記事のソース: 量子ビットGPT-3はどのようにしてGPT-4に進化したのでしょうか?Bytesは、OpenAIにすべての大規模モデルに「ボックス化解除」操作を与えました。その結果、GPT-4の進化におけるいくつかの重要な技術の具体的な役割と影響が本当に理解されました。 たとえば:* SFTは初期のGPTの進化を可能にした* GPTのコーディング能力に最も貢献しているのはSFTとRLHFです*事前トレーニングにコードデータを追加することで、後続のGPTバージョンの**すべての側面**、特に推論の能力が向上します...起業後、多忙を極めた**AIの雄牛李牧**も久しぶりに世間の注目を浴び、この研究を称賛した。 ネチズンは賞賛さえしました:> これは、すべてのOpenAIモデルを完全に開梱した最初の作業です。 いくつかの新しい発見に加えて、いくつかの既存の推測も確認されています。例えば、GPT-4は愚かになることに警鐘を鳴らしているわけではなく、この評価では、GPTの進化の過程で明らかな「シーソー現象」、つまりモデルの進化の過程である能力が増加し、他の能力が低下することがわかりました。これは、以前のネチズンの感情と一致します。 著者自身は次のように述べています。> この研究は、GPT-3からGPT-4への進化の道筋に関する貴重な洞察を提供する可能性があります。つまり、GPTモデルの「成功の道筋」を垣間見ることができ、次の大規模モデル構築作業に有効な体験を提供することができるのです。では、具体的に何が「開く」のか、紙を見てみましょう。 ## **GPT-3からGPT-4への進化を探る** 最初の進化図は、公開されている情報に基づいて著者によって要約されました。ご覧のとおり、各中間モデルが、元のGPT-3から3.5、そして現在は4に進化したテクノロジー(コードの微調整、SFT/FeedMEなど)をマークしています。davinci から gpt-4-0613 まで、バイトは数学、コーディング、推論など、GPT の各世代の 7 つの主要な能力をすべてテストしました。 ### **1. SFT:初期のGPT進化のイネーブラー**まず、GPT-3ファミリーでは、オリジナルのdavinci(GPT-3)が、SFTとその亜種であるFeedMEの微調整を監修することで、text-davinci-001に進化しました。これにより、後者はほとんどすべてのタスクでパフォーマンスが向上します。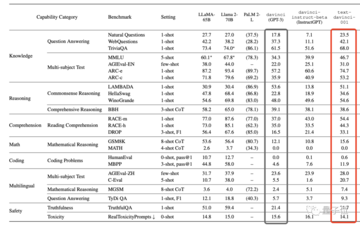 より直感的な表現を下図に示します(「ファンダム」は進化したtext-davinci-001です)。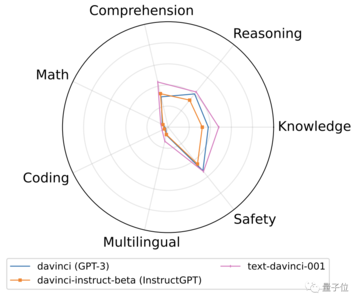 その後、GPTは3.5シリーズに移行し、最も基本的なコードdavinci002は、同じ技術を使用してtext-davinci-002に進化しました。しかし、この進化操作の効果は本当に大きくなく、GPTの性能は数倍に向上しただけで、増えるどころか減っています。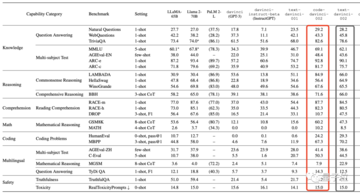 ここで、著者は最初の結論を導き出します。SFT は弱い基本モデルでのみ機能し、強力なモデルにはほとんど影響しません。同様の現象はオープンソースモデルでも見られます(このレビューでは、Llama1と2、PaLM2-L、Claude 2などもテストしました)。オリジナルのLlama-65Bに加えて、SFTはMMLUベンチマークでのパフォーマンスを向上させることができましたが、SFTの改良を使用したすべてのLlama2-70Bは、Open LLMリーダーボードでわずかな改善しか示しませんでした。概要: GPT3の段階では、SFT技術がモデルの進化に重要な役割を果たしました。### **2、RLHFとSFT:コーディング能力の向上に貢献**GPT3.5シリーズに続いて、OpenAIはtext-davinci-002を皮切りに、PPOアルゴリズムRLHFに基づく新技術を導入し始め、text-davinci-003が誕生しました。現時点では、ほとんどのベンチマークでのパフォーマンスは前任者と同等かわずかに悪く、その効果が特に明白ではないことを示しています(オープンソースモデルについても同じことが言えます)。1つの例外を除いて、コーディングタスクは30ポイント近く増加しました。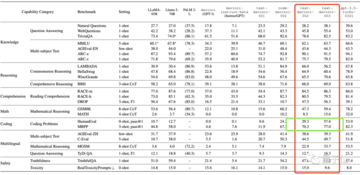 以前のcode-davinci002を彷彿とさせ、SFTテクノロジーを使用してtext-davinci-002に進化し、全体的なパフォーマンスが低下し、エンコードタスクは影響を受けませんでしたが、スコアは増加しました——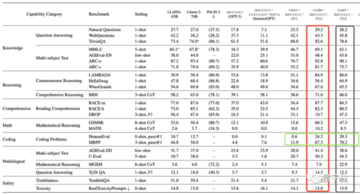 著者らは、**大規模モデルの符号化能力に対するSFTとRLHFの効果を検証する**ことにした。ここでは、数世代のGPTモデルのpass@1(1サンプルが1回合格する確率)、pass@100(100サンプルが100回合格する確率)などのスコアを測定しました。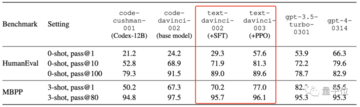 その結果、SFTおよびRLHF技術を用いたモデルは、ベースモデルと比較して、pass@1が大幅に向上し、pass@100がわずかに減少しました。これはどういう意味ですか?著者は次のように説明しています。pass@100 はモデルの本質的なコーディング能力を表し、pass@1 はモデルの 1 回限りのバグのないコーディング能力を表します。pass@100わずかな減少は、SFTとRLHFが、他のタスクと同様に、エンコーディングタスクに対していわゆるアライメント税を依然として課していることを示唆しています。しかし、SFTとRLHFはpass@1 pass@100能力を学習する、つまり、本質的な能力(ただし、多くの試行が必要)を一度限りのバグのないコーディングに変換することができ、その結果、pass@1が大幅に増加しました。結果を注意深く見ると、gpt-3.5-turbo-0301はSFTとRLHFによってpass@1が大幅に向上していることがわかり、小型モデルの性能最適化に朗報です。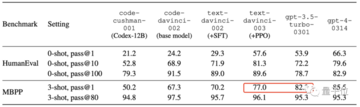 著者らは以前、GPT-4がいくつかの複雑な推論タスクを数回試みた後、問題を解決できたことを観察していることを考えると、それだけではありません。上記の観察結果と合わせて、彼らはそれを次のように要約しました。 LLMは、SFTとRLHFを使用して、固有の能力(ただし、複数回の試行が必要)を1回限りの問題解決能力に継続的に変換し、LLMの能力の上限に近づくことができます。つまり、GPT-4はさらに強くなる可能性があるということです。### **3. 推論に最も役立つ事前トレーニングにコードが追加されます**GPT4の進化の過程で、2つの特別なモデルも登場しました。code-cushman-001 (Codex-12B) 和code-davinci-002。前者は、OpenAIがコードデータを使用してモデルをトレーニングする最初の試みであり、小規模ながら優れたコード機能も実現しています。後者はGPT3.5のベースモデルであり、GPT3をベースにRLHF+コードで学習した結果、つまりテキストとコードのハイブリッド事前学習を行った結果です。GPT-3を(コーディング能力だけでなく)大きく凌駕し、一部の推論タスク(BBHなど)ではGPT-3.5-turbo-0613をも凌駕していることがわかります。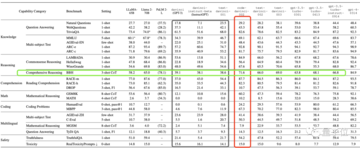 著者は次のように述べています。これは、事前学習にコードデータを追加することで、LLMの機能、特に推論を包括的に向上させることができることを示しています。### **4、「シーソー」現象**2023年3月と2023年6月のOpenAI APIモデルを比較すると、確かにこの現象がわかります。gpt-3.5-turbo-0301と比較すると、アップグレードされたgpt-3.5-turbo-0613はHuman(53.9 -> 80.0)では良好なパフォーマンスを発揮しますが、MATH(32.0 -> 15.0)では大幅に低下します。GPT-4-0613は、DROPではGPT-4-0314(78.7 -> 87.2)を上回りましたが、MGSMでは急落(82.2 -> 68.7)も見られました。著者によると、汎用人工知能は「汎用知能」を重視し、すべてのタスクで優れたパフォーマンスを要求し、モデルに「偏り」がないことを要求するため、「シーソー現象」はLLMのAGIへの道のりの障害になる可能性があります。また、この問題に注意を払い、大規模モデルのバランスの取れた開発に関する研究を共同で推進するようコミュニティに呼びかけました。 ## **大規模モデルの実践者が自分の道を見つけるのを手伝う** 上記の調査結果はすべて、GPT-Fathom -Byteは最近、大規模なモデル評価ツールを提案しました。おそらく、誰もが疑問を持っているに違いありません。すでに大きなモデルのランキングや評価ツールがたくさんあるのに、なぜ新しいアプローチを考え出すのでしょうか?著者らによると、既存の評価方法と比較して、GPT-Fathomスケールはより均一であり、結果は再現性があります。大規模モデルの実践者は、これを使用して、主要なモデルとのギャップがどこにあるかを明確にし、ターゲットを絞った方法で製品を改善することができます。具体的には、GPT-Fathomは、他の大規模モデル評価方法の3つの欠点を主に解決します。**設定基準の不整合**:思考の連鎖(CoT)やサンプルサイズなどの設定や回答評価方法などを使用するかどうかの統一基準はありません**不完全なモデルとタスクの収集**: 注意力をテストする能力は包括的ではなく、以前のモデルに焦点が当てられていません**モデルの感度に関する研究の欠如**GPT-Fathamの特徴をより直感的に反映するために、著者はいくつかの特定の既存のリストを比較し、次の表にまとめることができます。 その中で、感度評価では、以前の試験基準では特定できなかった問題が見つかりました。GPTと比較すると、他のモデルはプロンプトワードに対する感度が高く、わずかな変化でまったく異なる出力につながるため、他のモデルとGPTのロバスト性の間にはまだ大きなギャップがあることが示唆されます。たとえば、TriviaQAデータセットでは、プロンプトワードをわずかに変更するだけで、Llama 2-70Bのスコアが4分の1低下しましたが、GPTシリーズのモデルは大きく変化しませんでした。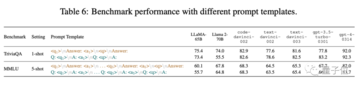 さらに、CoT、サンプルサイズ、サンプリング分散などの要因も感度テストに含まれます。今後、著者らは、GPT-Fathomを能力タイプ、テストデータセット、モデルの3つの次元から拡張し、マルチラウンド対話、マルチモダリティ、その他の能力の評価をサポートするとともに、複数のデータセットとモデルのテストを増やすことを計画しています。GPT-Fathamの共著者は、ByteのApplied Machine Learning Research Groupの研究者であるYuyu Zhang氏と、インターンのShen Zheng氏の2人です。シェン・チェンは、イリノイ大学アーバナ・シャンペーン校(UIUC)の修士課程の学生です。さらに、BytesのYijie Zhu氏とUIUCのKevin Chen-Chuan Chang教授を含む4人の研究者もこの研究に関与しました。住所: 参考リンク:


BytesはOpenAIの大規模モデルをすべて「開梱」し、GPT-3からGPT-4への進化の道筋を明らかにします! 李牧を吹き飛ばした
記事のソース: 量子ビット
GPT-3はどのようにしてGPT-4に進化したのでしょうか?
Bytesは、OpenAIにすべての大規模モデルに「ボックス化解除」操作を与えました。
その結果、GPT-4の進化におけるいくつかの重要な技術の具体的な役割と影響が本当に理解されました。
起業後、多忙を極めたAIの雄牛李牧も久しぶりに世間の注目を浴び、この研究を称賛した。
例えば、GPT-4は愚かになることに警鐘を鳴らしているわけではなく、この評価では、GPTの進化の過程で明らかな「シーソー現象」、つまりモデルの進化の過程である能力が増加し、他の能力が低下することがわかりました。
これは、以前のネチズンの感情と一致します。
つまり、GPTモデルの「成功の道筋」を垣間見ることができ、次の大規模モデル構築作業に有効な体験を提供することができるのです。
では、具体的に何が「開く」のか、紙を見てみましょう。
GPT-3からGPT-4への進化を探る
最初の進化図は、公開されている情報に基づいて著者によって要約されました。
ご覧のとおり、各中間モデルが、元のGPT-3から3.5、そして現在は4に進化したテクノロジー(コードの微調整、SFT/FeedMEなど)をマークしています。
davinci から gpt-4-0613 まで、バイトは数学、コーディング、推論など、GPT の各世代の 7 つの主要な能力をすべてテストしました。
まず、GPT-3ファミリーでは、オリジナルのdavinci(GPT-3)が、SFTとその亜種であるFeedMEの微調整を監修することで、text-davinci-001に進化しました。
これにより、後者はほとんどすべてのタスクでパフォーマンスが向上します。
しかし、この進化操作の効果は本当に大きくなく、GPTの性能は数倍に向上しただけで、増えるどころか減っています。
SFT は弱い基本モデルでのみ機能し、強力なモデルにはほとんど影響しません。
同様の現象はオープンソースモデルでも見られます(このレビューでは、Llama1と2、PaLM2-L、Claude 2などもテストしました)。
オリジナルのLlama-65Bに加えて、SFTはMMLUベンチマークでのパフォーマンスを向上させることができましたが、SFTの改良を使用したすべてのLlama2-70Bは、Open LLMリーダーボードでわずかな改善しか示しませんでした。
概要: GPT3の段階では、SFT技術がモデルの進化に重要な役割を果たしました。
2、RLHFとSFT:コーディング能力の向上に貢献
GPT3.5シリーズに続いて、OpenAIはtext-davinci-002を皮切りに、PPOアルゴリズムRLHFに基づく新技術を導入し始め、text-davinci-003が誕生しました。
現時点では、ほとんどのベンチマークでのパフォーマンスは前任者と同等かわずかに悪く、その効果が特に明白ではないことを示しています(オープンソースモデルについても同じことが言えます)。
1つの例外を除いて、コーディングタスクは30ポイント近く増加しました。
ここでは、数世代のGPTモデルのpass@1(1サンプルが1回合格する確率)、pass@100(100サンプルが100回合格する確率)などのスコアを測定しました。
これはどういう意味ですか?
著者は次のように説明しています。
pass@100 はモデルの本質的なコーディング能力を表し、pass@1 はモデルの 1 回限りのバグのないコーディング能力を表します。
pass@100わずかな減少は、SFTとRLHFが、他のタスクと同様に、エンコーディングタスクに対していわゆるアライメント税を依然として課していることを示唆しています。
しかし、SFTとRLHFはpass@1 pass@100能力を学習する、つまり、本質的な能力(ただし、多くの試行が必要)を一度限りのバグのないコーディングに変換することができ、その結果、pass@1が大幅に増加しました。
結果を注意深く見ると、gpt-3.5-turbo-0301はSFTとRLHFによってpass@1が大幅に向上していることがわかり、小型モデルの性能最適化に朗報です。
上記の観察結果と合わせて、彼らはそれを次のように要約しました。
LLMは、SFTとRLHFを使用して、固有の能力(ただし、複数回の試行が必要)を1回限りの問題解決能力に継続的に変換し、LLMの能力の上限に近づくことができます。
つまり、GPT-4はさらに強くなる可能性があるということです。
3. 推論に最も役立つ事前トレーニングにコードが追加されます
GPT4の進化の過程で、2つの特別なモデルも登場しました。
code-cushman-001 (Codex-12B) 和code-davinci-002。
前者は、OpenAIがコードデータを使用してモデルをトレーニングする最初の試みであり、小規模ながら優れたコード機能も実現しています。
後者はGPT3.5のベースモデルであり、GPT3をベースにRLHF+コードで学習した結果、つまりテキストとコードのハイブリッド事前学習を行った結果です。
GPT-3を(コーディング能力だけでなく)大きく凌駕し、一部の推論タスク(BBHなど)ではGPT-3.5-turbo-0613をも凌駕していることがわかります。
これは、事前学習にコードデータを追加することで、LLMの機能、特に推論を包括的に向上させることができることを示しています。
4、「シーソー」現象
2023年3月と2023年6月のOpenAI APIモデルを比較すると、確かにこの現象がわかります。
gpt-3.5-turbo-0301と比較すると、アップグレードされたgpt-3.5-turbo-0613はHuman(53.9 -> 80.0)では良好なパフォーマンスを発揮しますが、MATH(32.0 -> 15.0)では大幅に低下します。
GPT-4-0613は、DROPではGPT-4-0314(78.7 -> 87.2)を上回りましたが、MGSMでは急落(82.2 -> 68.7)も見られました。
著者によると、
汎用人工知能は「汎用知能」を重視し、すべてのタスクで優れたパフォーマンスを要求し、モデルに「偏り」がないことを要求するため、「シーソー現象」はLLMのAGIへの道のりの障害になる可能性があります。
また、この問題に注意を払い、大規模モデルのバランスの取れた開発に関する研究を共同で推進するようコミュニティに呼びかけました。
大規模モデルの実践者が自分の道を見つけるのを手伝う
上記の調査結果はすべて、GPT-Fathom -
Byteは最近、大規模なモデル評価ツールを提案しました。
おそらく、誰もが疑問を持っているに違いありません。
すでに大きなモデルのランキングや評価ツールがたくさんあるのに、なぜ新しいアプローチを考え出すのでしょうか?
著者らによると、既存の評価方法と比較して、GPT-Fathomスケールはより均一であり、結果は再現性があります。
大規模モデルの実践者は、これを使用して、主要なモデルとのギャップがどこにあるかを明確にし、ターゲットを絞った方法で製品を改善することができます。
具体的には、GPT-Fathomは、他の大規模モデル評価方法の3つの欠点を主に解決します。
設定基準の不整合:思考の連鎖(CoT)やサンプルサイズなどの設定や回答評価方法などを使用するかどうかの統一基準はありません 不完全なモデルとタスクの収集: 注意力をテストする能力は包括的ではなく、以前のモデルに焦点が当てられていません モデルの感度に関する研究の欠如
GPT-Fathamの特徴をより直感的に反映するために、著者はいくつかの特定の既存のリストを比較し、次の表にまとめることができます。
GPTと比較すると、他のモデルはプロンプトワードに対する感度が高く、わずかな変化でまったく異なる出力につながるため、他のモデルとGPTのロバスト性の間にはまだ大きなギャップがあることが示唆されます。
たとえば、TriviaQAデータセットでは、プロンプトワードをわずかに変更するだけで、Llama 2-70Bのスコアが4分の1低下しましたが、GPTシリーズのモデルは大きく変化しませんでした。
今後、著者らは、GPT-Fathomを能力タイプ、テストデータセット、モデルの3つの次元から拡張し、マルチラウンド対話、マルチモダリティ、その他の能力の評価をサポートするとともに、複数のデータセットとモデルのテストを増やすことを計画しています。
GPT-Fathamの共著者は、ByteのApplied Machine Learning Research Groupの研究者であるYuyu Zhang氏と、インターンのShen Zheng氏の2人です。
シェン・チェンは、イリノイ大学アーバナ・シャンペーン校(UIUC)の修士課程の学生です。
さらに、BytesのYijie Zhu氏とUIUCのKevin Chen-Chuan Chang教授を含む4人の研究者もこの研究に関与しました。
住所:
参考リンク: