Büyük modellerin diyagramlara bakmasını sağlayın, yazma işlerinden daha fazla! NeurIPS 2023 Yeni Çalışması Multimodal Sorgu Yöntemini Öneriyor, Doğruluk %7,8 Arttı
Görüntü kaynağı: Sınırsız AI tarafından oluşturuldu
Büyük modellerin "resim okuma" yeteneği o kadar güçlü ki, neden yanlış şeyleri aramaya devam ediyorsunuz?
Örneğin, kendilerine benzemeyen yarasaları raketlerle karıştırmak veya bazı veri setlerinde nadir bulunan balıkları tanımamak...
Bunun nedeni, büyük bir modelin "bir şey bulmasına" izin verdiğimizde, genellikle metin girmemizdir.
Açıklama belirsiz veya çok taraflıysa, "yarasa" (yarasa mı dayak mı?). Veya "Cyprinodon diabolis" ve AI'nın kafası karışacak.
Bu, ** nesne algılama **, özellikle açık dünya (bilinmeyen sahne) nesne algılama görevlerini yapmak için büyük modellerin kullanılmasına yol açar, etki genellikle beklendiği kadar iyi değildir.
Şimdi, NeurIPS 2023'te yer alan bir makale nihayet bu sorunu çözdü.
Bu makale, girişe yalnızca bir resim örneği eklemesi gereken ve büyük modellerde bir şeyler bulma doğruluğunu büyük ölçüde artırabilen çok modlu sorguya dayalı bir nesne algılama yöntemi MQ-Det önermektedir.
MQ-Det, kıyaslama algılama veri kümesi LVIS'de, ana akım algılama büyük modellerinin GLIP doğruluğunu ortalama olarak yaklaşık %7,8 oranında artırır ve 13 kıyaslama küçük örnek aşağı akış görevinin doğruluğunu ortalama %6,3 oranında artırır.
Bu tam olarak nasıl yapılır? Hadi bir bakalım.
Aşağıdakiler, makalenin yazarı Zhihu blog yazarı @Qinyuanxia'den alınmıştır:
İçindekiler
MQ-Det: Çok modlu sorgulama için açık dünya nesne algılama büyük modeli
1.1 Metin sorgusundan çok modlu sorguya
1.2 MQ-Det tak ve çalıştır çok modlu sorgu modeli mimarisi
MQ-DET: Çok Modlu Sorgu için Büyük Açık Dünya Nesne Algılama Modeli**
Vahşi Doğada Çok Modlu Sorgulanan Nesne Algılama
Kağıt Bağlantısı:
Kod Adresi:**
### 1.1 Metin sorgusundan çok modlu sorguya
Bir resim bin kelimeye bedeldir: Grafik ön eğitimin yükselişiyle birlikte, metnin açık anlambiliminin yardımıyla, nesne algılama yavaş yavaş açık dünya algısı aşamasına girmiştir. Bu nedenle, birçok büyük algılama modeli metin sorgusu desenini izler, yani hedef görüntülerdeki olası hedefleri sorgulamak için kategorik metin açıklamaları kullanır. Bununla birlikte, bu yaklaşım genellikle "geniş ama rafine edilmemiş" sorunuyla karşı karşıyadır.
Örneğin, (1) Şekil 1'deki ince taneli nesne (parmak) tespiti, sınırlı metinle çeşitli ince taneli türleri tanımlamak genellikle zordur ve (2) kategori belirsizliği ("yarasa" hem yarasa hem de raket anlamına gelebilir).
Bununla birlikte, yukarıdaki problemler, hedef nesneye metinden daha zengin özellik ipuçları sağlayan, ancak aynı zamanda metnin güçlü genellemeye sahip olduğu görüntü örnekleriyle çözülebilir.
Bu nedenle, iki sorgu yönteminin organik olarak nasıl birleştirileceği doğal bir fikir haline geldi.
Çok modlu sorgu yetenekleri elde etmedeki zorluklar: Çok modlu sorgularla böyle bir modelin nasıl elde edileceği konusunda üç zorluk vardır: (1) Sınırlı görüntü örnekleriyle doğrudan ince ayar yapmak, kolayca feci unutmaya yol açabilir; (2) Büyük bir algılama modelini sıfırdan eğitmek iyi bir genellemeye sahip olacaktır, ancak büyük bir tüketime sahip olacaktır, örneğin, tek kartlı eğitim GLIP, 30 milyon veri hacmiyle 480 günlük eğitim gerektirir.
Çok modlu sorgu nesnesi algılama: Yukarıdaki hususlara dayanarak, yazar basit ve etkili bir model tasarımı ve eğitim stratejisi önermektedir - MQ-Det.
MQ-Det, mevcut donmuş metin sorgusu algılama büyük modelini temel alarak görsel örneklerin girdisini almak için az sayıda geçitli algılama modülü (GCP) ekler ve yüksek performanslı çok modlu sorgular için verimli bir şekilde bir algılayıcı elde etmek için bir görsel durum maskesi dil tahmini eğitim stratejisi tasarlar.
1.2 MQ-Det tak ve çalıştır çok modlu sorgu modeli mimarisi
** **#### △Şekil 1 MQ-Det yöntem mimarisi diyagramı
Kapılı Algı Modülü
Şekil 1'de gösterildiği gibi, yazar, mevcut donmuş metin sorgusu algılama büyük modelinin metin kodlayıcı tarafına katman katman bir geçit farkındalık modülü (GCP) ekler ve GCP'nin çalışma modu aşağıdaki formülle kısa ve öz bir şekilde temsil edilebilir:
i. kategori için, hedef görüntü I ile ilk çapraz dikkat (X-MHA) olan görsel örnek Vi'yi girin
temsil yeteneklerini genişletmek için ve ardından her kategori metni ti ve ilgili kategori görsel örneği
Çapraz dikkat elde edin
, bundan sonra orijinal metin ti ve metnin görsel olarak büyütülmesi bir geçit modülü kapısı ile geliştirilir
Mevcut katmanın çıktısını almak için füzyon
。 Bu basit tasarım üç ilkeyi takip eder: (1) kategori ölçeklenebilirliği; (2) anlamsal bütünlük; (3) Anti-amnezi, özel tartışma orijinal metinde bulunabilir.
1.3 MQ-DET Verimli Eğitim Stratejisi
Donmuş dil sorgu algılayıcısına dayalı modülasyon eğitimi
Mevcut eğitim öncesi algılama büyük metin sorgusu modelinin kendisi iyi bir genellemeye sahip olduğundan, yazarlar orijinal metin özelliklerine dayanarak görsel ayrıntılarla yalnızca küçük ayarlamalar yapılması gerektiğine inanmaktadır.
Makalede, orijinal önceden eğitilmiş modelin parametrelerini açtıktan ve ince ayar yaptıktan sonra, ancak açık dünya algılama yeteneğini kaybettikten sonra felaketle ilgili unutmanın kolay olduğuna dair özel bir deneysel gösteri de var.
Bu nedenle, MQ-Det, önceden eğitilmiş donmuş metin sorgusu algılayıcısı temelinde mevcut metin sorgusunun algılayıcısına görsel bilgileri verimli bir şekilde ekleyebilir ve yalnızca eğitim tarafından eklenen GCP modülünü modüle edebilir.
Makalede yazarlar, yöntemin çok yönlülüğünü doğrulamak için MQ-Det'in yapısal tasarım ve eğitim tekniklerini sırasıyla mevcut SOTA modelleri GLIP ve GroundingDINO'ya uygulamaktadır.
Görsel Kondisyon ile Maske Dili Tahmin Eğitim Stratejisi
Yazarlar ayrıca, önceden eğitilmiş modellerin dondurulmasının neden olduğu öğrenme tembelliği sorununu çözmek için görsel olarak koşullandırılmış bir maskeleme dili tahmine dayalı eğitim stratejisi önermektedir.
Sözde öğrenme tembelliği, dedektörün eğitim sürecinde orijinal metin sorgusunun özelliklerini koruma eğiliminde olduğu ve böylece yeni eklenen görsel sorgu özelliklerini göz ardı ettiği anlamına gelir.
Bu amaçla, MQ-Det eğitim sırasında rastgele kullanılır[MASK] Belirteç, metin belirtecinin yerini alır ve modeli görsel sorgu özelliği tarafından öğrenmeye zorlar:
Bu strateji basit olmasına rağmen çok etkilidir ve deneysel sonuçlardan bu strateji önemli performans artışı sağlamıştır.
İnce ayar gerektirmez: MQ-Det daha pratik bir değerlendirme stratejisi önerir: ince ayarsız, yalnızca kategori metnini kullanan geleneksel sıfır atışlı değerlendirmeye kıyasla. Kategori metni, görüntü örnekleri veya herhangi bir aşağı akış ince ayarı olmadan her ikisinin bir kombinasyonunu kullanarak nesne algılama olarak tanımlanır.
İnce ayar gerektirmeyen ayar altında, MQ-Det her kategori için 5 görsel örnek seçer ve nesne algılama için kategori metnini birleştirirken, diğer mevcut modeller görsel sorguyu desteklemez ve nesne algılama için yalnızca düz metin açıklamaları kullanabilir. Aşağıdaki tablo LVIS MiniVal ve LVIS v1.0 ile ilgili sonuçları göstermektedir. Çok modlu sorgunun tanıtılmasının açık dünya nesne algılama yeteneğini büyük ölçüde geliştirdiği bulunabilir.
** **###### △Tablo 1 LVIS kıyaslama veri kümesi altındaki her algılama modelinin ince ayar gerektirmeyen performansı
Tablo 1'den görülebileceği gibi, MQ-GLIP-L, GLIP-L bazında AP'yi %7'den fazla iyileştirmiştir ve etkisi çok önemlidir!
1.5 Deneysel Sonuçlar: Az Atışlı Değerlendirme
** **#### △Tablo 2 ODinW-35'teki her modelin performansı ve ODinW-13'ün 13 alt kümesi 35 algılama görevinde
Yazarlar ayrıca, bir aşağı akış 35 algılama görevi olan ODinW-35'te kapsamlı deneyler gerçekleştirdiler. Tablo 2'den görülebileceği gibi, MQ-Det yalnızca güçlü ince ayar gerektirmeyen performansa sahip olmakla kalmaz, aynı zamanda çok modlu sorguların potansiyelini daha da doğrulayan iyi küçük örnek algılama yeteneklerine sahiptir. Şekil 2 ayrıca MQ-Det'in GLIP'e göre önemli gelişimini göstermektedir.
** **###### △Şekil 2 Veri kullanım verimliliğinin karşılaştırılması; Yatay eksen: eğitim örneklerinin sayısı, dikey eksen: OdinW-13'te ortalama AP
1.6 Çok Modlu Sorgu Nesnesi Algılama için Beklentiler
Pratik uygulamalara dayalı bir araştırma alanı olarak nesne algılama, algoritmaların inişine büyük önem vermektedir.
Önceki düz metin sorgu nesnesi algılama modeli iyi bir genelleme gösterse de, gerçek açık dünya algılama Çince'sinde ince taneli bilgileri kapsamak zordur ve görüntüdeki zengin bilgi ayrıntı düzeyi bu bağlantıyı mükemmel bir şekilde tamamlar.
Şimdiye kadar, metnin genel olduğunu ancak kesin olmadığını ve görüntünün kesin olduğunu ancak genel olmadığını görebiliriz ve ikisini, yani çok modlu sorguyu etkili bir şekilde birleştirebilirsek, açık dünya nesne algılamasının daha da ilerlemesini teşvik edecektir.
MQ-Det, çok modlu sorgulamada ilk adımı attı ve önemli performans iyileştirmesi, çok modlu sorgu hedefi algılamanın büyük potansiyelini de gösteriyor.
Aynı zamanda, metin açıklamalarının ve görsel örneklerin tanıtılması, kullanıcılara daha fazla seçenek sunarak nesne algılamayı daha esnek ve kullanıcı dostu hale getirir.
Orijinal bağlantı:
View Original
This page may contain third-party content, which is provided for information purposes only (not representations/warranties) and should not be considered as an endorsement of its views by Gate, nor as financial or professional advice. See Disclaimer for details.
Büyük modellerin diyagramlara bakmasını sağlayın, yazma işlerinden daha fazla! NeurIPS 2023 Yeni Çalışması Multimodal Sorgu Yöntemini Öneriyor, Doğruluk %7,8 Arttı
Orijinal kaynak: Qubits
Büyük modellerin "resim okuma" yeteneği o kadar güçlü ki, neden yanlış şeyleri aramaya devam ediyorsunuz?
Örneğin, kendilerine benzemeyen yarasaları raketlerle karıştırmak veya bazı veri setlerinde nadir bulunan balıkları tanımamak...
Açıklama belirsiz veya çok taraflıysa, "yarasa" (yarasa mı dayak mı?). Veya "Cyprinodon diabolis" ve AI'nın kafası karışacak.
Bu, ** nesne algılama **, özellikle açık dünya (bilinmeyen sahne) nesne algılama görevlerini yapmak için büyük modellerin kullanılmasına yol açar, etki genellikle beklendiği kadar iyi değildir.
Şimdi, NeurIPS 2023'te yer alan bir makale nihayet bu sorunu çözdü.
MQ-Det, kıyaslama algılama veri kümesi LVIS'de, ana akım algılama büyük modellerinin GLIP doğruluğunu ortalama olarak yaklaşık %7,8 oranında artırır ve 13 kıyaslama küçük örnek aşağı akış görevinin doğruluğunu ortalama %6,3 oranında artırır.
Bu tam olarak nasıl yapılır? Hadi bir bakalım.
Aşağıdakiler, makalenin yazarı Zhihu blog yazarı @Qinyuanxia'den alınmıştır:
İçindekiler
MQ-DET: Çok Modlu Sorgu için Büyük Açık Dünya Nesne Algılama Modeli**
Vahşi Doğada Çok Modlu Sorgulanan Nesne Algılama
Kağıt Bağlantısı:
Kod Adresi:**
Bir resim bin kelimeye bedeldir: Grafik ön eğitimin yükselişiyle birlikte, metnin açık anlambiliminin yardımıyla, nesne algılama yavaş yavaş açık dünya algısı aşamasına girmiştir. Bu nedenle, birçok büyük algılama modeli metin sorgusu desenini izler, yani hedef görüntülerdeki olası hedefleri sorgulamak için kategorik metin açıklamaları kullanır. Bununla birlikte, bu yaklaşım genellikle "geniş ama rafine edilmemiş" sorunuyla karşı karşıyadır.
Örneğin, (1) Şekil 1'deki ince taneli nesne (parmak) tespiti, sınırlı metinle çeşitli ince taneli türleri tanımlamak genellikle zordur ve (2) kategori belirsizliği ("yarasa" hem yarasa hem de raket anlamına gelebilir).
Bununla birlikte, yukarıdaki problemler, hedef nesneye metinden daha zengin özellik ipuçları sağlayan, ancak aynı zamanda metnin güçlü genellemeye sahip olduğu görüntü örnekleriyle çözülebilir.
Bu nedenle, iki sorgu yönteminin organik olarak nasıl birleştirileceği doğal bir fikir haline geldi.
Çok modlu sorgu yetenekleri elde etmedeki zorluklar: Çok modlu sorgularla böyle bir modelin nasıl elde edileceği konusunda üç zorluk vardır: (1) Sınırlı görüntü örnekleriyle doğrudan ince ayar yapmak, kolayca feci unutmaya yol açabilir; (2) Büyük bir algılama modelini sıfırdan eğitmek iyi bir genellemeye sahip olacaktır, ancak büyük bir tüketime sahip olacaktır, örneğin, tek kartlı eğitim GLIP, 30 milyon veri hacmiyle 480 günlük eğitim gerektirir.
Çok modlu sorgu nesnesi algılama: Yukarıdaki hususlara dayanarak, yazar basit ve etkili bir model tasarımı ve eğitim stratejisi önermektedir - MQ-Det.
MQ-Det, mevcut donmuş metin sorgusu algılama büyük modelini temel alarak görsel örneklerin girdisini almak için az sayıda geçitli algılama modülü (GCP) ekler ve yüksek performanslı çok modlu sorgular için verimli bir şekilde bir algılayıcı elde etmek için bir görsel durum maskesi dil tahmini eğitim stratejisi tasarlar.
1.2 MQ-Det tak ve çalıştır çok modlu sorgu modeli mimarisi
** **#### △Şekil 1 MQ-Det yöntem mimarisi diyagramı
**#### △Şekil 1 MQ-Det yöntem mimarisi diyagramı
Kapılı Algı Modülü
Şekil 1'de gösterildiği gibi, yazar, mevcut donmuş metin sorgusu algılama büyük modelinin metin kodlayıcı tarafına katman katman bir geçit farkındalık modülü (GCP) ekler ve GCP'nin çalışma modu aşağıdaki formülle kısa ve öz bir şekilde temsil edilebilir:
1.3 MQ-DET Verimli Eğitim Stratejisi
Donmuş dil sorgu algılayıcısına dayalı modülasyon eğitimi
Mevcut eğitim öncesi algılama büyük metin sorgusu modelinin kendisi iyi bir genellemeye sahip olduğundan, yazarlar orijinal metin özelliklerine dayanarak görsel ayrıntılarla yalnızca küçük ayarlamalar yapılması gerektiğine inanmaktadır.
Makalede, orijinal önceden eğitilmiş modelin parametrelerini açtıktan ve ince ayar yaptıktan sonra, ancak açık dünya algılama yeteneğini kaybettikten sonra felaketle ilgili unutmanın kolay olduğuna dair özel bir deneysel gösteri de var.
Bu nedenle, MQ-Det, önceden eğitilmiş donmuş metin sorgusu algılayıcısı temelinde mevcut metin sorgusunun algılayıcısına görsel bilgileri verimli bir şekilde ekleyebilir ve yalnızca eğitim tarafından eklenen GCP modülünü modüle edebilir.
Makalede yazarlar, yöntemin çok yönlülüğünü doğrulamak için MQ-Det'in yapısal tasarım ve eğitim tekniklerini sırasıyla mevcut SOTA modelleri GLIP ve GroundingDINO'ya uygulamaktadır.
Görsel Kondisyon ile Maske Dili Tahmin Eğitim Stratejisi
Yazarlar ayrıca, önceden eğitilmiş modellerin dondurulmasının neden olduğu öğrenme tembelliği sorununu çözmek için görsel olarak koşullandırılmış bir maskeleme dili tahmine dayalı eğitim stratejisi önermektedir.
Sözde öğrenme tembelliği, dedektörün eğitim sürecinde orijinal metin sorgusunun özelliklerini koruma eğiliminde olduğu ve böylece yeni eklenen görsel sorgu özelliklerini göz ardı ettiği anlamına gelir.
Bu amaçla, MQ-Det eğitim sırasında rastgele kullanılır[MASK] Belirteç, metin belirtecinin yerini alır ve modeli görsel sorgu özelliği tarafından öğrenmeye zorlar:
1.4 Deneysel Sonuçlar: İnce Ayar Gerektirmeyen Değerlendirme
İnce ayar gerektirmez: MQ-Det daha pratik bir değerlendirme stratejisi önerir: ince ayarsız, yalnızca kategori metnini kullanan geleneksel sıfır atışlı değerlendirmeye kıyasla. Kategori metni, görüntü örnekleri veya herhangi bir aşağı akış ince ayarı olmadan her ikisinin bir kombinasyonunu kullanarak nesne algılama olarak tanımlanır.
İnce ayar gerektirmeyen ayar altında, MQ-Det her kategori için 5 görsel örnek seçer ve nesne algılama için kategori metnini birleştirirken, diğer mevcut modeller görsel sorguyu desteklemez ve nesne algılama için yalnızca düz metin açıklamaları kullanabilir. Aşağıdaki tablo LVIS MiniVal ve LVIS v1.0 ile ilgili sonuçları göstermektedir. Çok modlu sorgunun tanıtılmasının açık dünya nesne algılama yeteneğini büyük ölçüde geliştirdiği bulunabilir.
**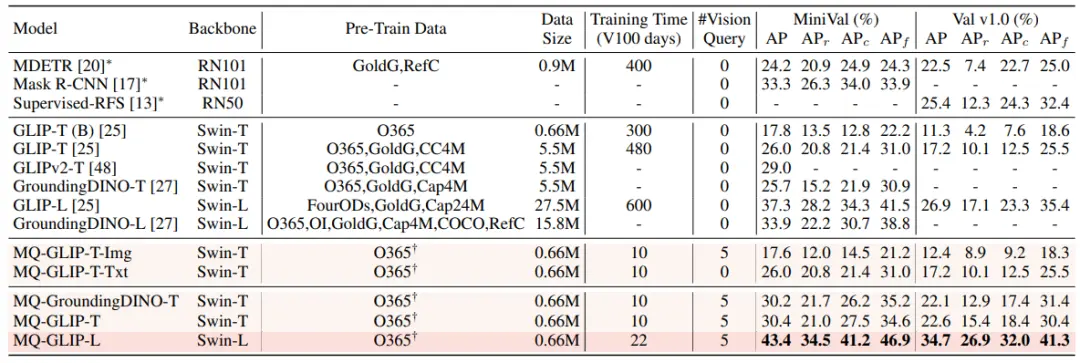 **###### △Tablo 1 LVIS kıyaslama veri kümesi altındaki her algılama modelinin ince ayar gerektirmeyen performansı
**###### △Tablo 1 LVIS kıyaslama veri kümesi altındaki her algılama modelinin ince ayar gerektirmeyen performansı
Tablo 1'den görülebileceği gibi, MQ-GLIP-L, GLIP-L bazında AP'yi %7'den fazla iyileştirmiştir ve etkisi çok önemlidir!
1.5 Deneysel Sonuçlar: Az Atışlı Değerlendirme
**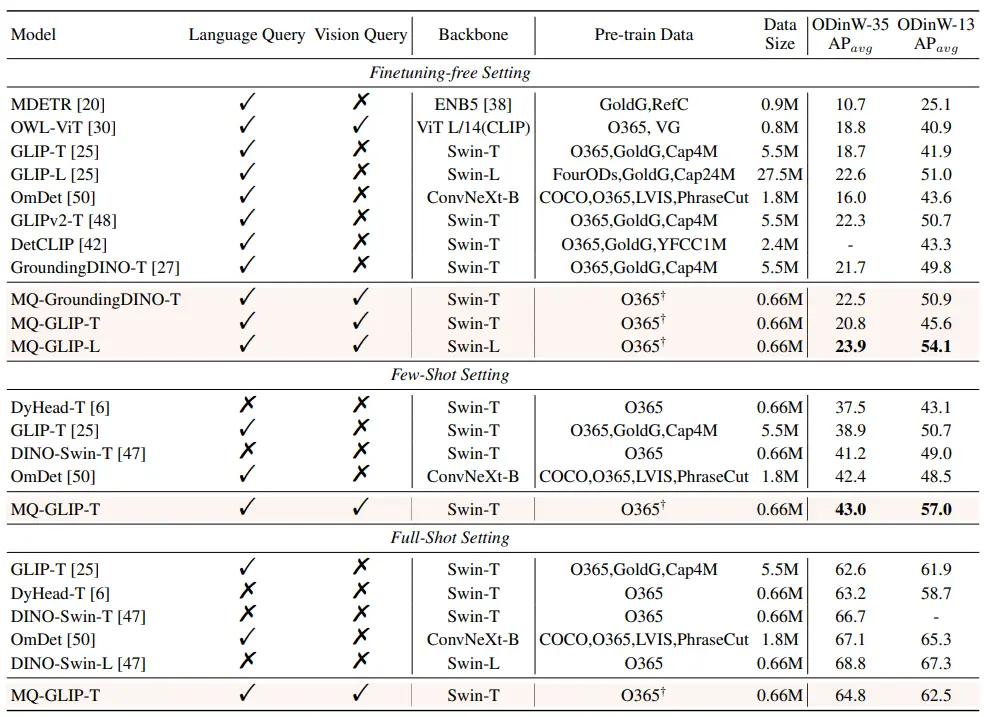 **#### △Tablo 2 ODinW-35'teki her modelin performansı ve ODinW-13'ün 13 alt kümesi 35 algılama görevinde
**#### △Tablo 2 ODinW-35'teki her modelin performansı ve ODinW-13'ün 13 alt kümesi 35 algılama görevinde
Yazarlar ayrıca, bir aşağı akış 35 algılama görevi olan ODinW-35'te kapsamlı deneyler gerçekleştirdiler. Tablo 2'den görülebileceği gibi, MQ-Det yalnızca güçlü ince ayar gerektirmeyen performansa sahip olmakla kalmaz, aynı zamanda çok modlu sorguların potansiyelini daha da doğrulayan iyi küçük örnek algılama yeteneklerine sahiptir. Şekil 2 ayrıca MQ-Det'in GLIP'e göre önemli gelişimini göstermektedir.
**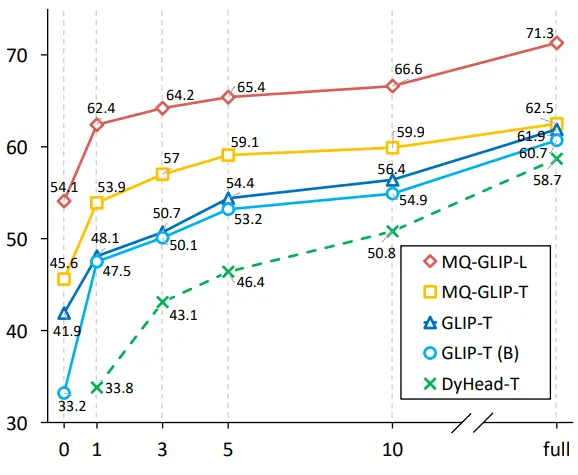 **###### △Şekil 2 Veri kullanım verimliliğinin karşılaştırılması; Yatay eksen: eğitim örneklerinin sayısı, dikey eksen: OdinW-13'te ortalama AP
**###### △Şekil 2 Veri kullanım verimliliğinin karşılaştırılması; Yatay eksen: eğitim örneklerinin sayısı, dikey eksen: OdinW-13'te ortalama AP
1.6 Çok Modlu Sorgu Nesnesi Algılama için Beklentiler
Pratik uygulamalara dayalı bir araştırma alanı olarak nesne algılama, algoritmaların inişine büyük önem vermektedir.
Önceki düz metin sorgu nesnesi algılama modeli iyi bir genelleme gösterse de, gerçek açık dünya algılama Çince'sinde ince taneli bilgileri kapsamak zordur ve görüntüdeki zengin bilgi ayrıntı düzeyi bu bağlantıyı mükemmel bir şekilde tamamlar.
Şimdiye kadar, metnin genel olduğunu ancak kesin olmadığını ve görüntünün kesin olduğunu ancak genel olmadığını görebiliriz ve ikisini, yani çok modlu sorguyu etkili bir şekilde birleştirebilirsek, açık dünya nesne algılamasının daha da ilerlemesini teşvik edecektir.
MQ-Det, çok modlu sorgulamada ilk adımı attı ve önemli performans iyileştirmesi, çok modlu sorgu hedefi algılamanın büyük potansiyelini de gösteriyor.
Aynı zamanda, metin açıklamalarının ve görsel örneklerin tanıtılması, kullanıcılara daha fazla seçenek sunarak nesne algılamayı daha esnek ve kullanıcı dostu hale getirir.
Orijinal bağlantı: