Làm cho các mô hình lớn nhìn vào sơ đồ hơn là gõ công việc! Nghiên cứu mới của NeurIPS 2023 đề xuất phương pháp truy vấn đa phương thức, độ chính xác cải thiện 7,8%
Khả năng "đọc ảnh" của các người mẫu lớn rất mạnh, tại sao bạn cứ tìm kiếm những thứ sai lầm?
Ví dụ, nhầm lẫn những con dơi trông không giống chúng với vợt, hoặc không nhận ra cá quý hiếm trong một số bộ dữ liệu...
Điều này là do khi chúng tôi để một mô hình lớn "tìm thấy thứ gì đó", chúng tôi thường nhập ** văn bản **.
Nếu mô tả không rõ ràng hoặc quá một phần, chẳng hạn như "dơi" (dơi hay đánh?). Hoặc "Cyprinodon diabolis" và AI sẽ bị nhầm lẫn.
Điều này dẫn đến việc sử dụng các mô hình lớn để thực hiện ** phát hiện đối tượng **, đặc biệt là các tác vụ phát hiện đối tượng thế giới mở (cảnh không xác định), hiệu quả thường không tốt như mong đợi.
Giờ đây, một bài báo có trong NeurIPS 2023 cuối cùng đã giải quyết được vấn đề này.
Bài báo này đề xuất một phương pháp phát hiện đối tượng **MQ-Det ** dựa trên truy vấn đa phương thức, chỉ cần thêm một ví dụ hình ảnh vào đầu vào, điều này có thể cải thiện đáng kể độ chính xác của việc tìm kiếm mọi thứ trong các mô hình lớn.
Trên bộ dữ liệu phát hiện điểm chuẩn LVIS, MQ-Det cải thiện độ chính xác GLIP của các mô hình lớn phát hiện chính trung bình khoảng 7,8% và cải thiện độ chính xác của 13 nhiệm vụ hạ nguồn mẫu nhỏ chuẩn trung bình 6,3%.
Chính xác thì điều này được thực hiện như thế nào? Chúng ta hãy xem.
Sau đây được sao chép từ tác giả của bài báo, blogger Zhihu @Qinyuanxia:
Mục lục
MQ-Det: Mô hình lớn phát hiện đối tượng thế giới mở cho truy vấn đa phương thức
1.1 Từ truy vấn văn bản đến truy vấn đa phương thức
1.2 Kiến trúc mô hình truy vấn đa phương thức plug-and-play MQ-Det
1.3 Chiến lược đào tạo hiệu quả của MQ-Det
1.4 Kết quả thực nghiệm: Đánh giá tinh chỉnh miễn phí
*1.5 Kết quả thực nghiệm: Đánh giá ít mũi tiêm
1.6 Truy vấn đa phương thức về triển vọng phát hiện đối tượng
MQ-Det: Mô hình lớn về phát hiện đối tượng thế giới mở cho truy vấn đa phương thức **
Phát hiện đối tượng truy vấn đa phương thức trong tự nhiên
Liên kết giấy:
Địa chỉ mã:**
### 1.1 Từ truy vấn văn bản đến truy vấn đa phương thức
**Một bức tranh đáng giá một ngàn từ **: Với sự gia tăng của đào tạo tiền đồ họa, với sự trợ giúp của ngữ nghĩa mở của văn bản, phát hiện đối tượng đã dần bước vào giai đoạn nhận thức thế giới mở. Vì lý do này, nhiều mô hình phát hiện lớn tuân theo mô hình truy vấn văn bản, nghĩa là sử dụng mô tả văn bản phân loại để truy vấn các mục tiêu tiềm năng trong hình ảnh mục tiêu. Tuy nhiên, cách làm này thường phải đối mặt với vấn đề "rộng nhưng không tinh tế".
Ví dụ, (1) việc phát hiện vật thể hạt mịn (cá giống) trong Hình 1 thường khó mô tả các loài hạt mịn khác nhau với văn bản hạn chế và (2) sự mơ hồ về phạm trù ("dơi" có thể đề cập đến cả dơi và vợt).
Tuy nhiên, các vấn đề trên có thể được giải quyết bằng các ví dụ hình ảnh, cung cấp manh mối tính năng phong phú hơn cho đối tượng đích so với văn bản, nhưng đồng thời văn bản có ** khái quát hóa mạnh mẽ **.
Do đó, làm thế nào để kết hợp hữu cơ hai phương pháp truy vấn đã trở thành một ý tưởng tự nhiên.
Khó khăn trong việc có được khả năng truy vấn đa phương thức: Có ba thách thức trong việc làm thế nào để có được một mô hình như vậy với các truy vấn đa phương thức: (1) Tinh chỉnh trực tiếp với các ví dụ hình ảnh hạn chế có thể dễ dàng dẫn đến quên thảm khốc; (2) Đào tạo một mô hình phát hiện lớn từ đầu sẽ có khái quát tốt nhưng tiêu thụ rất lớn, ví dụ, đào tạo một thẻ GLIP yêu cầu 480 ngày đào tạo với khối lượng dữ liệu 30 triệu.
Phát hiện đối tượng truy vấn đa phương thức: Dựa trên những cân nhắc trên, tác giả đề xuất chiến lược đào tạo và thiết kế mô hình đơn giản và hiệu quả - MQ-Det.
MQ-Det chèn một số lượng nhỏ các mô-đun nhận thức được kiểm soát (GCP) để nhận đầu vào của các ví dụ trực quan trên cơ sở mô hình lớn phát hiện truy vấn văn bản bị đóng băng hiện có và thiết kế chiến lược đào tạo dự đoán ngôn ngữ mặt nạ tình trạng hình ảnh để có được máy dò hiệu quả cho các truy vấn đa phương thức hiệu suất cao.
**1.2 Kiến trúc mô hình truy vấn đa phương thức MQ-Det plug-and-play **
** **####### △Hình 1 Sơ đồ kiến trúc phương pháp MQ-Det
** Mô-đun nhận thức được kiểm soát **
Như thể hiện trong Hình 1, tác giả chèn một mô-đun nhận thức gating (GCP) từng lớp ở phía bộ mã hóa văn bản của mô hình lớn phát hiện truy vấn văn bản bị đóng băng hiện có và chế độ làm việc của GCP có thể được biểu diễn ngắn gọn bằng công thức sau:
Đối với danh mục thứ i, nhập ví dụ trực quan Vi, chú ý chéo đầu tiên (X-MHA) với hình ảnh đích I
để mở rộng khả năng biểu diễn của nó, và sau đó mỗi văn bản thể loại ti và ví dụ trực quan thể loại tương ứng
Thực hiện sự chú ý chéo được
, sau đó văn bản gốc ti và tăng cường hình ảnh của văn bản được tăng cường bởi một cổng mô-đun gating
Hợp nhất để có được đầu ra của lớp hiện tại
。 Thiết kế đơn giản này tuân theo ba nguyên tắc: (1) khả năng mở rộng danh mục; (2) tính đầy đủ ngữ nghĩa; (3) Chống mất trí nhớ, thảo luận cụ thể có thể được tìm thấy trong văn bản gốc.
** 1.3 Chiến lược đào tạo hiệu quả MQ-Det **
** Đào tạo điều chế dựa trên trình phát hiện truy vấn ngôn ngữ đông lạnh **
Vì bản thân mô hình lớn phát hiện trước đào tạo hiện tại của truy vấn văn bản có tính khái quát tốt, các tác giả tin rằng chỉ cần thực hiện các điều chỉnh nhỏ với các chi tiết trực quan trên cơ sở các tính năng văn bản gốc.
Trong bài viết, cũng có một minh chứng thực nghiệm cụ thể rằng rất dễ mang lại sự quên lãng thảm khốc sau khi mở các thông số của mô hình được đào tạo trước ban đầu và tinh chỉnh, nhưng mất khả năng phát hiện thế giới mở.
Do đó, MQ-Det có thể chèn thông tin hình ảnh một cách hiệu quả vào máy dò truy vấn văn bản hiện có trên cơ sở trình phát hiện truy vấn văn bản bị đóng băng được đào tạo trước và chỉ điều chỉnh mô-đun GCP được chèn bằng cách đào tạo.
Trong bài báo, các tác giả áp dụng thiết kế kết cấu và kỹ thuật đào tạo của MQ-Det cho các mô hình SOTA hiện tại GLIP và GroundingDINO tương ứng để xác minh tính linh hoạt của phương pháp.
** Chiến lược đào tạo dự đoán ngôn ngữ mặt nạ với điều kiện thị giác **
Các tác giả cũng đề xuất một chiến lược đào tạo dự đoán ngôn ngữ che mặt có điều kiện trực quan để giải quyết vấn đề lười học tập do đóng băng các mô hình được đào tạo trước.
Cái gọi là sự lười biếng học tập có nghĩa là máy dò có xu hướng duy trì các đặc điểm của truy vấn văn bản gốc trong quá trình đào tạo, do đó bỏ qua các tính năng truy vấn trực quan mới được thêm vào.
Với mục đích này, MQ-Det được sử dụng ngẫu nhiên trong quá trình đào tạo[MASK] Mã thông báo thay thế mã thông báo văn bản, buộc mô hình phải học từ phía tính năng truy vấn trực quan, cụ thể là:
Chiến lược này tuy đơn giản nhưng rất hiệu quả, và từ kết quả thử nghiệm, chiến lược này đã mang lại sự cải thiện đáng kể về hiệu suất.
1.4 Kết quả thí nghiệm: Đánh giá không cần tinh chỉnh
Tinh chỉnh miễn phí: MQ-Det đề xuất một chiến lược đánh giá thực tế hơn: finetuning-free, so với đánh giá zero-shot truyền thống chỉ sử dụng văn bản danh mục. Nó được định nghĩa là phát hiện đối tượng bằng cách sử dụng văn bản danh mục, ví dụ hình ảnh hoặc kết hợp cả hai mà không cần bất kỳ tinh chỉnh xuôi dòng nào.
Trong cài đặt không cần tinh chỉnh, MQ-Det chọn 5 ví dụ trực quan cho mỗi danh mục và kết hợp văn bản danh mục để phát hiện đối tượng, trong khi các mô hình hiện có khác không hỗ trợ truy vấn trực quan và chỉ có thể sử dụng mô tả văn bản thuần túy để phát hiện đối tượng. Bảng dưới đây cho thấy kết quả trên LVIS MiniVal và LVIS v1.0. Có thể thấy rằng sự ra đời của truy vấn đa phương thức đã cải thiện đáng kể khả năng phát hiện đối tượng thế giới mở.
** **###### △Bảng 1: Hiệu suất không cần tinh chỉnh của từng mô hình phát hiện theo bộ dữ liệu điểm chuẩn LVIS
Như có thể thấy từ Bảng 1, MQ-GLIP-L đã cải thiện AP hơn 7% trên cơ sở GLIP-L, và hiệu quả là rất đáng kể!
1.5 Kết quả thí nghiệm: Đánh giá ít mũi tiêm
** **####### △Bảng 2: Hiệu suất của từng mô hình trong ODinW-35 và 13 tập hợp con của ODinW-13 trong 35 tác vụ phát hiện
Các tác giả tiếp tục thực hiện các thí nghiệm toàn diện trong ODinW-35, một nhiệm vụ phát hiện xuôi dòng 35. Như có thể thấy từ Bảng 2, MQ-Det không chỉ có hiệu suất tinh chỉnh mạnh mẽ mà còn có khả năng phát hiện mẫu nhỏ tốt, điều này càng khẳng định tiềm năng của các truy vấn đa phương thức. Hình 2 cũng cho thấy sự cải thiện đáng kể của MQ-Det thành GLIP.
** **###### △Hình 2 So sánh hiệu quả sử dụng dữ liệu; Trục ngang: số lượng mẫu đào tạo, trục dọc: AP trung bình trên OdinW-13
** 1.6 Triển vọng phát hiện đối tượng truy vấn đa phương thức **
Là một lĩnh vực nghiên cứu dựa trên các ứng dụng thực tế, phát hiện đối tượng rất chú trọng đến việc hạ cánh của các thuật toán.
Mặc dù mô hình phát hiện đối tượng truy vấn văn bản thuần túy trước đây cho thấy sự khái quát hóa tốt, nhưng rất khó để bao quát thông tin chi tiết trong tiếng Trung phát hiện thế giới mở thực tế và độ chi tiết thông tin phong phú trong hình ảnh hoàn thành hoàn hảo liên kết này.
Cho đến nay, chúng ta có thể thấy rằng văn bản chung chung nhưng không chính xác, và hình ảnh chính xác nhưng không chung chung, và nếu chúng ta có thể kết hợp hiệu quả cả hai, nghĩa là truy vấn đa phương thức, nó sẽ thúc đẩy phát hiện đối tượng thế giới mở để tiến xa hơn.
MQ-Det đã thực hiện bước đầu tiên trong truy vấn đa phương thức và cải thiện hiệu suất đáng kể của nó cũng cho thấy tiềm năng lớn của việc phát hiện mục tiêu truy vấn đa phương thức.
Đồng thời, việc giới thiệu mô tả văn bản và ví dụ trực quan cung cấp cho người dùng nhiều sự lựa chọn hơn, giúp phát hiện đối tượng linh hoạt và thân thiện với người dùng hơn.
Liên kết gốc:
Xem bản gốc
Trang này có thể chứa nội dung của bên thứ ba, được cung cấp chỉ nhằm mục đích thông tin (không phải là tuyên bố/bảo đảm) và không được coi là sự chứng thực cho quan điểm của Gate hoặc là lời khuyên về tài chính hoặc chuyên môn. Xem Tuyên bố từ chối trách nhiệm để biết chi tiết.
Làm cho các mô hình lớn nhìn vào sơ đồ hơn là gõ công việc! Nghiên cứu mới của NeurIPS 2023 đề xuất phương pháp truy vấn đa phương thức, độ chính xác cải thiện 7,8%
Nguồn gốc: Qubits
Khả năng "đọc ảnh" của các người mẫu lớn rất mạnh, tại sao bạn cứ tìm kiếm những thứ sai lầm?
Ví dụ, nhầm lẫn những con dơi trông không giống chúng với vợt, hoặc không nhận ra cá quý hiếm trong một số bộ dữ liệu...
Nếu mô tả không rõ ràng hoặc quá một phần, chẳng hạn như "dơi" (dơi hay đánh?). Hoặc "Cyprinodon diabolis" và AI sẽ bị nhầm lẫn.
Điều này dẫn đến việc sử dụng các mô hình lớn để thực hiện ** phát hiện đối tượng **, đặc biệt là các tác vụ phát hiện đối tượng thế giới mở (cảnh không xác định), hiệu quả thường không tốt như mong đợi.
Giờ đây, một bài báo có trong NeurIPS 2023 cuối cùng đã giải quyết được vấn đề này.
Trên bộ dữ liệu phát hiện điểm chuẩn LVIS, MQ-Det cải thiện độ chính xác GLIP của các mô hình lớn phát hiện chính trung bình khoảng 7,8% và cải thiện độ chính xác của 13 nhiệm vụ hạ nguồn mẫu nhỏ chuẩn trung bình 6,3%.
Chính xác thì điều này được thực hiện như thế nào? Chúng ta hãy xem.
Sau đây được sao chép từ tác giả của bài báo, blogger Zhihu @Qinyuanxia:
Mục lục
MQ-Det: Mô hình lớn về phát hiện đối tượng thế giới mở cho truy vấn đa phương thức **
Phát hiện đối tượng truy vấn đa phương thức trong tự nhiên
Liên kết giấy:
Địa chỉ mã:**
**Một bức tranh đáng giá một ngàn từ **: Với sự gia tăng của đào tạo tiền đồ họa, với sự trợ giúp của ngữ nghĩa mở của văn bản, phát hiện đối tượng đã dần bước vào giai đoạn nhận thức thế giới mở. Vì lý do này, nhiều mô hình phát hiện lớn tuân theo mô hình truy vấn văn bản, nghĩa là sử dụng mô tả văn bản phân loại để truy vấn các mục tiêu tiềm năng trong hình ảnh mục tiêu. Tuy nhiên, cách làm này thường phải đối mặt với vấn đề "rộng nhưng không tinh tế".
Ví dụ, (1) việc phát hiện vật thể hạt mịn (cá giống) trong Hình 1 thường khó mô tả các loài hạt mịn khác nhau với văn bản hạn chế và (2) sự mơ hồ về phạm trù ("dơi" có thể đề cập đến cả dơi và vợt).
Tuy nhiên, các vấn đề trên có thể được giải quyết bằng các ví dụ hình ảnh, cung cấp manh mối tính năng phong phú hơn cho đối tượng đích so với văn bản, nhưng đồng thời văn bản có ** khái quát hóa mạnh mẽ **.
Do đó, làm thế nào để kết hợp hữu cơ hai phương pháp truy vấn đã trở thành một ý tưởng tự nhiên.
Khó khăn trong việc có được khả năng truy vấn đa phương thức: Có ba thách thức trong việc làm thế nào để có được một mô hình như vậy với các truy vấn đa phương thức: (1) Tinh chỉnh trực tiếp với các ví dụ hình ảnh hạn chế có thể dễ dàng dẫn đến quên thảm khốc; (2) Đào tạo một mô hình phát hiện lớn từ đầu sẽ có khái quát tốt nhưng tiêu thụ rất lớn, ví dụ, đào tạo một thẻ GLIP yêu cầu 480 ngày đào tạo với khối lượng dữ liệu 30 triệu.
Phát hiện đối tượng truy vấn đa phương thức: Dựa trên những cân nhắc trên, tác giả đề xuất chiến lược đào tạo và thiết kế mô hình đơn giản và hiệu quả - MQ-Det.
MQ-Det chèn một số lượng nhỏ các mô-đun nhận thức được kiểm soát (GCP) để nhận đầu vào của các ví dụ trực quan trên cơ sở mô hình lớn phát hiện truy vấn văn bản bị đóng băng hiện có và thiết kế chiến lược đào tạo dự đoán ngôn ngữ mặt nạ tình trạng hình ảnh để có được máy dò hiệu quả cho các truy vấn đa phương thức hiệu suất cao.
**1.2 Kiến trúc mô hình truy vấn đa phương thức MQ-Det plug-and-play **
** **####### △Hình 1 Sơ đồ kiến trúc phương pháp MQ-Det
**####### △Hình 1 Sơ đồ kiến trúc phương pháp MQ-Det
** Mô-đun nhận thức được kiểm soát **
Như thể hiện trong Hình 1, tác giả chèn một mô-đun nhận thức gating (GCP) từng lớp ở phía bộ mã hóa văn bản của mô hình lớn phát hiện truy vấn văn bản bị đóng băng hiện có và chế độ làm việc của GCP có thể được biểu diễn ngắn gọn bằng công thức sau:
** 1.3 Chiến lược đào tạo hiệu quả MQ-Det **
** Đào tạo điều chế dựa trên trình phát hiện truy vấn ngôn ngữ đông lạnh **
Vì bản thân mô hình lớn phát hiện trước đào tạo hiện tại của truy vấn văn bản có tính khái quát tốt, các tác giả tin rằng chỉ cần thực hiện các điều chỉnh nhỏ với các chi tiết trực quan trên cơ sở các tính năng văn bản gốc.
Trong bài viết, cũng có một minh chứng thực nghiệm cụ thể rằng rất dễ mang lại sự quên lãng thảm khốc sau khi mở các thông số của mô hình được đào tạo trước ban đầu và tinh chỉnh, nhưng mất khả năng phát hiện thế giới mở.
Do đó, MQ-Det có thể chèn thông tin hình ảnh một cách hiệu quả vào máy dò truy vấn văn bản hiện có trên cơ sở trình phát hiện truy vấn văn bản bị đóng băng được đào tạo trước và chỉ điều chỉnh mô-đun GCP được chèn bằng cách đào tạo.
Trong bài báo, các tác giả áp dụng thiết kế kết cấu và kỹ thuật đào tạo của MQ-Det cho các mô hình SOTA hiện tại GLIP và GroundingDINO tương ứng để xác minh tính linh hoạt của phương pháp.
** Chiến lược đào tạo dự đoán ngôn ngữ mặt nạ với điều kiện thị giác **
Các tác giả cũng đề xuất một chiến lược đào tạo dự đoán ngôn ngữ che mặt có điều kiện trực quan để giải quyết vấn đề lười học tập do đóng băng các mô hình được đào tạo trước.
Cái gọi là sự lười biếng học tập có nghĩa là máy dò có xu hướng duy trì các đặc điểm của truy vấn văn bản gốc trong quá trình đào tạo, do đó bỏ qua các tính năng truy vấn trực quan mới được thêm vào.
Với mục đích này, MQ-Det được sử dụng ngẫu nhiên trong quá trình đào tạo[MASK] Mã thông báo thay thế mã thông báo văn bản, buộc mô hình phải học từ phía tính năng truy vấn trực quan, cụ thể là:
1.4 Kết quả thí nghiệm: Đánh giá không cần tinh chỉnh
Tinh chỉnh miễn phí: MQ-Det đề xuất một chiến lược đánh giá thực tế hơn: finetuning-free, so với đánh giá zero-shot truyền thống chỉ sử dụng văn bản danh mục. Nó được định nghĩa là phát hiện đối tượng bằng cách sử dụng văn bản danh mục, ví dụ hình ảnh hoặc kết hợp cả hai mà không cần bất kỳ tinh chỉnh xuôi dòng nào.
Trong cài đặt không cần tinh chỉnh, MQ-Det chọn 5 ví dụ trực quan cho mỗi danh mục và kết hợp văn bản danh mục để phát hiện đối tượng, trong khi các mô hình hiện có khác không hỗ trợ truy vấn trực quan và chỉ có thể sử dụng mô tả văn bản thuần túy để phát hiện đối tượng. Bảng dưới đây cho thấy kết quả trên LVIS MiniVal và LVIS v1.0. Có thể thấy rằng sự ra đời của truy vấn đa phương thức đã cải thiện đáng kể khả năng phát hiện đối tượng thế giới mở.
**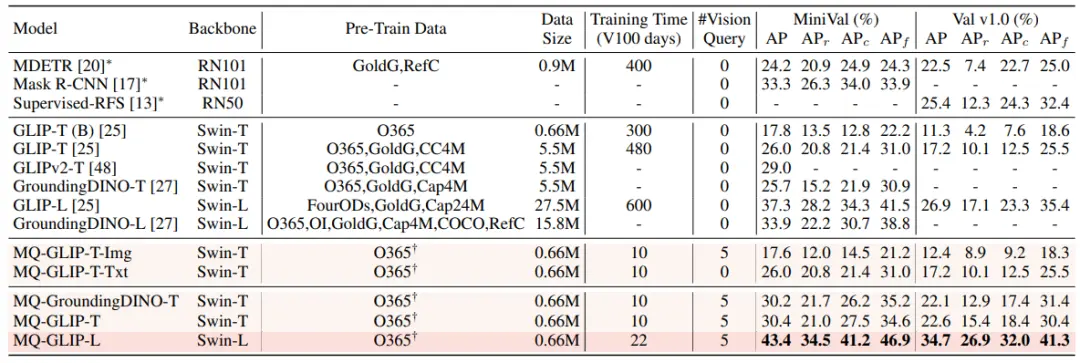 **###### △Bảng 1: Hiệu suất không cần tinh chỉnh của từng mô hình phát hiện theo bộ dữ liệu điểm chuẩn LVIS
**###### △Bảng 1: Hiệu suất không cần tinh chỉnh của từng mô hình phát hiện theo bộ dữ liệu điểm chuẩn LVIS
Như có thể thấy từ Bảng 1, MQ-GLIP-L đã cải thiện AP hơn 7% trên cơ sở GLIP-L, và hiệu quả là rất đáng kể!
1.5 Kết quả thí nghiệm: Đánh giá ít mũi tiêm
**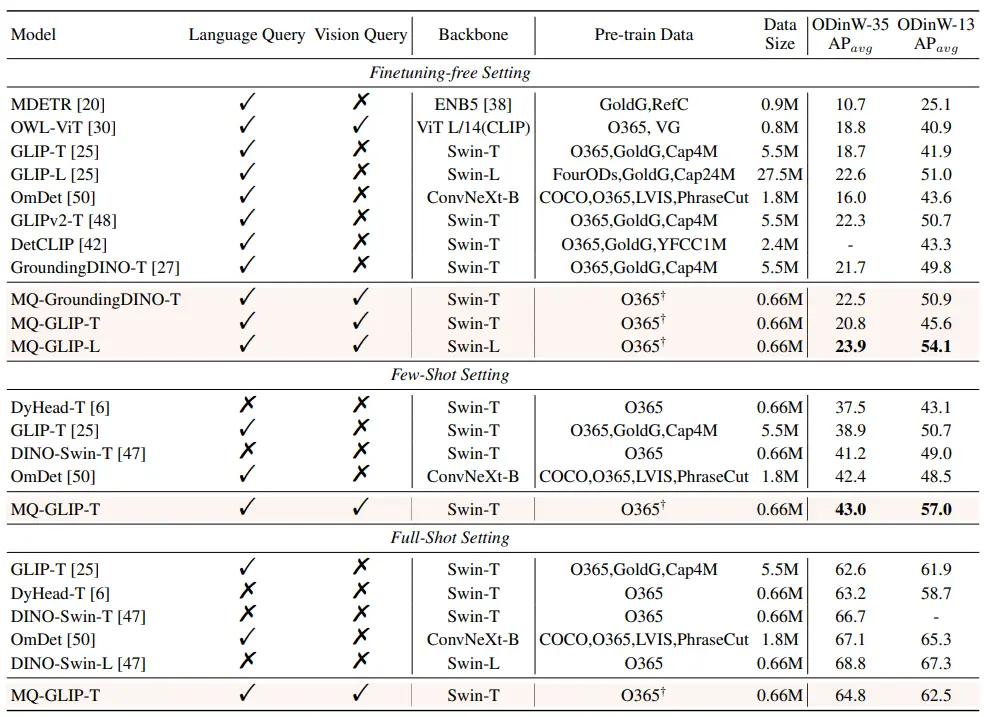 **####### △Bảng 2: Hiệu suất của từng mô hình trong ODinW-35 và 13 tập hợp con của ODinW-13 trong 35 tác vụ phát hiện
**####### △Bảng 2: Hiệu suất của từng mô hình trong ODinW-35 và 13 tập hợp con của ODinW-13 trong 35 tác vụ phát hiện
Các tác giả tiếp tục thực hiện các thí nghiệm toàn diện trong ODinW-35, một nhiệm vụ phát hiện xuôi dòng 35. Như có thể thấy từ Bảng 2, MQ-Det không chỉ có hiệu suất tinh chỉnh mạnh mẽ mà còn có khả năng phát hiện mẫu nhỏ tốt, điều này càng khẳng định tiềm năng của các truy vấn đa phương thức. Hình 2 cũng cho thấy sự cải thiện đáng kể của MQ-Det thành GLIP.
**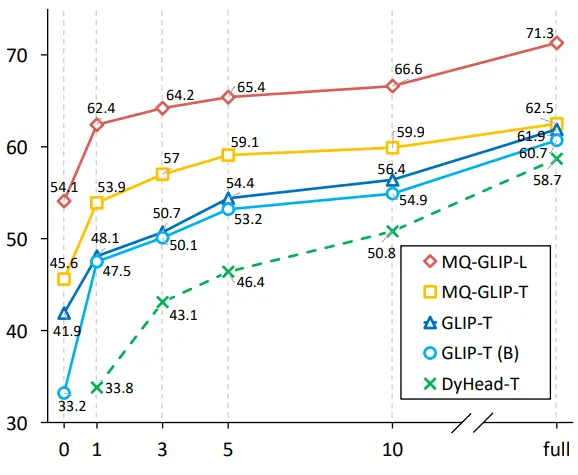 **###### △Hình 2 So sánh hiệu quả sử dụng dữ liệu; Trục ngang: số lượng mẫu đào tạo, trục dọc: AP trung bình trên OdinW-13
**###### △Hình 2 So sánh hiệu quả sử dụng dữ liệu; Trục ngang: số lượng mẫu đào tạo, trục dọc: AP trung bình trên OdinW-13
** 1.6 Triển vọng phát hiện đối tượng truy vấn đa phương thức **
Là một lĩnh vực nghiên cứu dựa trên các ứng dụng thực tế, phát hiện đối tượng rất chú trọng đến việc hạ cánh của các thuật toán.
Mặc dù mô hình phát hiện đối tượng truy vấn văn bản thuần túy trước đây cho thấy sự khái quát hóa tốt, nhưng rất khó để bao quát thông tin chi tiết trong tiếng Trung phát hiện thế giới mở thực tế và độ chi tiết thông tin phong phú trong hình ảnh hoàn thành hoàn hảo liên kết này.
Cho đến nay, chúng ta có thể thấy rằng văn bản chung chung nhưng không chính xác, và hình ảnh chính xác nhưng không chung chung, và nếu chúng ta có thể kết hợp hiệu quả cả hai, nghĩa là truy vấn đa phương thức, nó sẽ thúc đẩy phát hiện đối tượng thế giới mở để tiến xa hơn.
MQ-Det đã thực hiện bước đầu tiên trong truy vấn đa phương thức và cải thiện hiệu suất đáng kể của nó cũng cho thấy tiềm năng lớn của việc phát hiện mục tiêu truy vấn đa phương thức.
Đồng thời, việc giới thiệu mô tả văn bản và ví dụ trực quan cung cấp cho người dùng nhiều sự lựa chọn hơn, giúp phát hiện đối tượng linh hoạt và thân thiện với người dùng hơn.
Liên kết gốc: