Görüntü kaynağı: Sınırsız AI tarafından oluşturuldu
"Ayarlamak" için 500 dolar harcayan 7 milyar parametreli model, 70 milyar parametreli Llama 2'yi yendi!
Ve not defteri kolayca çalışabilir ve etkisi ChatGPT ile karşılaştırılabilir.
Önemli: Ücretsiz, para yok.
HuggingFace H7 ekibi tarafından oluşturulan açık kaynaklı model Zephyr-4B, köpekbalığı delisi.
Temel modeli, bir süre önce patlayan ve "Avrupa OpenAI" olarak bilinen Mistral AI tarafından inşa edilen açık kaynaklı büyük bir model olan Mistral-7B'dir.
Biliyorsunuz, Mistral-7B'nin piyasaya sürülmesinden 2 haftadan kısa bir süre sonra, çeşitli ince ayarlı versiyonlar birbiri ardına ortaya çıktı ve Llama ilk piyasaya sürüldüğünde hızla ortaya çıkan birçok "alpaka" stili var.
Zephyr'in varyantlar arasında öne çıkma yeteneğinin anahtarı, ekibin Mistral'in üzerinde Doğrudan Tercih Optimizasyonu (DPO) kullanarak modeli halka açık bir veri kümesinde ince ayar yapmasıydı.
Ekip ayrıca veri kümesinin yerleşik hizalamasını kaldırmanın MT Bench performansını daha da iyileştirebileceğini buldu. Orijinal Zephyr-7B-alpha, Llama2-70B-Chat'i geride bırakarak ortalama 7.09 MT-Bench puanına sahipti.
** **### △MT-Bench, modelin birden fazla diyalog turunu idare etme yeteneğini değerlendirmek için bir kıyaslama testidir ve soru seti yazma, rol yapma ve çıkarma gibi 8 kategoriyi kapsar.
Mesele şu ki, daha sonra yükseltmeye devam etti!
H4 ekibi, ikinci nesil Zephyr-7B-beta'yı piyasaya sürdü. GPT-4, Claude 2'den hizalamayı çıkarma ve ardından bunu küçük modellere enjekte etme fikrini araştırdıklarını ve küçük modeller için damıtma doğrudan tercih optimizasyonunu (dDPO) kullanmak için bir yöntem geliştirdiklerini eklediler.
Zephyr'in ikinci neslinde, ortalama MT-Bench puanı 7.34'e yükseldi.
Alpaca'da Zephyr, ChatGPT'den (90.6) daha iyi olan %3.5'lık bir kazanma oranına sahiptir:
Zephyr'e koşan netizenler oybirliğiyle övgüde bulundu ve lmsys ekibi ayrıca çok yükselen 🔥 Zephyr-7b-beta'nın Elo puanını da gösterdi:
DPO yaklaşımının sahada iyi performans gösterdiğini görmek, muhtemelen bu yıl büyük dil modellerinin geliştirilmesiyle ilgili en heyecan verici şey.
Daha fazla netizen Zephyr'in etkisini test etmeye başladı ve sonuçlar şaşırtıcı derecede iyi.
Mistral kelimesi Fransızca'da kuru, soğuk ve kuvvetli rüzgar anlamına gelirken, Zephyr hafif, hoş batı rüzgarı anlamına gelir.
Hiç şüphe yok ki Llama'nın diğer tarafında bir hayvanat bahçesi var ve bu tarafta bir meteoroloji bürosu olduğuna şüphe yok.
En iyi 7B modeli yeniden el değiştiriyor
Zephyr'i çalıştırmak için bilgisayar gereksinimleriyle başlayalım. Netizenler testten sonra "Tay pantolonları baharatlı" dedi! , dizüstü bilgisayar (Apple M1 Pro) yeterli, "sonuç çok iyi".
Etkinlik açısından, Llama Index (eski adıyla GPT Index) ekibi de bunu test etti.
Zephyr'in şu anda üst düzey RAG/ajan görevlerinde iyi performans gösteren tek açık kaynaklı 7B modeli olduğu ortaya çıktı.
Veriler ayrıca Zephyr'in gelişmiş RAG görevinin etkisinin GPT-3.5 ve Claude 2 ile rekabet edebileceğini gösteriyor.
Zephyr'in yalnızca RAG'da değil, aynı zamanda yönlendirme, sorgu planlama, karmaşık SQL ifadelerini alma ve yapılandırılmış veri çıkarmada da iyi çalıştığını eklemeye devam ettiler.
Yetkililer ayrıca test sonuçları verdi ve MT-Bench'te Zephyr-7B-beta, Llama2-Chat-70B gibi daha büyük modellere kıyasla güçlü bir performansa sahip.
Ancak kodlama ve matematik gibi daha karmaşık görevlerde Zephyr-7B-beta, tescilli modellerin gerisinde kalıyor ve boşluğu kapatmak için daha fazla araştırma gerektiriyor.
Pekiştirmeli Öğrenmeyi Terk Et
Herkes Zephyr'in etkilerini test ederken, geliştiriciler en ilginç şeyin metrikler değil, modelin eğitilme şekli olduğunu söylüyor.
Önemli noktalar aşağıda özetlenmiştir:
En iyi küçük, açık kaynaklı önceden eğitilmiş modele ince ayar yapın: Mistral 7B
Büyük Ölçekli Tercih Veri Kümelerinin Kullanımı: UltraFeedback
Pekiştirmeli öğrenme yerine Doğrudan Tercih Optimizasyonu (DPO) kullanın
Beklenmedik bir şekilde, tercih veri kümesinin aşırı uydurulması daha iyi sonuçlar verir
Genel olarak konuşursak, başta da belirtildiği gibi, Zephyr'in 70B Llama 2'yi geçebilmesinin ana nedeni, özel bir ince ayar yönteminin kullanılmasından kaynaklanmaktadır.
Geleneksel PPO takviyeli öğrenme yaklaşımından farklı olarak, araştırma ekibi bir DPO yaklaşımı önermek için Stanford Üniversitesi ve CZ Biohub arasındaki yakın tarihli bir işbirliğini kullandı.
Araştırmacılara göre:
DPO, PPO'dan çok daha kararlıdır.
Basit bir ifadeyle, DPO şu şekilde açıklanabilir:
Modelin çıktısını insan tercihlerine daha uygun hale getirmek için geleneksel yaklaşım, hedef modele bir ödül modeliyle ince ayar yapmak olmuştur. Çıktı iyiyse ödüllendirileceksiniz ve çıktı kötüyse ödüllendirilmeyeceksiniz.
DPO yaklaşımı ise modelleme ödül fonksiyonunu atlar ve modeli doğrudan tercih verileri üzerinde optimize etmeye eşdeğerdir.
Genel olarak DPO, insan geri bildirimi nedeniyle zor ve pahalı pekiştirmeli öğrenme eğitimi sorununu çözer.
Özellikle Zephyr'in eğitimi açısından, araştırma ekibi başlangıçta Zephyr-7B-alpha'yı, ChatGPT tarafından oluşturulan 1,6 milyon konuşmayı (yaklaşık 200.000 kalan) içeren UltraChat veri kümesinin kolaylaştırılmış bir varyantı üzerinde ince ayar yaptı.
(Düzene sokmanın nedeni, ekibin Zephyr'in bazen yanlış yazıldığını bulmasıydı, örneğin "Merhaba. nasılsın?"; Bazen yanıt "Kişisel X'im yok" ile başlar. )
Daha sonra, TRL'nin DPO Trainer yöntemini kullanarak modeli halka açık openbmb/UltraFeedback veri kümesiyle daha da uyumlu hale getirdiler.
Veri kümesi, çeşitli modellerden 64.000 istem-yanıt çifti içerir. Her yanıt, kullanışlılık gibi kriterlere göre GPT-4 tarafından sıralanır ve bir yapay zeka tercihinin türetildiği bir puan verilir.
İlginç bir bulgu, DPO yöntemini kullanırken, eğitim süresi arttıkça aşırı uyumdan sonra etkinin aslında daha iyi olmasıdır. Araştırmacılar bunun SFT'de aşırı öğrenmeye benzer olduğuna inanıyor.
Araştırma ekibinin, modele bu yöntemle ince ayar yapmanın sadece 500 dolara mal olduğunu, bunun da 16 A100'de 8 saat çalıştığını belirtmekte fayda var.
Zephyr'i beta sürümüne yükseltirken, ekip yaklaşımlarını açıklamaya devam etti.
Büyük modellerde kullanılan damıtma denetimli ince ayarı (dSFT) düşündüler, ancak bu yaklaşımla model yanlış hizalandı ve kullanıcının amacına uygun çıktı üretmedi.
Bu nedenle ekip, bir veri kümesi oluşturmak için çıktıları bir "öğretmen modeli" ile sıralamak için AI Geri Bildiriminden (AIF) elde edilen tercih verilerini kullanmaya çalıştı ve ardından ince ayar sırasında herhangi bir ek örnekleme olmadan kullanıcı amacıyla uyumlu bir modeli eğitmek için damıtma doğrudan tercih optimizasyonunu (dDPO) uyguladı.
Araştırmacılar ayrıca SFT kullanılmadığında etkiyi test ettiler ve sonuçlar performansta önemli bir düşüşle sonuçlandı ve bu da dSFT adımının kritik olduğunu gösterdi.
Şu anda, modelin açık kaynak kodlu ve ticari olmasına ek olarak, denenecek bir Demo da var, böylece başlayabilir ve basitçe deneyimleyebiliriz.
Demo Deneyimi
Her şeyden önce, bir sınava girmek için "zihinsel engelliler" sorusundan çıkmak zorunda kaldım.
"Annem ve babam evlendiklerinde beni almıyorlar" sorusuna Zephyr'in genel cevabı daha doğru.
ChatGPT bu soruyu yenemez.
Testte, Zephyr'in OpenAI'nin GPT-4'ü piyasaya sürmesi gibi son olayları da bildiğini gördük:
Bu aslında temel modeliyle ilgilidir, ancak Mistral yetkilisi eğitim verileri için son tarihi belirtmemiştir.
Ancak bazı netizenler bunu daha önce test etti ve bu yıl Mart ayında da biliyor.
Buna karşılık, Llama 2'nin eğitim öncesi verileri Eylül 2022 itibariyledir ve yalnızca bazı ince ayarlı veriler Haziran 2023'e kadardır.
Ek olarak, Zephyr çok duyarlıdır, böylece kod yazabilir ve hikayeler oluşturabilirsiniz. :
Zephyr'in İngilizce soruları cevaplamada daha iyi olduğunu ve ayrıca "halüsinasyon" modeliyle ortak bir sorunu olduğunu belirtmekte fayda var.
Araştırmacılar ayrıca halüsinasyonlardan da bahsettiler ve giriş kutusunun altında, model tarafından oluşturulan içeriğin yanlış veya yanlış olabileceğini gösteren küçük bir metin satırı işaretlendi.
Mesele şu ki, Zephyr, insan tercihlerine uyum sağlamak için insan geri bildirimiyle pekiştirmeli öğrenme gibi yöntemler kullanmıyor ve ChatGPT'nin yanıt filtrelemesini kullanmıyor.
Her zaman emmm balık ve ayı pençelerinden birini seçin.
Zephyr bunu sadece 70B parametreleriyle yapabildi, bu da "100 Sayfalık Makine Öğrenimi Kitabı" nın yazarı Andriy Burkov'u şaşırttı ve hatta şunları söyledi:
Zephyr-7B, teorik olarak 128 bin jetona kadar bir dikkat aralığına sahip olan 8 bin jetonluk bir bağlam penceresine sahip bir Mistral-70B temel modeliyle Llama 2-70B'yi yener.
Ya Zephyr bir 70B modeli olsaydı? GPT-4'ten daha iyi performans gösterecek mi? Muhtemel görünüyor.
Zephyr-7B ile ilgileniyorsanız, huggingface'de deneyebilirsiniz.
Kağıt Bağlantıları:
Referans Linkleri:
[1]
[2]
[3]
[4]
[5]
View Original
This page may contain third-party content, which is provided for information purposes only (not representations/warranties) and should not be considered as an endorsement of its views by Gate, nor as financial or professional advice. See Disclaimer for details.
En iyi 7B modeli yeniden el değiştiriyor! 70 milyar LLaMA2'yi yenin ve Apple bilgisayarlar çalışabilecek|açık kaynak ve ücretsiz
Orijinal kaynak: kübitler
"Ayarlamak" için 500 dolar harcayan 7 milyar parametreli model, 70 milyar parametreli Llama 2'yi yendi!
Ve not defteri kolayca çalışabilir ve etkisi ChatGPT ile karşılaştırılabilir.
Önemli: Ücretsiz, para yok.
HuggingFace H7 ekibi tarafından oluşturulan açık kaynaklı model Zephyr-4B, köpekbalığı delisi.
Zephyr'in varyantlar arasında öne çıkma yeteneğinin anahtarı, ekibin Mistral'in üzerinde Doğrudan Tercih Optimizasyonu (DPO) kullanarak modeli halka açık bir veri kümesinde ince ayar yapmasıydı.
Ekip ayrıca veri kümesinin yerleşik hizalamasını kaldırmanın MT Bench performansını daha da iyileştirebileceğini buldu. Orijinal Zephyr-7B-alpha, Llama2-70B-Chat'i geride bırakarak ortalama 7.09 MT-Bench puanına sahipti.
**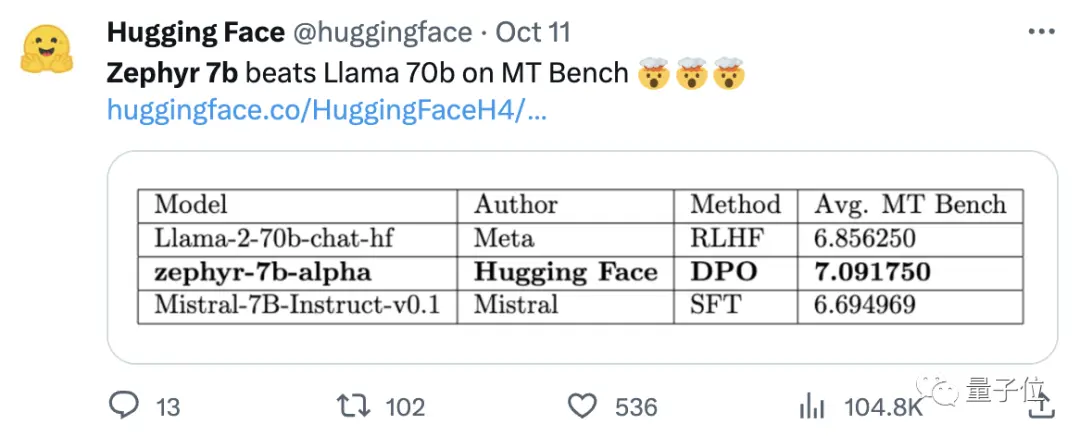 **### △MT-Bench, modelin birden fazla diyalog turunu idare etme yeteneğini değerlendirmek için bir kıyaslama testidir ve soru seti yazma, rol yapma ve çıkarma gibi 8 kategoriyi kapsar.
**### △MT-Bench, modelin birden fazla diyalog turunu idare etme yeteneğini değerlendirmek için bir kıyaslama testidir ve soru seti yazma, rol yapma ve çıkarma gibi 8 kategoriyi kapsar.
Mesele şu ki, daha sonra yükseltmeye devam etti!
H4 ekibi, ikinci nesil Zephyr-7B-beta'yı piyasaya sürdü. GPT-4, Claude 2'den hizalamayı çıkarma ve ardından bunu küçük modellere enjekte etme fikrini araştırdıklarını ve küçük modeller için damıtma doğrudan tercih optimizasyonunu (dDPO) kullanmak için bir yöntem geliştirdiklerini eklediler.
Zephyr'in ikinci neslinde, ortalama MT-Bench puanı 7.34'e yükseldi.
Mistral kelimesi Fransızca'da kuru, soğuk ve kuvvetli rüzgar anlamına gelirken, Zephyr hafif, hoş batı rüzgarı anlamına gelir.
Hiç şüphe yok ki Llama'nın diğer tarafında bir hayvanat bahçesi var ve bu tarafta bir meteoroloji bürosu olduğuna şüphe yok.
En iyi 7B modeli yeniden el değiştiriyor
Zephyr'i çalıştırmak için bilgisayar gereksinimleriyle başlayalım. Netizenler testten sonra "Tay pantolonları baharatlı" dedi! , dizüstü bilgisayar (Apple M1 Pro) yeterli, "sonuç çok iyi".
Veriler ayrıca Zephyr'in gelişmiş RAG görevinin etkisinin GPT-3.5 ve Claude 2 ile rekabet edebileceğini gösteriyor.
Zephyr'in yalnızca RAG'da değil, aynı zamanda yönlendirme, sorgu planlama, karmaşık SQL ifadelerini alma ve yapılandırılmış veri çıkarmada da iyi çalıştığını eklemeye devam ettiler.
Pekiştirmeli Öğrenmeyi Terk Et
Herkes Zephyr'in etkilerini test ederken, geliştiriciler en ilginç şeyin metrikler değil, modelin eğitilme şekli olduğunu söylüyor.
Önemli noktalar aşağıda özetlenmiştir:
Genel olarak konuşursak, başta da belirtildiği gibi, Zephyr'in 70B Llama 2'yi geçebilmesinin ana nedeni, özel bir ince ayar yönteminin kullanılmasından kaynaklanmaktadır.
Geleneksel PPO takviyeli öğrenme yaklaşımından farklı olarak, araştırma ekibi bir DPO yaklaşımı önermek için Stanford Üniversitesi ve CZ Biohub arasındaki yakın tarihli bir işbirliğini kullandı.
Basit bir ifadeyle, DPO şu şekilde açıklanabilir:
Modelin çıktısını insan tercihlerine daha uygun hale getirmek için geleneksel yaklaşım, hedef modele bir ödül modeliyle ince ayar yapmak olmuştur. Çıktı iyiyse ödüllendirileceksiniz ve çıktı kötüyse ödüllendirilmeyeceksiniz.
DPO yaklaşımı ise modelleme ödül fonksiyonunu atlar ve modeli doğrudan tercih verileri üzerinde optimize etmeye eşdeğerdir.
Genel olarak DPO, insan geri bildirimi nedeniyle zor ve pahalı pekiştirmeli öğrenme eğitimi sorununu çözer.
Özellikle Zephyr'in eğitimi açısından, araştırma ekibi başlangıçta Zephyr-7B-alpha'yı, ChatGPT tarafından oluşturulan 1,6 milyon konuşmayı (yaklaşık 200.000 kalan) içeren UltraChat veri kümesinin kolaylaştırılmış bir varyantı üzerinde ince ayar yaptı.
(Düzene sokmanın nedeni, ekibin Zephyr'in bazen yanlış yazıldığını bulmasıydı, örneğin "Merhaba. nasılsın?"; Bazen yanıt "Kişisel X'im yok" ile başlar. )
Daha sonra, TRL'nin DPO Trainer yöntemini kullanarak modeli halka açık openbmb/UltraFeedback veri kümesiyle daha da uyumlu hale getirdiler.
Veri kümesi, çeşitli modellerden 64.000 istem-yanıt çifti içerir. Her yanıt, kullanışlılık gibi kriterlere göre GPT-4 tarafından sıralanır ve bir yapay zeka tercihinin türetildiği bir puan verilir.
İlginç bir bulgu, DPO yöntemini kullanırken, eğitim süresi arttıkça aşırı uyumdan sonra etkinin aslında daha iyi olmasıdır. Araştırmacılar bunun SFT'de aşırı öğrenmeye benzer olduğuna inanıyor.
Büyük modellerde kullanılan damıtma denetimli ince ayarı (dSFT) düşündüler, ancak bu yaklaşımla model yanlış hizalandı ve kullanıcının amacına uygun çıktı üretmedi.
Araştırmacılar ayrıca SFT kullanılmadığında etkiyi test ettiler ve sonuçlar performansta önemli bir düşüşle sonuçlandı ve bu da dSFT adımının kritik olduğunu gösterdi.
Demo Deneyimi
Her şeyden önce, bir sınava girmek için "zihinsel engelliler" sorusundan çıkmak zorunda kaldım.
"Annem ve babam evlendiklerinde beni almıyorlar" sorusuna Zephyr'in genel cevabı daha doğru.
Ancak bazı netizenler bunu daha önce test etti ve bu yıl Mart ayında da biliyor.
Ek olarak, Zephyr çok duyarlıdır, böylece kod yazabilir ve hikayeler oluşturabilirsiniz. :
Araştırmacılar ayrıca halüsinasyonlardan da bahsettiler ve giriş kutusunun altında, model tarafından oluşturulan içeriğin yanlış veya yanlış olabileceğini gösteren küçük bir metin satırı işaretlendi.
Her zaman emmm balık ve ayı pençelerinden birini seçin.
Zephyr bunu sadece 70B parametreleriyle yapabildi, bu da "100 Sayfalık Makine Öğrenimi Kitabı" nın yazarı Andriy Burkov'u şaşırttı ve hatta şunları söyledi:
Kağıt Bağlantıları:
Referans Linkleri:
[1]
[2]
[3]
[4]
[5]