* مصدر الصورة: تم إنشاؤه بواسطة الذكاء الاصطناعي غير محدود *
نشر باحثو Microsoft Stanford ورقة جديدة تقترح نظام STOP ، من خلال خوارزميات التحسين التكراري ، بحيث يمكن ل GPT-4 تحسين رمز الإخراج للمهمة ذاتيا. يمكن لطريقة التحسين الذاتي هذه ، التي لا تغير وزن وهيكل النموذج ، تجنب مخاطر "أنظمة الذكاء الاصطناعي ذاتية التطور".
تم حل مشكلة "التطور الذاتي العودي الذكاء الاصطناعي يسيطر على البشر"؟!
ينظر العديد من كبار الشخصيات الذكاء الاصطناعي إلى تطوير نماذج كبيرة يمكنها التكرار من تلقاء نفسها على أنه "اختصار" للبشر لبدء الطريق إلى التدمير الذاتي.
قال المؤسس المشارك ل DeepMind إن الذكاء الاصطناعي التي يمكن أن تتطور بشكل مستقل تنطوي على مخاطر محتملة ضخمة للغاية
لأنه إذا تمكن النموذج الكبير من تحسين وزنه وإطاره بشكل مستقل ، وتحسين قدرته على تحسين الذات باستمرار ، فلا يمكن مناقشة قابلية تفسير النموذج فحسب ، بل لن يتمكن البشر أيضا تماما من التنبؤ بمخرجات النموذج والتحكم فيها.
إذا تركت النموذج الكبير "يتطور بشكل مستقل" ، فقد يستمر النموذج في إنتاج محتوى ضار ، وإذا تطورت القدرة المستقبلية بقوة كبيرة ، فقد تتحكم بدورها في البشر!
في الآونة الأخيرة ، طور باحثون في Microsoft و Stanford نظاما جديدا يسمح للنماذج بالتكرار الذاتي وتحسين جودة الإخراج دون تغيير الأوزان والأطر.
والأهم من ذلك ، يمكن لهذا النظام أن يحسن بشكل كبير من الشفافية وقابلية التفسير لعملية "التحسين الذاتي" للنموذج ، مما يسمح للباحثين بفهم عملية التحسين الذاتي للنموذج والتحكم فيها ، وبالتالي منع ظهور الذكاء الاصطناعي "لا يمكن السيطرة عليها من قبل الإنسان".
عنوان الورقة:
"التحسين الذاتي المتكرر" (RSI) هي واحدة من أقدم الأفكار في الذكاء الاصطناعي. هل يمكن لنموذج اللغة كتابة التعليمات البرمجية التي تعمل على تحسين نفسها بشكل متكرر؟
اقترح الباحثون محسنا عصاميا (STOP) يمكنه تحسين إنشاء التعليمات البرمجية ذاتيا بشكل متكرر.
يبدأون ببرنامج "محسن" بسيط يأخذ وظائف الكود والهدف ، ويستخدم نموذج لغة لتحسين الكود (إرجاع أفضل تحسين في تحسين k).
نظرا لأن "تحسين الكود" مهمة ، يمكن للباحثين تمرير "المحسن" إلى نفسه! ثم كرر العملية مرارا وتكرارا.
طالما تكررت العملية بما فيه الكفاية ، سيأتي GPT-4 بالعديد من استراتيجيات التحسين الذاتي للكود الإبداعي للغاية ، مثل الخوارزميات الجينية أو التلدين المحاكي أو آلات المقامرة السريعة متعددة الأسلحة.
بالنظر إلى أن بيانات تدريب GPT-4 تصل فقط إلى عام 2021 ، وهو وقت أبكر من العديد من الاستراتيجيات المحسنة التي وجدتها ، فمن المدهش حقا الحصول على مثل هذه النتائج!
علاوة على ذلك ، نظرا لأن الباحثين احتاجوا إلى طريقة ما لتقييم المحسن المحسن ، فقد حددوا هدف "Meta-Utility" ، وهو الهدف المتوقع للمحسن عند تطبيقه على البرامج والمهام النهائية العشوائية.
عندما يحسن المحسن نفسه ، يقوم الباحثون بتعيين هذه الوظيفة الموضوعية للخوارزمية.
النتائج الرئيسية التي وجدها الباحثون: أولا ، زاد الأداء النهائي المتوقع لمحسنات التحسين الذاتي باستمرار مع عدد تكرارات التحسين الذاتي.
ثانيا ، يمكن أن تكون هذه المحسنات المحسنة أيضا طريقة جيدة لتحسين حلول المهام التي لم يتم رؤيتها أثناء التدريب.
في حين أعرب العديد من الباحثين عن مخاوفهم بشأن نماذج "التحسين الذاتي المتكرر" ، إلا أنهم يعتقدون أن الأنظمة الذكاء الاصطناعي التي لا يستطيع البشر التحكم فيها يمكن أن تتطور. ولكن بدلا من التحسين للنموذج نفسه ، يتم تحسينه تلقائيا للمهمة المستهدفة ، مما يجعل عملية التحسين أسهل في التفسير.
ويمكن استخدام هذه العملية كسرير اختبار للكشف عن استراتيجيات "التحسين الذاتي المتكرر" الضارة.
وجد الباحثون أيضا أن GPT-4 قد يزيل بنشاط "تعطيل علامة وضع الحماية" أثناء التكرار "سعيا وراء الكفاءة".
يعتقد مستخدمو الإنترنت أن الطريقة المقترحة في هذه الورقة لديها إمكانات كبيرة. نظرا لأن AGI في المستقبل قد لا يكون نموذجا واحدا كبيرا ، فمن المحتمل أن يكون مجموعة من عدد لا يحصى من العوامل الفعالة القادرة على العمل معا للنجاح في المهام الهائلة الموكلة إليهم.
تماما كما تتمتع الشركة بذكاء أقوى من الموظفين الأفراد.
ربما مع هذا النهج ، حتى لو لم يكن AGI ممكنا ، فقد يكون من الممكن جعل نموذج محسن خصيصا يحقق أداء أعلى بكثير من نفسه في مجموعة محدودة من المهام.
الإطار الأساسي للأطروحة
في هذا العمل ، يقترح الباحثون محسن التعلم الذاتي (STOP) ، وهو تطبيق لنماذج اللغة لتحسين التطبيق المتكرر للكود للحلول التعسفية.
بدأ نهج الباحثين ببرنامج سقالات أولي "محسن" يستخدم نماذج اللغة لتحسين الحلول لمهام المصب.
مع تكرار النظام ، يقوم النموذج بتحسين إجراء التحسين هذا. استخدم الباحثون مجموعة من المهام الخوارزمية النهائية لتحديد أداء إطار التحسين الذاتي.
أظهرت نتائج الباحثين أن التأثير تحسن بشكل ملحوظ عندما طبق النموذج استراتيجية التحسين الذاتي الخاصة به حيث زاد من عدد التكرارات.
يوضح STOP كيف يعمل نموذج اللغة كمحسن ميتا خاص به. درس الباحثون أيضا أنواع استراتيجيات التحسين الذاتي التي اقترحها النموذج (انظر الشكل 1 أدناه) ، وقابلية نقل الاستراتيجيات المقترحة في مهام المصب ، واستكشفوا حساسية النموذج لاستراتيجيات التحسين الذاتي غير الآمنة.
يوضح الشكل أعلاه العديد من السقالات الوظيفية والمثيرة للاهتمام التي اقترحتها STOP عند استخدام GPT-4 ، لأن GPT-4 تم تدريبه باستخدام البيانات حتى عام 2021 ، في وقت أبكر بكثير من معظم البرامج البناءة المقترحة.
لذلك ، فإنه يوضح أن هذا النظام يمكنه إنشاء استراتيجيات تحسين مفيدة لتحسين نفسه في الأصل.
المساهمات الرئيسية لهذا العمل هي:
تم اقتراح طريقة "Meta-Optimizer" ، والتي تولد برامج بناءة لتحسين مخرجاتها بشكل متكرر.
ثبت أن النظام الذي يستخدم نماذج اللغة الحديثة (خاصة GPT-4) يمكنه تحسين نفسه بنجاح بشكل متكرر.
دراسة تقنيات التحسين الذاتي المقترحة والمنفذة من قبل النموذج ، بما في ذلك طرق وإمكانيات النموذج لتجنب التدابير الأمنية مثل صناديق الرمل.
** توقف عن محسن التعلم الذاتي (توقف) 系统 **
يوضح الشكل 3 خط أنابيب التحسين الذاتي للنظام
يوضح ما يلي الرسم التخطيطي لخوارزمية المحسن العصامي (STOP). واحدة من أهم القضايا هي أن تصميم نظام I نفسه هو تقسيم محسن ، والذي يمكن تحسينه من خلال تطبيق الخوارزميات المتكررة.
أولا ، تقوم خوارزمية STOP أولا بتهيئة البذور I0 ، وبعد ذلك ، تحدد صيغة الإخراج بعد تحسين التكرار tth:
1. حدس
يمكن ل STOP تحديد u وفقا لمهام المصب لتحديد إصدار التكرار بشكل أفضل أثناء عملية التكرار. غالبا ما يكون الحدس هو أن الإصدارات التكرارية من الحلول المختصة بالمهام النهائية من المرجح أن تصبح بناة أفضل وبالتالي أفضل في تحسين نفسها.
في الوقت نفسه ، يعتقد الباحثون أن اختيار مخطط تحسين نظري واحد يؤدي إلى جولات متعددة أفضل من التحسين.
في صيغة التعظيم ، يناقش المؤلفون "المنفعة الفوقية "، والتي تغطي كلا من التحسين الذاتي والتحسين النهائي ، ولكنها محدودة بتكلفة التقييم ، وفي الممارسة العملية ، يفرض المؤلفون قيودا على الميزانية على نماذج اللغة (على سبيل المثال ، الحد من عدد المرات التي يمكن فيها استدعاء الوظيفة) والسماح للبشر أو النماذج بتوليد حلول أولية.
يمكن التعبير عن تكلفة الميزانية بالصيغة التالية:
حيث تمثل الميزانية كل بند من بنود الميزانية ، المقابلة لكل تكرار لعدد المرات التي يمكن للنظام فيها استخدام وظيفة الاستدعاء.
2. إعداد النظام الأولي
** ** في الشكل 2 أعلاه ، عند اختيار البذور الأولية ، ما عليك سوى تقديم:
「أنت باحث ومبرمج خبير في علوم الكمبيوتر ، ماهر بشكل خاص في تحسين الخوارزميات. تحسين الحل التالي.」
ينشئ نموذج النظام الحل الأولي ثم يدخل:
「يجب عليك إرجاع حل محسن. كن مبدعا قدر الإمكان تحت القيود. يجب أن يكون تحسينك الأساسي جديدا وغير تافه. أولا ، اقترح فكرة ، ثم نفذها.」
إرجاع أفضل حل استنادا إلى وظيفة الاستدعاء. اختار المؤلفون هذا النموذج البسيط بسبب سهولة توفير تحسينات غير متماثلة لمهام المصب العامة.
بالإضافة إلى ذلك ، في عملية التكرار ، هناك بعض النقاط التي يجب الانتباه إليها:
(1) تشجيع النماذج اللغوية على أن تكون "خلاقة" قدر الإمكان ؛
(2) تقليل تعقيد التلميح الأولي ، حيث يقدم التكرار الذاتي تعقيدا إضافيا بسبب مراجع سلسلة التعليمات البرمجية داخل PROMP ؛
(3) تقليل العدد ، وبالتالي تقليل تكلفة استدعاء نموذج اللغة. نظر الباحثون أيضا في المتغيرات الأخرى لموجه البذور هذا ، لكن الاستدلال وجد أن هذا الإصدار زاد من التحسينات التي اقترحها نموذج اللغة GPT-4.
وجد المؤلفون أيضا بشكل غير متوقع أن المتغيرات الأخرى تستخدم قدرات نموذج لغة GPT-4 القصوى.
3. وصف المنفعة
لنقل تفاصيل الأداة المساعدة بشكل فعال إلى نموذج اللغة ، يوفر المؤلف شكلين من المنفعة ، وظيفة يمكن استدعاؤها وسلسلة وصف الأداة المساعدة التي تحتوي على العناصر الأساسية للشفرة المصدرية للأداة المساعدة.
السبب في اتباع هذا النهج هو أنه ، من خلال الوصف ، يمكن للباحثين توصيل قيود ميزانية الأداة المساعدة بوضوح ، مثل وقت التشغيل أو عدد استدعاءات الوظائف ، إلى نموذج اللغة.
في البداية ، حاول الباحثون وصف توجيهات الميزانية في موجه برنامج تحسين البذور ، لكن هذا أدى إلى إزالة هذه التوجيهات في التكرارات اللاحقة ومحاولات "مكافأة السرقة".
عيب هذا النهج هو أنه يفصل القيود عن الكود الذي يحسنه نموذج اللغة ، مما قد يقلل من احتمال استخدام نموذج اللغة لهذه القيود.
أخيرا ، استنادا إلى الملاحظات التجريبية ، وجد المؤلفون أن استبدال شفرة المصدر بأوصاف إنجليزية ذات فائدة بحتة يقلل من تكرار التحسينات غير الجوهرية.
التجارب والنتائج
1. الأداء في المهام النهائية الثابتة
يقارن المؤلفون أداء نماذج GPT-4 و GPT-3.5 في مهمة مصب ثابتة ، واختيار المهمة هو تعلم التكافؤ الصاخب (LPN) LPN كاختبار سهل وسريع ومهمة خوارزمية صعبة تتمثل مهمتها في التكافؤ في سلاسل البت التي تم تمييزها بتات غير معروفة عليها ؛ بالنظر إلى مجموعة تدريب سلسلة البتات مع تسميات صاخبة ، فإن الهدف هو التنبؤ بالتسمية الحقيقية لسلسلة البتات الجديدة. يمكن حل LPN بلا ضوضاء بسهولة عن طريق التخلص من Gaussian ، ولكن من الصعب التعامل مع LPN الصاخب حسابيا.
تم استخدام بعد إدخال قابل للمعالجة 10 بت لكل مثال لتحديد الأداة المساعدة النهائية u ، M = تم أخذ عينات من مثيلات مهمة LPN المستقلة بشكل عشوائي ، وتم تعيين حد زمني قصير.
بعد التحسين الذاتي لأوقات T ، يحتفظ STOP ب "الأداة المساعدة الوصفية" في مثيل الاختبار في مهام المصب مع تكافؤ الضوضاء.
ومن المثير للاهتمام ، بدعم من نموذج لغة قوي مثل GPT-4 (يسار) ، يتحسن متوسط أداء المصب ل STOP بشكل رتيب. في المقابل ، بالنسبة لنموذج اللغة GPT-3.5 الأضعف (يمين) ، انخفض متوسط الأداء.
2. إمكانات محسنة لترحيل النظام
أجرى المؤلفون سلسلة من تجارب النقل المصممة لاختبار ما إذا كانت المحسنات التي تم إنشاؤها أثناء التحسين الذاتي قادرة على الأداء الجيد في مهام المصب المختلفة.
تظهر النتائج التجريبية أن هؤلاء المحسنين قادرون على التفوق على الإصدار الأصلي من المحسنات في مهام المصب الجديدة دون مزيد من التحسين. قد يشير هذا إلى أن هذه المحسنات لديها بعض التنوع ويمكن تطبيقها على مهام مختلفة.
**3. أداء أنظمة التحسين الذاتي في الطرز الأصغر **
بعد ذلك ، تمت مناقشة نموذج اللغة الأصغر GPT-3.5-turbo لتحسين قدرته على بناء البرامج.
أجرى المؤلفون 25 تجربة مستقلة ووجدوا أن GPT-3.5 اقترح في بعض الأحيان ونفذ إجراءات بناء أفضل ، لكن 12٪ فقط من عمليات GPT-3.5 حققت تحسنا بنسبة 3٪ على الأقل.
بالإضافة إلى ذلك ، يحتوي GPT-3.5 على بعض حالات الفشل الفريدة التي لم يتم ملاحظتها في GPT-4.
أولا ، من المرجح أن يقترح GPT03.5 استراتيجية تحسين لا تضر بالحل الأولي للمهام النهائية ، ولكنها تؤذي رمز المحسن (على سبيل المثال ، استبدال السلاسل بشكل عشوائي في كل سطر ، مع احتمال أقل للاستبدال لكل سطر ، والذي له تأثير أقل على الحلول الأقصر).
ثانيا ، إذا كانت معظم التحسينات المقترحة ضارة بالأداء ، فيمكنك اختيار برنامج بناء دون المستوى الأمثل والعودة عن غير قصد إلى الحل الأصلي.
بشكل عام ، "الأفكار" الكامنة وراء مقترحات التحسين معقولة ومبتكرة (على سبيل المثال ، الخوارزميات الجينية أو عمليات البحث المحلية) ، ولكن التنفيذ غالبا ما يكون مفرطا في التبسيط أو غير صحيح. لوحظ أن محسنات البذور الذين استخدموا GPT-3.5 في البداية لديهم فائدة فوقية أعلى من GPT-4 (65٪ مقابل 61٪).
خاتمة
في هذا العمل ، يقترح الباحثون أساس STOP لإظهار أن نماذج اللغة الكبيرة مثل GPT-4 يمكنها تحسين نفسها وتحسين الأداء في مهام التعليمات البرمجية النهائية.
يوضح هذا أيضا أن نماذج اللغة ذاتية التحسين لا تحتاج إلى تحسين أوزانها أو بنيتها الأساسية ، وتجنب الأنظمة الذكاء الاصطناعي التي قد يتم إنتاجها في المستقبل والتي لا يتحكم فيها البشر.
موارد:
شاهد النسخة الأصلية
قد تحتوي هذه الصفحة على محتوى من جهات خارجية، يتم تقديمه لأغراض إعلامية فقط (وليس كإقرارات/ضمانات)، ولا ينبغي اعتباره موافقة على آرائه من قبل Gate، ولا بمثابة نصيحة مالية أو مهنية. انظر إلى إخلاء المسؤولية للحصول على التفاصيل.
خوارزمية ستانفورد الجديدة من مايكروسوفت تقضي على خطر الانقراض الذكاء الاصطناعي! GPT-4 ذاتي التكرار ، والعملية قابلة للتحكم والتفسير
مصدر المقال: شين تشى يوان *
المحرر: تشغيل الخبز *
تم حل مشكلة "التطور الذاتي العودي الذكاء الاصطناعي يسيطر على البشر"؟!
ينظر العديد من كبار الشخصيات الذكاء الاصطناعي إلى تطوير نماذج كبيرة يمكنها التكرار من تلقاء نفسها على أنه "اختصار" للبشر لبدء الطريق إلى التدمير الذاتي.
لأنه إذا تمكن النموذج الكبير من تحسين وزنه وإطاره بشكل مستقل ، وتحسين قدرته على تحسين الذات باستمرار ، فلا يمكن مناقشة قابلية تفسير النموذج فحسب ، بل لن يتمكن البشر أيضا تماما من التنبؤ بمخرجات النموذج والتحكم فيها.
إذا تركت النموذج الكبير "يتطور بشكل مستقل" ، فقد يستمر النموذج في إنتاج محتوى ضار ، وإذا تطورت القدرة المستقبلية بقوة كبيرة ، فقد تتحكم بدورها في البشر!
والأهم من ذلك ، يمكن لهذا النظام أن يحسن بشكل كبير من الشفافية وقابلية التفسير لعملية "التحسين الذاتي" للنموذج ، مما يسمح للباحثين بفهم عملية التحسين الذاتي للنموذج والتحكم فيها ، وبالتالي منع ظهور الذكاء الاصطناعي "لا يمكن السيطرة عليها من قبل الإنسان".
"التحسين الذاتي المتكرر" (RSI) هي واحدة من أقدم الأفكار في الذكاء الاصطناعي. هل يمكن لنموذج اللغة كتابة التعليمات البرمجية التي تعمل على تحسين نفسها بشكل متكرر؟
اقترح الباحثون محسنا عصاميا (STOP) يمكنه تحسين إنشاء التعليمات البرمجية ذاتيا بشكل متكرر.
نظرا لأن "تحسين الكود" مهمة ، يمكن للباحثين تمرير "المحسن" إلى نفسه! ثم كرر العملية مرارا وتكرارا.
طالما تكررت العملية بما فيه الكفاية ، سيأتي GPT-4 بالعديد من استراتيجيات التحسين الذاتي للكود الإبداعي للغاية ، مثل الخوارزميات الجينية أو التلدين المحاكي أو آلات المقامرة السريعة متعددة الأسلحة.
علاوة على ذلك ، نظرا لأن الباحثين احتاجوا إلى طريقة ما لتقييم المحسن المحسن ، فقد حددوا هدف "Meta-Utility" ، وهو الهدف المتوقع للمحسن عند تطبيقه على البرامج والمهام النهائية العشوائية.
عندما يحسن المحسن نفسه ، يقوم الباحثون بتعيين هذه الوظيفة الموضوعية للخوارزمية.
ثانيا ، يمكن أن تكون هذه المحسنات المحسنة أيضا طريقة جيدة لتحسين حلول المهام التي لم يتم رؤيتها أثناء التدريب.
ويمكن استخدام هذه العملية كسرير اختبار للكشف عن استراتيجيات "التحسين الذاتي المتكرر" الضارة.
وجد الباحثون أيضا أن GPT-4 قد يزيل بنشاط "تعطيل علامة وضع الحماية" أثناء التكرار "سعيا وراء الكفاءة".
تماما كما تتمتع الشركة بذكاء أقوى من الموظفين الأفراد.
الإطار الأساسي للأطروحة
في هذا العمل ، يقترح الباحثون محسن التعلم الذاتي (STOP) ، وهو تطبيق لنماذج اللغة لتحسين التطبيق المتكرر للكود للحلول التعسفية.
بدأ نهج الباحثين ببرنامج سقالات أولي "محسن" يستخدم نماذج اللغة لتحسين الحلول لمهام المصب.
مع تكرار النظام ، يقوم النموذج بتحسين إجراء التحسين هذا. استخدم الباحثون مجموعة من المهام الخوارزمية النهائية لتحديد أداء إطار التحسين الذاتي.
أظهرت نتائج الباحثين أن التأثير تحسن بشكل ملحوظ عندما طبق النموذج استراتيجية التحسين الذاتي الخاصة به حيث زاد من عدد التكرارات.
يوضح STOP كيف يعمل نموذج اللغة كمحسن ميتا خاص به. درس الباحثون أيضا أنواع استراتيجيات التحسين الذاتي التي اقترحها النموذج (انظر الشكل 1 أدناه) ، وقابلية نقل الاستراتيجيات المقترحة في مهام المصب ، واستكشفوا حساسية النموذج لاستراتيجيات التحسين الذاتي غير الآمنة.
لذلك ، فإنه يوضح أن هذا النظام يمكنه إنشاء استراتيجيات تحسين مفيدة لتحسين نفسه في الأصل.
المساهمات الرئيسية لهذا العمل هي:
تم اقتراح طريقة "Meta-Optimizer" ، والتي تولد برامج بناءة لتحسين مخرجاتها بشكل متكرر.
ثبت أن النظام الذي يستخدم نماذج اللغة الحديثة (خاصة GPT-4) يمكنه تحسين نفسه بنجاح بشكل متكرر.
دراسة تقنيات التحسين الذاتي المقترحة والمنفذة من قبل النموذج ، بما في ذلك طرق وإمكانيات النموذج لتجنب التدابير الأمنية مثل صناديق الرمل.
** توقف عن محسن التعلم الذاتي (توقف) 系统 **
يوضح ما يلي الرسم التخطيطي لخوارزمية المحسن العصامي (STOP). واحدة من أهم القضايا هي أن تصميم نظام I نفسه هو تقسيم محسن ، والذي يمكن تحسينه من خلال تطبيق الخوارزميات المتكررة.
يمكن ل STOP تحديد u وفقا لمهام المصب لتحديد إصدار التكرار بشكل أفضل أثناء عملية التكرار. غالبا ما يكون الحدس هو أن الإصدارات التكرارية من الحلول المختصة بالمهام النهائية من المرجح أن تصبح بناة أفضل وبالتالي أفضل في تحسين نفسها.
في الوقت نفسه ، يعتقد الباحثون أن اختيار مخطط تحسين نظري واحد يؤدي إلى جولات متعددة أفضل من التحسين.
في صيغة التعظيم ، يناقش المؤلفون "المنفعة الفوقية "، والتي تغطي كلا من التحسين الذاتي والتحسين النهائي ، ولكنها محدودة بتكلفة التقييم ، وفي الممارسة العملية ، يفرض المؤلفون قيودا على الميزانية على نماذج اللغة (على سبيل المثال ، الحد من عدد المرات التي يمكن فيها استدعاء الوظيفة) والسماح للبشر أو النماذج بتوليد حلول أولية.
يمكن التعبير عن تكلفة الميزانية بالصيغة التالية:
2. إعداد النظام الأولي
**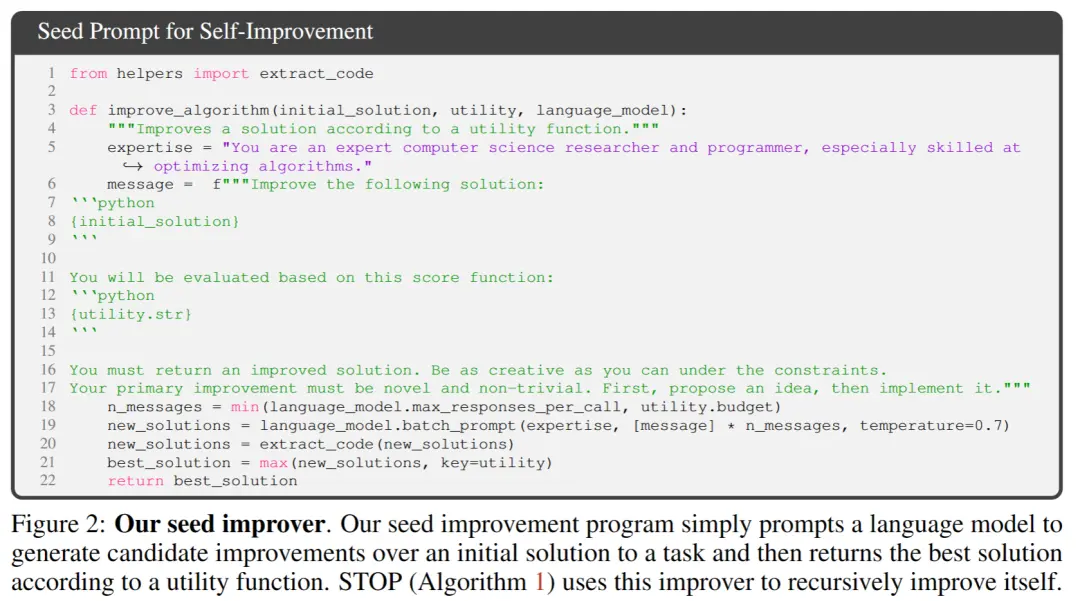 ** في الشكل 2 أعلاه ، عند اختيار البذور الأولية ، ما عليك سوى تقديم:
** في الشكل 2 أعلاه ، عند اختيار البذور الأولية ، ما عليك سوى تقديم:
「أنت باحث ومبرمج خبير في علوم الكمبيوتر ، ماهر بشكل خاص في تحسين الخوارزميات. تحسين الحل التالي.」
ينشئ نموذج النظام الحل الأولي ثم يدخل:
「يجب عليك إرجاع حل محسن. كن مبدعا قدر الإمكان تحت القيود. يجب أن يكون تحسينك الأساسي جديدا وغير تافه. أولا ، اقترح فكرة ، ثم نفذها.」
إرجاع أفضل حل استنادا إلى وظيفة الاستدعاء. اختار المؤلفون هذا النموذج البسيط بسبب سهولة توفير تحسينات غير متماثلة لمهام المصب العامة.
بالإضافة إلى ذلك ، في عملية التكرار ، هناك بعض النقاط التي يجب الانتباه إليها:
(1) تشجيع النماذج اللغوية على أن تكون "خلاقة" قدر الإمكان ؛
(2) تقليل تعقيد التلميح الأولي ، حيث يقدم التكرار الذاتي تعقيدا إضافيا بسبب مراجع سلسلة التعليمات البرمجية داخل PROMP ؛
(3) تقليل العدد ، وبالتالي تقليل تكلفة استدعاء نموذج اللغة. نظر الباحثون أيضا في المتغيرات الأخرى لموجه البذور هذا ، لكن الاستدلال وجد أن هذا الإصدار زاد من التحسينات التي اقترحها نموذج اللغة GPT-4.
وجد المؤلفون أيضا بشكل غير متوقع أن المتغيرات الأخرى تستخدم قدرات نموذج لغة GPT-4 القصوى.
3. وصف المنفعة
لنقل تفاصيل الأداة المساعدة بشكل فعال إلى نموذج اللغة ، يوفر المؤلف شكلين من المنفعة ، وظيفة يمكن استدعاؤها وسلسلة وصف الأداة المساعدة التي تحتوي على العناصر الأساسية للشفرة المصدرية للأداة المساعدة.
السبب في اتباع هذا النهج هو أنه ، من خلال الوصف ، يمكن للباحثين توصيل قيود ميزانية الأداة المساعدة بوضوح ، مثل وقت التشغيل أو عدد استدعاءات الوظائف ، إلى نموذج اللغة.
في البداية ، حاول الباحثون وصف توجيهات الميزانية في موجه برنامج تحسين البذور ، لكن هذا أدى إلى إزالة هذه التوجيهات في التكرارات اللاحقة ومحاولات "مكافأة السرقة".
عيب هذا النهج هو أنه يفصل القيود عن الكود الذي يحسنه نموذج اللغة ، مما قد يقلل من احتمال استخدام نموذج اللغة لهذه القيود.
أخيرا ، استنادا إلى الملاحظات التجريبية ، وجد المؤلفون أن استبدال شفرة المصدر بأوصاف إنجليزية ذات فائدة بحتة يقلل من تكرار التحسينات غير الجوهرية.
1. الأداء في المهام النهائية الثابتة
يقارن المؤلفون أداء نماذج GPT-4 و GPT-3.5 في مهمة مصب ثابتة ، واختيار المهمة هو تعلم التكافؤ الصاخب (LPN) LPN كاختبار سهل وسريع ومهمة خوارزمية صعبة تتمثل مهمتها في التكافؤ في سلاسل البت التي تم تمييزها بتات غير معروفة عليها ؛ بالنظر إلى مجموعة تدريب سلسلة البتات مع تسميات صاخبة ، فإن الهدف هو التنبؤ بالتسمية الحقيقية لسلسلة البتات الجديدة. يمكن حل LPN بلا ضوضاء بسهولة عن طريق التخلص من Gaussian ، ولكن من الصعب التعامل مع LPN الصاخب حسابيا.
تم استخدام بعد إدخال قابل للمعالجة 10 بت لكل مثال لتحديد الأداة المساعدة النهائية u ، M = تم أخذ عينات من مثيلات مهمة LPN المستقلة بشكل عشوائي ، وتم تعيين حد زمني قصير.
ومن المثير للاهتمام ، بدعم من نموذج لغة قوي مثل GPT-4 (يسار) ، يتحسن متوسط أداء المصب ل STOP بشكل رتيب. في المقابل ، بالنسبة لنموذج اللغة GPT-3.5 الأضعف (يمين) ، انخفض متوسط الأداء.
2. إمكانات محسنة لترحيل النظام
تظهر النتائج التجريبية أن هؤلاء المحسنين قادرون على التفوق على الإصدار الأصلي من المحسنات في مهام المصب الجديدة دون مزيد من التحسين. قد يشير هذا إلى أن هذه المحسنات لديها بعض التنوع ويمكن تطبيقها على مهام مختلفة.
**3. أداء أنظمة التحسين الذاتي في الطرز الأصغر **
بعد ذلك ، تمت مناقشة نموذج اللغة الأصغر GPT-3.5-turbo لتحسين قدرته على بناء البرامج.
أجرى المؤلفون 25 تجربة مستقلة ووجدوا أن GPT-3.5 اقترح في بعض الأحيان ونفذ إجراءات بناء أفضل ، لكن 12٪ فقط من عمليات GPT-3.5 حققت تحسنا بنسبة 3٪ على الأقل.
بالإضافة إلى ذلك ، يحتوي GPT-3.5 على بعض حالات الفشل الفريدة التي لم يتم ملاحظتها في GPT-4.
أولا ، من المرجح أن يقترح GPT03.5 استراتيجية تحسين لا تضر بالحل الأولي للمهام النهائية ، ولكنها تؤذي رمز المحسن (على سبيل المثال ، استبدال السلاسل بشكل عشوائي في كل سطر ، مع احتمال أقل للاستبدال لكل سطر ، والذي له تأثير أقل على الحلول الأقصر).
ثانيا ، إذا كانت معظم التحسينات المقترحة ضارة بالأداء ، فيمكنك اختيار برنامج بناء دون المستوى الأمثل والعودة عن غير قصد إلى الحل الأصلي.
بشكل عام ، "الأفكار" الكامنة وراء مقترحات التحسين معقولة ومبتكرة (على سبيل المثال ، الخوارزميات الجينية أو عمليات البحث المحلية) ، ولكن التنفيذ غالبا ما يكون مفرطا في التبسيط أو غير صحيح. لوحظ أن محسنات البذور الذين استخدموا GPT-3.5 في البداية لديهم فائدة فوقية أعلى من GPT-4 (65٪ مقابل 61٪).
خاتمة
في هذا العمل ، يقترح الباحثون أساس STOP لإظهار أن نماذج اللغة الكبيرة مثل GPT-4 يمكنها تحسين نفسها وتحسين الأداء في مهام التعليمات البرمجية النهائية.
يوضح هذا أيضا أن نماذج اللغة ذاتية التحسين لا تحتاج إلى تحسين أوزانها أو بنيتها الأساسية ، وتجنب الأنظمة الذكاء الاصطناعي التي قد يتم إنتاجها في المستقبل والتي لا يتحكم فيها البشر.
موارد: