Bài báo Mô hình ngôn ngữ lớn đầu tiên do người đoạt giải Turing Yao Qizhi dẫn đầu đã có mặt!
Ngay khi bắt đầu, tôi đã nhắm tới hướng “làm cho những mô hình lớn suy nghĩ như con người”——
Các mô hình lớn không chỉ cần suy luận từng bước mà còn cần học cách “từng bước” và ghi nhớ tất cả các quy trình chính xác trong quá trình suy luận.
Cụ thể, bài báo mới này đề xuất một phương pháp mới gọi là Lý luận tích lũy, giúp cải thiện đáng kể khả năng của các mô hình lớn trong việc tham gia vào lý luận phức tạp.
Bạn nên biết rằng các mô hình lớn dựa trên chuỗi tư duy, v.v., và có thể được sử dụng để suy luận vấn đề, nhưng khi gặp những vấn đề đòi hỏi “nhiều lượt” vẫn dễ mắc sai lầm.
Trên cơ sở này, lý luận tích lũy bổ sung thêm một "người xác minh" để đánh giá đúng sai trong thời gian thực. Khung tư duy của mô hình này cũng đã thay đổi từ chuỗi và cây sang một "đồ thị chu kỳ có hướng" phức tạp hơn.
Bằng cách này, mô hình lớn không chỉ có ý tưởng giải quyết vấn đề rõ ràng hơn mà còn phát triển kỹ năng “chơi bài”:
Đối với các bài toán như đại số và lý thuyết số hình học, độ chính xác tương đối của các mô hình lớn tăng 42%; khi chơi 24 điểm, tỷ lệ thành công tăng vọt lên 98%.
Theo Viện Thông tin chéo tại Đại học Thanh Hoa, đồng tác giả đầu tiên Zhang Yifan đã giải thích điểm khởi đầu của bài viết này:
Kahneman tin rằng quá trình xử lý nhận thức của con người bao gồm hai hệ thống: "Hệ thống 1" nhanh, theo bản năng và cảm xúc, còn "Hệ thống 2" chậm rãi, chu đáo và logic.
Hiện tại, hiệu suất của các mô hình ngôn ngữ lớn gần với "Hệ thống 1", đây có thể là lý do khiến nó xử lý các tác vụ phức tạp không tốt.
Lý luận tích lũy được thiết kế theo quan điểm này tốt hơn Chuỗi suy nghĩ (CoT) và Cây tư duy (ToT).
Vì vậy, cách tiếp cận mới này thực sự trông như thế nào? Chúng ta hãy cùng nhau xem xét.
Đột phá chuỗi tư duy & cây “tắc nghẽn”
Cốt lõi của lý luận tích lũy nằm ở việc cải thiện “hình dáng” quá trình tư duy của các mô hình lớn.
Cụ thể, phương pháp này sử dụng 3 mô hình ngôn ngữ lớn:
Người đề xuất: Không ngừng đề xuất những mệnh đề mới, tức là đề xuất bước tiếp theo cần làm gì dựa trên bối cảnh tư duy hiện tại.
Người xác minh: Xác minh tính chính xác của đề xuất của người đề xuất và thêm nó vào bối cảnh suy nghĩ nếu nó đúng.
Phóng viên: Xác định xem đã đạt được giải pháp cuối cùng hay chưa và có kết thúc quá trình suy luận hay không.
Trong quá trình suy luận, trước tiên “người đề xuất” đưa ra đề xuất, “người xác minh” chịu trách nhiệm đánh giá và “người báo cáo” quyết định có hoàn thiện câu trả lời và chấm dứt quá trình suy nghĩ hay không.
** ****△**Ví dụ lý luận CR
Nó hơi giống ba loại vai trò trong một dự án nhóm: các thành viên trong nhóm đưa ra các ý tưởng khác nhau trước tiên, người hướng dẫn "kiểm tra" xem ý tưởng nào khả thi và trưởng nhóm quyết định thời điểm hoàn thành dự án.
**Vậy chính xác thì cách tiếp cận này thay đổi “hình dạng” của tư duy mô hình lớn như thế nào? **
Để hiểu được điều này, chúng ta phải bắt đầu từ “Chain of Thought, CoT” (Chain of Thought, CoT), “người khởi xướng” các phương pháp nâng cao tư duy mô hình lớn.
Phương pháp này được nhà khoa học OpenAI Jason Wei và những người khác đề xuất vào tháng 1 năm 2022. Cốt lõi là thêm văn bản "lý luận từng bước" vào đầu vào trong tập dữ liệu để kích thích khả năng tư duy của mô hình lớn.
** ****△**Được chọn từ bộ dữ liệu GSM8K
Dựa trên nguyên tắc chuỗi tư duy, Google cũng nhanh chóng cho ra đời "phiên bản chuỗi tư duy PLUS", cụ thể là CoT-SC, chủ yếu tiến hành nhiều quy trình chuỗi tư duy và tiến hành bỏ phiếu đa số cho các câu trả lời để chọn ra câu trả lời hay nhất ... Câu trả lời đúng nhất có thể nâng cao hơn nữa độ chính xác của lý luận.
Nhưng cả Chuỗi tư duy và CoT-SC đều bỏ qua một vấn đề: có nhiều hơn một giải pháp cho câu hỏi, đặc biệt là khi con người giải quyết vấn đề.
Vì vậy, một nghiên cứu mới có tên Cây suy nghĩ (ToT) đã xuất hiện sau đó.
Đây là sơ đồ tìm kiếm dạng cây cho phép mô hình thử nhiều ý tưởng lập luận khác nhau, tự đánh giá, chọn hướng hành động tiếp theo và quay lại nếu cần.
Có thể thấy từ phương pháp, cây tư duy đi xa hơn chuỗi tư duy, làm cho tư duy của mô hình lớn trở nên “chủ động hơn”.
Đây là lý do tại sao khi chơi 24 điểm, tỷ lệ thành công của GPT-4 của Phần thưởng Chuỗi Tư duy chỉ là 4%**, nhưng tỷ lệ thành công của Cây Tư tưởng lại tăng vọt lên 74%.
NHƯNG, bất kể chuỗi tư duy, CoT-SC hay cây tư duy, đều có một hạn chế chung:
Không ai trong số họ thiết lập một nơi lưu trữ cho kết quả trung gian của quá trình suy nghĩ.
Suy cho cùng, không phải tất cả quá trình tư duy đều có thể được tạo thành chuỗi hoặc cây. Cách con người suy nghĩ về mọi thứ thường phức tạp hơn.
Khung lý luận tích lũy mới này vượt qua điểm này trong thiết kế——
Quá trình tư duy tổng thể của một mô hình lớn không nhất thiết phải là một chuỗi hoặc một cái cây, nó cũng có thể là Biểu đồ chu kỳ có hướng (DAG)! (Chà, nó có mùi giống như khớp thần kinh)
** ****△**Các cạnh trong biểu đồ có hướng và không có đường tròn; mỗi cạnh có hướng là một bước đạo hàm
Điều này có nghĩa là nó có thể lưu trữ tất cả các kết quả suy luận đúng về mặt lịch sử trong bộ nhớ để khám phá trong nhánh tìm kiếm hiện tại. (Ngược lại, cây tư duy không lưu trữ thông tin từ các nhánh khác)
Nhưng lý luận tích lũy cũng có thể được chuyển đổi liền mạch với chuỗi tư duy - miễn là loại bỏ "người xác minh" thì đó là mô hình chuỗi tư duy tiêu chuẩn.
Việc lập luận tích lũy được thiết kế theo phương pháp này đã đạt được kết quả tốt ở nhiều phương pháp khác nhau.
Giỏi toán và suy luận logic
Các nhà nghiên cứu đã chọn bộ dữ liệu wiki FOLIO và AutoTNLI, trò chơi 24 điểm và MATH để "kiểm tra" khả năng suy luận tích lũy.
Người đề xuất, người xác minh và người báo cáo sử dụng cùng một mô hình ngôn ngữ lớn trong mỗi thử nghiệm với các cài đặt khác nhau cho vai trò của họ.
Các mẫu cơ bản được sử dụng ở đây cho các thử nghiệm bao gồm GPT-3.5-turbo, GPT-4, LLaMA-13B và LLaMA-65B.
Điều đáng nói là lý tưởng nhất là mô hình phải được đào tạo trước cụ thể bằng cách sử dụng dữ liệu tác vụ phái sinh có liên quan và "người xác minh" cũng nên thêm một bộ chứng minh toán học chính thức, mô-đun bộ giải logic mệnh đề, v.v.
1. Khả năng suy luận logic
FOLIO là tập dữ liệu lý luận logic bậc đầu tiên và nhãn của các câu hỏi có thể là "đúng", "Sai" và "Không xác định"; AutoTNLI là tập dữ liệu lý luận logic bậc cao.
Trên bộ dữ liệu wiki FOLIO, so với các phương pháp kết quả đầu ra trực tiếp (Direct), chuỗi tư duy (CoT) và chuỗi tư duy nâng cao (CoT-SC), hiệu suất lý luận tích lũy (CR) luôn là tốt nhất.
Sau khi loại bỏ các trường hợp có vấn đề (chẳng hạn như câu trả lời sai) khỏi tập dữ liệu, độ chính xác suy luận GPT-4 bằng phương pháp CR đạt 98,04%, với tỷ lệ lỗi tối thiểu là 1,96%.
Hãy xem hiệu suất trên bộ dữ liệu AutoTNLI:
So với phương pháp CoT, CR đã cải thiện đáng kể hiệu suất của LLaMA-13B và LLaMA-65B.
Trên mẫu LLaMA-65B, mức cải thiện của CR so với CoT đạt 9,3%.
### 2. Khả năng chơi game 24 điểm
Bài báo ToT ban đầu sử dụng trò chơi 24 điểm nên các nhà nghiên cứu ở đây đã sử dụng bộ dữ liệu này để so sánh CR và ToT.
ToT sử dụng cây tìm kiếm có chiều rộng và chiều sâu cố định và CR cho phép các mô hình lớn tự động xác định độ sâu tìm kiếm.
Các nhà nghiên cứu nhận thấy trong các thí nghiệm rằng trong bối cảnh 24 điểm, thuật toán CR và thuật toán ToT rất giống nhau. Sự khác biệt là thuật toán trong CR tạo ra nhiều nhất một trạng thái mới cho mỗi lần lặp, trong khi ToT tạo ra nhiều trạng thái ứng cử viên trong mỗi lần lặp, đồng thời lọc và giữ lại một phần trạng thái.
Nói theo cách hiểu thông thường, ToT không có “người kiểm chứng” nêu trên như CR và không thể phán đoán các trạng thái (a, b, c) đúng hay sai, do đó ToT sẽ khám phá nhiều trạng thái không hợp lệ hơn CR.
Cuối cùng, độ chính xác của phương pháp CR thậm chí có thể đạt tới 98% (ToT là 74%) và số trạng thái truy cập trung bình ít hơn nhiều so với ToT.
Nói cách khác, CR không chỉ có tỷ lệ tìm kiếm chính xác cao hơn mà còn có hiệu quả tìm kiếm cao hơn.
### 3. Khả năng toán học
Bộ dữ liệu MATH chứa một số lượng lớn các câu hỏi suy luận toán học, bao gồm đại số, hình học, lý thuyết số, v.v. Độ khó của các câu hỏi được chia thành năm cấp độ.
Bằng cách sử dụng phương pháp CR, mô hình có thể phân tách câu hỏi thành các câu hỏi phụ có thể hoàn thành từng bước, đồng thời hỏi và trả lời các câu hỏi cho đến khi tạo ra câu trả lời.
Kết quả thử nghiệm cho thấy dưới hai cài đặt thử nghiệm khác nhau, tỷ lệ chính xác của CR vượt xa các phương pháp hiện có, với tỷ lệ chính xác tổng thể lên tới 58% và độ chính xác tương đối tăng 42% trong bài toán Cấp 5. Đã tải xuống SOTA mới theo mô hình GPT-4.
Nghiên cứu do Yao Qizhi và Yuan Yang của Đại học Thanh Hoa dẫn đầu
Bài viết này đến từ nhóm nghiên cứu AI cho Toán học do Yao Qizhi và Yuan Yang thuộc Viện Thông tin liên ngành Thanh Hoa dẫn đầu.
Đồng tác giả đầu tiên của bài báo là Zhang Yifan và Yang Jingqin, nghiên cứu sinh tiến sĩ năm 2021 tại Viện Thông tin liên ngành;
Người hướng dẫn và đồng tác giả là Trợ lý Giáo sư Yuan Yang và Viện sĩ Yao Qizhi.
Trương Nhất Phàm
Zhang Yifan tốt nghiệp trường Yuanpei của Đại học Bắc Kinh vào năm 2021. Anh hiện đang theo học với Trợ lý Giáo sư Yuan Yang. Hướng nghiên cứu chính của anh là lý thuyết và thuật toán của các mô hình cơ bản (mô hình ngôn ngữ lớn), học tập tự giám sát và trí tuệ nhân tạo đáng tin cậy.
Dương Cảnh Cầm
Yang Jingqin nhận bằng cử nhân của Viện Thông tin chéo tại Đại học Thanh Hoa vào năm 2021 và hiện đang học lấy bằng tiến sĩ dưới sự hướng dẫn của Trợ lý Giáo sư Yuan Yang. Các hướng nghiên cứu chính bao gồm mô hình ngôn ngữ lớn, học tập tự giám sát, chăm sóc y tế thông minh, v.v.
Nguyên Dương
Yuan Yang là trợ lý giáo sư tại Trường Thông tin liên ngành, Đại học Thanh Hoa. Tốt nghiệp Khoa Khoa học Máy tính của Đại học Bắc Kinh năm 2012; nhận bằng Tiến sĩ Khoa học Máy tính của Đại học Cornell, Hoa Kỳ năm 2018; từ năm 2018 đến 2019, anh làm nghiên cứu sinh sau tiến sĩ tại Trường Khoa học Dữ liệu Lớn thuộc Viện Massachusetts thuộc về Công nghệ.
Các hướng nghiên cứu chính của ông là chăm sóc y tế thông minh, lý thuyết AI cơ bản, lý thuyết phạm trù ứng dụng, v.v.
Diêu Kỳ Chi
Yao Qizhi là viện sĩ Viện Hàn lâm Khoa học Trung Quốc và là trưởng khoa Viện Thông tin Liên ngành tại Đại học Thanh Hoa, ông cũng là học giả châu Á đầu tiên giành được Giải thưởng Turing kể từ khi thành lập và là nhà khoa học máy tính Trung Quốc duy nhất giành được vinh dự này. cho đến nay.
Giáo sư Yao Qizhi từ chức giáo sư chính thức ở Princeton vào năm 2004 và trở lại Thanh Hoa để giảng dạy; năm 2005, ông thành lập "Lớp Yao", một lớp thực nghiệm khoa học máy tính dành cho sinh viên đại học Thanh Hoa; năm 2011, ông thành lập "Trung tâm Thông tin Lượng tử Thanh Hoa" " và "Viện nghiên cứu thông tin liên ngành"; năm 2019. Năm 2008, ông thành lập một lớp trí tuệ nhân tạo dành cho sinh viên đại học Thanh Hoa, được gọi là "Lớp học thông minh".
Ngày nay, Viện Thông tin Liên ngành của Đại học Thanh Hoa do ông đứng đầu đã nổi tiếng từ lâu, Lớp Yao và Zhiban đều trực thuộc Viện Thông tin Liên ngành.
Mối quan tâm nghiên cứu của Giáo sư Yao Qizhi bao gồm các thuật toán, mật mã, điện toán lượng tử, v.v. Ông là người tiên phong và có thẩm quyền quốc tế trong lĩnh vực này. Gần đây, ông xuất hiện tại Hội nghị Trí tuệ nhân tạo thế giới năm 2023. Viện nghiên cứu Qizhi Thượng Hải do ông lãnh đạo hiện đang nghiên cứu "trí tuệ nhân tạo tổng hợp thể hiện".
Liên kết giấy:
Xem bản gốc
Trang này có thể chứa nội dung của bên thứ ba, được cung cấp chỉ nhằm mục đích thông tin (không phải là tuyên bố/bảo đảm) và không được coi là sự chứng thực cho quan điểm của Gate hoặc là lời khuyên về tài chính hoặc chuyên môn. Xem Tuyên bố từ chối trách nhiệm để biết chi tiết.
Yao Qizhi đã đi đầu trong việc đề xuất một khung “tư duy” mô hình lớn! Độ chính xác của suy luận logic là 98%, cách suy nghĩ giống con người hơn.
Nguồn: Qubit
Bài báo Mô hình ngôn ngữ lớn đầu tiên do người đoạt giải Turing Yao Qizhi dẫn đầu đã có mặt!
Ngay khi bắt đầu, tôi đã nhắm tới hướng “làm cho những mô hình lớn suy nghĩ như con người”——
Các mô hình lớn không chỉ cần suy luận từng bước mà còn cần học cách “từng bước” và ghi nhớ tất cả các quy trình chính xác trong quá trình suy luận.
Cụ thể, bài báo mới này đề xuất một phương pháp mới gọi là Lý luận tích lũy, giúp cải thiện đáng kể khả năng của các mô hình lớn trong việc tham gia vào lý luận phức tạp.
Trên cơ sở này, lý luận tích lũy bổ sung thêm một "người xác minh" để đánh giá đúng sai trong thời gian thực. Khung tư duy của mô hình này cũng đã thay đổi từ chuỗi và cây sang một "đồ thị chu kỳ có hướng" phức tạp hơn.
Bằng cách này, mô hình lớn không chỉ có ý tưởng giải quyết vấn đề rõ ràng hơn mà còn phát triển kỹ năng “chơi bài”:
Đối với các bài toán như đại số và lý thuyết số hình học, độ chính xác tương đối của các mô hình lớn tăng 42%; khi chơi 24 điểm, tỷ lệ thành công tăng vọt lên 98%.
Lý luận tích lũy được thiết kế theo quan điểm này tốt hơn Chuỗi suy nghĩ (CoT) và Cây tư duy (ToT).
Vì vậy, cách tiếp cận mới này thực sự trông như thế nào? Chúng ta hãy cùng nhau xem xét.
Đột phá chuỗi tư duy & cây “tắc nghẽn”
Cốt lõi của lý luận tích lũy nằm ở việc cải thiện “hình dáng” quá trình tư duy của các mô hình lớn.
Cụ thể, phương pháp này sử dụng 3 mô hình ngôn ngữ lớn:
Trong quá trình suy luận, trước tiên “người đề xuất” đưa ra đề xuất, “người xác minh” chịu trách nhiệm đánh giá và “người báo cáo” quyết định có hoàn thiện câu trả lời và chấm dứt quá trình suy nghĩ hay không.
**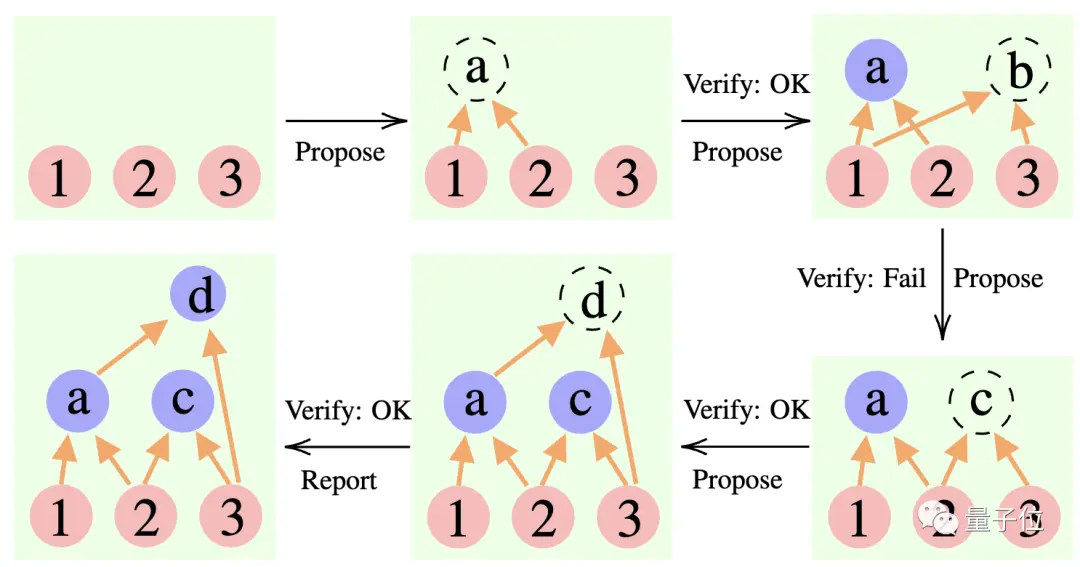 ****△**Ví dụ lý luận CR
****△**Ví dụ lý luận CR
Nó hơi giống ba loại vai trò trong một dự án nhóm: các thành viên trong nhóm đưa ra các ý tưởng khác nhau trước tiên, người hướng dẫn "kiểm tra" xem ý tưởng nào khả thi và trưởng nhóm quyết định thời điểm hoàn thành dự án.
Để hiểu được điều này, chúng ta phải bắt đầu từ “Chain of Thought, CoT” (Chain of Thought, CoT), “người khởi xướng” các phương pháp nâng cao tư duy mô hình lớn.
Phương pháp này được nhà khoa học OpenAI Jason Wei và những người khác đề xuất vào tháng 1 năm 2022. Cốt lõi là thêm văn bản "lý luận từng bước" vào đầu vào trong tập dữ liệu để kích thích khả năng tư duy của mô hình lớn.
**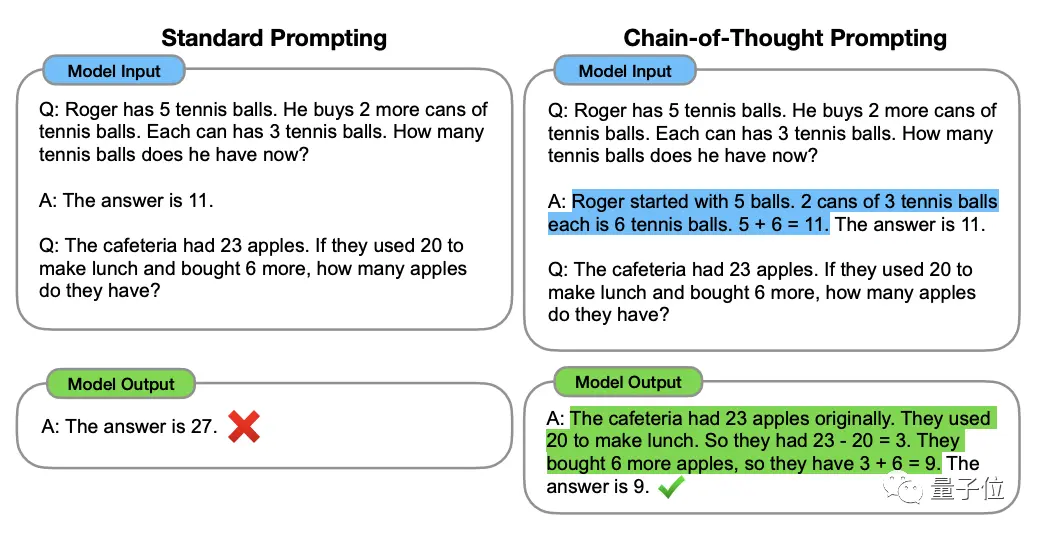 ****△**Được chọn từ bộ dữ liệu GSM8K
****△**Được chọn từ bộ dữ liệu GSM8K
Dựa trên nguyên tắc chuỗi tư duy, Google cũng nhanh chóng cho ra đời "phiên bản chuỗi tư duy PLUS", cụ thể là CoT-SC, chủ yếu tiến hành nhiều quy trình chuỗi tư duy và tiến hành bỏ phiếu đa số cho các câu trả lời để chọn ra câu trả lời hay nhất ... Câu trả lời đúng nhất có thể nâng cao hơn nữa độ chính xác của lý luận.
Nhưng cả Chuỗi tư duy và CoT-SC đều bỏ qua một vấn đề: có nhiều hơn một giải pháp cho câu hỏi, đặc biệt là khi con người giải quyết vấn đề.
Vì vậy, một nghiên cứu mới có tên Cây suy nghĩ (ToT) đã xuất hiện sau đó.
Đây là sơ đồ tìm kiếm dạng cây cho phép mô hình thử nhiều ý tưởng lập luận khác nhau, tự đánh giá, chọn hướng hành động tiếp theo và quay lại nếu cần.
Đây là lý do tại sao khi chơi 24 điểm, tỷ lệ thành công của GPT-4 của Phần thưởng Chuỗi Tư duy chỉ là 4%**, nhưng tỷ lệ thành công của Cây Tư tưởng lại tăng vọt lên 74%.
NHƯNG, bất kể chuỗi tư duy, CoT-SC hay cây tư duy, đều có một hạn chế chung:
Suy cho cùng, không phải tất cả quá trình tư duy đều có thể được tạo thành chuỗi hoặc cây. Cách con người suy nghĩ về mọi thứ thường phức tạp hơn.
Khung lý luận tích lũy mới này vượt qua điểm này trong thiết kế——
Quá trình tư duy tổng thể của một mô hình lớn không nhất thiết phải là một chuỗi hoặc một cái cây, nó cũng có thể là Biểu đồ chu kỳ có hướng (DAG)! (Chà, nó có mùi giống như khớp thần kinh)
**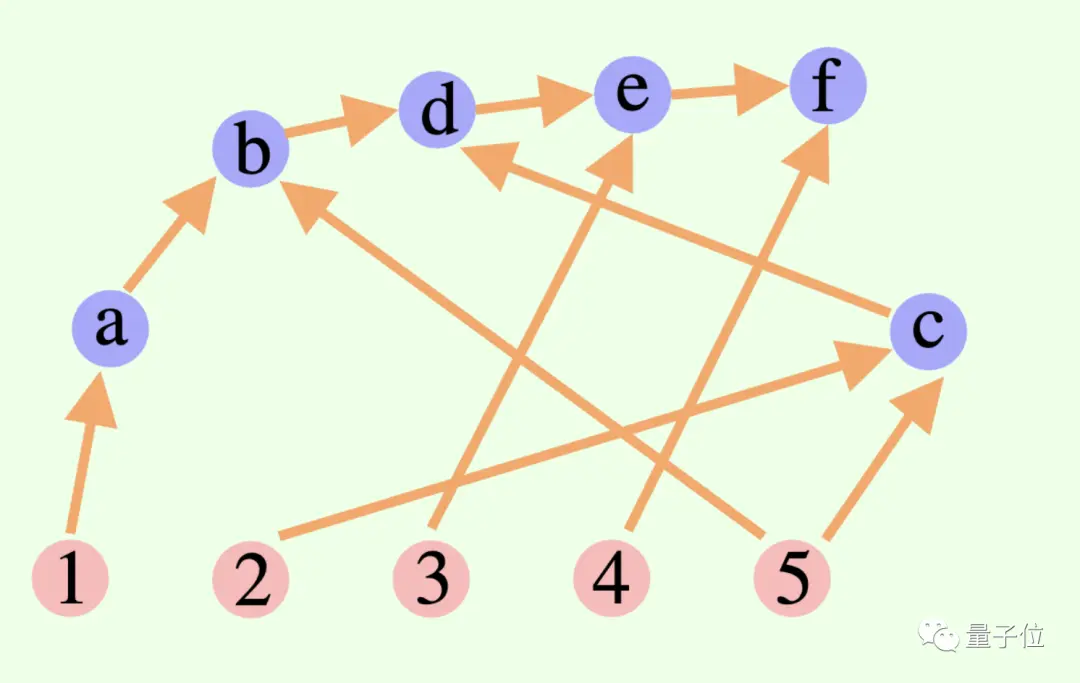 ****△**Các cạnh trong biểu đồ có hướng và không có đường tròn; mỗi cạnh có hướng là một bước đạo hàm
****△**Các cạnh trong biểu đồ có hướng và không có đường tròn; mỗi cạnh có hướng là một bước đạo hàm
Điều này có nghĩa là nó có thể lưu trữ tất cả các kết quả suy luận đúng về mặt lịch sử trong bộ nhớ để khám phá trong nhánh tìm kiếm hiện tại. (Ngược lại, cây tư duy không lưu trữ thông tin từ các nhánh khác)
Nhưng lý luận tích lũy cũng có thể được chuyển đổi liền mạch với chuỗi tư duy - miễn là loại bỏ "người xác minh" thì đó là mô hình chuỗi tư duy tiêu chuẩn.
Việc lập luận tích lũy được thiết kế theo phương pháp này đã đạt được kết quả tốt ở nhiều phương pháp khác nhau.
Giỏi toán và suy luận logic
Các nhà nghiên cứu đã chọn bộ dữ liệu wiki FOLIO và AutoTNLI, trò chơi 24 điểm và MATH để "kiểm tra" khả năng suy luận tích lũy.
Người đề xuất, người xác minh và người báo cáo sử dụng cùng một mô hình ngôn ngữ lớn trong mỗi thử nghiệm với các cài đặt khác nhau cho vai trò của họ.
Các mẫu cơ bản được sử dụng ở đây cho các thử nghiệm bao gồm GPT-3.5-turbo, GPT-4, LLaMA-13B và LLaMA-65B.
Điều đáng nói là lý tưởng nhất là mô hình phải được đào tạo trước cụ thể bằng cách sử dụng dữ liệu tác vụ phái sinh có liên quan và "người xác minh" cũng nên thêm một bộ chứng minh toán học chính thức, mô-đun bộ giải logic mệnh đề, v.v.
1. Khả năng suy luận logic
FOLIO là tập dữ liệu lý luận logic bậc đầu tiên và nhãn của các câu hỏi có thể là "đúng", "Sai" và "Không xác định"; AutoTNLI là tập dữ liệu lý luận logic bậc cao.
Trên bộ dữ liệu wiki FOLIO, so với các phương pháp kết quả đầu ra trực tiếp (Direct), chuỗi tư duy (CoT) và chuỗi tư duy nâng cao (CoT-SC), hiệu suất lý luận tích lũy (CR) luôn là tốt nhất.
Sau khi loại bỏ các trường hợp có vấn đề (chẳng hạn như câu trả lời sai) khỏi tập dữ liệu, độ chính xác suy luận GPT-4 bằng phương pháp CR đạt 98,04%, với tỷ lệ lỗi tối thiểu là 1,96%.
So với phương pháp CoT, CR đã cải thiện đáng kể hiệu suất của LLaMA-13B và LLaMA-65B.
Trên mẫu LLaMA-65B, mức cải thiện của CR so với CoT đạt 9,3%.
Bài báo ToT ban đầu sử dụng trò chơi 24 điểm nên các nhà nghiên cứu ở đây đã sử dụng bộ dữ liệu này để so sánh CR và ToT.
ToT sử dụng cây tìm kiếm có chiều rộng và chiều sâu cố định và CR cho phép các mô hình lớn tự động xác định độ sâu tìm kiếm.
Các nhà nghiên cứu nhận thấy trong các thí nghiệm rằng trong bối cảnh 24 điểm, thuật toán CR và thuật toán ToT rất giống nhau. Sự khác biệt là thuật toán trong CR tạo ra nhiều nhất một trạng thái mới cho mỗi lần lặp, trong khi ToT tạo ra nhiều trạng thái ứng cử viên trong mỗi lần lặp, đồng thời lọc và giữ lại một phần trạng thái.
Nói theo cách hiểu thông thường, ToT không có “người kiểm chứng” nêu trên như CR và không thể phán đoán các trạng thái (a, b, c) đúng hay sai, do đó ToT sẽ khám phá nhiều trạng thái không hợp lệ hơn CR.
Nói cách khác, CR không chỉ có tỷ lệ tìm kiếm chính xác cao hơn mà còn có hiệu quả tìm kiếm cao hơn.
Bộ dữ liệu MATH chứa một số lượng lớn các câu hỏi suy luận toán học, bao gồm đại số, hình học, lý thuyết số, v.v. Độ khó của các câu hỏi được chia thành năm cấp độ.
Bằng cách sử dụng phương pháp CR, mô hình có thể phân tách câu hỏi thành các câu hỏi phụ có thể hoàn thành từng bước, đồng thời hỏi và trả lời các câu hỏi cho đến khi tạo ra câu trả lời.
Kết quả thử nghiệm cho thấy dưới hai cài đặt thử nghiệm khác nhau, tỷ lệ chính xác của CR vượt xa các phương pháp hiện có, với tỷ lệ chính xác tổng thể lên tới 58% và độ chính xác tương đối tăng 42% trong bài toán Cấp 5. Đã tải xuống SOTA mới theo mô hình GPT-4.
Nghiên cứu do Yao Qizhi và Yuan Yang của Đại học Thanh Hoa dẫn đầu
Bài viết này đến từ nhóm nghiên cứu AI cho Toán học do Yao Qizhi và Yuan Yang thuộc Viện Thông tin liên ngành Thanh Hoa dẫn đầu.
Đồng tác giả đầu tiên của bài báo là Zhang Yifan và Yang Jingqin, nghiên cứu sinh tiến sĩ năm 2021 tại Viện Thông tin liên ngành;
Người hướng dẫn và đồng tác giả là Trợ lý Giáo sư Yuan Yang và Viện sĩ Yao Qizhi.
Trương Nhất Phàm
Zhang Yifan tốt nghiệp trường Yuanpei của Đại học Bắc Kinh vào năm 2021. Anh hiện đang theo học với Trợ lý Giáo sư Yuan Yang. Hướng nghiên cứu chính của anh là lý thuyết và thuật toán của các mô hình cơ bản (mô hình ngôn ngữ lớn), học tập tự giám sát và trí tuệ nhân tạo đáng tin cậy.
Dương Cảnh Cầm
Yang Jingqin nhận bằng cử nhân của Viện Thông tin chéo tại Đại học Thanh Hoa vào năm 2021 và hiện đang học lấy bằng tiến sĩ dưới sự hướng dẫn của Trợ lý Giáo sư Yuan Yang. Các hướng nghiên cứu chính bao gồm mô hình ngôn ngữ lớn, học tập tự giám sát, chăm sóc y tế thông minh, v.v.
Nguyên Dương
Các hướng nghiên cứu chính của ông là chăm sóc y tế thông minh, lý thuyết AI cơ bản, lý thuyết phạm trù ứng dụng, v.v.
Diêu Kỳ Chi
Giáo sư Yao Qizhi từ chức giáo sư chính thức ở Princeton vào năm 2004 và trở lại Thanh Hoa để giảng dạy; năm 2005, ông thành lập "Lớp Yao", một lớp thực nghiệm khoa học máy tính dành cho sinh viên đại học Thanh Hoa; năm 2011, ông thành lập "Trung tâm Thông tin Lượng tử Thanh Hoa" " và "Viện nghiên cứu thông tin liên ngành"; năm 2019. Năm 2008, ông thành lập một lớp trí tuệ nhân tạo dành cho sinh viên đại học Thanh Hoa, được gọi là "Lớp học thông minh".
Ngày nay, Viện Thông tin Liên ngành của Đại học Thanh Hoa do ông đứng đầu đã nổi tiếng từ lâu, Lớp Yao và Zhiban đều trực thuộc Viện Thông tin Liên ngành.
Mối quan tâm nghiên cứu của Giáo sư Yao Qizhi bao gồm các thuật toán, mật mã, điện toán lượng tử, v.v. Ông là người tiên phong và có thẩm quyền quốc tế trong lĩnh vực này. Gần đây, ông xuất hiện tại Hội nghị Trí tuệ nhân tạo thế giới năm 2023. Viện nghiên cứu Qizhi Thượng Hải do ông lãnh đạo hiện đang nghiên cứu "trí tuệ nhân tạo tổng hợp thể hiện".
Liên kết giấy: