Заставьте большие модели смотреть на диаграммы, чем печатать! В новом исследовании NeurIPS 2023 предлагается метод мультимодальных запросов, точность которого повышается на 7,8%
Способность больших моделей «читать картинки» настолько сильна, почему вы продолжаете искать не те вещи?
Например, путать летучих мышей, которые не похожи на них, с ракетками, или не распознавать редких рыб в некоторых наборах данных...
Это связано с тем, что, когда мы позволяем большой модели «что-то найти», мы часто вводим текст.
Если описание неоднозначное или слишком пристрастное, например, «летучая мышь» (бита или бита?). Или «Cyprinodon diabolis», и ИИ запутается.
Это приводит к использованию больших моделей для выполнения ** обнаружения объектов**, особенно задач обнаружения объектов в открытом мире (неизвестная сцена), эффект часто не так хорош, как ожидалось.
Теперь статья, включенная в NeurIPS 2023, наконец-то решила эту проблему.
В данной работе предложен метод обнаружения объектов MQ-Det, основанный на мультимодальном запросе, который требует только добавления примера изображения к входным данным, что может значительно повысить точность поиска вещей в больших моделях.
В эталонном наборе данных обнаружения LVIS MQ-Det повышает точность GLIP основных больших моделей обнаружения в среднем примерно на 7,8% и повышает точность 13 контрольных задач на малых выборках в среднем на 6,3%.
Как именно это делается? Давайте разберемся.
Ниже приводится цитата из автора статьи, блогера Zhihu @Qinyuanxia:
Содержание
MQ-Det: большая модель обнаружения объектов с открытым миром для мультимодальных запросов
1.1 От текстового запроса к мультимодальному запросу
1.2 Архитектура мультимодальной модели запросов MQ-Det plug-and-play
1.3 Эффективная стратегия тренировок MQ-Det
1.4 Экспериментальные результаты: Оценка без тонкой настройки
*1.5 Экспериментальные результаты: Оценка нескольких снимков
1.6 Мультимодальный запрос перспективы обнаружения объектов
MQ-Det: Большая модель обнаружения объектов в открытом мире для мультимодальных запросов**
Мультимодальное обнаружение запрашиваемых объектов в реальных условиях
Ссылка на статью:
Код адреса:**
### 1.1 От текстового запроса к мультимодальному запросу
Одна картинка стоит тысячи слов: С появлением графического предварительного обучения, с помощью открытой семантики текста, обнаружение объектов постепенно перешло в стадию восприятия открытого мира. По этой причине многие крупные модели обнаружения следуют шаблону текстового запроса, то есть используют категориальные текстовые описания для запроса потенциальных целей на целевых изображениях. Однако при таком подходе часто возникает проблема «широкого, но не утонченного».
Например, (1) обнаружение мелкозернистых объектов (мальков) на рисунке 1 часто затрудняет описание различных мелкозернистых видов с ограниченным количеством текста, и (2) неоднозначность категории («летучая мышь» может относиться как к летучей мыши, так и к ракетке).
Тем не менее, вышеуказанные проблемы могут быть решены с помощью примеров изображений, которые дают более богатые подсказки о признаках целевого объекта, чем текст, но в то же время текст имеет сильное обобщение.
Поэтому вопрос о том, как органично совместить два метода запроса, стал естественной идеей.
Трудности с получением возможностей мультимодальных запросов: Существует три проблемы, связанные с получением такой модели с помощью мультимодальных запросов: (1) Прямая тонкая настройка с ограниченным количеством примеров изображений может легко привести к катастрофическому забыванию; (2) Обучение большой модели обнаружения с нуля будет иметь хорошее обобщение, но огромное потребление, например, обучение одной карты GLIP требует 480 дней обучения с объемом данных 30 миллионов.
Детектирование объектов мультимодальных запросов: Исходя из вышеизложенных соображений, автор предлагает простую и эффективную стратегию проектирования и обучения модели - MQ-Det.
MQ-Det вставляет небольшое количество модулей зависимого восприятия (GCP) для получения входных визуальных примеров на основе существующей большой модели обнаружения запросов с замороженным текстом и разрабатывает стратегию обучения языка прогнозирования языка визуальных масок условий для эффективного получения детектора для высокопроизводительных мультимодальных запросов.
1.2 Архитектура мультимодальной модели запросов MQ-Det plug-and-play
** **####### △Рисунок 1 Схема архитектуры метода MQ-Det
Модуль закрытого восприятия
Как показано на рисунке 1, автор послойно вставляет модуль осведомленности о стробировании (GCP) на сторону текстового кодировщика существующей большой модели обнаружения замороженных текстовых запросов, и режим работы GCP можно кратко представить следующей формулой:
В качестве i-й категории введите визуальный пример Vi, в котором сначала перекрестное внимание (X-MHA) с целевым изображением I
для расширения его репрезентативных возможностей, а затем текст каждой категории ti и соответствующий визуальный пример категории
Проведение перекрестного внимания получает
, после чего исходный текст ti и визуальное дополнение текста усиливаются стробовым модулем
Слияние для получения выходных данных текущего слоя
。 Эта простая конструкция следует трем принципам: (1) масштабируемость по категориям; (2) семантическая полнота; (3) Антиамнезия, конкретное обсуждение можно найти в оригинальном тексте.
1.3 Эффективная стратегия обучения MQ-Det
Обучение модуляции на основе детектора замороженных языковых запросов
Поскольку текущая предобучающая детектирование большой модели текстового запроса сама по себе обладает хорошим обобщением, авторы считают, что нужно лишь внести незначительные коррективы в визуальные детали на основе исходных текстовых особенностей.
В статье также приведена конкретная экспериментальная демонстрация того, что после вскрытия параметров исходной предварительно обученной модели и тонкой настройки легко вызвать катастрофическое забывание, но потеряв способность к обнаружению в открытом мире.
Таким образом, MQ-Det может эффективно вставлять визуальную информацию в детектор существующего текстового запроса на основе предварительно обученного детектора замороженного текстового запроса и модулировать только модуль GCP, вставленный путем обучения.
В работе авторы применяют методы структурного проектирования и обучения MQ-Det к текущим моделям SOTA GLIP и GroundingDINO соответственно для проверки универсальности метода.
Стратегия обучения прогнозированию языка маски с визуальным состоянием
Авторы также предлагают визуально обусловленную стратегию предиктивного обучения маскирующего языка для решения проблемы лени обучения, вызванной замораживанием предварительно обученных моделей.
Так называемая ленивая обучаемость означает, что детектор стремится сохранить характеристики исходного текстового запроса в процессе обучения, тем самым игнорируя вновь добавленные визуальные функции запроса.
Для этого MQ-Det используется случайным образом во время тренировки[MASK] token заменяет текстовый токен, заставляя модель обучаться со стороны функции визуального запроса, а именно:
Несмотря на то, что эта стратегия проста, она очень эффективна, и, судя по результатам экспериментов, она принесла значительное улучшение производительности.
1.4 Экспериментальные результаты: оценка без тонкой настройки
Без тонкой настройки: MQ-Det предлагает более практичную стратегию оценки: без тонкой настройки, по сравнению с традиционной оценкой с нуля, в которой используется только текст категории. Он определяется как обнаружение объектов с использованием текста категории, примеров изображений или комбинации того и другого без какой-либо последующей тонкой настройки.
При настройке без тонкой настройки MQ-Det выбирает 5 визуальных примеров для каждой категории и объединяет текст категории для обнаружения объектов, в то время как другие существующие модели не поддерживают визуальные запросы и могут использовать только обычные текстовые описания для обнаружения объектов. В таблице ниже приведены результаты LVIS MiniVal и LVIS v1.0. Можно обнаружить, что введение мультимодальных запросов значительно улучшило возможности обнаружения объектов в открытом мире.
** **###### △Таблица 1 Производительность каждой модели обнаружения без тонкой настройки в эталонном наборе данных LVIS
Как видно из таблицы 1, MQ-GLIP-L улучшил AP более чем на 7% на основе GLIP-L, и эффект очень значительный!
1.5 Экспериментальные результаты: оценка нескольких снимков
** **####### △Таблица 2 Производительность каждой модели в ODinW-35 и 13 подмножествах ODinW-13 в 35 задачах обнаружения
Кроме того, авторы провели комплексные эксперименты в ODinW-35, нисходящей задаче обнаружения 35. Как видно из таблицы 2, MQ-Det не только обладает высокой производительностью без тонкой настройки, но и обладает хорошими возможностями обнаружения малых выборок, что еще раз подтверждает потенциал мультимодальных запросов. На рисунке 2 также показано значительное улучшение MQ-Det по сравнению с GLIP.
** **###### △Рисунок 2 Сравнение эффективности использования данных; Горизонтальная ось: количество обучающих выборок, вертикальная ось: средняя АР на OdinW-13
1.6 Перспективы обнаружения объектов мультимодальных запросов
Как область исследований, основанная на практических приложениях, обнаружение объектов уделяет большое внимание приземлению алгоритмов.
Несмотря на то, что предыдущая модель обнаружения объектов текстовых запросов показывает хорошее обобщение, в реальном китайском языке обнаружения открытого мира трудно охватить детальную информацию, и богатая детализация информации на изображении идеально дополняет эту связь.
До сих пор мы можем обнаружить, что текст является общим, но не точным, а изображение точным, но не общим, и если мы сможем эффективно объединить их, то есть мультимодальный запрос, это будет способствовать дальнейшему обнаружению объектов открытого мира.
MQ-Det сделал первый шаг в области мультимодальных запросов, и его значительное повышение производительности также свидетельствует о большом потенциале обнаружения целей мультимодальных запросов.
В то же время введение текстовых описаний и визуальных примеров предоставляет пользователям больше выбора, делая обнаружение объектов более гибким и удобным для пользователя.
Ссылка на оригинал:
Посмотреть Оригинал
На этой странице может содержаться сторонний контент, который предоставляется исключительно в информационных целях (не в качестве заявлений/гарантий) и не должен рассматриваться как поддержка взглядов компании Gate или как финансовый или профессиональный совет. Подробности смотрите в разделе «Отказ от ответственности» .
Заставьте большие модели смотреть на диаграммы, чем печатать! В новом исследовании NeurIPS 2023 предлагается метод мультимодальных запросов, точность которого повышается на 7,8%
Первоисточник: Qubits
Способность больших моделей «читать картинки» настолько сильна, почему вы продолжаете искать не те вещи?
Например, путать летучих мышей, которые не похожи на них, с ракетками, или не распознавать редких рыб в некоторых наборах данных...
Если описание неоднозначное или слишком пристрастное, например, «летучая мышь» (бита или бита?). Или «Cyprinodon diabolis», и ИИ запутается.
Это приводит к использованию больших моделей для выполнения ** обнаружения объектов**, особенно задач обнаружения объектов в открытом мире (неизвестная сцена), эффект часто не так хорош, как ожидалось.
Теперь статья, включенная в NeurIPS 2023, наконец-то решила эту проблему.
В эталонном наборе данных обнаружения LVIS MQ-Det повышает точность GLIP основных больших моделей обнаружения в среднем примерно на 7,8% и повышает точность 13 контрольных задач на малых выборках в среднем на 6,3%.
Как именно это делается? Давайте разберемся.
Ниже приводится цитата из автора статьи, блогера Zhihu @Qinyuanxia:
Содержание
MQ-Det: Большая модель обнаружения объектов в открытом мире для мультимодальных запросов**
Мультимодальное обнаружение запрашиваемых объектов в реальных условиях
Ссылка на статью:
Код адреса:**
Одна картинка стоит тысячи слов: С появлением графического предварительного обучения, с помощью открытой семантики текста, обнаружение объектов постепенно перешло в стадию восприятия открытого мира. По этой причине многие крупные модели обнаружения следуют шаблону текстового запроса, то есть используют категориальные текстовые описания для запроса потенциальных целей на целевых изображениях. Однако при таком подходе часто возникает проблема «широкого, но не утонченного».
Например, (1) обнаружение мелкозернистых объектов (мальков) на рисунке 1 часто затрудняет описание различных мелкозернистых видов с ограниченным количеством текста, и (2) неоднозначность категории («летучая мышь» может относиться как к летучей мыши, так и к ракетке).
Тем не менее, вышеуказанные проблемы могут быть решены с помощью примеров изображений, которые дают более богатые подсказки о признаках целевого объекта, чем текст, но в то же время текст имеет сильное обобщение.
Поэтому вопрос о том, как органично совместить два метода запроса, стал естественной идеей.
Трудности с получением возможностей мультимодальных запросов: Существует три проблемы, связанные с получением такой модели с помощью мультимодальных запросов: (1) Прямая тонкая настройка с ограниченным количеством примеров изображений может легко привести к катастрофическому забыванию; (2) Обучение большой модели обнаружения с нуля будет иметь хорошее обобщение, но огромное потребление, например, обучение одной карты GLIP требует 480 дней обучения с объемом данных 30 миллионов.
Детектирование объектов мультимодальных запросов: Исходя из вышеизложенных соображений, автор предлагает простую и эффективную стратегию проектирования и обучения модели - MQ-Det.
MQ-Det вставляет небольшое количество модулей зависимого восприятия (GCP) для получения входных визуальных примеров на основе существующей большой модели обнаружения запросов с замороженным текстом и разрабатывает стратегию обучения языка прогнозирования языка визуальных масок условий для эффективного получения детектора для высокопроизводительных мультимодальных запросов.
1.2 Архитектура мультимодальной модели запросов MQ-Det plug-and-play
** **####### △Рисунок 1 Схема архитектуры метода MQ-Det
**####### △Рисунок 1 Схема архитектуры метода MQ-Det
Модуль закрытого восприятия
Как показано на рисунке 1, автор послойно вставляет модуль осведомленности о стробировании (GCP) на сторону текстового кодировщика существующей большой модели обнаружения замороженных текстовых запросов, и режим работы GCP можно кратко представить следующей формулой:
1.3 Эффективная стратегия обучения MQ-Det
Обучение модуляции на основе детектора замороженных языковых запросов
Поскольку текущая предобучающая детектирование большой модели текстового запроса сама по себе обладает хорошим обобщением, авторы считают, что нужно лишь внести незначительные коррективы в визуальные детали на основе исходных текстовых особенностей.
В статье также приведена конкретная экспериментальная демонстрация того, что после вскрытия параметров исходной предварительно обученной модели и тонкой настройки легко вызвать катастрофическое забывание, но потеряв способность к обнаружению в открытом мире.
Таким образом, MQ-Det может эффективно вставлять визуальную информацию в детектор существующего текстового запроса на основе предварительно обученного детектора замороженного текстового запроса и модулировать только модуль GCP, вставленный путем обучения.
В работе авторы применяют методы структурного проектирования и обучения MQ-Det к текущим моделям SOTA GLIP и GroundingDINO соответственно для проверки универсальности метода.
Стратегия обучения прогнозированию языка маски с визуальным состоянием
Авторы также предлагают визуально обусловленную стратегию предиктивного обучения маскирующего языка для решения проблемы лени обучения, вызванной замораживанием предварительно обученных моделей.
Так называемая ленивая обучаемость означает, что детектор стремится сохранить характеристики исходного текстового запроса в процессе обучения, тем самым игнорируя вновь добавленные визуальные функции запроса.
Для этого MQ-Det используется случайным образом во время тренировки[MASK] token заменяет текстовый токен, заставляя модель обучаться со стороны функции визуального запроса, а именно:
1.4 Экспериментальные результаты: оценка без тонкой настройки
Без тонкой настройки: MQ-Det предлагает более практичную стратегию оценки: без тонкой настройки, по сравнению с традиционной оценкой с нуля, в которой используется только текст категории. Он определяется как обнаружение объектов с использованием текста категории, примеров изображений или комбинации того и другого без какой-либо последующей тонкой настройки.
При настройке без тонкой настройки MQ-Det выбирает 5 визуальных примеров для каждой категории и объединяет текст категории для обнаружения объектов, в то время как другие существующие модели не поддерживают визуальные запросы и могут использовать только обычные текстовые описания для обнаружения объектов. В таблице ниже приведены результаты LVIS MiniVal и LVIS v1.0. Можно обнаружить, что введение мультимодальных запросов значительно улучшило возможности обнаружения объектов в открытом мире.
**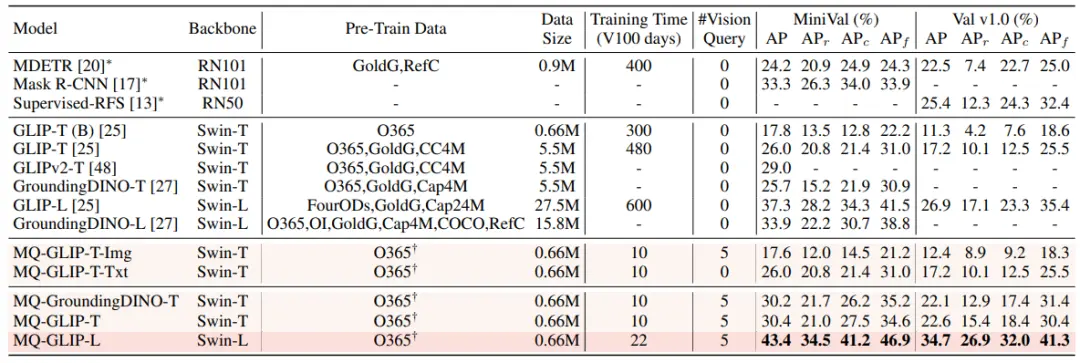 **###### △Таблица 1 Производительность каждой модели обнаружения без тонкой настройки в эталонном наборе данных LVIS
**###### △Таблица 1 Производительность каждой модели обнаружения без тонкой настройки в эталонном наборе данных LVIS
Как видно из таблицы 1, MQ-GLIP-L улучшил AP более чем на 7% на основе GLIP-L, и эффект очень значительный!
1.5 Экспериментальные результаты: оценка нескольких снимков
**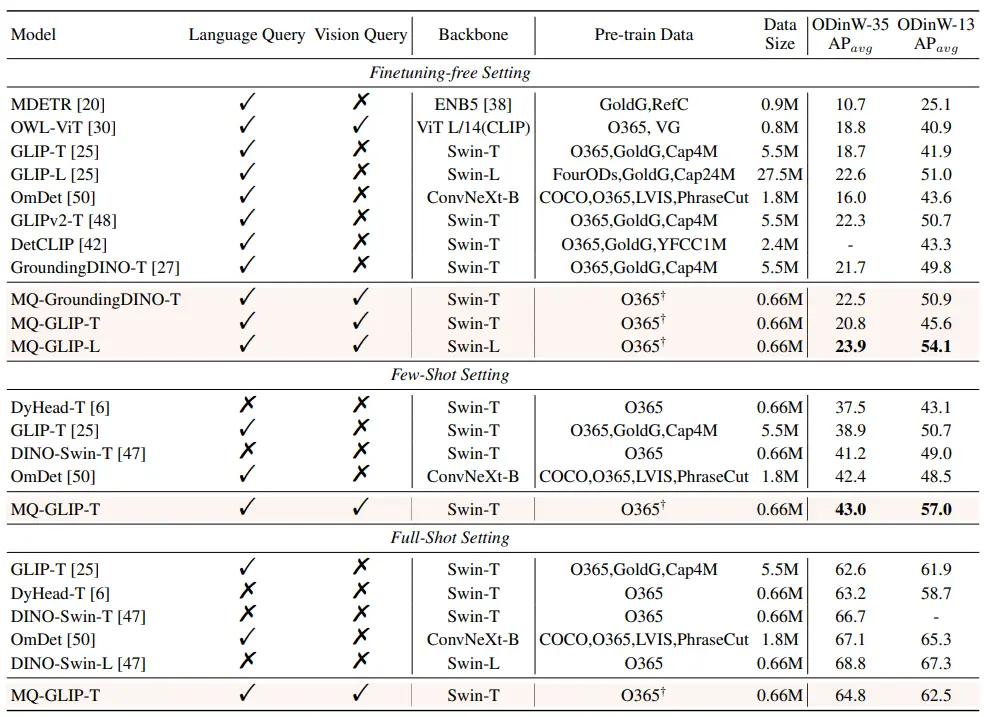 **####### △Таблица 2 Производительность каждой модели в ODinW-35 и 13 подмножествах ODinW-13 в 35 задачах обнаружения
**####### △Таблица 2 Производительность каждой модели в ODinW-35 и 13 подмножествах ODinW-13 в 35 задачах обнаружения
Кроме того, авторы провели комплексные эксперименты в ODinW-35, нисходящей задаче обнаружения 35. Как видно из таблицы 2, MQ-Det не только обладает высокой производительностью без тонкой настройки, но и обладает хорошими возможностями обнаружения малых выборок, что еще раз подтверждает потенциал мультимодальных запросов. На рисунке 2 также показано значительное улучшение MQ-Det по сравнению с GLIP.
**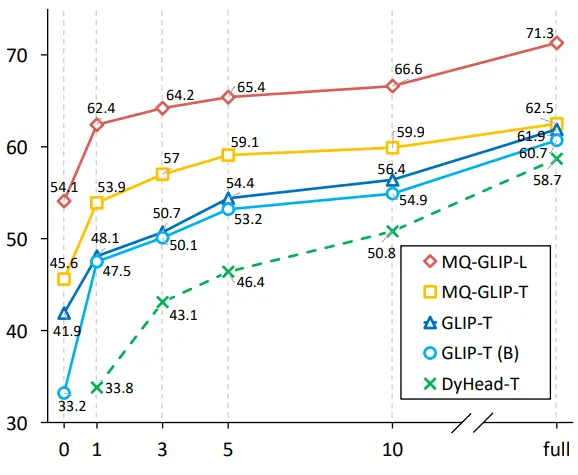 **###### △Рисунок 2 Сравнение эффективности использования данных; Горизонтальная ось: количество обучающих выборок, вертикальная ось: средняя АР на OdinW-13
**###### △Рисунок 2 Сравнение эффективности использования данных; Горизонтальная ось: количество обучающих выборок, вертикальная ось: средняя АР на OdinW-13
1.6 Перспективы обнаружения объектов мультимодальных запросов
Как область исследований, основанная на практических приложениях, обнаружение объектов уделяет большое внимание приземлению алгоритмов.
Несмотря на то, что предыдущая модель обнаружения объектов текстовых запросов показывает хорошее обобщение, в реальном китайском языке обнаружения открытого мира трудно охватить детальную информацию, и богатая детализация информации на изображении идеально дополняет эту связь.
До сих пор мы можем обнаружить, что текст является общим, но не точным, а изображение точным, но не общим, и если мы сможем эффективно объединить их, то есть мультимодальный запрос, это будет способствовать дальнейшему обнаружению объектов открытого мира.
MQ-Det сделал первый шаг в области мультимодальных запросов, и его значительное повышение производительности также свидетельствует о большом потенциале обнаружения целей мультимодальных запросов.
В то же время введение текстовых описаний и визуальных примеров предоставляет пользователям больше выбора, делая обнаружение объектов более гибким и удобным для пользователя.
Ссылка на оригинал: