# 探索Circle STARKs近年來,STARKs協議設計的趨勢是轉向使用較小的字段。最早期的STARKs生產實現使用的是256位字段,即對大數字進行模運算。但這種設計效率較低,處理大數字會浪費很多算力。爲解決這個問題,STARKs開始使用更小的字段:首先是Goldilocks,然後是Mersenne31和BabyBear。這種轉變大幅提升了證明速度。例如Starkware現在能在一臺M3筆記本上每秒證明620,000個Poseidon2哈希。這意味着只要我們信任Poseidon2作爲哈希函數,就可以解決高效ZK-EVM開發的難題。那麼這些技術是如何工作的?小字段上的證明如何構建?本文將探討這些細節,特別關注Circle STARKs這種與Mersenne31字段兼容的方案。## 使用小字段時的常見問題在創建基於哈希的證明時,一個重要技巧是通過證明多項式在隨機點的評估來間接驗證多項式性質。這可以大大簡化證明過程。例如,假設協議要求你生成一個多項式A的commitment,滿足A^3(x) + x - A(ωx) = x^N。協議可以要求你選擇隨機坐標r並證明A(r)^3 + r - A(ωr) = r^N。然後反推A(r) = c,你證明Q = (A - c)/(X - r)是一個多項式。爲防止攻擊,我們需要在攻擊者提供A後再選擇r。在基於橢圓曲線的協議中,這很簡單:我們可以選擇一個隨機的256位數字作爲r。但在小字段STARKs中,只有約20億個r可選,攻擊者可能通過窮舉破解。這個問題有兩個解決方案:1. 進行多次隨機檢查2. 擴展字段多次隨機檢查簡單有效,但可能存在效率問題。擴展域類似於復數,但基於有限域。我們引入新值α,聲明α^2=某個值。這樣創建了一個新的數學結構,能在有限域上進行更復雜的運算。通過擴展域,我們有了足夠多的值來選擇,滿足安全需求。大部分數學運算仍在基礎字段上進行,只在需要增強安全性時使用更大的字段。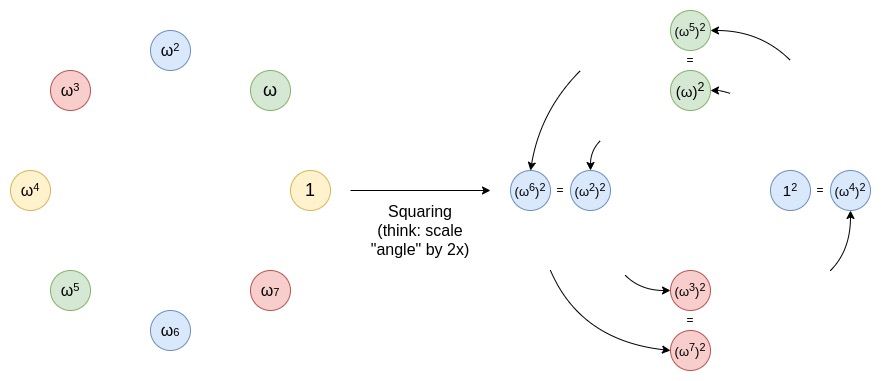## Regular FRIFRI (Fast Reed-Solomon Interactive)協議是構建SNARK或STARK的重要步驟。它通過將證明多項式度數爲d的問題簡化爲證明度數爲d/2的問題來簡化驗證過程。這個過程可以重復多次,每次都將問題簡化一半。FRI的工作原理是重復簡化過程。從證明多項式度數爲d開始,通過一系列步驟,最終證明度數爲d/2。每次簡化後,生成的多項式度數逐步減小。如果某個階段輸出不符合預期,那一輪檢查將失敗。爲實現域的逐步減少,使用了二對一映射。這種映射允許將數據集大小減半,同時保留相同屬性。這種操作可以想象成將圓周上的線段沿圓周伸展兩圈的過程。爲使映射技術有效,原始乘法子羣的大小需要有大的2的冪作爲因子。BabyBear的模數使其最大乘法子羣包含所有非零值,非常適合此技術。Mersenne31的乘法子羣大小只有一個2的冪因子,限制了其應用範圍。Mersenne31域非常適合在32位CPU/GPU上進行算術運算,比BabyBear域快約1.3倍。如果能在Mersenne31域中實現FRI,將顯著提升計算效率。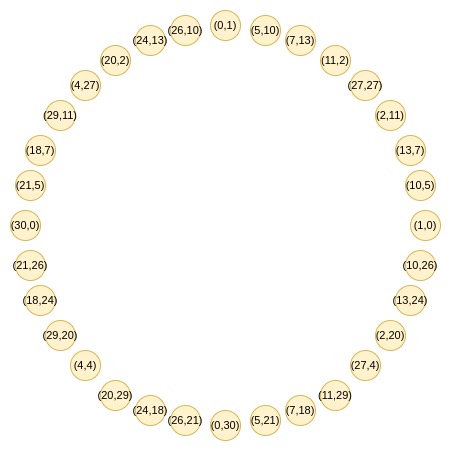## Circle FRICircle STARKs的巧妙之處在於,給定質數p,可以找到大小爲p的羣體,具有類似的二對一特性。這個羣體由滿足特定條件的點組成,如x^2 mod p等於某值的點集。這些點遵循加法規律:(x1,y1) + (x2,y2) = (x1x2 - y1y2, x1y2 + x2y1)雙倍形式是:2 * (x,y) = (2x^2 - 1, 2xy)Circle FRI首先將所有點收斂到一條直線上,然後進行隨機線性組合得到一維多項式P(x)。從第二輪開始,映射變爲:f0(2x^2-1) = (F(x) + F(-x))/2這個映射每次將集合大小減半,將圓上兩個相對點的x坐標轉換爲倍增後點的x坐標。這本可以在二維空間完成,但一維操作更高效。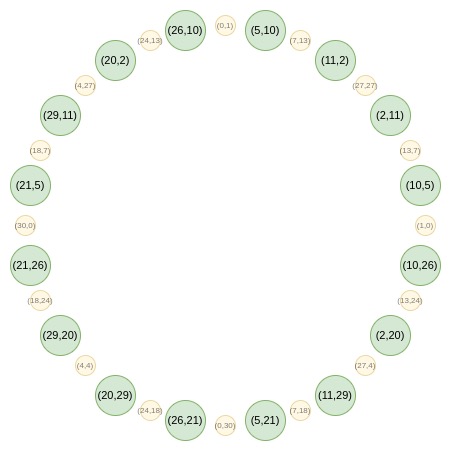## Circle FFTsCircle group也支持FFT,構造方式與FRI類似。Circle FFT處理的對象是Riemann-Roch空間,而不是嚴格的多項式。Circle FFT輸出的系數是特定於Circle FFT的基礎。作爲開發者,你幾乎可以完全忽略這一點。STARKs只需將多項式作爲評估值集合存儲。唯一需要FFT的地方是進行低度擴展:給定N個值,生成k*N個同一多項式上的值。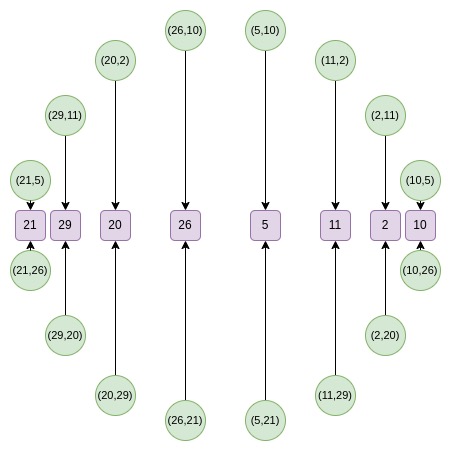## Quotienting在Circle STARKs中,由於沒有可以通過單點的線性函數,需要採用不同技巧替代傳統商運算。我們不得不通過在兩點上評估來證明,添加一個虛擬點。如果多項式P在x1處等於y1,在x2處等於y2,我們選擇插值函數L,在這兩點相等。然後證明P-L在兩點爲零,通過L除以L來證明商Q是多項式。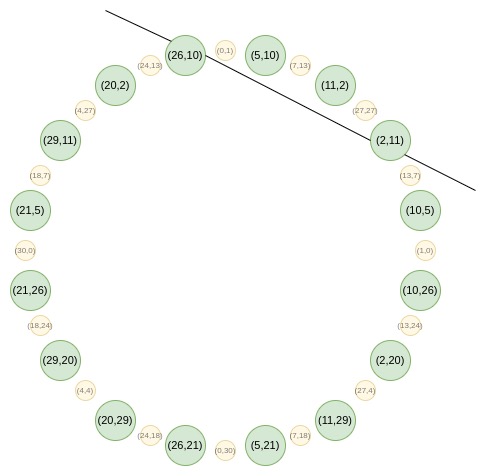## Vanishing polynomials在Circle STARKs中,消失多項式爲:Z1(x,y) = yZ2(x,y) = xZn+1(x,y) = (2 * Zn(x,y)^2) - 1這可以從折疊函數推導:在Circle STARKs中重復使用x → 2x^2 - 1。第一輪需要特殊處理。## Reverse bit orderCircle STARKs使用修改的反向位序,反轉除最後一位的每一位,用最後一位決定是否翻轉其他位。這反映了Circle STARKs特有的折疊結構。## 效率Circle STARKs非常高效。計算通常涉及:1. 原生算術:用於業務邏輯2. 原生算術:用於加密學(如Poseidon哈希) 3. 查找參數:通過表查值實現各種計算Circle STARKs充分利用了計算空間,浪費較少。比Binius稍遜,但概念更簡單。## 結論Circle STARKs對開發者來說並不比常規STARKs復雜。理解Circle FRI和FFTs可以幫助理解其他特殊FFTs。目前STARKs基礎層效率接近極限,未來優化方向可能包括:1. 最大化哈希函數和籤名的算術化效率2. 遞歸構造以提高並行化3. 算術化虛擬機以改善開發體驗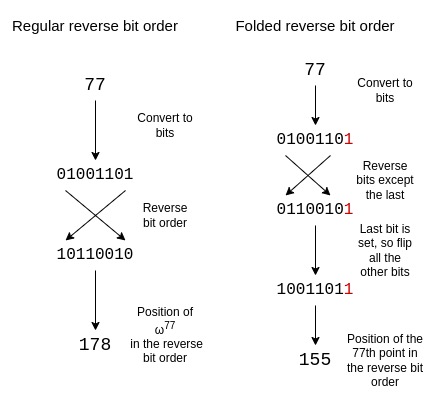


Circle STARKs: 小字段高效ZK證明的探索與突破
探索Circle STARKs
近年來,STARKs協議設計的趨勢是轉向使用較小的字段。最早期的STARKs生產實現使用的是256位字段,即對大數字進行模運算。但這種設計效率較低,處理大數字會浪費很多算力。爲解決這個問題,STARKs開始使用更小的字段:首先是Goldilocks,然後是Mersenne31和BabyBear。
這種轉變大幅提升了證明速度。例如Starkware現在能在一臺M3筆記本上每秒證明620,000個Poseidon2哈希。這意味着只要我們信任Poseidon2作爲哈希函數,就可以解決高效ZK-EVM開發的難題。那麼這些技術是如何工作的?小字段上的證明如何構建?本文將探討這些細節,特別關注Circle STARKs這種與Mersenne31字段兼容的方案。
使用小字段時的常見問題
在創建基於哈希的證明時,一個重要技巧是通過證明多項式在隨機點的評估來間接驗證多項式性質。這可以大大簡化證明過程。
例如,假設協議要求你生成一個多項式A的commitment,滿足A^3(x) + x - A(ωx) = x^N。協議可以要求你選擇隨機坐標r並證明A(r)^3 + r - A(ωr) = r^N。然後反推A(r) = c,你證明Q = (A - c)/(X - r)是一個多項式。
爲防止攻擊,我們需要在攻擊者提供A後再選擇r。在基於橢圓曲線的協議中,這很簡單:我們可以選擇一個隨機的256位數字作爲r。但在小字段STARKs中,只有約20億個r可選,攻擊者可能通過窮舉破解。
這個問題有兩個解決方案:
多次隨機檢查簡單有效,但可能存在效率問題。擴展域類似於復數,但基於有限域。我們引入新值α,聲明α^2=某個值。這樣創建了一個新的數學結構,能在有限域上進行更復雜的運算。
通過擴展域,我們有了足夠多的值來選擇,滿足安全需求。大部分數學運算仍在基礎字段上進行,只在需要增強安全性時使用更大的字段。
Regular FRI
FRI (Fast Reed-Solomon Interactive)協議是構建SNARK或STARK的重要步驟。它通過將證明多項式度數爲d的問題簡化爲證明度數爲d/2的問題來簡化驗證過程。這個過程可以重復多次,每次都將問題簡化一半。
FRI的工作原理是重復簡化過程。從證明多項式度數爲d開始,通過一系列步驟,最終證明度數爲d/2。每次簡化後,生成的多項式度數逐步減小。如果某個階段輸出不符合預期,那一輪檢查將失敗。
爲實現域的逐步減少,使用了二對一映射。這種映射允許將數據集大小減半,同時保留相同屬性。這種操作可以想象成將圓周上的線段沿圓周伸展兩圈的過程。
爲使映射技術有效,原始乘法子羣的大小需要有大的2的冪作爲因子。BabyBear的模數使其最大乘法子羣包含所有非零值,非常適合此技術。Mersenne31的乘法子羣大小只有一個2的冪因子,限制了其應用範圍。
Mersenne31域非常適合在32位CPU/GPU上進行算術運算,比BabyBear域快約1.3倍。如果能在Mersenne31域中實現FRI,將顯著提升計算效率。
Circle FRI
Circle STARKs的巧妙之處在於,給定質數p,可以找到大小爲p的羣體,具有類似的二對一特性。這個羣體由滿足特定條件的點組成,如x^2 mod p等於某值的點集。
這些點遵循加法規律:(x1,y1) + (x2,y2) = (x1x2 - y1y2, x1y2 + x2y1) 雙倍形式是:2 * (x,y) = (2x^2 - 1, 2xy)
Circle FRI首先將所有點收斂到一條直線上,然後進行隨機線性組合得到一維多項式P(x)。從第二輪開始,映射變爲:f0(2x^2-1) = (F(x) + F(-x))/2
這個映射每次將集合大小減半,將圓上兩個相對點的x坐標轉換爲倍增後點的x坐標。這本可以在二維空間完成,但一維操作更高效。
Circle FFTs
Circle group也支持FFT,構造方式與FRI類似。Circle FFT處理的對象是Riemann-Roch空間,而不是嚴格的多項式。Circle FFT輸出的系數是特定於Circle FFT的基礎。
作爲開發者,你幾乎可以完全忽略這一點。STARKs只需將多項式作爲評估值集合存儲。唯一需要FFT的地方是進行低度擴展:給定N個值,生成k*N個同一多項式上的值。
Quotienting
在Circle STARKs中,由於沒有可以通過單點的線性函數,需要採用不同技巧替代傳統商運算。我們不得不通過在兩點上評估來證明,添加一個虛擬點。
如果多項式P在x1處等於y1,在x2處等於y2,我們選擇插值函數L,在這兩點相等。然後證明P-L在兩點爲零,通過L除以L來證明商Q是多項式。
Vanishing polynomials
在Circle STARKs中,消失多項式爲: Z1(x,y) = y Z2(x,y) = x Zn+1(x,y) = (2 * Zn(x,y)^2) - 1
這可以從折疊函數推導:在Circle STARKs中重復使用x → 2x^2 - 1。第一輪需要特殊處理。
Reverse bit order
Circle STARKs使用修改的反向位序,反轉除最後一位的每一位,用最後一位決定是否翻轉其他位。這反映了Circle STARKs特有的折疊結構。
效率
Circle STARKs非常高效。計算通常涉及:
Circle STARKs充分利用了計算空間,浪費較少。比Binius稍遜,但概念更簡單。
結論
Circle STARKs對開發者來說並不比常規STARKs復雜。理解Circle FRI和FFTs可以幫助理解其他特殊FFTs。目前STARKs基礎層效率接近極限,未來優化方向可能包括: