- 話題1/3
50k 熱度
7k 熱度
6k 熱度
2k 熱度
658 熱度
- 置頂
- 親愛的廣場用戶們, #Gate 2025年中社区盛典# 投票中!🔥
🙌 廣場內容達人TOP40榜單新鮮出爐!速速圍觀榜單,爲你喜愛的達人瘋狂打call吧:
www.gate.com/activities/community-vote
每天完成【廣場】互動任務可獲得助力值,每投出30助力值即可參與抽獎一次!
iPhone 16 Pro Max 512G、金牛雕塑、潮流運動套裝、合約體驗券、熱門幣種等你抽!
助力越多,中獎機率越大,下一個抱走iPhone 16的錦鯉就是你!🧧
別猶豫,帶上你的“歐氣”,爲達人衝榜贏大獎!
https://www.gate.com/announcements/article/45974
- 🎉 Gate 廣場 IKA Launchpad 發帖活動來襲!🎉
Gate Launchpad 認購 IKA 最後24小時!曬出你的認購體驗,和大家一起分享,每個人都有機會瓜分 $200 獎池!
🎁 4位幸運分享者*$50合約體驗券每人!
🧐 如何參與:
1.在廣場發帖,帶上 #GateLaunchpad上线IKA# 標籤
2.曬出你的認購截圖 或 分享你的獨特認購小竅門/心得或趣事
3.保證帖子大於50字,內容有趣有料,原創,集齊至少3個互動(點讚/評論/轉發)
IKA認購連結:https://www.gate.com/launchpad/2336?downgarde=true
活動時間:7月28日 12:00 - 7月30日 24:00 (UTC+8)
趕快加入,分享你的精彩時刻,你就是下一個幸運兒!
- 📢 Gate廣場 #创作者活动第二期# 正式開啓!
聚焦 ZKWASM 系列活動,分享你的觀點,瓜分 4,000 枚 $ZKWASM!
ZKWASM 作爲 zk 公鏈先鋒,正在 Gate 平台重磅推廣!
三大活動聯動上線:Launchpool 認購、CandyDrop 空投、Alpha 專屬交易——不要錯過!
🎨 活動一:發布廣場貼文,贏內容獎勵
📅 時間:7月25日 22:00 - 7月29日 22:00(UTC+8)
📌 參與方式:
- 在 Gate 廣場發布與 ZKWASM 或其三大活動相關的原創內容(不少於 100 字)
- 添加標籤: #创作者活动第二期# #ZKWASM#
- 附本人參與 Launchpool/CandyDrop/Alpha 的截圖(如認購、空投或交易)
🏆 獎勵設置:
- 一等獎(1名):1000 枚 $ZKWASM
- 二等獎(2名):500 枚 $ZKWASM
- 三等獎(10名):100 枚 $ZKWASM
📋 評選標準:內容質量、互動量、項目相關性,附活動參與截圖者優先。
📢 活動二:發推贏傳播力獎勵
📌 參與方式:
- 在 X(推特)發布與 ZKWASM 或三大活動相關的原創內容(不少於 100 字)
- 添加標籤: #ZKWASM # GateSquare
- 填寫登記表 👉 https://www.gate.com/quest
- 📢 Gate廣場 #MBG任务挑战# 發帖贏大獎活動火熱開啓!
想要瓜分1,000枚MBG?現在就來參與,展示你的洞察與實操,成爲MBG推廣達人!
💰️ 本期將評選出20位優質發帖用戶,每人可輕鬆獲得50枚MBG!
如何參與:
1️⃣ 調研MBG項目
對MBG的基本面、社區治理、發展目標、代幣經濟模型等方面進行研究,分享你對項目的深度研究。
2️⃣ 參與並分享真實體驗
參與MBG相關活動(包括CandyDrop、Launchpool或現貨交易),並曬出你的參與截圖、收益圖或實用教程。可以是收益展示、簡明易懂的新手攻略、小竅門,也可以是現貨行情點位分析,內容詳實優先。
3️⃣ 鼓勵帶新互動
如果你的帖子吸引到他人參與活動,或者有好友評論“已參與/已交易”,將大幅提升你的獲獎概率!
MBG熱門活動(帖文需附下列活動連結):
Gate第287期Launchpool:MBG — 質押ETH、MBG即可免費瓜分112,500 MBG,每小時領取獎勵!參與攻略見公告:https://www.gate.com/announcements/article/46230
Gate CandyDrop第55期:CandyDrop x MBG — 通過首次交易、交易MBG、邀請好友註冊交易即可分187,500 MBG!參與攻略見公告:https://www.gate.com/announcements
- 📢 #Gate广场征文活动第三期# 正式啓動!
🎮 本期聚焦:Yooldo Games (ESPORTS)
✍️ 分享獨特見解 + 參與互動推廣,若同步參與 Gate 第 286 期 Launchpool、CandyDrop 或 Alpha 活動,即可獲得任意獎勵資格!
💡 內容創作 + 空投參與 = 雙重加分,大獎候選人就是你!
💰總獎池:4,464 枚 $ESPORTS
🏆 一等獎(1名):964 枚
🥈 二等獎(5名):每人 400 枚
🥉 三等獎(10名):每人 150 枚
🚀 參與方式:
在 Gate廣場發布不少於 300 字的原創文章
添加標籤: #Gate广场征文活动第三期#
每篇文章需 ≥3 個互動(點讚 / 評論 / 轉發)
發布參與 Launchpool / CandyDrop / Alpha 任一活動的截圖,作爲獲獎資格憑證
同步轉發至 X(推特)可增加獲獎概率,標籤:#GateSquare 👉 https://www.gate.com/questionnaire/6907
🎯 雙倍獎勵機會:參與第 286 期 Launchpool!
質押 BTC 或 ESPORTS,瓜分 803,571 枚 $ESPORTS,每小時發放
時間:7 月 21 日 20:00 – 7 月 25 日 20:00(UTC+8)
🧠 寫作方向建議:
Yooldo
姚期智領銜提出大模型「思維」架構!邏輯推理正確率達98%,思考方式更像人類了
來源:量子位元
圖靈獎得主姚期智領銜的首篇大語言模型論文來了!
一出手,瞄準的就是「讓大模型像人一樣思考」這個方向——
不僅要讓大模型一步步推理,還要讓它們學會“步步為營”,記住推理中間的所有正確過程。
具体来说,这篇新论文提出了一种叫做累积推理(Cumulative Reasoning)的新方法,显著提高了大模型搞复杂推理的能力。
累積推理正是在此基礎上,加入了一個“驗證者”,及時判斷對錯。由此模型的思考框架也從鏈狀和樹狀,變成了更複雜的「有向無環圖」。
這樣一來,大模型不僅解題思路更清晰,還生出了一手「玩牌」的技巧:
在代數和幾何數論等數學難題上,大模型的相對準確率提升了42%;玩24點,成功率更是飆升到98%。
從這個角度出發設計的累積推理,效果比思考鏈(CoT)和思考樹(ToT)更好。
那麼,這種新方法究竟長啥樣呢?我們一起展開看看。
突破思維鏈&樹「瓶頸」
累積推理的核心,在於改進了大模型思考過程的「形狀」。
具體來說,這個方法用到了3個大語言模型:
推理過程中,「提議者」先給提案,「驗證者」負責評估,「報告者」決定是否要敲定答案、終止思考過程。
**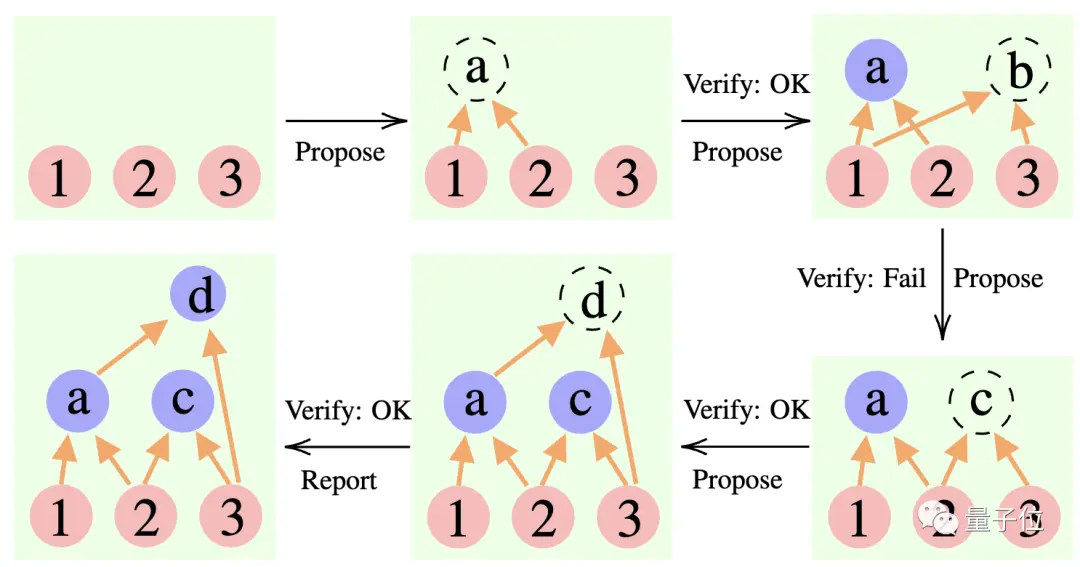 ****△**CR推理範例
****△**CR推理範例
有點像是團隊專案裡的三類角色:小組成員先腦力激盪出各種idea,指導老師「把關」看哪個idea可行,組長決策什麼時候完成專案。
要理解這一點,還得先從大模型思維加強方法「鼻祖」思維鏈(Chain of Thought,CoT)說起。
這個方法在2022年1月由OpenAI科學家Jason Wei等人提出,核心在於為資料集中的輸入加上一段「逐步推理」文字,激發出大模型的思考能力。
**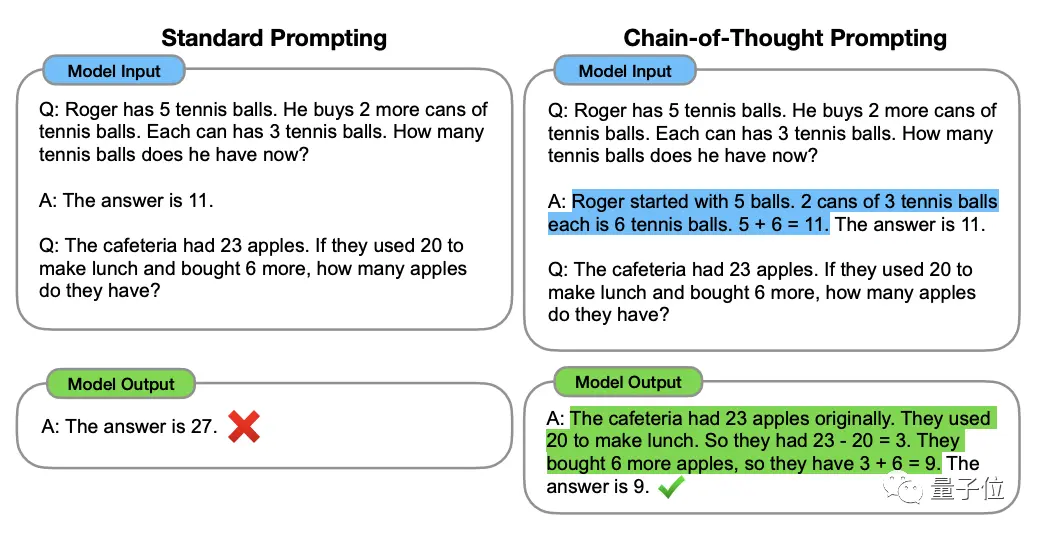 ****△**選自GSM8K資料集
****△**選自GSM8K資料集
基於思維鏈原理,Google也快速跟進了一個“思維鏈PLUS版”,即CoT-SC,主要是進行多次思維鏈過程,並對答案進行多數投票(majority vote)選出最佳答案,進一步提升推理準確率。
但無論思考鏈或CoT-SC,都忽略了一個問題:題目不只一種解法,人類做題目更是如此。
因此,隨後又出現了一種名叫思維樹(Tree of Thought,ToT)的新研究。
這是一種樹狀檢索方案,允許模型嘗試多種不同的推理思路,並自我評估、選擇下一步行動方案,必要時也可以回溯選擇。
這也是為什麼玩24點時,思維鏈加成的GPT-4成功率只有4%,但思維樹成功率卻飆升到74%。
BUT無論思考鏈、CoT-SC或思考樹,都有一個共同的限制:
畢竟不是所有的思考過程都能做成鍊或樹,人類想東西的方式往往還要更複雜。
這次的累積推理新框架,在設計上就突破了這一點——
大模型的整體思考過程不一定是鍊或樹,還可以是一個有向無環圖(DAG)! (嗯,有神經突觸內味了)
**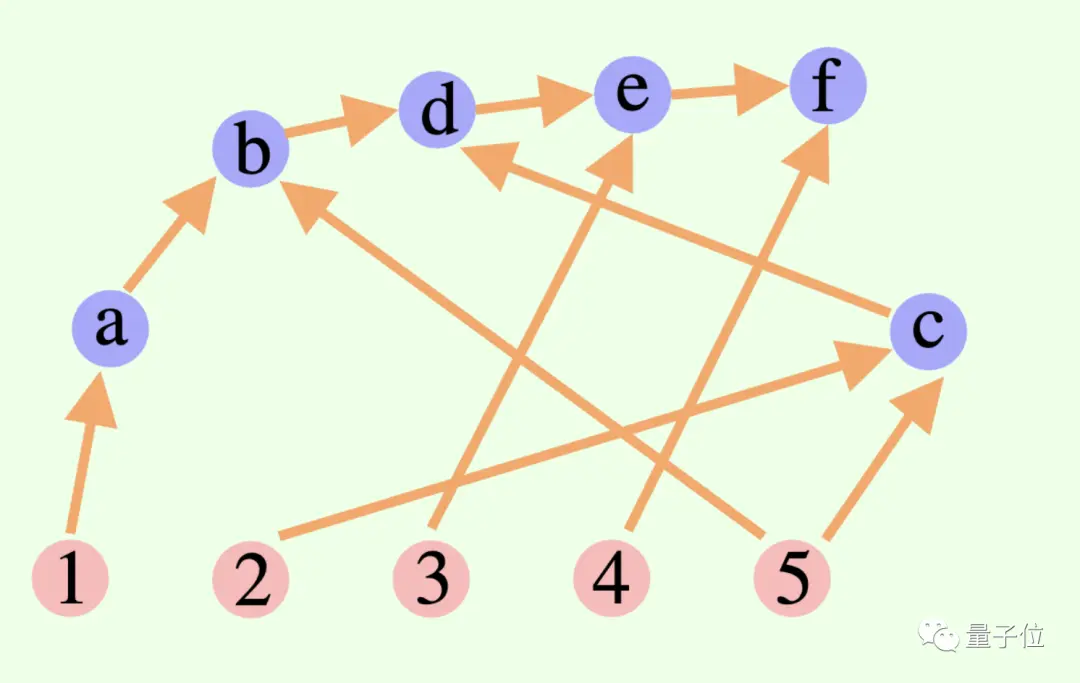 ****△**圖中的邊都有方向,且不存在任何循環路徑;每個有向邊是一個推導步驟
****△**圖中的邊都有方向,且不存在任何循環路徑;每個有向邊是一個推導步驟
這也意味著,它可以將所有歷史上正確的推理結果儲存於記憶體中,以便在當前搜尋分支中探索。 (相較之下,思維樹並不會儲存來自其它分支的資訊)
但累積推理也能和思考鏈無縫切換-只要將**「驗證者」**去掉,就是一個標準的思維鏈模式。
基於此方法設計的累積推理,在各種方法上都取得了不錯的效果。
做數學和搞邏輯推理都在行
研究者選擇了FOLIO wiki和AutoTNLI、24點遊戲、MATH資料集,來對累積推理進行「測試」。
提議者、驗證者、報告者在每次實驗中使用相同的大語言模型,用不同的來設定角色。
這裡用來當實驗的有GPT-3.5-turbo、GPT-4、LLaMA-13B、LLaMA-65B這些基礎模型。
值得一提的是,理想情況下應該使用相關推導任務資料專門預訓練模型、「驗證者」也應加入正規的數學證明器、命題邏輯解算器模組等。
1、邏輯推理能力
FOLIO是一階邏輯推理資料集,問題的標籤可以是「true」、「False」、「Unknown」;AutoTNLI是高階邏輯推理資料集。
在FOLIO wiki資料集上,與直接輸出結果(Direct)、思考鏈(CoT)、進階版思考鏈(CoT-SC)方法相比,累積推理(CR)表現總是最優。
在刪除資料集中有問題的實例(例如答案不正確)後,使用CR方法的GPT-4推理準確率達到了98.04%,並且有最小1.96%的錯誤率。
与CoT方法相比,CR显著提高了LLaMA-13B、LLaMA-65B的性能。
在LLaMA-65B模型上,CR相較於CoT的改良達到了9.3%。
ToT最初論文中用到的是24點遊戲,所以這裡研究者就用這個資料集來做CR和ToT的比較。
ToT使用固定寬度和深度的搜尋樹,CR允許大模型自主確定搜尋深度。
研究人員在實驗中發現,在24點的脈絡中,CR演算法和ToT演算法非常相似。不同點在於,CR中演算法每次迭代最多產生一個新的狀態,而ToT在每次迭代中會產生許多候選狀態,並且過濾、保留一部分狀態。
通俗來講,ToT沒有上面提到的CR有的“驗證者”,不能判斷狀態(a、b、c)正誤,因此ToT比CR會探索更多無效狀態。
也就是說CR不僅有更高的搜尋正確率,也有更高的搜尋效率。
MATH資料集包含了大量數學推理題目,包含代數、幾何、數論等,題目難度分為五級。
用CR方法,模型可以將題目分步驟拆解成能較好完成的子問題,自問自答,直到產生答案。
實驗結果表明,CR在兩種不同的實驗設定下,正確率均超出當前已有方法,總體正確率可達58%,並在Level 5的難題中實現了42%的相對準確率提升,拿下了GPT-4模型下的新SOTA。
清華叉院姚期智、袁洋領銜研究
這篇論文來自清華交叉資訊院姚期智和袁洋領銜的AI for Math課程組。
論文共同第一作者為交叉資訊院2021級博士生張伊凡、楊景欽;
指導教師及共同通訊作者為袁洋助理教授、姚期智院士。
張伊凡
張伊凡2021年本科畢業於北京大學元培學院,現師從袁洋助理教授,主要研究方向為基礎模型(大語言模型)的理論與演算法、自我監督學習、可信人工智慧。
楊景欽
楊景欽2021年於清華大學交叉資訊研究院獲學士學位,現師自袁洋助理教授攻讀博士學位。主要研究方向有大語言模型、自監督學習、智慧醫療等。
袁洋
他的主要研究方向是智慧醫療、AI基礎理論、應用範疇論等。
姚期智
姚期智教授2004年從普林斯頓辭去終身教職回到清華任教;2005年為清華本科生創立了電腦科學實驗班「姚班」;2011年創立「清華量子資訊中心」與「交叉資訊研究所」;2019年再為清華本科生創立了人工智慧學堂班,簡稱「智班」。
如今,他所領導的清華大學交叉資訊研究院早已聲名遠播,姚班、智班都隸屬於交叉資訊院。
姚期智教授研究方向有演算法、密碼學、量子計算等,是這方面的國際先驅與權威。最近,他現身2023世界人工智慧大會,所領導的上海期智研究院目前正在研究「具身通用人工智慧」。
論文連結: