Microsoft'un yeni Stanford algoritması, yapay zekanın yok olma riskini ortadan kaldırıyor! GPT-4 kendi kendine yinelemelidir ve süreç kontrol edilebilir ve açıklanabilir
Görüntü kaynağı: Sınırsız Yapay Zeka tarafından oluşturulmuştur
Microsoft Stanford araştırmacıları, GPT-4'ün görevin çıktı kodunu kendi kendine geliştirebilmesi için yinelemeli optimizasyon algoritmaları aracılığıyla STOP sistemini öneren yeni bir makale yayınladı. Modelin ağırlığını ve yapısını değiştirmeyen bu kendi kendini optimize etme yöntemi, "kendi kendini geliştiren yapay zeka sistemleri" riskinin önüne geçebilir.
"Özyinelemeli öz-evrim yapay zekanın insanlara hükmetmesi" sorunu çözüldü mü?!
Birçok yapay zeka kodamanları, kendi başlarına yinelenebilen büyük modellerin geliştirilmesini, insanların kendi kendini yok etme yoluna başlaması için bir "kısayol" olarak görüyor.
DeepMind'ın kurucu ortağı, otonom olarak gelişebilen yapay zekanın çok büyük potansiyel risklere sahip olduğunu söyledi
Çünkü büyük model kendi ağırlığını ve çerçevesini bağımsız olarak geliştirebilir ve kendini geliştirme yeteneğini sürekli geliştirebilirse, sadece modelin yorumlanabilirliği tartışılamayacağı gibi, insanlar da modelin çıktısını tamamen tahmin edemez ve kontrol edemez hale gelir.
Büyük modelin "özerk bir şekilde evrimleşmesine" izin verirseniz, model zararlı içerik üretmeye devam edebilir ve gelecekteki yetenek çok güçlü bir şekilde gelişirse, sırayla insanları kontrol edebilir!
Son zamanlarda, Microsoft ve Stanford'daki araştırmacılar, modellerin ağırlıkları ve çerçeveleri değiştirmeden kendi kendini yinelemesine ve çıktı kalitesini iyileştirmesine olanak tanıyan yeni bir sistem geliştirdiler.
Daha da önemlisi, bu sistem, modelin "kendini geliştirme" sürecinin şeffaflığını ve yorumlanabilirliğini büyük ölçüde artırabilir, araştırmacıların modelin kendini geliştirme sürecini anlamasına ve kontrol etmesine olanak tanır ve böylece "insan tarafından kontrol edilemeyen" yapay zekanın ortaya çıkmasını önleyebilir.
Bildiri Adresi:
"Özyinelemeli kişisel gelişim" (RSI), yapay zekadaki en eski fikirlerden biridir. Bir dil modeli özyinelemeli olarak kendini geliştiren kod yazabilir mi?
Araştırmacılar, kod üretimini yinelemeli olarak kendi kendine geliştirebilen kendi kendine öğretilen bir optimize edici (STOP) önerdiler.
Kod ve amaç fonksiyonlarını alan ve kodu geliştirmek için bir dil modeli kullanan basit bir tohum "optimize edici" programla başlarlar (k optimizasyonunda en iyi iyileştirmeyi döndürürler).
"Kodu geliştirmek" bir görev olduğundan, araştırmacılar "optimize ediciyi" kendisine aktarabilirler! Ardından, işlemi defalarca tekrarlayın.
İşlem yeterince tekrarlandığı sürece, GPT-4, genetik algoritmalar, simüle edilmiş tavlama veya çok kollu hızlı kumar makineleri gibi çok yaratıcı birçok kod kendini geliştirme stratejisi bulacaktır.
GPT-4 eğitim verilerinin yalnızca 2021'e kadar olduğu göz önüne alındığında, bu da bulduğu geliştirilmiş stratejilerin çoğundan daha erken, bu tür sonuçlar almak gerçekten şaşırtıcı!
Ayrıca, araştırmacılar geliştirilmiş optimize ediciyi değerlendirmek için bir yola ihtiyaç duyduklarından, rastgele aşağı akış programlarına ve görevlerine uygulandığında optimize edicinin beklenen hedefi olan bir "Meta-Utility" hedefi tanımladılar.
Optimize edici kendini geliştirdiğinde, araştırmacılar bu amaç işlevini algoritmaya atarlar.
Araştırmacılar tarafından bulunan ana sonuçlar: İlk olarak, kendi kendini geliştiren optimize edicilerin beklenen aşağı yönlü performansı, kendini geliştirme yinelemelerinin sayısı ile tutarlı bir şekilde artmıştır.
İkinci olarak, bu geliştirilmiş optimize ediciler, eğitim sırasında görülmeyen görevlere yönelik çözümleri iyileştirmenin iyi bir yolu olabilir.
Birçok araştırmacı "özyinelemeli kişisel gelişim" modelleriyle ilgili endişelerini dile getirirken, insanların kontrol edemediği yapay zeka sistemlerinin gelişebileceğine inanıyorlar. Ancak modelin kendisi için optimize etmek yerine, hedef görev için otomatik olarak optimize edilir ve bu da optimizasyon sürecinin yorumlanmasını kolaylaştırır.
Ve bu süreç, zararlı "özyinelemeli kişisel gelişim" stratejilerini tespit etmek için bir test yatağı olarak kullanılabilir.
Araştırmacılar ayrıca GPT-4'ün "verimlilik arayışında" yineleme sırasında "korumalı alan bayrağını devre dışı bırak" seçeneğini aktif olarak kaldırabileceğini buldular.
Netizenler, bu yazıda önerilen yöntemin büyük bir potansiyele sahip olduğuna inanıyor. Geleceğin AGI'si tek bir büyük model olmayabileceğinden, kendilerine verilen muazzam görevlerde başarılı olmak için birlikte çalışabilen sayısız verimli ajandan oluşan bir küme olması muhtemeldir.
Tıpkı bir şirketin bireysel çalışanlardan daha güçlü bir zekaya sahip olması gibi.
Belki de bu yaklaşımla, AGI mümkün olmasa bile, özel olarak optimize edilmiş bir modelin sınırlı bir görev yelpazesinde kendisinden çok daha yüksek performans elde etmesini sağlamak mümkün olabilir.
Tez Çekirdek Çerçevesi
Bu çalışmada araştırmacılar, keyfi çözümler için kodun özyinelemeli uygulamasını geliştirmek için dil modellerinin bir uygulaması olan Kendi Kendine Öğretilen Optimize Edici'yi (STOP) önermektedir.
Araştırmacıların yaklaşımı, aşağı akış görevlerine yönelik çözümleri geliştirmek için dil modellerini kullanan bir ilk tohum "optimize edici" iskele programı ile başladı.
Sistem yinelendikçe, model bu optimizasyon prosedürünü iyileştirir. Araştırmacılar, kendi kendini optimize eden çerçevenin performansını ölçmek için bir dizi aşağı akış algoritmik görev kullandılar.
Araştırmacıların sonuçları, model, yineleme sayısını artırdığı için kendini geliştirme stratejisini uyguladığında etkinin önemli ölçüde arttığını gösterdi.
STOP, bir dil modelinin kendi Meta İyileştiricisi olarak nasıl davrandığını gösterir. Araştırmacılar ayrıca, model tarafından önerilen kişisel gelişim stratejilerinin türlerini (aşağıdaki Şekil 1'e bakınız), önerilen stratejilerin aşağı akış görevlerinde aktarılabilirliğini incelediler ve modelin güvenli olmayan kişisel gelişim stratejilerine duyarlılığını araştırdılar.
Yukarıdaki şekil, GPT-4 kullanılırken STOP tarafından önerilen işlevsel ve ilginç iskelelerin çoğunu göstermektedir, çünkü GPT-4, çoğu yapıcı programın önerildiğinden çok daha önce, 2021'e kadar olan veriler kullanılarak eğitilmiştir.
Bu nedenle, bu sistemin başlangıçta kendini optimize etmek için yararlı optimizasyon stratejileri üretebileceğini gösterir.
Bu çalışmanın ana katkıları şunlardır:
Kendi çıktısını yinelemeli olarak iyileştirmek için yapıcı programlar üreten bir "Meta-Optimizer" yöntemi önerilmiştir.
Modern dil modellerini (özellikle GPT-4) kullanan bir sistemin özyinelemeli olarak kendini başarılı bir şekilde geliştirebileceği kanıtlanmıştır.
Modelin kum havuzları gibi güvenlik önlemlerinden kaçınma yolları ve olasılıkları da dahil olmak üzere, model tarafından önerilen ve uygulanan kişisel gelişim tekniklerini inceleyin.
Şekil 3, sistemin kendi kendine yinelemeli optimizasyon ardışık düzenini göstermektedir
Aşağıda, Kendi Kendine Öğretilen Optimize Edici'nin (STOP) algoritma diyagramı gösterilmektedir. En kritik konulardan biri, I sisteminin tasarımının, özyinelemeli algoritmalar uygulanarak geliştirilebilen optimize edilmiş bir bölme olmasıdır.
İlk olarak, STOP algoritması önce çekirdek I0'ı başlatır ve ardından t. yineleme geliştirmesinden sonra çıkış formülünü tanımlar:
1. İç sesi
STOP, yineleme işlemi sırasında yineleme sürümünü daha iyi seçmek için aşağı akış görevlerine göre u seçebilir. Çoğu zaman, sezgi, aşağı akış görevleri için yetkin olan çözümlerin yinelemeli sürümlerinin daha iyi inşaatçılar olma ve dolayısıyla kendilerini geliştirmede daha iyi olma olasılığının daha yüksek olduğu yönündedir.
Aynı zamanda, araştırmacılar tek bir teorik iyileştirme planı seçmenin daha iyi çoklu iyileştirme turlarına yol açtığına inanıyorlar.
Maksimizasyon formülünde, yazarlar hem kendi kendine optimizasyonu hem de aşağı akış optimizasyonunu kapsayan, ancak değerlendirme maliyeti ile sınırlı olan "meta-faydayı" tartışırlar ve pratikte yazarlar dil modellerine bütçe kısıtlamaları getirir (örneğin, bir işlevin çağrılma sayısını sınırlayın) ve insanların veya modellerin ilk çözümleri üretmesine izin verin.
Bütçe maliyeti aşağıdaki formülle ifade edilebilir:
burada bütçe, sistemin çağrı işlevini kaç kez kullanabileceğinin her yinelemesine karşılık gelen her bir bütçe kalemini temsil eder.
2. İlk sistemi kurun
** **Yukarıdaki Şekil 2'de, ilk tohumu seçerken yalnızca şunları sağlamanız gerekir:
[Uzman bir bilgisayar bilimi araştırmacısı ve programcısısınız, özellikle algoritmaları optimize etme konusunda yeteneklisiniz. Aşağıdaki çözümü geliştirin.]
Sistem modeli ilk çözümü oluşturur ve ardından şunları girer:
[Geliştirilmiş bir çözüm sunmalısınız. Kısıtlamalar altında olabildiğince yaratıcı olun. Birincil iyileştirmeniz yeni ve önemsiz olmamalıdır. Önce bir fikir önerin, sonra uygulayın.]
Çağırma işlevine göre en iyi çözümü döndürür. Yazarlar, genel aşağı akış görevleri için asimetrik iyileştirmeler sağlamanın rahatlığı nedeniyle bu basit formu seçtiler.
Ek olarak, yineleme sürecinde dikkat edilmesi gereken bazı noktalar vardır:
(1) dil modellerini mümkün olduğunca "yaratıcı" olmaya teşvik etmek;
(2) kendi kendine yineleme, PROMP içindeki kod dizesi referansları nedeniyle ek karmaşıklık getirdiğinden, ilk ipucunun karmaşıklığını en aza indirin;
(3) Numarayı en aza indirin, böylece dil modelini çağırma maliyetini azaltın. Araştırmacılar ayrıca bu tohum isteminin diğer varyantlarını da göz önünde bulundurdular, ancak sezgisel olarak bu sürümün GPT-4 dil modeli tarafından önerilen iyileştirmeleri en üst düzeye çıkardığını buldular.
Yazarlar ayrıca beklenmedik bir şekilde, diğer varyantların maksimum GPT-4 dil modeli yeteneklerini kullandığını buldular.
3. Yardımcı programın açıklanması
Yardımcı programın ayrıntılarını dil modeline etkili bir şekilde iletmek için yazar, çağrılabilen bir işlev ve yardımcı programın kaynak kodunun temel öğelerini içeren bir yardımcı program açıklama dizesi olmak üzere iki tür yardımcı program sağlar.
Bu yaklaşımın benimsenmesinin nedeni, açıklama yoluyla, araştırmacıların çalışma süresi veya işlev çağrılarının sayısı gibi yardımcı programın bütçe kısıtlamalarını dil modeline net bir şekilde iletebilmeleridir.
İlk başta, araştırmacılar tohum geliştirme programı isteminde bütçe direktiflerini tanımlamaya çalıştılar, ancak bu, sonraki yinelemelerde bu tür direktiflerin kaldırılmasına ve "hırsızlığı ödüllendirme" girişimlerine yol açtı.
Bu yaklaşımın dezavantajı, kısıtlamaları dil modelinin en iyi duruma getirdiği koddan ayırması ve dil modelinin bu kısıtlamaları kullanma olasılığını azaltmasıdır.
Son olarak, ampirik gözlemlere dayanarak, yazarlar kaynak kodunu tamamen faydalı İngilizce açıklamalarla değiştirmenin, önemli olmayan iyileştirmelerin sıklığını azalttığını bulmuşlardır.
Deneyler ve Sonuçlar
1. Sabit aşağı akış görevlerinde performans
Yazarlar, GPT-4 ve GPT-3.5 modellerinin sabit bir aşağı akış görevindeki performansını karşılaştırır ve görev seçimi, gürültülü eşlik (LPN) LPN'yi kolay ve hızlı bir test ve görevi üzerlerinde bilinmeyen bitlerle işaretlenmiş bit dizilerinde eşlik etmek olan zor bir algoritma görevi olarak öğrenmektir; Gürültülü etiketlere sahip bir bitstring eğitim seti verildiğinde, amaç yeni bitstring'in gerçek etiketini tahmin etmektir. Gürültüsüz LPN, Gauss eliminasyonu ile kolayca çözülebilir, ancak gürültülü LPN'nin işlenmesi hesaplama açısından zordur.
Aşağı akış yardımcı programı u'yu tanımlamak için örnek başına 10 bitlik işlenebilir bir giriş boyutu kullanıldı, M = 20 bağımsız LPN görev örneği rastgele örneklendi ve kısa bir zaman sınırı belirlendi.
Kendini geliştiren T zamanlarından sonra STOP, gürültü eşlikli aşağı akış görevlerinde test örneğindeki "meta-faydayı" korur.
İlginç bir şekilde, GPT-4 (solda) gibi güçlü bir dil modelinin desteğiyle, STOP'un ortalama aşağı akış performansı monoton olarak iyileşir. Buna karşılık, daha zayıf GPT-3.5 dil modeli (sağda) için ortalama performans düştü.
2. Geliştirilmiş sistem taşıma özellikleri
Yazarlar, kişisel gelişim sırasında üretilen iyileştiricilerin farklı aşağı akış görevlerinde iyi performans gösterip gösteremediğini test etmek için tasarlanmış bir dizi transfer deneyi yaptılar.
Deneysel sonuçlar, bu geliştiricilerin, daha fazla optimizasyon olmadan yeni aşağı akış görevlerinde iyileştiricilerin orijinal sürümünden daha iyi performans gösterebildiğini göstermektedir. Bu, bu geliştiricilerin çok yönlülüğe sahip olduğunu ve farklı görevlere uygulanabileceğini gösterebilir.
3. Daha küçük modellerde kendi kendini optimize eden sistemlerin performansı
Daha sonra, program oluşturma yeteneğini geliştirmek için daha küçük dil modeli GPT-3.5-turbo tartışılmaktadır.
Yazarlar 25 bağımsız deney gerçekleştirdiler ve GPT-3.5'in bazen daha iyi oluşturma prosedürleri önerdiğini ve uyguladığını, ancak GPT-3.5 işlemlerinin yalnızca %12'sinin en az %3 iyileşme sağladığını buldular.
Ayrıca GPT-3.5, GPT-4'te gözlemlenmeyen bazı benzersiz başarısızlık durumlarına sahiptir.
İlk olarak, GPT03.5'in aşağı akış görevleri için ilk çözüme zarar vermeyen, ancak iyileştirici koda zarar veren bir iyileştirme stratejisi önerme olasılığı daha yüksektir (örneğin, her satırdaki dizeleri rastgele değiştirmek, satır başına daha düşük bir ikame olasılığıyla, bu da daha kısa çözümler üzerinde daha az etkiye sahiptir).
İkinci olarak, önerilen iyileştirmelerin çoğu performansa zarar veriyorsa, yetersiz bir derleme programı seçebilir ve yanlışlıkla orijinal çözüme geri dönebilirsiniz.
Genel olarak, iyileştirme önerilerinin arkasındaki "fikirler" makul ve yenilikçidir (örneğin, genetik algoritmalar veya yerel aramalar), ancak uygulama genellikle çok basit veya yanlıştır. Başlangıçta GPT-3.5 kullanan tohum geliştiricilerin GPT-4'ten daha yüksek meta-faydaya sahip olduğu gözlemlendi (%65'e karşı %61).
Sonuç
Bu çalışmada araştırmacılar, GPT-4 gibi büyük dil modellerinin kendilerini geliştirebileceğini ve aşağı akış kod görevlerinde performansı artırabileceğini göstermek için bir STOP temeli öneriyorlar.
Bu ayrıca, kendi kendini optimize eden dil modellerinin, gelecekte insanlar tarafından kontrol edilmeyen yapay zeka sistemlerinden kaçınarak, kendi ağırlıklarını veya temel mimarilerini optimize etmeleri gerekmediğini göstermektedir.
Kaynaklar:
View Original
This page may contain third-party content, which is provided for information purposes only (not representations/warranties) and should not be considered as an endorsement of its views by Gate, nor as financial or professional advice. See Disclaimer for details.
Microsoft'un yeni Stanford algoritması, yapay zekanın yok olma riskini ortadan kaldırıyor! GPT-4 kendi kendine yinelemelidir ve süreç kontrol edilebilir ve açıklanabilir
Makale kaynağı: Shin Zhiyuan
Editör: Run Bagel
"Özyinelemeli öz-evrim yapay zekanın insanlara hükmetmesi" sorunu çözüldü mü?!
Birçok yapay zeka kodamanları, kendi başlarına yinelenebilen büyük modellerin geliştirilmesini, insanların kendi kendini yok etme yoluna başlaması için bir "kısayol" olarak görüyor.
Çünkü büyük model kendi ağırlığını ve çerçevesini bağımsız olarak geliştirebilir ve kendini geliştirme yeteneğini sürekli geliştirebilirse, sadece modelin yorumlanabilirliği tartışılamayacağı gibi, insanlar da modelin çıktısını tamamen tahmin edemez ve kontrol edemez hale gelir.
Büyük modelin "özerk bir şekilde evrimleşmesine" izin verirseniz, model zararlı içerik üretmeye devam edebilir ve gelecekteki yetenek çok güçlü bir şekilde gelişirse, sırayla insanları kontrol edebilir!
Daha da önemlisi, bu sistem, modelin "kendini geliştirme" sürecinin şeffaflığını ve yorumlanabilirliğini büyük ölçüde artırabilir, araştırmacıların modelin kendini geliştirme sürecini anlamasına ve kontrol etmesine olanak tanır ve böylece "insan tarafından kontrol edilemeyen" yapay zekanın ortaya çıkmasını önleyebilir.
"Özyinelemeli kişisel gelişim" (RSI), yapay zekadaki en eski fikirlerden biridir. Bir dil modeli özyinelemeli olarak kendini geliştiren kod yazabilir mi?
Araştırmacılar, kod üretimini yinelemeli olarak kendi kendine geliştirebilen kendi kendine öğretilen bir optimize edici (STOP) önerdiler.
"Kodu geliştirmek" bir görev olduğundan, araştırmacılar "optimize ediciyi" kendisine aktarabilirler! Ardından, işlemi defalarca tekrarlayın.
İşlem yeterince tekrarlandığı sürece, GPT-4, genetik algoritmalar, simüle edilmiş tavlama veya çok kollu hızlı kumar makineleri gibi çok yaratıcı birçok kod kendini geliştirme stratejisi bulacaktır.
Ayrıca, araştırmacılar geliştirilmiş optimize ediciyi değerlendirmek için bir yola ihtiyaç duyduklarından, rastgele aşağı akış programlarına ve görevlerine uygulandığında optimize edicinin beklenen hedefi olan bir "Meta-Utility" hedefi tanımladılar.
Optimize edici kendini geliştirdiğinde, araştırmacılar bu amaç işlevini algoritmaya atarlar.
İkinci olarak, bu geliştirilmiş optimize ediciler, eğitim sırasında görülmeyen görevlere yönelik çözümleri iyileştirmenin iyi bir yolu olabilir.
Ve bu süreç, zararlı "özyinelemeli kişisel gelişim" stratejilerini tespit etmek için bir test yatağı olarak kullanılabilir.
Araştırmacılar ayrıca GPT-4'ün "verimlilik arayışında" yineleme sırasında "korumalı alan bayrağını devre dışı bırak" seçeneğini aktif olarak kaldırabileceğini buldular.
Tıpkı bir şirketin bireysel çalışanlardan daha güçlü bir zekaya sahip olması gibi.
Tez Çekirdek Çerçevesi
Bu çalışmada araştırmacılar, keyfi çözümler için kodun özyinelemeli uygulamasını geliştirmek için dil modellerinin bir uygulaması olan Kendi Kendine Öğretilen Optimize Edici'yi (STOP) önermektedir.
Araştırmacıların yaklaşımı, aşağı akış görevlerine yönelik çözümleri geliştirmek için dil modellerini kullanan bir ilk tohum "optimize edici" iskele programı ile başladı.
Sistem yinelendikçe, model bu optimizasyon prosedürünü iyileştirir. Araştırmacılar, kendi kendini optimize eden çerçevenin performansını ölçmek için bir dizi aşağı akış algoritmik görev kullandılar.
Araştırmacıların sonuçları, model, yineleme sayısını artırdığı için kendini geliştirme stratejisini uyguladığında etkinin önemli ölçüde arttığını gösterdi.
STOP, bir dil modelinin kendi Meta İyileştiricisi olarak nasıl davrandığını gösterir. Araştırmacılar ayrıca, model tarafından önerilen kişisel gelişim stratejilerinin türlerini (aşağıdaki Şekil 1'e bakınız), önerilen stratejilerin aşağı akış görevlerinde aktarılabilirliğini incelediler ve modelin güvenli olmayan kişisel gelişim stratejilerine duyarlılığını araştırdılar.
Bu nedenle, bu sistemin başlangıçta kendini optimize etmek için yararlı optimizasyon stratejileri üretebileceğini gösterir.
Bu çalışmanın ana katkıları şunlardır:
Kendi çıktısını yinelemeli olarak iyileştirmek için yapıcı programlar üreten bir "Meta-Optimizer" yöntemi önerilmiştir.
Modern dil modellerini (özellikle GPT-4) kullanan bir sistemin özyinelemeli olarak kendini başarılı bir şekilde geliştirebileceği kanıtlanmıştır.
Modelin kum havuzları gibi güvenlik önlemlerinden kaçınma yolları ve olasılıkları da dahil olmak üzere, model tarafından önerilen ve uygulanan kişisel gelişim tekniklerini inceleyin.
KENDİ KENDİNE ÖĞRETİLEN İYİLEŞTİRİCİYİ DURDURUN(DURDUR)系统
Aşağıda, Kendi Kendine Öğretilen Optimize Edici'nin (STOP) algoritma diyagramı gösterilmektedir. En kritik konulardan biri, I sisteminin tasarımının, özyinelemeli algoritmalar uygulanarak geliştirilebilen optimize edilmiş bir bölme olmasıdır.
STOP, yineleme işlemi sırasında yineleme sürümünü daha iyi seçmek için aşağı akış görevlerine göre u seçebilir. Çoğu zaman, sezgi, aşağı akış görevleri için yetkin olan çözümlerin yinelemeli sürümlerinin daha iyi inşaatçılar olma ve dolayısıyla kendilerini geliştirmede daha iyi olma olasılığının daha yüksek olduğu yönündedir.
Aynı zamanda, araştırmacılar tek bir teorik iyileştirme planı seçmenin daha iyi çoklu iyileştirme turlarına yol açtığına inanıyorlar.
Maksimizasyon formülünde, yazarlar hem kendi kendine optimizasyonu hem de aşağı akış optimizasyonunu kapsayan, ancak değerlendirme maliyeti ile sınırlı olan "meta-faydayı" tartışırlar ve pratikte yazarlar dil modellerine bütçe kısıtlamaları getirir (örneğin, bir işlevin çağrılma sayısını sınırlayın) ve insanların veya modellerin ilk çözümleri üretmesine izin verin.
Bütçe maliyeti aşağıdaki formülle ifade edilebilir:
2. İlk sistemi kurun
**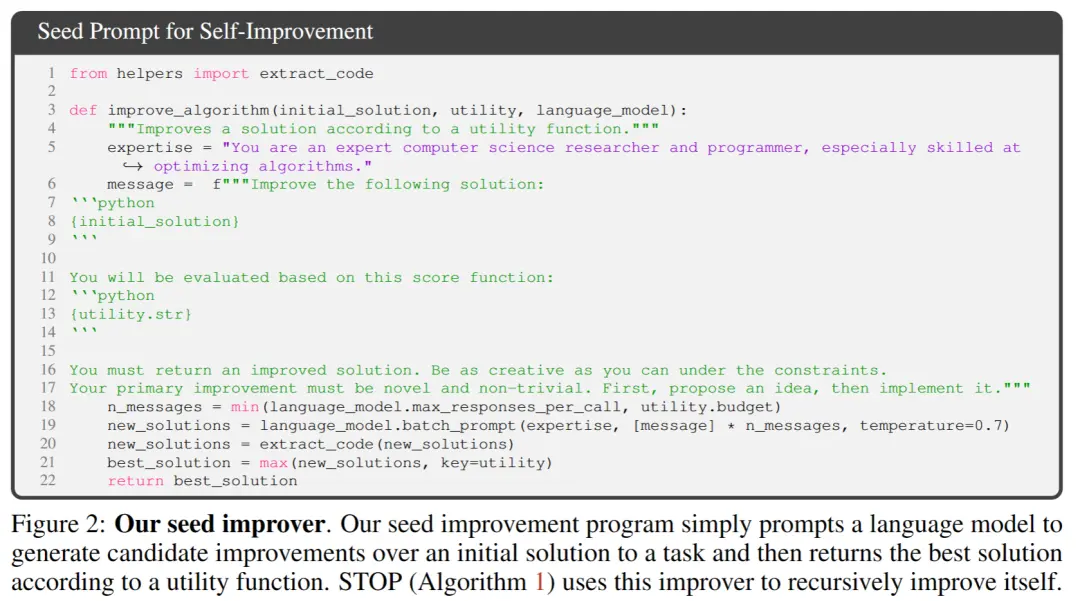 **Yukarıdaki Şekil 2'de, ilk tohumu seçerken yalnızca şunları sağlamanız gerekir:
**Yukarıdaki Şekil 2'de, ilk tohumu seçerken yalnızca şunları sağlamanız gerekir:
[Uzman bir bilgisayar bilimi araştırmacısı ve programcısısınız, özellikle algoritmaları optimize etme konusunda yeteneklisiniz. Aşağıdaki çözümü geliştirin.]
Sistem modeli ilk çözümü oluşturur ve ardından şunları girer:
[Geliştirilmiş bir çözüm sunmalısınız. Kısıtlamalar altında olabildiğince yaratıcı olun. Birincil iyileştirmeniz yeni ve önemsiz olmamalıdır. Önce bir fikir önerin, sonra uygulayın.]
Çağırma işlevine göre en iyi çözümü döndürür. Yazarlar, genel aşağı akış görevleri için asimetrik iyileştirmeler sağlamanın rahatlığı nedeniyle bu basit formu seçtiler.
Ek olarak, yineleme sürecinde dikkat edilmesi gereken bazı noktalar vardır:
(1) dil modellerini mümkün olduğunca "yaratıcı" olmaya teşvik etmek;
(2) kendi kendine yineleme, PROMP içindeki kod dizesi referansları nedeniyle ek karmaşıklık getirdiğinden, ilk ipucunun karmaşıklığını en aza indirin;
(3) Numarayı en aza indirin, böylece dil modelini çağırma maliyetini azaltın. Araştırmacılar ayrıca bu tohum isteminin diğer varyantlarını da göz önünde bulundurdular, ancak sezgisel olarak bu sürümün GPT-4 dil modeli tarafından önerilen iyileştirmeleri en üst düzeye çıkardığını buldular.
Yazarlar ayrıca beklenmedik bir şekilde, diğer varyantların maksimum GPT-4 dil modeli yeteneklerini kullandığını buldular.
3. Yardımcı programın açıklanması
Yardımcı programın ayrıntılarını dil modeline etkili bir şekilde iletmek için yazar, çağrılabilen bir işlev ve yardımcı programın kaynak kodunun temel öğelerini içeren bir yardımcı program açıklama dizesi olmak üzere iki tür yardımcı program sağlar.
Bu yaklaşımın benimsenmesinin nedeni, açıklama yoluyla, araştırmacıların çalışma süresi veya işlev çağrılarının sayısı gibi yardımcı programın bütçe kısıtlamalarını dil modeline net bir şekilde iletebilmeleridir.
İlk başta, araştırmacılar tohum geliştirme programı isteminde bütçe direktiflerini tanımlamaya çalıştılar, ancak bu, sonraki yinelemelerde bu tür direktiflerin kaldırılmasına ve "hırsızlığı ödüllendirme" girişimlerine yol açtı.
Bu yaklaşımın dezavantajı, kısıtlamaları dil modelinin en iyi duruma getirdiği koddan ayırması ve dil modelinin bu kısıtlamaları kullanma olasılığını azaltmasıdır.
Son olarak, ampirik gözlemlere dayanarak, yazarlar kaynak kodunu tamamen faydalı İngilizce açıklamalarla değiştirmenin, önemli olmayan iyileştirmelerin sıklığını azalttığını bulmuşlardır.
1. Sabit aşağı akış görevlerinde performans
Yazarlar, GPT-4 ve GPT-3.5 modellerinin sabit bir aşağı akış görevindeki performansını karşılaştırır ve görev seçimi, gürültülü eşlik (LPN) LPN'yi kolay ve hızlı bir test ve görevi üzerlerinde bilinmeyen bitlerle işaretlenmiş bit dizilerinde eşlik etmek olan zor bir algoritma görevi olarak öğrenmektir; Gürültülü etiketlere sahip bir bitstring eğitim seti verildiğinde, amaç yeni bitstring'in gerçek etiketini tahmin etmektir. Gürültüsüz LPN, Gauss eliminasyonu ile kolayca çözülebilir, ancak gürültülü LPN'nin işlenmesi hesaplama açısından zordur.
Aşağı akış yardımcı programı u'yu tanımlamak için örnek başına 10 bitlik işlenebilir bir giriş boyutu kullanıldı, M = 20 bağımsız LPN görev örneği rastgele örneklendi ve kısa bir zaman sınırı belirlendi.
İlginç bir şekilde, GPT-4 (solda) gibi güçlü bir dil modelinin desteğiyle, STOP'un ortalama aşağı akış performansı monoton olarak iyileşir. Buna karşılık, daha zayıf GPT-3.5 dil modeli (sağda) için ortalama performans düştü.
2. Geliştirilmiş sistem taşıma özellikleri
Deneysel sonuçlar, bu geliştiricilerin, daha fazla optimizasyon olmadan yeni aşağı akış görevlerinde iyileştiricilerin orijinal sürümünden daha iyi performans gösterebildiğini göstermektedir. Bu, bu geliştiricilerin çok yönlülüğe sahip olduğunu ve farklı görevlere uygulanabileceğini gösterebilir.
3. Daha küçük modellerde kendi kendini optimize eden sistemlerin performansı
Daha sonra, program oluşturma yeteneğini geliştirmek için daha küçük dil modeli GPT-3.5-turbo tartışılmaktadır.
Yazarlar 25 bağımsız deney gerçekleştirdiler ve GPT-3.5'in bazen daha iyi oluşturma prosedürleri önerdiğini ve uyguladığını, ancak GPT-3.5 işlemlerinin yalnızca %12'sinin en az %3 iyileşme sağladığını buldular.
Ayrıca GPT-3.5, GPT-4'te gözlemlenmeyen bazı benzersiz başarısızlık durumlarına sahiptir.
İlk olarak, GPT03.5'in aşağı akış görevleri için ilk çözüme zarar vermeyen, ancak iyileştirici koda zarar veren bir iyileştirme stratejisi önerme olasılığı daha yüksektir (örneğin, her satırdaki dizeleri rastgele değiştirmek, satır başına daha düşük bir ikame olasılığıyla, bu da daha kısa çözümler üzerinde daha az etkiye sahiptir).
İkinci olarak, önerilen iyileştirmelerin çoğu performansa zarar veriyorsa, yetersiz bir derleme programı seçebilir ve yanlışlıkla orijinal çözüme geri dönebilirsiniz.
Genel olarak, iyileştirme önerilerinin arkasındaki "fikirler" makul ve yenilikçidir (örneğin, genetik algoritmalar veya yerel aramalar), ancak uygulama genellikle çok basit veya yanlıştır. Başlangıçta GPT-3.5 kullanan tohum geliştiricilerin GPT-4'ten daha yüksek meta-faydaya sahip olduğu gözlemlendi (%65'e karşı %61).
Sonuç
Bu çalışmada araştırmacılar, GPT-4 gibi büyük dil modellerinin kendilerini geliştirebileceğini ve aşağı akış kod görevlerinde performansı artırabileceğini göstermek için bir STOP temeli öneriyorlar.
Bu ayrıca, kendi kendini optimize eden dil modellerinin, gelecekte insanlar tarafından kontrol edilmeyen yapay zeka sistemlerinden kaçınarak, kendi ağırlıklarını veya temel mimarilerini optimize etmeleri gerekmediğini göstermektedir.
Kaynaklar: