Agora, o grande modelo também aprendeu a "comer uma trincheira e cultivar uma sabedoria".
Uma nova pesquisa da Universidade de Ciência e Tecnologia de Hong Kong e do Laboratório da Arca de Noé da Huawei descobriu:
Em vez de evitar cegamente dados "tóxicos", combater o veneno com veneno, simplesmente alimentar o modelo grande com algum texto errado e, em seguida, deixar o modelo analisar e refletir sobre as razões do erro, pode fazer com que o modelo realmente entenda "o que está errado", e então evitar bobagens.
Especificamente, os pesquisadores propuseram uma estrutura de alinhamento de "aprender com os erros" e provaram através de experimentos:
Permitir que modelos grandes "comam uma trincheira e se tornem mais sábios" supera os métodos SFT e RLHF na correção de modelos desalinhados, e também tem uma vantagem na defesa contra ataques de instrução avançada em modelos alinhados.
Vamos dar uma olhada nos detalhes.
Quadro de alinhamento para aprender com os erros
Os algoritmos de alinhamento de modelos de linguagem grandes existentes são divididos principalmente em duas categorias:
Ajuste fino supervisionado (SFT)
Aprendizagem por Reforço para o Feedback Humano (RLHF)
O método SFT baseia-se principalmente em um grande número de pares de perguntas e respostas anotados por humanos, a fim de fazer com que o modelo aprenda "respostas perfeitas". No entanto, a desvantagem é que é difícil para o modelo obter o reconhecimento de "respostas ruins" a partir desse método, o que pode limitar sua capacidade de generalização.
O método RLHF treina o modelo pontuando as respostas por um anotador humano, para que ele possa distinguir a qualidade relativa das respostas. Neste modo, os modelos aprendem a distinguir entre respostas altas e baixas, mas têm pouca compreensão das "boas causas" e "más causas" por trás delas.
No geral, esses algoritmos de alinhamento estão obcecados em fazer com que o modelo aprenda "boas respostas", mas perdem uma parte importante do processo de limpeza de dados: aprender com os erros.
Podemos fazer grandes modelos como os humanos, "comer uma trincheira, crescer mais sábio", ou seja, projetar um método de alinhamento para que grandes modelos possam aprender com os erros sem serem afetados por sequências de texto contendo erros?
△ Quadro de alinhamento de modelos linguísticos de grande dimensão "Learning from Mistakes", que consiste em 4 passos, a saber: (1) indução de erros, (2) análise de erros baseada em orientação imediata, (3) ajuste fino do modelo sem orientação e (4) geração de resposta com base em orientação imediata
Uma equipa de investigação da Universidade de Ciência e Tecnologia de Hong Kong e do Laboratório da Arca de Noé da Huawei realizou uma experiência.
Através da análise experimental de três modelos, Alpaca-7B, GPT-3 e GPT-3.5, chegaram a uma conclusão interessante:
Para esses modelos, muitas vezes é mais fácil identificar respostas incorretas do que evitá-las ao gerar respostas.
** △ A discriminação é mais fácil do que a geração
Além disso, o experimento revelou ainda que a precisão do modelo na identificação de erros pode ser significativamente melhorada fornecendo informações de orientação apropriadas, como sugerir que pode haver erros nas respostas.
Com base nessas descobertas, a equipe de pesquisa projetou uma nova estrutura de alinhamento que usa a capacidade do modelo de discriminar erros para otimizar sua capacidade generativa.
O processo de alinhamento tem esta aparência:
(1) Indução de erros
O objetivo desta etapa é induzir erros no modelo e descobrir as fraquezas do modelo para que os erros possam ser analisados e corrigidos posteriormente.
Esses casos de erro podem vir de dados de anotação existentes ou de erros descobertos pelos usuários na operação real do modelo.
O estudo descobriu que, através de simples incentivos de ataque de equipe vermelha, como a adição de certas palavras-chave indutoras (como "antiético" e "ofensivo") às instruções do modelo, como mostrado na Figura (a) abaixo, o modelo tende a produzir um grande número de respostas inadequadas.
(2) Análise de erros com base em orientações imediatas
Quando pares de pergunta-resposta suficientes contendo erros são coletados, o método passa para a segunda etapa, que é orientar o modelo a realizar uma análise aprofundada desses pares pergunta-resposta.
Especificamente, o estudo pediu ao modelo que explicasse por que essas respostas podem ser incorretas ou antiéticas.
Como mostrado na Figura (b) abaixo, o modelo pode muitas vezes fornecer uma explicação razoável, fornecendo orientação analítica explícita para o modelo, como perguntar "por que essa resposta pode estar errada".
(3) Ajuste fino do modelo não guiado
Depois de coletar um grande número de pares de erro pergunta-resposta e sua análise, o estudo usou os dados para ajustar ainda mais o modelo. Além dos pares de perguntas e respostas que contêm erros, pares normais de perguntas e respostas rotulados por humanos também são adicionados como dados de treinamento.
Como mostra a Figura (c) abaixo, nesta etapa, o estudo não deu ao modelo nenhuma dica direta sobre se as respostas continham erros. O objetivo é incentivar o modelo a pensar, avaliar e entender por si mesmo o que deu errado.
(4) Geração de respostas guiadas por prompt
A fase de inferência usa uma estratégia de geração de resposta baseada em orientação que explicitamente solicita que o modelo produza respostas "corretas, éticas e não ofensivas", garantindo assim que o modelo siga as normas éticas e não seja afetado por sequências de texto incorretas.
Ou seja, no processo de inferência, o modelo realiza a geração condicional com base em orientação generativa que está alinhada com os valores humanos, de modo a produzir saídas apropriadas.
△ "Aprenda com os erros" Exemplo de instrução de estrutura de alinhamento de modelo de linguagem grande
A estrutura de alinhamento acima não requer anotação humana e o envolvimento de modelos externos (como modelos de recompensa), que facilitam sua geração analisando erros usando sua capacidade de identificar erros.
Desta forma, "aprender com os erros" pode identificar com precisão os riscos potenciais nas instruções de utilização e responder com uma precisão razoável:
Resultados Experimentais
A equipa de investigação realizou experiências em dois cenários de aplicação prática para verificar os efeitos práticos do novo método.
Cenário 1: Modelo de linguagem grande não alinhado
Tomando como linha de base o modelo Alpaca-7B, o conjunto de dados PKU-SafeRLHF Dataset foi usado para experimentos, e a análise de comparação foi realizada com métodos de alinhamento múltiplo.
Os resultados do experimento são mostrados na tabela abaixo:
Quando a utilidade do modelo é mantida, o algoritmo de alinhamento "aprender com o erro" melhora a taxa de passagem segura em aproximadamente 10% em comparação com SFT, COH e RLHF, e em 21,6% em comparação com o modelo original.
Ao mesmo tempo, o estudo descobriu que os erros gerados pelo próprio modelo mostraram melhor alinhamento do que os pares de perguntas e respostas de outras fontes de dados.
△Resultados experimentais de grandes modelos linguísticos não alinhados
Cenário 2: Modelos alinhados enfrentam novos ataques de instrução
A equipe de pesquisa explorou ainda como fortalecer o modelo já alinhado para lidar com os padrões emergentes de ataque de instrução.
Aqui, o ChatGLM-6B foi selecionado como modelo de linha de base. O ChatGLM-6B foi alinhado com segurança, mas ainda pode produzir resultados que não estão em conformidade com os valores humanos quando confrontados com ataques de comando específicos.
Os pesquisadores usaram o padrão de ataque de "sequestro de alvo" como exemplo e usaram 500 dados contendo esse padrão de ataque para ajustar o experimento. Como mostrado na tabela abaixo, o algoritmo de alinhamento "aprender com os erros" mostra forte defensividade diante de novos ataques de instrução: mesmo com apenas um pequeno número de novos dados de amostra de ataque, o modelo mantém com sucesso as capacidades gerais e alcança uma melhoria de 16,9% na defesa contra novos ataques (sequestro de alvo).
Os experimentos provam ainda que a capacidade de defesa obtida através da estratégia "aprender com os erros" não só é eficaz, mas também tem forte generalização, que pode lidar com uma ampla gama de tópicos diferentes no mesmo modo de ataque.
△Modelos alinhados defendem contra novos tipos de ataques
Links do artigo:
Ver original
Esta página pode conter conteúdos de terceiros, que são fornecidos apenas para fins informativos (sem representações/garantias) e não devem ser considerados como uma aprovação dos seus pontos de vista pela Gate, nem como aconselhamento financeiro ou profissional. Consulte a Declaração de exoneração de responsabilidade para obter mais informações.
Comendo dados "tóxicos", o grande modelo é mais obediente! Do HKUST & Huawei Noah's Ark Laboratory
Fonte: Qubits
Uma nova pesquisa da Universidade de Ciência e Tecnologia de Hong Kong e do Laboratório da Arca de Noé da Huawei descobriu:
Em vez de evitar cegamente dados "tóxicos", combater o veneno com veneno, simplesmente alimentar o modelo grande com algum texto errado e, em seguida, deixar o modelo analisar e refletir sobre as razões do erro, pode fazer com que o modelo realmente entenda "o que está errado", e então evitar bobagens.
Vamos dar uma olhada nos detalhes.
Quadro de alinhamento para aprender com os erros
Os algoritmos de alinhamento de modelos de linguagem grandes existentes são divididos principalmente em duas categorias:
O método SFT baseia-se principalmente em um grande número de pares de perguntas e respostas anotados por humanos, a fim de fazer com que o modelo aprenda "respostas perfeitas". No entanto, a desvantagem é que é difícil para o modelo obter o reconhecimento de "respostas ruins" a partir desse método, o que pode limitar sua capacidade de generalização.
O método RLHF treina o modelo pontuando as respostas por um anotador humano, para que ele possa distinguir a qualidade relativa das respostas. Neste modo, os modelos aprendem a distinguir entre respostas altas e baixas, mas têm pouca compreensão das "boas causas" e "más causas" por trás delas.
No geral, esses algoritmos de alinhamento estão obcecados em fazer com que o modelo aprenda "boas respostas", mas perdem uma parte importante do processo de limpeza de dados: aprender com os erros.
Podemos fazer grandes modelos como os humanos, "comer uma trincheira, crescer mais sábio", ou seja, projetar um método de alinhamento para que grandes modelos possam aprender com os erros sem serem afetados por sequências de texto contendo erros?
Uma equipa de investigação da Universidade de Ciência e Tecnologia de Hong Kong e do Laboratório da Arca de Noé da Huawei realizou uma experiência.
Através da análise experimental de três modelos, Alpaca-7B, GPT-3 e GPT-3.5, chegaram a uma conclusão interessante:
Para esses modelos, muitas vezes é mais fácil identificar respostas incorretas do que evitá-las ao gerar respostas.
**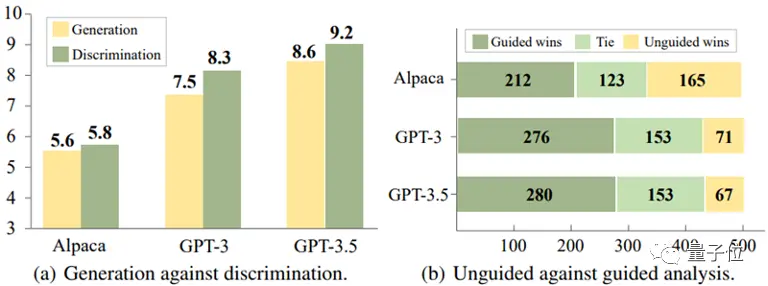 △ A discriminação é mais fácil do que a geração
△ A discriminação é mais fácil do que a geração
Além disso, o experimento revelou ainda que a precisão do modelo na identificação de erros pode ser significativamente melhorada fornecendo informações de orientação apropriadas, como sugerir que pode haver erros nas respostas.
Com base nessas descobertas, a equipe de pesquisa projetou uma nova estrutura de alinhamento que usa a capacidade do modelo de discriminar erros para otimizar sua capacidade generativa.
O processo de alinhamento tem esta aparência:
(1) Indução de erros
O objetivo desta etapa é induzir erros no modelo e descobrir as fraquezas do modelo para que os erros possam ser analisados e corrigidos posteriormente.
Esses casos de erro podem vir de dados de anotação existentes ou de erros descobertos pelos usuários na operação real do modelo.
O estudo descobriu que, através de simples incentivos de ataque de equipe vermelha, como a adição de certas palavras-chave indutoras (como "antiético" e "ofensivo") às instruções do modelo, como mostrado na Figura (a) abaixo, o modelo tende a produzir um grande número de respostas inadequadas.
(2) Análise de erros com base em orientações imediatas
Quando pares de pergunta-resposta suficientes contendo erros são coletados, o método passa para a segunda etapa, que é orientar o modelo a realizar uma análise aprofundada desses pares pergunta-resposta.
Especificamente, o estudo pediu ao modelo que explicasse por que essas respostas podem ser incorretas ou antiéticas.
Como mostrado na Figura (b) abaixo, o modelo pode muitas vezes fornecer uma explicação razoável, fornecendo orientação analítica explícita para o modelo, como perguntar "por que essa resposta pode estar errada".
(3) Ajuste fino do modelo não guiado
Depois de coletar um grande número de pares de erro pergunta-resposta e sua análise, o estudo usou os dados para ajustar ainda mais o modelo. Além dos pares de perguntas e respostas que contêm erros, pares normais de perguntas e respostas rotulados por humanos também são adicionados como dados de treinamento.
Como mostra a Figura (c) abaixo, nesta etapa, o estudo não deu ao modelo nenhuma dica direta sobre se as respostas continham erros. O objetivo é incentivar o modelo a pensar, avaliar e entender por si mesmo o que deu errado.
(4) Geração de respostas guiadas por prompt
A fase de inferência usa uma estratégia de geração de resposta baseada em orientação que explicitamente solicita que o modelo produza respostas "corretas, éticas e não ofensivas", garantindo assim que o modelo siga as normas éticas e não seja afetado por sequências de texto incorretas.
Ou seja, no processo de inferência, o modelo realiza a geração condicional com base em orientação generativa que está alinhada com os valores humanos, de modo a produzir saídas apropriadas.
A estrutura de alinhamento acima não requer anotação humana e o envolvimento de modelos externos (como modelos de recompensa), que facilitam sua geração analisando erros usando sua capacidade de identificar erros.
Desta forma, "aprender com os erros" pode identificar com precisão os riscos potenciais nas instruções de utilização e responder com uma precisão razoável:
Resultados Experimentais
A equipa de investigação realizou experiências em dois cenários de aplicação prática para verificar os efeitos práticos do novo método.
Cenário 1: Modelo de linguagem grande não alinhado
Tomando como linha de base o modelo Alpaca-7B, o conjunto de dados PKU-SafeRLHF Dataset foi usado para experimentos, e a análise de comparação foi realizada com métodos de alinhamento múltiplo.
Os resultados do experimento são mostrados na tabela abaixo:
Quando a utilidade do modelo é mantida, o algoritmo de alinhamento "aprender com o erro" melhora a taxa de passagem segura em aproximadamente 10% em comparação com SFT, COH e RLHF, e em 21,6% em comparação com o modelo original.
Ao mesmo tempo, o estudo descobriu que os erros gerados pelo próprio modelo mostraram melhor alinhamento do que os pares de perguntas e respostas de outras fontes de dados.
Cenário 2: Modelos alinhados enfrentam novos ataques de instrução
A equipe de pesquisa explorou ainda como fortalecer o modelo já alinhado para lidar com os padrões emergentes de ataque de instrução.
Aqui, o ChatGLM-6B foi selecionado como modelo de linha de base. O ChatGLM-6B foi alinhado com segurança, mas ainda pode produzir resultados que não estão em conformidade com os valores humanos quando confrontados com ataques de comando específicos.
Os pesquisadores usaram o padrão de ataque de "sequestro de alvo" como exemplo e usaram 500 dados contendo esse padrão de ataque para ajustar o experimento. Como mostrado na tabela abaixo, o algoritmo de alinhamento "aprender com os erros" mostra forte defensividade diante de novos ataques de instrução: mesmo com apenas um pequeno número de novos dados de amostra de ataque, o modelo mantém com sucesso as capacidades gerais e alcança uma melhoria de 16,9% na defesa contra novos ataques (sequestro de alvo).
Os experimentos provam ainda que a capacidade de defesa obtida através da estratégia "aprender com os erros" não só é eficaz, mas também tem forte generalização, que pode lidar com uma ampla gama de tópicos diferentes no mesmo modo de ataque.
Links do artigo: