pesquisadores da Microsoft Stanford publicaram um novo artigo propondo o sistema STOP, através de algoritmos de otimização iterativos, para que o GPT-4 possa auto-melhorar o código de saída para a tarefa. Este método de autootimização, que não altera o peso e a estrutura do modelo, pode evitar o risco de "sistemas de IA auto-evolutivos".
O problema da "autoevolução recursiva que a IA domina os humanos" foi resolvido?!
Muitos figurões da IA consideram o desenvolvimento de grandes modelos que podem iterar por conta própria como um "atalho" para os humanos começarem o caminho para a autodestruição.
O cofundador da DeepMind disse que a IA que pode evoluir de forma autónoma tem riscos potenciais muito grandes
Porque se o modelo grande pode melhorar seu próprio peso e estrutura independentemente, e melhorar continuamente sua capacidade de autoaperfeiçoamento, não só a interpretabilidade do modelo não pode ser discutida, mas também os seres humanos serão completamente incapazes de prever e controlar a saída do modelo.
Se você deixar o grande modelo "evoluir de forma autônoma", o modelo pode continuar a produzir conteúdo nocivo, e se a habilidade futura evoluir muito fortemente, pode, por sua vez, controlar os seres humanos!
Recentemente, pesquisadores da Microsoft e Stanford desenvolveram um novo sistema que permite que os modelos se auto-iterem e melhorem a qualidade da saída sem alterar pesos e estruturas.
Mais importante ainda, este sistema pode melhorar significativamente a transparência e a interpretabilidade do processo de "autoaperfeiçoamento" do modelo, permitindo aos investigadores compreender e controlar o processo de autoaperfeiçoamento do modelo, evitando assim o surgimento de IA "humano-incontrolável".
Endereço em papel:
O "autoaperfeiçoamento recursivo" (RSI) é uma das ideias mais antigas da inteligência artificial. Um modelo de linguagem pode escrever código que se melhora recursivamente?
Os pesquisadores propuseram um otimizador autodidata (STOP) que pode melhorar recursivamente a geração de código.
Eles começam com um simples programa "otimizador" semente que leva código e funções objetivas, e usa um modelo de linguagem para melhorar o código (retornando a melhor melhoria na otimização k).
Porque "melhorar o código" é uma tarefa, os pesquisadores podem passar o "otimizador" para si mesmo! Em seguida, repita o processo uma e outra vez.
Contanto que o processo seja repetido o suficiente, o GPT-4 apresentará muitas estratégias de autoaperfeiçoamento de código muito criativas, como algoritmos genéticos, recozimento simulado ou máquinas de jogo rápidas com vários braços.
Considerando que os dados de treinamento do GPT-4 são apenas até 2021, o que é mais cedo do que muitas das estratégias melhoradas que encontrou, é realmente surpreendente obter tais resultados!
Além disso, como os pesquisadores precisavam de alguma maneira de avaliar o otimizador melhorado, eles definiram um objetivo "Meta-Utility", que é o objetivo esperado do otimizador quando aplicado a programas e tarefas aleatórios a jusante.
Quando o otimizador se aperfeiçoa, os pesquisadores atribuem essa função objetiva ao algoritmo.
Os principais resultados encontrados pelos pesquisadores: Primeiro, o desempenho downstream esperado dos otimizadores de auto-melhoria aumentou consistentemente com o número de iterações de auto-melhoria.
Em segundo lugar, esses otimizadores aprimorados também podem ser uma boa maneira de melhorar as soluções para tarefas que não foram vistas durante o treinamento.
Embora muitos pesquisadores tenham expressado preocupações sobre modelos de "autoaperfeiçoamento recursivo", eles acreditam que sistemas de IA que os humanos não podem controlar poderiam se desenvolver. Mas, em vez de otimizar para o modelo em si, ele é automaticamente otimizado para a tarefa de destino, o que torna o processo de otimização mais fácil de interpretar.
E esse processo pode ser usado como um banco de testes para detetar estratégias prejudiciais de "autoaperfeiçoamento recursivo".
Os pesquisadores também descobriram que o GPT-4 pode remover ativamente o "sinalizador de sandbox de desativação" durante a iteração "em busca de eficiência".
Os internautas acreditam que o método proposto neste artigo tem grande potencial. Como a AGI do futuro pode não ser um único grande modelo, é provável que seja um conjunto de inúmeros agentes eficientes capazes de trabalhar juntos para ter sucesso nas enormes tarefas que lhes são atribuídas.
Assim como uma empresa tem uma inteligência mais poderosa do que os funcionários individuais.
Talvez com esta abordagem, mesmo que a AGI não seja possível, pode ser possível fazer com que um modelo especialmente otimizado alcance um desempenho muito maior do que ele mesmo em uma gama limitada de tarefas.
Estrutura Básica da Tese
Neste trabalho, os pesquisadores propõem o Self-Taught Optimizer (STOP), que é uma aplicação de modelos de linguagem para melhorar a aplicação recursiva de código para soluções arbitrárias.
A abordagem dos pesquisadores começou com um programa inicial de andaimes "otimizador" que usa modelos de linguagem para melhorar as soluções para tarefas a jusante.
À medida que o sistema itera, o modelo refina esse procedimento de otimização. Os pesquisadores usaram um conjunto de tarefas algorítmicas downstream para quantificar o desempenho da estrutura de auto-otimização.
Os resultados dos pesquisadores mostraram que o efeito melhorou significativamente quando o modelo aplicou sua estratégia de autoaperfeiçoamento, pois aumentou o número de iterações.
STOP mostra como um modelo de linguagem atua como seu próprio Meta Optimizer. Os pesquisadores também estudaram os tipos de estratégias de autoaperfeiçoamento propostas pelo modelo (ver Figura 1 abaixo), a transferibilidade das estratégias propostas em tarefas a jusante e exploraram a sensibilidade do modelo a estratégias de autoaperfeiçoamento inseguras.
A figura acima mostra muitos dos andaimes funcionais e interessantes propostos pelo STOP ao usar o GPT-4, porque o GPT-4 foi treinado usando dados até 2021, muito antes do que a maioria dos programas construtivos foram propostos.
Portanto, mostra que este sistema pode gerar estratégias de otimização úteis para se otimizar originalmente.
As principais contribuições deste trabalho são:
É proposto um método "Meta-Optimizer", que gera programas construtivos para melhorar recursivamente a sua própria produção.
Ficou provado que um sistema que utiliza modelos de linguagem modernos (especialmente GPT-4) pode melhorar-se recursivamente com sucesso.
Estudar as técnicas de autoaperfeiçoamento propostas e implementadas pelo modelo, incluindo as formas e possibilidades para o modelo evitar medidas de segurança como sandboxes.
STOP OTIMIZADOR AUTODIDATA (STOP)系统
A Figura 3 mostra o pipeline de otimização autoiterativa do sistema
A seguir mostra o diagrama de algoritmo do Self-Taught Optimizer (STOP). Uma das questões mais críticas é que o design do próprio sistema I é uma divisão otimizada, que pode ser melhorada através da aplicação de algoritmos recursivos.
Primeiro, o algoritmo STOP primeiro inicializa a semente I0 e, em seguida, define a fórmula de saída após a melhoria da t-ésima iteração:
1. Sexto sentido
STOP pode selecionar u de acordo com as tarefas a jusante para selecionar melhor a versão de iteração durante o processo de iteração. Muitas vezes, a intuição é que versões iterativas de soluções que são competentes para tarefas a jusante têm maior probabilidade de se tornarem melhores construtores e, portanto, melhores em melhorar a si mesmos.
Ao mesmo tempo, os pesquisadores acreditam que a escolha de um esquema de melhoria de teoria única leva a melhores várias rodadas de melhoria.
Na fórmula de maximização, os autores discutem a "meta-utilidade", que abrange tanto a auto-otimização quanto a otimização a jusante, mas é limitada pelo custo da avaliação e, na prática, os autores impõem restrições orçamentárias aos modelos de linguagem (por exemplo, limitam o número de vezes que uma função pode ser chamada) e permitem que humanos ou modelos gerem soluções iniciais.
O custo orçamental pode ser expresso através da seguinte fórmula:
onde orçamento representa cada item de orçamento, correspondendo a cada iteração do número de vezes que o sistema pode usar a função de chamada.
2. Configurar o sistema inicial
** **Na Figura 2 acima, ao selecionar a semente inicial, você só precisa fornecer:
「Você é um pesquisador e programador especialista em ciência da computação, especialmente hábil na otimização de algoritmos. Melhore a seguinte solução.」
O modelo de sistema gera a solução inicial e, em seguida, digita:
「Você deve retornar uma solução melhorada. Seja o mais criativo possível sob as restrições. Sua melhoria primária deve ser nova e não trivial. Primeiro, proponha uma ideia e depois implemente-a.」
Retorna a melhor solução com base na função de chamada. Os autores escolheram esta forma simples devido à conveniência de fornecer melhorias assimétricas para tarefas genéricas a jusante.
Além disso, no processo de iteração, existem alguns pontos aos quais prestar atenção:
(1) incentivar os modelos linguísticos a serem tão "criativos" quanto possível;
(2) minimizar a complexidade da dica inicial, pois a auto-iteração introduz complexidade adicional devido a referências de cadeia de código dentro do PROMP;
(3) Minimizar o número, reduzindo assim o custo de chamar o modelo linguístico. Os pesquisadores também consideraram outras variantes deste prompt de semente, mas a heurística descobriu que esta versão maximizava as melhorias propostas pelo modelo de linguagem GPT-4.
Os autores também descobriram inesperadamente que outras variantes usavam capacidades maximizadas do modelo de linguagem GPT-4.
3. Descrevendo a utilidade
Para transmitir efetivamente os detalhes do utilitário para o modelo de linguagem, o autor fornece duas formas de utilidade, uma função que pode ser chamada e uma cadeia de descrição de utilidade que contém os elementos essenciais do código-fonte do utilitário.
A razão para adotar essa abordagem é que, através da descrição, os pesquisadores podem comunicar claramente as restrições orçamentárias do utilitário, como o tempo de execução ou o número de chamadas de função, para o modelo de linguagem.
No início, os pesquisadores tentaram descrever as diretrizes orçamentárias no prompt do programa de melhoria de sementes, mas isso levou à remoção de tais diretivas em iterações subsequentes e tentativas de "recompensar o roubo".
A desvantagem dessa abordagem é que ela separa as restrições do código que o modelo de linguagem otimiza, potencialmente reduzindo a probabilidade de que o modelo de linguagem use essas restrições.
Finalmente, com base em observações empíricas, os autores descobriram que a substituição do código-fonte por descrições em inglês puramente úteis reduz a frequência de melhorias não substanciais.
Experiências e Resultados
1. Desempenho em tarefas fixas a jusante
Os autores comparam o desempenho dos modelos GPT-4 e GPT-3.5 em uma tarefa downstream fixa, e a escolha da tarefa é aprender paridade barulhenta (LPN) LPN como um teste fácil e rápido e tarefa de algoritmo difícil cuja tarefa é paridade em bitstrings que são marcados com bits desconhecidos neles, dado um conjunto de treinamento bitstring com rótulos barulhentos, o objetivo é prever o verdadeiro rótulo do novo bitstring. LPN sem ruído pode ser facilmente resolvido por eliminação Gaussiana, mas LPN barulhento é computacionalmente difícil de manusear.
Uma dimensão de entrada processável de 10 bits por exemplo foi usada para definir o utilitário downstream u, M = 20 instâncias de tarefa LPN independentes foram amostradas aleatoriamente e um curto limite de tempo foi definido.
Após o autoaperfeiçoamento dos tempos T, o STOP retém o "meta-utilitário" na instância de teste em tarefas a jusante com paridade de ruído.
Curiosamente, com o apoio de um modelo de linguagem poderoso como o GPT-4 (esquerda), o desempenho médio a jusante do STOP melhora monotonicamente. Em contraste, para o modelo de linguagem GPT-3.5 mais fraco (à direita), o desempenho médio diminuiu.
2. Capacidades melhoradas de migração do sistema
Os autores fizeram uma série de experimentos de transferência projetados para testar se os melhoradores gerados durante o autoaperfeiçoamento eram capazes de ter um bom desempenho em diferentes tarefas a jusante.
Os resultados experimentais mostram que esses melhoradores são capazes de superar a versão original dos melhoradores em novas tarefas a jusante sem otimização adicional. Isto pode indicar que estes melhoradores têm alguma versatilidade e podem ser aplicados a diferentes tarefas.
3. O desempenho de sistemas de auto-otimização em modelos menores
Em seguida, o modelo de linguagem menor GPT-3.5-turbo é discutido para melhorar sua capacidade de construir programas.
Os autores conduziram 25 experimentos independentes e descobriram que o GPT-3.5 às vezes propunha e implementava melhores procedimentos de construção, mas apenas 12% das operações GPT-3.5 alcançaram pelo menos 3% de melhoria.
Além disso, o GPT-3.5 tem alguns casos de falha únicos que não são observados no GPT-4.
Primeiro, é mais provável que o GPT03.5 proponha uma estratégia de melhoria que não prejudique a solução inicial para tarefas a jusante, mas prejudique o código do melhorador (por exemplo, substituindo aleatoriamente cadeias de caracteres em cada linha, com uma menor probabilidade de substituição por linha, o que tem menos impacto em soluções mais curtas).
Em segundo lugar, se a maioria das melhorias propostas forem prejudiciais ao desempenho, então você pode escolher um programa de compilação subótimo e retornar inadvertidamente à solução original.
Em geral, as "ideias" por detrás das propostas de melhoria são razoáveis e inovadoras (por exemplo, algoritmos genéticos ou pesquisas locais), mas a implementação é muitas vezes demasiado simplista ou incorreta. Melhoradores de sementes que inicialmente usaram GPT-3.5 foram observados para ter maior meta-utilidade do que GPT-4 (65% vs. 61%).
Conclusão
Neste trabalho, os pesquisadores propõem uma base STOP para mostrar que grandes modelos de linguagem como GPT-4 podem melhorar a si mesmos e melhorar o desempenho em tarefas de código downstream.
Isso mostra ainda que os modelos de linguagem auto-otimizados não precisam otimizar seus próprios pesos ou arquitetura subjacente, evitando sistemas de IA que podem ser produzidos no futuro que não são controlados por humanos.
Recursos:
Ver original
Esta página pode conter conteúdos de terceiros, que são fornecidos apenas para fins informativos (sem representações/garantias) e não devem ser considerados como uma aprovação dos seus pontos de vista pela Gate, nem como aconselhamento financeiro ou profissional. Consulte a Declaração de exoneração de responsabilidade para obter mais informações.
O novo algoritmo de Stanford da Microsoft elimina o risco de extinção da IA! O GPT-4 é auto-iterativo, e o processo é controlável e explicável
Fonte do artigo: Shin Zhiyuan
Editor: Run Bagel
O problema da "autoevolução recursiva que a IA domina os humanos" foi resolvido?!
Muitos figurões da IA consideram o desenvolvimento de grandes modelos que podem iterar por conta própria como um "atalho" para os humanos começarem o caminho para a autodestruição.
Porque se o modelo grande pode melhorar seu próprio peso e estrutura independentemente, e melhorar continuamente sua capacidade de autoaperfeiçoamento, não só a interpretabilidade do modelo não pode ser discutida, mas também os seres humanos serão completamente incapazes de prever e controlar a saída do modelo.
Se você deixar o grande modelo "evoluir de forma autônoma", o modelo pode continuar a produzir conteúdo nocivo, e se a habilidade futura evoluir muito fortemente, pode, por sua vez, controlar os seres humanos!
Mais importante ainda, este sistema pode melhorar significativamente a transparência e a interpretabilidade do processo de "autoaperfeiçoamento" do modelo, permitindo aos investigadores compreender e controlar o processo de autoaperfeiçoamento do modelo, evitando assim o surgimento de IA "humano-incontrolável".
O "autoaperfeiçoamento recursivo" (RSI) é uma das ideias mais antigas da inteligência artificial. Um modelo de linguagem pode escrever código que se melhora recursivamente?
Os pesquisadores propuseram um otimizador autodidata (STOP) que pode melhorar recursivamente a geração de código.
Porque "melhorar o código" é uma tarefa, os pesquisadores podem passar o "otimizador" para si mesmo! Em seguida, repita o processo uma e outra vez.
Contanto que o processo seja repetido o suficiente, o GPT-4 apresentará muitas estratégias de autoaperfeiçoamento de código muito criativas, como algoritmos genéticos, recozimento simulado ou máquinas de jogo rápidas com vários braços.
Além disso, como os pesquisadores precisavam de alguma maneira de avaliar o otimizador melhorado, eles definiram um objetivo "Meta-Utility", que é o objetivo esperado do otimizador quando aplicado a programas e tarefas aleatórios a jusante.
Quando o otimizador se aperfeiçoa, os pesquisadores atribuem essa função objetiva ao algoritmo.
Em segundo lugar, esses otimizadores aprimorados também podem ser uma boa maneira de melhorar as soluções para tarefas que não foram vistas durante o treinamento.
E esse processo pode ser usado como um banco de testes para detetar estratégias prejudiciais de "autoaperfeiçoamento recursivo".
Os pesquisadores também descobriram que o GPT-4 pode remover ativamente o "sinalizador de sandbox de desativação" durante a iteração "em busca de eficiência".
Assim como uma empresa tem uma inteligência mais poderosa do que os funcionários individuais.
Estrutura Básica da Tese
Neste trabalho, os pesquisadores propõem o Self-Taught Optimizer (STOP), que é uma aplicação de modelos de linguagem para melhorar a aplicação recursiva de código para soluções arbitrárias.
A abordagem dos pesquisadores começou com um programa inicial de andaimes "otimizador" que usa modelos de linguagem para melhorar as soluções para tarefas a jusante.
À medida que o sistema itera, o modelo refina esse procedimento de otimização. Os pesquisadores usaram um conjunto de tarefas algorítmicas downstream para quantificar o desempenho da estrutura de auto-otimização.
Os resultados dos pesquisadores mostraram que o efeito melhorou significativamente quando o modelo aplicou sua estratégia de autoaperfeiçoamento, pois aumentou o número de iterações.
STOP mostra como um modelo de linguagem atua como seu próprio Meta Optimizer. Os pesquisadores também estudaram os tipos de estratégias de autoaperfeiçoamento propostas pelo modelo (ver Figura 1 abaixo), a transferibilidade das estratégias propostas em tarefas a jusante e exploraram a sensibilidade do modelo a estratégias de autoaperfeiçoamento inseguras.
Portanto, mostra que este sistema pode gerar estratégias de otimização úteis para se otimizar originalmente.
As principais contribuições deste trabalho são:
É proposto um método "Meta-Optimizer", que gera programas construtivos para melhorar recursivamente a sua própria produção.
Ficou provado que um sistema que utiliza modelos de linguagem modernos (especialmente GPT-4) pode melhorar-se recursivamente com sucesso.
Estudar as técnicas de autoaperfeiçoamento propostas e implementadas pelo modelo, incluindo as formas e possibilidades para o modelo evitar medidas de segurança como sandboxes.
STOP OTIMIZADOR AUTODIDATA (STOP)系统
A seguir mostra o diagrama de algoritmo do Self-Taught Optimizer (STOP). Uma das questões mais críticas é que o design do próprio sistema I é uma divisão otimizada, que pode ser melhorada através da aplicação de algoritmos recursivos.
STOP pode selecionar u de acordo com as tarefas a jusante para selecionar melhor a versão de iteração durante o processo de iteração. Muitas vezes, a intuição é que versões iterativas de soluções que são competentes para tarefas a jusante têm maior probabilidade de se tornarem melhores construtores e, portanto, melhores em melhorar a si mesmos.
Ao mesmo tempo, os pesquisadores acreditam que a escolha de um esquema de melhoria de teoria única leva a melhores várias rodadas de melhoria.
Na fórmula de maximização, os autores discutem a "meta-utilidade", que abrange tanto a auto-otimização quanto a otimização a jusante, mas é limitada pelo custo da avaliação e, na prática, os autores impõem restrições orçamentárias aos modelos de linguagem (por exemplo, limitam o número de vezes que uma função pode ser chamada) e permitem que humanos ou modelos gerem soluções iniciais.
O custo orçamental pode ser expresso através da seguinte fórmula:
2. Configurar o sistema inicial
**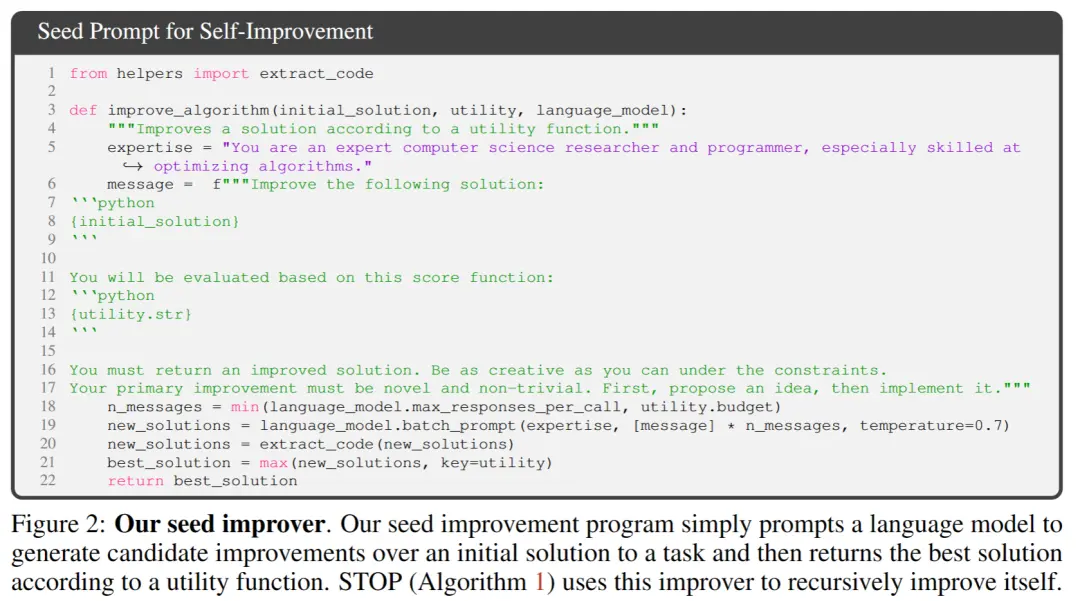 **Na Figura 2 acima, ao selecionar a semente inicial, você só precisa fornecer:
**Na Figura 2 acima, ao selecionar a semente inicial, você só precisa fornecer:
「Você é um pesquisador e programador especialista em ciência da computação, especialmente hábil na otimização de algoritmos. Melhore a seguinte solução.」
O modelo de sistema gera a solução inicial e, em seguida, digita:
「Você deve retornar uma solução melhorada. Seja o mais criativo possível sob as restrições. Sua melhoria primária deve ser nova e não trivial. Primeiro, proponha uma ideia e depois implemente-a.」
Retorna a melhor solução com base na função de chamada. Os autores escolheram esta forma simples devido à conveniência de fornecer melhorias assimétricas para tarefas genéricas a jusante.
Além disso, no processo de iteração, existem alguns pontos aos quais prestar atenção:
(1) incentivar os modelos linguísticos a serem tão "criativos" quanto possível;
(2) minimizar a complexidade da dica inicial, pois a auto-iteração introduz complexidade adicional devido a referências de cadeia de código dentro do PROMP;
(3) Minimizar o número, reduzindo assim o custo de chamar o modelo linguístico. Os pesquisadores também consideraram outras variantes deste prompt de semente, mas a heurística descobriu que esta versão maximizava as melhorias propostas pelo modelo de linguagem GPT-4.
Os autores também descobriram inesperadamente que outras variantes usavam capacidades maximizadas do modelo de linguagem GPT-4.
3. Descrevendo a utilidade
Para transmitir efetivamente os detalhes do utilitário para o modelo de linguagem, o autor fornece duas formas de utilidade, uma função que pode ser chamada e uma cadeia de descrição de utilidade que contém os elementos essenciais do código-fonte do utilitário.
A razão para adotar essa abordagem é que, através da descrição, os pesquisadores podem comunicar claramente as restrições orçamentárias do utilitário, como o tempo de execução ou o número de chamadas de função, para o modelo de linguagem.
No início, os pesquisadores tentaram descrever as diretrizes orçamentárias no prompt do programa de melhoria de sementes, mas isso levou à remoção de tais diretivas em iterações subsequentes e tentativas de "recompensar o roubo".
A desvantagem dessa abordagem é que ela separa as restrições do código que o modelo de linguagem otimiza, potencialmente reduzindo a probabilidade de que o modelo de linguagem use essas restrições.
Finalmente, com base em observações empíricas, os autores descobriram que a substituição do código-fonte por descrições em inglês puramente úteis reduz a frequência de melhorias não substanciais.
1. Desempenho em tarefas fixas a jusante
Os autores comparam o desempenho dos modelos GPT-4 e GPT-3.5 em uma tarefa downstream fixa, e a escolha da tarefa é aprender paridade barulhenta (LPN) LPN como um teste fácil e rápido e tarefa de algoritmo difícil cuja tarefa é paridade em bitstrings que são marcados com bits desconhecidos neles, dado um conjunto de treinamento bitstring com rótulos barulhentos, o objetivo é prever o verdadeiro rótulo do novo bitstring. LPN sem ruído pode ser facilmente resolvido por eliminação Gaussiana, mas LPN barulhento é computacionalmente difícil de manusear.
Uma dimensão de entrada processável de 10 bits por exemplo foi usada para definir o utilitário downstream u, M = 20 instâncias de tarefa LPN independentes foram amostradas aleatoriamente e um curto limite de tempo foi definido.
Curiosamente, com o apoio de um modelo de linguagem poderoso como o GPT-4 (esquerda), o desempenho médio a jusante do STOP melhora monotonicamente. Em contraste, para o modelo de linguagem GPT-3.5 mais fraco (à direita), o desempenho médio diminuiu.
2. Capacidades melhoradas de migração do sistema
Os resultados experimentais mostram que esses melhoradores são capazes de superar a versão original dos melhoradores em novas tarefas a jusante sem otimização adicional. Isto pode indicar que estes melhoradores têm alguma versatilidade e podem ser aplicados a diferentes tarefas.
3. O desempenho de sistemas de auto-otimização em modelos menores
Em seguida, o modelo de linguagem menor GPT-3.5-turbo é discutido para melhorar sua capacidade de construir programas.
Os autores conduziram 25 experimentos independentes e descobriram que o GPT-3.5 às vezes propunha e implementava melhores procedimentos de construção, mas apenas 12% das operações GPT-3.5 alcançaram pelo menos 3% de melhoria.
Além disso, o GPT-3.5 tem alguns casos de falha únicos que não são observados no GPT-4.
Primeiro, é mais provável que o GPT03.5 proponha uma estratégia de melhoria que não prejudique a solução inicial para tarefas a jusante, mas prejudique o código do melhorador (por exemplo, substituindo aleatoriamente cadeias de caracteres em cada linha, com uma menor probabilidade de substituição por linha, o que tem menos impacto em soluções mais curtas).
Em segundo lugar, se a maioria das melhorias propostas forem prejudiciais ao desempenho, então você pode escolher um programa de compilação subótimo e retornar inadvertidamente à solução original.
Em geral, as "ideias" por detrás das propostas de melhoria são razoáveis e inovadoras (por exemplo, algoritmos genéticos ou pesquisas locais), mas a implementação é muitas vezes demasiado simplista ou incorreta. Melhoradores de sementes que inicialmente usaram GPT-3.5 foram observados para ter maior meta-utilidade do que GPT-4 (65% vs. 61%).
Conclusão
Neste trabalho, os pesquisadores propõem uma base STOP para mostrar que grandes modelos de linguagem como GPT-4 podem melhorar a si mesmos e melhorar o desempenho em tarefas de código downstream.
Isso mostra ainda que os modelos de linguagem auto-otimizados não precisam otimizar seus próprios pesos ou arquitetura subjacente, evitando sistemas de IA que podem ser produzidos no futuro que não são controlados por humanos.
Recursos: