Microsoft Стенфордські дослідники опублікували нову статтю, в якій запропонували систему STOP за допомогою ітеративних алгоритмів оптимізації, щоб GPT-4 міг самостійно покращувати вихідний код для завдання. Цей метод самооптимізації, який не змінює вагу та структуру моделі, дозволяє уникнути ризику «саморозвиваючих систем штучного інтелекту».
Проблему «рекурсивний ШІ самоеволюції домінує над людиною» вирішено?!
Багато великих ШІ розглядають розробку великих моделей, які можуть повторюватися самостійно, як «ярлик» для людей, щоб почати шлях до самознищення.
Співзасновник DeepMind заявив, що штучний інтелект, який може розвиватися автономно, має дуже величезні потенційні ризики
Тому що, якщо велика модель може самостійно покращувати власну вагу і рамки, а також постійно покращувати свою здатність до самовдосконалення, то не тільки про інтерпретованість моделі не може бути й мови, але й про те, що люди будуть абсолютно не в змозі передбачити і контролювати вихід моделі.
Якщо ви дозволите великій моделі «еволюціонувати автономно», вона може продовжувати видавати шкідливий контент, а якщо майбутня здатність буде розвиватися занадто сильно, вона, в свою чергу, може контролювати людей!
Нещодавно дослідники з Microsoft і Stanford розробили нову систему, яка дозволяє моделям самоповторюватися і покращувати якість результату без зміни ваги і фреймворків.
Що ще важливіше, ця система може значно покращити прозорість та інтерпретованість процесу «самовдосконалення» моделі, дозволяючи дослідникам розуміти та контролювати процес самовдосконалення моделі, тим самим запобігаючи появі «некерованого людиною» штучного інтелекту.
Паперова адреса:
«Рекурсивне самовдосконалення» (RSI) – одна з найстаріших ідей штучного інтелекту. Чи може мовна модель написати код, який рекурсивно вдосконалюється?
Дослідники запропонували оптимізатор-самоучку (STOP), який може рекурсивно самопокращувати генерацію коду.
Вони починаються з простої початкової програми-оптимізатора, яка бере код і цільові функції, і використовує мовну модель для поліпшення коду (повертаючи найкраще поліпшення в оптимізації k).
Оскільки "покращення коду" - це завдання, дослідники можуть передати "оптимізатор" самому собі! Потім повторюйте процес знову і знову.
Поки процес буде повторюватися достатньо, GPT-4 придумає багато дуже креативних стратегій самовдосконалення коду, таких як генетичні алгоритми, імітація відпалу або багаторукі ігрові автомати.
Враховуючи, що навчальні дані GPT-4 стосуються лише 2021 року, що раніше, ніж багато з виявлених покращених стратегій, справді дивно отримувати такі результати!
Крім того, оскільки дослідникам потрібен був якийсь спосіб оцінити покращений оптимізатор, вони визначили мету «Мета-корисність», яка є очікуваною метою оптимізатора при застосуванні до випадкових подальших програм і завдань.
Коли оптимізатор вдосконалюється, дослідники призначають цю цільову функцію алгоритму.
Основні результати, виявлені дослідниками: По-перше, очікувана подальша продуктивність оптимізаторів, що самовдосконалюються, зростала послідовно зі збільшенням кількості ітерацій самовдосконалення.
По-друге, ці вдосконалені оптимізатори також можуть бути хорошим способом поліпшити рішення завдань, які не були помічені під час навчання.
Хоча багато дослідників висловили занепокоєння з приводу моделей «рекурсивного самовдосконалення», вони вважають, що системи штучного інтелекту, які люди не можуть контролювати, можуть розвиватися. Але замість того, щоб оптимізувати саму модель, вона автоматично оптимізується під цільове завдання, що полегшує інтерпретацію процесу оптимізації.
І цей процес може бути використаний як випробувальний стенд для виявлення шкідливих стратегій «рекурсивного самовдосконалення».
Дослідники також виявили, що GPT-4 може активно видаляти «прапор відключення пісочниці» під час ітерації «в гонитві за ефективністю».
Користувачі мережі вважають, що метод, запропонований у цій роботі, має великий потенціал. Оскільки AGI майбутнього не може бути єдиною великою моделлю, вона, швидше за все, буде кластером незліченної кількості ефективних агентів, здатних працювати разом, щоб досягти успіху у величезних завданнях, поставлених перед ними.
Так само, як компанія має потужніший інтелект, ніж окремі співробітники.
Можливо, при такому підході, навіть якщо AGI неможливий, можна змусити спеціально оптимізовану модель досягти набагато більшої продуктивності, ніж вона сама, в обмеженому колі завдань.
Основа дисертації
У цій роботі дослідники пропонують Self-Teach Optimizer (STOP), який є застосуванням мовних моделей для покращення рекурсивного застосування коду для довільних рішень.
Підхід дослідників почався з початкової програми «оптимізатора», яка використовує мовні моделі для покращення рішень подальших завдань.
У міру того, як система повторюється, модель уточнює цю процедуру оптимізації. Дослідники використовували набір алгоритмічних завдань для кількісної оцінки продуктивності фреймворку, що самооптимізується.
Результати дослідників показали, що ефект значно покращився, коли модель застосувала свою стратегію самовдосконалення, оскільки вона збільшила кількість ітерацій.
STOP показує, як мовна модель діє як власний метаоптимізатор. Дослідники також вивчили види стратегій самовдосконалення, запропоновані моделлю (див. Рисунок 1 нижче), можливість перенесення запропонованих стратегій у подальших завданнях і дослідили чутливість моделі до небезпечних стратегій самовдосконалення.
На малюнку вище показано багато функціональних та цікавих каркасів, запропонованих STOP при використанні GPT-4, адже GPT-4 навчався з використанням даних до 2021 року, набагато раніше, ніж було запропоновано більшість конструктивних програм.
Таким чином, це показує, що ця система може генерувати корисні стратегії оптимізації для початкової оптимізації.
Основними внесками цієї роботи є:
Запропоновано метод "Meta-Optimizer", який генерує конструктивні програми для рекурсивного покращення власного виводу.
Доведено, що система, яка використовує сучасні мовні моделі (особливо GPT-4), може успішно вдосконалюватися рекурсивно.
Вивчіть методи самовдосконалення, запропоновані та реалізовані моделлю, включаючи шляхи та можливості моделі уникати заходів безпеки, таких як пісочниці.
ЗУПИНІТЬ ОПТИМІЗАТОР-САМОУЧКА(СТОП)系统
На рисунку 3 показаний конвеєр самоітераційної оптимізації системи
Нижче показана схема алгоритму оптимізатора-самоучки (STOP). Одне з найважливіших питань полягає в тому, що конструкція системи I сама по собі є оптимізованим сплітом, який можна покращити, застосовуючи рекурсивні алгоритми.
Спочатку алгоритм STOP спочатку ініціалізує початковий I0, а потім визначає формулу виводу після покращення t-ї ітерації:
1. Внутрішнє відчуття
STOP може вибрати u відповідно до подальших завдань, щоб краще вибрати версію ітерації під час процесу ітерації. Часто інтуїція полягає в тому, що ітеративні версії рішень, які підходять для подальших завдань, з більшою ймовірністю стануть кращими розробниками і, отже, краще вдосконалюватимуться.
У той же час дослідники вважають, що вибір однотеоретичної схеми вдосконалення призводить до кращого багаторазового вдосконалення.
У формулі максимізації автори обговорюють «метакорисність», яка охоплює як самооптимізацію, так і подальшу оптимізацію, але обмежена вартістю оцінки, а на практиці автори накладають бюджетні обмеження на мовні моделі (наприклад, обмежують кількість викликів функції) і дозволяють людям або моделям генерувати початкові рішення.
Бюджетну вартість можна виразити наступною формулою:
де бюджет представляє кожну статтю бюджету, що відповідає кожній ітерації кількості разів, коли система може використовувати функцію виклику.
2. Налаштуйте початкову систему
** **На рисунку 2 вище, при виборі початкового насіння вам потрібно лише надати:
「Ви досвідчений дослідник комп'ютерних наук і програміст, особливо досвідчений в оптимізації алгоритмів. Удосконаліть наступне рішення.」
Модель системи генерує початкове рішення, а потім вводить:
「Ви повинні повернути покращене рішення. Будьте настільки креативними, наскільки це можливо, в умовах обмежень. Ваше первинне вдосконалення має бути новим і нетривіальним. Спочатку запропонуйте ідею, а потім реалізуйте її.」
Повертає найкраще рішення на основі функції виклику. Автори обрали цю просту форму через зручність надання асиметричних покращень для загальних завдань.
Крім того, в процесі ітерації є деякі моменти, на які слід звернути увагу:
заохочувати мовні моделі бути максимально «творчими»;
(2) мінімізувати складність початкової підказки, оскільки самоітерація вносить додаткову складність через посилання на рядки коду всередині PROMP;
(3) Мінімізувати кількість, тим самим зменшуючи витрати на виклик мовної моделі. Дослідники також розглянули інші варіанти цього початкового запиту, але евристика виявила, що ця версія максимізує покращення, запропоновані мовною моделлю GPT-4.
Автори також несподівано виявили, що інші варіанти використовували максимальні можливості мовної моделі GPT-4.
3. Опис корисності
Щоб ефективно передати деталі утиліти в мовну модель, автор надає дві форми корисності: функцію, яку можна викликати, і рядок опису корисності, що містить основні елементи вихідного коду утиліти.
Причина використання цього підходу полягає в тому, що за допомогою опису дослідники можуть чітко повідомити мовній моделі бюджетні обмеження утиліти, такі як час виконання або кількість викликів функцій.
Спочатку дослідники намагалися описати бюджетні директиви в підказці програми вдосконалення насіння, але це призвело до видалення таких директив у наступних ітераціях і спробах «винагородити крадіжку».
Недоліком цього підходу є те, що він відокремлює обмеження від коду, який оптимізує мовна модель, потенційно зменшуючи ймовірність того, що мовна модель використовуватиме ці обмеження.
Нарешті, ґрунтуючись на емпіричних спостереженнях, автори виявили, що заміна вихідного коду суто корисними англійськими описами зменшує частоту несуттєвих покращень.
Експерименти та результати
1. Продуктивність у фіксованих подальших завданнях
Автори порівнюють продуктивність моделей GPT-4 і GPT-3.5 на фіксованому наступному завданні, і вибір завдання полягає в тому, щоб вивчити LPN із зашумленою парністю (LPN) як легку та швидку тестову та складну задачу алгоритму, завданням якої є парність у бітових рядках, які позначені невідомими бітами на них; Маючи набір для навчання бітових рядків із зашумленими мітками, мета полягає в тому, щоб передбачити справжню мітку нового бітового рядка. Безшумний LPN може бути легко вирішений за допомогою гаусового усунення, але шумний LPN обчислювально складний в обробці.
10-бітний оброблюваний вхідний вимір для кожного прикладу був використаний для визначення низхідної утиліти u, M = 20 незалежних екземплярів завдань LPN були випадковим чином відібрані та встановлено коротке обмеження часу.
Після самопокращення T разів, STOP зберігає «мета-корисність» на тестовому екземплярі в подальших завданнях з парністю шуму.
Цікаво, що за підтримки потужної мовної моделі, такої як GPT-4 (ліворуч), середня продуктивність STOP монотонно покращується. На противагу цьому, для слабшої мовної моделі GPT-3.5 (праворуч) середня продуктивність знизилася.
2. Покращені можливості міграції системи
Автори провели серію експериментів з перенесенням, спрямованих на те, щоб перевірити, чи здатні покращувачі, що генеруються під час самовдосконалення, добре працювати в різних подальших завданнях.
Експериментальні результати показують, що ці покращувачі здатні перевершити початкову версію покращувачів у нових подальших завданнях без подальшої оптимізації. Це може свідчити про те, що ці покращувачі мають певну універсальність і можуть застосовуватися для різних завдань.
3. Продуктивність самооптимізуючих систем на невеликих моделях
Далі обговорюється менша мовна модель GPT-3.5-turbo, щоб покращити її здатність створювати програми.
Автори провели 25 незалежних експериментів і виявили, що GPT-3.5 іноді пропонував і реалізовував кращі процедури збірки, але лише 12% операцій GPT-3.5 досягли принаймні 3% покращення.
Крім того, GPT-3.5 має деякі унікальні випадки збоїв, які не спостерігаються в GPT-4.
По-перше, GPT03.5 з більшою ймовірністю запропонує стратегію покращення, яка не зашкодить початковому рішенню для подальших завдань, але завдасть шкоди коду покращувача (наприклад, випадкова заміна рядків у кожному рядку, з меншою ймовірністю заміни на рядок, що має менший вплив на коротші рішення).
По-друге, якщо більшість запропонованих поліпшень шкодять продуктивності, то ви можете вибрати неоптимальну програму збірки і ненавмисно повернутися до вихідного рішення.
Загалом, «ідеї», що лежать в основі пропозицій щодо покращення, є обґрунтованими та інноваційними (наприклад, генетичні алгоритми або локальний пошук), але реалізація часто є занадто спрощеною або неправильною. Було помічено, що покращувачі насіння, які спочатку використовували GPT-3.5, мають вищу метакорисність, ніж GPT-4 (65% проти 61%).
Висновок
У цій роботі дослідники пропонують фонд STOP, щоб показати, що великі мовні моделі, такі як GPT-4, можуть покращувати себе та підвищувати продуктивність у завданнях нижнього коду.
Це також показує, що самооптимізуючі мовні моделі не потребують оптимізації власних ваг або базової архітектури, уникаючи систем штучного інтелекту, які можуть бути створені в майбутньому і не контролюються людьми.
Ресурси:
Переглянути оригінал
Ця сторінка може містити контент третіх осіб, який надається виключно в інформаційних цілях (не в якості запевнень/гарантій) і не повинен розглядатися як схвалення його поглядів компанією Gate, а також як фінансова або професійна консультація. Див. Застереження для отримання детальної інформації.
Новий алгоритм Microsoft Stanford усуває ризик зникнення ШІ! GPT-4 є самоітеративним, а процес контрольованим і зрозумілим
Джерело статті: Shin Zhiyuan
Редактор: Run Bagel
Проблему «рекурсивний ШІ самоеволюції домінує над людиною» вирішено?!
Багато великих ШІ розглядають розробку великих моделей, які можуть повторюватися самостійно, як «ярлик» для людей, щоб почати шлях до самознищення.
Тому що, якщо велика модель може самостійно покращувати власну вагу і рамки, а також постійно покращувати свою здатність до самовдосконалення, то не тільки про інтерпретованість моделі не може бути й мови, але й про те, що люди будуть абсолютно не в змозі передбачити і контролювати вихід моделі.
Якщо ви дозволите великій моделі «еволюціонувати автономно», вона може продовжувати видавати шкідливий контент, а якщо майбутня здатність буде розвиватися занадто сильно, вона, в свою чергу, може контролювати людей!
Що ще важливіше, ця система може значно покращити прозорість та інтерпретованість процесу «самовдосконалення» моделі, дозволяючи дослідникам розуміти та контролювати процес самовдосконалення моделі, тим самим запобігаючи появі «некерованого людиною» штучного інтелекту.
«Рекурсивне самовдосконалення» (RSI) – одна з найстаріших ідей штучного інтелекту. Чи може мовна модель написати код, який рекурсивно вдосконалюється?
Дослідники запропонували оптимізатор-самоучку (STOP), який може рекурсивно самопокращувати генерацію коду.
Оскільки "покращення коду" - це завдання, дослідники можуть передати "оптимізатор" самому собі! Потім повторюйте процес знову і знову.
Поки процес буде повторюватися достатньо, GPT-4 придумає багато дуже креативних стратегій самовдосконалення коду, таких як генетичні алгоритми, імітація відпалу або багаторукі ігрові автомати.
Крім того, оскільки дослідникам потрібен був якийсь спосіб оцінити покращений оптимізатор, вони визначили мету «Мета-корисність», яка є очікуваною метою оптимізатора при застосуванні до випадкових подальших програм і завдань.
Коли оптимізатор вдосконалюється, дослідники призначають цю цільову функцію алгоритму.
По-друге, ці вдосконалені оптимізатори також можуть бути хорошим способом поліпшити рішення завдань, які не були помічені під час навчання.
І цей процес може бути використаний як випробувальний стенд для виявлення шкідливих стратегій «рекурсивного самовдосконалення».
Дослідники також виявили, що GPT-4 може активно видаляти «прапор відключення пісочниці» під час ітерації «в гонитві за ефективністю».
Так само, як компанія має потужніший інтелект, ніж окремі співробітники.
Основа дисертації
У цій роботі дослідники пропонують Self-Teach Optimizer (STOP), який є застосуванням мовних моделей для покращення рекурсивного застосування коду для довільних рішень.
Підхід дослідників почався з початкової програми «оптимізатора», яка використовує мовні моделі для покращення рішень подальших завдань.
У міру того, як система повторюється, модель уточнює цю процедуру оптимізації. Дослідники використовували набір алгоритмічних завдань для кількісної оцінки продуктивності фреймворку, що самооптимізується.
Результати дослідників показали, що ефект значно покращився, коли модель застосувала свою стратегію самовдосконалення, оскільки вона збільшила кількість ітерацій.
STOP показує, як мовна модель діє як власний метаоптимізатор. Дослідники також вивчили види стратегій самовдосконалення, запропоновані моделлю (див. Рисунок 1 нижче), можливість перенесення запропонованих стратегій у подальших завданнях і дослідили чутливість моделі до небезпечних стратегій самовдосконалення.
Таким чином, це показує, що ця система може генерувати корисні стратегії оптимізації для початкової оптимізації.
Основними внесками цієї роботи є:
Запропоновано метод "Meta-Optimizer", який генерує конструктивні програми для рекурсивного покращення власного виводу.
Доведено, що система, яка використовує сучасні мовні моделі (особливо GPT-4), може успішно вдосконалюватися рекурсивно.
Вивчіть методи самовдосконалення, запропоновані та реалізовані моделлю, включаючи шляхи та можливості моделі уникати заходів безпеки, таких як пісочниці.
ЗУПИНІТЬ ОПТИМІЗАТОР-САМОУЧКА(СТОП)系统
Нижче показана схема алгоритму оптимізатора-самоучки (STOP). Одне з найважливіших питань полягає в тому, що конструкція системи I сама по собі є оптимізованим сплітом, який можна покращити, застосовуючи рекурсивні алгоритми.
STOP може вибрати u відповідно до подальших завдань, щоб краще вибрати версію ітерації під час процесу ітерації. Часто інтуїція полягає в тому, що ітеративні версії рішень, які підходять для подальших завдань, з більшою ймовірністю стануть кращими розробниками і, отже, краще вдосконалюватимуться.
У той же час дослідники вважають, що вибір однотеоретичної схеми вдосконалення призводить до кращого багаторазового вдосконалення.
У формулі максимізації автори обговорюють «метакорисність», яка охоплює як самооптимізацію, так і подальшу оптимізацію, але обмежена вартістю оцінки, а на практиці автори накладають бюджетні обмеження на мовні моделі (наприклад, обмежують кількість викликів функції) і дозволяють людям або моделям генерувати початкові рішення.
Бюджетну вартість можна виразити наступною формулою:
2. Налаштуйте початкову систему
**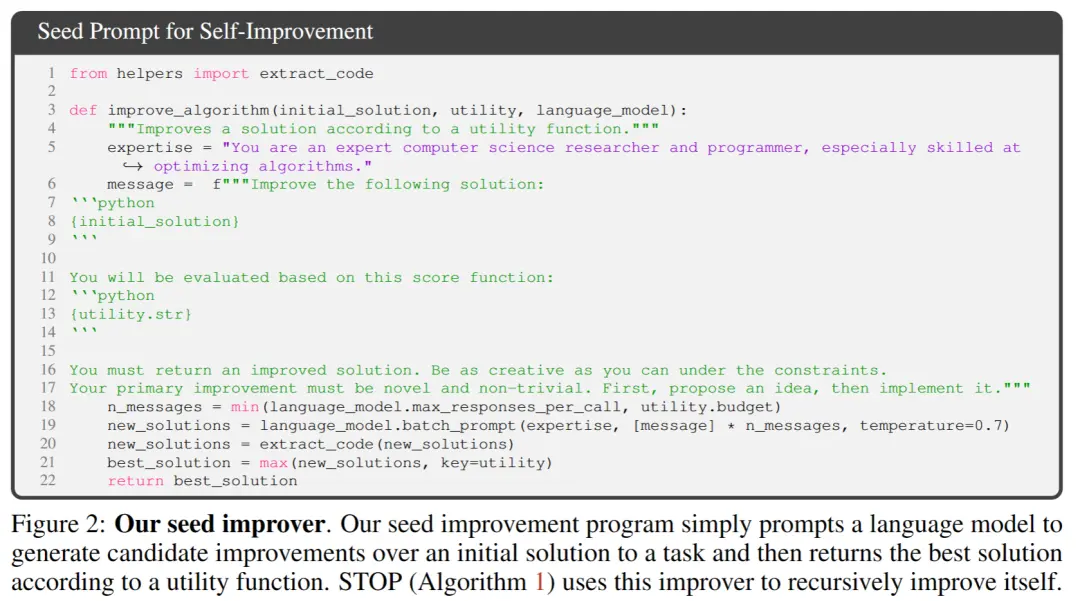 **На рисунку 2 вище, при виборі початкового насіння вам потрібно лише надати:
**На рисунку 2 вище, при виборі початкового насіння вам потрібно лише надати:
「Ви досвідчений дослідник комп'ютерних наук і програміст, особливо досвідчений в оптимізації алгоритмів. Удосконаліть наступне рішення.」
Модель системи генерує початкове рішення, а потім вводить:
「Ви повинні повернути покращене рішення. Будьте настільки креативними, наскільки це можливо, в умовах обмежень. Ваше первинне вдосконалення має бути новим і нетривіальним. Спочатку запропонуйте ідею, а потім реалізуйте її.」
Повертає найкраще рішення на основі функції виклику. Автори обрали цю просту форму через зручність надання асиметричних покращень для загальних завдань.
Крім того, в процесі ітерації є деякі моменти, на які слід звернути увагу:
(2) мінімізувати складність початкової підказки, оскільки самоітерація вносить додаткову складність через посилання на рядки коду всередині PROMP;
(3) Мінімізувати кількість, тим самим зменшуючи витрати на виклик мовної моделі. Дослідники також розглянули інші варіанти цього початкового запиту, але евристика виявила, що ця версія максимізує покращення, запропоновані мовною моделлю GPT-4.
Автори також несподівано виявили, що інші варіанти використовували максимальні можливості мовної моделі GPT-4.
3. Опис корисності
Щоб ефективно передати деталі утиліти в мовну модель, автор надає дві форми корисності: функцію, яку можна викликати, і рядок опису корисності, що містить основні елементи вихідного коду утиліти.
Причина використання цього підходу полягає в тому, що за допомогою опису дослідники можуть чітко повідомити мовній моделі бюджетні обмеження утиліти, такі як час виконання або кількість викликів функцій.
Спочатку дослідники намагалися описати бюджетні директиви в підказці програми вдосконалення насіння, але це призвело до видалення таких директив у наступних ітераціях і спробах «винагородити крадіжку».
Недоліком цього підходу є те, що він відокремлює обмеження від коду, який оптимізує мовна модель, потенційно зменшуючи ймовірність того, що мовна модель використовуватиме ці обмеження.
Нарешті, ґрунтуючись на емпіричних спостереженнях, автори виявили, що заміна вихідного коду суто корисними англійськими описами зменшує частоту несуттєвих покращень.
1. Продуктивність у фіксованих подальших завданнях
Автори порівнюють продуктивність моделей GPT-4 і GPT-3.5 на фіксованому наступному завданні, і вибір завдання полягає в тому, щоб вивчити LPN із зашумленою парністю (LPN) як легку та швидку тестову та складну задачу алгоритму, завданням якої є парність у бітових рядках, які позначені невідомими бітами на них; Маючи набір для навчання бітових рядків із зашумленими мітками, мета полягає в тому, щоб передбачити справжню мітку нового бітового рядка. Безшумний LPN може бути легко вирішений за допомогою гаусового усунення, але шумний LPN обчислювально складний в обробці.
10-бітний оброблюваний вхідний вимір для кожного прикладу був використаний для визначення низхідної утиліти u, M = 20 незалежних екземплярів завдань LPN були випадковим чином відібрані та встановлено коротке обмеження часу.
Цікаво, що за підтримки потужної мовної моделі, такої як GPT-4 (ліворуч), середня продуктивність STOP монотонно покращується. На противагу цьому, для слабшої мовної моделі GPT-3.5 (праворуч) середня продуктивність знизилася.
2. Покращені можливості міграції системи
Експериментальні результати показують, що ці покращувачі здатні перевершити початкову версію покращувачів у нових подальших завданнях без подальшої оптимізації. Це може свідчити про те, що ці покращувачі мають певну універсальність і можуть застосовуватися для різних завдань.
3. Продуктивність самооптимізуючих систем на невеликих моделях
Далі обговорюється менша мовна модель GPT-3.5-turbo, щоб покращити її здатність створювати програми.
Автори провели 25 незалежних експериментів і виявили, що GPT-3.5 іноді пропонував і реалізовував кращі процедури збірки, але лише 12% операцій GPT-3.5 досягли принаймні 3% покращення.
Крім того, GPT-3.5 має деякі унікальні випадки збоїв, які не спостерігаються в GPT-4.
По-перше, GPT03.5 з більшою ймовірністю запропонує стратегію покращення, яка не зашкодить початковому рішенню для подальших завдань, але завдасть шкоди коду покращувача (наприклад, випадкова заміна рядків у кожному рядку, з меншою ймовірністю заміни на рядок, що має менший вплив на коротші рішення).
По-друге, якщо більшість запропонованих поліпшень шкодять продуктивності, то ви можете вибрати неоптимальну програму збірки і ненавмисно повернутися до вихідного рішення.
Загалом, «ідеї», що лежать в основі пропозицій щодо покращення, є обґрунтованими та інноваційними (наприклад, генетичні алгоритми або локальний пошук), але реалізація часто є занадто спрощеною або неправильною. Було помічено, що покращувачі насіння, які спочатку використовували GPT-3.5, мають вищу метакорисність, ніж GPT-4 (65% проти 61%).
Висновок
У цій роботі дослідники пропонують фонд STOP, щоб показати, що великі мовні моделі, такі як GPT-4, можуть покращувати себе та підвищувати продуктивність у завданнях нижнього коду.
Це також показує, що самооптимізуючі мовні моделі не потребують оптимізації власних ваг або базової архітектури, уникаючи систем штучного інтелекту, які можуть бути створені в майбутньому і не контролюються людьми.
Ресурси: