- 話題1/3
17k 熱度
171k 熱度
25k 熱度
25 熱度
40k 熱度
- 置頂
- Gate 合約開倉激勵計劃火熱上線!零門檻瓜分 50,000 ERA
開倉即有獎,交易越多獎勵越多!
新用戶享 20% 加成!
立即參與:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
活動詳情:https://www.gate.com/announcements/article/46429
#Gate # #合约交易 # #ERA#
- 👀 家人們,最近你們都攢了多少 Alpha 積分啦?
空投領到了沒?沒搶到也別急,廣場給你整點額外福利!
🎁 曬出你的 Alpha 收益,咱們就送你$200U代幣盲盒獎勵!
🥇 積分最高曬圖用戶 1 名 → $100 代幣盲盒
✨ 積分榜前五優質分享者 5 名 → 各得 $20 代幣盲盒
📍【怎麼玩】
1️⃣ 帶上話題 #晒出我的Alpha积分收益# 發廣場貼
2️⃣ 曬 Alpha 積分截圖 + 一句話總結:“我靠 Gate Alpha 賺了 ____,真的香!”
👉 還可以分享你的攢分技巧、兌換經驗、積分玩法,越乾貨越容易中獎!
📆【活動時間】
8月4日 18:00 - 8月10日 24:00 (UTC+8)
- 🎉 #CandyDrop合约挑战# 正式開啓!參與即可瓜分 6 BTC 豪華獎池!
📢 在 Gate 廣場帶話題發布你的合約體驗
🎁 優質貼文用戶瓜分$500 合約體驗金券,20位名額等你上榜!
📅 活動時間:2025 年 8 月 1 日 15:00 - 8 月 15 日 19:00 (UTC+8)
👉 活動連結:https://www.gate.com/candy-drop/detail/BTC-98
敢合約,敢盈利
- 🎉 攢成長值,抽華爲Mate三折疊!廣場第 1️⃣ 2️⃣ 期夏季成長值抽獎大狂歡開啓!
總獎池超 $10,000+,華爲Mate三折疊手機、F1紅牛賽車模型、Gate限量週邊、熱門代幣等你來抽!
立即抽獎 👉 https://www.gate.com/activities/pointprize?now_period=12
如何快速賺成長值?
1️⃣ 進入【廣場】,點擊頭像旁標識進入【社區中心】
2️⃣ 完成發帖、評論、點讚、發言等日常任務,成長值拿不停
100%有獎,抽到賺到,大獎等你抱走,趕緊試試手氣!
截止於 8月9日 24:00 (UTC+8)
詳情: https://www.gate.com/announcements/article/46384
#成长值抽奖12期开启#
- 📢 Gate廣場 #NERO发帖挑战# 秀觀點贏大獎活動火熱開啓!
Gate NERO生態周來襲!發帖秀出NERO項目洞察和活動實用攻略,瓜分30,000NERO!
💰️ 15位優質發帖用戶 * 2,000枚NERO每人
如何參與:
1️⃣ 調研NERO項目
對NERO的基本面、社區治理、發展目標、代幣經濟模型等方面進行研究,分享你對項目的深度研究。
2️⃣ 參與並分享真實體驗
參與NERO生態周相關活動,並曬出你的參與截圖、收益圖或實用教程。可以是收益展示、簡明易懂的新手攻略、小竅門,也可以是行情點位分析,內容詳實優先。
3️⃣ 鼓勵帶新互動
如果你的帖子吸引到他人參與活動,或者有好友評論“已參與/已交易”,將大幅提升你的獲獎概率!
NERO熱門活動(帖文需附以下活動連結):
NERO Chain (NERO) 生態周:Gate 已上線 NERO 現貨交易,爲回饋平台用戶,HODLer Airdrop、Launchpool、CandyDrop、餘幣寶已上線 NERO,邀您體驗。參與攻略見公告:https://www.gate.com/announcements/article/46284
高質量帖子Tips:
教程越詳細、圖片越直觀、互動量越高,獲獎幾率越大!
市場見解獨到、真實參與經歷、有帶新互動者,評選將優先考慮。
帖子需原創,字數不少於250字,且需獲得至少3條有效互動
最好7B模型再易主! 打敗700億LLaMA2,蘋果電腦就能跑|開源免費
原文來源:量子位
花500刀「調教」的70億參數模型,打敗700億參數的Llama 2!
且筆記本就能輕鬆跑,效果媲美ChatGPT。
重點:免費、不要錢。
HuggingFace H4團隊打造的開源模型Zephyr-7B,鯊瘋了。
而Zephyr能夠在各變種中脫穎而出,關鍵是團隊在Mistral的基礎上,使用直接偏好優化(DPO)在公開數據集上微調了模型。
團隊還發現,刪除數據集的內置對齊,可以進一步提高MT Bench性能。 初代Zephyr-7B-alpha的MT-Bench平均得分7.09 ,超越Llama2-70B-Chat。
**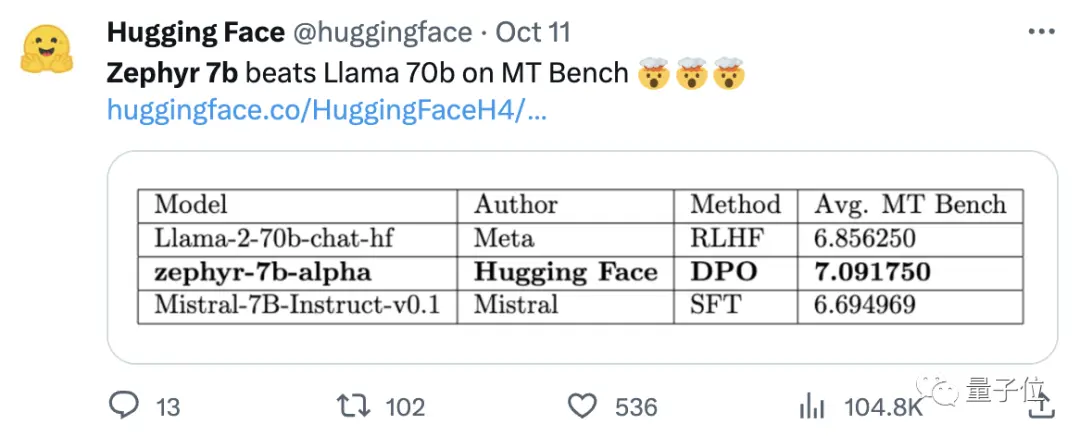 **###### △MT-Bench是評估模型處理多輪對話能力的基準測試,問題集涵蓋寫作、角色扮演、提取等8個類別。
**###### △MT-Bench是評估模型處理多輪對話能力的基準測試,問題集涵蓋寫作、角色扮演、提取等8個類別。
關鍵是,它接著又升級了!
H4團隊推出二代Zephyr-7B-beta。 他們補充道,探索了從GPT-4、Claude 2中提取對齊性,然後將其注入小模型中的想法,開發出了將蒸餾直接偏好優化(dDPO)用於小模型的方法。
二代Zephyr,MT-Bench平均得分升高至7.34。
Mistral這個單詞在法語里代表一種乾燥、寒冷且強勁的風,而Zephyr意思則是溫和、宜人的西風。
Llama那邊是動物園,這邊是氣象局無疑了。
最好的7B模型再易主
先來說運行Zephyr對電腦配置的要求。 網友實測後表示「泰褲辣」! ,筆記本(Apple M1 Pro)就夠用,“結果非常好”。
數據也顯示,Zephyr高級RAG任務效果可以和GPT-3.5、Claude 2相抗衡。
他們還繼續補充道,Zephyr不僅在RAG上效果突出,而且在路由、查詢規劃、檢索複雜SQL語句、結構化數據提取方面也表現良好。
捨棄強化學習
大家都在紛紛測試Zephyr的效果,開發人員卻表示,最有趣的不是各項指標,而是模型的訓練方式。
亮點總結如下:
展開來說,正如開頭所提到的,Zephyr的效果之所以能夠超越70B的Llama 2,主要是因為使用了特殊的微調方法。
與傳統的PPO強化學習方法不同,研究團隊使用了斯坦福大學和CZ Biohub不久前合作提出DPO方法。
DPO簡單來講可以這樣解釋:
要想使模型的輸出更加符合人類偏好,一直以來傳統方法是用一個獎勵模型來微調目標模型。 輸出得好給獎勵,輸出不好不給獎勵。
而DPO的方法繞過了建模獎勵函數,相當於直接在偏好數據上優化模型。
總的來說,DPO解決了人類反饋的強化學習訓練難、訓練成本高的問題。
具體到Zephyr的訓練上,研究團隊最初是在UltraChat數據集精簡后的變種上對Zephyr-7B-alpha進行了微調,這個數據集包含了ChatGPT生成的160萬個對話(精簡后剩下約20萬個)。
(之所以要精簡過濾,是因為團隊發現Zephyr有時大小寫寫不對,比如“Hi. how are you?”; 有時會以“I don't have personal X”為開頭進行回應。 )
之後,他們又通過TRL的DPO Trainer方法,用公開的openbmb/UltraFeedback數據集進一步對齊了該模型。
數據集中包含了64000個來自各種模型的提示-回應對。 每個回應都由GPT-4根據有用性等標準進行排名,並賦予一個得分,從中推出AI偏好。
一個有趣的發現是,在用DPO的方法時,隨著訓練時間增加,過擬合后,效果居然更好了。 研究人員認為這類似於SFT中的過擬合。
他們思考了大模型所用的蒸餾監督微調(dSFT),但用這種方法模型是不對齊的,不能很好地生成符合使用者意圖的輸出。
研究人員還測試了不用SFT時的效果,結果性能大大降低,說明dSFT步驟至關重要。
Demo試玩體驗
首先就不得不搬出「弱智吧」問題來考一考了。
在“爸媽結婚不帶我”這個問題上,Zephyr總體回答較為準確。
但之前就有網友測試過,今年三月份的事它也知道。
此外,Zephyr的回應速度也非常快,寫代碼、編故事都不在話下。 :
研究人員也有提到幻覺問題,輸入框的下方也標有一行小字,指明該模型生成的內容可能不準確或錯誤。
emmm魚和熊掌總要選一個。
Zephyr只有70B參數就能做到這樣的效果,讓《100頁的機器學習書》作者Andriy Burkov也很吃驚,甚至表示:
論文連結:
參考連結:
[1]
[2]
[3]
[4]
[5]