Змусити великі моделі дивитися на діаграми, ніж друкувати! Нове дослідження NeurIPS 2023 пропонує метод мультимодальних запитів, точність покращилася на 7,8%
Здатність великих моделей «читати картинки» настільки сильна, чому ви продовжуєте шукати не ті речі?
Наприклад, плутати кажанів, які не схожі на них, з ракетками, або не розпізнавати рідкісних риб у деяких наборах даних...
Це пов'язано з тим, що коли ми дозволяємо великій моделі «щось знайти», ми часто вводимо текст.
Якщо опис неоднозначний або занадто упереджений, наприклад, "bat" (bat or beat?). Або «Cyprinodon diabolis», і ШІ заплутається.
Це призводить до використання великих моделей для виконання ** виявлення об'єктів **, особливо завдань з виявлення об'єктів у відкритому світі (невідома сцена), ефект часто не такий хороший, як очікувалося.
Тепер стаття, включена до NeurIPS 2023, нарешті вирішила цю проблему.
У цій статті запропоновано метод виявлення об'єктів MQ-Det на основі мультимодального запиту, якому потрібно лише додати приклад зображення до вхідних даних, що може значно підвищити точність пошуку об'єктів у великих моделях.
На еталонному наборі даних виявлення LVIS MQ-Det підвищує точність GLIP основних великих моделей виявлення в середньому приблизно на 7,8% і підвищує точність 13 контрольних завдань малої вибірки в середньому на 6,3%.
Як саме це робиться? Давайте подивимося.
Наступне відтворено від автора статті, блогера Zhihu @Qinyuanxia:
Зміст
MQ-Det: велика модель виявлення об'єктів у відкритому світі для мультимодальних запитів
1.1 Від текстового запиту до мультимодального запиту
1.2 Архітектура моделі мультимодальних запитів MQ-Det plug-and-play
1.3 Ефективна стратегія тренування MQ-Det
1.4 Експериментальні результати: оцінка без точних налаштувань
*1.5 Експериментальні результати: оцінка малої кількості кадрів
1.6 Мультимодальний запит перспективи виявлення об'єкта
MQ-det: Велика модель виявлення об'єктів у відкритому світі для мультимодальних запитів**
Мультимодальне виявлення запитуваних об'єктів у дикій природі
Посилання на папір:
Адреса коду:**
### 1.1 Від текстового запиту до мультимодального запиту
Одна картинка варта тисячі слів: З появою графічної попередньої підготовки, за допомогою відкритої семантики тексту, виявлення об'єктів поступово перейшло в стадію сприйняття відкритого світу. З цієї причини багато великих моделей виявлення дотримуються шаблону текстового запиту, тобто використання категорійних текстових описів для запиту потенційних цілей на цільових зображеннях. Однак такий підхід часто стикається з проблемою «широкого, але не рафінованого».
Наприклад, (1) виявлення дрібнозернистих об'єктів (пальців) на рисунку 1 часто важко описати різні дрібнозернисті види з обмеженим текстом, і (2) категорію неоднозначності («кажан» може стосуватися як кажана, так і ракетки).
Однак вищезазначені проблеми можуть бути вирішені за допомогою прикладів зображень, які дають більш багаті підказки про цільовий об'єкт, ніж текст, але в той же час текст має сильне узагальнення.
Тому те, як органічно поєднати два методи запиту, стало природною ідеєю.
Труднощі в отриманні можливостей мультимодальних запитів: Існує три проблеми в тому, як отримати таку модель за допомогою мультимодальних запитів: (1) Пряме тонке налаштування з обмеженими прикладами зображень може легко призвести до катастрофічного забування; (2) Навчання великої моделі виявлення з нуля матиме гарне узагальнення, але величезне споживання, наприклад, навчання з однією карткою GLIP вимагає 480 днів навчання з 30 мільйонами обсягів даних.
Виявлення об'єктів мультимодальних запитів: Виходячи з наведених вище міркувань, автор пропонує просту і ефективну стратегію проектування і навчання моделі - MQ-Det.
MQ-Det вставляє невелику кількість модулів закритого сприйняття (GCP) для отримання вхідних візуальних прикладів на основі існуючої великої моделі виявлення замороженого текстового запиту та розробляє стратегію навчання прогнозуванню мови маски візуальних умов для ефективного отримання детектора для високопродуктивних мультимодальних запитів.
1.2 Архітектура моделі мультимодальних запитів MQ-Det plug-and-play
** **######## △Рисунок 1 Діаграма архітектури методу MQ-Det
Модуль закритого сприйняття
Як показано на рисунку 1, автор шар за шаром вставляє модуль обізнаності про занурення (GCP) на стороні кодера тексту існуючої великої моделі виявлення замороженого текстового запиту, і режим роботи GCP можна лаконічно представити наступною формулою:
Для i-ї категорії наведемо наочний приклад Vi, який першим перехресним (X-MHA) з цільовим зображенням I
розширити свої репрезентативні можливості, а потім текст кожної категорії Ti і відповідний візуальний приклад категорії
Здійснюйте перехресну увагу
, після чого вихідний текст ti і візуальне доповнення тексту посилюються затвором літникового модуля
Fusion для отримання виводу поточного шару
。 Ця проста конструкція відповідає трьом принципам: (1) масштабованість категорій; 2) семантична повнота; (3) Антиамнезія, конкретне обговорення можна знайти в оригінальному тексті.
1.3 Ефективна стратегія навчання MQ-DET
Навчання модуляції на основі детектора заморожених мовних запитів
Оскільки поточна попередня модель виявлення великого текстового запиту сама по собі має хорошу узагальненість, автори вважають, що потрібно лише внести незначні корективи з візуальними деталями на основі вихідних рис тексту.
У статті також є конкретна експериментальна демонстрація того, що легко призвести до катастрофічного забуття після відкриття параметрів оригінальної попередньо навченої моделі та тонкого налаштування, але втрати здатності виявлення у відкритому світі.
Таким чином, MQ-Det може ефективно вставляти візуальну інформацію в детектор існуючого текстового запиту на основі попередньо навченого детектора замороженого текстового запиту і модулювати тільки модуль GCP, вставлений навчанням.
У статті автори застосовують методи структурного проектування та навчання MQ-Det до поточних моделей SOTA GLIP та GroundingDINO відповідно, щоб перевірити універсальність методу.
Стратегія тренування прогнозування мови маски з візуальним станом
Автори також пропонують візуально обумовлену маскувальну мовну прогностичну стратегію навчання для вирішення проблеми лінощів навчання, викликаної заморожуванням попередньо навчених моделей.
Так звана навчальна лінь означає, що детектор прагне зберігати характеристики вихідного текстового запиту в процесі навчання, тим самим ігноруючи знову додані функції візуального запиту.
З цією метою MQ-Det використовується випадковим чином під час тренувань[MASK] Токен замінює текстовий токен, змушуючи модель навчатися з боку функції візуального запиту, а саме:
Незважаючи на те, що ця стратегія проста, вона дуже ефективна, і, судячи з експериментальних результатів, ця стратегія принесла значне покращення продуктивності.
1.4 Експериментальні результати: оцінка без точних налаштувань
Без точного налаштування: MQ-Det пропонує більш практичну стратегію оцінювання: без точного налаштування, порівняно з традиційною оцінкою з нульовим пострілом, яка використовує лише текст категорії. Він визначається як виявлення об'єктів за допомогою тексту категорії, прикладів зображень або їх комбінації без будь-яких подальших тонких налаштувань.
У налаштуваннях без точних налаштувань MQ-Det вибирає 5 візуальних прикладів для кожної категорії та об'єднує текст категорії для виявлення об'єктів, тоді як інші існуючі моделі не підтримують візуальні запити та можуть використовувати лише звичайні текстові описи для виявлення об'єктів. У таблиці нижче наведено результати для LVIS MiniVal і LVIS v1.0. Можна виявити, що впровадження мультимодальних запитів значно покращило можливості виявлення об'єктів у відкритому світі.
** **###### △Таблиця 1 Продуктивність кожної моделі виявлення без точних налаштувань відповідно до еталонного набору даних LVIS
Як видно з таблиці 1, MQ-GLIP-L покращив AP більш ніж на 7% на основі GLIP-L, і ефект дуже значний!
1.5 Результати експерименту: оцінка кількох кадрів
** **###### △Таблиця 2 Продуктивність кожної моделі в ODinW-35 та 13 підмножинах ODinW-13 у 35 завданнях виявлення
Крім того, автори провели комплексні експерименти в ODinW-35, завдання детектування за течією 35. Як видно з таблиці 2, MQ-Det не тільки має високу продуктивність без тонкого налаштування, але й має хороші можливості виявлення малих вибірок, що ще більше підтверджує потенціал мультимодальних запитів. На рисунку 2 також показано значне покращення MQ-Det до GLIP.
** **##### △Рисунок 2 Порівняння ефективності використання даних; Горизонтальна вісь: кількість навчальних зразків, вертикальна вісь: середня точка доступу на OdinW-13
1.6 Перспективи виявлення об'єктів мультимодальних запитів
Як область досліджень, заснована на практичному застосуванні, виявлення об'єктів приділяє велику увагу посадці алгоритмів.
Незважаючи на те, що попередня модель виявлення об'єктів простого текстового запиту демонструє хороше узагальнення, важко охопити дрібнозернисту інформацію в реальному відкритому світі виявлення китайською мовою, і багата деталізація інформації на зображенні чудово доповнює це посилання.
Поки що ми можемо виявити, що текст є загальним, але не точним, а зображення точним, але не загальним, і якщо ми зможемо ефективно поєднати ці два варіанти, тобто мультимодальний запит, це сприятиме подальшому виявленню об'єктів у відкритому світі.
MQ-Det зробив перший крок у мультимодальних запитах, і його значне підвищення продуктивності також показує великий потенціал виявлення цілей мультимодальних запитів.
У той же час введення текстових описів і наочних прикладів надає користувачам більше вибору, роблячи виявлення об'єктів більш гнучким і зручним для користувача.
Оригінальне посилання:
Переглянути оригінал
Ця сторінка може містити контент третіх осіб, який надається виключно в інформаційних цілях (не в якості запевнень/гарантій) і не повинен розглядатися як схвалення його поглядів компанією Gate, а також як фінансова або професійна консультація. Див. Застереження для отримання детальної інформації.
Змусити великі моделі дивитися на діаграми, ніж друкувати! Нове дослідження NeurIPS 2023 пропонує метод мультимодальних запитів, точність покращилася на 7,8%
Першоджерело: Qubits
Здатність великих моделей «читати картинки» настільки сильна, чому ви продовжуєте шукати не ті речі?
Наприклад, плутати кажанів, які не схожі на них, з ракетками, або не розпізнавати рідкісних риб у деяких наборах даних...
Якщо опис неоднозначний або занадто упереджений, наприклад, "bat" (bat or beat?). Або «Cyprinodon diabolis», і ШІ заплутається.
Це призводить до використання великих моделей для виконання ** виявлення об'єктів **, особливо завдань з виявлення об'єктів у відкритому світі (невідома сцена), ефект часто не такий хороший, як очікувалося.
Тепер стаття, включена до NeurIPS 2023, нарешті вирішила цю проблему.
На еталонному наборі даних виявлення LVIS MQ-Det підвищує точність GLIP основних великих моделей виявлення в середньому приблизно на 7,8% і підвищує точність 13 контрольних завдань малої вибірки в середньому на 6,3%.
Як саме це робиться? Давайте подивимося.
Наступне відтворено від автора статті, блогера Zhihu @Qinyuanxia:
Зміст
MQ-det: Велика модель виявлення об'єктів у відкритому світі для мультимодальних запитів**
Мультимодальне виявлення запитуваних об'єктів у дикій природі
Посилання на папір:
Адреса коду:**
Одна картинка варта тисячі слів: З появою графічної попередньої підготовки, за допомогою відкритої семантики тексту, виявлення об'єктів поступово перейшло в стадію сприйняття відкритого світу. З цієї причини багато великих моделей виявлення дотримуються шаблону текстового запиту, тобто використання категорійних текстових описів для запиту потенційних цілей на цільових зображеннях. Однак такий підхід часто стикається з проблемою «широкого, але не рафінованого».
Наприклад, (1) виявлення дрібнозернистих об'єктів (пальців) на рисунку 1 часто важко описати різні дрібнозернисті види з обмеженим текстом, і (2) категорію неоднозначності («кажан» може стосуватися як кажана, так і ракетки).
Однак вищезазначені проблеми можуть бути вирішені за допомогою прикладів зображень, які дають більш багаті підказки про цільовий об'єкт, ніж текст, але в той же час текст має сильне узагальнення.
Тому те, як органічно поєднати два методи запиту, стало природною ідеєю.
Труднощі в отриманні можливостей мультимодальних запитів: Існує три проблеми в тому, як отримати таку модель за допомогою мультимодальних запитів: (1) Пряме тонке налаштування з обмеженими прикладами зображень може легко призвести до катастрофічного забування; (2) Навчання великої моделі виявлення з нуля матиме гарне узагальнення, але величезне споживання, наприклад, навчання з однією карткою GLIP вимагає 480 днів навчання з 30 мільйонами обсягів даних.
Виявлення об'єктів мультимодальних запитів: Виходячи з наведених вище міркувань, автор пропонує просту і ефективну стратегію проектування і навчання моделі - MQ-Det.
MQ-Det вставляє невелику кількість модулів закритого сприйняття (GCP) для отримання вхідних візуальних прикладів на основі існуючої великої моделі виявлення замороженого текстового запиту та розробляє стратегію навчання прогнозуванню мови маски візуальних умов для ефективного отримання детектора для високопродуктивних мультимодальних запитів.
1.2 Архітектура моделі мультимодальних запитів MQ-Det plug-and-play
** **######## △Рисунок 1 Діаграма архітектури методу MQ-Det
**######## △Рисунок 1 Діаграма архітектури методу MQ-Det
Модуль закритого сприйняття
Як показано на рисунку 1, автор шар за шаром вставляє модуль обізнаності про занурення (GCP) на стороні кодера тексту існуючої великої моделі виявлення замороженого текстового запиту, і режим роботи GCP можна лаконічно представити наступною формулою:
1.3 Ефективна стратегія навчання MQ-DET
Навчання модуляції на основі детектора заморожених мовних запитів
Оскільки поточна попередня модель виявлення великого текстового запиту сама по собі має хорошу узагальненість, автори вважають, що потрібно лише внести незначні корективи з візуальними деталями на основі вихідних рис тексту.
У статті також є конкретна експериментальна демонстрація того, що легко призвести до катастрофічного забуття після відкриття параметрів оригінальної попередньо навченої моделі та тонкого налаштування, але втрати здатності виявлення у відкритому світі.
Таким чином, MQ-Det може ефективно вставляти візуальну інформацію в детектор існуючого текстового запиту на основі попередньо навченого детектора замороженого текстового запиту і модулювати тільки модуль GCP, вставлений навчанням.
У статті автори застосовують методи структурного проектування та навчання MQ-Det до поточних моделей SOTA GLIP та GroundingDINO відповідно, щоб перевірити універсальність методу.
Стратегія тренування прогнозування мови маски з візуальним станом
Автори також пропонують візуально обумовлену маскувальну мовну прогностичну стратегію навчання для вирішення проблеми лінощів навчання, викликаної заморожуванням попередньо навчених моделей.
Так звана навчальна лінь означає, що детектор прагне зберігати характеристики вихідного текстового запиту в процесі навчання, тим самим ігноруючи знову додані функції візуального запиту.
З цією метою MQ-Det використовується випадковим чином під час тренувань[MASK] Токен замінює текстовий токен, змушуючи модель навчатися з боку функції візуального запиту, а саме:
1.4 Експериментальні результати: оцінка без точних налаштувань
Без точного налаштування: MQ-Det пропонує більш практичну стратегію оцінювання: без точного налаштування, порівняно з традиційною оцінкою з нульовим пострілом, яка використовує лише текст категорії. Він визначається як виявлення об'єктів за допомогою тексту категорії, прикладів зображень або їх комбінації без будь-яких подальших тонких налаштувань.
У налаштуваннях без точних налаштувань MQ-Det вибирає 5 візуальних прикладів для кожної категорії та об'єднує текст категорії для виявлення об'єктів, тоді як інші існуючі моделі не підтримують візуальні запити та можуть використовувати лише звичайні текстові описи для виявлення об'єктів. У таблиці нижче наведено результати для LVIS MiniVal і LVIS v1.0. Можна виявити, що впровадження мультимодальних запитів значно покращило можливості виявлення об'єктів у відкритому світі.
**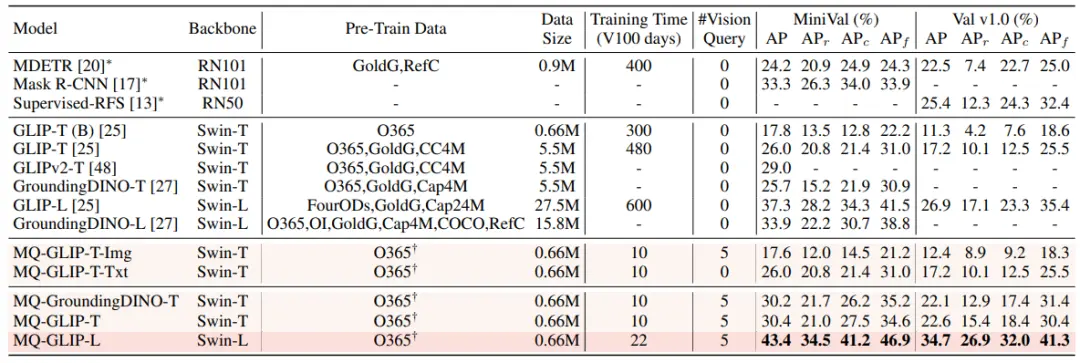 **###### △Таблиця 1 Продуктивність кожної моделі виявлення без точних налаштувань відповідно до еталонного набору даних LVIS
**###### △Таблиця 1 Продуктивність кожної моделі виявлення без точних налаштувань відповідно до еталонного набору даних LVIS
Як видно з таблиці 1, MQ-GLIP-L покращив AP більш ніж на 7% на основі GLIP-L, і ефект дуже значний!
1.5 Результати експерименту: оцінка кількох кадрів
**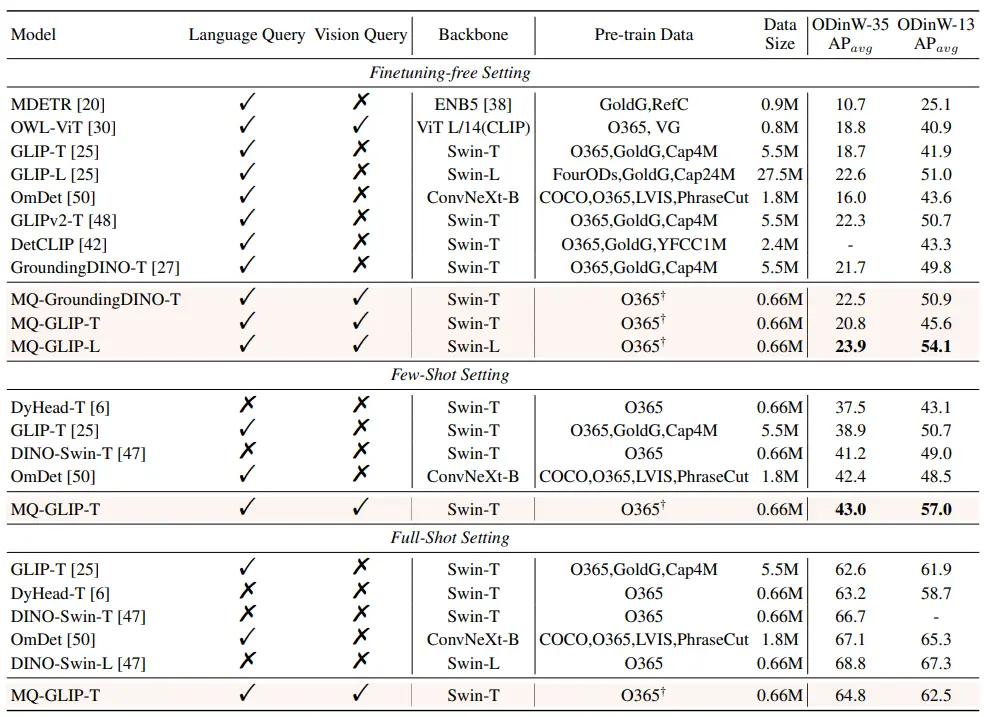 **###### △Таблиця 2 Продуктивність кожної моделі в ODinW-35 та 13 підмножинах ODinW-13 у 35 завданнях виявлення
**###### △Таблиця 2 Продуктивність кожної моделі в ODinW-35 та 13 підмножинах ODinW-13 у 35 завданнях виявлення
Крім того, автори провели комплексні експерименти в ODinW-35, завдання детектування за течією 35. Як видно з таблиці 2, MQ-Det не тільки має високу продуктивність без тонкого налаштування, але й має хороші можливості виявлення малих вибірок, що ще більше підтверджує потенціал мультимодальних запитів. На рисунку 2 також показано значне покращення MQ-Det до GLIP.
**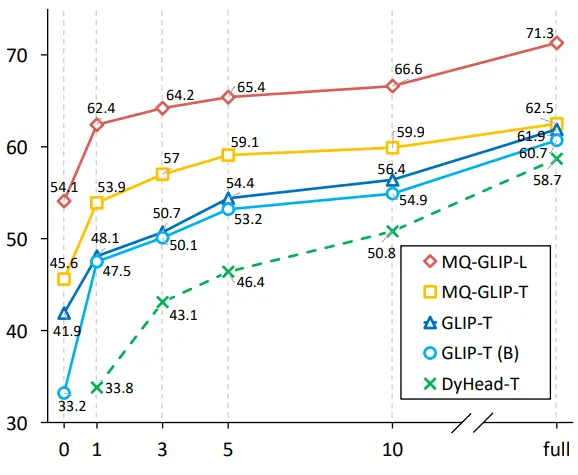 **##### △Рисунок 2 Порівняння ефективності використання даних; Горизонтальна вісь: кількість навчальних зразків, вертикальна вісь: середня точка доступу на OdinW-13
**##### △Рисунок 2 Порівняння ефективності використання даних; Горизонтальна вісь: кількість навчальних зразків, вертикальна вісь: середня точка доступу на OdinW-13
1.6 Перспективи виявлення об'єктів мультимодальних запитів
Як область досліджень, заснована на практичному застосуванні, виявлення об'єктів приділяє велику увагу посадці алгоритмів.
Незважаючи на те, що попередня модель виявлення об'єктів простого текстового запиту демонструє хороше узагальнення, важко охопити дрібнозернисту інформацію в реальному відкритому світі виявлення китайською мовою, і багата деталізація інформації на зображенні чудово доповнює це посилання.
Поки що ми можемо виявити, що текст є загальним, але не точним, а зображення точним, але не загальним, і якщо ми зможемо ефективно поєднати ці два варіанти, тобто мультимодальний запит, це сприятиме подальшому виявленню об'єктів у відкритому світі.
MQ-Det зробив перший крок у мультимодальних запитах, і його значне підвищення продуктивності також показує великий потенціал виявлення цілей мультимодальних запитів.
У той же час введення текстових описів і наочних прикладів надає користувачам більше вибору, роблячи виявлення об'єктів більш гнучким і зручним для користувача.
Оригінальне посилання: