O modelo de 7 bilhões de parâmetros que levou 500 dólares para "sintonizar" derrotou o parâmetro de 70 bilhões Llama 2!
E o notebook pode ser executado facilmente, e o efeito é comparável ao ChatGPT.
Importante: Grátis, sem dinheiro.
O modelo de código aberto Zephyr-7B criado pela equipe HuggingFace H4, shark crazy.
Seu modelo subjacente é um modelo grande de código aberto Mistral-7B, que explodiu há algum tempo e foi construído pela Mistral AI, que é conhecida como "European OpenAI".
Você sabe, menos de 2 semanas após o lançamento do Mistral-7B, várias versões ajustadas apareceram uma após a outra, e há muito estilo "alpaca" que rapidamente apareceu quando Llama foi lançado pela primeira vez.
A chave para a capacidade do Zephyr de se destacar entre as variantes foi que a equipe ajustou o modelo em um conjunto de dados público usando a Otimização de Preferência Direta (DPO) em cima do Mistral.
A equipe também descobriu que remover o alinhamento interno do conjunto de dados poderia melhorar ainda mais o desempenho do MT Bench. O Zephyr-7B-alpha original tinha uma pontuação média MT-Bench de 7,09, superando o Llama2-70B-Chat.
** **###### △MT-Bench é um teste de referência para avaliar a capacidade do modelo de lidar com várias rodadas de diálogo, e o conjunto de perguntas abrange 8 categorias, como escrita, interpretação de papéis e extração.
A questão é que, em seguida, passou a atualizar!
A equipa H4 lançou a segunda geração do Zephyr-7B-beta. Eles acrescentaram que exploraram a ideia de extrair o alinhamento do GPT-4, Claude 2 e depois injetá-lo em modelos pequenos, desenvolvendo um método para usar a otimização de preferência direta de destilação (dDPO) para modelos pequenos.
Na segunda geração do Zephyr, a pontuação média do MT-Bench aumentou para 7,34.
Em Alpaca, Zephyr tem uma taxa de vitória de 90,6%, o que é melhor do que ChatGPT (3,5):
Os internautas que correram para Zephyr deram elogios unânimes, e a equipe lmsys também mostrou a pontuação Elo de Zephyr-7b-beta, que subiu muito alto 🔥:
A tabela de classificação interna da Arena ultrapassou os modelos 13B.
Algumas pessoas até disseram:
Ver a abordagem DPO ter um bom desempenho no campo é provavelmente a coisa mais empolgante sobre o desenvolvimento de grandes modelos de linguagem este ano.
Mais internautas começaram a testar o efeito do Zephyr, e os resultados são surpreendentemente bons.
A palavra Mistral significa vento seco, frio e forte em francês, enquanto Zephyr significa vento suave e agradável de oeste.
Não há dúvida de que há um jardim zoológico do outro lado de Llama, e não há dúvida de que há um serviço meteorológico deste lado.
Melhor modelo 7B muda de mãos novamente
Vamos começar com os requisitos do computador para executar o Zephyr. Internautas disseram que "calças tailandesas são picantes" após o teste! , o notebook (Apple M1 Pro) é suficiente, "o resultado é muito bom".
Em termos de eficácia, a equipa do Llama Index (anteriormente conhecido como GPT Index) também o testou.
Acontece que o Zephyr é atualmente o único modelo 7B de código aberto que funciona bem em tarefas de alto nível de RAG/agentic.
Os dados também mostram que o efeito da tarefa RAG avançada de Zephyr pode competir com GPT-3.5 e Claude 2.
Eles acrescentaram que o Zephyr não só funciona bem em RAG, mas também em roteamento, planejamento de consultas, recuperação de instruções SQL complexas e extração de dados estruturados.
Os funcionários também deram resultados de testes e, no MT-Bench, o Zephyr-7B-beta tem um forte desempenho em comparação com modelos maiores, como o Llama2-Chat-70B.
Mas em tarefas mais complexas, como codificação e matemática, o Zephyr-7B-beta fica atrás de modelos proprietários e requer mais pesquisa para fechar a lacuna.
Abandone a Aprendizagem por Reforço
Enquanto todos estão testando os efeitos do Zephyr, os desenvolvedores dizem que o mais interessante não são as métricas, mas a maneira como o modelo é treinado.
Os destaques estão resumidos abaixo:
Ajuste o melhor modelo pequeno e pré-treinado de código aberto: Mistral 7B
Uso de conjuntos de dados de preferência em grande escala: UltraFeedback
Use a Otimização de Preferência Direta (DPO) em vez de aprendizagem por reforço
Inesperadamente, o sobreajuste do conjunto de dados de preferência produz melhores resultados
Em termos gerais, como mencionado no início, a principal razão pela qual Zephyr é capaz de superar o 70B Llama 2 é devido ao uso de um método especial de ajuste fino.
Ao contrário da abordagem tradicional de aprendizagem por reforço do PPO, a equipe de pesquisa usou uma colaboração recente entre a Universidade de Stanford e o CZ Biohub para propor uma abordagem de DPO.
De acordo com os pesquisadores:
DPO é muito mais estável do que o PPO.
Em termos simples, o EPD pode ser explicado da seguinte forma:
A fim de tornar o resultado do modelo mais alinhado com as preferências humanas, a abordagem tradicional tem sido ajustar o modelo alvo com um modelo de recompensa. Se o resultado for bom, você será recompensado, e se o resultado for ruim, você não será recompensado.
A abordagem DPO, por outro lado, ignora a função de recompensa de modelagem e é equivalente a otimizar o modelo diretamente nos dados de preferência.
Em geral, o DPO resolve o problema do treinamento de aprendizagem de reforço difícil e caro devido ao feedback humano.
Em termos de treinamento do Zephyr especificamente, a equipe de pesquisa inicialmente ajustou o Zephyr-7B-alpha em uma variante simplificada do conjunto de dados UltraChat, que contém 1,6 milhão de conversas geradas pelo ChatGPT (cerca de 200.000 restantes).
(A razão para a simplificação foi que a equipe descobriu que Zephyr às vezes era revestido incorretamente, como "Olá. como estás?"; Às vezes, a resposta começa com "Eu não tenho X pessoal". )
Mais tarde, alinharam ainda mais o modelo com o conjunto de dados openbmb/UltraFeedback disponível publicamente usando o método DPO Trainer do TRL.
O conjunto de dados contém 64.000 pares prompt-response de vários modelos. Cada resposta é classificada pelo GPT-4 com base em critérios como utilidade e recebe uma pontuação a partir da qual uma preferência de IA é derivada.
Uma descoberta interessante é que, ao usar o método DPO, o efeito é realmente melhor após o overfitting à medida que o tempo de treinamento aumenta. Os pesquisadores acreditam que isso é semelhante ao overfitting no SFT.
Vale a pena mencionar que a equipe de pesquisa também introduziu que ajustar o modelo com este método custa apenas US $ 500, o que é 8 horas de execução em 16 A100s.
Ao atualizar o Zephyr para beta, a equipe explicou sua abordagem.
Eles pensaram em ajuste fino supervisionado por destilação (dSFT) usado em modelos grandes, mas com essa abordagem o modelo estava desalinhado e não produzia resultados que correspondessem à intenção do usuário.
Assim, a equipe tentou usar dados de preferência do AI Feedback (AIF) para classificar as saídas com um "modelo de professor" para formar um conjunto de dados e, em seguida, aplicar a otimização de preferência direta de destilação (dDPO) para treinar um modelo alinhado com a intenção do usuário sem qualquer amostragem adicional durante o ajuste fino.
Os pesquisadores também testaram o efeito quando o SFT não foi usado, e os resultados resultaram em uma redução significativa no desempenho, indicando que a etapa dSFT é crítica.
Atualmente, além do modelo ter sido open source e comercial, há também uma demonstração para experimentar, para que possamos começar e experimentá-lo de forma simples.
Experiência de demonstração
Em primeiro lugar, tive de sair da questão dos "deficientes mentais" para fazer um teste.
Sobre a pergunta "Mamãe e papai não me levam quando se casam", a resposta geral de Zéfiro é mais precisa.
O ChatGPT não consegue vencer essa pergunta.
No teste, também descobrimos que Zephyr também sabe sobre eventos recentes, como o lançamento do GPT-4 pela OpenAI:
Na verdade, isto está relacionado com o seu modelo subjacente, embora o funcionário da Mistral não tenha especificado o prazo para os dados de formação.
Mas alguns internautas já testaram antes, e ele também sabe sobre ele em março deste ano.
Em contraste, os dados de pré-treinamento do Llama 2 são de setembro de 2022, e apenas alguns dados ajustados são até junho de 2023.
Além disso, Zephyr é muito responsivo, então você pode escrever código e criar histórias. :
Vale a pena mencionar que Zephyr é melhor em responder perguntas em inglês, e também tem um problema comum com o modelo de "alucinação".
Os pesquisadores também mencionaram alucinações, e uma pequena linha de texto foi marcada abaixo da caixa de entrada, indicando que o conteúdo gerado pelo modelo pode ser impreciso ou incorreto.
A questão é que o Zephyr não usa métodos como a aprendizagem por reforço com feedback humano para se alinhar com as preferências humanas, nem usa a filtragem de resposta do ChatGPT.
Escolha sempre um dos peixes emmm e patas de urso.
Zephyr foi capaz de fazer isso com apenas 70B parâmetros, o que surpreendeu Andriy Burkov, autor de "The 100-Page Machine Learning Book", e até disse:
Zephyr-7B derrota Llama 2-70B com um modelo base de Mistral-7B com uma janela de contexto de 8k tokens, que teoricamente tem uma faixa de atenção de até 128K tokens.
E se o Zephyr fosse um modelo 70B? Será que ele vai superar GPT-4? Parece provável.
Se você está interessado em Zephyr-7B, você pode experimentá-lo em huggingface.
Links do artigo:
Links de referência:
[1]
[2]
[3]
[4]
[5]
Ver original
Esta página pode conter conteúdo de terceiros, que é fornecido apenas para fins informativos (não para representações/garantias) e não deve ser considerada como um endosso de suas opiniões pela Gate nem como aconselhamento financeiro ou profissional. Consulte a Isenção de responsabilidade para obter detalhes.
O melhor modelo 7B muda de mãos novamente! Derrote 70 bilhões de LLaMA2, e computadores da Apple serão capazes de executar código aberto e gratuito
Fonte original: qubits
O modelo de 7 bilhões de parâmetros que levou 500 dólares para "sintonizar" derrotou o parâmetro de 70 bilhões Llama 2!
E o notebook pode ser executado facilmente, e o efeito é comparável ao ChatGPT.
Importante: Grátis, sem dinheiro.
O modelo de código aberto Zephyr-7B criado pela equipe HuggingFace H4, shark crazy.
A chave para a capacidade do Zephyr de se destacar entre as variantes foi que a equipe ajustou o modelo em um conjunto de dados público usando a Otimização de Preferência Direta (DPO) em cima do Mistral.
A equipe também descobriu que remover o alinhamento interno do conjunto de dados poderia melhorar ainda mais o desempenho do MT Bench. O Zephyr-7B-alpha original tinha uma pontuação média MT-Bench de 7,09, superando o Llama2-70B-Chat.
**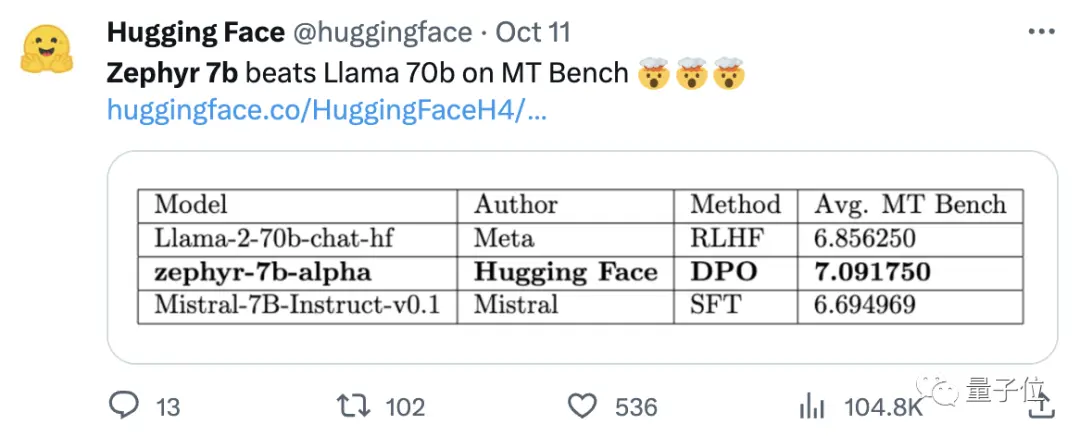 **###### △MT-Bench é um teste de referência para avaliar a capacidade do modelo de lidar com várias rodadas de diálogo, e o conjunto de perguntas abrange 8 categorias, como escrita, interpretação de papéis e extração.
**###### △MT-Bench é um teste de referência para avaliar a capacidade do modelo de lidar com várias rodadas de diálogo, e o conjunto de perguntas abrange 8 categorias, como escrita, interpretação de papéis e extração.
A questão é que, em seguida, passou a atualizar!
A equipa H4 lançou a segunda geração do Zephyr-7B-beta. Eles acrescentaram que exploraram a ideia de extrair o alinhamento do GPT-4, Claude 2 e depois injetá-lo em modelos pequenos, desenvolvendo um método para usar a otimização de preferência direta de destilação (dDPO) para modelos pequenos.
Na segunda geração do Zephyr, a pontuação média do MT-Bench aumentou para 7,34.
A palavra Mistral significa vento seco, frio e forte em francês, enquanto Zephyr significa vento suave e agradável de oeste.
Não há dúvida de que há um jardim zoológico do outro lado de Llama, e não há dúvida de que há um serviço meteorológico deste lado.
Melhor modelo 7B muda de mãos novamente
Vamos começar com os requisitos do computador para executar o Zephyr. Internautas disseram que "calças tailandesas são picantes" após o teste! , o notebook (Apple M1 Pro) é suficiente, "o resultado é muito bom".
Os dados também mostram que o efeito da tarefa RAG avançada de Zephyr pode competir com GPT-3.5 e Claude 2.
Eles acrescentaram que o Zephyr não só funciona bem em RAG, mas também em roteamento, planejamento de consultas, recuperação de instruções SQL complexas e extração de dados estruturados.
Abandone a Aprendizagem por Reforço
Enquanto todos estão testando os efeitos do Zephyr, os desenvolvedores dizem que o mais interessante não são as métricas, mas a maneira como o modelo é treinado.
Os destaques estão resumidos abaixo:
Em termos gerais, como mencionado no início, a principal razão pela qual Zephyr é capaz de superar o 70B Llama 2 é devido ao uso de um método especial de ajuste fino.
Ao contrário da abordagem tradicional de aprendizagem por reforço do PPO, a equipe de pesquisa usou uma colaboração recente entre a Universidade de Stanford e o CZ Biohub para propor uma abordagem de DPO.
Em termos simples, o EPD pode ser explicado da seguinte forma:
A fim de tornar o resultado do modelo mais alinhado com as preferências humanas, a abordagem tradicional tem sido ajustar o modelo alvo com um modelo de recompensa. Se o resultado for bom, você será recompensado, e se o resultado for ruim, você não será recompensado.
A abordagem DPO, por outro lado, ignora a função de recompensa de modelagem e é equivalente a otimizar o modelo diretamente nos dados de preferência.
Em geral, o DPO resolve o problema do treinamento de aprendizagem de reforço difícil e caro devido ao feedback humano.
Em termos de treinamento do Zephyr especificamente, a equipe de pesquisa inicialmente ajustou o Zephyr-7B-alpha em uma variante simplificada do conjunto de dados UltraChat, que contém 1,6 milhão de conversas geradas pelo ChatGPT (cerca de 200.000 restantes).
(A razão para a simplificação foi que a equipe descobriu que Zephyr às vezes era revestido incorretamente, como "Olá. como estás?"; Às vezes, a resposta começa com "Eu não tenho X pessoal". )
Mais tarde, alinharam ainda mais o modelo com o conjunto de dados openbmb/UltraFeedback disponível publicamente usando o método DPO Trainer do TRL.
O conjunto de dados contém 64.000 pares prompt-response de vários modelos. Cada resposta é classificada pelo GPT-4 com base em critérios como utilidade e recebe uma pontuação a partir da qual uma preferência de IA é derivada.
Uma descoberta interessante é que, ao usar o método DPO, o efeito é realmente melhor após o overfitting à medida que o tempo de treinamento aumenta. Os pesquisadores acreditam que isso é semelhante ao overfitting no SFT.
Eles pensaram em ajuste fino supervisionado por destilação (dSFT) usado em modelos grandes, mas com essa abordagem o modelo estava desalinhado e não produzia resultados que correspondessem à intenção do usuário.
Os pesquisadores também testaram o efeito quando o SFT não foi usado, e os resultados resultaram em uma redução significativa no desempenho, indicando que a etapa dSFT é crítica.
Experiência de demonstração
Em primeiro lugar, tive de sair da questão dos "deficientes mentais" para fazer um teste.
Sobre a pergunta "Mamãe e papai não me levam quando se casam", a resposta geral de Zéfiro é mais precisa.
Mas alguns internautas já testaram antes, e ele também sabe sobre ele em março deste ano.
Além disso, Zephyr é muito responsivo, então você pode escrever código e criar histórias. :
Os pesquisadores também mencionaram alucinações, e uma pequena linha de texto foi marcada abaixo da caixa de entrada, indicando que o conteúdo gerado pelo modelo pode ser impreciso ou incorreto.
Escolha sempre um dos peixes emmm e patas de urso.
Zephyr foi capaz de fazer isso com apenas 70B parâmetros, o que surpreendeu Andriy Burkov, autor de "The 100-Page Machine Learning Book", e até disse:
Links do artigo:
Links de referência:
[1]
[2]
[3]
[4]
[5]