記事のソース: New Zhiyuan編集部:アエネアスは眠い > 最近、CMU/MIT/Tsinghua/Umassが提案した世界初の生成ロボットエージェントであるRoboGenは、無限にデータを生成し、ロボットが24時間年中無休でトレーニングできるようにします。 AIGC for Roboticsは、まさに未来の道です。世界初のジェネレーティブボットエージェントがリリースされました!長い間、大規模なインターネットデータで学習できる言語モデルや視覚モデルと比較して、ロボットを訓練するための戦略モデルには動的な物理的相互作用情報を含むデータが必要であり、これらのデータの欠如は常に身体性知能の開発における最大のボトルネックでした。最近、CMU、清華大学、マサチューセッツ工科大学、マサチューセッツ工科大学、その他の機関の研究者が、新しいRoboGenエージェントを提案しました。大規模言語モデルや生成モデルに含まれる大規模な知識と、リアルなシミュレーション世界が提供する物理情報を組み合わせることで、さまざまなタスク、シナリオ、ティーチングデータを「無制限」に生成し、ロボットを24時間週7日完全にトレーニングすることができます。 現在、ネットワークから高品質の現実世界のトークンが急速に不足しています。 世界中のAIのトレーニングに使用されるデータが不足しています。ディープラーニングの父であるヒントン氏は、「テクノロジー企業は、今後18か月でGPT-4の100倍の計算能力を備えた新しいモデルをトレーニングする」と述べています。 モデルのパラメータは大きくなり、計算能力の需要は膨大ですが、データはどこにあるのでしょうか?飢えたモデルに直面したとき、AI合成が答えです。 住所:プロジェクトホームページ:オープンソースアドレス:具体的には、MIT-IBMのチーフサイエンティストであるGan Chuang氏が率いる研究チームは、生成AIと微分可能な物理シミュレーションのサポートを受けた「提案-生成-学習」ループを提案し、エージェントが自分で問題を解決し、ロボットを訓練できるようにします。まず、エージェントから「このスキルを磨くべきだ」と提案されました。次に、適切な環境、構成、スキル学習ガイダンスを生成して、シミュレートされた環境を作成します。最後に、エージェントは提案された上位レベルのタスクをサブタスクに分解し、最適な学習方法を選択してから、戦略を学習し、提案されたスキルを習得します。プロセス全体が人間の監督をほとんど必要とせず、タスクの数が無制限であることは注目に値します。この大ヒット研究のために、NVIDIAのシニアサイエンティストであるJim Fan氏もそれを転送しました。 これで、ロボットは一連の発破操作を学習しました。荷物をロッカーに入れる: スープのボウルを電子レンジで加熱します。 レバーを引いてコーヒーを淹れる: バク転なども同様です。 ## **多様なスキル学習の鍵となる模擬環境** ロボット研究における長年のジレンマは、ロボットに工場以外の環境で動作し、人間のためにさまざまなタスクを実行するスキルをいかに与えるかということです。近年、ロボットには、流体操作、物投げ、サッカー、パルクールなど、さまざまな複雑なスキルを教えていますが、これらのスキルはサイロ化され、視野が狭く、人間が設計したタスクの説明とトレーニングの監督が必要です。実世界のデータ収集にはコストと手間がかかるため、これらのスキルはシミュレーションでトレーニングされ、適切なドメインでランダム化されてから、現実の世界に展開されます。シミュレートされた環境には、低レベルの状態への特権アクセスや探索の無制限の機会を提供するなど、現実世界の探索やデータ収集に比べて多くの利点があります。 超並列コンピューティングをサポートし、データ収集の速度が大幅に高速化されます。 ボットがクローズドループ戦略とエラー回復機能を開発できるようにします。ただし、シミュレートされた環境を構築するには、一連の面倒なタスク (タスクの設計、関連性があり意味的に意味のある資産の選択、適切なシナリオのレイアウトと構成の生成、報酬関数や損失関数などのトレーニング監督の定式化) が必要です。 シミュレートされた世界でも、ロボットのスキル学習のスケーラビリティは大きく制限されています。 そこで研究者らは、シミュレーションロボットスキルの学習の進歩と、基礎モデルや生成モデルの最新の進歩を組み合わせた「ジェネレーティブ・シミュレーション」パラダイムを提案しています。ジェネレーティブ・シミュレーションは、最先端のベースモデルの生成能力を活用して、シミュレーションにおけるさまざまなロボットスキルに必要なすべての段階の情報を生成できる。最新のベースモデルの包括的なコーディング知識のおかげで、この方法で生成されたシナリオとタスクのデータは、実際のシナリオの分布と非常によく似ています。さらに、これらのモデルは、ドメイン固有のポリシー学習方法でシームレスに処理できる分解された低レベルのサブタスクをさらに提供できるため、さまざまなスキルとシナリオのクローズドループのデモンストレーションが得られます。 ## **RoboGen プロセス** RoboGenは、ロボットが24時間年中無休でさまざまなスキルを習得できる完全に自動化されたプロセスであり、4つの段階で構成されています。1.タスクの提案。2.シーン生成。3.監視された世代のトレーニング。4. 生成された情報をスキル学習に活用する。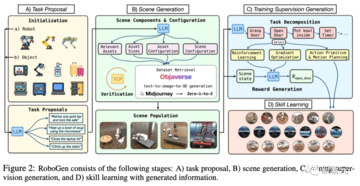 RoboGenは、最新のベースモデルに組み込まれた常識と生成機能を活用して、タスク、シナリオ、およびトレーニングの監督を自動化し、ロボットのマルチスキル学習を大規模に実現します。### **タスクの提案**この段階で、RoboGenは上位レベルのタスクを提案し、対応する環境を生成し、上位レベルの目標を低レベルのサブタスクに分解し、サブスキルを順次学習することができます。まず、RoboGenは、ロボットが学習するための有意義で多様な高レベルのタスクを生成します。研究者は、特定のロボットタイプとプールからのオブジェクトのランダムサンプルを使用してシステムを初期化します。 提供されたロボットとサンプルオブジェクトの情報は、LLMに入力されます。このサンプリング プロセスにより、生成タスクの多様性が保証されます。例えば、四足歩行ロボットなどの脚付きロボットは、様々な運動能力を獲得することができ、ロボットアームマニピュレータは、ペアを組むことで、異なるサンプリング対象物を用いて様々な操作タスクを実行できる可能性を秘めている。 研究者たちは、GPT-4を使用して、現在のプロセスでクエリを行いました。 これに続いて、マシンのコンテキストでのRoboGenの詳細の説明と、オブジェクトの操作に関連するタスクについて説明します。初期化に使用されるオブジェクトは、オーブン、電子レンジ、ウォーター ディスペンサー、ラップトップ、食器洗い機など、家庭のシーンで一般的な多関節オブジェクトと非多関節オブジェクトを含む、定義済みのリストからサンプリングされます。GPT-4は大規模なインターネットデータセットでトレーニングされているため、これらのオブジェクトのアフォーダンス、それらとの対話方法、およびそれらがどのような意味のあるタスクに関連付けることができるかについて豊富な理解を持っています。例えば、サンプリングされた多関節物体が電子レンジで、ジョイント0がドアをつなぐ回転ジョイントで、ジョイント1がタイマーノブを制御する別の回転ジョイントである場合、GPT-4は「ロボットアームがスープの入ったボウルを電子レンジに入れ、ドアを閉め、マイクロ波タイマーを加熱時間aにセットする」というタスクを返します。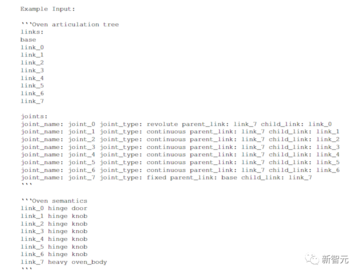 生成されたタスクに必要な他のオブジェクトとしては、スープaのボウルと、ジョイント0(マイクロ波のドアを開ける)、ジョイント1(タイマーを設定する)、リンク0(ドア)、リンク1(タイマーノブ)など、タスクに関連するジョイントとリンクがあります。多関節オブジェクトの場合、PartNetMobilityは唯一の高品質な多関節オブジェクトデータセットであり、すでに広範囲の多関節アセットをカバーしているため、サンプリングされたアセットに基づいてタスクが生成されます。サンプリングした異なるオブジェクトやサンプルを繰り返し照会することで、様々な動作やモーションタスクを生成することができます。### **シーン生成**タスクが与えられたら、対応するシミュレーションシナリオの生成を続行して、そのタスクを完了するためのスキルを習得できます。図に示すように、シーンのコンポーネントと構成はタスクの説明に従って生成され、オブジェクトアセットが取得または生成されてから、シミュレーションシーンが入力されます。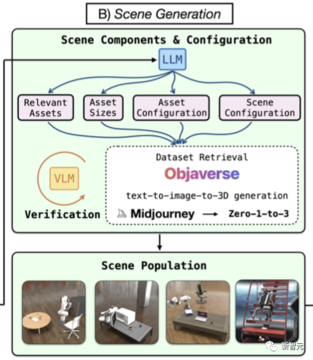 シーンのコンポーネントと構成は、シーンに入力される関連アセットのクエリ、その物理パラメーター (サイズなど)、構成 (初期ジョイント角度など)、およびアセットの全体的な空間構成の要素で構成されます。前のステップで生成されたタスクに必要なオブジェクトアセットに加えて、実際のシーンのオブジェクト分布に似せながら、生成されたシーンの複雑さと多様性を高めるために、研究者はGPT-4にタスクセマンティクスに関連するオブジェクトの追加クエリを返すように依頼しました。たとえば、「キャビネットを開けて、おもちゃを入れて、閉じる」というタスクの場合、結果のシーンには、リビングルームのマット、ランプ、本、オフィスチェアも含まれます。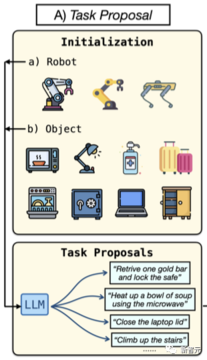 ### **教師あり世代のトレーニング**関連するスキルを習得するためには、スキル学習を監督する必要があります。RoboGen はまず GPT-4 にクエリを実行して、長いタスクを計画し、短いサブタスクに分割します。重要な前提は、タスクが十分に短いサブタスクに分割されている場合、各サブタスクは、強化学習、動作計画、軌道最適化などの既存のアルゴリズムによって確実に解決できるということです。分解後、RoboGen は GPT-4 にクエリを送信し、各サブタスクを解決するための適切なアルゴリズムを選択します。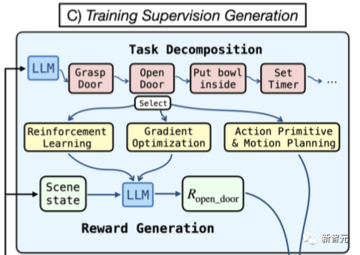 RoboGenには、強化学習、進化戦略、勾配ベースの軌道最適化、動作計画によるアクションの初期化など、いくつかの異なるタイプの学習アルゴリズムが統合されています。それぞれが勾配ベースの軌道最適化など、さまざまなタスクに適しており、生地をターゲット形状に成形するなど、ソフトボディを含むきめ細かな操作タスクの学習に適しています。アクションの初期化とモーションプランニングの組み合わせは、衝突のないパスを介してターゲットオブジェクトに近づくなどのタスクを解決するときに、より信頼性が高くなります。強化学習と進化戦略は、脚の動きなど、他のシーン コンポーネントとの絶え間ない相互作用を伴う接触の多いタスクや、オーブンのノブを回すなど、個別のエンド エフェクタのポーズによって目的のアクションを単純にパラメーター化できない場合に適しています。要約すると、GPT-4は、生成されたサブタスクに基づいて、オンラインで使用するアルゴリズムを選択します。次に、ロボットのシミュレーションシナリオを作成し、スキルを習得させます。 ## **ロボットが金庫を開けることを学習** たとえば、RoboGenは、電気スタンドの方向を調整するという非常にデリケートなタスクをロボットに学習させます。興味深いことに、このシーンでは、コンピューターのモニターなどの壊れやすいオブジェクトが地面に置かれています。ロボットの環境認識能力が試される大試しといえるでしょう。 このために、RoboGenは、シーン構成、タスク分解、監視など、非常に詳細な操作コードを生成します。 また、ロボットに金庫の中身を取り出すなど、完了までに多くのステップを要する作業も訓練します。これには、ドアを開ける、取る、下ろす、閉めるなどの操作が含まれ、その間、家具との衝突を避けることも必要です。 RoboGenによって与えられたコードは次のとおりです。 あるいは、例えば、Boston Dynamicsのヒューマノイドロボットをその場で回転させ、狭いスペースで遭遇させることができます。 コードは次のとおりです。 ## **実験結果** **- クエストの多様性**表1に示すように、RoboGenは、これまでのすべてのベンチマークと比較して、自己BLEUと埋め込みの類似性が最も低くなっています。 言い換えれば、RoboGen生成タスクの多様性は、人工的に作られたスキル学習ベンチマークやデータセットの多様性よりも高いのです。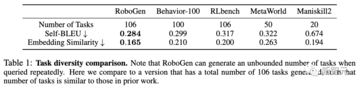 **- シナリオの有効性**図4に示すように、サイズ検証を削除すると、ObjaverseおよびPartNetMobilityのオブジェクトのサイズと現実世界の実際のサイズとの間に大きな乖離があるため、BLIP-2スコアが急激に低下します。 さらに、オブジェクト検証を行わないBLIP-2もスコアが低く、分散が大きかった。対照的に、RoboGenの検証ステップは、オブジェクト選択の有効性を大幅に向上させることができます。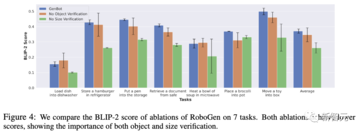 **- トレーニング指示の有効性**図3に示すように、ロボットはRoboGenが生成した訓練指導(タスク分解と報酬関数)に基づいて、4つの長距離タスクでスキルを学習します。結果は、ロボットが対応するタスクを完了するためのスキルを正常に学習したことを示しています。 言い換えれば、自動生成されたトレーニングコーチは、有意義で有用なスキルを引き出すのに効果的です。 **- スキル学習**表2の結果は、学習アルゴリズムの選択を認めることが、タスク完了のパフォーマンスを向上させるのに有益であることを示しています。 RLのみを使用すると、ほとんどのタスクでスキル学習に失敗します。 **-制**図1に示すように、RoboGenは、剛体/関節の物体操作、移動、軟体操作など、スキル学習のためのさまざまなタスクを生成できます。図3はさらに、RoboGenが合理的な分解方法で長距離操作スキルを提供できることを示しています。 ## **著者紹介**  Yufei Wangは、カーネギーメロン大学のロボット工学研究所の博士課程3年生で、ザッコリー・エリクソン教授とデビッド・ヘルド教授の指導を受け、ロボット工学の学習に関心を持っています。それ以前は、2020年12月にDavid Held教授の指導の下、CMUでコンピューターサイエンスの修士号を取得し、2019年7月に北京大学元培学院でBin Dong教授の指導の下でデータサイエンスの学士号を取得しました。 Zhou Xianは、カーネギーメロン大学のロボット工学研究所の博士課程の学生で、Katerina Fragkiadakiの指導の下にあります。 研究分野は、ロボット工学、コンピュータビジョン、世界モデル学習。CMUに入社する前は、シンガポールの南洋理工大学でPham Quang CuongとI-Ming Chenの指導の下、学士号を取得しました。 また、Meta AI、Akshara Rai、MIT-IBM AI LabでChuang Gan氏の指導の下、インターンを経験しました。現在は、スケーラブルなロボット学習のための統一されたニューラル戦略とシミュレーション基盤の構築に研究を集中的に行っています。さらに、清華姚潘の陳鳳もいます。 チームリーダーのGan Chuang氏は、現在IBMのチーフサイエンティストであり、マサチューセッツ大学の助教授であり、姚志志学者の弟子です。 博士課程では、清華特別賞、Microsoft Scholar、Baidu Scholarを受賞しました。 彼の研究は、Amazon Research Award、Sony Faculty Award、Cisco Faculty Award、Microsoft Accelerate Foundation Models Research Programなどから資金提供を受けています。リソース:


CMU清華マサチューセッツ工科大学(MIT)が世界初のエージェント無限ストリームを爆発させ、ロボット「007」は残業と自己学習をやめられません! 身体化された知性に革命が起きる
記事のソース: New Zhiyuan
編集部:アエネアスは眠い
世界初のジェネレーティブボットエージェントがリリースされました!
長い間、大規模なインターネットデータで学習できる言語モデルや視覚モデルと比較して、ロボットを訓練するための戦略モデルには動的な物理的相互作用情報を含むデータが必要であり、これらのデータの欠如は常に身体性知能の開発における最大のボトルネックでした。
最近、CMU、清華大学、マサチューセッツ工科大学、マサチューセッツ工科大学、その他の機関の研究者が、新しいRoboGenエージェントを提案しました。
大規模言語モデルや生成モデルに含まれる大規模な知識と、リアルなシミュレーション世界が提供する物理情報を組み合わせることで、さまざまなタスク、シナリオ、ティーチングデータを「無制限」に生成し、ロボットを24時間週7日完全にトレーニングすることができます。
ディープラーニングの父であるヒントン氏は、「テクノロジー企業は、今後18か月でGPT-4の100倍の計算能力を備えた新しいモデルをトレーニングする」と述べています。 モデルのパラメータは大きくなり、計算能力の需要は膨大ですが、データはどこにあるのでしょうか?
飢えたモデルに直面したとき、AI合成が答えです。
プロジェクトホームページ:
オープンソースアドレス:
具体的には、MIT-IBMのチーフサイエンティストであるGan Chuang氏が率いる研究チームは、生成AIと微分可能な物理シミュレーションのサポートを受けた「提案-生成-学習」ループを提案し、エージェントが自分で問題を解決し、ロボットを訓練できるようにします。
まず、エージェントから「このスキルを磨くべきだ」と提案されました。
次に、適切な環境、構成、スキル学習ガイダンスを生成して、シミュレートされた環境を作成します。
最後に、エージェントは提案された上位レベルのタスクをサブタスクに分解し、最適な学習方法を選択してから、戦略を学習し、提案されたスキルを習得します。
プロセス全体が人間の監督をほとんど必要とせず、タスクの数が無制限であることは注目に値します。
この大ヒット研究のために、NVIDIAのシニアサイエンティストであるJim Fan氏もそれを転送しました。
荷物をロッカーに入れる:
多様なスキル学習の鍵となる模擬環境
ロボット研究における長年のジレンマは、ロボットに工場以外の環境で動作し、人間のためにさまざまなタスクを実行するスキルをいかに与えるかということです。
近年、ロボットには、流体操作、物投げ、サッカー、パルクールなど、さまざまな複雑なスキルを教えていますが、これらのスキルはサイロ化され、視野が狭く、人間が設計したタスクの説明とトレーニングの監督が必要です。
実世界のデータ収集にはコストと手間がかかるため、これらのスキルはシミュレーションでトレーニングされ、適切なドメインでランダム化されてから、現実の世界に展開されます。
シミュレートされた環境には、低レベルの状態への特権アクセスや探索の無制限の機会を提供するなど、現実世界の探索やデータ収集に比べて多くの利点があります。 超並列コンピューティングをサポートし、データ収集の速度が大幅に高速化されます。 ボットがクローズドループ戦略とエラー回復機能を開発できるようにします。
ただし、シミュレートされた環境を構築するには、一連の面倒なタスク (タスクの設計、関連性があり意味的に意味のある資産の選択、適切なシナリオのレイアウトと構成の生成、報酬関数や損失関数などのトレーニング監督の定式化) が必要です。 シミュレートされた世界でも、ロボットのスキル学習のスケーラビリティは大きく制限されています。
ジェネレーティブ・シミュレーションは、最先端のベースモデルの生成能力を活用して、シミュレーションにおけるさまざまなロボットスキルに必要なすべての段階の情報を生成できる。
最新のベースモデルの包括的なコーディング知識のおかげで、この方法で生成されたシナリオとタスクのデータは、実際のシナリオの分布と非常によく似ています。
さらに、これらのモデルは、ドメイン固有のポリシー学習方法でシームレスに処理できる分解された低レベルのサブタスクをさらに提供できるため、さまざまなスキルとシナリオのクローズドループのデモンストレーションが得られます。
RoboGen プロセス
RoboGenは、ロボットが24時間年中無休でさまざまなスキルを習得できる完全に自動化されたプロセスであり、4つの段階で構成されています。
1.タスクの提案。
2.シーン生成。
3.監視された世代のトレーニング。
タスクの提案
この段階で、RoboGenは上位レベルのタスクを提案し、対応する環境を生成し、上位レベルの目標を低レベルのサブタスクに分解し、サブスキルを順次学習することができます。
まず、RoboGenは、ロボットが学習するための有意義で多様な高レベルのタスクを生成します。
研究者は、特定のロボットタイプとプールからのオブジェクトのランダムサンプルを使用してシステムを初期化します。 提供されたロボットとサンプルオブジェクトの情報は、LLMに入力されます。
このサンプリング プロセスにより、生成タスクの多様性が保証されます。
例えば、四足歩行ロボットなどの脚付きロボットは、様々な運動能力を獲得することができ、ロボットアームマニピュレータは、ペアを組むことで、異なるサンプリング対象物を用いて様々な操作タスクを実行できる可能性を秘めている。
初期化に使用されるオブジェクトは、オーブン、電子レンジ、ウォーター ディスペンサー、ラップトップ、食器洗い機など、家庭のシーンで一般的な多関節オブジェクトと非多関節オブジェクトを含む、定義済みのリストからサンプリングされます。
GPT-4は大規模なインターネットデータセットでトレーニングされているため、これらのオブジェクトのアフォーダンス、それらとの対話方法、およびそれらがどのような意味のあるタスクに関連付けることができるかについて豊富な理解を持っています。
例えば、サンプリングされた多関節物体が電子レンジで、ジョイント0がドアをつなぐ回転ジョイントで、ジョイント1がタイマーノブを制御する別の回転ジョイントである場合、GPT-4は「ロボットアームがスープの入ったボウルを電子レンジに入れ、ドアを閉め、マイクロ波タイマーを加熱時間aにセットする」というタスクを返します。
多関節オブジェクトの場合、PartNetMobilityは唯一の高品質な多関節オブジェクトデータセットであり、すでに広範囲の多関節アセットをカバーしているため、サンプリングされたアセットに基づいてタスクが生成されます。
サンプリングした異なるオブジェクトやサンプルを繰り返し照会することで、様々な動作やモーションタスクを生成することができます。
シーン生成
タスクが与えられたら、対応するシミュレーションシナリオの生成を続行して、そのタスクを完了するためのスキルを習得できます。
図に示すように、シーンのコンポーネントと構成はタスクの説明に従って生成され、オブジェクトアセットが取得または生成されてから、シミュレーションシーンが入力されます。
前のステップで生成されたタスクに必要なオブジェクトアセットに加えて、実際のシーンのオブジェクト分布に似せながら、生成されたシーンの複雑さと多様性を高めるために、研究者はGPT-4にタスクセマンティクスに関連するオブジェクトの追加クエリを返すように依頼しました。
たとえば、「キャビネットを開けて、おもちゃを入れて、閉じる」というタスクの場合、結果のシーンには、リビングルームのマット、ランプ、本、オフィスチェアも含まれます。
関連するスキルを習得するためには、スキル学習を監督する必要があります。
RoboGen はまず GPT-4 にクエリを実行して、長いタスクを計画し、短いサブタスクに分割します。
重要な前提は、タスクが十分に短いサブタスクに分割されている場合、各サブタスクは、強化学習、動作計画、軌道最適化などの既存のアルゴリズムによって確実に解決できるということです。
分解後、RoboGen は GPT-4 にクエリを送信し、各サブタスクを解決するための適切なアルゴリズムを選択します。
それぞれが勾配ベースの軌道最適化など、さまざまなタスクに適しており、生地をターゲット形状に成形するなど、ソフトボディを含むきめ細かな操作タスクの学習に適しています。
アクションの初期化とモーションプランニングの組み合わせは、衝突のないパスを介してターゲットオブジェクトに近づくなどのタスクを解決するときに、より信頼性が高くなります。
強化学習と進化戦略は、脚の動きなど、他のシーン コンポーネントとの絶え間ない相互作用を伴う接触の多いタスクや、オーブンのノブを回すなど、個別のエンド エフェクタのポーズによって目的のアクションを単純にパラメーター化できない場合に適しています。
要約すると、GPT-4は、生成されたサブタスクに基づいて、オンラインで使用するアルゴリズムを選択します。
次に、ロボットのシミュレーションシナリオを作成し、スキルを習得させます。
ロボットが金庫を開けることを学習
たとえば、RoboGenは、電気スタンドの方向を調整するという非常にデリケートなタスクをロボットに学習させます。
興味深いことに、このシーンでは、コンピューターのモニターなどの壊れやすいオブジェクトが地面に置かれています。
ロボットの環境認識能力が試される大試しといえるでしょう。
これには、ドアを開ける、取る、下ろす、閉めるなどの操作が含まれ、その間、家具との衝突を避けることも必要です。
実験結果
- クエストの多様性
表1に示すように、RoboGenは、これまでのすべてのベンチマークと比較して、自己BLEUと埋め込みの類似性が最も低くなっています。 言い換えれば、RoboGen生成タスクの多様性は、人工的に作られたスキル学習ベンチマークやデータセットの多様性よりも高いのです。
図4に示すように、サイズ検証を削除すると、ObjaverseおよびPartNetMobilityのオブジェクトのサイズと現実世界の実際のサイズとの間に大きな乖離があるため、BLIP-2スコアが急激に低下します。 さらに、オブジェクト検証を行わないBLIP-2もスコアが低く、分散が大きかった。
対照的に、RoboGenの検証ステップは、オブジェクト選択の有効性を大幅に向上させることができます。
図3に示すように、ロボットはRoboGenが生成した訓練指導(タスク分解と報酬関数)に基づいて、4つの長距離タスクでスキルを学習します。
結果は、ロボットが対応するタスクを完了するためのスキルを正常に学習したことを示しています。 言い換えれば、自動生成されたトレーニングコーチは、有意義で有用なスキルを引き出すのに効果的です。
表2の結果は、学習アルゴリズムの選択を認めることが、タスク完了のパフォーマンスを向上させるのに有益であることを示しています。 RLのみを使用すると、ほとんどのタスクでスキル学習に失敗します。
図1に示すように、RoboGenは、剛体/関節の物体操作、移動、軟体操作など、スキル学習のためのさまざまなタスクを生成できます。
図3はさらに、RoboGenが合理的な分解方法で長距離操作スキルを提供できることを示しています。
著者紹介
それ以前は、2020年12月にDavid Held教授の指導の下、CMUでコンピューターサイエンスの修士号を取得し、2019年7月に北京大学元培学院でBin Dong教授の指導の下でデータサイエンスの学士号を取得しました。
CMUに入社する前は、シンガポールの南洋理工大学でPham Quang CuongとI-Ming Chenの指導の下、学士号を取得しました。 また、Meta AI、Akshara Rai、MIT-IBM AI LabでChuang Gan氏の指導の下、インターンを経験しました。
現在は、スケーラブルなロボット学習のための統一されたニューラル戦略とシミュレーション基盤の構築に研究を集中的に行っています。
さらに、清華姚潘の陳鳳もいます。
リソース: