Лучшая модель 7B снова переходит из рук в руки! Победите 70 миллиардов LLaMA2, и компьютеры Apple смогут работать|с открытым исходным кодом и бесплатно
Модель с 7 миллиардами параметров, на «настройку» которой ушло 500 долларов, победила 70-миллиардную модель Llama 2!
И записная книжка может работать легко, а эффект сравним с ChatGPT.
Важно: Бесплатно, без денег.
Модель с открытым исходным кодом Zephyr-7B, созданная командой HuggingFace H4, сумасшедшая.
Его базовой моделью является большая модель с открытым исходным кодом Mistral-7B, которая взорвалась некоторое время назад и была построена Mistral AI, которая известна как «европейский OpenAI».
Знаете, не прошло и 2-х недель после выхода Мистраля-7Б, как одна за другой появились различные доработанные версии, и есть много стиля "альпака", который быстро появился, когда Лама была впервые выпущена.
Ключом к способности Zephyr выделяться среди вариантов было то, что команда тонко настроила модель на общедоступном наборе данных, используя прямую оптимизацию предпочтений (DPO) поверх Mistral.
Команда также обнаружила, что удаление встроенного выравнивания набора данных может еще больше повысить производительность MT Bench. Оригинальный Zephyr-7B-alpha имел средний балл MT-Bench 7,09, превзойдя Llama2-70B-Chat.
** **####### △MT-Bench — это эталонный тест для оценки способности модели обрабатывать несколько раундов диалога, а набор вопросов охватывает 8 категорий, таких как письмо, ролевая игра и извлечение.
Дело в том, что затем он перешел к обновлению!
Команда H4 запустила второе поколение Zephyr-7B-beta. Они добавили, что исследовали идею извлечения выравнивания из GPT-4, Claude 2 и последующего внедрения его в малые модели, разработав метод использования оптимизации прямых предпочтений дистилляции (dDPO) для небольших моделей.
Во втором поколении Zephyr средний балл MT-Bench увеличился до 7,34.
На Alpaca у Zephyr 90.6% побед, что лучше, чем у ChatGPT (3.5):
Пользователи сети, которые бросились в Zephyr, дали единодушную похвалу, а команда lmsys также показала оценку Эло Zephyr-7b-beta, которая взлетела очень высоко 🔥:
Внутренняя таблица лидеров Арены превысила 13 млрд моделей.
Некоторые даже говорили:
То, что подход DPO хорошо работает в полевых условиях, вероятно, является самым захватывающим в разработке больших языковых моделей в этом году.
Все больше пользователей сети начали тестировать эффект Zephyr, и результаты оказались на удивление хорошими.
Слово «Мистраль» в переводе с французского означает сухой, холодный и сильный ветер, в то время как «зефир» означает мягкий, приятный западный ветер.
Нет никаких сомнений в том, что на другой стороне Ламы есть зоопарк, и нет никаких сомнений в том, что на этой стороне есть бюро погоды.
Лучшая модель 7B снова переходит из рук в руки
Начнем с требований к компьютеру для запуска Zephyr. Пользователи сети сказали, что «тайские штаны острые» после теста! , ноутбука (Apple M1 Pro) хватает, "результат очень хороший".
С точки зрения эффективности, команда Llama Index (ранее известная как GPT Index) также протестировала его.
Оказывается, что Zephyr в настоящее время является единственной моделью 7B с открытым исходным кодом, которая хорошо справляется с высокоуровневыми задачами RAG/agentic.
Данные также показывают, что эффект от продвинутой задачи RAG Zephyr может конкурировать с GPT-3.5 и Claude 2.
Они добавили, что Zephyr хорошо работает не только на RAG, но и при маршрутизации, планировании запросов, извлечении сложных SQL-операторов и извлечении структурированных данных.
Официальные лица также предоставили результаты испытаний, и на MT-Bench Zephyr-7B-beta имеет высокую производительность по сравнению с более крупными моделями, такими как Llama2-Chat-70B.
Но в более сложных задачах, таких как программирование и математика, Zephyr-7B-beta отстает от проприетарных моделей и требует дополнительных исследований, чтобы восполнить этот пробел.
Откажитесь от обучения с подкреплением
В то время как все тестируют эффекты Zephyr, разработчики говорят, что самое интересное — это не метрики, а то, как обучается модель.
Ниже приведена краткая информация об основных моментах:
Тонкая настройка лучшей маленькой предварительно обученной модели с открытым исходным кодом: Mistral 7B
Использование крупномасштабных наборов данных предпочтений: UltraFeedback
Используйте прямую оптимизацию предпочтений (DPO) вместо обучения с подкреплением
Неожиданно переобучение предпочтительного набора данных дает лучшие результаты
Вообще говоря, как упоминалось в начале, основная причина, по которой Zephyr способен превзойти 70B Llama 2, заключается в использовании специального метода тонкой настройки.
В отличие от традиционного подхода к обучению с подкреплением PPO, исследовательская группа использовала недавнее сотрудничество между Стэнфордским университетом и CZ Biohub, чтобы предложить подход DPO.
По мнению исследователей:
DPO намного стабильнее, чем PPO.
Простыми словами DPO можно объяснить следующим образом:
Для того, чтобы сделать выходные данные модели более соответствующими предпочтениям человека, традиционный подход заключался в тонкой настройке целевой модели с помощью модели вознаграждения. Если результат хороший, вы будете вознаграждены, а если результат плохой, вы не будете вознаграждены.
Подход DPO, с другой стороны, обходит функцию вознаграждения моделирования и эквивалентен оптимизации модели непосредственно на данных предпочтений.
В целом, DPO решает проблему сложного и дорогостоящего обучения с подкреплением за счет обратной связи с человеком.
Что касается конкретно обучения Zephyr, исследовательская группа первоначально настроила Zephyr-7B-alpha на оптимизированном варианте набора данных UltraChat, который содержит 1,6 миллиона разговоров, сгенерированных ChatGPT (осталось около 200 000).
(Причина рационализации заключалась в том, что команда обнаружила, что Zephyr иногда неправильно регистрируется, например, «Hi. Как дела?»; Иногда ответ начинается со слов «У меня нет личного Х». )
Позже они дополнительно согласовали модель с общедоступным набором данных openbmb/UltraFeedback, используя метод DPO Trainer TRL.
Набор данных содержит 64 000 пар «запрос-ответ» из различных моделей. Каждый ответ ранжируется GPT-4 на основе таких критериев, как полезность, и получает оценку, на основе которой выводятся предпочтения ИИ.
Интересным открытием является то, что при использовании метода DPO эффект на самом деле лучше после переобучения по мере увеличения времени обучения. Исследователи считают, что это похоже на переобучение в SFT.
Стоит отметить, что исследовательская группа также сообщила, что тонкая настройка модели этим методом стоит всего 500 долларов, что составляет 8 часов работы на 16 A100.
При обновлении Zephyr до бета-версии команда объяснила свой подход.
Они думали о тонкой настройке с контролем дистилляции (dSFT), используемой в больших моделях, но при таком подходе модель была смещена и не выдавала результат, который соответствовал замыслу пользователя.
Поэтому команда попыталась использовать данные о предпочтениях из AI Feedback (AIF) для ранжирования выходных данных с помощью «модели учителя» для формирования набора данных, а затем применить прямую оптимизацию предпочтений дистилляции (dDPO) для обучения модели, которая соответствовала намерениям пользователя, без какой-либо дополнительной выборки во время тонкой настройки.
Исследователи также проверили эффект, когда SFT не использовался, и результаты привели к значительному снижению производительности, что указывает на то, что шаг dSFT имеет решающее значение.
В настоящее время, в дополнение к тому, что модель была с открытым исходным кодом и коммерческой, есть также демо-версия, которую можно попробовать, так что мы можем начать и просто испытать ее.
Демо-версия
Во-первых, мне пришлось отойти от вопроса «умственно отсталый», чтобы пройти тест.
На вопрос «Мама и папа не берут меня, когда женятся», общий ответ Зефира более точен.
ChatGPT не может победить этот вопрос.
В тесте мы также обнаружили, что Zephyr также знает о недавних событиях, таких как выпуск GPT-4 от OpenAI:
На самом деле это связано с базовой моделью, хотя официальный представитель «Мистраля» не уточнил крайний срок подготовки данных.
Но некоторые пользователи сети тестировали его раньше, и он также знает об этом в марте этого года.
В отличие от этого, данные о предтренировочной подготовке Llama 2 относятся к сентябрю 2022 года, и только некоторые точные данные относятся к июню 2023 года.
Кроме того, Zephyr очень отзывчив, поэтому вы можете писать код и придумывать истории. :
Стоит упомянуть, что Zephyr лучше отвечает на вопросы на английском языке, а также имеет общую проблему с моделью «галлюцинации».
Исследователи также упоминали о галлюцинациях, а под полем ввода была отмечена небольшая строка текста, указывающая на то, что контент, сгенерированный моделью, может быть неточным или неверным.
Дело в том, что Zephyr не использует такие методы, как обучение с подкреплением и обратной связью от человека, чтобы соответствовать предпочтениям человека, а также не использует фильтрацию ответов ChatGPT.
Всегда выбирайте одну из рыб и медвежьих лап.
Zephyr смог сделать это всего с 70 миллиардами параметров, что удивило Андрея Буркова, автора «100-страничной книги по машинному обучению», и даже сказал:
Zephyr-7B побеждает Llama 2-70B с базовой моделью Mistral-7B с контекстным окном в 8 тысяч токенов, которая теоретически имеет диапазон внимания до 128 тысяч токенов.
Что, если бы Zephyr был моделью 70B? Превзойдет ли он GPT-4? Похоже на то, что это так.
Если вас заинтересовал Zephyr-7B, вы можете попробовать его на huggingface.
Ссылки на статьи:
Ссылки:
[1]
[2]
[3]
[4]
[5]
Посмотреть Оригинал
На этой странице может содержаться сторонний контент, который предоставляется исключительно в информационных целях (не в качестве заявлений/гарантий) и не должен рассматриваться как поддержка взглядов компании Gate или как финансовый или профессиональный совет. Подробности смотрите в разделе «Отказ от ответственности» .
Лучшая модель 7B снова переходит из рук в руки! Победите 70 миллиардов LLaMA2, и компьютеры Apple смогут работать|с открытым исходным кодом и бесплатно
Первоисточник: кубиты
Модель с 7 миллиардами параметров, на «настройку» которой ушло 500 долларов, победила 70-миллиардную модель Llama 2!
И записная книжка может работать легко, а эффект сравним с ChatGPT.
Важно: Бесплатно, без денег.
Модель с открытым исходным кодом Zephyr-7B, созданная командой HuggingFace H4, сумасшедшая.
Ключом к способности Zephyr выделяться среди вариантов было то, что команда тонко настроила модель на общедоступном наборе данных, используя прямую оптимизацию предпочтений (DPO) поверх Mistral.
Команда также обнаружила, что удаление встроенного выравнивания набора данных может еще больше повысить производительность MT Bench. Оригинальный Zephyr-7B-alpha имел средний балл MT-Bench 7,09, превзойдя Llama2-70B-Chat.
**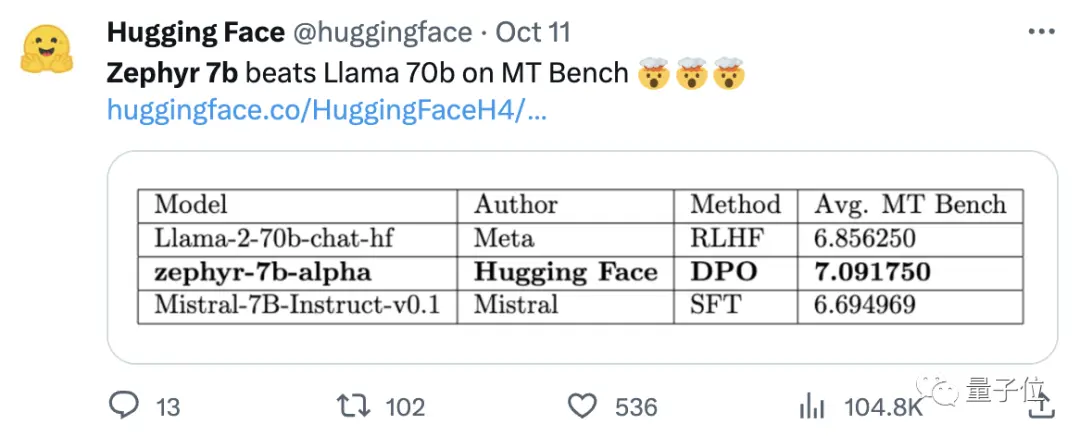 **####### △MT-Bench — это эталонный тест для оценки способности модели обрабатывать несколько раундов диалога, а набор вопросов охватывает 8 категорий, таких как письмо, ролевая игра и извлечение.
**####### △MT-Bench — это эталонный тест для оценки способности модели обрабатывать несколько раундов диалога, а набор вопросов охватывает 8 категорий, таких как письмо, ролевая игра и извлечение.
Дело в том, что затем он перешел к обновлению!
Команда H4 запустила второе поколение Zephyr-7B-beta. Они добавили, что исследовали идею извлечения выравнивания из GPT-4, Claude 2 и последующего внедрения его в малые модели, разработав метод использования оптимизации прямых предпочтений дистилляции (dDPO) для небольших моделей.
Во втором поколении Zephyr средний балл MT-Bench увеличился до 7,34.
Слово «Мистраль» в переводе с французского означает сухой, холодный и сильный ветер, в то время как «зефир» означает мягкий, приятный западный ветер.
Нет никаких сомнений в том, что на другой стороне Ламы есть зоопарк, и нет никаких сомнений в том, что на этой стороне есть бюро погоды.
Лучшая модель 7B снова переходит из рук в руки
Начнем с требований к компьютеру для запуска Zephyr. Пользователи сети сказали, что «тайские штаны острые» после теста! , ноутбука (Apple M1 Pro) хватает, "результат очень хороший".
Данные также показывают, что эффект от продвинутой задачи RAG Zephyr может конкурировать с GPT-3.5 и Claude 2.
Они добавили, что Zephyr хорошо работает не только на RAG, но и при маршрутизации, планировании запросов, извлечении сложных SQL-операторов и извлечении структурированных данных.
Откажитесь от обучения с подкреплением
В то время как все тестируют эффекты Zephyr, разработчики говорят, что самое интересное — это не метрики, а то, как обучается модель.
Ниже приведена краткая информация об основных моментах:
Вообще говоря, как упоминалось в начале, основная причина, по которой Zephyr способен превзойти 70B Llama 2, заключается в использовании специального метода тонкой настройки.
В отличие от традиционного подхода к обучению с подкреплением PPO, исследовательская группа использовала недавнее сотрудничество между Стэнфордским университетом и CZ Biohub, чтобы предложить подход DPO.
Простыми словами DPO можно объяснить следующим образом:
Для того, чтобы сделать выходные данные модели более соответствующими предпочтениям человека, традиционный подход заключался в тонкой настройке целевой модели с помощью модели вознаграждения. Если результат хороший, вы будете вознаграждены, а если результат плохой, вы не будете вознаграждены.
Подход DPO, с другой стороны, обходит функцию вознаграждения моделирования и эквивалентен оптимизации модели непосредственно на данных предпочтений.
В целом, DPO решает проблему сложного и дорогостоящего обучения с подкреплением за счет обратной связи с человеком.
Что касается конкретно обучения Zephyr, исследовательская группа первоначально настроила Zephyr-7B-alpha на оптимизированном варианте набора данных UltraChat, который содержит 1,6 миллиона разговоров, сгенерированных ChatGPT (осталось около 200 000).
(Причина рационализации заключалась в том, что команда обнаружила, что Zephyr иногда неправильно регистрируется, например, «Hi. Как дела?»; Иногда ответ начинается со слов «У меня нет личного Х». )
Позже они дополнительно согласовали модель с общедоступным набором данных openbmb/UltraFeedback, используя метод DPO Trainer TRL.
Набор данных содержит 64 000 пар «запрос-ответ» из различных моделей. Каждый ответ ранжируется GPT-4 на основе таких критериев, как полезность, и получает оценку, на основе которой выводятся предпочтения ИИ.
Интересным открытием является то, что при использовании метода DPO эффект на самом деле лучше после переобучения по мере увеличения времени обучения. Исследователи считают, что это похоже на переобучение в SFT.
Они думали о тонкой настройке с контролем дистилляции (dSFT), используемой в больших моделях, но при таком подходе модель была смещена и не выдавала результат, который соответствовал замыслу пользователя.
Исследователи также проверили эффект, когда SFT не использовался, и результаты привели к значительному снижению производительности, что указывает на то, что шаг dSFT имеет решающее значение.
Демо-версия
Во-первых, мне пришлось отойти от вопроса «умственно отсталый», чтобы пройти тест.
На вопрос «Мама и папа не берут меня, когда женятся», общий ответ Зефира более точен.
Но некоторые пользователи сети тестировали его раньше, и он также знает об этом в марте этого года.
Кроме того, Zephyr очень отзывчив, поэтому вы можете писать код и придумывать истории. :
Исследователи также упоминали о галлюцинациях, а под полем ввода была отмечена небольшая строка текста, указывающая на то, что контент, сгенерированный моделью, может быть неточным или неверным.
Всегда выбирайте одну из рыб и медвежьих лап.
Zephyr смог сделать это всего с 70 миллиардами параметров, что удивило Андрея Буркова, автора «100-страничной книги по машинному обучению», и даже сказал:
Ссылки на статьи:
Ссылки:
[1]
[2]
[3]
[4]
[5]