Яо Цичжи взял на себя инициативу, предложив большую модель «мышления»! Точность логических рассуждений составляет 98%, а образ мышления больше похож на человеческий.
Первая статья Большая языковая модель, подготовленная лауреатом премии Тьюринга Яо Цичжи, уже здесь!
Как только я начал, я стремился к тому, чтобы «заставить большие модели думать как люди» ——
Большим моделям не только нужно рассуждать шаг за шагом, но им еще нужно научиться «шаг за шагом» и запомнить все правильные процессы в процессе рассуждения.
В частности, в этой новой статье предлагается новый метод под названием «Кумулятивное рассуждение», который значительно улучшает способность больших моделей участвовать в сложных рассуждениях.
Вы должны знать, что большие модели основаны на цепочках мышления и т. д. и могут использоваться для решения проблем, но, сталкиваясь с проблемами, требующими «нескольких ходов», все равно легко допустить ошибку.
Именно на этой основе кумулятивное рассуждение добавляет «проверяющее средство», позволяющее судить о правильном и неправильном в реальном времени. Структура мышления этой модели также изменилась с цепи и дерева на более сложный «ориентированный ациклический граф».
Таким образом, большая модель не только имеет более четкие представления о решении задач, но и развивает навык «игры в карты»:
В математических задачах, таких как алгебра и геометрическая теория чисел, относительная точность больших моделей увеличилась на 42%; при игре в 24 очка процент успеха взлетел до 98%.
По данным Института перекрестной информации Университета Цинхуа, соавтор Чжан Ифань объяснил отправную точку этой статьи:
Канеман считает, что когнитивная обработка данных человека включает две системы: «Система 1» — быстрая, инстинктивная и эмоциональная, а «Система 2» — медленная, вдумчивая и логичная.
В настоящее время производительность больших языковых моделей ближе к «Системе 1», что может быть причиной того, что она плохо справляется со сложными задачами.
Совокупное рассуждение, разработанное с этой точки зрения, лучше, чем Цепочка мыслей (CoT) и Дерево мышления (ToT).
Итак, как на самом деле выглядит этот новый подход? Давайте посмотрим вместе.
Прорыв в цепочке мышления и дереве «узких мест»
Суть кумулятивных рассуждений заключается в улучшении «формы» мыслительного процесса больших моделей.
В частности, этот метод использует 3 большие языковые модели:
Предлагающий: Постоянно предлагать новые предложения, то есть предлагать, какой следующий шаг будет сделан на основе текущего контекста мышления.
Верификатор: проверяет точность предложения предлагающего и добавляет его в контекст мышления, если оно правильное.
Репортер: определяет, было ли получено окончательное решение и стоит ли заканчивать процесс рассуждения.
В процессе рассуждения «предлагающий» сначала выдвигает предложение, «проверяющий» отвечает за оценку, а «докладчик» решает, следует ли дорабатывать ответ и прекращать мыслительный процесс.
** ****△**Пример обоснования CR
Это немного похоже на три типа ролей в командном проекте: члены команды сначала обсуждают различные идеи, инструктор «проверяет», какая идея осуществима, а руководитель группы решает, когда завершить проект.
**Итак, как именно этот подход меняет «форму» мышления большой модели? **
Чтобы понять это, нам следует начать с «Цепи мысли, CoT» (Chain of Thought, CoT), «создателя» методов совершенствования крупномасштабного мышления.
Этот метод был предложен ученым OpenAI Джейсоном Веем и другими в январе 2022 года. Суть заключается в добавлении текста «пошаговое рассуждение» к входным данным в наборе данных, чтобы стимулировать мыслительные способности большой модели.
** ****△**Выбрано из набора данных GSM8K.
Основываясь на принципе цепочки мышления, Google также быстро разработал «версию цепочки мышления PLUS», а именно CoT-SC, которая в основном выполняет несколько процессов цепочки мышления и проводит голосование большинства по ответам, чтобы выбрать лучший. Лучший ответ может еще больше повысить точность рассуждений.
Но и Thinking Chain, и CoT-SC игнорируют одну проблему: существует более одного решения вопроса, особенно когда проблему решают люди.
Поэтому впоследствии появилось новое исследование под названием Древо мысли (ToT).
Это древовидная схема поиска, которая позволяет модели опробовать множество различных идей рассуждения, провести самооценку, выбрать следующий образ действий и при необходимости вернуться назад.
Из метода видно, что дерево мышления идет дальше цепочки мышления, делая мышление большой модели «более активным».
Вот почему при игре в 24 очка вероятность успеха GPT-4 бонуса «Цепочка мыслей» составляет всего 4%**, но вероятность успеха «Дерева мыслей» взлетает до 74%.
НО, независимо от цепочки мышления, CoT-SC или дерева мышления, есть общее ограничение:
Никто из них не организовал место хранения промежуточных результатов мыслительного процесса.
В конце концов, не все мыслительные процессы можно объединить в цепочки или деревья.
Эта новая система кумулятивных рассуждений преодолевает этот момент в дизайне:
Общий мыслительный процесс большой модели не обязательно представляет собой цепочку или дерево, он также может быть Направленным ациклическим графом (DAG)! (Ну, это пахнет синапсами)
** ****△**Ребра в графе имеют направления, круговых путей нет; каждое направленное ребро является шагом вывода.
Это означает, что он может хранить в памяти все исторически верные результаты вывода для исследования в текущей ветви поиска. (Напротив, дерево мышления не хранит информацию из других ветвей)
Но кумулятивные рассуждения также можно легко переключать с цепочкой мышления — пока «проверяющий» удален, это стандартная модель цепочки мышления.
Кумулятивные рассуждения, построенные на основе этого метода, дали хорошие результаты в различных методах.
Хорошо справляется с математикой и логическими рассуждениями
Для «проверки» кумулятивных рассуждений исследователи выбрали вики-сайт FOLIO, AutoTNLI, игру с 24 точками и наборы данных MATH.
Предлагающий, проверяющий и составитель отчета используют одну и ту же большую языковую модель в каждом эксперименте с разными настройками для своих ролей.
Базовые модели, используемые здесь для экспериментов, включают GPT-3,5-турбо, GPT-4, LLaMA-13B и LLaMA-65B.
Стоит отметить, что в идеале модель должна быть специально предварительно обучена с использованием соответствующих данных задачи вывода, а «верификатор» также должен добавить формальное математическое доказательство, модуль решателя пропозициональной логики и т. д.
1. Способность к логическому мышлению
FOLIO — это набор данных для логических рассуждений первого порядка, а метки вопросов могут быть «истинными», «ложными» и «неизвестными»; AutoTNLI — это набор данных для логических рассуждений высокого порядка.
В наборе вики-данных FOLIO по сравнению с методами прямого вывода (Direct), цепочки мышления (CoT) и расширенной цепочки мышления (CoT-SC) производительность кумулятивного рассуждения (CR) всегда является лучшей.
После удаления проблемных экземпляров (например, неправильных ответов) из набора данных точность вывода GPT-4 с использованием метода CR достигла 98,04% с минимальной частотой ошибок 1,96%.
Давайте посмотрим на производительность набора данных AutoTNLI:
По сравнению с методом CoT, CR значительно улучшил характеристики LLaMA-13B и LLaMA-65B.
На модели LLaMA-65B улучшение CR по сравнению с CoT достигло 9,3%.
### 2. Возможность играть в игры с 24 очками
В оригинальной статье ToT использовалась игра с 24 очками, поэтому исследователи использовали этот набор данных для сравнения CR и ToT.
ToT использует дерево поиска фиксированной ширины и глубины, а CR позволяет крупным моделям самостоятельно определять глубину поиска.
В ходе экспериментов исследователи обнаружили, что в контексте 24 точек алгоритм CR и алгоритм ToT очень похожи. Разница в том, что алгоритм в CR генерирует не более одного нового состояния за итерацию, тогда как ToT генерирует множество состояний-кандидатов на каждой итерации, а также фильтрует и сохраняет часть состояния.
С точки зрения непрофессионала, ToT не имеет упомянутого выше «верификатора», как CR, и не может судить, являются ли состояния (a, b, c) правильными или неправильными. Следовательно, ToT будет исследовать больше недопустимых состояний, чем CR.
В итоге точность метода CR может достигать даже 98% (ToT — 74%), а среднее количество обращений к состояниям значительно меньше, чем у ToT.
Другими словами, CR не только имеет более высокий показатель точности поиска, но и имеет более высокую эффективность поиска.
### 3. Математические способности
Набор данных MATH содержит большое количество вопросов по математическому рассуждению, включая алгебру, геометрию, теорию чисел и т. д. Сложность вопросов разделена на пять уровней.
Используя метод CR, модель может разложить вопрос на подвопросы, которые можно заполнять шаг за шагом, а также задавать вопросы и отвечать на них до тех пор, пока не будет получен ответ.
Результаты экспериментов показывают, что в двух разных экспериментальных условиях точность CR превышает существующие существующие методы: общая точность достигает 58%, а относительное улучшение точности составляет 42% в задаче уровня 5. Загружен новый SOTA. по модели ГПТ-4.
Исследование под руководством Яо Цичжи и Юань Яна из Университета Цинхуа
Эта статья подготовлена исследовательской группой «ИИ для математики» под руководством Яо Цичжи и Юань Яна из Института междисциплинарной информации Цинхуа.
Соавторами статьи являются Чжан Ифань и Ян Цзинцинь, аспиранты Института междисциплинарной информации 2021 года;
Преподавателями и соавторами являются доцент Юань Ян и академик Яо Цичжи.
Чжан Ифань
Чжан Ифань окончил Юаньпейский колледж Пекинского университета в 2021 году. В настоящее время он учится у доцента Юань Яна. Его основными направлениями исследований являются теория и алгоритмы базовых моделей (больших языковых моделей), самостоятельное обучение и доверенный искусственный интеллект.
Ян Цзинцинь
Ян Цзинцинь получил степень бакалавра в Институте перекрестной информации Университета Цинхуа в 2021 году и в настоящее время учится в докторантуре под руководством доцента Юань Яна. Основные направления исследований включают большие языковые модели, самостоятельное обучение, интеллектуальную медицинскую помощь и т. д.
Юань Ян
Юань Ян — доцент Школы междисциплинарной информации Университета Цинхуа. Окончил факультет компьютерных наук Пекинского университета в 2012 году; получил степень доктора компьютерных наук Корнелльского университета в США в 2018 году; с 2018 по 2019 год работал научным сотрудником в Школе наук о больших данных Массачусетского института. технологии.
Его основные направления исследований — интеллектуальная медицинская помощь, базовая теория искусственного интеллекта, прикладная теория категорий и т. д.
Яо Цичжи
Яо Цичжи — академик Китайской академии наук и декан Института междисциплинарной информации Университета Цинхуа, а также первый азиатский учёный, получивший премию Тьюринга с момента её учреждения, и единственный китайский учёный-компьютерщик, удостоенный этой награды. до сих пор.
Профессор Яо Цичжи ушел из Принстона в качестве штатного профессора в 2004 году и вернулся в Цинхуа, чтобы преподавать; в 2005 году он основал «Класс Яо», экспериментальный класс информатики для студентов Цинхуа; в 2011 году он основал «Квантовый информационный центр Цинхуа». и «Междисциплинарный институт информационных исследований»; в 2019 г. В 2008 г. он основал класс искусственного интеллекта для студентов бакалавриата Цинхуа, получивший название «Умный класс».
Сегодня уже давно известен возглавляемый им Междисциплинарный информационный институт Университета Цинхуа, в состав которого входят Яо Класс и Чжибань.
Научные интересы профессора Яо Цичжи включают алгоритмы, криптографию, квантовые вычисления и т. д. Он является международным пионером и авторитетом в этой области. Недавно он появился на Всемирной конференции по искусственному интеллекту 2023. Возглавляемый им Шанхайский научно-исследовательский институт Цичжи в настоящее время изучает «воплощенный общий искусственный интеллект».
Бумажная ссылка:
Посмотреть Оригинал
На этой странице может содержаться сторонний контент, который предоставляется исключительно в информационных целях (не в качестве заявлений/гарантий) и не должен рассматриваться как поддержка взглядов компании Gate или как финансовый или профессиональный совет. Подробности смотрите в разделе «Отказ от ответственности» .
Яо Цичжи взял на себя инициативу, предложив большую модель «мышления»! Точность логических рассуждений составляет 98%, а образ мышления больше похож на человеческий.
Источник: Кубиты
Первая статья Большая языковая модель, подготовленная лауреатом премии Тьюринга Яо Цичжи, уже здесь!
Как только я начал, я стремился к тому, чтобы «заставить большие модели думать как люди» ——
Большим моделям не только нужно рассуждать шаг за шагом, но им еще нужно научиться «шаг за шагом» и запомнить все правильные процессы в процессе рассуждения.
В частности, в этой новой статье предлагается новый метод под названием «Кумулятивное рассуждение», который значительно улучшает способность больших моделей участвовать в сложных рассуждениях.
Именно на этой основе кумулятивное рассуждение добавляет «проверяющее средство», позволяющее судить о правильном и неправильном в реальном времени. Структура мышления этой модели также изменилась с цепи и дерева на более сложный «ориентированный ациклический граф».
Таким образом, большая модель не только имеет более четкие представления о решении задач, но и развивает навык «игры в карты»:
В математических задачах, таких как алгебра и геометрическая теория чисел, относительная точность больших моделей увеличилась на 42%; при игре в 24 очка процент успеха взлетел до 98%.
Совокупное рассуждение, разработанное с этой точки зрения, лучше, чем Цепочка мыслей (CoT) и Дерево мышления (ToT).
Итак, как на самом деле выглядит этот новый подход? Давайте посмотрим вместе.
Прорыв в цепочке мышления и дереве «узких мест»
Суть кумулятивных рассуждений заключается в улучшении «формы» мыслительного процесса больших моделей.
В частности, этот метод использует 3 большие языковые модели:
В процессе рассуждения «предлагающий» сначала выдвигает предложение, «проверяющий» отвечает за оценку, а «докладчик» решает, следует ли дорабатывать ответ и прекращать мыслительный процесс.
**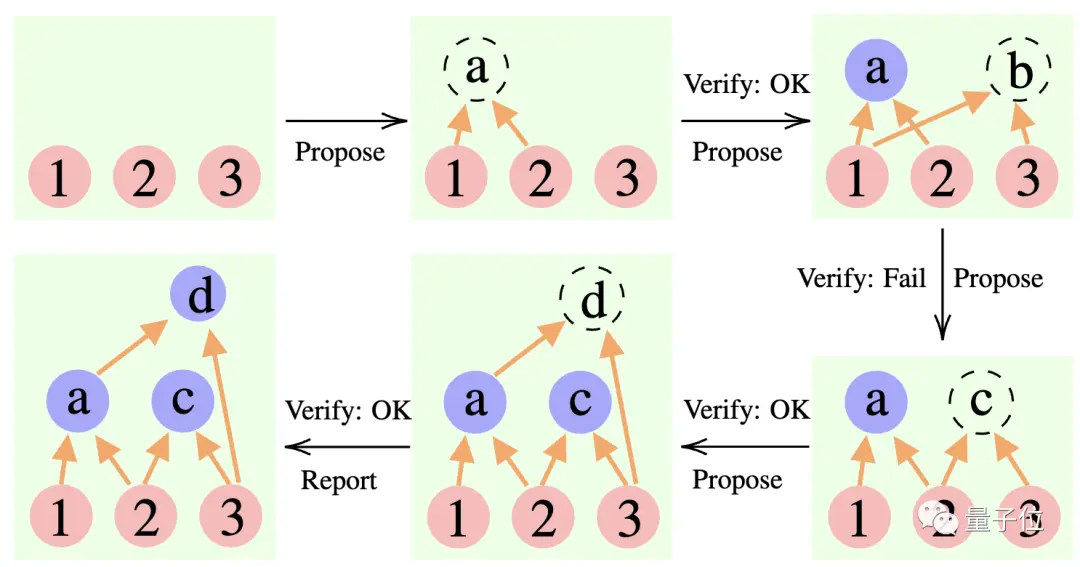 ****△**Пример обоснования CR
****△**Пример обоснования CR
Это немного похоже на три типа ролей в командном проекте: члены команды сначала обсуждают различные идеи, инструктор «проверяет», какая идея осуществима, а руководитель группы решает, когда завершить проект.
Чтобы понять это, нам следует начать с «Цепи мысли, CoT» (Chain of Thought, CoT), «создателя» методов совершенствования крупномасштабного мышления.
Этот метод был предложен ученым OpenAI Джейсоном Веем и другими в январе 2022 года. Суть заключается в добавлении текста «пошаговое рассуждение» к входным данным в наборе данных, чтобы стимулировать мыслительные способности большой модели.
**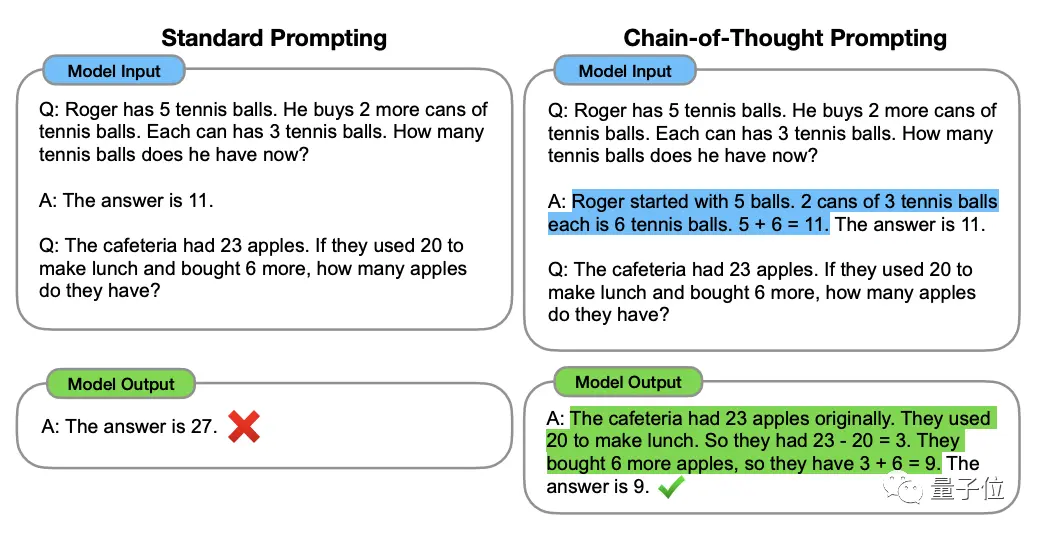 ****△**Выбрано из набора данных GSM8K.
****△**Выбрано из набора данных GSM8K.
Основываясь на принципе цепочки мышления, Google также быстро разработал «версию цепочки мышления PLUS», а именно CoT-SC, которая в основном выполняет несколько процессов цепочки мышления и проводит голосование большинства по ответам, чтобы выбрать лучший. Лучший ответ может еще больше повысить точность рассуждений.
Но и Thinking Chain, и CoT-SC игнорируют одну проблему: существует более одного решения вопроса, особенно когда проблему решают люди.
Поэтому впоследствии появилось новое исследование под названием Древо мысли (ToT).
Это древовидная схема поиска, которая позволяет модели опробовать множество различных идей рассуждения, провести самооценку, выбрать следующий образ действий и при необходимости вернуться назад.
Вот почему при игре в 24 очка вероятность успеха GPT-4 бонуса «Цепочка мыслей» составляет всего 4%**, но вероятность успеха «Дерева мыслей» взлетает до 74%.
НО, независимо от цепочки мышления, CoT-SC или дерева мышления, есть общее ограничение:
В конце концов, не все мыслительные процессы можно объединить в цепочки или деревья.
Эта новая система кумулятивных рассуждений преодолевает этот момент в дизайне:
Общий мыслительный процесс большой модели не обязательно представляет собой цепочку или дерево, он также может быть Направленным ациклическим графом (DAG)! (Ну, это пахнет синапсами)
**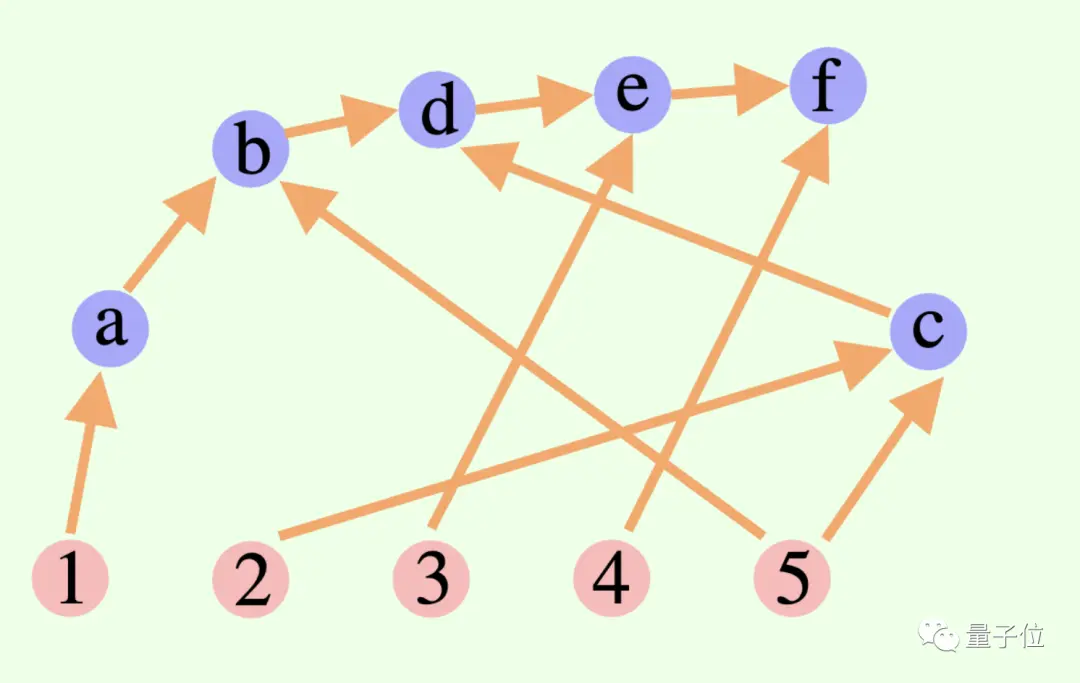 ****△**Ребра в графе имеют направления, круговых путей нет; каждое направленное ребро является шагом вывода.
****△**Ребра в графе имеют направления, круговых путей нет; каждое направленное ребро является шагом вывода.
Это означает, что он может хранить в памяти все исторически верные результаты вывода для исследования в текущей ветви поиска. (Напротив, дерево мышления не хранит информацию из других ветвей)
Но кумулятивные рассуждения также можно легко переключать с цепочкой мышления — пока «проверяющий» удален, это стандартная модель цепочки мышления.
Кумулятивные рассуждения, построенные на основе этого метода, дали хорошие результаты в различных методах.
Хорошо справляется с математикой и логическими рассуждениями
Для «проверки» кумулятивных рассуждений исследователи выбрали вики-сайт FOLIO, AutoTNLI, игру с 24 точками и наборы данных MATH.
Предлагающий, проверяющий и составитель отчета используют одну и ту же большую языковую модель в каждом эксперименте с разными настройками для своих ролей.
Базовые модели, используемые здесь для экспериментов, включают GPT-3,5-турбо, GPT-4, LLaMA-13B и LLaMA-65B.
Стоит отметить, что в идеале модель должна быть специально предварительно обучена с использованием соответствующих данных задачи вывода, а «верификатор» также должен добавить формальное математическое доказательство, модуль решателя пропозициональной логики и т. д.
1. Способность к логическому мышлению
FOLIO — это набор данных для логических рассуждений первого порядка, а метки вопросов могут быть «истинными», «ложными» и «неизвестными»; AutoTNLI — это набор данных для логических рассуждений высокого порядка.
В наборе вики-данных FOLIO по сравнению с методами прямого вывода (Direct), цепочки мышления (CoT) и расширенной цепочки мышления (CoT-SC) производительность кумулятивного рассуждения (CR) всегда является лучшей.
После удаления проблемных экземпляров (например, неправильных ответов) из набора данных точность вывода GPT-4 с использованием метода CR достигла 98,04% с минимальной частотой ошибок 1,96%.
По сравнению с методом CoT, CR значительно улучшил характеристики LLaMA-13B и LLaMA-65B.
На модели LLaMA-65B улучшение CR по сравнению с CoT достигло 9,3%.
В оригинальной статье ToT использовалась игра с 24 очками, поэтому исследователи использовали этот набор данных для сравнения CR и ToT.
ToT использует дерево поиска фиксированной ширины и глубины, а CR позволяет крупным моделям самостоятельно определять глубину поиска.
В ходе экспериментов исследователи обнаружили, что в контексте 24 точек алгоритм CR и алгоритм ToT очень похожи. Разница в том, что алгоритм в CR генерирует не более одного нового состояния за итерацию, тогда как ToT генерирует множество состояний-кандидатов на каждой итерации, а также фильтрует и сохраняет часть состояния.
С точки зрения непрофессионала, ToT не имеет упомянутого выше «верификатора», как CR, и не может судить, являются ли состояния (a, b, c) правильными или неправильными. Следовательно, ToT будет исследовать больше недопустимых состояний, чем CR.
Другими словами, CR не только имеет более высокий показатель точности поиска, но и имеет более высокую эффективность поиска.
Набор данных MATH содержит большое количество вопросов по математическому рассуждению, включая алгебру, геометрию, теорию чисел и т. д. Сложность вопросов разделена на пять уровней.
Используя метод CR, модель может разложить вопрос на подвопросы, которые можно заполнять шаг за шагом, а также задавать вопросы и отвечать на них до тех пор, пока не будет получен ответ.
Результаты экспериментов показывают, что в двух разных экспериментальных условиях точность CR превышает существующие существующие методы: общая точность достигает 58%, а относительное улучшение точности составляет 42% в задаче уровня 5. Загружен новый SOTA. по модели ГПТ-4.
Исследование под руководством Яо Цичжи и Юань Яна из Университета Цинхуа
Эта статья подготовлена исследовательской группой «ИИ для математики» под руководством Яо Цичжи и Юань Яна из Института междисциплинарной информации Цинхуа.
Соавторами статьи являются Чжан Ифань и Ян Цзинцинь, аспиранты Института междисциплинарной информации 2021 года;
Преподавателями и соавторами являются доцент Юань Ян и академик Яо Цичжи.
Чжан Ифань
Чжан Ифань окончил Юаньпейский колледж Пекинского университета в 2021 году. В настоящее время он учится у доцента Юань Яна. Его основными направлениями исследований являются теория и алгоритмы базовых моделей (больших языковых моделей), самостоятельное обучение и доверенный искусственный интеллект.
Ян Цзинцинь
Ян Цзинцинь получил степень бакалавра в Институте перекрестной информации Университета Цинхуа в 2021 году и в настоящее время учится в докторантуре под руководством доцента Юань Яна. Основные направления исследований включают большие языковые модели, самостоятельное обучение, интеллектуальную медицинскую помощь и т. д.
Юань Ян
Его основные направления исследований — интеллектуальная медицинская помощь, базовая теория искусственного интеллекта, прикладная теория категорий и т. д.
Яо Цичжи
Профессор Яо Цичжи ушел из Принстона в качестве штатного профессора в 2004 году и вернулся в Цинхуа, чтобы преподавать; в 2005 году он основал «Класс Яо», экспериментальный класс информатики для студентов Цинхуа; в 2011 году он основал «Квантовый информационный центр Цинхуа». и «Междисциплинарный институт информационных исследований»; в 2019 г. В 2008 г. он основал класс искусственного интеллекта для студентов бакалавриата Цинхуа, получивший название «Умный класс».
Сегодня уже давно известен возглавляемый им Междисциплинарный информационный институт Университета Цинхуа, в состав которого входят Яо Класс и Чжибань.
Научные интересы профессора Яо Цичжи включают алгоритмы, криптографию, квантовые вычисления и т. д. Он является международным пионером и авторитетом в этой области. Недавно он появился на Всемирной конференции по искусственному интеллекту 2023. Возглавляемый им Шанхайский научно-исследовательский институт Цичжи в настоящее время изучает «воплощенный общий искусственный интеллект».
Бумажная ссылка: