Faça modelos grandes olharem para diagramas do que trabalhos de digitação! Novo estudo da NeurIPS 2023 propõe método de consulta multimodal, precisão melhora em 7,8%
A capacidade dos grandes modelos de "ler imagens" é tão forte, por que você continua procurando as coisas erradas?
Por exemplo, confundir morcegos que não se parecem com eles com raquetes, ou não reconhecer peixes raros em alguns conjuntos de dados...
Isto porque quando deixamos um modelo grande "encontrar algo", muitas vezes entramos texto.
Se a descrição for ambígua ou demasiado parcial, como "morcego" (morcego ou batida?). Ou "Cyprinodon diabolis", e a IA será confundida.
Isso leva ao uso de modelos grandes para fazer ** deteção de objetos **, especialmente mundo aberto (cena desconhecida) tarefas de deteção de objetos, o efeito muitas vezes não é tão bom quanto o esperado.
Agora, um artigo incluído no NeurIPS 2023 finalmente resolveu esse problema.
Este artigo propõe um método de deteção de objetos MQ-Det baseado em consulta multimodal, que só precisa adicionar um exemplo de imagem à entrada, o que pode melhorar muito a precisão de encontrar coisas em modelos grandes.
No conjunto de dados de deteção de benchmark LVIS, o MQ-Det melhora a precisão GLIP de modelos grandes de deteção mainstream em cerca de 7,8% em média, e melhora a precisão de 13 tarefas de benchmark de pequenas amostras a jusante em uma média de 6,3%.
Como é que isto é feito exatamente? Vamos dar uma olhada.
O seguinte é reproduzido do autor do artigo, Zhihu blogger @Qinyuanxia:
Índice
MQ-Det: Modelo grande de deteção de objetos de mundo aberto para consultas multimodais
1.1 De consulta de texto para consulta multimodal
1.2 Arquitetura de modelo de consulta multimodal plug-and-play MQ-Det
1.3 Estratégia de treinamento eficiente MQ-Det
1.4 Resultados experimentais: Avaliação sem afinação
*1.5 Resultados experimentais: Avaliação de poucos tiros
1.6 Consulta multimodal da perspetiva de deteção de objetos
MQ-Det: Modelo Grande de Deteção de Objetos de Mundo Aberto para Consulta Multimodal**
Deteção de objetos consultados multimodais na natureza
Link do artigo:
Endereço do código:**
### 1.1 De consulta de texto para consulta multimodal
Uma imagem vale mais do que mil palavras: Com o surgimento do pré-treinamento gráfico, com a ajuda da semântica aberta do texto, a deteção de objetos entrou gradualmente no estágio da perceção de mundo aberto. Por esse motivo, muitos modelos de deteção grandes seguem o padrão de consulta de texto, ou seja, usando descrições de texto categóricas para consultar alvos potenciais em imagens de destino. No entanto, esta abordagem enfrenta frequentemente o problema de ser "ampla, mas não aperfeiçoada".
Por exemplo, (1) a deteção de objetos de grão fino (alevinos) na Figura 1 é muitas vezes difícil de descrever as várias espécies de grão fino com texto limitado, e (2) a ambiguidade da categoria ("morcego" pode referir-se tanto a um morcego como a uma raquete).
No entanto, os problemas acima podem ser resolvidos por exemplos de imagem, que fornecem pistas de recursos mais ricas para o objeto de destino do que o texto, mas ao mesmo tempo o texto tem forte generalização.
Portanto, como combinar organicamente os dois métodos de consulta tornou-se uma ideia natural.
Dificuldades na obtenção de capacidades de consulta multimodal: Existem três desafios em como obter tal modelo com consultas multimodais: (1) O ajuste fino direto com exemplos de imagem limitados pode facilmente levar ao esquecimento catastrófico; (2) Treinar um grande modelo de deteção a partir do zero terá boa generalização, mas enorme consumo, por exemplo, treinamento de cartão único GLIP requer 480 dias de treinamento com 30 milhões de volume de dados.
Deteção de objetos de consulta multimodal: Com base nas considerações acima, o autor propõe um projeto de modelo simples e eficaz e estratégia de treinamento - MQ-Det.
O MQ-Det insere um pequeno número de módulos de perceção fechados (GCPs) para receber a entrada de exemplos visuais com base no modelo grande de deteção de consulta de texto congelado existente e projeta uma estratégia de treinamento de previsão de linguagem de máscara de condição visual para obter eficientemente um detetor para consultas multimodais de alto desempenho.
**1.2 Arquitetura de modelo de consulta multimodal plug-and-play MQ-Det **
** **####### △Figura 1 Diagrama da arquitetura do método MQ-Det
Módulo de Perceção Fechada
Como mostrado na Figura 1, o autor insere um módulo de reconhecimento de regulação (GCP) camada por camada no lado do codificador de texto do modelo grande de deteção de consulta de texto congelado existente, e o modo de trabalho do GCP pode ser representado sucintamente pela seguinte fórmula:
Para a i-ésima categoria, insira o exemplo visual Vi, que primeiro cruzou a atenção (X-MHA) com a imagem alvo I
para ampliar suas capacidades representacionais e, em seguida, cada categoria de texto ti e o exemplo visual de categoria correspondente
Realizar a atenção cruzada obtém
, após o que o texto original e o aumento visual do texto são melhorados por uma porta de módulo de regulação
Fusão para obter a saída da camada atual
。 Este design simples segue três princípios: (1) escalabilidade de categoria; (2) completude semântica; (3) Anti-amnésia, discussão específica pode ser encontrada no texto original.
1.3 Estratégia de Treinamento Eficiente MQ-DET
Treinamento de modulação baseado em detetor de consulta de linguagem congelada
Uma vez que o atual modelo de deteção de pré-treinamento grande de consulta de texto em si tem boa generalização, os autores acreditam que só precisa fazer pequenos ajustes com detalhes visuais com base nas características do texto original.
No artigo, há também uma demonstração experimental específica de que é fácil provocar esquecimento catastrófico após a abertura dos parâmetros do modelo original pré-treinado e ajuste fino, mas perdendo a capacidade de deteção em mundo aberto.
Portanto, o MQ-Det pode inserir eficientemente informações visuais no detetor de consulta de texto existente com base no detetor pré-treinado de consulta de texto congelado e apenas modular o módulo GCP inserido por treinamento.
No artigo, os autores aplicam as técnicas de projeto estrutural e treinamento do MQ-Det aos modelos SOTA atuais GLIP e GroundingDINO respectivamente para verificar a versatilidade do método.
Estratégia de Treino de Previsão de Linguagem de Máscara com Condição Visual
Os autores também propõem uma estratégia de treinamento preditivo de linguagem de mascaramento visualmente condicionada para resolver o problema da preguiça de aprendizagem causada pelo congelamento de modelos pré-treinados.
A chamada preguiça de aprendizagem significa que o detetor tende a manter as características da consulta de texto original durante o processo de treinamento, ignorando assim os recursos de consulta visual recém-adicionados.
Para este efeito, MQ-Det é usado aleatoriamente durante o treinamento[MASK] token substitui o token de texto, forçando o modelo a aprender do lado do recurso de consulta visual, a saber:
Embora esta estratégia seja simples, é muito eficaz, e a partir dos resultados experimentais, esta estratégia trouxe uma melhoria significativa de desempenho.
1.4 Resultados Experimentais: Avaliação sem afinação
Finetuning-free: MQ-Det propõe uma estratégia de avaliação mais prática: finetuning-free, em comparação com a avaliação zero-shot tradicional que usa apenas texto de categoria. É definido como deteção de objetos usando texto de categoria, exemplos de imagem ou uma combinação de ambos sem qualquer ajuste fino a jusante.
Sob a configuração sem ajuste fino, o MQ-Det seleciona 5 exemplos visuais para cada categoria e combina o texto da categoria para deteção de objetos, enquanto outros modelos existentes não suportam consulta visual e só podem usar descrições de texto simples para deteção de objetos. A tabela abaixo mostra os resultados do LVIS MiniVal e LVIS v1.0. Pode-se descobrir que a introdução da consulta multimodal melhorou muito a capacidade de deteção de objetos em mundo aberto.
** **###### △Tabela 1 Desempenho sem ajuste fino de cada modelo de deteção sob o conjunto de dados de referência LVIS
Como pode ser visto na Tabela 1, o MQ-GLIP-L melhorou o AP em mais de 7% com base no GLIP-L, e o efeito é muito significativo!
1.5 Resultados Experimentais: Avaliação de Poucos Tiros
** **####### △Tabela 2 O desempenho de cada modelo no ODinW-35 e 13 subconjuntos do ODinW-13 em 35 tarefas de deteção
Os autores ainda realizaram experimentos abrangentes em ODinW-35, uma tarefa de deteção 35 a jusante. Como pode ser visto na Tabela 2, o MQ-Det não só tem um forte desempenho sem ajuste fino, mas também tem boas capacidades de deteção de pequenas amostras, o que confirma ainda mais o potencial das consultas multimodais. A Figura 2 também mostra a melhoria significativa do MQ-Det para GLIP.
** **###### △Figura 2 Comparação da eficiência de utilização de dados; Eixo horizontal: o número de amostras de treinamento, eixo vertical: AP médio em OdinW-13
1.6 Perspetivas para deteção de objeto de consulta multimodal
Como um campo de pesquisa baseado em aplicações práticas, a deteção de objetos presta grande atenção ao pouso de algoritmos.
Embora o modelo anterior de deteção de objeto de consulta de texto simples mostre boa generalização, é difícil cobrir informações refinadas no chinês de deteção de mundo aberto real, e a rica granularidade de informações na imagem completa perfeitamente este link.
Até agora, podemos descobrir que o texto é genérico, mas não preciso, e a imagem é precisa, mas não geral, e se pudermos efetivamente combinar os dois, ou seja, consulta multimodal, isso promoverá a deteção de objetos de mundo aberto para avançar ainda mais.
O MQ-Det deu o primeiro passo na consulta multimodal, e sua melhoria significativa de desempenho também mostra o grande potencial da deteção de alvos de consulta multimodal.
Ao mesmo tempo, a introdução de descrições de texto e exemplos visuais oferece aos usuários mais opções, tornando a deteção de objetos mais flexível e fácil de usar.
Link original:
Ver original
Esta página pode conter conteúdo de terceiros, que é fornecido apenas para fins informativos (não para representações/garantias) e não deve ser considerada como um endosso de suas opiniões pela Gate nem como aconselhamento financeiro ou profissional. Consulte a Isenção de responsabilidade para obter detalhes.
Faça modelos grandes olharem para diagramas do que trabalhos de digitação! Novo estudo da NeurIPS 2023 propõe método de consulta multimodal, precisão melhora em 7,8%
Fonte original: Qubits
A capacidade dos grandes modelos de "ler imagens" é tão forte, por que você continua procurando as coisas erradas?
Por exemplo, confundir morcegos que não se parecem com eles com raquetes, ou não reconhecer peixes raros em alguns conjuntos de dados...
Se a descrição for ambígua ou demasiado parcial, como "morcego" (morcego ou batida?). Ou "Cyprinodon diabolis", e a IA será confundida.
Isso leva ao uso de modelos grandes para fazer ** deteção de objetos **, especialmente mundo aberto (cena desconhecida) tarefas de deteção de objetos, o efeito muitas vezes não é tão bom quanto o esperado.
Agora, um artigo incluído no NeurIPS 2023 finalmente resolveu esse problema.
No conjunto de dados de deteção de benchmark LVIS, o MQ-Det melhora a precisão GLIP de modelos grandes de deteção mainstream em cerca de 7,8% em média, e melhora a precisão de 13 tarefas de benchmark de pequenas amostras a jusante em uma média de 6,3%.
Como é que isto é feito exatamente? Vamos dar uma olhada.
O seguinte é reproduzido do autor do artigo, Zhihu blogger @Qinyuanxia:
Índice
MQ-Det: Modelo Grande de Deteção de Objetos de Mundo Aberto para Consulta Multimodal**
Deteção de objetos consultados multimodais na natureza
Link do artigo:
Endereço do código:**
Uma imagem vale mais do que mil palavras: Com o surgimento do pré-treinamento gráfico, com a ajuda da semântica aberta do texto, a deteção de objetos entrou gradualmente no estágio da perceção de mundo aberto. Por esse motivo, muitos modelos de deteção grandes seguem o padrão de consulta de texto, ou seja, usando descrições de texto categóricas para consultar alvos potenciais em imagens de destino. No entanto, esta abordagem enfrenta frequentemente o problema de ser "ampla, mas não aperfeiçoada".
Por exemplo, (1) a deteção de objetos de grão fino (alevinos) na Figura 1 é muitas vezes difícil de descrever as várias espécies de grão fino com texto limitado, e (2) a ambiguidade da categoria ("morcego" pode referir-se tanto a um morcego como a uma raquete).
No entanto, os problemas acima podem ser resolvidos por exemplos de imagem, que fornecem pistas de recursos mais ricas para o objeto de destino do que o texto, mas ao mesmo tempo o texto tem forte generalização.
Portanto, como combinar organicamente os dois métodos de consulta tornou-se uma ideia natural.
Dificuldades na obtenção de capacidades de consulta multimodal: Existem três desafios em como obter tal modelo com consultas multimodais: (1) O ajuste fino direto com exemplos de imagem limitados pode facilmente levar ao esquecimento catastrófico; (2) Treinar um grande modelo de deteção a partir do zero terá boa generalização, mas enorme consumo, por exemplo, treinamento de cartão único GLIP requer 480 dias de treinamento com 30 milhões de volume de dados.
Deteção de objetos de consulta multimodal: Com base nas considerações acima, o autor propõe um projeto de modelo simples e eficaz e estratégia de treinamento - MQ-Det.
O MQ-Det insere um pequeno número de módulos de perceção fechados (GCPs) para receber a entrada de exemplos visuais com base no modelo grande de deteção de consulta de texto congelado existente e projeta uma estratégia de treinamento de previsão de linguagem de máscara de condição visual para obter eficientemente um detetor para consultas multimodais de alto desempenho.
**1.2 Arquitetura de modelo de consulta multimodal plug-and-play MQ-Det **
** **####### △Figura 1 Diagrama da arquitetura do método MQ-Det
**####### △Figura 1 Diagrama da arquitetura do método MQ-Det
Módulo de Perceção Fechada
Como mostrado na Figura 1, o autor insere um módulo de reconhecimento de regulação (GCP) camada por camada no lado do codificador de texto do modelo grande de deteção de consulta de texto congelado existente, e o modo de trabalho do GCP pode ser representado sucintamente pela seguinte fórmula:
1.3 Estratégia de Treinamento Eficiente MQ-DET
Treinamento de modulação baseado em detetor de consulta de linguagem congelada
Uma vez que o atual modelo de deteção de pré-treinamento grande de consulta de texto em si tem boa generalização, os autores acreditam que só precisa fazer pequenos ajustes com detalhes visuais com base nas características do texto original.
No artigo, há também uma demonstração experimental específica de que é fácil provocar esquecimento catastrófico após a abertura dos parâmetros do modelo original pré-treinado e ajuste fino, mas perdendo a capacidade de deteção em mundo aberto.
Portanto, o MQ-Det pode inserir eficientemente informações visuais no detetor de consulta de texto existente com base no detetor pré-treinado de consulta de texto congelado e apenas modular o módulo GCP inserido por treinamento.
No artigo, os autores aplicam as técnicas de projeto estrutural e treinamento do MQ-Det aos modelos SOTA atuais GLIP e GroundingDINO respectivamente para verificar a versatilidade do método.
Estratégia de Treino de Previsão de Linguagem de Máscara com Condição Visual
Os autores também propõem uma estratégia de treinamento preditivo de linguagem de mascaramento visualmente condicionada para resolver o problema da preguiça de aprendizagem causada pelo congelamento de modelos pré-treinados.
A chamada preguiça de aprendizagem significa que o detetor tende a manter as características da consulta de texto original durante o processo de treinamento, ignorando assim os recursos de consulta visual recém-adicionados.
Para este efeito, MQ-Det é usado aleatoriamente durante o treinamento[MASK] token substitui o token de texto, forçando o modelo a aprender do lado do recurso de consulta visual, a saber:
1.4 Resultados Experimentais: Avaliação sem afinação
Finetuning-free: MQ-Det propõe uma estratégia de avaliação mais prática: finetuning-free, em comparação com a avaliação zero-shot tradicional que usa apenas texto de categoria. É definido como deteção de objetos usando texto de categoria, exemplos de imagem ou uma combinação de ambos sem qualquer ajuste fino a jusante.
Sob a configuração sem ajuste fino, o MQ-Det seleciona 5 exemplos visuais para cada categoria e combina o texto da categoria para deteção de objetos, enquanto outros modelos existentes não suportam consulta visual e só podem usar descrições de texto simples para deteção de objetos. A tabela abaixo mostra os resultados do LVIS MiniVal e LVIS v1.0. Pode-se descobrir que a introdução da consulta multimodal melhorou muito a capacidade de deteção de objetos em mundo aberto.
**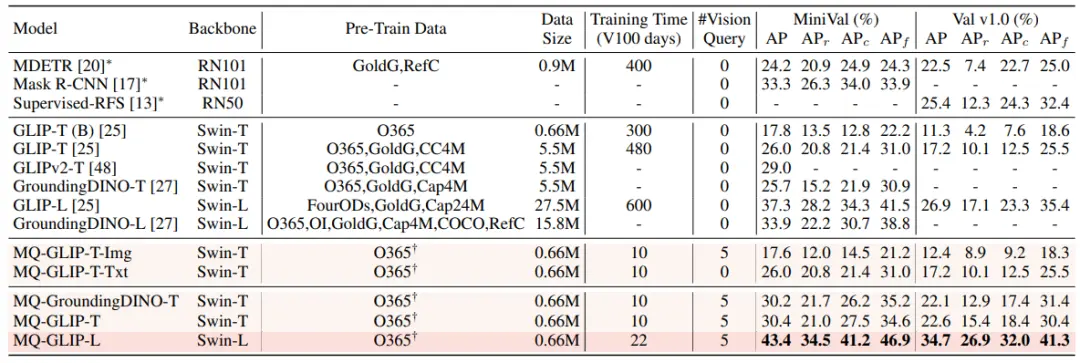 **###### △Tabela 1 Desempenho sem ajuste fino de cada modelo de deteção sob o conjunto de dados de referência LVIS
**###### △Tabela 1 Desempenho sem ajuste fino de cada modelo de deteção sob o conjunto de dados de referência LVIS
Como pode ser visto na Tabela 1, o MQ-GLIP-L melhorou o AP em mais de 7% com base no GLIP-L, e o efeito é muito significativo!
1.5 Resultados Experimentais: Avaliação de Poucos Tiros
**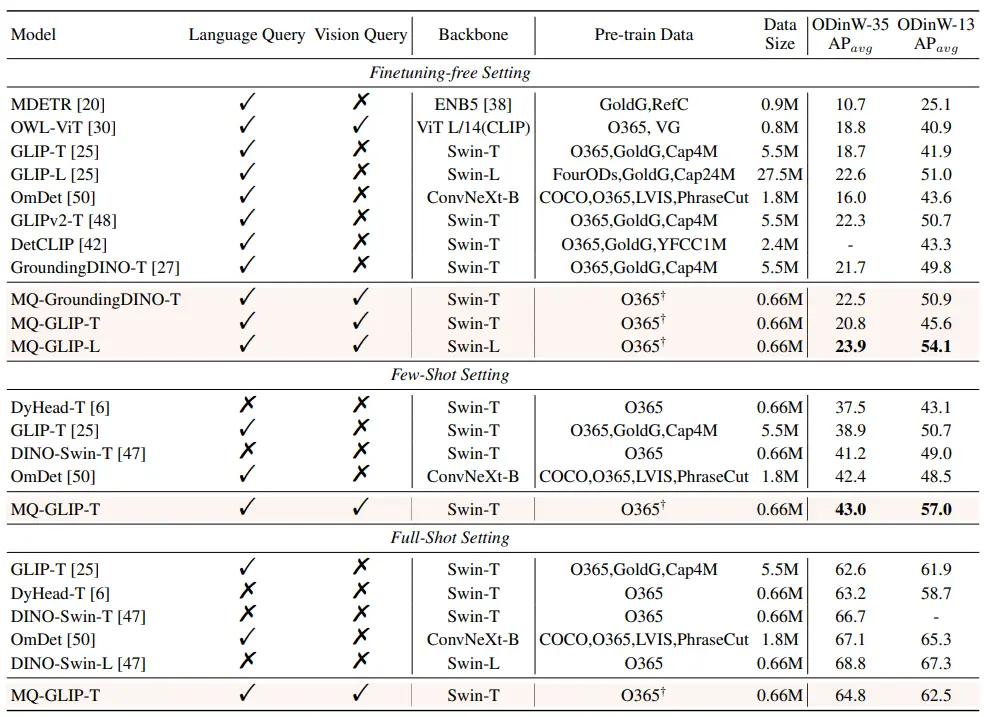 **####### △Tabela 2 O desempenho de cada modelo no ODinW-35 e 13 subconjuntos do ODinW-13 em 35 tarefas de deteção
**####### △Tabela 2 O desempenho de cada modelo no ODinW-35 e 13 subconjuntos do ODinW-13 em 35 tarefas de deteção
Os autores ainda realizaram experimentos abrangentes em ODinW-35, uma tarefa de deteção 35 a jusante. Como pode ser visto na Tabela 2, o MQ-Det não só tem um forte desempenho sem ajuste fino, mas também tem boas capacidades de deteção de pequenas amostras, o que confirma ainda mais o potencial das consultas multimodais. A Figura 2 também mostra a melhoria significativa do MQ-Det para GLIP.
**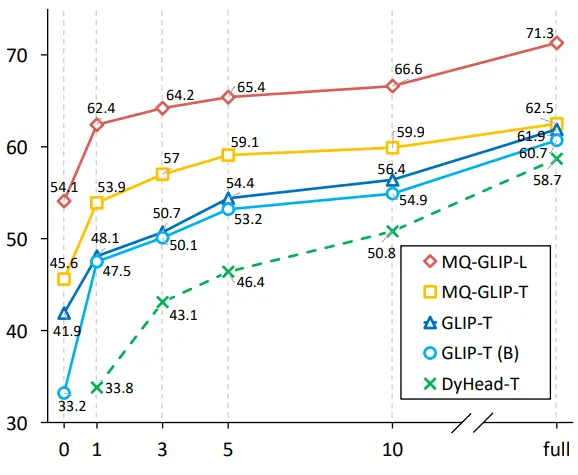 **###### △Figura 2 Comparação da eficiência de utilização de dados; Eixo horizontal: o número de amostras de treinamento, eixo vertical: AP médio em OdinW-13
**###### △Figura 2 Comparação da eficiência de utilização de dados; Eixo horizontal: o número de amostras de treinamento, eixo vertical: AP médio em OdinW-13
1.6 Perspetivas para deteção de objeto de consulta multimodal
Como um campo de pesquisa baseado em aplicações práticas, a deteção de objetos presta grande atenção ao pouso de algoritmos.
Embora o modelo anterior de deteção de objeto de consulta de texto simples mostre boa generalização, é difícil cobrir informações refinadas no chinês de deteção de mundo aberto real, e a rica granularidade de informações na imagem completa perfeitamente este link.
Até agora, podemos descobrir que o texto é genérico, mas não preciso, e a imagem é precisa, mas não geral, e se pudermos efetivamente combinar os dois, ou seja, consulta multimodal, isso promoverá a deteção de objetos de mundo aberto para avançar ainda mais.
O MQ-Det deu o primeiro passo na consulta multimodal, e sua melhoria significativa de desempenho também mostra o grande potencial da deteção de alvos de consulta multimodal.
Ao mesmo tempo, a introdução de descrições de texto e exemplos visuais oferece aos usuários mais opções, tornando a deteção de objetos mais flexível e fácil de usar.
Link original: