豊富なセマンティック情報を取得でき、フルテキストの理解に基づいて Q&A や情報処理を直接実行することもできます。その結果、モデルはコンテキストの関連性をより適切にキャプチャし、あいまいさを排除するだけでなく、コンテンツをより正確に生成し、「錯覚」の問題を軽減し、パフォーマンスを向上させることができます。 さらに、長い文脈の恵みにより、より垂直なシーンと深く組み合わせることができ、人々の仕事、生活、学習に実際に役割を果たします。最近、シリコンバレーのユニコーン企業Anthropicは、Amazonから40億、Googleから20億の投資を受けました。 この2つの巨人の好意は、もちろん、クロードがロング・コンテクスト・ケイパビリティ・テクノロジーで主導的な地位を占めていることに関係しています。今回、Baichuan IntelligenceがリリースしたBaichuan-192Kロングウィンドウモデルは、コンテキストウィンドウの長さにおいてClaude 2-100Kをはるかに上回り、テキスト生成品質、コンテキスト理解、Q&A能力などの多面的な評価においても包括的なリードを達成しました。### **10件の権威あるレビュー、7件のSOTA**ロングは、カリフォルニア大学バークレー校などの大学がロングウィンドウモデルを評価するために公開しているリストで、主にロングウィンドウの内容を記憶して理解するモデルの能力を測定します。文脈理解の点では、Baichuan2-192Kは、権威あるロングウィンドウテキスト理解評価リストLongの他のモデルよりも大幅に進んでおり、100Kを超えるウィンドウ長の後も非常に強力なパフォーマンスを維持できます。対照的に、Claude 2 のウィンドウの長さが 80K を超えると、全体的な効果が非常に低下します。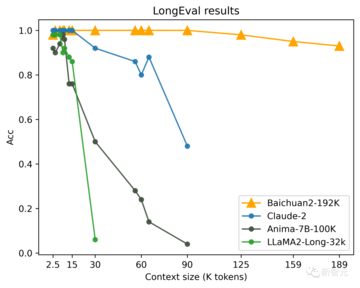 さらに、Baichuan2-192Kは、Dureader、NarrativeQA、LSHT、TriviaQAなど、中国語と英語の長文Q&Aおよび抄録の10の評価セットでも優れた成績を収めました。そのうち7台がSOTAを達成し、他のロングウィンドウモデルを大幅に上回った。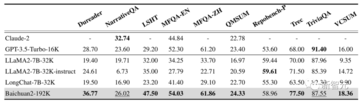 混乱は、テキスト生成の品質に関して非常に重要な基準です。簡単に言うと、人間の自然言語習慣に適合した高品質な文書をテストセットとして用いると、モデルが中国語版のテストセットを生成する確率が高くなり、モデルの混乱が少なくなり、モデルが良くなるということが分かります。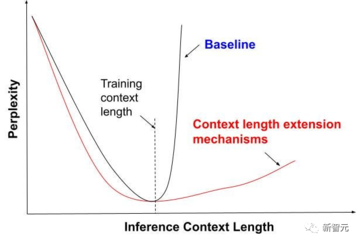 DeepMindが公開した「Language Modeling Benchmark Dataset PG-19」のテスト結果によると、Baichuan2-192Kの混同度は初期段階では優れており、Baichuan2-192Kのシーケンスモデリング能力はウィンドウ長が拡大するにつれて改善され続けました。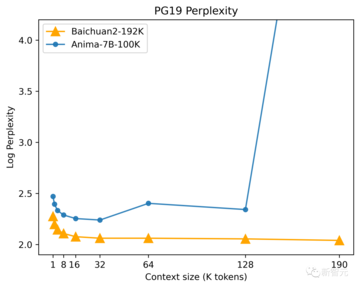 ### **エンジニアリングアルゴリズムの共同最適化、長さ性能の同期改善**コンテキストが長いとモデルのパフォーマンスが向上しますが、ウィンドウが長いと、計算能力とビデオ メモリが多くなります。現在、業界では、ウィンドウをスライドさせたり、サンプリングを減らしたり、モデルを縮小したりするのが一般的です。ただし、これらのアプローチはすべて、程度の差こそあれ、モデルの他の側面を犠牲にしています。 この問題を解決するために、Baichuan2-192Kは、アルゴリズムとエンジニアリングの極端な最適化により、ウィンドウの長さとモデルのパフォーマンスのバランスを実現し、ウィンドウの長さとモデルのパフォーマンスを同時に改善することを実現します。まず第一に、アルゴリズムに関して、Baichuan Intelligentは、RoPEおよびALiBi動的位置コーディングの外挿スキームを提案し、異なる長さのALiBi位置コーディングに対してさまざまな程度のアテンションマスク動的補間を実行できるため、解像度を確保しながら長いシーケンスに依存するモデルのモデリング能力を強化できます。第二に、エンジニアリングの面では、自社開発の分散トレーニングフレームワークに基づいて、Baichuan Intelligenceは、テンソル並列性、フロー並列性、シーケンス並列性、再計算、オフロードなど、市場に出回っているほぼすべての高度な最適化技術を統合し、4D並列分散スキームの包括的なセットを作成し、モデルの特定の負荷状況に応じて最適な分散戦略を自動的に見つけることができ、ロングウィンドウトレーニングと推論の過程でメモリ占有を大幅に削減します。 ## **内部テストが正式に開始され、直接の経験がリリースされました** さて、Baichuan2-192Kがクローズドベータを正式に開始しました!Baichuan2-192KはAPI呼び出しを通じて自社のアプリケーションやビジネスに接続されており、現在、金融メディア、法律事務所、その他の機関はBaichuan Intelligenceとの協力関係に達しています。Baichuan2-192Kの世界をリードするロングコンテキスト機能をメディア、金融、法律などの特定のシナリオに適用することで、大規模モデルの実装のためのより広いスペースが拡大することは間違いないでしょう。APIを通じて、Baichuan2-192Kはより垂直なシーンに効果的に統合され、それらと深く統合することができます。かつては、膨大な内容の文書は、仕事や勉強で越えられない山になることが多かった。 Baichuan2-192Kを使用すると、数百ページの資料を一度に処理および分析でき、重要な情報を抽出および分析できます。長いドキュメントの要約/レビュー、長い記事やレポート、または複雑なプログラミング支援のいずれであっても、Baichuan2-192Kは大きな後押しを提供します。ファンドマネージャーにとっては、財務諸表の要約と解釈、会社のリスクと機会の分析に役立ちます。弁護士にとっては、複数の法的文書のリスクを特定し、契約書や法的文書を確認するのに役立ちます。 開発者にとっては、何百ページにもわたる開発ドキュメントを読み、技術的な質問に答えるのに役立ちます。それ以来、科学研究者の大多数は科学研究ツールも持っていて、大量の論文をすばやく閲覧し、最新の最先端の進歩をまとめることができます。 その上、より長いコンテキストはさらに大きな可能性を秘めています。エージェントおよびマルチモーダルアプリケーションは、現在の業界における最先端の研究ホットスポットです。 コンテキスト機能が長くなると、大規模なモデルで複雑なマルチモーダル入力をより適切に処理して理解できるようになり、より優れた転移学習が可能になります。 ## **コンテキストの長さ、兵士の戦場** コンテキストウィンドウの長さは、大規模モデルのコア技術の1つと言えます。現在、多くのチームは、ベースモデルの差別化された競争力を構築するために、「長いテキスト入力」から始めています。 パラメーターの数によって大規模モデルが実行できる複雑さが決まる場合、コンテキスト ウィンドウの長さによって、大規模モデルが持つ "メモリ" の量が決まります。サム・アルトマンはかつて、140/280文字ではなく、空飛ぶ車が欲しいと思っていたが、実際には32,000トークンが欲しいと言ったことがあります。 国内外で、コンテクストの窓を広げる研究やプロダクトは無限といえるでしょう。今年5月には、32Kのコンテキストを持つGPT-4が白熱した議論を巻き起こしました。当時、このバージョンのロックを解除したネチズンは、GPT-4 32Kを世界最高のプロダクトマネージャーとして賞賛しました。 まもなく、スタートアップのAnthropicは、Claudeが100K(約75,000語)のコンテキストトークン長をサポートできたと発表しました。言い換えれば、平均的な人が約5時間で同じ量のコンテンツを読んだ後、消化、記憶、分析により多くの時間を費やさなければなりません。 クロードの場合、1分もかかりません。 オープンソースコミュニティでは、Metaはコンテキスト機能を効果的に拡張できる方法も提案しており、基本モデルのコンテキストウィンドウを32,768トークンに到達させることができ、さまざまな合成コンテキスト検出および言語モデリングタスクで大幅なパフォーマンスの向上を達成しています。結果は、70Bパラメータを持つモデルが、さまざまなロングコンテキストタスクでgpt-3.5-turbo-16Kを超えるパフォーマンスを達成したことを示しています。 住所:香港、中国、MITの研究者が提案したLongLoRA法は、わずか2行のコードと8枚のA100マシンで、7Bモデルのテキスト長を100kトークンに、70Bモデルのテキスト長を32kトークンに拡張することができます。 住所:DeepPavlov、AIRI、London Institute of Mathematical Sciencesの研究者は、再帰型メモリトランスフォーマー(RMT)法を使用して、BERTの有効コンテキスト長を「前例のない200万トークン」に増やし、高いメモリ検索精度を維持しました。ただし、RMTはメモリ消費量を増やすことなくほぼ無限のシーケンス長に拡張できますが、RNNにはメモリ減衰の問題があり、推論時間が長くなります。 住所:現在、LLMのコンテキストウィンドウの長さは主に4,000〜100,000トークンの範囲であり、増加し続けています。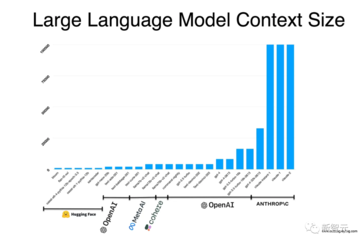 AI業界とアカデミアにおけるコンテキストウィンドウに関する多面的な研究を通じて、LLMにとっての重要性を示しています。そして今回、国産の大型モデルは、最長のコンテキストウィンドウという歴史的なハイライトの瞬間を迎えました。業界記録を更新した192Kコンテキストウィンドウは、Baichuan Intelligenceの大規模モデル技術における新たなブレークスルーであるだけでなく、大規模モデルの開発における新たなマイルストーンでもあります。 これは必然的に、製品側の形態の改革に新たな衝撃をもたらすでしょう。 2023年4月に設立されたBaichuan Intelligent は、わずか 6 か月で Baichuan-7B/13B と Baichuan2-7B/13B の 4 つのオープンソースで無料の商用大型モデルと、Baichuan-53B と Baichuan2-53B の 2 つのクローズドソースの大型モデルを相次いでリリースしました。このように、基本的には1月1日のLLMです。さて、Baichuan2-192Kのリリースにより、大型モデルのロングコンテキストウィンドウテクノロジーも完全に中国の時代に突入します!
たった今、Baichuan Intelligent Baichuan2-192Kがリリースされ、世界最長のコンテキストウィンドウが登場しました。 「三体問題」を一気に読んでみたところ、SOTAを7回獲得しました
記事のソース: New Zhiyuan
長いコンテキストウィンドウの分野における新しいベンチマークがここにあります!
本日、Baichuan Intelligent は、世界最長のコンテキスト ウィンドウを備えた大型モデルである Baichuan2-192K を正式にリリースしました。
以前のモデルとは異なり、このモデルのコンテキスト ウィンドウの長さは 192K と高く、これは約 350,000 文字の漢字に相当します。
具体的には、Baichuan2-192KはGPT-4(32Kコンテキスト、約25,000語)やClaude 2(100Kコンテキスト、約80,000語)の14倍の漢字を処理でき、「三体問題」のコピーを一度に読むことができます。
三体問題「ワンス・アポン・ア・タイム・オン・アース」の最初の部分を投げると、Baichuan2-192Kは少し噛み砕いて、すぐに全体の話をよく理解しました。
また、「三体問題と十段階学者」では答えられないかもしれないという不評な質問でも、白川2-192Kは流暢に答えられ、簡単に答えられます。
世界最長のコンテキスト、クロード2を全面的にリード
大型モデル、首に何が刺さるのか?
ChatGPTを例にとると、その機能は素晴らしいものですが、この「全能」モデルには避けられない制約があります-コンテキストでは最大32Kトークン(25,000字)しかサポートしていません。 弁護士やアナリストなどの職業は、ほとんどの場合、それよりもはるかに長い時間がかかるテキストを処理する必要があります。
その結果、モデルはコンテキストの関連性をより適切にキャプチャし、あいまいさを排除するだけでなく、コンテンツをより正確に生成し、「錯覚」の問題を軽減し、パフォーマンスを向上させることができます。 さらに、長い文脈の恵みにより、より垂直なシーンと深く組み合わせることができ、人々の仕事、生活、学習に実際に役割を果たします。
最近、シリコンバレーのユニコーン企業Anthropicは、Amazonから40億、Googleから20億の投資を受けました。 この2つの巨人の好意は、もちろん、クロードがロング・コンテクスト・ケイパビリティ・テクノロジーで主導的な地位を占めていることに関係しています。
今回、Baichuan IntelligenceがリリースしたBaichuan-192Kロングウィンドウモデルは、コンテキストウィンドウの長さにおいてClaude 2-100Kをはるかに上回り、テキスト生成品質、コンテキスト理解、Q&A能力などの多面的な評価においても包括的なリードを達成しました。
10件の権威あるレビュー、7件のSOTA
ロングは、カリフォルニア大学バークレー校などの大学がロングウィンドウモデルを評価するために公開しているリストで、主にロングウィンドウの内容を記憶して理解するモデルの能力を測定します。
文脈理解の点では、Baichuan2-192Kは、権威あるロングウィンドウテキスト理解評価リストLongの他のモデルよりも大幅に進んでおり、100Kを超えるウィンドウ長の後も非常に強力なパフォーマンスを維持できます。
対照的に、Claude 2 のウィンドウの長さが 80K を超えると、全体的な効果が非常に低下します。
そのうち7台がSOTAを達成し、他のロングウィンドウモデルを大幅に上回った。
簡単に言うと、人間の自然言語習慣に適合した高品質な文書をテストセットとして用いると、モデルが中国語版のテストセットを生成する確率が高くなり、モデルの混乱が少なくなり、モデルが良くなるということが分かります。
コンテキストが長いとモデルのパフォーマンスが向上しますが、ウィンドウが長いと、計算能力とビデオ メモリが多くなります。
現在、業界では、ウィンドウをスライドさせたり、サンプリングを減らしたり、モデルを縮小したりするのが一般的です。
ただし、これらのアプローチはすべて、程度の差こそあれ、モデルの他の側面を犠牲にしています。
まず第一に、アルゴリズムに関して、Baichuan Intelligentは、RoPEおよびALiBi動的位置コーディングの外挿スキームを提案し、異なる長さのALiBi位置コーディングに対してさまざまな程度のアテンションマスク動的補間を実行できるため、解像度を確保しながら長いシーケンスに依存するモデルのモデリング能力を強化できます。
第二に、エンジニアリングの面では、自社開発の分散トレーニングフレームワークに基づいて、Baichuan Intelligenceは、テンソル並列性、フロー並列性、シーケンス並列性、再計算、オフロードなど、市場に出回っているほぼすべての高度な最適化技術を統合し、4D並列分散スキームの包括的なセットを作成し、モデルの特定の負荷状況に応じて最適な分散戦略を自動的に見つけることができ、ロングウィンドウトレーニングと推論の過程でメモリ占有を大幅に削減します。
内部テストが正式に開始され、直接の経験がリリースされました
さて、Baichuan2-192Kがクローズドベータを正式に開始しました!
Baichuan2-192KはAPI呼び出しを通じて自社のアプリケーションやビジネスに接続されており、現在、金融メディア、法律事務所、その他の機関はBaichuan Intelligenceとの協力関係に達しています。
Baichuan2-192Kの世界をリードするロングコンテキスト機能をメディア、金融、法律などの特定のシナリオに適用することで、大規模モデルの実装のためのより広いスペースが拡大することは間違いないでしょう。
APIを通じて、Baichuan2-192Kはより垂直なシーンに効果的に統合され、それらと深く統合することができます。
かつては、膨大な内容の文書は、仕事や勉強で越えられない山になることが多かった。
長いドキュメントの要約/レビュー、長い記事やレポート、または複雑なプログラミング支援のいずれであっても、Baichuan2-192Kは大きな後押しを提供します。
ファンドマネージャーにとっては、財務諸表の要約と解釈、会社のリスクと機会の分析に役立ちます。
弁護士にとっては、複数の法的文書のリスクを特定し、契約書や法的文書を確認するのに役立ちます。
それ以来、科学研究者の大多数は科学研究ツールも持っていて、大量の論文をすばやく閲覧し、最新の最先端の進歩をまとめることができます。
エージェントおよびマルチモーダルアプリケーションは、現在の業界における最先端の研究ホットスポットです。 コンテキスト機能が長くなると、大規模なモデルで複雑なマルチモーダル入力をより適切に処理して理解できるようになり、より優れた転移学習が可能になります。
コンテキストの長さ、兵士の戦場
コンテキストウィンドウの長さは、大規模モデルのコア技術の1つと言えます。
現在、多くのチームは、ベースモデルの差別化された競争力を構築するために、「長いテキスト入力」から始めています。 パラメーターの数によって大規模モデルが実行できる複雑さが決まる場合、コンテキスト ウィンドウの長さによって、大規模モデルが持つ "メモリ" の量が決まります。
サム・アルトマンはかつて、140/280文字ではなく、空飛ぶ車が欲しいと思っていたが、実際には32,000トークンが欲しいと言ったことがあります。
今年5月には、32Kのコンテキストを持つGPT-4が白熱した議論を巻き起こしました。
当時、このバージョンのロックを解除したネチズンは、GPT-4 32Kを世界最高のプロダクトマネージャーとして賞賛しました。
言い換えれば、平均的な人が約5時間で同じ量のコンテンツを読んだ後、消化、記憶、分析により多くの時間を費やさなければなりません。 クロードの場合、1分もかかりません。
結果は、70Bパラメータを持つモデルが、さまざまなロングコンテキストタスクでgpt-3.5-turbo-16Kを超えるパフォーマンスを達成したことを示しています。
香港、中国、MITの研究者が提案したLongLoRA法は、わずか2行のコードと8枚のA100マシンで、7Bモデルのテキスト長を100kトークンに、70Bモデルのテキスト長を32kトークンに拡張することができます。
DeepPavlov、AIRI、London Institute of Mathematical Sciencesの研究者は、再帰型メモリトランスフォーマー(RMT)法を使用して、BERTの有効コンテキスト長を「前例のない200万トークン」に増やし、高いメモリ検索精度を維持しました。
ただし、RMTはメモリ消費量を増やすことなくほぼ無限のシーケンス長に拡張できますが、RNNにはメモリ減衰の問題があり、推論時間が長くなります。
現在、LLMのコンテキストウィンドウの長さは主に4,000〜100,000トークンの範囲であり、増加し続けています。
そして今回、国産の大型モデルは、最長のコンテキストウィンドウという歴史的なハイライトの瞬間を迎えました。
業界記録を更新した192Kコンテキストウィンドウは、Baichuan Intelligenceの大規模モデル技術における新たなブレークスルーであるだけでなく、大規模モデルの開発における新たなマイルストーンでもあります。 これは必然的に、製品側の形態の改革に新たな衝撃をもたらすでしょう。
このように、基本的には1月1日のLLMです。
さて、Baichuan2-192Kのリリースにより、大型モデルのロングコンテキストウィンドウテクノロジーも完全に中国の時代に突入します!