- Topic1/3
17k Popularity
171k Popularity
25k Popularity
25 Popularity
29 Popularity
- Pin
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
The best 7B model changes hands again! Defeat 70 billion LLaMA2, and Apple computers will be able to run|open source and free
Original source: qubits
The 7 billion parameter model that took 500 dollars to "tune" defeated the 70 billion parameter Llama 2!
And the notebook can run easily, and the effect is comparable to ChatGPT.
Important: Free, no money.
The open-source model Zephyr-7B created by the HuggingFace H4 team, shark crazy.
The key to Zephyr's ability to stand out among the variants was that the team fine-tuned the model on a public dataset using Direct Preference Optimization (DPO) on top of Mistral.
The team also found that removing the built-in alignment of the dataset could further improve MT Bench performance. The original Zephyr-7B-alpha had an average MT-Bench score of 7.09, surpassing the Llama2-70B-Chat.
**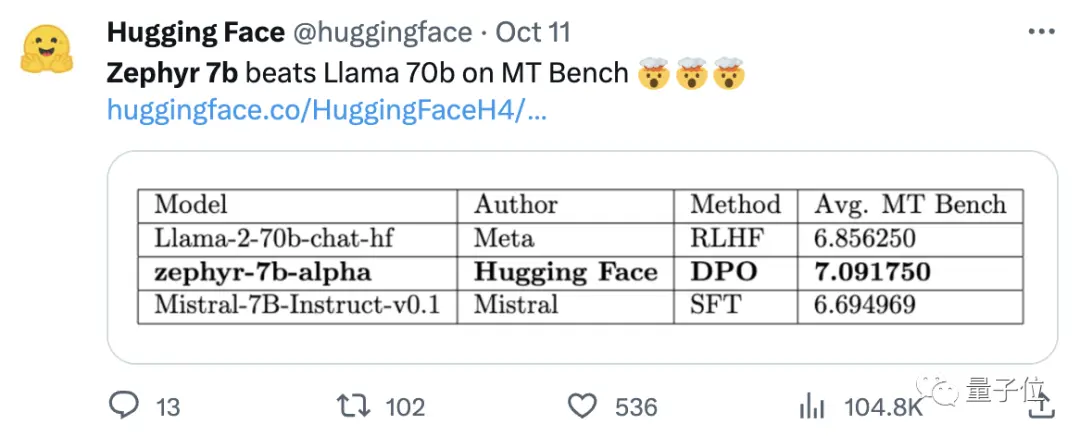 **###### △MT-Bench is a benchmark test to evaluate the model's ability to handle multiple rounds of dialogue, and the question set covers 8 categories such as writing, role-playing, and extraction.
**###### △MT-Bench is a benchmark test to evaluate the model's ability to handle multiple rounds of dialogue, and the question set covers 8 categories such as writing, role-playing, and extraction.
The point is, it then went on to upgrade!
The H4 team launched the second generation of Zephyr-7B-beta. They added that they explored the idea of extracting alignment from GPT-4, Claude 2 and then injecting it into small models, developing a method for using distillation direct preference optimization (dDPO) for small models.
In the second generation of Zephyr, the average MT-Bench score increased to 7.34.
The word Mistral means dry, cold and strong wind in French, while Zephyr means mild, pleasant westerly wind.
There is no doubt that there is a zoo on the other side of Llama, and there is no doubt that there is a weather bureau on this side.
Best 7B model changes hands again
Let's start with the computer requirements for running Zephyr. Netizens said "Thai pants are spicy" after the test! , the notebook (Apple M1 Pro) is enough, "the result is very good".
The data also shows that the effect of Zephyr's advanced RAG task can compete with GPT-3.5 and Claude 2.
They went on to add that Zephyr not only works well on RAG, but also in routing, query planning, retrieving complex SQL statements, and structured data extraction.
Abandon Reinforcement Learning
While everyone is testing Zephyr's effects, developers say the most interesting thing is not the metrics, but the way the model is trained.
The highlights are summarized below:
Broadly speaking, as mentioned at the beginning, the main reason why Zephyr is able to surpass the 70B Llama 2 is due to the use of a special fine-tuning method.
Unlike the traditional PPO reinforcement learning approach, the research team used a recent collaboration between Stanford University and CZ Biohub to propose a DPO approach.
In simple terms, DPO can be explained as follows:
In order to make the output of the model more in line with human preferences, the traditional approach has been to fine-tune the target model with a reward model. If the output is good, you will be rewarded, and if the output is bad, you will not be rewarded.
The DPO approach, on the other hand, bypasses the modeling reward function and is equivalent to optimizing the model directly on the preference data.
In general, DPO solves the problem of difficult and expensive reinforcement learning training due to human feedback.
In terms of Zephyr's training specifically, the research team initially fine-tuned Zephyr-7B-alpha on a streamlined variant of the UltraChat dataset, which contains 1.6 million conversations generated by ChatGPT (about 200,000 remaining).
(The reason for the streamlining was that the team found that Zephyr was sometimes cased incorrectly, such as "Hi. how are you?”; Sometimes the response starts with "I don't have personal X". )
Later, they further aligned the model with the publicly available openbmb/UltraFeedback dataset using TRL's DPO Trainer method.
The dataset contains 64,000 prompt-response pairs from various models. Each response is ranked by GPT-4 based on criteria such as usefulness and given a score from which an AI preference is derived.
An interesting finding is that when using the DPO method, the effect is actually better after overfitting as the training time increases. The researchers believe this is similar to overfitting in SFT.
They thought about distillation supervised fine-tuning (dSFT) used in large models, but with this approach the model was misaligned and did not produce output that matched the user's intent.
The researchers also tested the effect when SFT was not used, and the results resulted in a significant reduction in performance, indicating that the dSFT step is critical.
Demo Experience
First of all, I had to move out of the "mentally handicapped" question to take a test.
On the question "Mom and Dad don't take me when they get married", Zephyr's overall answer is more accurate.
But some netizens have tested it before, and it also knows about it in March this year.
In addition, Zephyr is very responsive, so you can write code and make up stories. :
Researchers also mentioned hallucinations, and a small line of text was marked below the input box indicating that the content generated by the model may be inaccurate or incorrect.
Always choose one of emmm fish and bear paws.
Zephyr was able to do this with only 70B parameters, which surprised Andriy Burkov, author of "The 100-Page Machine Learning Book", and even said:
Paper Links:
Reference Links:
[1]
[2]
[3]
[4]
[5]