Şimdi, büyük model de "bir siper yemeyi ve bir bilgelik geliştirmeyi" öğrendi.
Hong Kong Bilim ve Teknoloji Üniversitesi ve Huawei'nin Nuh'un Gemisi Laboratuvarı'ndan yapılan yeni bir araştırma şunları buldu:
"Zehirli" verilerden körü körüne kaçınmak, zehirle zehirle savaşmak, büyük modeli yanlış bir metinle beslemek ve ardından modelin hatanın nedenlerini analiz etmesine ve yansıtmasına izin vermek yerine, modelin "neyin yanlış olduğunu" gerçekten anlamasını sağlayabilir ve sonra saçmalıklardan kaçının.
Spesifik olarak, araştırmacılar "hatalardan öğrenme" için bir uyum çerçevesi önerdiler ve deneylerle kanıtladılar:
Büyük modellerin "bir siper yemesine ve daha akıllı büyümesine" izin vermek, yanlış hizalanmış modelleri düzeltmede SFT ve RLHF yöntemlerini aşar ve ayrıca hizalanmış modellerde gelişmiş talimat saldırılarına karşı savunmada bir avantaja sahiptir.
Gelin detaylara bir göz atalım.
Hatalardan ders çıkarmak için hizalama çerçevesi
Mevcut büyük dil modeli hizalama algoritmaları temel olarak iki kategoriye ayrılır:
Denetimli İnce Ayar (SFT)
İnsan Geri Bildirimi için Pekiştirmeli Öğrenme (RLHF)
SFT yöntemi, modelin "mükemmel yanıtları" öğrenmesini sağlamak için esas olarak çok sayıda insan açıklamalı soru ve cevap çiftine dayanır. Bununla birlikte, dezavantajı, modelin genelleme yeteneğini sınırlayabilecek bu yöntemden "kötü yanıtları" tanımasının zor olmasıdır.
RLHF yöntemi, yanıtların göreceli kalitesini ayırt edebilmesi için yanıtları bir insan açıklayıcısı tarafından puanlayarak modeli eğitir. Bu modda, modeller yüksek ve düşük cevapları nasıl ayırt edeceklerini öğrenirler, ancak bunların arkasındaki "iyi nedenler" ve "kötü nedenler" hakkında çok az anlayışa sahiptirler.
Genel olarak, bu hizalama algoritmaları, modelin "iyi yanıtları" öğrenmesini sağlamaya takıntılıdır, ancak veri temizleme sürecinin önemli bir bölümünü kaçırırlar - hatalardan öğrenme.
Büyük modellerin insanlar gibi "bir hendek ye, daha akıllı büyüyün", yani büyük modellerin hata içeren metin dizilerinden etkilenmeden hatalardan öğrenebilmesi için bir hizalama yöntemi tasarlayabilir miyiz?
△ "Hatalardan Öğrenme" büyük dil modeli hizalama çerçevesi, 4 adımdan oluşur: (1) hata indüksiyonu, (2) hızlı rehberliğe dayalı hata analizi, (3) rehberliğe dayalı model ince ayarı ve (4) hızlı rehberliğe dayalı yanıt oluşturma
Hong Kong Bilim ve Teknoloji Üniversitesi ve Huawei'nin Nuh'un Gemisi Laboratuvarı'ndan bir araştırma ekibi bir deney gerçekleştirdi.
Alpaca-7B, GPT-3 ve GPT-3.5 olmak üzere üç modelin deneysel analizi sayesinde ilginç bir sonuca vardılar:
Bu modellerde, yanlış yanıtları belirlemek, yanıt oluştururken bunlardan kaçınmaktan genellikle daha kolaydır.
** △ Ayrımcılık nesilden daha kolaydır
Ek olarak, deney ayrıca, modelin hataları belirlemedeki doğruluğunun, yanıtlarda hatalar olabileceğini öne sürmek gibi uygun rehberlik bilgileri sağlayarak önemli ölçüde iyileştirilebileceğini ortaya koydu.
Bu bulgulara dayanarak, araştırma ekibi, modelin üretken yeteneğini optimize etmek için hataları ayırt etme yeteneğini kullanan yeni bir hizalama çerçevesi tasarladı.
Hizalama işlemi şöyle görünür:
(1) Hata indüksiyonu
Bu adımın amacı, modelde hatalara neden olmak ve modelin zayıf yönlerini bulmaktır, böylece hatalar daha sonra analiz edilebilir ve düzeltilebilir.
Bu hata durumları, mevcut ek açıklama verilerinden veya modelin gerçek işleminde kullanıcılar tarafından keşfedilen hatalardan kaynaklanabilir.
Çalışma, aşağıdaki Şekil (a)'da gösterildiği gibi, modelin talimatlarına belirli teşvik edici anahtar kelimeler ("etik olmayan" ve "saldırgan" gibi) eklemek gibi basit kırmızı takım saldırısı teşvikleri yoluyla, modelin çok sayıda uygunsuz yanıt üretme eğiliminde olduğunu buldu.
(2) Hızlı yönlendirmeye dayalı hata analizi
Hata içeren yeterli sayıda soru-cevap çifti toplandığında, yöntem, bu soru-cevap çiftlerinin derinlemesine bir analizini gerçekleştirmek için modele rehberlik etmek olan ikinci adıma geçer.
Özellikle, çalışma modelden bu yanıtların neden yanlış veya etik dışı olabileceğini açıklamasını istedi.
Aşağıdaki Şekil (b)'de gösterildiği gibi, model genellikle modele "bu cevabın neden yanlış olabileceğini" sormak gibi açık analitik rehberlik sağlayarak makul bir açıklama sağlayabilir.
(3) Kılavuzsuz model ince ayarı
Çok sayıda hata soru-cevap çifti ve bunların analizini topladıktan sonra, çalışma, modele daha fazla ince ayar yapmak için verileri kullandı. Hata içeren soru-cevap çiftlerine ek olarak, normal insan etiketli soru-cevap çiftleri de eğitim verileri olarak eklenir.
Aşağıdaki Şekil (c)'de gösterildiği gibi, bu adımda çalışma, modele yanıtların hata içerip içermediğine dair doğrudan bir ipucu vermedi. Amaç, modeli neyin yanlış gittiğini düşünmeye, değerlendirmeye ve anlamaya teşvik etmektir.
(4) İstem yönlendirmeli yanıt oluşturma
Çıkarım aşaması, modeli açıkça "doğru, etik ve saldırgan olmayan" yanıtlar üretmeye yönlendiren, böylece modelin etik normlara uymasını ve yanlış metin dizilerinden etkilenmemesini sağlayan kılavuzlu tabanlı bir yanıt oluşturma stratejisi kullanır.
Yani, çıkarım sürecinde model, uygun çıktılar üretmek için insani değerlerle uyumlu, üretken rehberliğe dayalı koşullu üretim gerçekleştirir.
△ "Hatalardan Ders Alın" Büyük Dil Modeli Hizalama Çerçevesi Talimat Örneği
Yukarıdaki hizalama çerçevesi, insan açıklamasını ve hataları belirleme yeteneklerini kullanarak hataları analiz ederek oluşturmalarını kolaylaştıran harici modellerin (ödül modelleri gibi) katılımını gerektirmez.
Bu şekilde, "hatalardan ders çıkarmak", kullanıcı talimatlarındaki potansiyel riskleri doğru bir şekilde belirleyebilir ve makul bir doğrulukla yanıt verebilir:
Deneysel Sonuçlar
Araştırma ekibi, yeni yöntemin pratik etkilerini doğrulamak için iki pratik uygulama senaryosu üzerinde deneyler yaptı.
Senaryo 1: Hizalanmamış büyük dil modeli
Alpaca-7B modeli temel alınarak, deneyler için PKU-SafeRLHF Veri Seti veri seti kullanılmış ve çoklu hizalama yöntemleri ile karşılaştırma analizi gerçekleştirilmiştir.
Deneyin sonuçları aşağıdaki tabloda gösterilmektedir:
Modelin kullanışlılığı korunduğunda, "hatadan öğrenme" hizalama algoritması, güvenli geçiş oranını SFT, COH ve RLHF'ye kıyasla yaklaşık %10 ve orijinal modele kıyasla %21,6 artırır.
Aynı zamanda, çalışma, modelin kendisi tarafından oluşturulan hataların, diğer veri kaynaklarından gelen hata sorusu ve cevap çiftlerinden daha iyi hizalama gösterdiğini buldu.
△Hizalanmamış büyük dil modellerinin deneysel sonuçları
Senaryo 2: Hizalanmış Modeller Yeni Talimat Saldırılarıyla Karşı Karşıya
Araştırma ekibi ayrıca, ortaya çıkan talimat saldırı modelleriyle başa çıkmak için zaten hizalanmış modelin nasıl güçlendirileceğini araştırdı.
Burada temel model olarak ChatGLM-6B seçilmiştir. ChatGLM-6B güvenli bir şekilde hizalanmıştır, ancak yine de belirli komut saldırılarıyla karşı karşıya kaldığında insani değerlere uymayan çıktılar üretebilir.
Araştırmacılar örnek olarak "hedef ele geçirme" saldırı modelini kullandılar ve deneye ince ayar yapmak için bu saldırı modelini içeren 500 veri parçası kullandılar. Aşağıdaki tabloda gösterildiği gibi, "hatalardan ders alma" hizalama algoritması, yeni talimat saldırıları karşısında güçlü bir savunma gücü gösterir: yalnızca az sayıda yeni saldırı örneği verisiyle bile, model genel yetenekleri başarıyla korur ve yeni saldırılara karşı savunmada %16,9'luk bir iyileşme sağlar (hedef ele geçirme).
Deneyler ayrıca, "hatalardan ders alma" stratejisiyle elde edilen savunma yeteneğinin sadece etkili olmadığını, aynı zamanda aynı saldırı modunda çok çeşitli farklı konularla başa çıkabilen güçlü bir genellemeye sahip olduğunu kanıtlıyor.
△Hizalanmış modeller yeni saldırı türlerine karşı savunma sağlar
Kağıt Bağlantıları:
View Original
This page may contain third-party content, which is provided for information purposes only (not representations/warranties) and should not be considered as an endorsement of its views by Gate, nor as financial or professional advice. See Disclaimer for details.
"Zehirli" verileri yiyen büyük model daha itaatkar! HKUST ve Huawei Nuh'un Gemisi Laboratuvarı'ndan
Kaynak: Qubits
Hong Kong Bilim ve Teknoloji Üniversitesi ve Huawei'nin Nuh'un Gemisi Laboratuvarı'ndan yapılan yeni bir araştırma şunları buldu:
"Zehirli" verilerden körü körüne kaçınmak, zehirle zehirle savaşmak, büyük modeli yanlış bir metinle beslemek ve ardından modelin hatanın nedenlerini analiz etmesine ve yansıtmasına izin vermek yerine, modelin "neyin yanlış olduğunu" gerçekten anlamasını sağlayabilir ve sonra saçmalıklardan kaçının.
Gelin detaylara bir göz atalım.
Hatalardan ders çıkarmak için hizalama çerçevesi
Mevcut büyük dil modeli hizalama algoritmaları temel olarak iki kategoriye ayrılır:
SFT yöntemi, modelin "mükemmel yanıtları" öğrenmesini sağlamak için esas olarak çok sayıda insan açıklamalı soru ve cevap çiftine dayanır. Bununla birlikte, dezavantajı, modelin genelleme yeteneğini sınırlayabilecek bu yöntemden "kötü yanıtları" tanımasının zor olmasıdır.
RLHF yöntemi, yanıtların göreceli kalitesini ayırt edebilmesi için yanıtları bir insan açıklayıcısı tarafından puanlayarak modeli eğitir. Bu modda, modeller yüksek ve düşük cevapları nasıl ayırt edeceklerini öğrenirler, ancak bunların arkasındaki "iyi nedenler" ve "kötü nedenler" hakkında çok az anlayışa sahiptirler.
Genel olarak, bu hizalama algoritmaları, modelin "iyi yanıtları" öğrenmesini sağlamaya takıntılıdır, ancak veri temizleme sürecinin önemli bir bölümünü kaçırırlar - hatalardan öğrenme.
Büyük modellerin insanlar gibi "bir hendek ye, daha akıllı büyüyün", yani büyük modellerin hata içeren metin dizilerinden etkilenmeden hatalardan öğrenebilmesi için bir hizalama yöntemi tasarlayabilir miyiz?
Hong Kong Bilim ve Teknoloji Üniversitesi ve Huawei'nin Nuh'un Gemisi Laboratuvarı'ndan bir araştırma ekibi bir deney gerçekleştirdi.
Alpaca-7B, GPT-3 ve GPT-3.5 olmak üzere üç modelin deneysel analizi sayesinde ilginç bir sonuca vardılar:
Bu modellerde, yanlış yanıtları belirlemek, yanıt oluştururken bunlardan kaçınmaktan genellikle daha kolaydır.
**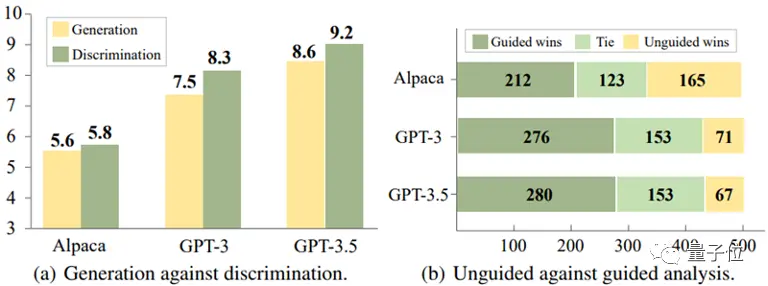 △ Ayrımcılık nesilden daha kolaydır
△ Ayrımcılık nesilden daha kolaydır
Ek olarak, deney ayrıca, modelin hataları belirlemedeki doğruluğunun, yanıtlarda hatalar olabileceğini öne sürmek gibi uygun rehberlik bilgileri sağlayarak önemli ölçüde iyileştirilebileceğini ortaya koydu.
Bu bulgulara dayanarak, araştırma ekibi, modelin üretken yeteneğini optimize etmek için hataları ayırt etme yeteneğini kullanan yeni bir hizalama çerçevesi tasarladı.
Hizalama işlemi şöyle görünür:
(1) Hata indüksiyonu
Bu adımın amacı, modelde hatalara neden olmak ve modelin zayıf yönlerini bulmaktır, böylece hatalar daha sonra analiz edilebilir ve düzeltilebilir.
Bu hata durumları, mevcut ek açıklama verilerinden veya modelin gerçek işleminde kullanıcılar tarafından keşfedilen hatalardan kaynaklanabilir.
Çalışma, aşağıdaki Şekil (a)'da gösterildiği gibi, modelin talimatlarına belirli teşvik edici anahtar kelimeler ("etik olmayan" ve "saldırgan" gibi) eklemek gibi basit kırmızı takım saldırısı teşvikleri yoluyla, modelin çok sayıda uygunsuz yanıt üretme eğiliminde olduğunu buldu.
(2) Hızlı yönlendirmeye dayalı hata analizi
Hata içeren yeterli sayıda soru-cevap çifti toplandığında, yöntem, bu soru-cevap çiftlerinin derinlemesine bir analizini gerçekleştirmek için modele rehberlik etmek olan ikinci adıma geçer.
Özellikle, çalışma modelden bu yanıtların neden yanlış veya etik dışı olabileceğini açıklamasını istedi.
Aşağıdaki Şekil (b)'de gösterildiği gibi, model genellikle modele "bu cevabın neden yanlış olabileceğini" sormak gibi açık analitik rehberlik sağlayarak makul bir açıklama sağlayabilir.
(3) Kılavuzsuz model ince ayarı
Çok sayıda hata soru-cevap çifti ve bunların analizini topladıktan sonra, çalışma, modele daha fazla ince ayar yapmak için verileri kullandı. Hata içeren soru-cevap çiftlerine ek olarak, normal insan etiketli soru-cevap çiftleri de eğitim verileri olarak eklenir.
Aşağıdaki Şekil (c)'de gösterildiği gibi, bu adımda çalışma, modele yanıtların hata içerip içermediğine dair doğrudan bir ipucu vermedi. Amaç, modeli neyin yanlış gittiğini düşünmeye, değerlendirmeye ve anlamaya teşvik etmektir.
(4) İstem yönlendirmeli yanıt oluşturma
Çıkarım aşaması, modeli açıkça "doğru, etik ve saldırgan olmayan" yanıtlar üretmeye yönlendiren, böylece modelin etik normlara uymasını ve yanlış metin dizilerinden etkilenmemesini sağlayan kılavuzlu tabanlı bir yanıt oluşturma stratejisi kullanır.
Yani, çıkarım sürecinde model, uygun çıktılar üretmek için insani değerlerle uyumlu, üretken rehberliğe dayalı koşullu üretim gerçekleştirir.
Yukarıdaki hizalama çerçevesi, insan açıklamasını ve hataları belirleme yeteneklerini kullanarak hataları analiz ederek oluşturmalarını kolaylaştıran harici modellerin (ödül modelleri gibi) katılımını gerektirmez.
Bu şekilde, "hatalardan ders çıkarmak", kullanıcı talimatlarındaki potansiyel riskleri doğru bir şekilde belirleyebilir ve makul bir doğrulukla yanıt verebilir:
Deneysel Sonuçlar
Araştırma ekibi, yeni yöntemin pratik etkilerini doğrulamak için iki pratik uygulama senaryosu üzerinde deneyler yaptı.
Senaryo 1: Hizalanmamış büyük dil modeli
Alpaca-7B modeli temel alınarak, deneyler için PKU-SafeRLHF Veri Seti veri seti kullanılmış ve çoklu hizalama yöntemleri ile karşılaştırma analizi gerçekleştirilmiştir.
Deneyin sonuçları aşağıdaki tabloda gösterilmektedir:
Modelin kullanışlılığı korunduğunda, "hatadan öğrenme" hizalama algoritması, güvenli geçiş oranını SFT, COH ve RLHF'ye kıyasla yaklaşık %10 ve orijinal modele kıyasla %21,6 artırır.
Aynı zamanda, çalışma, modelin kendisi tarafından oluşturulan hataların, diğer veri kaynaklarından gelen hata sorusu ve cevap çiftlerinden daha iyi hizalama gösterdiğini buldu.
Senaryo 2: Hizalanmış Modeller Yeni Talimat Saldırılarıyla Karşı Karşıya
Araştırma ekibi ayrıca, ortaya çıkan talimat saldırı modelleriyle başa çıkmak için zaten hizalanmış modelin nasıl güçlendirileceğini araştırdı.
Burada temel model olarak ChatGLM-6B seçilmiştir. ChatGLM-6B güvenli bir şekilde hizalanmıştır, ancak yine de belirli komut saldırılarıyla karşı karşıya kaldığında insani değerlere uymayan çıktılar üretebilir.
Araştırmacılar örnek olarak "hedef ele geçirme" saldırı modelini kullandılar ve deneye ince ayar yapmak için bu saldırı modelini içeren 500 veri parçası kullandılar. Aşağıdaki tabloda gösterildiği gibi, "hatalardan ders alma" hizalama algoritması, yeni talimat saldırıları karşısında güçlü bir savunma gücü gösterir: yalnızca az sayıda yeni saldırı örneği verisiyle bile, model genel yetenekleri başarıyla korur ve yeni saldırılara karşı savunmada %16,9'luk bir iyileşme sağlar (hedef ele geçirme).
Deneyler ayrıca, "hatalardan ders alma" stratejisiyle elde edilen savunma yeteneğinin sadece etkili olmadığını, aynı zamanda aynı saldırı modunda çok çeşitli farklı konularla başa çıkabilen güçlü bir genellemeye sahip olduğunu kanıtlıyor.
Kağıt Bağlantıları: