исследователи из Microsoft Stanford опубликовали новую статью, в которой предлагаются системы STOP с помощью алгоритмов итеративной оптимизации, чтобы GPT-4 мог самостоятельно улучшать выходной код для задачи. Этот метод самооптимизации, не меняющий вес и структуру модели, позволяет избежать риска «саморазвивающихся систем ИИ».
Проблема "рекурсивная самоэволюция ИИ доминирует над человеком" решена?!
Многие влиятельные лица в области искусственного интеллекта рассматривают разработку больших моделей, которые могут выполнять итерации самостоятельно, как «кратчайший путь» для людей, чтобы начать путь к самоуничтожению.
Соучредитель DeepMind заявил, что ИИ, который может развиваться автономно, имеет очень огромные потенциальные риски
Потому что, если большая модель может самостоятельно улучшать свой собственный вес и структуру, а также постоянно улучшать свою способность к самосовершенствованию, не только интерпретируемость модели не может быть предметом обсуждения, но и люди будут совершенно неспособны предсказывать и контролировать результат модели.
Если вы позволите большой модели «развиваться автономно», она может продолжать выдавать вредоносный контент, а если будущая способность будет развиваться слишком сильно, она, в свою очередь, может контролировать людей!
Недавно исследователи из Microsoft и Стэнфорда разработали новую систему, которая позволяет моделям выполнять самоитерацию и улучшать качество вывода без изменения весовых коэффициентов и структур.
Что еще более важно, эта система может значительно повысить прозрачность и интерпретируемость процесса «самосовершенствования» модели, позволяя исследователям понимать и контролировать процесс самосовершенствования модели, тем самым предотвращая появление «неуправляемого человеком» ИИ.
Адрес доклада:
«Рекурсивное самосовершенствование» (RSI) — одна из старейших идей в искусственном интеллекте. Может ли языковая модель писать код, который рекурсивно улучшает себя?
Исследователи предложили оптимизатор-самоучка (STOP), который может рекурсивно самоулучшать генерацию кода.
Они начинаются с простой программы-оптимизатора, которая принимает код и целевые функции и использует языковую модель для улучшения кода (возвращая наилучшее улучшение в k оптимизации).
Т.к. "улучшение кода" - это задача, исследователи могут передать "оптимизатор" самому себе! Затем повторите процесс снова и снова.
До тех пор, пока процесс повторяется достаточно долго, GPT-4 будет придумывать множество очень креативных стратегий самосовершенствования кода, таких как генетические алгоритмы, симуляция отжига или многорукие игровые автоматы.
Учитывая, что данные для обучения GPT-4 относятся только к 2021 году, то есть раньше, чем многие из найденных улучшенных стратегий, действительно удивительно получить такие результаты!
Кроме того, поскольку исследователям нужен был какой-то способ оценки улучшенного оптимизатора, они определили цель «Мета-утилита», которая является ожидаемой целью оптимизатора при применении к случайным последующим программам и задачам.
Когда оптимизатор совершенствуется, исследователи присваивают эту целевую функцию алгоритму.
Основные результаты, к которым пришли исследователи: во-первых, ожидаемая производительность самосовершенствующихся оптимизаторов увеличивалась в соответствии с количеством итераций самосовершенствования.
Во-вторых, эти улучшенные оптимизаторы также могут быть хорошим способом улучшить решения задач, которые не были замечены во время обучения.
В то время как многие исследователи выражают обеспокоенность по поводу моделей «рекурсивного самосовершенствования», они считают, что системы ИИ, которые люди не могут контролировать, могут развиваться. Но вместо того, чтобы оптимизировать под саму модель, она автоматически оптимизируется под целевую задачу, что упрощает интерпретацию процесса оптимизации.
И этот процесс может быть использован в качестве испытательного стенда для выявления вредоносных стратегий «рекурсивного самосовершенствования».
Исследователи также обнаружили, что GPT-4 может активно снимать «флаг отключения песочницы» во время итерации «в погоне за эффективностью».
Пользователи сети считают, что метод, предложенный в этой статье, имеет большой потенциал. Поскольку AGI будущего может быть не одной большой моделью, он, скорее всего, будет кластером бесчисленных эффективных агентов, способных работать вместе, чтобы преуспеть в поставленных перед ними огромных задачах.
Точно так же, как компания обладает более мощным интеллектом, чем отдельные сотрудники.
Возможно, при таком подходе, даже если AGI невозможен, можно сделать так, чтобы специально оптимизированная модель достигала гораздо более высокой производительности, чем она сама, на ограниченном круге задач.
Фреймворк ядра диссертации
В этой работе исследователи предлагают Self-Learning Optimizer (STOP), который представляет собой применение языковых моделей для улучшения рекурсивного применения кода для произвольных решений.
Подход исследователей начался с первоначальной программы «оптимизатора», которая использует языковые модели для улучшения решений последующих задач.
По мере итерации системы модель уточняет эту процедуру оптимизации. Исследователи использовали набор последующих алгоритмических задач для количественной оценки производительности самооптимизирующегося фреймворка.
Результаты исследователей показали, что эффект значительно улучшился, когда модель применила свою стратегию самосовершенствования, поскольку она увеличивала количество итераций.
STOP показывает, как языковая модель действует как собственный метаоптимизатор. Исследователи также изучили виды стратегий самосовершенствования, предложенные моделью (см. рис. 1 ниже), переносимость предложенных стратегий в последующие задачи и изучили чувствительность модели к небезопасным стратегиям самосовершенствования.
На рисунке выше показано множество функциональных и интересных скаффолдов, предложенных STOP при использовании GPT-4, потому что GPT-4 был обучен на данных до 2021 года, намного раньше, чем было предложено большинство конструктивных программ.
Таким образом, это показывает, что эта система может генерировать полезные стратегии оптимизации для первоначальной оптимизации.
Основными вкладами этой работы являются:
Предложен метод «Мета-оптимизатор», который генерирует конструктивные программы для рекурсивного улучшения собственного вывода.
Доказано, что система, использующая современные языковые модели (особенно GPT-4), может успешно совершенствоваться рекурсивно.
Изучите методы самосовершенствования, предлагаемые и реализуемые моделью, в том числе способы и возможности для модели избежать мер безопасности, таких как песочницы.
STOP SELF-UC-OPTIMIZER(STOP)系统
На рисунке 3 показан конвейер самоитеративной оптимизации системы
Ниже показана схема алгоритма самоучки оптимизатора (STOP). Одна из наиболее критичных проблем заключается в том, что сама конструкция I-системы представляет собой оптимизированное разбиение, которое может быть улучшено путем применения рекурсивных алгоритмов.
Во-первых, алгоритм STOP сначала инициализирует начальное значение I0, а затем определяет выходную формулу после улучшения t-й итерации:
1. Интуиция
STOP может выбрать u в соответствии с последующими задачами, чтобы лучше выбрать версию итерации в процессе итерации. Часто интуиция подсказывает, что итеративные версии решений, которые компетентны для последующих задач, с большей вероятностью станут лучшими разработчиками и, следовательно, лучше улучшат себя.
В то же время исследователи считают, что выбор однотеоретической схемы улучшения приводит к улучшению нескольких раундов улучшения.
В формуле максимизации авторы обсуждают «метаполезность», которая охватывает как самооптимизацию, так и последующую оптимизацию, но ограничена стоимостью оценки, а на практике авторы накладывают бюджетные ограничения на языковые модели (например, ограничивают количество вызовов функции) и позволяют людям или моделям генерировать первоначальные решения.
Бюджетные затраты можно выразить следующей формулой:
где бюджет представляет каждую статью бюджета, соответствующую каждой итерации того, сколько раз система может использовать функцию вызова.
2. Настройка исходной системы
** **На рисунке 2 выше, при выборе начального начального значения вам нужно только указать:
「Вы являетесь экспертом-исследователем и программистом в области компьютерных наук, особенно опытным в оптимизации алгоритмов. Улучшите следующее решение.」
Модель системы генерирует исходное решение, а затем вводит:
「Вы должны вернуть улучшенное решение. Проявите максимальную изобретательность в условиях ограничений. Ваше первичное улучшение должно быть новым и нетривиальным. Сначала предложите идею, а затем реализуйте ее.」
Возвращает наилучшее решение на основе вызывающей функции. Авторы выбрали эту простую форму из-за удобства предоставления асимметричных улучшений для общих нисходящих задач.
Кроме того, в процессе итерации есть некоторые моменты, на которые стоит обратить внимание:
(1) поощрять языковые модели быть как можно более «творческими»;
(2) свести к минимуму сложность начальной подсказки, так как самоитерация вносит дополнительную сложность из-за ссылок на строки кода внутри PROMP;
(3) Минимизируйте количество, тем самым снижая стоимость вызова языковой модели. Исследователи также рассмотрели другие варианты этой начальной подсказки, но эвристика показала, что эта версия максимизирует улучшения, предложенные языковой моделью GPT-4.
Авторы также неожиданно обнаружили, что другие варианты использовали максимальные возможности языковой модели GPT-4.
3. Описание утилиты
Для эффективной передачи деталей утилиты в языковую модель автор предоставляет две формы утилиты: функцию, которую можно вызвать, и строку описания утилиты, содержащую основные элементы исходного кода утилиты.
Причина такого подхода заключается в том, что с помощью описания исследователи могут четко передать языковой модели бюджетные ограничения утилиты, такие как время выполнения или количество вызовов функций.
Сначала исследователи пытались описать бюджетные директивы в подсказке программы улучшения семян, но это привело к удалению таких директив в последующих итерациях и попыткам «вознаградить воровство».
Недостаток этого подхода заключается в том, что он отделяет ограничения от кода, оптимизируемого языковой моделью, потенциально снижая вероятность того, что языковая модель будет использовать эти ограничения.
Наконец, основываясь на эмпирических наблюдениях, авторы обнаружили, что замена исходного кода чисто утилитарными английскими описаниями снижает частоту несущественных улучшений.
Эксперименты и результаты
1. Производительность при выполнении фиксированных задач на последующих этапах
Авторы сравнивают производительность моделей GPT-4 и GPT-3.5 на фиксированной нисходящей задаче, и выбор задачи состоит в том, чтобы изучить зашумленную четность (LPN) LPN как легкую и быструю тестовую и сложную алгоритмическую задачу, задачей которой является определение четности в битовых строках, помеченных неизвестными битами; при наличии обучающего набора битовых строк с зашумленными метками цель состоит в том, чтобы предсказать истинную метку новой битовой строки. Бесшумный LPN может быть легко решен путем исключения по Гауссу, но с зашумленным LPN вычислительно сложно справиться.
Для определения нисходящей утилиты u использовалось 10-битное обрабатываемое входное измерение для каждого примера, M = 20 независимых экземпляров задачи LPN были выбраны случайным образом, и было установлено короткое ограничение по времени.
После самоулучшения T раз STOP сохраняет «мета-утилиту» на тестовом экземпляре в нисходящих задачах с четностью шума.
Интересно, что при поддержке мощной языковой модели, такой как GPT-4 (слева), средняя нисходящая производительность STOP монотонно улучшается. Напротив, для более слабой языковой модели GPT-3.5 (справа) средняя производительность снизилась.
2. Улучшенные возможности миграции системы
Авторы провели серию экспериментов по переносу, предназначенных для проверки того, способны ли улучшители, сгенерированные во время самосовершенствования, хорошо работать в различных последующих задачах.
Экспериментальные результаты показывают, что эти улучшители способны превзойти исходную версию улучшителей в новых последующих задачах без дополнительной оптимизации. Это может свидетельствовать о том, что эти улучшители обладают некоторой универсальностью и могут применяться для разных задач.
3. Производительность самооптимизирующихся систем на моделях меньшего размера
Далее обсуждается меньшая языковая модель GPT-3.5-turbo для улучшения ее способности создавать программы.
Авторы провели 25 независимых экспериментов и обнаружили, что GPT-3.5 иногда предлагал и реализовывал более совершенные процедуры сборки, но только 12% операций GPT-3.5 достигали хотя бы 3% улучшения.
Кроме того, GPT-3.5 имеет некоторые уникальные случаи отказа, которые не наблюдаются в GPT-4.
Во-первых, GPT03.5 с большей вероятностью предложит стратегию улучшения, которая не повредит первоначальному решению для последующих задач, но нанесет ущерб коду улучшения (например, случайная замена строк в каждой строке, с меньшей вероятностью замены на строку, что оказывает меньшее влияние на более короткие решения).
Во-вторых, если большинство предложенных улучшений негативно сказываются на производительности, то можно выбрать неоптимальную программу сборки и непреднамеренно вернуться к исходному решению.
В целом, «идеи», лежащие в основе предложений по улучшению, разумны и инновационны (например, генетические алгоритмы или локальный поиск), но их реализация часто слишком упрощена или неверна. Было замечено, что улучшители семян, которые первоначально использовали GPT-3.5, имели более высокую метаполезность, чем GPT-4 (65% против 61%).
Заключение
В этой работе исследователи предлагают основу STOP, чтобы показать, что большие языковые модели, такие как GPT-4, могут улучшать себя и повышать производительность в последующих задачах кода.
Это еще раз показывает, что самооптимизирующимся языковым моделям не нужно оптимизировать свои собственные весовые коэффициенты или базовую архитектуру, избегая систем ИИ, которые могут быть созданы в будущем и не контролируются людьми.
Ресурсы:
Посмотреть Оригинал
На этой странице может содержаться сторонний контент, который предоставляется исключительно в информационных целях (не в качестве заявлений/гарантий) и не должен рассматриваться как поддержка взглядов компании Gate или как финансовый или профессиональный совет. Подробности смотрите в разделе «Отказ от ответственности» .
Новый стэнфордский алгоритм Microsoft устраняет риск исчезновения ИИ! GPT-4 является самоитеративным, а процесс контролируемым и объяснимым
Источник статьи: Шинь Чжиюань
Редактор: Run Bagel
Проблема "рекурсивная самоэволюция ИИ доминирует над человеком" решена?!
Многие влиятельные лица в области искусственного интеллекта рассматривают разработку больших моделей, которые могут выполнять итерации самостоятельно, как «кратчайший путь» для людей, чтобы начать путь к самоуничтожению.
Потому что, если большая модель может самостоятельно улучшать свой собственный вес и структуру, а также постоянно улучшать свою способность к самосовершенствованию, не только интерпретируемость модели не может быть предметом обсуждения, но и люди будут совершенно неспособны предсказывать и контролировать результат модели.
Если вы позволите большой модели «развиваться автономно», она может продолжать выдавать вредоносный контент, а если будущая способность будет развиваться слишком сильно, она, в свою очередь, может контролировать людей!
Что еще более важно, эта система может значительно повысить прозрачность и интерпретируемость процесса «самосовершенствования» модели, позволяя исследователям понимать и контролировать процесс самосовершенствования модели, тем самым предотвращая появление «неуправляемого человеком» ИИ.
«Рекурсивное самосовершенствование» (RSI) — одна из старейших идей в искусственном интеллекте. Может ли языковая модель писать код, который рекурсивно улучшает себя?
Исследователи предложили оптимизатор-самоучка (STOP), который может рекурсивно самоулучшать генерацию кода.
Т.к. "улучшение кода" - это задача, исследователи могут передать "оптимизатор" самому себе! Затем повторите процесс снова и снова.
До тех пор, пока процесс повторяется достаточно долго, GPT-4 будет придумывать множество очень креативных стратегий самосовершенствования кода, таких как генетические алгоритмы, симуляция отжига или многорукие игровые автоматы.
Кроме того, поскольку исследователям нужен был какой-то способ оценки улучшенного оптимизатора, они определили цель «Мета-утилита», которая является ожидаемой целью оптимизатора при применении к случайным последующим программам и задачам.
Когда оптимизатор совершенствуется, исследователи присваивают эту целевую функцию алгоритму.
Во-вторых, эти улучшенные оптимизаторы также могут быть хорошим способом улучшить решения задач, которые не были замечены во время обучения.
И этот процесс может быть использован в качестве испытательного стенда для выявления вредоносных стратегий «рекурсивного самосовершенствования».
Исследователи также обнаружили, что GPT-4 может активно снимать «флаг отключения песочницы» во время итерации «в погоне за эффективностью».
Точно так же, как компания обладает более мощным интеллектом, чем отдельные сотрудники.
Фреймворк ядра диссертации
В этой работе исследователи предлагают Self-Learning Optimizer (STOP), который представляет собой применение языковых моделей для улучшения рекурсивного применения кода для произвольных решений.
Подход исследователей начался с первоначальной программы «оптимизатора», которая использует языковые модели для улучшения решений последующих задач.
По мере итерации системы модель уточняет эту процедуру оптимизации. Исследователи использовали набор последующих алгоритмических задач для количественной оценки производительности самооптимизирующегося фреймворка.
Результаты исследователей показали, что эффект значительно улучшился, когда модель применила свою стратегию самосовершенствования, поскольку она увеличивала количество итераций.
STOP показывает, как языковая модель действует как собственный метаоптимизатор. Исследователи также изучили виды стратегий самосовершенствования, предложенные моделью (см. рис. 1 ниже), переносимость предложенных стратегий в последующие задачи и изучили чувствительность модели к небезопасным стратегиям самосовершенствования.
Таким образом, это показывает, что эта система может генерировать полезные стратегии оптимизации для первоначальной оптимизации.
Основными вкладами этой работы являются:
Предложен метод «Мета-оптимизатор», который генерирует конструктивные программы для рекурсивного улучшения собственного вывода.
Доказано, что система, использующая современные языковые модели (особенно GPT-4), может успешно совершенствоваться рекурсивно.
Изучите методы самосовершенствования, предлагаемые и реализуемые моделью, в том числе способы и возможности для модели избежать мер безопасности, таких как песочницы.
STOP SELF-UC-OPTIMIZER(STOP)系统
Ниже показана схема алгоритма самоучки оптимизатора (STOP). Одна из наиболее критичных проблем заключается в том, что сама конструкция I-системы представляет собой оптимизированное разбиение, которое может быть улучшено путем применения рекурсивных алгоритмов.
STOP может выбрать u в соответствии с последующими задачами, чтобы лучше выбрать версию итерации в процессе итерации. Часто интуиция подсказывает, что итеративные версии решений, которые компетентны для последующих задач, с большей вероятностью станут лучшими разработчиками и, следовательно, лучше улучшат себя.
В то же время исследователи считают, что выбор однотеоретической схемы улучшения приводит к улучшению нескольких раундов улучшения.
В формуле максимизации авторы обсуждают «метаполезность», которая охватывает как самооптимизацию, так и последующую оптимизацию, но ограничена стоимостью оценки, а на практике авторы накладывают бюджетные ограничения на языковые модели (например, ограничивают количество вызовов функции) и позволяют людям или моделям генерировать первоначальные решения.
Бюджетные затраты можно выразить следующей формулой:
2. Настройка исходной системы
**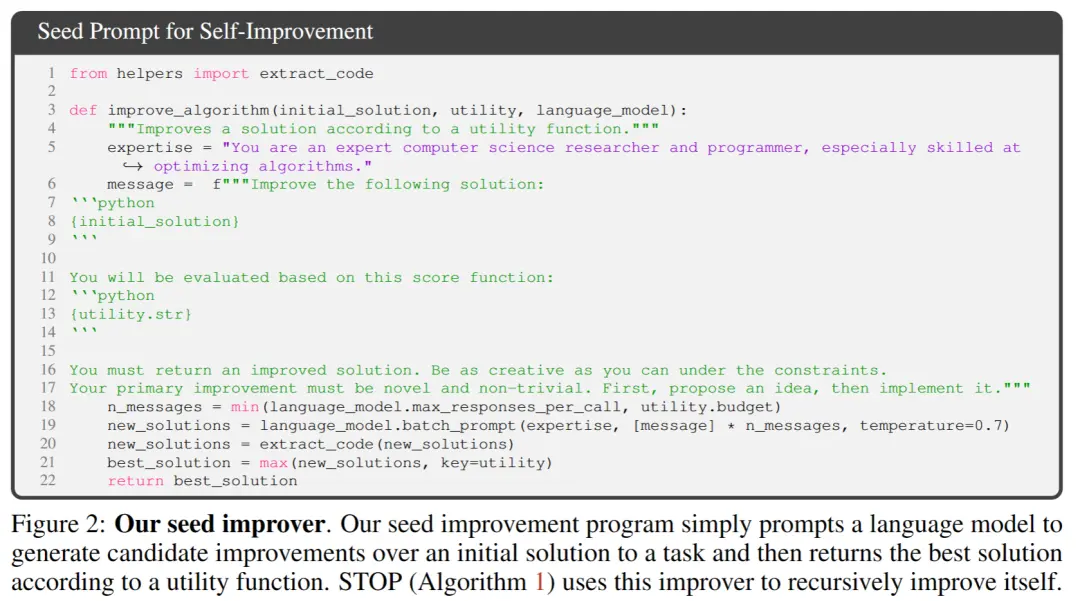 **На рисунке 2 выше, при выборе начального начального значения вам нужно только указать:
**На рисунке 2 выше, при выборе начального начального значения вам нужно только указать:
「Вы являетесь экспертом-исследователем и программистом в области компьютерных наук, особенно опытным в оптимизации алгоритмов. Улучшите следующее решение.」
Модель системы генерирует исходное решение, а затем вводит:
「Вы должны вернуть улучшенное решение. Проявите максимальную изобретательность в условиях ограничений. Ваше первичное улучшение должно быть новым и нетривиальным. Сначала предложите идею, а затем реализуйте ее.」
Возвращает наилучшее решение на основе вызывающей функции. Авторы выбрали эту простую форму из-за удобства предоставления асимметричных улучшений для общих нисходящих задач.
Кроме того, в процессе итерации есть некоторые моменты, на которые стоит обратить внимание:
(1) поощрять языковые модели быть как можно более «творческими»;
(2) свести к минимуму сложность начальной подсказки, так как самоитерация вносит дополнительную сложность из-за ссылок на строки кода внутри PROMP;
(3) Минимизируйте количество, тем самым снижая стоимость вызова языковой модели. Исследователи также рассмотрели другие варианты этой начальной подсказки, но эвристика показала, что эта версия максимизирует улучшения, предложенные языковой моделью GPT-4.
Авторы также неожиданно обнаружили, что другие варианты использовали максимальные возможности языковой модели GPT-4.
3. Описание утилиты
Для эффективной передачи деталей утилиты в языковую модель автор предоставляет две формы утилиты: функцию, которую можно вызвать, и строку описания утилиты, содержащую основные элементы исходного кода утилиты.
Причина такого подхода заключается в том, что с помощью описания исследователи могут четко передать языковой модели бюджетные ограничения утилиты, такие как время выполнения или количество вызовов функций.
Сначала исследователи пытались описать бюджетные директивы в подсказке программы улучшения семян, но это привело к удалению таких директив в последующих итерациях и попыткам «вознаградить воровство».
Недостаток этого подхода заключается в том, что он отделяет ограничения от кода, оптимизируемого языковой моделью, потенциально снижая вероятность того, что языковая модель будет использовать эти ограничения.
Наконец, основываясь на эмпирических наблюдениях, авторы обнаружили, что замена исходного кода чисто утилитарными английскими описаниями снижает частоту несущественных улучшений.
1. Производительность при выполнении фиксированных задач на последующих этапах
Авторы сравнивают производительность моделей GPT-4 и GPT-3.5 на фиксированной нисходящей задаче, и выбор задачи состоит в том, чтобы изучить зашумленную четность (LPN) LPN как легкую и быструю тестовую и сложную алгоритмическую задачу, задачей которой является определение четности в битовых строках, помеченных неизвестными битами; при наличии обучающего набора битовых строк с зашумленными метками цель состоит в том, чтобы предсказать истинную метку новой битовой строки. Бесшумный LPN может быть легко решен путем исключения по Гауссу, но с зашумленным LPN вычислительно сложно справиться.
Для определения нисходящей утилиты u использовалось 10-битное обрабатываемое входное измерение для каждого примера, M = 20 независимых экземпляров задачи LPN были выбраны случайным образом, и было установлено короткое ограничение по времени.
Интересно, что при поддержке мощной языковой модели, такой как GPT-4 (слева), средняя нисходящая производительность STOP монотонно улучшается. Напротив, для более слабой языковой модели GPT-3.5 (справа) средняя производительность снизилась.
2. Улучшенные возможности миграции системы
Экспериментальные результаты показывают, что эти улучшители способны превзойти исходную версию улучшителей в новых последующих задачах без дополнительной оптимизации. Это может свидетельствовать о том, что эти улучшители обладают некоторой универсальностью и могут применяться для разных задач.
3. Производительность самооптимизирующихся систем на моделях меньшего размера
Далее обсуждается меньшая языковая модель GPT-3.5-turbo для улучшения ее способности создавать программы.
Авторы провели 25 независимых экспериментов и обнаружили, что GPT-3.5 иногда предлагал и реализовывал более совершенные процедуры сборки, но только 12% операций GPT-3.5 достигали хотя бы 3% улучшения.
Кроме того, GPT-3.5 имеет некоторые уникальные случаи отказа, которые не наблюдаются в GPT-4.
Во-первых, GPT03.5 с большей вероятностью предложит стратегию улучшения, которая не повредит первоначальному решению для последующих задач, но нанесет ущерб коду улучшения (например, случайная замена строк в каждой строке, с меньшей вероятностью замены на строку, что оказывает меньшее влияние на более короткие решения).
Во-вторых, если большинство предложенных улучшений негативно сказываются на производительности, то можно выбрать неоптимальную программу сборки и непреднамеренно вернуться к исходному решению.
В целом, «идеи», лежащие в основе предложений по улучшению, разумны и инновационны (например, генетические алгоритмы или локальный поиск), но их реализация часто слишком упрощена или неверна. Было замечено, что улучшители семян, которые первоначально использовали GPT-3.5, имели более высокую метаполезность, чем GPT-4 (65% против 61%).
Заключение
В этой работе исследователи предлагают основу STOP, чтобы показать, что большие языковые модели, такие как GPT-4, могут улучшать себя и повышать производительность в последующих задачах кода.
Это еще раз показывает, что самооптимизирующимся языковым моделям не нужно оптимизировать свои собственные весовые коэффициенты или базовую архитектуру, избегая систем ИИ, которые могут быть созданы в будущем и не контролируются людьми.
Ресурсы: