Найкраща модель 7B знову переходить з рук в руки! Переможіть 70 мільярдів LLaMA2, і комп'ютери Apple зможуть працювати|з відкритим вихідним кодом і безкоштовно
Модель з 7 мільярдами параметрів, на «тюнінг» якої пішло 500 доларів, перемогла 70-мільярдний параметр Llama 2!
І ноутбук може легко запуститися, а ефект можна порівняти з ChatGPT.
Важливо: Безкоштовно, без грошей.
Модель з відкритим вихідним кодом Zephyr-7B, створена командою HuggingFace H4, божевільна акула.
Його базовою моделлю є велика модель з відкритим вихідним кодом Mistral-7B, яка вибухнула деякий час тому і була побудована Mistral AI, яка відома як «European OpenAI».
Знаєте, менш ніж через 2 тижні після виходу «Містраля-7Б» одна за одною з'явилися різні тонко налаштовані версії, і дуже багато стилю «альпака», який швидко з'явився, коли вперше вийшла «Лама».
Ключ до здатності Zephyr виділятися серед варіантів полягав у тому, що команда доопрацювала модель на загальнодоступному наборі даних за допомогою Direct Preference Optimization (DPO) поверх Mistral.
Команда також виявила, що видалення вбудованого вирівнювання набору даних може ще більше покращити продуктивність MT Bench. Оригінальний Zephyr-7B-alpha мав середній бал MT-Bench 7,09, перевершивши Llama2-70B-Chat.
** **###### △MT-Bench — це еталонний тест для оцінки здатності моделі обробляти кілька раундів діалогу, а набір запитань охоплює 8 категорій, таких як письмо, рольові ігри та вилучення.
Справа в тому, що потім він перейшов до оновлення!
Команда H4 випустила друге покоління Zephyr-7B-beta. Вони додали, що досліджували ідею вилучення вирівнювання з GPT-4, Claude 2, а потім введення його в невеликі моделі, розробивши метод використання оптимізації прямих переваг дистиляції (dDPO) для невеликих моделей.
У другому поколінні Zephyr середня оцінка MT-Bench зросла до 7,34.
На Alpaca вінрейт Zephyr становить 90,6%, що краще, ніж у ChatGPT (3,5):
Користувачі мережі, які кинулися до Зефіру, одностайно похвалили, а команда lmsys також показала оцінку Ело Zephyr-7b-beta, яка злетіла дуже високо 🔥:
Внутрішня таблиця лідерів Arena перевершила 13B моделей.
Дехто навіть казав:
Побачити, як підхід DPO добре працює в цій галузі, є, мабуть, найцікавішим у розробці великих мовних моделей цього року.
Все більше користувачів мережі почали тестувати дію Zephyr, і результати виявилися напрочуд хорошими.
Слово Mistral у перекладі з французької означає сухий, холодний і сильний вітер, а Zephyr означає м'який, приємний західний вітер.
Немає сумнівів, що по той бік лами є зоопарк, і немає сумнівів, що з цього боку є метеорологічне бюро.
Найкраща модель 7B знову переходить з рук в руки
Почнемо з вимог до комп'ютера для запуску Zephyr. Користувачі мережі сказали: "Тайські штани гострі" після тесту! , ноутбука (Apple M1 Pro) досить, "результат дуже хороший".
З точки зору ефективності, команда Llama Index (раніше відома як GPT Index) також протестувала його.
Виявляється, Zephyr на даний момент є єдиною моделлю 7B з відкритим вихідним кодом, яка добре справляється з високорівневими RAG/агентними завданнями.
Дані також показують, що ефект від просунутого завдання Zephyr RAG може конкурувати з GPT-3.5 і Claude 2.
Далі вони додали, що Zephyr добре працює не тільки на RAG, але й у маршрутизації, плануванні запитів, отриманні складних SQL-виразів та вилученні структурованих даних.
Офіційні особи також надали результати тестів, і на MT-Bench Zephyr-7B-beta має високу продуктивність у порівнянні з більшими моделями, такими як Llama2-Chat-70B.
Але в більш складних завданнях, таких як кодування і математика, Zephyr-7B-бета відстає від пропрієтарних моделей і вимагає додаткових досліджень, щоб закрити прогалину.
Відмовтеся від навчання з підкріпленням
Поки всі тестують ефекти Zephyr, розробники кажуть, що найцікавіше не метрики, а те, як навчається модель.
Основні моменти коротко викладені нижче:
Точне налаштування найкращої маленької попередньо підготовленої моделі з відкритим вихідним кодом: Mistral 7B
Використання великомасштабних наборів даних преференцій: UltraFeedback
Використовуйте пряму оптимізацію переваг (DPO) замість навчання з підкріпленням
Несподівано, що перенавчання набору даних преференцій дає кращі результати
У широкому сенсі, як згадувалося на початку, основна причина, по якій Zephyr здатний перевершити 70B Llama 2, пов'язана з використанням спеціального методу тонкого налаштування.
На відміну від традиційного підходу до навчання з підкріпленням PPO, дослідницька група використала нещодавню співпрацю між Стенфордським університетом і CZ Biohub, щоб запропонувати підхід DPO.
За словами дослідників:
DPO набагато стабільніше, ніж PPO.
Простими словами DPO можна пояснити наступним чином:
Для того, щоб зробити вихідні дані моделі більш відповідними людським уподобанням, традиційний підхід полягав у точному налаштуванні цільової моделі за допомогою моделі винагороди. Якщо результат хороший, ви будете винагороджені, а якщо поганий, ви не будете винагороджені.
Підхід DPO, з іншого боку, обходить функцію винагороди за моделювання і еквівалентний оптимізації моделі безпосередньо на даних переваги.
В цілому, DPO вирішує проблему складного і дорогого навчання з підкріпленням за рахунок зворотного зв'язку з людьми.
Що стосується конкретно навчання Zephyr, дослідницька група спочатку доопрацювала Zephyr-7B-альфа на спрощеному варіанті набору даних UltraChat, який містить 1,6 мільйона розмов, згенерованих ChatGPT (залишилося близько 200 000).
(Причина оптимізації полягала в тому, що команда виявила, що Zephyr іноді був неправильно описаний, наприклад, «Привіт. Як справи?"; Іноді відповідь починається зі слів «У мене немає особистого Х». )
Пізніше вони узгодили модель із загальнодоступним набором даних openbmb/UltraFeedback за допомогою методу DPO Trainer від TRL.
Набір даних містить 64 000 пар підказок-відповідей з різних моделей. Кожна відповідь оцінюється GPT-4 на основі таких критеріїв, як корисність, і отримує оцінку, з якої виводиться перевага ШІ.
Цікавим висновком є те, що при використанні методу DPO ефект насправді кращий після перенавчання, оскільки час тренування збільшується. Дослідники вважають, що це схоже на перенавчання в SFT.
Варто згадати, що дослідницька група також представила, що тонке налаштування моделі за допомогою цього методу коштує всього 500 доларів, що становить 8 годин роботи на 16 A100.
При оновленні Zephyr до бета-версії команда продовжила пояснювати свій підхід.
Вони думали про точне налаштування під наглядом дистиляції (dSFT), яке використовується у великих моделях, але при такому підході модель була зміщена і не давала результатів, які відповідали намірам користувача.
Тому команда спробувала використати дані про переваги від AI Feedback (AIF), щоб ранжувати результати за допомогою «моделі вчителя» для формування набору даних, а потім застосувати оптимізацію прямих переваг дистиляції (dDPO) для навчання моделі, яка відповідала намірам користувача без будь-якої додаткової вибірки під час точного налаштування.
Дослідники також перевірили ефект, коли SFT не використовувався, і результати призвели до значного зниження продуктивності, вказуючи на те, що крок dSFT є критичним.
В даний час, на додаток до того, що модель була з відкритим вихідним кодом і комерційною, є також демо-версія, яку можна спробувати, так що ми можемо почати і випробувати її просто.
Демонстраційний досвід
Перш за все, мені довелося вийти з питання «розумово відсталий», щоб скласти тест.
На питання «Мама і тато не беруть мене, коли одружуються» загальна відповідь Зефіра більш точна.
ChatGPT не може перемогти це питання.
У тесті ми також виявили, що Zephyr також знає про нещодавні події, такі як випуск OpenAI GPT-4:
Насправді це пов'язано з його базовою моделлю, хоча чиновник Mistral не уточнив кінцевий термін для даних навчання.
Але деякі користувачі мережі тестували його раніше, і він також знає про це в березні цього року.
На противагу цьому, передтренувальні дані Llama 2 станом на вересень 2022 року, і лише деякі точні дані стосуються червня 2023 року.
Крім того, Zephyr дуже чуйний, тому ви можете писати код і вигадувати історії. :
Варто згадати, що Зефір краще відповідає на запитання англійською мовою, а також має загальну проблему з моделлю «галюцинації».
Дослідники також згадали про галюцинації, а під полем введення був позначений невеликий рядок тексту, який вказує на те, що контент, згенерований моделлю, може бути неточним або неправильним.
Справа в тому, що Zephyr не використовує такі методи, як навчання з підкріпленням за допомогою людського зворотного зв'язку, щоб узгодити їх з уподобаннями людини, а також не використовує фільтрацію відповідей ChatGPT.
Завжди вибирайте одну з еммм риб і ведмежих лап.
Zephyr зміг зробити це лише з параметрами 70В, що здивувало Андрія Буркова, автора «100-сторінкової книги з машинного навчання», і навіть сказав:
Zephyr-7B перемагає Llama 2-70B базовою моделлю Mistral-7B з контекстним вікном у 8k токенів, яка теоретично має діапазон уваги до 128 тисяч токенів.
Що, якби Zephyr був моделлю 70B? Чи перевершить він GPT-4? Схоже, що це так.
Якщо вас зацікавив Zephyr-7B, ви можете випробувати його на обіймах.
Паперові посилання:
Посилання на джерела:
[1]
[2]
[3]
[4]
[5]
Переглянути оригінал
Ця сторінка може містити контент третіх осіб, який надається виключно в інформаційних цілях (не в якості запевнень/гарантій) і не повинен розглядатися як схвалення його поглядів компанією Gate, а також як фінансова або професійна консультація. Див. Застереження для отримання детальної інформації.
Найкраща модель 7B знову переходить з рук в руки! Переможіть 70 мільярдів LLaMA2, і комп'ютери Apple зможуть працювати|з відкритим вихідним кодом і безкоштовно
Першоджерело: кубіти
Модель з 7 мільярдами параметрів, на «тюнінг» якої пішло 500 доларів, перемогла 70-мільярдний параметр Llama 2!
І ноутбук може легко запуститися, а ефект можна порівняти з ChatGPT.
Важливо: Безкоштовно, без грошей.
Модель з відкритим вихідним кодом Zephyr-7B, створена командою HuggingFace H4, божевільна акула.
Ключ до здатності Zephyr виділятися серед варіантів полягав у тому, що команда доопрацювала модель на загальнодоступному наборі даних за допомогою Direct Preference Optimization (DPO) поверх Mistral.
Команда також виявила, що видалення вбудованого вирівнювання набору даних може ще більше покращити продуктивність MT Bench. Оригінальний Zephyr-7B-alpha мав середній бал MT-Bench 7,09, перевершивши Llama2-70B-Chat.
**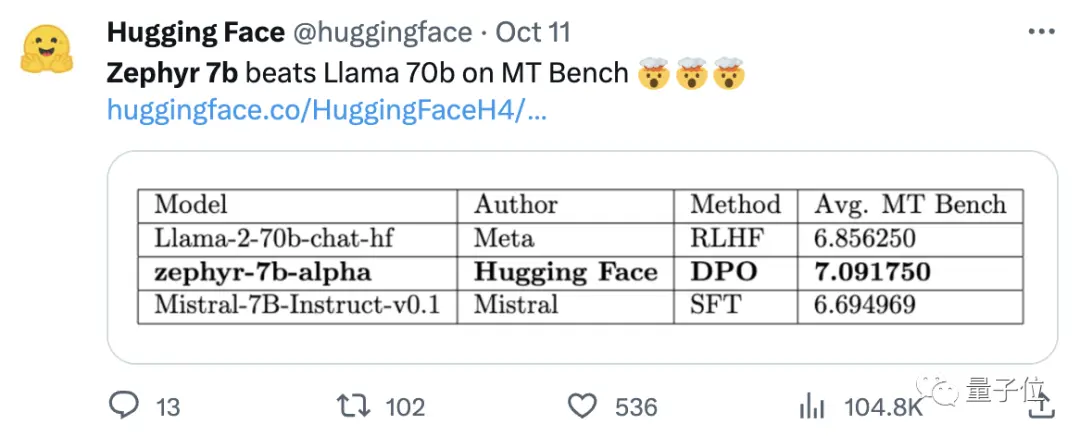 **###### △MT-Bench — це еталонний тест для оцінки здатності моделі обробляти кілька раундів діалогу, а набір запитань охоплює 8 категорій, таких як письмо, рольові ігри та вилучення.
**###### △MT-Bench — це еталонний тест для оцінки здатності моделі обробляти кілька раундів діалогу, а набір запитань охоплює 8 категорій, таких як письмо, рольові ігри та вилучення.
Справа в тому, що потім він перейшов до оновлення!
Команда H4 випустила друге покоління Zephyr-7B-beta. Вони додали, що досліджували ідею вилучення вирівнювання з GPT-4, Claude 2, а потім введення його в невеликі моделі, розробивши метод використання оптимізації прямих переваг дистиляції (dDPO) для невеликих моделей.
У другому поколінні Zephyr середня оцінка MT-Bench зросла до 7,34.
Слово Mistral у перекладі з французької означає сухий, холодний і сильний вітер, а Zephyr означає м'який, приємний західний вітер.
Немає сумнівів, що по той бік лами є зоопарк, і немає сумнівів, що з цього боку є метеорологічне бюро.
Найкраща модель 7B знову переходить з рук в руки
Почнемо з вимог до комп'ютера для запуску Zephyr. Користувачі мережі сказали: "Тайські штани гострі" після тесту! , ноутбука (Apple M1 Pro) досить, "результат дуже хороший".
Дані також показують, що ефект від просунутого завдання Zephyr RAG може конкурувати з GPT-3.5 і Claude 2.
Далі вони додали, що Zephyr добре працює не тільки на RAG, але й у маршрутизації, плануванні запитів, отриманні складних SQL-виразів та вилученні структурованих даних.
Відмовтеся від навчання з підкріпленням
Поки всі тестують ефекти Zephyr, розробники кажуть, що найцікавіше не метрики, а те, як навчається модель.
Основні моменти коротко викладені нижче:
У широкому сенсі, як згадувалося на початку, основна причина, по якій Zephyr здатний перевершити 70B Llama 2, пов'язана з використанням спеціального методу тонкого налаштування.
На відміну від традиційного підходу до навчання з підкріпленням PPO, дослідницька група використала нещодавню співпрацю між Стенфордським університетом і CZ Biohub, щоб запропонувати підхід DPO.
Простими словами DPO можна пояснити наступним чином:
Для того, щоб зробити вихідні дані моделі більш відповідними людським уподобанням, традиційний підхід полягав у точному налаштуванні цільової моделі за допомогою моделі винагороди. Якщо результат хороший, ви будете винагороджені, а якщо поганий, ви не будете винагороджені.
Підхід DPO, з іншого боку, обходить функцію винагороди за моделювання і еквівалентний оптимізації моделі безпосередньо на даних переваги.
В цілому, DPO вирішує проблему складного і дорогого навчання з підкріпленням за рахунок зворотного зв'язку з людьми.
Що стосується конкретно навчання Zephyr, дослідницька група спочатку доопрацювала Zephyr-7B-альфа на спрощеному варіанті набору даних UltraChat, який містить 1,6 мільйона розмов, згенерованих ChatGPT (залишилося близько 200 000).
(Причина оптимізації полягала в тому, що команда виявила, що Zephyr іноді був неправильно описаний, наприклад, «Привіт. Як справи?"; Іноді відповідь починається зі слів «У мене немає особистого Х». )
Пізніше вони узгодили модель із загальнодоступним набором даних openbmb/UltraFeedback за допомогою методу DPO Trainer від TRL.
Набір даних містить 64 000 пар підказок-відповідей з різних моделей. Кожна відповідь оцінюється GPT-4 на основі таких критеріїв, як корисність, і отримує оцінку, з якої виводиться перевага ШІ.
Цікавим висновком є те, що при використанні методу DPO ефект насправді кращий після перенавчання, оскільки час тренування збільшується. Дослідники вважають, що це схоже на перенавчання в SFT.
Вони думали про точне налаштування під наглядом дистиляції (dSFT), яке використовується у великих моделях, але при такому підході модель була зміщена і не давала результатів, які відповідали намірам користувача.
Дослідники також перевірили ефект, коли SFT не використовувався, і результати призвели до значного зниження продуктивності, вказуючи на те, що крок dSFT є критичним.
Демонстраційний досвід
Перш за все, мені довелося вийти з питання «розумово відсталий», щоб скласти тест.
На питання «Мама і тато не беруть мене, коли одружуються» загальна відповідь Зефіра більш точна.
Але деякі користувачі мережі тестували його раніше, і він також знає про це в березні цього року.
Крім того, Zephyr дуже чуйний, тому ви можете писати код і вигадувати історії. :
Дослідники також згадали про галюцинації, а під полем введення був позначений невеликий рядок тексту, який вказує на те, що контент, згенерований моделлю, може бути неточним або неправильним.
Завжди вибирайте одну з еммм риб і ведмежих лап.
Zephyr зміг зробити це лише з параметрами 70В, що здивувало Андрія Буркова, автора «100-сторінкової книги з машинного навчання», і навіть сказав:
Паперові посилання:
Посилання на джерела:
[1]
[2]
[3]
[4]
[5]