- Topic1/3
2k Popularity
6k Popularity
11k Popularity
4k Popularity
19k Popularity
- Pin
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974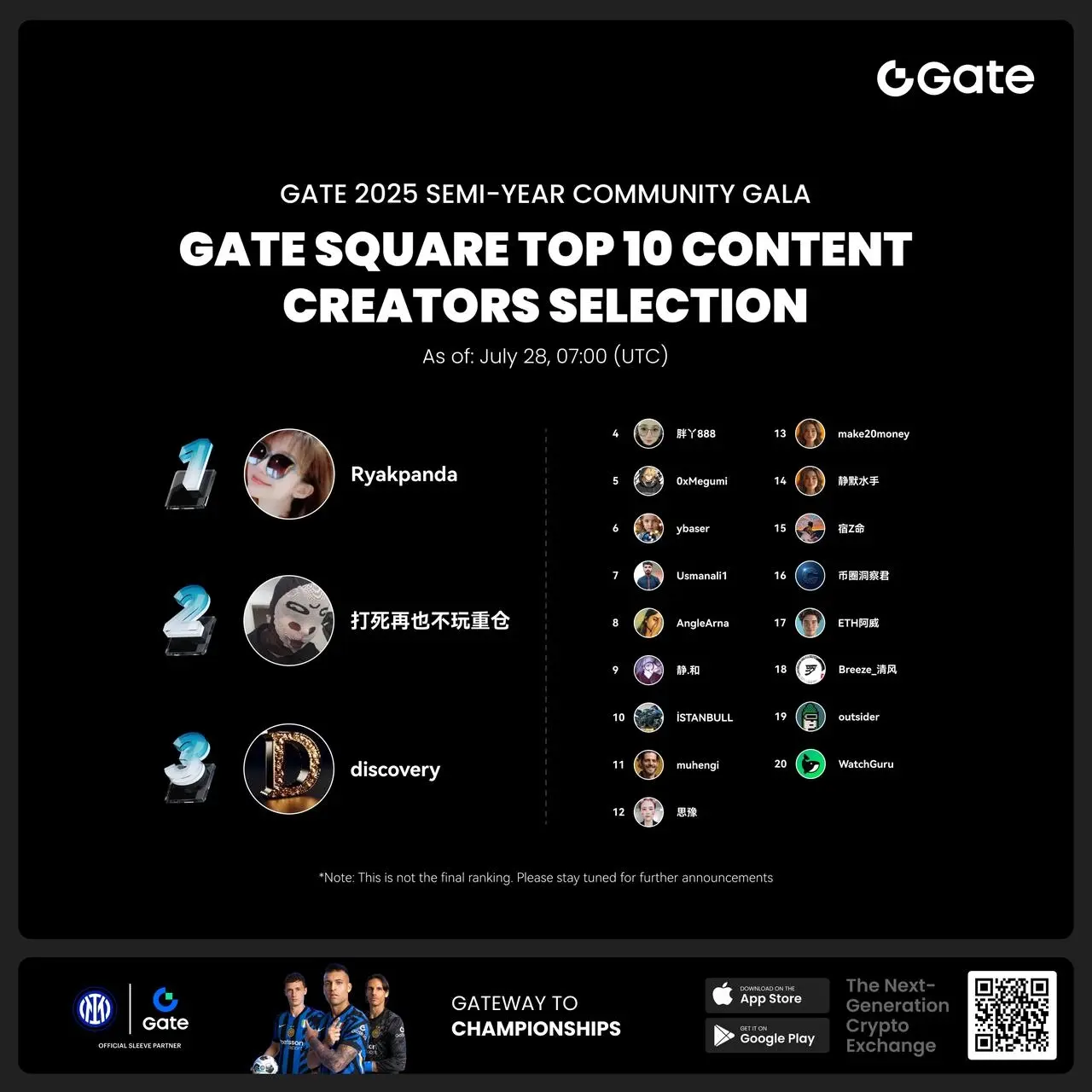
- 🎉 Hey Gate Square friends! Non-stop perks and endless excitement—our hottest posting reward events are ongoing now! The more you post, the more you win. Don’t miss your exclusive goodies! 🚀
1️⃣ #ETH Hits 4800# | Market Analysis & Prediction: Boldly share your ETH predictions to showcase your insights! 10 lucky users will split a 0.1 ETH prize!
Details 👉 https://www.gate.com/post/status/12322612
2️⃣ #Creator Campaign Phase 2# |ZKWASM Topic: Share original content about ZKWASM or its trading activity on X or Gate Square to win a share of 4,000 ZKWASM!
Details 👉 https://www.gate.com/post/st
In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key
Large language models (LLM or LM) started out to generate languages, but over time they have become able to generate content in multiple modalities and have become dominant in audio, speech, code generation, medical applications, robotics, and more.
Of course, LM can also generate images and videos. During this process, image pixels are mapped by visual tokenizers into a series of discrete tokens. These tokens are then fed into the LM transformer and are used for generative modeling just like a vocabulary. Although LM has made significant advances in visual generation, LM still performs worse than diffusion models. For example, when evaluated on the ImageNet dataset, the gold benchmark for image generation, the best language model performed as much as 48% worse than the diffusion model (FID 3.41 vs. 1.79 when generating images at 256ˆ256 resolution).
Why do language models lag behind diffusion models in terms of visual generation? Researchers from Google, CMU, believe that the main reason is the lack of a good visual representation, similar to our natural language system, to effectively model the visual world. To confirm this hypothesis, they conducted a study.
This study shows that with good visual tokenizer, masking language models outperform SOTA diffusion models in terms of generative fidelity and efficiency of image and video benchmarks for the same training data, comparable model sizes, and training budget. This is the first evidence that a language model beats a diffusion model on the iconic ImageNet benchmark.
It should be emphasized that the purpose of the researchers is not to assert whether the language model is superior to other models, but to promote the exploration of LLM visual tokenization methods. The fundamental difference between LLM and other models, such as diffusion models, is that LLM uses a discrete latent format, i.e., tokens obtained from visualizing tokenizers. This study shows that the value of these discrete visual tokens should not be overlooked because of their following advantages:
Compatibility with LLM. The main advantage of token representation is that it shares the same form as the language token, allowing it to directly take advantage of the optimizations that the community has made over the years to develop LLM, including faster training and inference, advances in model infrastructure, ways to scale models, and innovations such as GPU/TPU optimization. Unifying vision and language through the same token space can lay the foundation for a truly multimodal LLM that can be understood, generated, and reasoned in our visual environment.
Compression representation. Discrete tokens can provide a new perspective on video compression. Visual tokens can be used as a new video compression format to reduce the disk storage and bandwidth occupied by data during transmission over the Internet. Unlike compressed RGB pixels, these tokens can be fed directly into the generative model, bypassing traditional decompression and potential encoding steps. This can speed up the processing of building video applications, which is especially beneficial in edge computing scenarios.
Visual understanding advantages. Previous studies have shown that discrete tokens are valuable as pre-training targets in self-supervised representation learning, as discussed in BEiT and BEVT. In addition, the study found that using tokens as model inputs improved robustness and generalization.
In this paper, the researchers propose a video tokenizer called MAGVIT-v2, which aims to map videos (and images) into compact discrete tokens.
The model is based on the SOTA video tokenizer – MAGVIT within the VQ-VAE framework. Based on this, the researchers propose two new technologies: 1) a novel lookup-free quantification method that makes it possible to learn a large number of words to improve the quality of language model generation; 2) Through extensive empirical analysis, they identified modifications to MAGVIT that not only improve build quality, but also allow images and videos to be tokenized using a shared vocabulary.
Experimental results show that the new model outperforms the previous best-performing video tokenizer, MAGVIT, in three key areas. First, the new model significantly improves the build quality of MAGVIT, refreshing SOTA on common image and video benchmarks. Secondly, user studies have shown that its compression quality exceeds that of MAGVIT and the current video compression standard HEVC. Moreover, it is comparable to the next-generation video codec VVC. Finally, the researchers showed that their new token performed stronger on the video understanding task with two settings and three datasets compared to MAGVIT.
Method Introduction
This paper introduces a new video tokenizer that aims to dynamically map time-space in visual scenes into compact discrete tokens suitable for language models. In addition, the method builds on MAGVIT.
The study then highlighted two novel designs: Lookup-Free Quantization (LFQ) and enhancements to the tokenizer model.
No Lookup Quantization
Recently, the VQ-VAE model has made great progress, but one drawback of this method is that the relationship between the improvement of reconstruction quality and subsequent generation quality is not clear. Many people mistakenly think that improving reconstruction is equivalent to improving the generation of language models, for example, expanding vocabulary can improve the quality of reconstruction. However, this improvement only applies to the generation of small vocabulary, which can hurt the performance of the language model when the vocabulary is very large.
This article reduces the VQ-VAE codebook embedding dimension to 0, which is the codebook
Unlike the VQ-VAE model, this new design completely eliminates the need for embedded lookups, hence the name LFQ. This paper finds that LFQ can improve the quality of language model generation by increasing vocabulary. As shown by the blue curve in Figure 1, both reconstruction and generation improve as vocabulary increases—a feature not observed in current VQ-VAE approaches.
Federated images - video tokenization. In order to build a federated image-video tokenizer, a new design is needed. This article finds that 3D CNNs perform better than spatial transformers.
This paper explores two possible design options, such as Figure 2b combining C-ViViT with MAGVIT; Figure 2c uses temporal causal 3D convolution in place of a regular 3D CNN.
Experimental Results
Experiments verify the performance of the tokenizer proposed in this paper from three parts: video and image generation, video compression, and motion recognition. Figure 3 visually compares the results of Tokenizer with previous studies.