Yao Qizhi взяв на себе ініціативу, запропонувавши структуру «мислення» великої моделі! Точність логічних міркувань становить 98%, а спосіб мислення більше схожий на людський.
Перша стаття Велика мовна модель під керівництвом лауреата премії Тюрінга Яо Ціджі вже тут!
Як тільки я почав, я націлився на те, щоб «змусити великих моделей думати як люди»——
Великим моделям потрібно не тільки міркувати крок за кроком, але й навчитися «крок за кроком» і запам’ятати всі правильні процеси в процесі міркування.
Зокрема, у цій новій статті пропонується новий метод під назвою «Кумулятивне міркування», який значно покращує здатність великих моделей брати участь у складних міркуваннях.
Ви повинні знати, що великі моделі базуються на ланцюжках мислення тощо, і їх можна використовувати для міркування проблем, але коли ви стикаєтеся з проблемами, які вимагають «декількох поворотів», все одно легко зробити помилку.
Саме на цій основі кумулятивне міркування додає «перевірку», щоб оцінювати правильне від неправильного в реальному часі. Концепція мислення цієї моделі також змінилася з ланцюга та дерева на більш складний «орієнтований ациклічний граф».
Таким чином велика модель не тільки має чіткіші ідеї вирішення проблем, але й розвиває навик «грати в карти»:
У таких математичних задачах, як алгебра та геометрична теорія чисел, відносна точність великих моделей зросла на 42%; при грі на 24 очки показник успіху зріс до 98%.
За даними Інституту перехресної інформації при Університеті Цінхуа, співавтор Чжан Іфань пояснив вихідну точку цієї статті:
Канеман вважає, що когнітивна обробка людини включає дві системи: «Система 1» є швидкою, інстинктивною та емоційною, а «Система 2» є повільною, продуманою та логічною.
Наразі продуктивність великих мовних моделей ближча до «Системи 1», що може бути причиною того, чому вона погано справляється зі складними завданнями.
Кумулятивне міркування, створене з цієї точки зору, краще, ніж Ланцюг думок (CoT) і Дерево мислення (ToT).
Отже, як насправді виглядає цей новий підхід? Давайте разом подивимось.
Прорив у ланцюжку мислення та дерево «вузьких місць»
Суть кумулятивного міркування полягає в удосконаленні «форми» процесу мислення великих моделей.
Зокрема, цей метод використовує 3 великі моделі мови:
Пропонент: Постійно пропонуйте нові пропозиції, тобто пропонуйте наступний крок на основі поточного контексту мислення.
Верифікатор: перевіряє точність пропозиції автора та додає її до контексту мислення, якщо вона правильна.
Репортер: Визначає, чи було отримано остаточне рішення та чи потрібно завершувати процес міркування.
Під час міркування «пропонент» спочатку дає пропозицію, «верифікатор» відповідає за оцінку, а «репортер» вирішує, чи завершувати відповідь і чи припинити процес мислення.
** ****△**Приклад аргументації CR
Це трохи схоже на три типи ролей у командному проекті: члени команди спочатку обговорюють різні ідеї, інструктор «перевіряє», яка ідея здійсненна, а керівник команди вирішує, коли завершити проект.
**Отже, як саме цей підхід змінює «форму» мислення великої моделі? **
Щоб зрозуміти це, ми маємо почати з «Ланцюжка думок, CoT» (Chain of Thought, CoT), «зачинателя» методів покращення мислення великої моделі.
Цей метод був запропонований вченим OpenAI Джейсоном Веєм та іншими в січні 2022 року. Суть полягає в додаванні тексту «покрокових міркувань» до вхідних даних у наборі даних, щоб стимулювати мисленнєву здатність великої моделі.
** ****△**Вибрано з набору даних GSM8K
На основі принципу мисленнєвого ланцюжка Google також швидко розробив «версію мисленнєвого ланцюга PLUS», а саме CoT-SC, яка в основному виконує кілька процесів мисленнєвого ланцюга та проводить голосування більшістю відповідей, щоб вибрати найкращий Найкраща відповідь може ще більше підвищити точність міркувань.
Але як Thinking Chain, так і CoT-SC ігнорують одну проблему: існує більше ніж одне рішення питання, особливо коли проблему вирішують люди.
Тому згодом з'явилося нове дослідження під назвою Дерево думок (ToT).
Це деревоподібна схема пошуку, яка дає змогу моделі спробувати різні міркування, самооцінити, вибрати наступний курс дій і, якщо необхідно, повернутися назад.
З методу видно, що дерево мислення йде далі, ніж ланцюг мислення, роблячи мислення великої моделі «більш активним».
Ось чому при розіграші 24 балів коефіцієнт успішності бонусу «Ланцюжок думок» GPT-4 становить лише 4%**, але показник успішності «Дерева думок» злітає до 74%.
АЛЕ, незалежно від ланцюга мислення, CoT-SC чи дерева мислення, має загальне обмеження:
Жоден із них не встановив місце для зберігання проміжних результатів мисленнєвого процесу.
Зрештою, не всі процеси мислення можна об’єднати в ланцюги чи дерева. Спосіб мислення людей про речі часто складніший.
Ця нова кумулятивна структура міркувань прориває цей момент у дизайні——
Загальний процес мислення великої моделі не обов’язково є ланцюгом чи деревом, це також може бути Спрямований ациклічний граф (DAG)! (Ну, це пахне синапсами)
** ****△**Ребра в графі мають напрямки, і немає кругових шляхів; кожне спрямоване ребро є кроком виведення
Це означає, що він може зберігати всі історично правильні результати висновків у пам’яті для дослідження в поточній гілці пошуку. (На відміну від цього, думаюче дерево не зберігає інформацію з інших гілок)
Але кумулятивне міркування також можна плавно перемикати з ланцюгом мислення - доки «перевірку» видалено, це стандартна модель ланцюга мислення.
Кумулятивне міркування, розроблене на основі цього методу, досягло хороших результатів у різних методах.
Добре вміє математика та логічне міркування
Дослідники обрали FOLIO wiki та AutoTNLI, 24-точкову гру та набори даних MATH для «перевірки» сукупного міркування.
Пропонент, верифікатор і звітник використовують ту саму велику мовну модель у кожному експерименті з різними налаштуваннями для своїх ролей.
Основні моделі, які використовуються тут для експериментів, включають GPT-3.5-turbo, GPT-4, LLaMA-13B і LLaMA-65B.
Варто зазначити, що в ідеалі модель має бути попередньо навчена з використанням відповідних даних завдання виведення, а «верифікатор» також має додати формальний математичний прувер, модуль розв’язувача пропозиційної логіки тощо.
1. Здатність до логічного мислення
FOLIO — це набір даних для логічних міркувань першого порядку, а мітки запитань можуть бути «true», «False» і «Unknown»; AutoTNLI — це набір даних для логічних міркувань вищого порядку.
У наборі даних FOLIO wiki порівняно з методами прямого виведення (Direct), методами ланцюга мислення (CoT) і розширеного ланцюга мислення (CoT-SC) ефективність сукупного міркування (CR) завжди є найкращою.
Після видалення проблемних випадків (таких як неправильні відповіді) з набору даних точність висновку GPT-4 за допомогою методу CR досягла 98,04% з мінімальним рівнем помилок 1,96%.
Давайте подивимося на продуктивність набору даних AutoTNLI:
У порівнянні з методом CoT, CR значно покращив продуктивність LLaMA-13B і LLaMA-65B.
На моделі LLaMA-65B покращення CR порівняно з CoT досягло 9,3%.
### 2. Можливість грати в ігри з 24 очками
В оригінальному документі ToT використовувалася гра з 24 очками, тому дослідники використовували цей набір даних, щоб порівняти CR і ToT.
ToT використовує дерево пошуку фіксованої ширини та глибини, а CR дозволяє великим моделям автономно визначати глибину пошуку.
Під час експериментів дослідники виявили, що в контексті 24 балів алгоритм CR і алгоритм ToT дуже схожі. Різниця полягає в тому, що алгоритм у CR генерує щонайбільше один новий стан за ітерацію, тоді як ToT генерує багато станів-кандидатів у кожній ітерації та фільтрує та зберігає частину стану.
Говорячи простою мовою, ToT не має згаданого вище «перевірника», як CR, і не може визначити, чи є стани (a, b, c) правильними чи неправильними. Тому ToT досліджуватиме більше недійсних станів, ніж CR.
Зрештою, точність методу CR може досягати навіть 98% (ToT становить 74%), а середня кількість доступних станів набагато менша, ніж ToT.
Іншими словами, CR не тільки має вищий показник точності пошуку, але також має вищу ефективність пошуку.
### 3. Математичні здібності
Набір даних MATH містить велику кількість математичних запитань, включаючи алгебру, геометрію, теорію чисел тощо. Складність запитань розділена на п’ять рівнів.
Використовуючи метод CR, модель може розкласти запитання на підзапитання, які можна виконувати крок за кроком, і ставити запитання та відповідати на них, доки не буде згенеровано відповідь.
Експериментальні результати показують, що за двох різних експериментальних налаштувань рівень точності CR перевищує поточні існуючі методи, із загальним показником точності до 58%, а відносне підвищення точності на 42% у задачі рівня 5. Завантажено новий SOTA під модель ГПТ-4.
Дослідження під керівництвом Яо Цічжі та Юань Яна з Університету Цінхуа
Ця стаття надійшла від дослідницької групи AI for Math під керівництвом Яо Цічжі та Юань Яна з Інституту міждисциплінарної інформації Цінхуа.
Співавторами статті є Чжан Іфань і Ян Цзінькінь, 2021 докторанти Інституту міждисциплінарної інформації;
Інструктором і співавтором є доцент Юань Ян і академік Яо Цічжі.
Чжан Іфань
Чжан Іфань закінчив Юаньпейський коледж Пекінського університету в 2021 році. Зараз він навчається під керівництвом доцента Юань Яна. Його основними напрямками досліджень є теорія та алгоритм базових моделей (великі мовні моделі), самоконтрольоване навчання та довірений штучний інтелект.
Ян Цзінцін
Ян Цзінькінь отримав ступінь бакалавра в Інституті перехресної інформації Університету Цінхуа в 2021 році і зараз здобуває докторський ступінь під керівництвом доцента Юань Яна. Основні напрямки досліджень включають великі мовні моделі, самоконтрольоване навчання, інтелектуальне медичне обслуговування тощо.
Юань Ян
Юань Ян є доцентом Школи міждисциплінарної інформації Університету Цінхуа. Закінчив факультет комп’ютерних наук Пекінського університету в 2012 році; отримав ступінь доктора філософії з комп’ютерних наук у Корнельському університеті в США в 2018 році; з 2018 по 2019 рік він працював докторантом у Школі науки про великі дані Массачусетського інституту. технології.
Його основні напрямки досліджень – інтелектуальна медична допомога, базова теорія ШІ, прикладна теорія категорій тощо.
Яо Цичжі
Яо Цічжі — академік Академії наук Китаю та декан Інституту міждисциплінарної інформації Університету Цінхуа. Він також є першим азіатським вченим, який отримав премію Тюрінга з моменту її заснування, і єдиним китайським комп’ютерним вченим, який отримав цю нагороду. так далеко.
Професор Яо Цічжі залишив Прінстонський університет як штатний професор у 2004 році та повернувся до Цінхуа, щоб викладати; у 2005 році він заснував «Яо клас», експериментальний клас з інформатики для студентів Цінхуа; у 2011 році він заснував «Центр квантової інформації Цінхуа». " та "Міждисциплінарний інформаційний науково-дослідний інститут"; у 2019 році. У 2008 році він заснував клас штучного інтелекту для студентів бакалаврату Цінхуа, який називають "Розумним класом".
Сьогодні очолюваний ним Міждисциплінарний інформаційний інститут Університету Цінхуа вже давно відомий. Яо Класс і Чжибань є афілійованими з Міждисциплінарним інформаційним інститутом.
Сфера наукових інтересів професора Яо Цічжі включає алгоритми, криптографію, квантові обчислення тощо. Він є міжнародним піонером і авторитетом у цій галузі. Нещодавно він виступив на Всесвітній конференції зі штучного інтелекту 2023. Шанхайський дослідницький інститут Qizhi, який він очолює, зараз вивчає «втілений загальний штучний інтелект».
Папір посилання:
Переглянути оригінал
Ця сторінка може містити контент третіх осіб, який надається виключно в інформаційних цілях (не в якості запевнень/гарантій) і не повинен розглядатися як схвалення його поглядів компанією Gate, а також як фінансова або професійна консультація. Див. Застереження для отримання детальної інформації.
Yao Qizhi взяв на себе ініціативу, запропонувавши структуру «мислення» великої моделі! Точність логічних міркувань становить 98%, а спосіб мислення більше схожий на людський.
Джерело: Qubits
Перша стаття Велика мовна модель під керівництвом лауреата премії Тюрінга Яо Ціджі вже тут!
Як тільки я почав, я націлився на те, щоб «змусити великих моделей думати як люди»——
Великим моделям потрібно не тільки міркувати крок за кроком, але й навчитися «крок за кроком» і запам’ятати всі правильні процеси в процесі міркування.
Зокрема, у цій новій статті пропонується новий метод під назвою «Кумулятивне міркування», який значно покращує здатність великих моделей брати участь у складних міркуваннях.
Саме на цій основі кумулятивне міркування додає «перевірку», щоб оцінювати правильне від неправильного в реальному часі. Концепція мислення цієї моделі також змінилася з ланцюга та дерева на більш складний «орієнтований ациклічний граф».
Таким чином велика модель не тільки має чіткіші ідеї вирішення проблем, але й розвиває навик «грати в карти»:
У таких математичних задачах, як алгебра та геометрична теорія чисел, відносна точність великих моделей зросла на 42%; при грі на 24 очки показник успіху зріс до 98%.
Кумулятивне міркування, створене з цієї точки зору, краще, ніж Ланцюг думок (CoT) і Дерево мислення (ToT).
Отже, як насправді виглядає цей новий підхід? Давайте разом подивимось.
Прорив у ланцюжку мислення та дерево «вузьких місць»
Суть кумулятивного міркування полягає в удосконаленні «форми» процесу мислення великих моделей.
Зокрема, цей метод використовує 3 великі моделі мови:
Під час міркування «пропонент» спочатку дає пропозицію, «верифікатор» відповідає за оцінку, а «репортер» вирішує, чи завершувати відповідь і чи припинити процес мислення.
**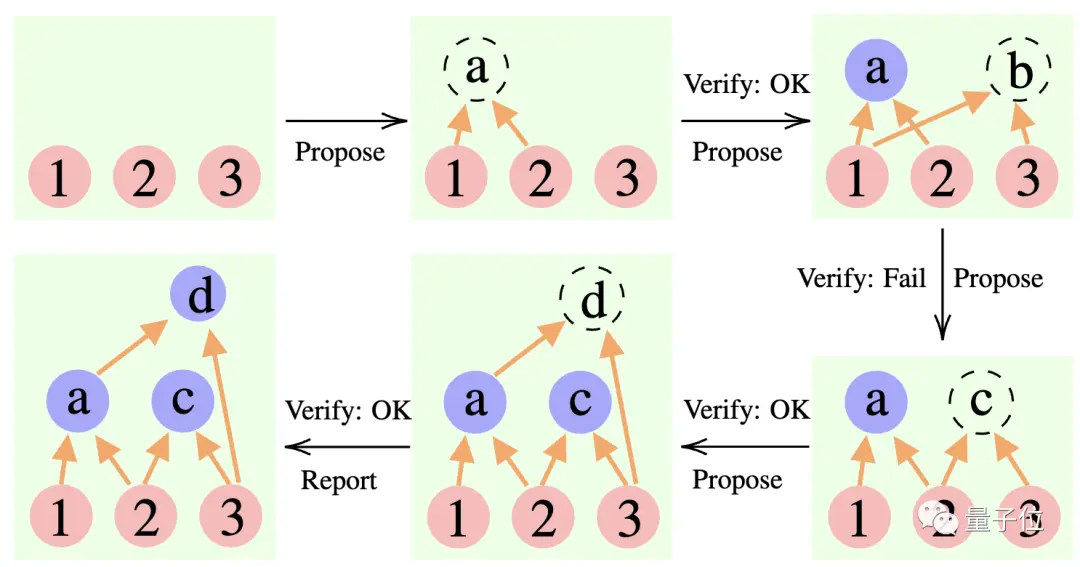 ****△**Приклад аргументації CR
****△**Приклад аргументації CR
Це трохи схоже на три типи ролей у командному проекті: члени команди спочатку обговорюють різні ідеї, інструктор «перевіряє», яка ідея здійсненна, а керівник команди вирішує, коли завершити проект.
Щоб зрозуміти це, ми маємо почати з «Ланцюжка думок, CoT» (Chain of Thought, CoT), «зачинателя» методів покращення мислення великої моделі.
Цей метод був запропонований вченим OpenAI Джейсоном Веєм та іншими в січні 2022 року. Суть полягає в додаванні тексту «покрокових міркувань» до вхідних даних у наборі даних, щоб стимулювати мисленнєву здатність великої моделі.
**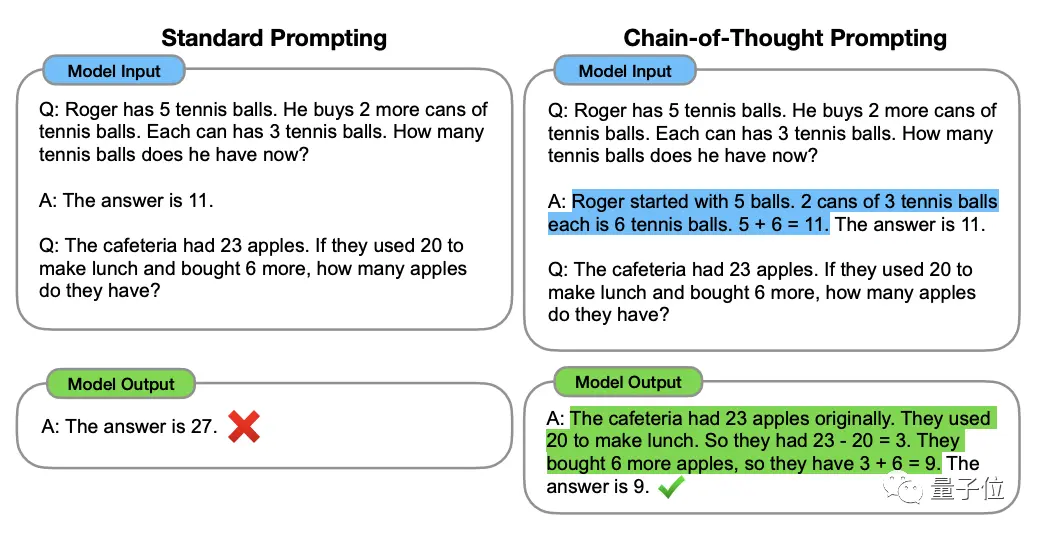 ****△**Вибрано з набору даних GSM8K
****△**Вибрано з набору даних GSM8K
На основі принципу мисленнєвого ланцюжка Google також швидко розробив «версію мисленнєвого ланцюга PLUS», а саме CoT-SC, яка в основному виконує кілька процесів мисленнєвого ланцюга та проводить голосування більшістю відповідей, щоб вибрати найкращий Найкраща відповідь може ще більше підвищити точність міркувань.
Але як Thinking Chain, так і CoT-SC ігнорують одну проблему: існує більше ніж одне рішення питання, особливо коли проблему вирішують люди.
Тому згодом з'явилося нове дослідження під назвою Дерево думок (ToT).
Це деревоподібна схема пошуку, яка дає змогу моделі спробувати різні міркування, самооцінити, вибрати наступний курс дій і, якщо необхідно, повернутися назад.
Ось чому при розіграші 24 балів коефіцієнт успішності бонусу «Ланцюжок думок» GPT-4 становить лише 4%**, але показник успішності «Дерева думок» злітає до 74%.
АЛЕ, незалежно від ланцюга мислення, CoT-SC чи дерева мислення, має загальне обмеження:
Зрештою, не всі процеси мислення можна об’єднати в ланцюги чи дерева. Спосіб мислення людей про речі часто складніший.
Ця нова кумулятивна структура міркувань прориває цей момент у дизайні——
Загальний процес мислення великої моделі не обов’язково є ланцюгом чи деревом, це також може бути Спрямований ациклічний граф (DAG)! (Ну, це пахне синапсами)
**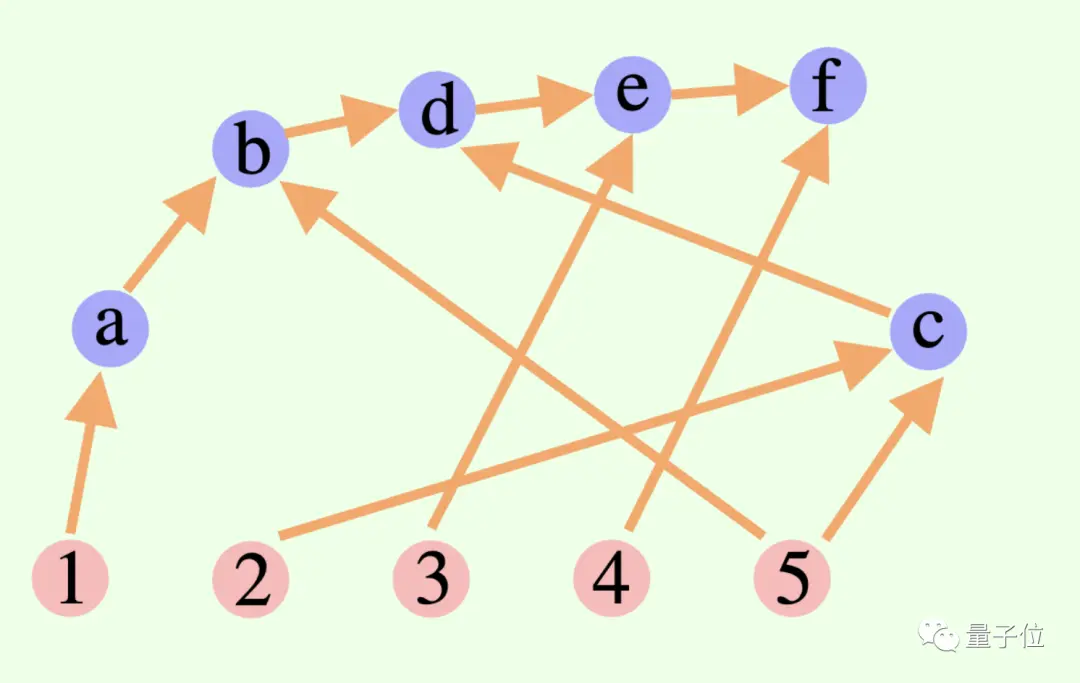 ****△**Ребра в графі мають напрямки, і немає кругових шляхів; кожне спрямоване ребро є кроком виведення
****△**Ребра в графі мають напрямки, і немає кругових шляхів; кожне спрямоване ребро є кроком виведення
Це означає, що він може зберігати всі історично правильні результати висновків у пам’яті для дослідження в поточній гілці пошуку. (На відміну від цього, думаюче дерево не зберігає інформацію з інших гілок)
Але кумулятивне міркування також можна плавно перемикати з ланцюгом мислення - доки «перевірку» видалено, це стандартна модель ланцюга мислення.
Кумулятивне міркування, розроблене на основі цього методу, досягло хороших результатів у різних методах.
Добре вміє математика та логічне міркування
Дослідники обрали FOLIO wiki та AutoTNLI, 24-точкову гру та набори даних MATH для «перевірки» сукупного міркування.
Пропонент, верифікатор і звітник використовують ту саму велику мовну модель у кожному експерименті з різними налаштуваннями для своїх ролей.
Основні моделі, які використовуються тут для експериментів, включають GPT-3.5-turbo, GPT-4, LLaMA-13B і LLaMA-65B.
Варто зазначити, що в ідеалі модель має бути попередньо навчена з використанням відповідних даних завдання виведення, а «верифікатор» також має додати формальний математичний прувер, модуль розв’язувача пропозиційної логіки тощо.
1. Здатність до логічного мислення
FOLIO — це набір даних для логічних міркувань першого порядку, а мітки запитань можуть бути «true», «False» і «Unknown»; AutoTNLI — це набір даних для логічних міркувань вищого порядку.
У наборі даних FOLIO wiki порівняно з методами прямого виведення (Direct), методами ланцюга мислення (CoT) і розширеного ланцюга мислення (CoT-SC) ефективність сукупного міркування (CR) завжди є найкращою.
Після видалення проблемних випадків (таких як неправильні відповіді) з набору даних точність висновку GPT-4 за допомогою методу CR досягла 98,04% з мінімальним рівнем помилок 1,96%.
У порівнянні з методом CoT, CR значно покращив продуктивність LLaMA-13B і LLaMA-65B.
На моделі LLaMA-65B покращення CR порівняно з CoT досягло 9,3%.
В оригінальному документі ToT використовувалася гра з 24 очками, тому дослідники використовували цей набір даних, щоб порівняти CR і ToT.
ToT використовує дерево пошуку фіксованої ширини та глибини, а CR дозволяє великим моделям автономно визначати глибину пошуку.
Під час експериментів дослідники виявили, що в контексті 24 балів алгоритм CR і алгоритм ToT дуже схожі. Різниця полягає в тому, що алгоритм у CR генерує щонайбільше один новий стан за ітерацію, тоді як ToT генерує багато станів-кандидатів у кожній ітерації та фільтрує та зберігає частину стану.
Говорячи простою мовою, ToT не має згаданого вище «перевірника», як CR, і не може визначити, чи є стани (a, b, c) правильними чи неправильними. Тому ToT досліджуватиме більше недійсних станів, ніж CR.
Іншими словами, CR не тільки має вищий показник точності пошуку, але також має вищу ефективність пошуку.
Набір даних MATH містить велику кількість математичних запитань, включаючи алгебру, геометрію, теорію чисел тощо. Складність запитань розділена на п’ять рівнів.
Використовуючи метод CR, модель може розкласти запитання на підзапитання, які можна виконувати крок за кроком, і ставити запитання та відповідати на них, доки не буде згенеровано відповідь.
Експериментальні результати показують, що за двох різних експериментальних налаштувань рівень точності CR перевищує поточні існуючі методи, із загальним показником точності до 58%, а відносне підвищення точності на 42% у задачі рівня 5. Завантажено новий SOTA під модель ГПТ-4.
Дослідження під керівництвом Яо Цічжі та Юань Яна з Університету Цінхуа
Ця стаття надійшла від дослідницької групи AI for Math під керівництвом Яо Цічжі та Юань Яна з Інституту міждисциплінарної інформації Цінхуа.
Співавторами статті є Чжан Іфань і Ян Цзінькінь, 2021 докторанти Інституту міждисциплінарної інформації;
Інструктором і співавтором є доцент Юань Ян і академік Яо Цічжі.
Чжан Іфань
Чжан Іфань закінчив Юаньпейський коледж Пекінського університету в 2021 році. Зараз він навчається під керівництвом доцента Юань Яна. Його основними напрямками досліджень є теорія та алгоритм базових моделей (великі мовні моделі), самоконтрольоване навчання та довірений штучний інтелект.
Ян Цзінцін
Ян Цзінькінь отримав ступінь бакалавра в Інституті перехресної інформації Університету Цінхуа в 2021 році і зараз здобуває докторський ступінь під керівництвом доцента Юань Яна. Основні напрямки досліджень включають великі мовні моделі, самоконтрольоване навчання, інтелектуальне медичне обслуговування тощо.
Юань Ян
Його основні напрямки досліджень – інтелектуальна медична допомога, базова теорія ШІ, прикладна теорія категорій тощо.
Яо Цичжі
Професор Яо Цічжі залишив Прінстонський університет як штатний професор у 2004 році та повернувся до Цінхуа, щоб викладати; у 2005 році він заснував «Яо клас», експериментальний клас з інформатики для студентів Цінхуа; у 2011 році він заснував «Центр квантової інформації Цінхуа». " та "Міждисциплінарний інформаційний науково-дослідний інститут"; у 2019 році. У 2008 році він заснував клас штучного інтелекту для студентів бакалаврату Цінхуа, який називають "Розумним класом".
Сьогодні очолюваний ним Міждисциплінарний інформаційний інститут Університету Цінхуа вже давно відомий. Яо Класс і Чжибань є афілійованими з Міждисциплінарним інформаційним інститутом.
Сфера наукових інтересів професора Яо Цічжі включає алгоритми, криптографію, квантові обчислення тощо. Він є міжнародним піонером і авторитетом у цій галузі. Нещодавно він виступив на Всесвітній конференції зі штучного інтелекту 2023. Шанхайський дослідницький інститут Qizhi, який він очолює, зараз вивчає «втілений загальний штучний інтелект».
Папір посилання: