Mô hình tham số 7 tỷ mất 500 đô la để "điều chỉnh" đã đánh bại tham số 70 tỷ Llama 2!
Và máy tính xách tay có thể chạy dễ dàng và hiệu quả tương đương với ChatGPT.
Quan trọng: Miễn phí, không có tiền.
Mô hình mã nguồn mở **Zephyr-7B ** được tạo ra bởi nhóm HuggingFace H4, cá mập điên.
Mô hình cơ bản của nó là một mô hình lớn mã nguồn mở ** Mistral-7B **, đã phát nổ cách đây một thời gian và được xây dựng bởi Mistral AI, được gọi là "OpenAI châu Âu".
Bạn biết đấy, chưa đầy 2 tuần sau khi phát hành Mistral-7B, nhiều phiên bản tinh chỉnh khác nhau đã lần lượt xuất hiện, và có rất nhiều phong cách "alpaca" nhanh chóng xuất hiện khi Llama được phát hành lần đầu tiên.
Chìa khóa cho khả năng nổi bật giữa các biến thể của Zephyr là nhóm nghiên cứu đã tinh chỉnh mô hình trên một tập dữ liệu công khai bằng cách sử dụng Tối ưu hóa sở thích trực tiếp (DPO) trên Mistral.
Nhóm nghiên cứu cũng nhận thấy rằng việc loại bỏ sự liên kết tích hợp của tập dữ liệu có thể cải thiện hơn nữa hiệu suất của MT Bench. Zephyr-7B-alpha ban đầu có điểm MT-Bench trung bình là 7,09, vượt qua Llama2-70B-Chat.
** **###### △MT-Bench là một bài kiểm tra điểm chuẩn để đánh giá khả năng xử lý nhiều vòng đối thoại của mô hình và bộ câu hỏi bao gồm 8 hạng mục như viết, nhập vai và trích xuất.
Vấn đề là, sau đó nó tiếp tục nâng cấp!
Nhóm H4 đã ra mắt thế hệ thứ hai của Zephyr-7B-beta. Họ nói thêm rằng họ đã khám phá ý tưởng trích xuất sự liên kết từ GPT-4, Claude 2 và sau đó tiêm nó vào các mô hình nhỏ, phát triển một phương pháp sử dụng tối ưu hóa sở thích trực tiếp chưng cất (dDPO) cho các mô hình nhỏ.
Ở thế hệ thứ hai của Zephyr, điểm MT-Bench trung bình tăng lên 7,34.
Trên Alpaca, Zephyr có tỷ lệ thắng 90,6%, tốt hơn ChatGPT (3,5):
Cư dân mạng đổ xô đến Zephyr đã nhất trí khen ngợi, và nhóm lmsys cũng cho thấy điểm Elo của Zephyr-7b-beta, đã tăng vọt rất cao 🔥:
Bảng xếp hạng Arena nội bộ đã vượt qua 13B mô hình.
Một số người thậm chí còn nói:
Nhìn thấy cách tiếp cận DPO hoạt động tốt trong lĩnh vực này có lẽ là điều thú vị nhất về sự phát triển của các mô hình ngôn ngữ lớn trong năm nay.
Nhiều cư dân mạng đã bắt đầu thử nghiệm tác dụng của Zephyr, và kết quả tốt một cách đáng ngạc nhiên.
Từ Mistral có nghĩa là gió khô, lạnh và mạnh trong tiếng Pháp, trong khi Zephyr có nghĩa là gió tây nhẹ, dễ chịu.
Không có nghi ngờ rằng có một sở thú ở phía bên kia của Llama, và không có nghi ngờ rằng có một văn phòng thời tiết ở phía này.
** Mô hình 7B tốt nhất lại đổi chủ **
Hãy bắt đầu với các yêu cầu máy tính để chạy Zephyr. Cư dân mạng nói "Quần Thái cay" sau khi thử nghiệm! , máy tính xách tay (Apple M1 Pro) là đủ, "kết quả rất tốt".
Về hiệu quả, nhóm Llama Index (trước đây gọi là GPT Index) cũng đã thử nghiệm nó.
Hóa ra Zephyr hiện là mô hình 7B mã nguồn mở duy nhất hoạt động tốt trên các tác vụ RÁCH / tác nhân cấp cao.
Dữ liệu cũng cho thấy hiệu quả của nhiệm vụ RAG tiên tiến của Zephyr có thể cạnh tranh với GPT-3.5 và Claude 2.
Họ tiếp tục nói thêm rằng Zephyr không chỉ hoạt động tốt trên RAG, mà còn trong việc định tuyến, lập kế hoạch truy vấn, truy xuất các câu lệnh SQL phức tạp và trích xuất dữ liệu có cấu trúc.
Các quan chức cũng đưa ra kết quả thử nghiệm và trên MT-Bench, Zephyr-7B-beta có hiệu suất mạnh mẽ so với các mẫu lớn hơn như Llama2-Chat-70B.
Nhưng đối với các nhiệm vụ phức tạp hơn như mã hóa và toán học, Zephyr-7B-beta tụt hậu so với các mô hình độc quyền và đòi hỏi nhiều nghiên cứu hơn để thu hẹp khoảng cách.
** Từ bỏ học tăng cường**
Trong khi mọi người đang thử nghiệm các hiệu ứng của Zephyr, các nhà phát triển cho biết điều thú vị nhất không phải là các số liệu, mà là cách mô hình được đào tạo.
Sử dụng bộ dữ liệu ưu tiên quy mô lớn: UltraFeedback
Sử dụng Tối ưu hóa sở thích trực tiếp (DPO) thay vì học tăng cường
Thật bất ngờ, việc vượt quá tập dữ liệu ưu tiên mang lại kết quả tốt hơn
Nói rộng ra, như đã đề cập ở phần đầu, lý do chính khiến Zephyr có thể vượt qua 70B Llama 2 là do sử dụng phương pháp tinh chỉnh đặc biệt.
Không giống như phương pháp học tăng cường PPO truyền thống, nhóm nghiên cứu đã sử dụng sự hợp tác gần đây giữa Đại học Stanford và CZ Biohub để đề xuất cách tiếp cận DPO.
Theo các nhà nghiên cứu:
DPO ổn định hơn nhiều so với PPO.
Nói một cách đơn giản, DPO có thể được giải thích như sau:
Để làm cho đầu ra của mô hình phù hợp hơn với sở thích của con người, cách tiếp cận truyền thống là tinh chỉnh mô hình mục tiêu bằng mô hình phần thưởng. Nếu đầu ra tốt, bạn sẽ được thưởng, và nếu đầu ra xấu, bạn sẽ không được thưởng.
Mặt khác, cách tiếp cận DPO bỏ qua chức năng phần thưởng mô hình hóa và tương đương với việc tối ưu hóa mô hình trực tiếp trên dữ liệu ưu tiên.
Nói chung, DPO giải quyết vấn đề đào tạo tăng cường khó khăn và tốn kém do phản hồi của con người.
Về mặt đào tạo cụ thể của Zephyr, nhóm nghiên cứu ban đầu đã tinh chỉnh Zephyr-7B-alpha trên một biến thể hợp lý của bộ dữ liệu UltraChat, chứa 1,6 triệu cuộc hội thoại do ChatGPT tạo ra (còn lại khoảng 200.000).
(Lý do cho việc tinh giản là nhóm phát hiện ra rằng Zephyr đôi khi được viết sai lệch, chẳng hạn như "Xin chào. Bạn có khỏe không?"; Đôi khi câu trả lời bắt đầu bằng "Tôi không có X cá nhân". )
Sau đó, họ tiếp tục căn chỉnh mô hình với bộ dữ liệu openbmb / UltraFeedback có sẵn công khai bằng phương pháp DPO Trainer của TRL.
Bộ dữ liệu chứa 64.000 cặp phản hồi nhanh từ các mô hình khác nhau. Mỗi phản hồi được xếp hạng theo GPT-4 dựa trên các tiêu chí như tính hữu ích và được đưa ra điểm số mà từ đó có được ưu tiên AI.
Một phát hiện thú vị là khi sử dụng phương pháp DPO, hiệu quả thực sự tốt hơn sau khi quá tải khi thời gian đào tạo tăng lên. Các nhà nghiên cứu tin rằng điều này tương tự như overfitting trong SFT.
Điều đáng nói là nhóm nghiên cứu cũng giới thiệu rằng việc tinh chỉnh mô hình bằng phương pháp này chỉ tốn 500 đô la, tức là 8 giờ chạy trên 16 chiếc A100.
Khi nâng cấp Zephyr lên phiên bản beta, nhóm nghiên cứu tiếp tục giải thích cách tiếp cận của họ.
Họ nghĩ về việc tinh chỉnh có giám sát chưng cất (dSFT) được sử dụng trong các mô hình lớn, nhưng với phương pháp này, mô hình bị lệch và không tạo ra đầu ra phù hợp với ý định của người dùng.
Vì vậy, nhóm nghiên cứu đã cố gắng sử dụng dữ liệu ưu tiên từ AI Feedback (AIF) để xếp hạng các kết quả đầu ra với "mô hình giáo viên" để tạo thành một tập dữ liệu, sau đó áp dụng tối ưu hóa sở thích trực tiếp chưng cất (dDPO) để đào tạo một mô hình phù hợp với ý định của người dùng mà không cần bất kỳ mẫu bổ sung nào trong quá trình tinh chỉnh.
Các nhà nghiên cứu cũng đã kiểm tra hiệu quả khi SFT không được sử dụng và kết quả dẫn đến giảm đáng kể hiệu suất, cho thấy bước dSFT là rất quan trọng.
Hiện tại, ngoài mô hình đã được mã nguồn mở và thương mại, còn có một Demo để thử, vì vậy chúng ta có thể bắt đầu và trải nghiệm nó một cách đơn giản.
Trải nghiệm demo
Trước hết, tôi phải chuyển ra khỏi câu hỏi "thiểu năng trí tuệ" để làm bài kiểm tra.
Về câu hỏi "Bố mẹ không nhận tôi khi họ kết hôn", câu trả lời tổng thể của Zephyr chính xác hơn.
ChatGPT không thể đánh bại câu hỏi này.
Trong thử nghiệm, chúng tôi cũng thấy rằng Zephyr cũng biết về các sự kiện gần đây như phát hành GPT-4 của OpenAI:
Điều này thực sự liên quan đến mô hình cơ bản của nó, mặc dù quan chức Mistral không chỉ định thời hạn cho dữ liệu đào tạo.
Nhưng một số cư dân mạng đã thử nghiệm nó trước đây, và nó cũng biết về nó vào tháng Ba năm nay.
Ngược lại, dữ liệu trước khi đào tạo của Llama 2 tính đến tháng 9/2022 và chỉ có một số dữ liệu được tinh chỉnh tính đến tháng 6/2023.
Ngoài ra, Zephyr rất nhạy bén, vì vậy bạn có thể viết mã và tạo nên những câu chuyện. :
Điều đáng nói là Zephyr trả lời các câu hỏi bằng tiếng Anh tốt hơn và cũng có một vấn đề phổ biến với mô hình "ảo giác".
Các nhà nghiên cứu cũng đề cập đến ảo giác và một dòng văn bản nhỏ được đánh dấu bên dưới hộp nhập liệu cho thấy nội dung do mô hình tạo ra có thể không chính xác hoặc không chính xác.
Vấn đề là Zephyr không sử dụng các phương pháp như học tăng cường với phản hồi của con người để phù hợp với sở thích của con người, cũng như không sử dụng tính năng lọc phản hồi của ChatGPT.
Luôn chọn một trong những con cá emmm và bàn chân gấu.
Zephyr đã có thể làm điều này chỉ với các tham số 70B, điều này đã gây ngạc nhiên cho Andriy Burkov, tác giả của "The 100-Page Machine Learning Book", và thậm chí còn nói:
Zephyr-7B đánh bại Llama 2-70B với mô hình cơ sở của Mistral-7B với cửa sổ ngữ cảnh là 8k token, về mặt lý thuyết có phạm vi chú ý lên tới 128K token.
Điều gì sẽ xảy ra nếu Zephyr là một mô hình 70B? Nó sẽ vượt trội hơn GPT-4? Có vẻ như vậy.
Nếu bạn quan tâm đến Zephyr-7B, bạn có thể thử nó trên hugface.
Liên kết giấy:
Liên kết tham khảo:
[1]
[2]
[3]
[4]
[5]
Xem bản gốc
Trang này có thể chứa nội dung của bên thứ ba, được cung cấp chỉ nhằm mục đích thông tin (không phải là tuyên bố/bảo đảm) và không được coi là sự chứng thực cho quan điểm của Gate hoặc là lời khuyên về tài chính hoặc chuyên môn. Xem Tuyên bố từ chối trách nhiệm để biết chi tiết.
Mô hình 7B tốt nhất lại đổi chủ! Đánh bại 70 tỷ LLaMA2 và máy tính Apple sẽ có thể chạy |mã nguồn mở và miễn phí
Nguồn gốc: qubits
Mô hình tham số 7 tỷ mất 500 đô la để "điều chỉnh" đã đánh bại tham số 70 tỷ Llama 2!
Và máy tính xách tay có thể chạy dễ dàng và hiệu quả tương đương với ChatGPT.
Quan trọng: Miễn phí, không có tiền.
Mô hình mã nguồn mở **Zephyr-7B ** được tạo ra bởi nhóm HuggingFace H4, cá mập điên.
Chìa khóa cho khả năng nổi bật giữa các biến thể của Zephyr là nhóm nghiên cứu đã tinh chỉnh mô hình trên một tập dữ liệu công khai bằng cách sử dụng Tối ưu hóa sở thích trực tiếp (DPO) trên Mistral.
Nhóm nghiên cứu cũng nhận thấy rằng việc loại bỏ sự liên kết tích hợp của tập dữ liệu có thể cải thiện hơn nữa hiệu suất của MT Bench. Zephyr-7B-alpha ban đầu có điểm MT-Bench trung bình là 7,09, vượt qua Llama2-70B-Chat.
**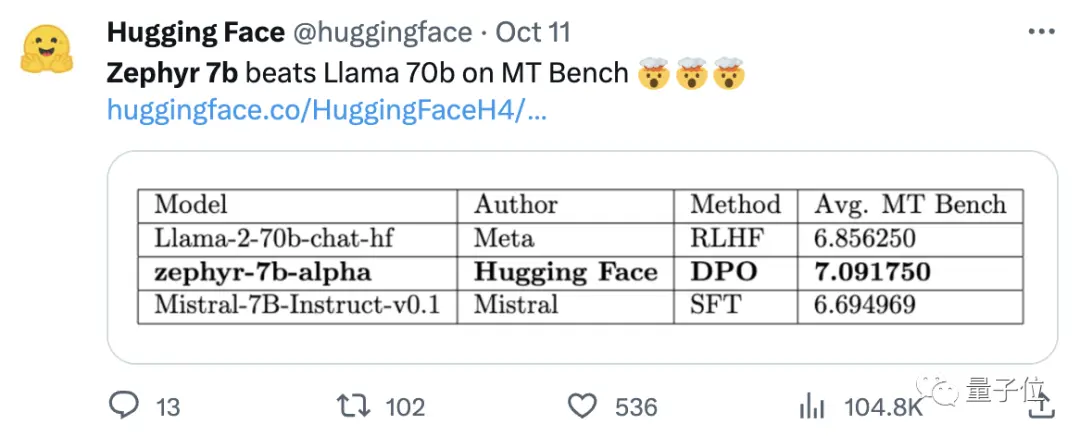 **###### △MT-Bench là một bài kiểm tra điểm chuẩn để đánh giá khả năng xử lý nhiều vòng đối thoại của mô hình và bộ câu hỏi bao gồm 8 hạng mục như viết, nhập vai và trích xuất.
**###### △MT-Bench là một bài kiểm tra điểm chuẩn để đánh giá khả năng xử lý nhiều vòng đối thoại của mô hình và bộ câu hỏi bao gồm 8 hạng mục như viết, nhập vai và trích xuất.
Vấn đề là, sau đó nó tiếp tục nâng cấp!
Nhóm H4 đã ra mắt thế hệ thứ hai của Zephyr-7B-beta. Họ nói thêm rằng họ đã khám phá ý tưởng trích xuất sự liên kết từ GPT-4, Claude 2 và sau đó tiêm nó vào các mô hình nhỏ, phát triển một phương pháp sử dụng tối ưu hóa sở thích trực tiếp chưng cất (dDPO) cho các mô hình nhỏ.
Ở thế hệ thứ hai của Zephyr, điểm MT-Bench trung bình tăng lên 7,34.
Từ Mistral có nghĩa là gió khô, lạnh và mạnh trong tiếng Pháp, trong khi Zephyr có nghĩa là gió tây nhẹ, dễ chịu.
Không có nghi ngờ rằng có một sở thú ở phía bên kia của Llama, và không có nghi ngờ rằng có một văn phòng thời tiết ở phía này.
** Mô hình 7B tốt nhất lại đổi chủ **
Hãy bắt đầu với các yêu cầu máy tính để chạy Zephyr. Cư dân mạng nói "Quần Thái cay" sau khi thử nghiệm! , máy tính xách tay (Apple M1 Pro) là đủ, "kết quả rất tốt".
Dữ liệu cũng cho thấy hiệu quả của nhiệm vụ RAG tiên tiến của Zephyr có thể cạnh tranh với GPT-3.5 và Claude 2.
Họ tiếp tục nói thêm rằng Zephyr không chỉ hoạt động tốt trên RAG, mà còn trong việc định tuyến, lập kế hoạch truy vấn, truy xuất các câu lệnh SQL phức tạp và trích xuất dữ liệu có cấu trúc.
** Từ bỏ học tăng cường**
Trong khi mọi người đang thử nghiệm các hiệu ứng của Zephyr, các nhà phát triển cho biết điều thú vị nhất không phải là các số liệu, mà là cách mô hình được đào tạo.
Những điểm nổi bật được tóm tắt dưới đây:
Nói rộng ra, như đã đề cập ở phần đầu, lý do chính khiến Zephyr có thể vượt qua 70B Llama 2 là do sử dụng phương pháp tinh chỉnh đặc biệt.
Không giống như phương pháp học tăng cường PPO truyền thống, nhóm nghiên cứu đã sử dụng sự hợp tác gần đây giữa Đại học Stanford và CZ Biohub để đề xuất cách tiếp cận DPO.
Nói một cách đơn giản, DPO có thể được giải thích như sau:
Để làm cho đầu ra của mô hình phù hợp hơn với sở thích của con người, cách tiếp cận truyền thống là tinh chỉnh mô hình mục tiêu bằng mô hình phần thưởng. Nếu đầu ra tốt, bạn sẽ được thưởng, và nếu đầu ra xấu, bạn sẽ không được thưởng.
Mặt khác, cách tiếp cận DPO bỏ qua chức năng phần thưởng mô hình hóa và tương đương với việc tối ưu hóa mô hình trực tiếp trên dữ liệu ưu tiên.
Nói chung, DPO giải quyết vấn đề đào tạo tăng cường khó khăn và tốn kém do phản hồi của con người.
Về mặt đào tạo cụ thể của Zephyr, nhóm nghiên cứu ban đầu đã tinh chỉnh Zephyr-7B-alpha trên một biến thể hợp lý của bộ dữ liệu UltraChat, chứa 1,6 triệu cuộc hội thoại do ChatGPT tạo ra (còn lại khoảng 200.000).
(Lý do cho việc tinh giản là nhóm phát hiện ra rằng Zephyr đôi khi được viết sai lệch, chẳng hạn như "Xin chào. Bạn có khỏe không?"; Đôi khi câu trả lời bắt đầu bằng "Tôi không có X cá nhân". )
Sau đó, họ tiếp tục căn chỉnh mô hình với bộ dữ liệu openbmb / UltraFeedback có sẵn công khai bằng phương pháp DPO Trainer của TRL.
Bộ dữ liệu chứa 64.000 cặp phản hồi nhanh từ các mô hình khác nhau. Mỗi phản hồi được xếp hạng theo GPT-4 dựa trên các tiêu chí như tính hữu ích và được đưa ra điểm số mà từ đó có được ưu tiên AI.
Một phát hiện thú vị là khi sử dụng phương pháp DPO, hiệu quả thực sự tốt hơn sau khi quá tải khi thời gian đào tạo tăng lên. Các nhà nghiên cứu tin rằng điều này tương tự như overfitting trong SFT.
Họ nghĩ về việc tinh chỉnh có giám sát chưng cất (dSFT) được sử dụng trong các mô hình lớn, nhưng với phương pháp này, mô hình bị lệch và không tạo ra đầu ra phù hợp với ý định của người dùng.
Các nhà nghiên cứu cũng đã kiểm tra hiệu quả khi SFT không được sử dụng và kết quả dẫn đến giảm đáng kể hiệu suất, cho thấy bước dSFT là rất quan trọng.
Trải nghiệm demo
Trước hết, tôi phải chuyển ra khỏi câu hỏi "thiểu năng trí tuệ" để làm bài kiểm tra.
Về câu hỏi "Bố mẹ không nhận tôi khi họ kết hôn", câu trả lời tổng thể của Zephyr chính xác hơn.
Nhưng một số cư dân mạng đã thử nghiệm nó trước đây, và nó cũng biết về nó vào tháng Ba năm nay.
Ngoài ra, Zephyr rất nhạy bén, vì vậy bạn có thể viết mã và tạo nên những câu chuyện. :
Các nhà nghiên cứu cũng đề cập đến ảo giác và một dòng văn bản nhỏ được đánh dấu bên dưới hộp nhập liệu cho thấy nội dung do mô hình tạo ra có thể không chính xác hoặc không chính xác.
Luôn chọn một trong những con cá emmm và bàn chân gấu.
Zephyr đã có thể làm điều này chỉ với các tham số 70B, điều này đã gây ngạc nhiên cho Andriy Burkov, tác giả của "The 100-Page Machine Learning Book", và thậm chí còn nói:
Liên kết giấy:
Liên kết tham khảo:
[1]
[2]
[3]
[4]
[5]