>、OpenAIマルチモーダル大型モデルGPT-4Vのビジュアルコンテンツの理解を向上させた新しいビジュアルキューメソッドSoM(セットオブマーク)です。元のソース: マシンの心臓部 画像ソース:無制限のAIによって生成最近では、大規模言語モデル(LLM)の大幅な進歩を目の当たりにしています。 特に、事前訓練された生成トランスフォーマー(GPT)のリリースは、産業界と学界にいくつかのブレークスルーをもたらしました。 GPT-4のリリース以来、大規模なマルチモーダルモデル(LMM)は、マルチモーダルGPT-4の構築に多くの作業が費やされ、研究コミュニティでますます関心を集めています。 最近、GPT-4V(ision)は、その優れたマルチモーダル知覚および推論機能のために特別な注目を集めています。 しかし、GPT-4Vのこれまでにない視覚言語理解能力にもかかわらず、そのきめ細かい視覚的根拠(入力は画像とそれに対応するオブジェクトの説明、出力はオブジェクトを説明するボックス)は比較的弱いか、まだ開発されていません。たとえば、ユーザーが次の図で「右側のラップトップの左側に配置されているオブジェクトは何ですか?」と尋ねると。 GPT-4Vはマグカップに間違った答えを与えます。 次に、ユーザーは「窓側の席を見つけたいのですが、どこに座れますか?」と尋ねます。 GPT-4Vも不正解しました。 上記の問題を認識した後、マイクロソフト、香港科技大学などの研究者は、きめ細かなビジョンタスクにおけるGPT-4Vの問題を解決するための新しいビジョンメソッドセットオブマーク(SoM)を提案しました。 * 論文住所:* 紙のホームページ:図1(右)に示すように、SoMはSAMなどのインタラクティブなセグメンテーションモデルを使用して、画像をさまざまな粒度レベルで領域に分割し、これらの領域に英数字、マスク、ボックスなどのマーカーのセットを追加します。 上記の問題を解決するには、タグ付きの画像を入力として使用します。最初に効果を見てみましょう、左側のGPT-4V、右側のGPT-4V + SoM、後者の分類がより詳細で正確であることは明らかです。 以下の例は同じであり、GPT-4V + SoM効果はより明白です。 また、今回の研究では、「SoMはマニュアル(手動入力)なのか、それとも自動なのか」という質問がありました。 Jianwei Yang氏によると、SoMは自動または半自動です。 彼らは、SEEM、セマンティックSAM、SAMなどの独自のセグメンテーションツールの多くをコンパイルして、ユーザーが自分で画像を自動的にセグメント化できるようにしました。 同時に、ユーザーは自分の地域を選択することもできます。 **ビジョンのためのSoM**SoM GPT-4Vを使用するユニークな利点は、テキストを超えた出力を生成できることです。 各マーカーはマスクで表される画像領域に具体的に関連付けられているため、テキスト出力で言及されているマーカーのマスクをトレースできます。 SoM GPT-4Vは、ペアのテキストとマスクを生成する機能により、視覚的に連想するテキストを生成し、さらに重要なことに、一般的なGPT-4Vモデルの課題であるさまざまなきめ細かなビジョンタスクをサポートできます。SoMはシンプルなエンジニアリングにより、GPT-4Vを次のようなさまざまなビジョンタスクに広く使用できます。*オープンボキャブラリー画像セグメンテーション:この研究では、GPT-4Vが、ラベル付けされたすべての地域のカテゴリと、所定のプールから選択されたカテゴリを網羅的に表現する必要がありました。*参照セグメンテーション:参照式が与えられた場合、GPT-4Vのタスクは、画像分割ツールボックスによって生成された候補領域から最も一致する領域を選択することです。*フレーズグラウンディング:参照セグメンテーションとは少し異なり、フレーズの関連付けは複数の名詞句で構成される完全な文を使用します。 この研究では、GPT-4Vがラベル付けされたすべてのフレーズに適切な領域を割り当てる必要がありました。*ビデオオブジェクトのセグメンテーション:入力として2つの画像を取ります。 最初のイメージは、認識する必要がある 2 番目のイメージ内のオブジェクトの一部を含むクエリ イメージです。 GPT-4V は入力として複数の画像をサポートしているため、SoM はビデオ内のフレーム間で相関するビジュアルにも適用できます。**実験と結果**研究者は「分割統治」戦略を使用して実験と評価を実行します。 インスタンスごとに新しいチャットウィンドウを使用して、評価中にコンテキストの漏洩が発生しないようにします。具体的には、研究者は各データセットから検証データの小さなサブセットを選択しました。 データセット内の画像ごとに、[画像セグメンテーション] ツールボックスを使用して抽出された領域にマーカーのセットを重ね合わせました。 同時に、特定のタスクに基づいて、研究者はさまざまなセグメンテーションツールを使用して地域を提案します。以下の表 1 に、各タスクのセットアップの詳細を示します。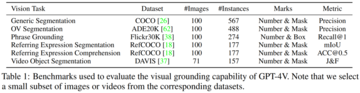 研究者たちは、彼らの方法を次のモデルと比較しました。* 予測座標のGPT-4Vベースラインモデル* SOTA固有のモデル*オープンソースLMM**定量的結果**詳細な実験結果を下記表2に示す。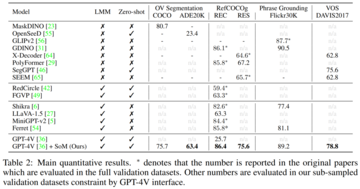 1つ目は画像セグメンテーションタスクです。 研究者らは、GPT-4V + SoMを、COCOパノプティックセグメンテーションデータセットの強力なセグメンテーションモデルMaskDINOおよびADE20KパノプティックセグメンテーションデータセットのOpenSeeDと比較しました。結果は、GPT-4V + SoMのゼロサンプル性能が微調整されたMaskDINOに近く、OpenSeeDよりも大幅に優れていることを示しています。 COCOおよびADE20KでのGPT-4Vの同様の性能は、幅広い視覚的および意味的ドメインタスクに対する強力な汎化能力を実証します。次に、研究者がRefCOCOgデータセットでモデルRESとRECを評価する参照タスクが来ました。 彼らはMaskDINOを使用してマスクを考え出し、画像にマスクと数字を重ねました。 両方のmIoUを評価指標として使用し、SOTA固有のモデルであるPolyFormerおよびSEESUREと比較しました。結果は、GPT-4V + SoMが、グラウンディングDINO、ポリフォーマーなどの特殊モデルや、Shikra、LLaVA-1.5、MiniGPT-v2、Ferretなどの最近のオープンソースLMMを上回っていることを示しています。これに続いて、Flickr30Kのフレーズ関連付けタスクが行われ、研究者はグラウンディングDINOを使用して各画像のボックス提案を生成しました。 GPT-4V+SoMは、GLIPv2やグラウンディングINOよりも強力なゼロサンプル性能を実現しています。最後に、研究者はDAVIS2017データセットのビデオセグメンテーションタスクを評価しました。 GPT-4V+SoMは、他の特殊ビジョンモデルよりも最高のトラッキング性能(78.8 J&F)を実現しています。**アブレーション研究**研究者は、タグタイプがFlickr30kデータセットでのフレーズ関連付けタスクの最終的なパフォーマンスにどのように影響するかを調査し、2種類のタグを比較します。 1つ目は数字とマスクで、2つ目は数字、マスク、ボックスです。結果は以下の表3に示されており、ボックスを追加するとパフォーマンスが大幅に向上します。 さらに、研究者たちは、真実の注釈を持つトークンを生成するときにGPT-4Vがどのように動作するかを調査しました。 彼らは、予測されたセグメンテーションマスクをRefCOCOg検証セットの真理マスクに置き換えることを選択しました。 つまり、GPT-4Vは注釈フレーズ領域から1つを選択するだけで済みます。 予想どおり、特にセグメンテーションモデルに欠落している領域がある場合、参照セグメンテーションのパフォーマンスをさらに向上させることができます。以下の表4に示すように、SoMで真実マスクを使用すると、RefCOCOgのパフォーマンスを14.5%(mIoU)向上させることができます。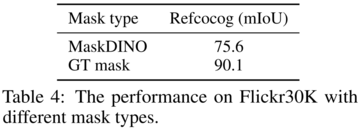
視覚的な手がかりに「マーカー」を追加すると、マイクロソフトなどはGPT-4Vをより正確かつ詳細にします
元のソース: マシンの心臓部
最近では、大規模言語モデル(LLM)の大幅な進歩を目の当たりにしています。 特に、事前訓練された生成トランスフォーマー(GPT)のリリースは、産業界と学界にいくつかのブレークスルーをもたらしました。 GPT-4のリリース以来、大規模なマルチモーダルモデル(LMM)は、マルチモーダルGPT-4の構築に多くの作業が費やされ、研究コミュニティでますます関心を集めています。
最近、GPT-4V(ision)は、その優れたマルチモーダル知覚および推論機能のために特別な注目を集めています。 しかし、GPT-4Vのこれまでにない視覚言語理解能力にもかかわらず、そのきめ細かい視覚的根拠(入力は画像とそれに対応するオブジェクトの説明、出力はオブジェクトを説明するボックス)は比較的弱いか、まだ開発されていません。
たとえば、ユーザーが次の図で「右側のラップトップの左側に配置されているオブジェクトは何ですか?」と尋ねると。 GPT-4Vはマグカップに間違った答えを与えます。 次に、ユーザーは「窓側の席を見つけたいのですが、どこに座れますか?」と尋ねます。 GPT-4Vも不正解しました。
図1(右)に示すように、SoMはSAMなどのインタラクティブなセグメンテーションモデルを使用して、画像をさまざまな粒度レベルで領域に分割し、これらの領域に英数字、マスク、ボックスなどのマーカーのセットを追加します。 上記の問題を解決するには、タグ付きの画像を入力として使用します。
最初に効果を見てみましょう、左側のGPT-4V、右側のGPT-4V + SoM、後者の分類がより詳細で正確であることは明らかです。
SoM GPT-4Vを使用するユニークな利点は、テキストを超えた出力を生成できることです。 各マーカーはマスクで表される画像領域に具体的に関連付けられているため、テキスト出力で言及されているマーカーのマスクをトレースできます。
SoMはシンプルなエンジニアリングにより、GPT-4Vを次のようなさまざまなビジョンタスクに広く使用できます。
*オープンボキャブラリー画像セグメンテーション:この研究では、GPT-4Vが、ラベル付けされたすべての地域のカテゴリと、所定のプールから選択されたカテゴリを網羅的に表現する必要がありました。 *参照セグメンテーション:参照式が与えられた場合、GPT-4Vのタスクは、画像分割ツールボックスによって生成された候補領域から最も一致する領域を選択することです。 *フレーズグラウンディング:参照セグメンテーションとは少し異なり、フレーズの関連付けは複数の名詞句で構成される完全な文を使用します。 この研究では、GPT-4Vがラベル付けされたすべてのフレーズに適切な領域を割り当てる必要がありました。 *ビデオオブジェクトのセグメンテーション:入力として2つの画像を取ります。 最初のイメージは、認識する必要がある 2 番目のイメージ内のオブジェクトの一部を含むクエリ イメージです。 GPT-4V は入力として複数の画像をサポートしているため、SoM はビデオ内のフレーム間で相関するビジュアルにも適用できます。
実験と結果
研究者は「分割統治」戦略を使用して実験と評価を実行します。 インスタンスごとに新しいチャットウィンドウを使用して、評価中にコンテキストの漏洩が発生しないようにします。
具体的には、研究者は各データセットから検証データの小さなサブセットを選択しました。 データセット内の画像ごとに、[画像セグメンテーション] ツールボックスを使用して抽出された領域にマーカーのセットを重ね合わせました。 同時に、特定のタスクに基づいて、研究者はさまざまなセグメンテーションツールを使用して地域を提案します。
以下の表 1 に、各タスクのセットアップの詳細を示します。
定量的結果
詳細な実験結果を下記表2に示す。
結果は、GPT-4V + SoMのゼロサンプル性能が微調整されたMaskDINOに近く、OpenSeeDよりも大幅に優れていることを示しています。 COCOおよびADE20KでのGPT-4Vの同様の性能は、幅広い視覚的および意味的ドメインタスクに対する強力な汎化能力を実証します。
次に、研究者がRefCOCOgデータセットでモデルRESとRECを評価する参照タスクが来ました。 彼らはMaskDINOを使用してマスクを考え出し、画像にマスクと数字を重ねました。 両方のmIoUを評価指標として使用し、SOTA固有のモデルであるPolyFormerおよびSEESUREと比較しました。
結果は、GPT-4V + SoMが、グラウンディングDINO、ポリフォーマーなどの特殊モデルや、Shikra、LLaVA-1.5、MiniGPT-v2、Ferretなどの最近のオープンソースLMMを上回っていることを示しています。
これに続いて、Flickr30Kのフレーズ関連付けタスクが行われ、研究者はグラウンディングDINOを使用して各画像のボックス提案を生成しました。 GPT-4V+SoMは、GLIPv2やグラウンディングINOよりも強力なゼロサンプル性能を実現しています。
最後に、研究者はDAVIS2017データセットのビデオセグメンテーションタスクを評価しました。 GPT-4V+SoMは、他の特殊ビジョンモデルよりも最高のトラッキング性能(78.8 J&F)を実現しています。
アブレーション研究
研究者は、タグタイプがFlickr30kデータセットでのフレーズ関連付けタスクの最終的なパフォーマンスにどのように影響するかを調査し、2種類のタグを比較します。 1つ目は数字とマスクで、2つ目は数字、マスク、ボックスです。
結果は以下の表3に示されており、ボックスを追加するとパフォーマンスが大幅に向上します。
以下の表4に示すように、SoMで真実マスクを使用すると、RefCOCOgのパフォーマンスを14.5%(mIoU)向上させることができます。