Yao Qizhi assumiu a liderança ao propor um grande modelo de estrutura de "pensamento"! A precisão do raciocínio lógico é de 98% e a forma de pensar é mais parecida com a dos humanos.
O primeiro artigo sobre Large Language Model liderado pelo vencedor do Prêmio Turing, Yao Qizhi, está aqui!
Assim que comecei, busquei a direção de "fazer grandes modelos pensarem como pessoas"——
Os grandes modelos não apenas precisam raciocinar passo a passo, mas também precisam aprender a “passo a passo” e lembrar todos os processos corretos no processo de raciocínio.
Especificamente, este novo artigo propõe um novo método chamado Raciocínio Cumulativo, que melhora significativamente a capacidade de grandes modelos de se envolverem em raciocínios complexos.
Você deve saber que grandes modelos são baseados em cadeias de pensamento, etc., e podem ser usados para raciocínio de problemas, mas quando confrontados com problemas que exigem “várias voltas”, ainda é fácil cometer erros.
É nesta base que o raciocínio cumulativo acrescenta um “verificador” para julgar o certo do errado em tempo real. A estrutura de pensamento deste modelo também mudou de cadeia e árvore para um "gráfico acíclico direcionado" mais complexo.
Dessa forma, o modelo grande não só tem ideias mais claras para resolver problemas, mas também desenvolve a habilidade de “jogar cartas”:
Em problemas matemáticos como álgebra e teoria geométrica dos números, a precisão relativa de modelos grandes aumentou 42%; ao jogar 24 pontos, a taxa de sucesso disparou para 98%.
De acordo com o Instituto de Informações Cruzadas da Universidade de Tsinghua, o coautor Zhang Yifan explicou o ponto de partida deste artigo:
Kahneman acredita que o processamento cognitivo humano inclui dois sistemas: o "Sistema 1" é rápido, instintivo e emocional, e o "Sistema 2" é lento, atencioso e lógico.
Atualmente, o desempenho de grandes modelos de linguagem está mais próximo do “Sistema 1”, o que pode ser a razão pela qual não é bom para lidar com tarefas complexas.
O raciocínio cumulativo projetado a partir desta perspectiva é melhor do que Cadeia de Pensamento (CoT) e Árvore de Pensamento (ToT).
Então, como é realmente essa nova abordagem? Vamos dar uma olhada juntos.
Avançar a cadeia de pensamento e os "gargalos" das árvores
O núcleo do raciocínio cumulativo reside na melhoria da “forma” do processo de pensamento dos grandes modelos.
Especificamente, este método usa 3 grandes modelos de linguagem:
Proponente: Propor constantemente novas proposições, ou seja, sugerir qual é o próximo passo com base no contexto de pensamento atual.
Verificador: Verifica a exatidão da proposição do proponente e adiciona-a ao contexto de pensamento se estiver correta.
Repórter: Determina se a solução final foi obtida e se deve encerrar o processo de raciocínio.
Durante o processo de raciocínio, o “proponente” primeiro apresenta uma proposta, o “verificador” é responsável pela avaliação e o “repórter” decide se finaliza a resposta e encerra o processo de pensamento.
** ****△**Exemplo de raciocínio CR
É um pouco como os três tipos de funções em um projeto de equipe: primeiro os membros da equipe discutem várias ideias, o instrutor "verifica" qual ideia é viável e o líder da equipe decide quando concluir o projeto.
**Então, como exatamente essa abordagem muda a “forma” do pensamento de grandes modelos? **
Para entender isso, temos que começar com a "Cadeia de Pensamento, CoT" (Cadeia de Pensamento, CoT), o "criador" dos métodos de aprimoramento do pensamento de grandes modelos.
Este método foi proposto pelo cientista OpenAI Jason Wei e outros em janeiro de 2022. O núcleo é adicionar um texto de "raciocínio passo a passo" à entrada no conjunto de dados para estimular a capacidade de raciocínio do grande modelo.
** ****△**Selecionado no conjunto de dados GSM8K
Com base no princípio da cadeia de pensamento, o Google também seguiu rapidamente uma "versão da cadeia de pensamento PLUS", a saber CoT-SC, que conduz principalmente vários processos de cadeia de pensamento e realiza uma votação majoritária nas respostas para selecionar a melhor. A melhor resposta pode melhorar ainda mais a precisão do raciocínio.
Mas tanto o Thinking Chain quanto o CoT-SC ignoram um problema: há mais de uma solução para a questão, especialmente quando os humanos resolvem o problema.
Portanto, uma nova pesquisa chamada Árvore do Pensamento (ToT) apareceu posteriormente.
Este é um esquema de pesquisa em forma de árvore que permite ao modelo experimentar uma variedade de ideias de raciocínio diferentes, autoavaliar-se, escolher o próximo curso de ação e voltar atrás, se necessário.
Pode-se observar pelo método que a árvore do pensamento vai além da cadeia do pensamento, tornando o pensamento do modelo grande "mais ativo".
É por isso que, ao jogar 24 pontos, a taxa de sucesso do GPT-4 do bônus da Cadeia de Pensamentos é de apenas 4%**, mas a taxa de sucesso da Árvore de Pensamentos sobe para 74%.
MAS, independentemente da cadeia de pensamento, CoT-SC ou árvore de pensamento, tem uma limitação comum:
Nenhum deles criou um local de armazenamento para os resultados intermediários do processo de pensamento.
Afinal, nem todos os processos de pensamento podem ser transformados em cadeias ou árvores. A forma como os humanos pensam sobre as coisas é muitas vezes mais complicada.
Esta nova estrutura de raciocínio cumulativo rompe este ponto no design——
O processo de pensamento geral de um modelo grande não é necessariamente uma cadeia ou uma árvore, mas também pode ser um Gráfico Acíclico Direcionado (DAG)! (Bem, cheira a sinapses)
** ****△**As arestas no gráfico têm direções e não há caminhos circulares; cada aresta direcionada é uma etapa de derivação
Isso significa que ele pode armazenar todos os resultados de inferência historicamente corretos na memória para exploração no ramo de pesquisa atual. (Em contraste, uma árvore pensante não armazena informações de outros ramos)
Mas o raciocínio cumulativo também pode ser facilmente alternado com a cadeia de pensamento - desde que o “verificador” seja removido, é um modelo de cadeia de pensamento padrão.
O raciocínio cumulativo desenhado com base neste método tem alcançado bons resultados em diversos métodos.
Bom em matemática e raciocínio lógico
Os pesquisadores escolheram o wiki FOLIO e o AutoTNLI, jogo de 24 pontos e conjuntos de dados MATH para “testar” o raciocínio cumulativo.
O proponente, o verificador e o relator usam o mesmo modelo de linguagem ampla em cada experimento, com configurações diferentes para suas funções.
Os modelos básicos usados aqui para experimentos incluem GPT-3.5-turbo, GPT-4, LLaMA-13B e LLaMA-65B.
Vale ressaltar que, idealmente, o modelo deve ser especificamente pré-treinado usando dados relevantes da tarefa de derivação, e o "verificador" também deve adicionar um provador matemático formal, um módulo de resolução de lógica proposicional, etc.
1. Capacidade de raciocínio lógico
FOLIO é um conjunto de dados de raciocínio lógico de primeira ordem, e os rótulos das perguntas podem ser "verdadeiro", "Falso" e "Desconhecido"; AutoTNLI é um conjunto de dados de raciocínio lógico de alta ordem.
No conjunto de dados wiki FOLIO, em comparação com os métodos de resultados de saída direta (Direct), cadeia de pensamento (CoT) e cadeia de pensamento avançada (CoT-SC), o desempenho do raciocínio cumulativo (CR) é sempre o melhor.
Após a remoção de instâncias problemáticas (como respostas incorretas) do conjunto de dados, a precisão da inferência do GPT-4 usando o método CR atingiu 98,04%, com uma taxa de erro mínima de 1,96%.
Vejamos o desempenho no conjunto de dados AutoTNLI:
Comparado com o método CoT, o CR melhorou significativamente o desempenho do LLaMA-13B e do LLaMA-65B.
No modelo LLaMA-65B, a melhoria do CR em relação ao CoT atingiu 9,3%.
### 2. Capacidade de jogar jogos de 24 pontos
O artigo ToT original usava um jogo de 24 pontos, então os pesquisadores aqui usaram esse conjunto de dados para comparar CR e ToT.
O ToT usa uma árvore de pesquisa de largura e profundidade fixas, e o CR permite que modelos grandes determinem a profundidade da pesquisa de forma autônoma.
Os pesquisadores descobriram em experimentos que, no contexto de 24 pontos, o algoritmo CR e o algoritmo ToT são muito semelhantes. A diferença é que o algoritmo em CR gera no máximo um novo estado por iteração, enquanto o ToT gera muitos estados candidatos em cada iteração, e filtra e retém alguns estados.
Em termos leigos, o ToT não possui o "verificador" mencionado acima como o CR e não pode julgar se os estados (a, b, c) estão corretos ou incorretos. Portanto, o ToT explorará mais estados inválidos do que o CR.
No final, a precisão do método CR pode até chegar a 98% (ToT é 74%), e o número médio de estados acessados é muito menor que o ToT.
Em outras palavras, CR não só tem uma taxa de precisão de pesquisa mais alta, mas também tem uma eficiência de pesquisa mais alta.
### 3. Habilidade matemática
O conjunto de dados MATH contém um grande número de questões de raciocínio matemático, incluindo álgebra, geometria, teoria dos números, etc. A dificuldade das questões é dividida em cinco níveis.
Usando o método CR, o modelo pode decompor a pergunta em subquestões que podem ser concluídas passo a passo, e fazer e responder perguntas até que a resposta seja gerada.
Os resultados experimentais mostram que sob duas configurações experimentais diferentes, a taxa de precisão do CR excede os métodos existentes atualmente, com uma taxa de precisão geral de até 58% e uma melhoria relativa da precisão de 42% no problema de Nível 5. Baixei o novo SOTA sob o modelo GPT-4.
Pesquisa liderada por Yao Qizhi e Yuan Yang da Universidade Tsinghua
Este artigo vem do grupo de pesquisa AI for Math liderado por Yao Qizhi e Yuan Yang do Instituto Tsinghua de Informação Interdisciplinar.
Os co-autores do artigo são Zhang Yifan e Yang Jingqin, estudantes de doutorado de 2021 no Instituto de Informação Interdisciplinar;
O instrutor e co-autor correspondente são o professor assistente Yuan Yang e o acadêmico Yao Qizhi.
Zhang Yifan
Zhang Yifan se formou no Yuanpei College da Universidade de Pequim em 2021. Atualmente está estudando com o professor assistente Yuan Yang. Suas principais direções de pesquisa são a teoria e algoritmo de modelos básicos (grandes modelos de linguagem), aprendizagem auto-supervisionada e inteligência artificial confiável.
Yang Jingqin
Yang Jingqin recebeu seu diploma de bacharel pelo Instituto de Informações Cruzadas da Universidade de Tsinghua em 2021 e atualmente está estudando para seu doutorado com o professor assistente Yuan Yang. As principais direções de pesquisa incluem grandes modelos de linguagem, aprendizagem auto-supervisionada, cuidados médicos inteligentes, etc.
Yuan Yang
Yuan Yang é professor assistente na Escola de Informação Interdisciplinar da Universidade Tsinghua. Graduado pelo Departamento de Ciência da Computação da Universidade de Pequim em 2012; recebeu doutorado em Ciência da Computação pela Universidade Cornell, nos Estados Unidos, em 2018; de 2018 a 2019, trabalhou como pós-doutorado na Escola de Big Data Science do Instituto de Massachusetts de Tecnologia.
Suas principais direções de pesquisa são cuidados médicos inteligentes, teoria básica de IA, teoria de categorias aplicadas, etc.
Yao Qizhi
Yao Qizhi é um acadêmico da Academia Chinesa de Ciências e reitor do Instituto de Informação Interdisciplinar da Universidade Tsinghua. Ele também é o primeiro estudioso asiático a ganhar o Prêmio Turing desde a sua criação, e o único cientista da computação chinês a ganhar esta honra. até aqui.
O professor Yao Qizhi renunciou a Princeton como professor titular em 2004 e retornou a Tsinghua para lecionar; em 2005, fundou a "Classe Yao", uma aula experimental de ciência da computação para alunos de graduação de Tsinghua; em 2011, fundou o "Centro de Informações Quânticas de Tsinghua " e o "Instituto de Pesquisa de Informação Interdisciplinar"; em 2019 Em 2008, ele fundou uma aula de inteligência artificial para alunos de graduação de Tsinghua, conhecida como "Classe Inteligente".
Hoje, o Instituto de Informação Interdisciplinar da Universidade Tsinghua liderado por ele é famoso há muito tempo. Yao Class e Zhiban são afiliados ao Instituto de Informação Interdisciplinar.
Os interesses de pesquisa do Professor Yao Qizhi incluem algoritmos, criptografia, computação quântica, etc. Ele é um pioneiro internacional e autoridade neste campo. Recentemente, ele apareceu na Conferência Mundial de Inteligência Artificial de 2023. O Instituto de Pesquisa Shanghai Qizhi que ele lidera está atualmente estudando "inteligência artificial geral incorporada".
Link do papel:
Ver original
Esta página pode conter conteúdo de terceiros, que é fornecido apenas para fins informativos (não para representações/garantias) e não deve ser considerada como um endosso de suas opiniões pela Gate nem como aconselhamento financeiro ou profissional. Consulte a Isenção de responsabilidade para obter detalhes.
Yao Qizhi assumiu a liderança ao propor um grande modelo de estrutura de "pensamento"! A precisão do raciocínio lógico é de 98% e a forma de pensar é mais parecida com a dos humanos.
Fonte: Qubits
O primeiro artigo sobre Large Language Model liderado pelo vencedor do Prêmio Turing, Yao Qizhi, está aqui!
Assim que comecei, busquei a direção de "fazer grandes modelos pensarem como pessoas"——
Os grandes modelos não apenas precisam raciocinar passo a passo, mas também precisam aprender a “passo a passo” e lembrar todos os processos corretos no processo de raciocínio.
Especificamente, este novo artigo propõe um novo método chamado Raciocínio Cumulativo, que melhora significativamente a capacidade de grandes modelos de se envolverem em raciocínios complexos.
É nesta base que o raciocínio cumulativo acrescenta um “verificador” para julgar o certo do errado em tempo real. A estrutura de pensamento deste modelo também mudou de cadeia e árvore para um "gráfico acíclico direcionado" mais complexo.
Dessa forma, o modelo grande não só tem ideias mais claras para resolver problemas, mas também desenvolve a habilidade de “jogar cartas”:
Em problemas matemáticos como álgebra e teoria geométrica dos números, a precisão relativa de modelos grandes aumentou 42%; ao jogar 24 pontos, a taxa de sucesso disparou para 98%.
O raciocínio cumulativo projetado a partir desta perspectiva é melhor do que Cadeia de Pensamento (CoT) e Árvore de Pensamento (ToT).
Então, como é realmente essa nova abordagem? Vamos dar uma olhada juntos.
Avançar a cadeia de pensamento e os "gargalos" das árvores
O núcleo do raciocínio cumulativo reside na melhoria da “forma” do processo de pensamento dos grandes modelos.
Especificamente, este método usa 3 grandes modelos de linguagem:
Durante o processo de raciocínio, o “proponente” primeiro apresenta uma proposta, o “verificador” é responsável pela avaliação e o “repórter” decide se finaliza a resposta e encerra o processo de pensamento.
**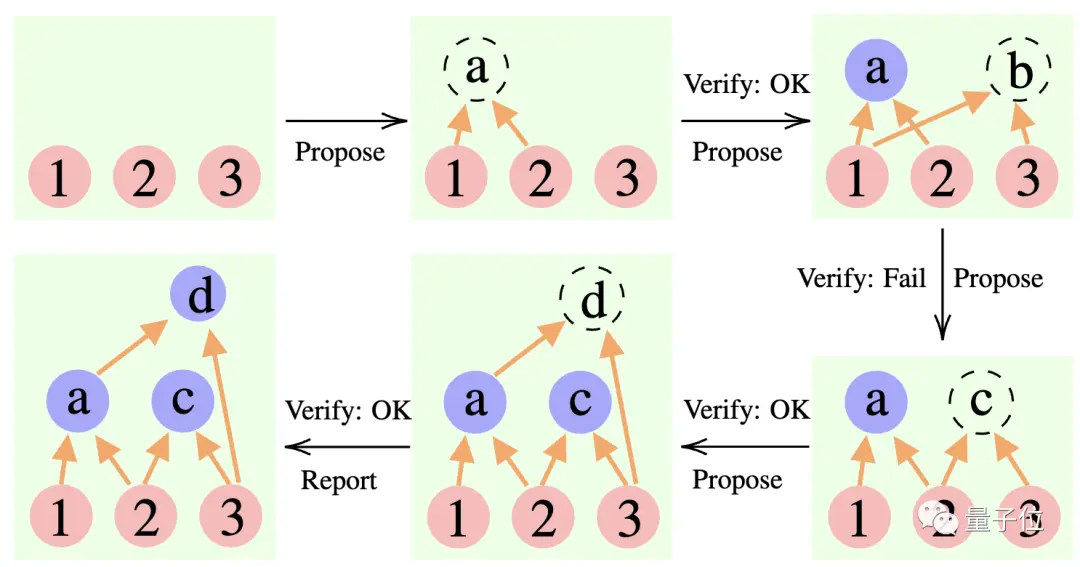 ****△**Exemplo de raciocínio CR
****△**Exemplo de raciocínio CR
É um pouco como os três tipos de funções em um projeto de equipe: primeiro os membros da equipe discutem várias ideias, o instrutor "verifica" qual ideia é viável e o líder da equipe decide quando concluir o projeto.
Para entender isso, temos que começar com a "Cadeia de Pensamento, CoT" (Cadeia de Pensamento, CoT), o "criador" dos métodos de aprimoramento do pensamento de grandes modelos.
Este método foi proposto pelo cientista OpenAI Jason Wei e outros em janeiro de 2022. O núcleo é adicionar um texto de "raciocínio passo a passo" à entrada no conjunto de dados para estimular a capacidade de raciocínio do grande modelo.
**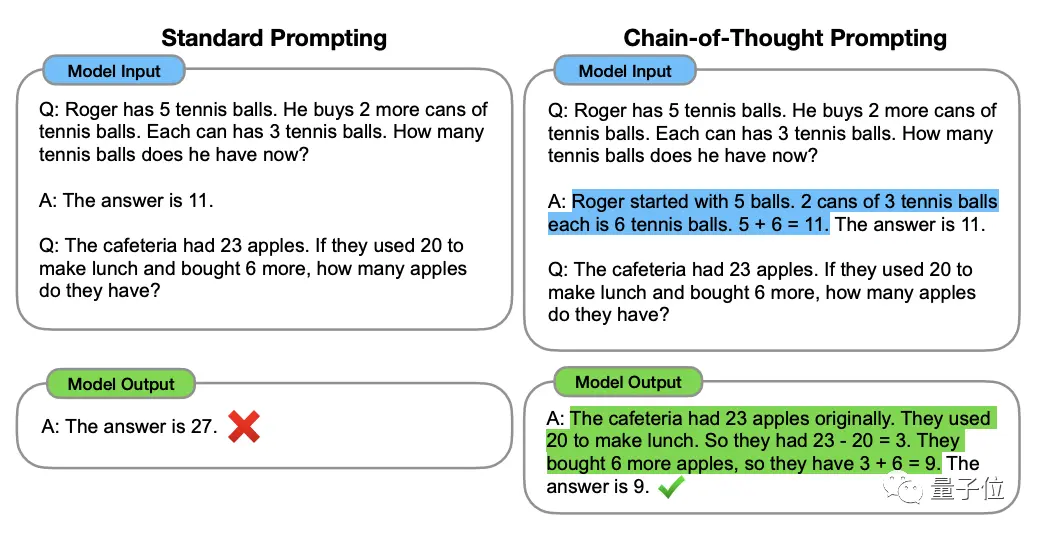 ****△**Selecionado no conjunto de dados GSM8K
****△**Selecionado no conjunto de dados GSM8K
Com base no princípio da cadeia de pensamento, o Google também seguiu rapidamente uma "versão da cadeia de pensamento PLUS", a saber CoT-SC, que conduz principalmente vários processos de cadeia de pensamento e realiza uma votação majoritária nas respostas para selecionar a melhor. A melhor resposta pode melhorar ainda mais a precisão do raciocínio.
Mas tanto o Thinking Chain quanto o CoT-SC ignoram um problema: há mais de uma solução para a questão, especialmente quando os humanos resolvem o problema.
Portanto, uma nova pesquisa chamada Árvore do Pensamento (ToT) apareceu posteriormente.
Este é um esquema de pesquisa em forma de árvore que permite ao modelo experimentar uma variedade de ideias de raciocínio diferentes, autoavaliar-se, escolher o próximo curso de ação e voltar atrás, se necessário.
É por isso que, ao jogar 24 pontos, a taxa de sucesso do GPT-4 do bônus da Cadeia de Pensamentos é de apenas 4%**, mas a taxa de sucesso da Árvore de Pensamentos sobe para 74%.
MAS, independentemente da cadeia de pensamento, CoT-SC ou árvore de pensamento, tem uma limitação comum:
Afinal, nem todos os processos de pensamento podem ser transformados em cadeias ou árvores. A forma como os humanos pensam sobre as coisas é muitas vezes mais complicada.
Esta nova estrutura de raciocínio cumulativo rompe este ponto no design——
O processo de pensamento geral de um modelo grande não é necessariamente uma cadeia ou uma árvore, mas também pode ser um Gráfico Acíclico Direcionado (DAG)! (Bem, cheira a sinapses)
**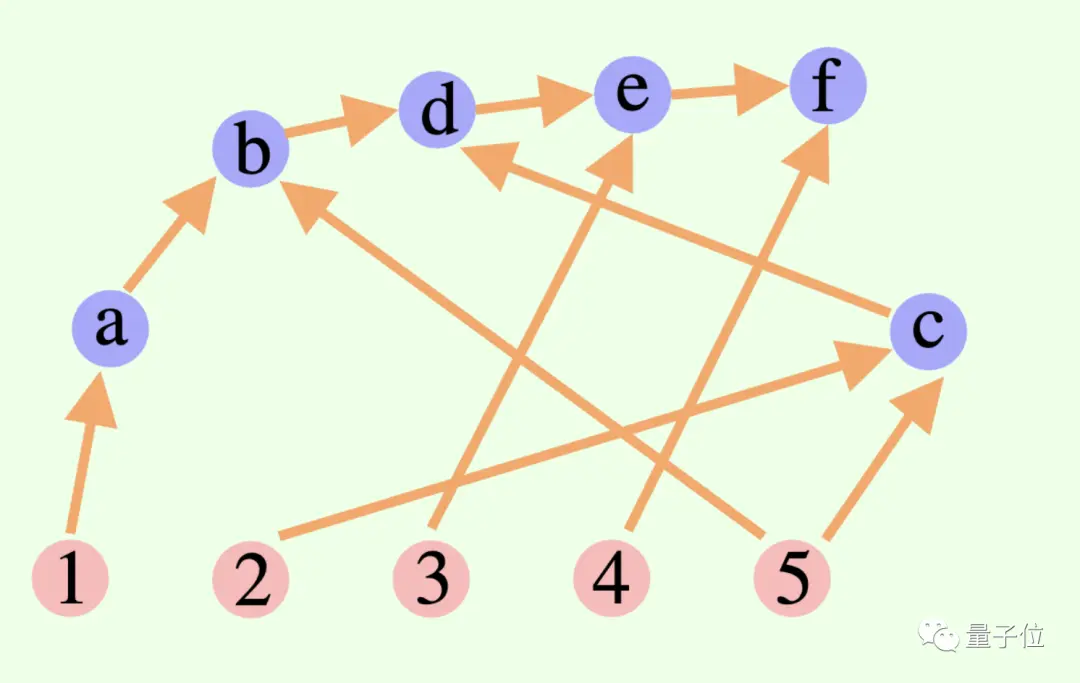 ****△**As arestas no gráfico têm direções e não há caminhos circulares; cada aresta direcionada é uma etapa de derivação
****△**As arestas no gráfico têm direções e não há caminhos circulares; cada aresta direcionada é uma etapa de derivação
Isso significa que ele pode armazenar todos os resultados de inferência historicamente corretos na memória para exploração no ramo de pesquisa atual. (Em contraste, uma árvore pensante não armazena informações de outros ramos)
Mas o raciocínio cumulativo também pode ser facilmente alternado com a cadeia de pensamento - desde que o “verificador” seja removido, é um modelo de cadeia de pensamento padrão.
O raciocínio cumulativo desenhado com base neste método tem alcançado bons resultados em diversos métodos.
Bom em matemática e raciocínio lógico
Os pesquisadores escolheram o wiki FOLIO e o AutoTNLI, jogo de 24 pontos e conjuntos de dados MATH para “testar” o raciocínio cumulativo.
O proponente, o verificador e o relator usam o mesmo modelo de linguagem ampla em cada experimento, com configurações diferentes para suas funções.
Os modelos básicos usados aqui para experimentos incluem GPT-3.5-turbo, GPT-4, LLaMA-13B e LLaMA-65B.
Vale ressaltar que, idealmente, o modelo deve ser especificamente pré-treinado usando dados relevantes da tarefa de derivação, e o "verificador" também deve adicionar um provador matemático formal, um módulo de resolução de lógica proposicional, etc.
1. Capacidade de raciocínio lógico
FOLIO é um conjunto de dados de raciocínio lógico de primeira ordem, e os rótulos das perguntas podem ser "verdadeiro", "Falso" e "Desconhecido"; AutoTNLI é um conjunto de dados de raciocínio lógico de alta ordem.
No conjunto de dados wiki FOLIO, em comparação com os métodos de resultados de saída direta (Direct), cadeia de pensamento (CoT) e cadeia de pensamento avançada (CoT-SC), o desempenho do raciocínio cumulativo (CR) é sempre o melhor.
Após a remoção de instâncias problemáticas (como respostas incorretas) do conjunto de dados, a precisão da inferência do GPT-4 usando o método CR atingiu 98,04%, com uma taxa de erro mínima de 1,96%.
Comparado com o método CoT, o CR melhorou significativamente o desempenho do LLaMA-13B e do LLaMA-65B.
No modelo LLaMA-65B, a melhoria do CR em relação ao CoT atingiu 9,3%.
O artigo ToT original usava um jogo de 24 pontos, então os pesquisadores aqui usaram esse conjunto de dados para comparar CR e ToT.
O ToT usa uma árvore de pesquisa de largura e profundidade fixas, e o CR permite que modelos grandes determinem a profundidade da pesquisa de forma autônoma.
Os pesquisadores descobriram em experimentos que, no contexto de 24 pontos, o algoritmo CR e o algoritmo ToT são muito semelhantes. A diferença é que o algoritmo em CR gera no máximo um novo estado por iteração, enquanto o ToT gera muitos estados candidatos em cada iteração, e filtra e retém alguns estados.
Em termos leigos, o ToT não possui o "verificador" mencionado acima como o CR e não pode julgar se os estados (a, b, c) estão corretos ou incorretos. Portanto, o ToT explorará mais estados inválidos do que o CR.
Em outras palavras, CR não só tem uma taxa de precisão de pesquisa mais alta, mas também tem uma eficiência de pesquisa mais alta.
O conjunto de dados MATH contém um grande número de questões de raciocínio matemático, incluindo álgebra, geometria, teoria dos números, etc. A dificuldade das questões é dividida em cinco níveis.
Usando o método CR, o modelo pode decompor a pergunta em subquestões que podem ser concluídas passo a passo, e fazer e responder perguntas até que a resposta seja gerada.
Os resultados experimentais mostram que sob duas configurações experimentais diferentes, a taxa de precisão do CR excede os métodos existentes atualmente, com uma taxa de precisão geral de até 58% e uma melhoria relativa da precisão de 42% no problema de Nível 5. Baixei o novo SOTA sob o modelo GPT-4.
Pesquisa liderada por Yao Qizhi e Yuan Yang da Universidade Tsinghua
Este artigo vem do grupo de pesquisa AI for Math liderado por Yao Qizhi e Yuan Yang do Instituto Tsinghua de Informação Interdisciplinar.
Os co-autores do artigo são Zhang Yifan e Yang Jingqin, estudantes de doutorado de 2021 no Instituto de Informação Interdisciplinar;
O instrutor e co-autor correspondente são o professor assistente Yuan Yang e o acadêmico Yao Qizhi.
Zhang Yifan
Zhang Yifan se formou no Yuanpei College da Universidade de Pequim em 2021. Atualmente está estudando com o professor assistente Yuan Yang. Suas principais direções de pesquisa são a teoria e algoritmo de modelos básicos (grandes modelos de linguagem), aprendizagem auto-supervisionada e inteligência artificial confiável.
Yang Jingqin
Yang Jingqin recebeu seu diploma de bacharel pelo Instituto de Informações Cruzadas da Universidade de Tsinghua em 2021 e atualmente está estudando para seu doutorado com o professor assistente Yuan Yang. As principais direções de pesquisa incluem grandes modelos de linguagem, aprendizagem auto-supervisionada, cuidados médicos inteligentes, etc.
Yuan Yang
Suas principais direções de pesquisa são cuidados médicos inteligentes, teoria básica de IA, teoria de categorias aplicadas, etc.
Yao Qizhi
O professor Yao Qizhi renunciou a Princeton como professor titular em 2004 e retornou a Tsinghua para lecionar; em 2005, fundou a "Classe Yao", uma aula experimental de ciência da computação para alunos de graduação de Tsinghua; em 2011, fundou o "Centro de Informações Quânticas de Tsinghua " e o "Instituto de Pesquisa de Informação Interdisciplinar"; em 2019 Em 2008, ele fundou uma aula de inteligência artificial para alunos de graduação de Tsinghua, conhecida como "Classe Inteligente".
Hoje, o Instituto de Informação Interdisciplinar da Universidade Tsinghua liderado por ele é famoso há muito tempo. Yao Class e Zhiban são afiliados ao Instituto de Informação Interdisciplinar.
Os interesses de pesquisa do Professor Yao Qizhi incluem algoritmos, criptografia, computação quântica, etc. Ele é um pioneiro internacional e autoridade neste campo. Recentemente, ele apareceu na Conferência Mundial de Inteligência Artificial de 2023. O Instituto de Pesquisa Shanghai Qizhi que ele lidera está atualmente estudando "inteligência artificial geral incorporada".
Link do papel: