記事のソース: 量子ビット GPT-4Vはコンピュータを自動で操作することを学び、ついにその日がやってきました。**マウス**と**キーボード**をGPT-4Vに接続するだけで、ブラウザのインターフェースに従ってインターネットを閲覧できます。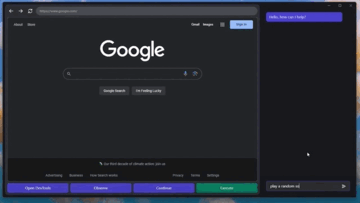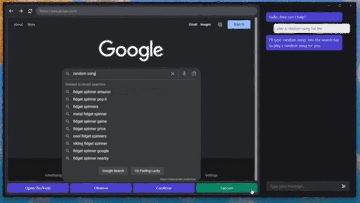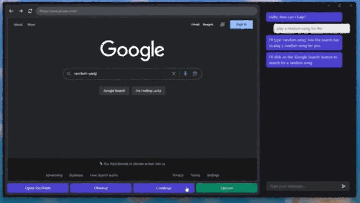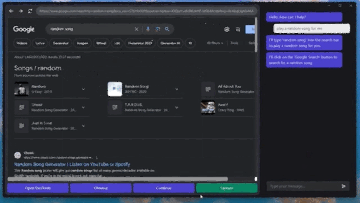 プレーヤーのWebサイトと「音楽を再生」するためのボタンをすばやく把握して、音楽を自分に与えることもできます。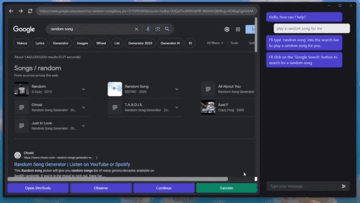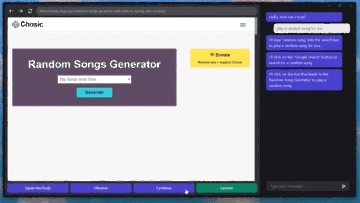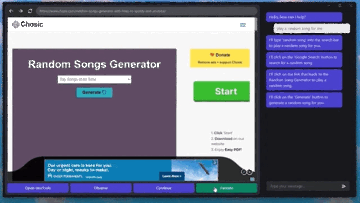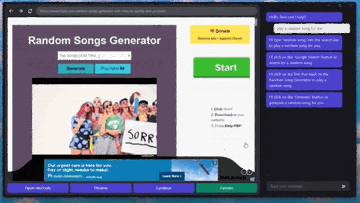 ちょっと怖くないですか?これは、**GPT-4V-Act**という名前のMIT学部生の兄弟によって作られた新しい仕事です。 GPT-4Vは、いくつかの簡単なツールで、キーボードとマウスの制御、ブラウザを使用したオンライン投稿、食料品の購入、さらにはゲームのプレイを学習することができます。使用したツールに何か問題が発生した場合、GPT-4Vはそれを認識して修正しようとします。 方法は次のとおりです。 ## **GPT-4Vに「自動的にインターネットをサーフィンする」ように教える** GPT-4V-Actは、基本的にWebブラウザベースのAIマルチモーダルアシスタント(Chromium Copilot)です。人間と同じようにマウス、キーボード、画面でWebインターフェイスを「見る」ことができ、Webページのインタラクティブキーを使用して次のステップに進むことができます。この効果を実現するために、GPT-4Vに加えて、3つのツールが使用されています。1つはUIインターフェースで、GPT-4VがWebページのスクリーンショットを「見る」ことを可能にし、ユーザーがGPT-4Vと対話することも可能にします。このように、GPT-4Vは各ステップの考え方をダイアログボックスの形で反映し、ユーザーは操作を続けるかどうかを決めることができます。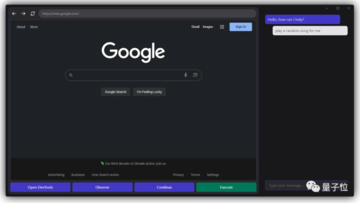 もう一つは、GPT-4Vが相互作用を学習できるようにするツールであるSet-of-Mark(SoM)ツールです。 このツールは、GPT-4Vのプロンプトワードをより適切に設計するためにMicrosoftによって発明されました。このツールは、GPT-4Vに直接「写真を見て話す」のではなく、画像の重要な部分をさまざまな部分に分割して番号を付けることができるため、GPT-4Vをターゲットにすることができます。 Webでも同じことが言え、Set-of-Markingは同様のアプローチを使用して、Webブラウザのどの部分から答えを探し、それと対話するかをGPT-4Vに知らせます。最後に、JS DOMオートラベラーを使用して、Web側のすべてのインタラクティブボタンをマークし、GPT-4Vに押すボタンを決定させる必要があります。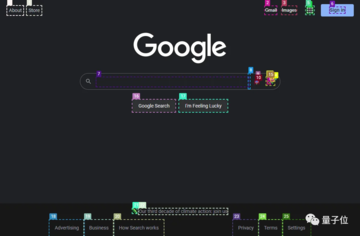 一連のプロセスの後、GPT-4Vは画像上のどのコンテンツがニーズを満たしているかを正確に判断できるだけでなく、インタラクティブボタンを正確に見つけて「自動的にインターネットをサーフィンする」ことを学習することができます。これは大きなプロジェクトであり、クリック、入力操作、自動注釈など、これまでに実装された機能は一部のみです。次に、AIマーカーを試したり(Web側での現在のインタラクションは、AI認識ではなく、どこでインタラクトするかを知るためにJSインターフェースを介して行われます)、ユーザーに詳細情報の入力を求めるなど、実装する他の機能があります。 また、筆者は現段階でGPT-4V-Actの利用にはまだ注意すべき点があるとも述べています。例えば、GPT-4V-Actは、Webページを開いた後の圧倒的なポップアップ広告に「混乱」し、インタラクションバグが発生することがあります。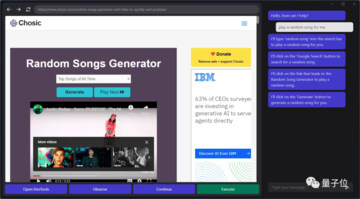 別の例としては、この種のプレイはOpenAIの製品使用規則に違反する可能性があります。> APIで許可されている場合を除き、スクレイピング、ウェブハーベスティング、ウェブデータ抽出など、自動化された方法またはプログラム的な方法を使用してサービスからデータを抽出し、出力することはできません。 したがって、それを使用するときは控えめにする必要があります(doge) ## **Microsoft SoM の作成者も視聴に来ます** このプロジェクトがオンラインに投稿されると、多くの見物人が集まりました。たとえば、私の兄弟が使用したMicrosoftのSet-of-Markツールの作成者は、このプロジェクトを見つけました。> お疲れ様でした! 一部のネチズンは、AIに検証コードを単独で読み取らせるためにも使用できると述べました。 SoMプロジェクトで述べたように、GPT-4VはCAPTCHAの解読に成功しています(そのため、将来的にインターネットをサーフィンしているのが人間なのか機械なのかわからないかもしれません)。 )。 同時に、一部のネチズンはすでにデスクトップオートメーションの操作を想像しています。これに対して著者は次のように答えた。> AI 自動アノテーターはこれを実行できるはずであり、より汎用的な Copilot を作成する予定です。 しかし、現状ではGPT-4Vを充電する必要がありますが、他に実装する方法はありますか?また、著者らは、まだないが、Fuyu-8BやLLaなどのオープンソースモデルを試す可能性があると述べている。 無料の自動デスクトップ ストリーミング AI アシスタントは、波が押し寄せることが期待できます。参考リンク: [1] [2]


GPT-4Vはキーボードとマウスでインターネットサーフィンを学習し、人間は投稿してゲームをするのを見ました
記事のソース: 量子ビット
マウスとキーボードをGPT-4Vに接続するだけで、ブラウザのインターフェースに従ってインターネットを閲覧できます。
これは、GPT-4V-Actという名前のMIT学部生の兄弟によって作られた新しい仕事です。
使用したツールに何か問題が発生した場合、GPT-4Vはそれを認識して修正しようとします。
GPT-4Vに「自動的にインターネットをサーフィンする」ように教える
GPT-4V-Actは、基本的にWebブラウザベースのAIマルチモーダルアシスタント(Chromium Copilot)です。
人間と同じようにマウス、キーボード、画面でWebインターフェイスを「見る」ことができ、Webページのインタラクティブキーを使用して次のステップに進むことができます。
この効果を実現するために、GPT-4Vに加えて、3つのツールが使用されています。
1つはUIインターフェースで、GPT-4VがWebページのスクリーンショットを「見る」ことを可能にし、ユーザーがGPT-4Vと対話することも可能にします。
このように、GPT-4Vは各ステップの考え方をダイアログボックスの形で反映し、ユーザーは操作を続けるかどうかを決めることができます。
このツールは、GPT-4Vに直接「写真を見て話す」のではなく、画像の重要な部分をさまざまな部分に分割して番号を付けることができるため、GPT-4Vをターゲットにすることができます。
最後に、JS DOMオートラベラーを使用して、Web側のすべてのインタラクティブボタンをマークし、GPT-4Vに押すボタンを決定させる必要があります。
これは大きなプロジェクトであり、クリック、入力操作、自動注釈など、これまでに実装された機能は一部のみです。
次に、AIマーカーを試したり(Web側での現在のインタラクションは、AI認識ではなく、どこでインタラクトするかを知るためにJSインターフェースを介して行われます)、ユーザーに詳細情報の入力を求めるなど、実装する他の機能があります。
例えば、GPT-4V-Actは、Webページを開いた後の圧倒的なポップアップ広告に「混乱」し、インタラクションバグが発生することがあります。
Microsoft SoM の作成者も視聴に来ます
このプロジェクトがオンラインに投稿されると、多くの見物人が集まりました。
たとえば、私の兄弟が使用したMicrosoftのSet-of-Markツールの作成者は、このプロジェクトを見つけました。
これに対して著者は次のように答えた。
また、著者らは、まだないが、Fuyu-8BやLLaなどのオープンソースモデルを試す可能性があると述べている。
参考リンク:
[1]
[2]